
تصميم تحليلات الدفق ونظم تدفق البيانات لديها الفروق الدقيقة الخاصة بها ، ومشاكلها الخاصة ، ومجموعتها التكنولوجية الخاصة. تحدثنا عن هذا في
الدرس المفتوح التالي ، الذي عقد عشية إطلاق دورة
مهندس البيانات .
في الندوة التي تمت مناقشتها:
- عندما تكون معالجة الدفق مطلوبة ؛
- ما هي العناصر الموجودة في SPOD ، ما هي الأدوات التي يمكننا استخدامها لتنفيذ هذه العناصر ؛
- كيفية بناء نظام تحليل النقر الخاص بك.
محاضر -
ايجور ماتشوك ، كبير مهندسي البيانات في MaximaTelecom.
متى يتم البث؟ تيار مقابل الدفعة
بادئ ذي بدء ، نحتاج إلى معرفة متى نحتاج إلى التدفق ، ومعالجة الدُفعات. دعونا نوضح نقاط القوة والضعف في هذه النهج.
لذلك ، عيوب معالجة الدفعي:- يتم تسليم البيانات مع تأخير. نظرًا لأن لدينا فترة معينة من العمليات الحسابية ، فإننا في هذه الفترة نتخلف دائمًا عن الوقت الفعلي. وكلما زاد التكرار ، كلما تخلفنا عن الركب. وبالتالي ، نحصل على تأخير زمني ، وهو أمر بالغ الأهمية في بعض الحالات ؛
- يتم إنشاء ذروة الحمل على الحديد. إذا قمنا بحساب الكثير في وضع الدُفعات ، فلدينا في نهاية الفترة (اليوم ، الأسبوع ، الشهر) حمولة قصوى ، لأنك تحتاج إلى حساب الكثير من الأشياء. ماذا يؤدي هذا إلى؟ أولاً ، نبدأ بالراحة مقابل الحدود ، التي ، كما تعلمون ، ليست بلا حدود. نتيجة لذلك ، يعمل النظام بشكل دوري إلى الحد الأقصى ، مما يؤدي في كثير من الأحيان إلى فشل. ثانياً ، نظرًا لأن كل هذه الوظائف تبدأ في نفس الوقت ، فهي تتنافس وتحسب ببطء شديد ، أي أنه لا يمكنك الاعتماد على نتيجة سريعة.
لكن معالجة الدُفعات لها مزاياها:- كفاءة عالية. لن نتعمق أكثر ، نظرًا لأن الكفاءة مرتبطة بالضغط ، مع الأطر ، وباستخدام تنسيقات الأعمدة ، وما إلى ذلك. الحقيقة هي أن معالجة الدُفعات ، إذا أخذت عدد السجلات المعالجة لكل وحدة زمنية ، ستكون أكثر كفاءة ؛
- سهولة التطوير والدعم. يمكنك معالجة أي جزء من البيانات عن طريق اختبار وإعادة فرز الأصوات حسب الضرورة.
مزايا دفق معالجة البيانات (الدفق):- يؤدي في الوقت الحقيقي. لا ننتظر نهاية أي فترات: بمجرد أن تصل إلينا البيانات (حتى ولو كانت صغيرة جدًا) ، يمكننا معالجتها على الفور ونقلها. وهذا هو ، النتيجة ، بحكم تعريفها ، تسعى جاهدة في الوقت الحقيقي ؛
- حمولة موحدة على الحديد. من الواضح أن هناك دورات يومية ، وما إلى ذلك ، ومع ذلك ، لا يزال يتم توزيع الحمل على مدار اليوم ، ويبدو أنه أكثر اتساقًا ويمكن التنبؤ به.
العيب الرئيسي لمعالجة الدفق:- تعقيد التنمية والدعم. أولاً ، اختبار البيانات وإدارتها واستردادها أصعب قليلاً مقارنةً بالدُفعات. وترتبط الصعوبة الثانية (في الواقع ، هذه هي المشكلة الأساسية) مع الاستعادة. إذا لم تنجح الوظائف ، وكان هناك فشل ، فسيكون من الصعب للغاية التقاط اللحظة التي تحطم فيها كل شيء. وسوف يتطلب حل المشكلة بذل المزيد من الجهد والموارد من معالجة الدُفعات.
لذلك ، إذا كنت تفكر
فيما إذا كنت بحاجة إلى تدفقات ، أجب عن الأسئلة التالية لنفسك:
- هل تحتاج حقا في الوقت الحقيقي؟
- هل هناك العديد من مصادر التدفق؟
- هل فقدان سجل واحد حرج؟
لنلقِ نظرة على
مثالين :
مثال 1. تحليلات الأسهم للبيع بالتجزئة:- عرض البضائع لا يتغير في الوقت الحقيقي ؛
- غالبًا ما يتم تسليم البيانات في وضع الدُفعات ؛
- فقدان المعلومات أمر بالغ الأهمية.
في هذا المثال ، من الأفضل استخدام الدُفعات.
مثال 2. تحليلات لبوابة الويب:- تحدد سرعة التحليلات زمن الاستجابة للمشكلة ؛
- البيانات تأتي في الوقت الحقيقي.
- خسائر كمية صغيرة من معلومات نشاط المستخدم مقبولة.
تخيل أن التحليلات تعكس مدى شعور زوار بوابة الويب باستخدام المنتج الخاص بك. على سبيل المثال ، قمت بطرح إصدار جديد وتحتاج إلى أن تفهم في غضون 10 إلى 30 دقيقة ما إذا كان كل شيء على ما يرام أم لا ، إذا تعطلت أي ميزات مخصصة. دعنا نقول أن النص من زر "Order" قد رحل - سوف تسمح لك التحليلات بالرد بسرعة على الانخفاض الحاد في عدد الطلبات ، وستفهم على الفور أنك بحاجة إلى التراجع.
وبالتالي ، في المثال الثاني ، من الأفضل استخدام التدفقات.
عناصر SPOD
يلتقط مهندسو معالجة البيانات هذه البيانات ذاتها ونقلها وتسليمها وتحويلها وتخزينها (نعم ، تخزين البيانات هو أيضًا عملية نشطة!).
لذلك ، من أجل بناء نظام معالجة البيانات المتدفقة (SPOD) ، سنحتاج إلى العناصر التالية:
- محمل البيانات (وسيلة إيصال البيانات إلى التخزين) ؛
- ناقل تبادل البيانات (ليس ضروريًا دائمًا ، ولكن لا توجد طريقة لدفقه ، لأنك تحتاج إلى نظام يمكنك من خلاله تبادل البيانات في الوقت الفعلي) ؛
- تخزين البيانات (بدونها) ؛
- محرك ETL (ضروري للقيام بعمليات التصفية والفرز وغيرها من العمليات المختلفة) ؛
- BI (لعرض النتائج) ؛
- أوركسترا (يربط العملية برمتها معا ، وتنظيم معالجة البيانات متعددة المراحل).
في حالتنا ، سننظر في أبسط الموقف والتركيز فقط على العناصر الثلاثة الأولى.
أدوات معالجة دفق البيانات
لدينا العديد من "المرشحين" لدور أداة تحميل
البيانات :
- اباتشي المسايل
- اباتشي نيفي
- StreamSets
اباتشي المسايل
أول ما سنتحدث عنه هو
Apache Flume ، وهي أداة لنقل البيانات بين المصادر والمستودعات المختلفة.

الايجابيات:
- هناك تقريبا في كل مكان
- تستخدم منذ فترة طويلة
- مرنة وقابلة للتوسيع بما فيه الكفاية
سلبيات:
- التكوين غير مريح
- يصعب مراقبته
بالنسبة لتكوينه ، يبدو كالتالي:

أعلاه ، نقوم بإنشاء قناة واحدة بسيطة موجودة على المنفذ ، وتأخذ البيانات من هناك وتسجيلها ببساطة. من حيث المبدأ ، لوصف عملية واحدة ، لا يزال هذا طبيعيًا ، لكن عندما يكون لديك العشرات من هذه العمليات ، يتحول ملف التكوين إلى جهنم. يضيف شخص ما بعض التكوينات المرئية ، لكن لماذا تهتم إذا كانت هناك أدوات تجعلها خارج الصندوق؟ على سبيل المثال ، نفس NiFi و StreamSets.
اباتشي نيفي
في الواقع ، يؤدي نفس دور Flume ، ولكن مع واجهة مرئية ، وهي ميزة كبيرة ، خاصةً عندما يكون هناك الكثير من العمليات.
بعض الحقائق عن نيفي
- وضعت أصلا في وكالة الأمن القومي.
- Hortonworks الآن مدعومة وتطويرها.
- جزء من HDF من Hortonworks ؛
- لديه إصدار خاص من MiNiFi لجمع البيانات من الأجهزة.
يبدو النظام مثل هذا:
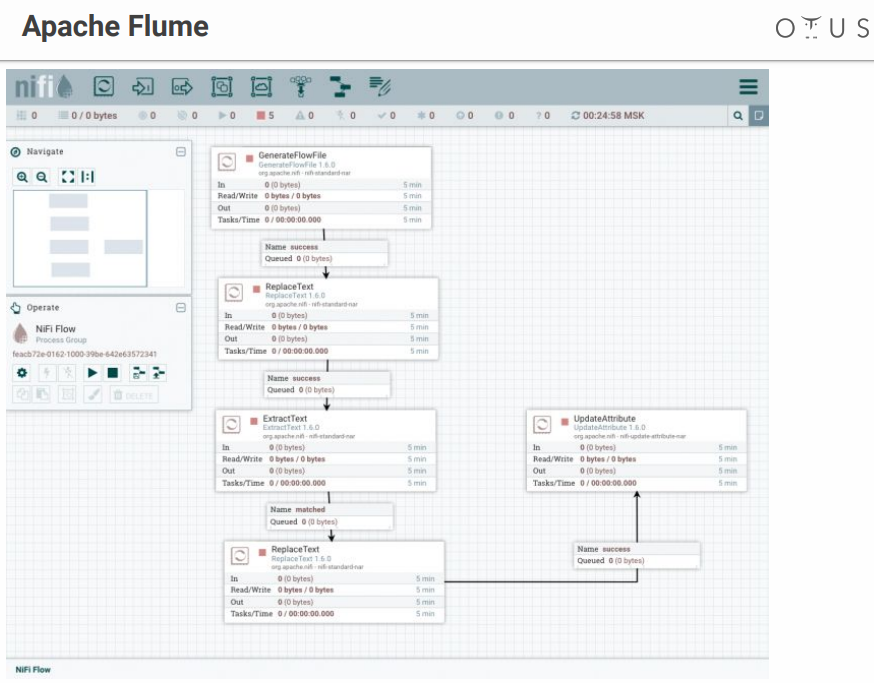
لدينا مجال للإبداع ومراحل معالجة البيانات التي نرميها هناك. هناك العديد من الموصلات لجميع الأنظمة الممكنة ، إلخ.
StreamSets
إنه أيضًا نظام للتحكم في تدفق البيانات مع واجهة مرئية. تم تطويره من قبل أشخاص من Cloudera ، يتم تثبيته بسهولة باسم Parcel على CDH ، ويحتوي على إصدار خاص من SDC Edge لجمع البيانات من الأجهزة.
يتكون من عنصرين:
- SDC - نظام يقوم بمعالجة البيانات المباشرة (مجانًا) ؛
- StreamSets Control Hub - مركز تحكم للعديد من SDCs مع ميزات إضافية لتطوير paylines (المدفوعة).
يبدو شيء مثل هذا:

لحظة غير سارة - تحتوي StreamSets على أجزاء مجانية ومدفوعة.
حافلة البيانات
الآن دعنا نتعرف على المكان الذي سنقوم فيه بتحميل هذه البيانات. المتقدمين:
يعد Apache Kafka الخيار الأفضل ، ولكن إذا كان لديك RabbitMQ أو NATS في شركتك ، وتحتاج إلى إضافة القليل من التحليلات ، فإن نشر تطبيق Kafka من البداية لن يكون مربحًا للغاية.
في جميع الحالات الأخرى ، يعتبر كافكا خيارًا رائعًا. في الواقع ، هو وسيط الرسائل مع التوسع الأفقي وعرض النطاق الترددي الضخم. تم دمجها بشكل كامل في النظام البيئي بأكمله من الأدوات للعمل مع البيانات ، ويمكن أن تحمل الأحمال الثقيلة. لديه واجهة عالمية وهو نظام الدورة الدموية لمعالجة البيانات لدينا.
في الداخل ، يتم تقسيم كافكا إلى موضوع - دفق بيانات معين معيّن من الرسائل التي لها نفس المخطط أو ، على الأقل ، لنفس الغرض.
لمناقشة الفروق الدقيقة التالية ، عليك أن تتذكر أن مصادر البيانات قد تختلف قليلاً. تنسيق البيانات مهم للغاية:

يستحق تنسيق تسلسل بيانات Apache Avro إشارة خاصة. يستخدم النظام JSON لتحديد بنية البيانات (المخطط) المسلسل في
تنسيق ثنائي مضغوط . لذلك ، نحن نحفظ كمية هائلة من البيانات ، والتسلسل / إلغاء التسلسل أرخص.
يبدو أن كل شيء على ما يرام ، ولكن وجود ملفات منفصلة مع دوائر تشكل مشكلة ، حيث نحتاج إلى تبادل الملفات بين أنظمة مختلفة. قد يبدو الأمر بسيطًا ، لكن عندما تعمل في أقسام مختلفة ، يمكن للاعبين على الطرف الآخر تغيير شيء وتهدئة ، وكل شيء سينهار من أجلك.
من أجل عدم نقل جميع هذه الملفات إلى محركات الأقراص المحمولة والأقراص المرنة ولوحات الكهوف ، هناك خدمة تسجيل خاصة بالمخطط. هذه خدمة لمزامنة مخططات avro بين الخدمات التي تكتب وتقرأ من Kafka.

بالنسبة إلى كافكا ، فإن المنتج هو الذي يكتب ، والمستهلك هو الذي يستهلك (يقرأ) البيانات.
مستودع البيانات
المتحدون (في الواقع ، هناك العديد من الخيارات ، لكن لا تأخذ سوى القليل منها):
- HDFS + خلية
- كودو + إمبالا
- ClickHouse
قبل اختيار مستودع ، تذكر ماهية
اللامبالاة . تقول ويكيبيديا أن الشغف (المصطلح اللاتيني - نفس + potens - قادر) - خاصية كائن أو عملية عند تطبيق العملية على الكائن مرة أخرى ، يعطي نفس النتيجة مثل الأولى. في حالتنا ، ينبغي بناء عملية معالجة الدفق بحيث تظل النتيجة صحيحة عند إعادة ملء البيانات المصدر.
كيفية تحقيق ذلك في أنظمة التدفق:
- تحديد معرف فريد (يمكن أن يكون مركبًا)
- استخدم هذا المعرف لإلغاء البيانات المكررة
لا توفر وحدة التخزين HDFS + Hive شغفًا لبث التسجيل "خارج الصندوق" ، لذلك لدينا:
كودو هو مستودع مناسب للاستعلامات التحليلية ، ولكن مع مفتاح أساسي ، لإلغاء البيانات المكررة.
Impala هي واجهة SQL لهذا المستودع (وعدة أخرى).
بالنسبة إلى ClickHouse ، فهذه قاعدة بيانات تحليلية من Yandex. الغرض الرئيسي منه هو التحليلات على طاولة مليئة دفق كبير من البيانات الخام. من بين المزايا - هناك محرك ReplacingMergeTree لإلغاء البيانات المكررة (تم إلغاء البيانات المكررة لتوفير مساحة وقد تتكرر مكررة في بعض الحالات ، تحتاج إلى مراعاة
الفروق الدقيقة ).
يبقى لإضافة بضع كلمات عن
Divolte . إذا كنت تتذكر ، تحدثنا عن حقيقة أن بعض البيانات تحتاج إلى التقاط. إذا كنت بحاجة إلى تنظيم تحليلات لبوابة بسرعة وسهولة ، فإن Divolte هي خدمة ممتازة لالتقاط أحداث المستخدم على صفحة ويب عبر JavaScript.
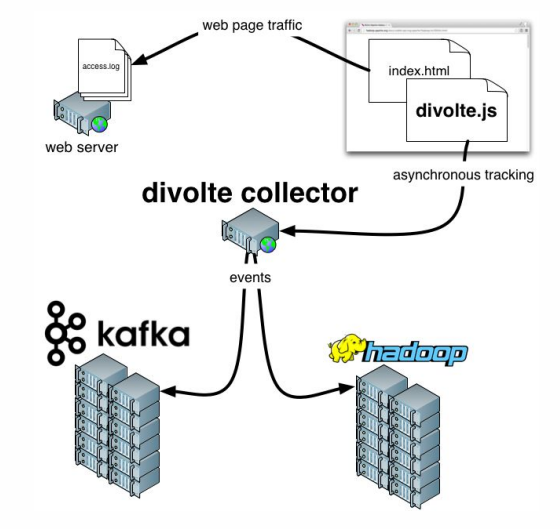
مثال عملي
ما الذي نحاول القيام به؟
دعونا نحاول بناء خط أنابيب لجمع بيانات Clickstream في الوقت الحقيقي.
Clickstream هي بصمة افتراضية يتركها المستخدم أثناء وجوده على موقعك. سنلتقط البيانات باستخدام Divolte ، ونكتبها في كافكا.

تحتاج إلى أن يعمل Docker ، بالإضافة إلى أنك بحاجة إلى استنساخ
المستودع التالي . سيتم إطلاق كل ما يحدث في حاويات. لتشغيل حاويات متعددة باستمرار في وقت واحد ، سيتم استخدام
docker-compose.yml . بالإضافة إلى ذلك ، هناك
Dockerfile يجمع StreamSets لدينا مع بعض التبعيات.
هناك أيضًا ثلاثة مجلدات:
- سيتم كتابة بيانات clickhouse إلى بيانات clickhouse
- بالضبط نفس بابا ( بيانات sdc) سيكون لدينا ل StreamSets ، حيث يمكن للنظام تخزين التكوينات
- يتضمن المجلد الثالث ( أمثلة ) ملف طلب وملف تكوين توجيه الإخراج لـ StreamSets

للبدء ، أدخل الأمر التالي:
docker-compose up
ونحن نستمتع كيف تبدأ الحاويات ببطء ولكن بثبات. بعد البدء ، يمكننا الانتقال إلى العنوان
http: // localhost: 18630 / ولمس Divolte على الفور:

لذلك ، لدينا Divolte ، التي تلقت بالفعل بعض الأحداث وسجلت لهم في كافكا. دعونا نحاول حسابهم باستخدام StreamSets:
http: // localhost: 18630 / (كلمة المرور / اسم المستخدم - admin / admin).

لكي لا تعاني ، من الأفضل
استيراد Pipeline ، وتسمية ذلك ، على سبيل المثال ،
clickstream_pipeline . ومن مجلد الأمثلة نستورد
clickstream.json . إذا كان كل شيء على ما يرام ،
فسوف نرى الصورة التالية :

لذلك ، أنشأنا اتصالاً بكافكا ، مسجلاً أي كافكا نحتاجه ، وسجل أي موضوع يهمنا ، ثم حدد الحقول التي تهمنا ، ثم وضع استنزافًا في كافكا ، وسجل أي كافكا وأي موضوع. الاختلافات هي أنه في حالة واحدة ، تنسيق البيانات هو Avro ، وفي الحالة الثانية فقط JSON.
دعنا ننتقل. يمكننا ، على سبيل المثال ،
إجراء معاينة تلتقط سجلات معينة في الوقت الفعلي من Kafka. ثم نكتب كل شيء.
بعد الإطلاق ، سنرى أن هناك مجموعة من الأحداث تنتقل إلى كافكا ، وهذا يحدث في الوقت الفعلي:

يمكنك الآن إنشاء مستودع لهذه البيانات في ClickHouse. للعمل مع ClickHouse ، يمكنك استخدام عميل أصلي بسيط عن طريق تشغيل الأمر التالي:
docker run -it --rm --network divolte-ss-ch_default yandex/clickhouse-client --host clickhouse
يرجى ملاحظة أن هذا الخط يشير إلى الشبكة التي تريد الاتصال بها. واعتمادًا على كيفية تسمية المجلد بالمستودع ، قد يختلف اسم الشبكة. بشكل عام ، سيكون الأمر كما يلي:
docker run -it --rm --network {your_network_name} yandex/clickhouse-client --host clickhouse
يمكن الاطلاع على قائمة الشبكات باستخدام الأمر:
docker network ls
حسنًا ، لم يتبق شيء:
1.
أولاً ، "قم بتوقيع" ClickHouse الخاص بنا إلى كافكا ، وضح له ما هو تنسيق البيانات التي نحتاجها هناك:
CREATE TABLE IF NOT EXISTS clickstream_topic ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = Kafka SETTINGS kafka_broker_list = 'kafka:9092', kafka_topic_list = 'clickstream', kafka_group_name = 'clickhouse', kafka_format = 'JSONEachRow';
2.
الآن سنقوم بإنشاء جدول حقيقي حيث سنضع البيانات النهائية:
CREATE TABLE clickstream ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = ReplacingMergeTree() ORDER BY (timestamp, pageViewId);
3.
ثم سنقدم علاقة بين هذين الجدولين :
CREATE MATERIALIZED VIEW clickstream_consumer TO clickstream AS SELECT * FROM clickstream_topic;
4.
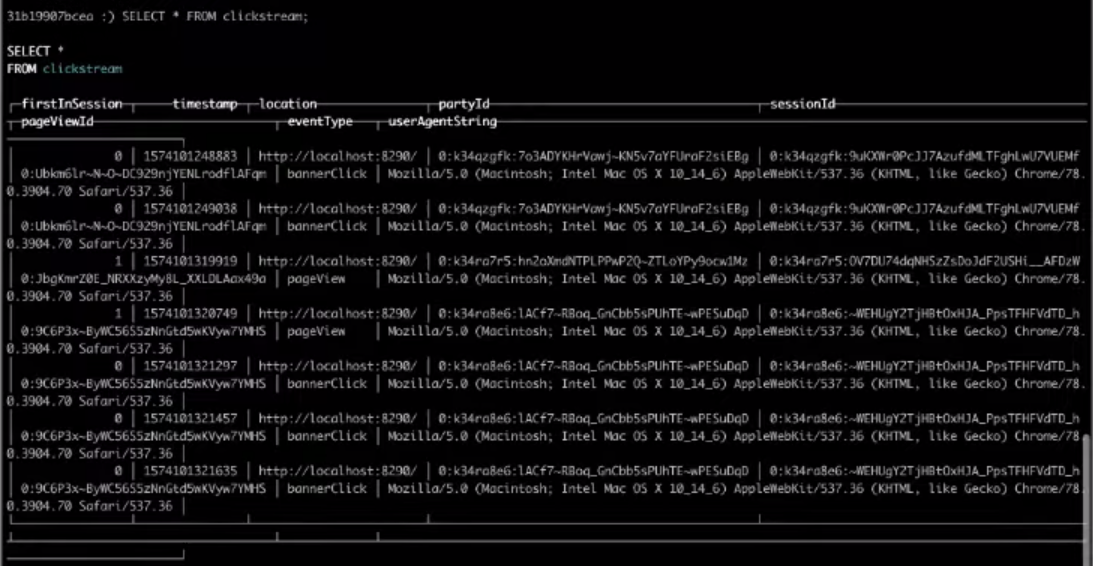
والآن سوف نختار الحقول اللازمة :
SELECT * FROM clickstream;
نتيجة لذلك ، فإن الاختيار من الجدول المستهدف سوف يعطينا النتيجة التي نحتاجها.
هذا كل شيء ، كان أبسط Clickstream التي يمكنك بناء. إذا كنت تريد إكمال الخطوات المذكورة أعلاه بنفسك ،
شاهد الفيديو بالكامل.