
بدأ تاريخ التعلم الآلي في منتصف القرن الماضي. في ذلك الوقت ، كانت هذه التكنولوجيا أكثر من مجال للبحث العلمي والتجارب ، وأعطت أجهزة الكمبيوتر القوية زخما للتطبيق العملي ل ML.
اليوم ، التعلم الآلي هو اتجاه لا يمكن إنكاره في سوق تكنولوجيا المعلومات. تقوم المزيد من الشركات من مختلف الصناعات بإنشاء أقسام لعلوم البيانات من أجل استخدام التعلم الآلي لإيجاد فرص جديدة في البيانات المتراكمة للنمو وتحسين كفاءة العمل. ومع ذلك ، في حين أن هذه المبادرات لا تعطي العائد الواجب. وفقا للاحصاءات ، 8 من أصل 10 حالات مؤكدة لا تدخل حيز التشغيل التجاري.
على الأرجح ، سمعت معظمكم النكتة "أكثر الطرق فعالية لجعل تعلم الآلة أكثر إنتاجية هو شرائح PowerPoint." لسوء الحظ ، هذه ليست مزحة. غالبًا ما تبدو العملية برمتها على النحو التالي: يقوم العمل بنقل البيانات وحالة العمل التي تم تنزيلها من أنظمة العمل. يطور علماء البيانات نموذجًا للتعلم الآلي في Jupiter Notebook ، ويضعون لقطة شاشة للرسوم البيانية على شريحة PowerPoint ، ويرسلونها إلى عميل العمل. هل من الممكن استخدام الشريحة الناتجة في اتخاذ القرارات الإدارية؟ على الأرجح لا ، نظرًا لأن البيانات المتوقعة سرعان ما أصبحت قديمة ، والوضع في العمل خلال هذا الوقت يمكن أن يتغير بشكل خطير.
في محاولة للتغلب على جميع العقبات ووضع تعلم الآلة على التدفق ، تستثمر معظم الشركات في البنية التحتية لجمع وتخزين ومعالجة كميات كبيرة من البيانات - بحيرة البيانات. بالطبع ، هذه خطوة ضرورية. ولكن ماذا هذا التغيير من منظور الأعمال؟ هل من الممكن اتخاذ القرارات على أساس التعلم الآلي؟ لا ، لأن هناك فجوة بين بحيرة البيانات والأعمال. من الواضح أن 86٪ من الشركات التي شملها الاستطلاع تعتقد أن تطبيقات الأعمال من الجيل القادم يجب أن تكون مجهزة بالتعلم الآلي.
قررنا في SAP كتابة سلسلة من المقالات حول كيفية التغلب على الصعوبات الحالية باستخدام منصة SAP Data Intelligence الجديدة ووضع أداة قوية مثل التعلم الآلي في خدمة الأعمال. وإذا كنت مهتمًا بهذا الموضوع ، فاقرأ :)
للبدء ، سوف أخبرك بالمرحلة الأولى والمهمة للغاية في تطوير أي حالة تجارية "البحث عن البيانات وإعدادها". في المقالات اللاحقة ، سننظر في المراحل "تطوير وتدريب النماذج" ، "التكامل مع SAP و مصادر البيانات السحابية المحلية غير التابعة لـ SAP بالتفصيل" ، "إنشاء خدمات لاستخدام النماذج" ، "نقل حالات العمل إلى إنتاجية" ، "مراقبة وتشغيل الحالات التجارية "وأكثر من ذلك بكثير.
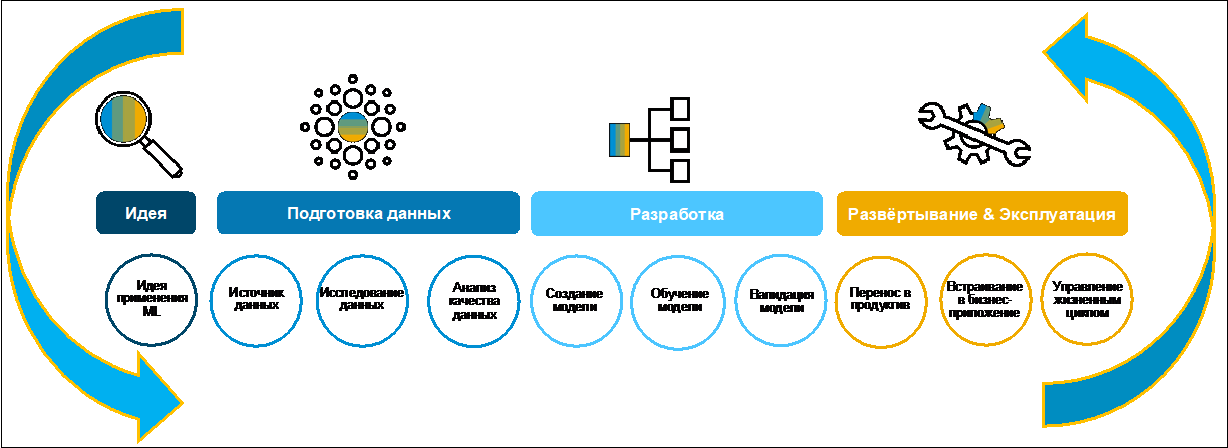
تطوير حالة العمل على أساس التعلم الآلي. بحث وإعداد البيانات.دعنا ننظر إلى عملية إنشاء حالة عمل (الشكل 1).
في البداية ، عادة ما تصاغ فكرة من قبل الشركة. في كثير من الأحيان ، يقوم بذلك عن طيب خاطر ، حيث أن لديه هدفًا محددًا يتمثل في ترقيم الوظائف داخل التحول الرقمي للمشروع بأكمله. لجمع الأفكار وتقييمها وترتيب أولوياتها ، يمكنك استخدام SAP Innovation Management ، على سبيل المثال.
 الشكل 1
الشكل 1في المرحلة الأولى من البحث عن البيانات وإعدادها ، من الضروري أن نفهم ما إذا كانت موجودة على الإطلاق لتطوير حالة العمل ، حيث يتم تخزينها ، وبأي تنسيقات وما هي نوعيتها. يتضمن المشهد النموذجي الحديث العديد من الأنظمة غير المتجانسة. يمكن تكرار البيانات في تطبيقات مختلفة. قد يستغرق العثور على المعلومات الصحيحة الكثير من الوقت. لهذا الغرض ، في ذكاء SAP Data ، تم تبسيط هذه المهمة إلى حد كبير باستخدام كتالوج البيانات الوصفية. دعونا ننظر في ما هو عليه وكيفية استخدامه.
كتالوج البيانات الوصفيةلاستخدام كتالوج البيانات الأولية ، يجب عليك توصيل النظام المصدر بذكاء البيانات. يمكن أن تكون مصادر البيانات لـ Data Intelligence هي الأنظمة المحلية SAP ERP و BW والتسويق ... وغير SAP MES و Oracle و MS SQL و DB2 و Hadoop وغيرها الكثير ، بالإضافة إلى الخدمات السحابية Amazon و Azzure و Google SCP. للاتصال بمصادر البيانات ، تحتاج إلى معلومات حول موقع الأنظمة والمستخدمين الفنيين الذين تم إنشاؤها في هذه الأنظمة خصيصًا للتكامل مع SAP Data Intelligence. يوضح الشكل 2 مثالًا لمشهد بيانات مخصص في SAP Data Intelligence.
 الشكل 2
الشكل 2
بمجرد التهيئة في كتالوج بيانات SAP Data Intelligence Metadata ، يمكن رؤية المعلومات المخزنة على الأنظمة المتصلة. يوضح الشكل 3 قائمة الملفات الموجودة في مجلد DAT263 في Hadoop المتصل بـ SAP Data Intelligence.
 الشكل 3
الشكل 3إذا وجدت البيانات الضرورية لتنفيذ حالة العمل ، فلنقم بإضافة كائنات البيانات إلى الفهرس باستخدام وظيفة النشر. سأستخدم ملف autos_history.csv ، والذي يحتوي على إحصائيات مبيعات السيارات المستعملة. في الشكل 4 ، ترى كيف يمكنك نشر كائن بيانات وبيانات التعريف الخاصة به في الفهرس للوصول السريع في المستقبل.
 الشكل 4
الشكل 4يمكنك تخصيص بنية الدليل ، ومستويات التسلسل الهرمي وفقًا لمتطلبات حالة عملك. على سبيل المثال ، في مجلد Habr_demo الخاص بي ، سيتم جمع كل البيانات الوصفية حول الكائنات التي أحتاجها لهذه المقالة.
كتالوج البيانات الوصفية الذي تم إنشاؤه هو وصول سريع إلى بيانات حالة العمل. سأجري إنشاء ملفات تعريف وتحليل لجودتها على كائنات المجلد الخاص بي في كتالوج بيانات SAP Data Intelligence Metadata. تظهر الشاشة الأولية لكتالوج البيانات الوصفية في الشكل. 5.
 الشكل 5
الشكل 5وهنا كائن البيانات الذي نشرته في مجلد Habr_demo (الشكل 6)
 الشكل 6
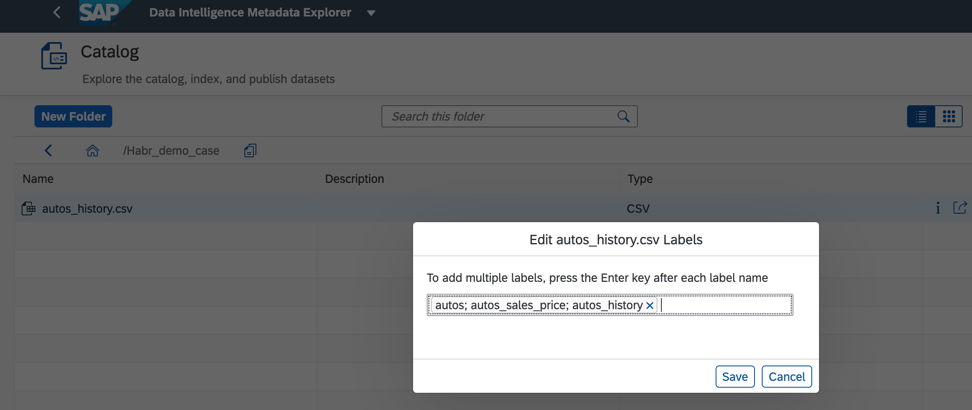
الشكل 6بالإضافة إلى ذلك ، لتحسين عملية البحث وتسريعها ، يمكننا تعيين علامات أو علامات في كتالوج كائنات البيانات ، كما هو موضح في الشكل. 7.
 الشكل 7
الشكل 7يسمح لك كتالوج البيانات الأولية بالبحث عن الكائنات حسب أسمائها وحقولها وكذلك عن طريق التصنيف. قد يحتوي كائن بيانات واحد على تسميات متعددة. يعد هذا أمرًا ملائمًا إذا عمل العديد من المطورين على ذلك ، فبإمكان الجميع تعيين ملصق لحالة أعمالهم ، والعثور بسرعة على كل ما تحتاج إليه. أيضًا ، يمكن للعلامات إبراز البيانات الشخصية والسرية ، والتي يجب أن يكون الوصول إليها محدودًا تمامًا.
في مجموعة البيانات المدروسة ، يعطي البحث حسب التسمية واسم الحقل نتيجة سريعة (الشكل 8). توافق ، أنها مريحة للغاية!
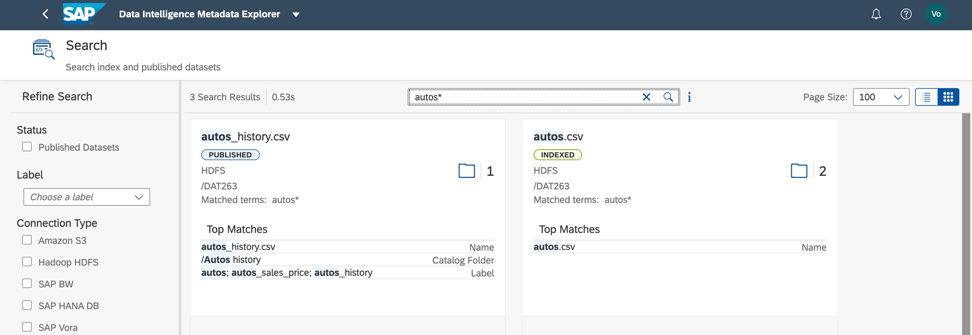 الشكل 8
الشكل 8بعد ذلك ، نحتاج إلى فهم كيفية ملء ملفنا. للقيام بذلك ، يمكننا ملف تعريف البيانات. نبدأ العملية أيضًا من كتالوج البيانات الوصفية وقائمة السياق لكائنات البيانات (الشكل 9).
 الشكل 9
الشكل 9أثناء التوصيف ، سيقرأ فهرس البيانات الوصفية محتويات الملف ، ويحلل هيكله وملؤه. يمكن العثور على النتيجة في صحيفة الوقائع (الشكل 10).
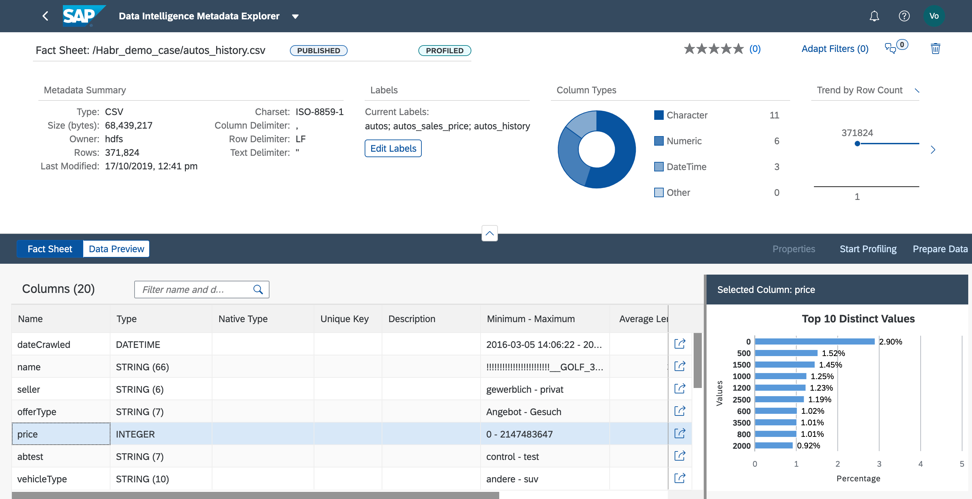 الشكل 10
الشكل 10
في صحيفة الوقائع ، نرى هيكل الملف ومعلومات عن ملء الحقول.
1. في الملف المحدد ، نتيجة للتوصيف ، كشفنا: حقل البائع له قيمة واحدة في جميع الخطوط. هذا يعني أنه يمكننا إزالة هذا الحقل من مجموعة البيانات حتى لا نستخدم التعلم الآلي عند إنشاء النموذج ، لأنه لن يؤثر على النتيجة المتوقعة (الشكل 11).
 الشكل 11.2. عند
الشكل 11.2. عند تحليل عمود السعر ، نفهم أن حوالي 3٪ من البيانات التي لدينا تحتوي على سعر صفري. من أجل استخدام هذا الملف في حالة أعمالنا ، يجب أن نملأ السعر إما بالقيم الفعلية أو المتوسط لهذا المنتج ، أو يجب علينا حذف الأسطر التي بها سعر صفري من الملف (الشكل 12).
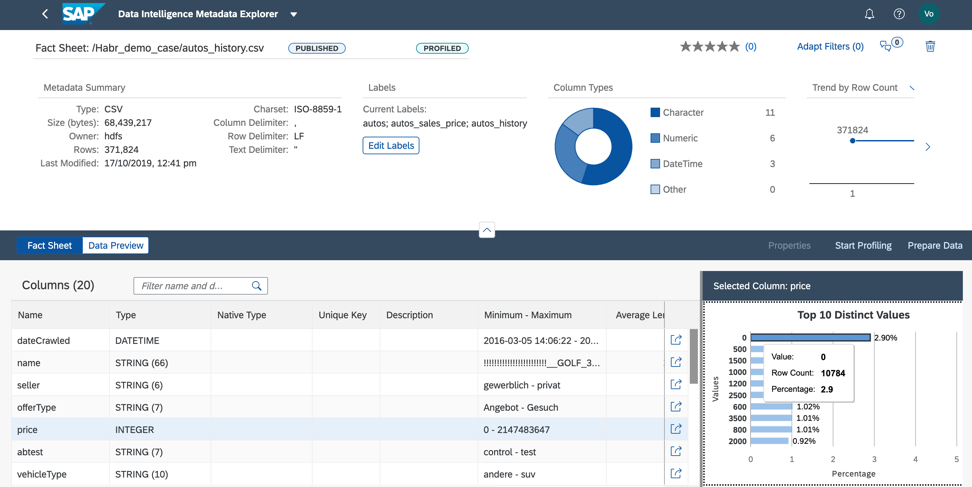 الشكل 12.
الشكل 12.يمكننا القيام بمعالجة البيانات مسبقًا بطريقتين: في كتالوج البيانات الوصفية أو مباشرة في دفتر ملاحظات المشتري. يعتمد اختيار الأداة على من المسؤول عن المعالجة المسبقة للبيانات لحالة العمل. إذا كنت محللًا ، فأنا أوصي باستخدام واجهة إعداد البيانات المرئية المتوفرة في كتالوج البيانات الوصفية. إذا كان عالِم البيانات منشغلاً في إعداد البيانات ، فمن المؤكد أن يكون الخيار لصالح دفتر ملاحظات المشتري ، الذي تم دمجه أيضًا في ذكاء البيانات.
3. يتم توزيع قيمة حقل النموذج بشكل جيد ، مما سيسمح لنا بتدريب النموذج نوعياً ، كما في الشكل 13.
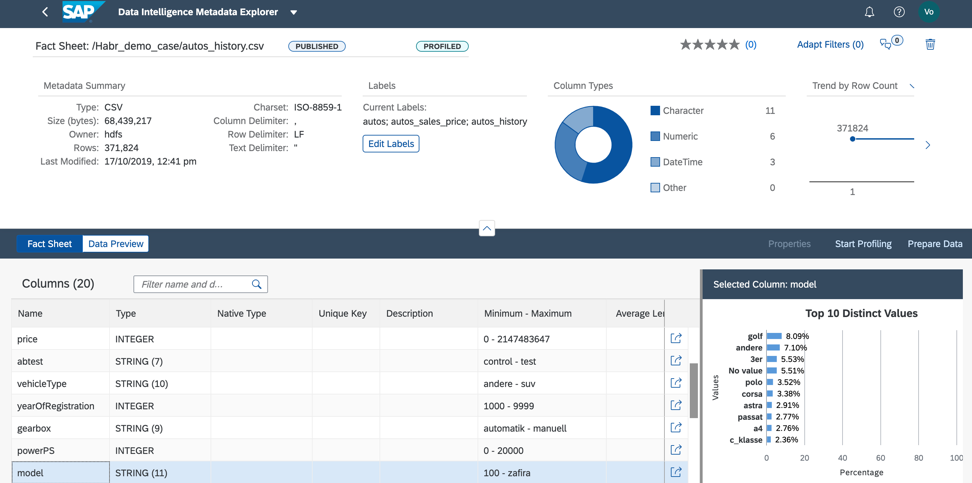 الشكل 13.
الشكل 13.
نحن الآن نفهم ماهية كائنات البيانات المطلوبة لتنفيذ حالة العمل ، وما هي كائنات البيانات المملوءة بها ، وما هي المعالجة المسبقة التي يجب أن نفعلها لاستخدام هذه البيانات لتنفيذ النموذج وتدريبه واختباره. ولكن قبل البدء في المعالجة ، تحتاج إلى التحقق من جودة البيانات. للقيام بذلك ، تتوفر قواعد العمل في كتالوج البيانات الوصفية. وألاحظ على الفور أن وظيفة قواعد العمل في الوقت الحالي بها عدد من القيود الخطيرة. لذلك ، أوصي بمعالجة بيانات أكثر أو أقل تعقيدًا في Jupiter Notebook ، الذي تم دمجه في SAP Data Intelligence.
لذلك ، دعنا نعود إلى مجموعة البيانات الخاصة بنا والتحقق من الامتثال للحد الأدنى والحد الأقصى للعتبات في مجال السعر ، حتى نتمكن من تقدير ما إذا كانت البيانات تحتوي على حالات شاذة أو قيم غير صحيحة. كما فهمت بالفعل ، يتم تكوين قواعد العمل أيضًا في كتالوج البيانات الوصفية ، كما في الشكل. 14 أ ، ج. يتم تكوين علاقة القواعد والبيانات في كتاب القواعد (كتاب القواعد). يسمح لك هذا باستخدام نفس القواعد للتحقق من البيانات المختلفة.
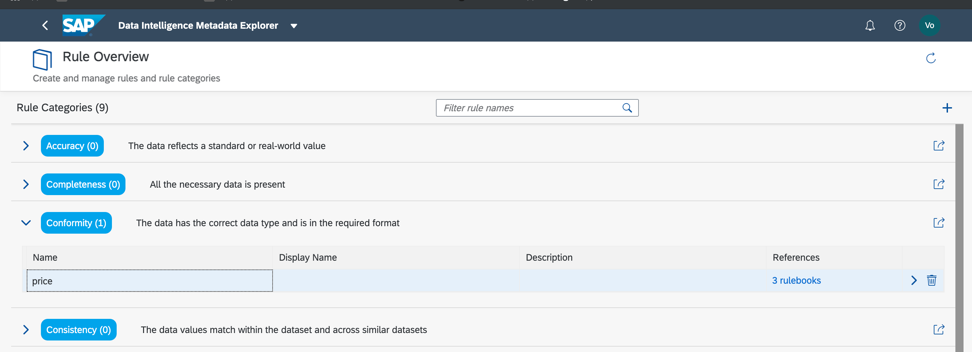 الشكل 14
الشكل 14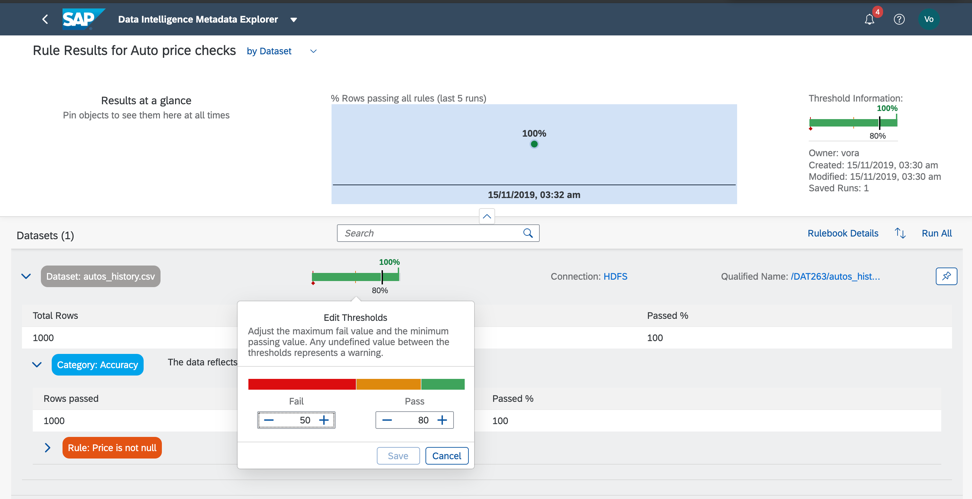 الشكل 14 ج.
الشكل 14 ج.لذلك ، كما نرى ، بياناتنا صحيحة 100 ٪.
لكن هذا لا يحدث دائما. يمكن اعتبار البيانات صحيحة إذا كان 75٪ من السجلات تستوفي الشروط المحددة في القواعد.
من الممكن تحسين جودة البيانات ، وقبل كل شيء ، يتم ذلك في النظم المحاسبية. للقيام بذلك ، تنظم الشركات عملية إدارة البيانات. السبب المحتمل الآخر هو معايير جودة البيانات المحددة بشكل غير صحيح.
بإيجاز ، أريد أن أقول عن مزايا وعيوب كتالوج البيانات الوصفية.
في رأيي ، لديها 3 مزايا رئيسية هي:
- تبسيط الوصول إلى البيانات.
- تسريع استعادة البيانات.
- واجهة مريحة وبديهية ، وهي مخصصة ليس فقط للمتقدمين في تكنولوجيا المعلومات أو المتخصصين في علوم البيانات ، ولكن أيضًا لرجال الأعمال المشاركين في تنفيذ ودعم حالة العمل.
وبطبيعة الحال ، عن العيوب. إنها واضحة. حاليًا ، تكون وظيفة كتالوج البيانات الوصفية في SAP Data Intelligence في مستوى أساسي. قد يكون من الكافي البدء في استخدام ، لكن الوظيفة لا تغطي بالضبط جميع متطلبات حل إدارة البيانات.
وهذا نتيجة لحداثة وتعقيد SAP Data Intelligence. تستثمر SAP الكثير من الموارد لتحسين هذا الحل. وهذا يلهم الثقة في أن كتالوج البيانات الوصفية سيتحول في المستقبل القريب إلى أداة قوية لإدارة البيانات. ستكون هناك فرصة لإنشاء قواعد عمل معقدة دون برمجة. سيكون من الممكن أيضًا دمج SAP Information Steward و SAP Data Hub لغرض التغطية الوظيفية الكاملة لموضوع إدارة البيانات.
في المقالة التالية ، سنتحدث عن مرحلة "تطوير وتدريب نموذج في SAP Data Intelligence". كل الأكثر إثارة للاهتمام في المستقبل!
كتب بواسطة ايلينا Ganchenko ، SAP رابطة الدول المستقلة الخبراء