مرحباً بالجميع ، اسمي ألكسندر ، أعمل مهندسًا في CIAN وأشارك في إدارة النظام وأتمتة عمليات البنية التحتية. في التعليقات على واحدة من المقالات السابقة ، طُلب منا أن نحدد من أين نحصل على 4 تيرابايت من السجلات يوميًا وماذا نفعل بها. نعم ، لدينا الكثير من السجلات ، وتم إنشاء مجموعة بنية أساسية منفصلة لمعالجتها ، مما يسمح لنا بحل المشكلات بسرعة. في هذه المقالة ، سأتحدث عن كيفية تكييفها على مدار العام للعمل مع تدفق البيانات المتزايد باستمرار.
من أين بدأنا؟
خلال السنوات القليلة الماضية ، نما الحمل على cian.ru بسرعة كبيرة ، وبحلول الربع الثالث من عام 2018 ، وصلت حركة مرور الموارد إلى 11.2 مليون مستخدم فريد شهريًا. في ذلك الوقت ، في اللحظات الحرجة ، فقدنا ما يصل إلى 40 ٪ من سجلات ، بسبب ذلك لم نتمكن من التعامل بسرعة مع الحوادث وقضينا الكثير من الوقت والجهد لحلها. لم نتمكن من العثور على سبب المشكلة في كثير من الأحيان ، وتكرر ذلك بعد مرور بعض الوقت. كان الجحيم الذي كان عليك أن تفعل شيئا.
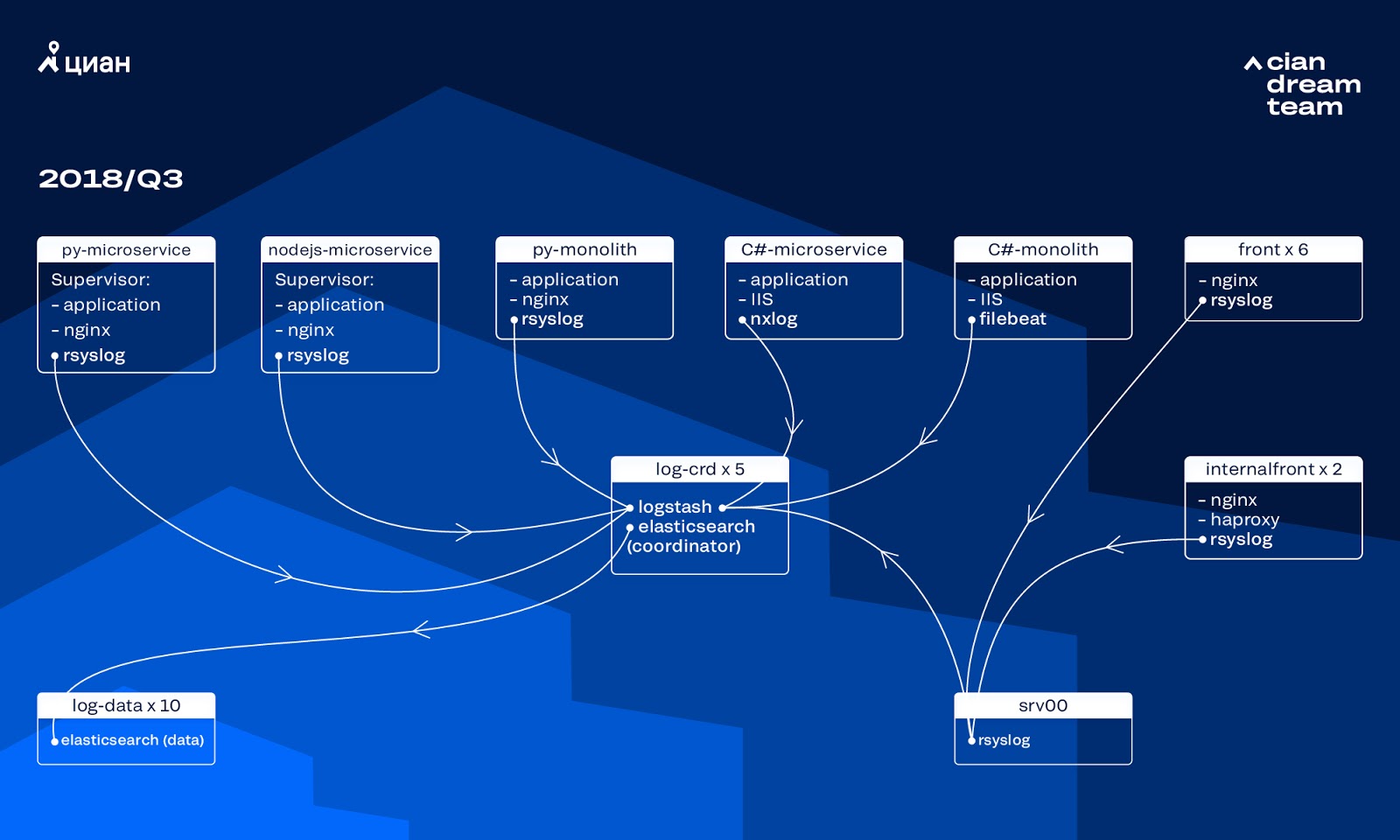
في ذلك الوقت ، استخدمنا مجموعة من 10 عقد بيانات مع تطبيق FlexSearch الإصدار 5.5.2 مع إعدادات فهرس نموذجية لتخزين السجلات. تم تقديمه منذ أكثر من عام كحل شعبي وبأسعار معقولة: ثم لم يكن دفق السجل كبيرًا جدًا ، ولم يكن من المنطقي التوصل إلى تكوينات غير قياسية.
قدمت Logstash على منافذ مختلفة معالجة سجلات واردة على خمسة منسقين ElasticSearch. مؤشر واحد ، بغض النظر عن الحجم ، يتألف من خمسة شظايا. تم تنظيم دورة كل ساعة ودوران يوميًا ، ونتيجة لذلك ، ظهر حوالي 100 قطعة جديدة في المجموعة كل ساعة. على الرغم من عدم وجود سجلات كثيرة للغاية ، إلا أن المجموعة المدارة ولم يلفت أحد الانتباه إلى إعداداته.
مشاكل النمو
نما حجم السجلات التي تم إنشاؤها بسرعة كبيرة ، حيث تداخلت عمليتان مع بعضهما البعض. من ناحية ، كان هناك المزيد والمزيد من مستخدمي الخدمة. من ناحية أخرى ، بدأنا في التحول بنشاط إلى بنية microservice ، ورأى متراصة لدينا القديمة في C # وبيثون. إنشاء عشرات من الخدمات الميكروية الجديدة التي استبدلت أجزاء من المتراصة سجلات أكثر بكثير لمجموعة البنية التحتية.
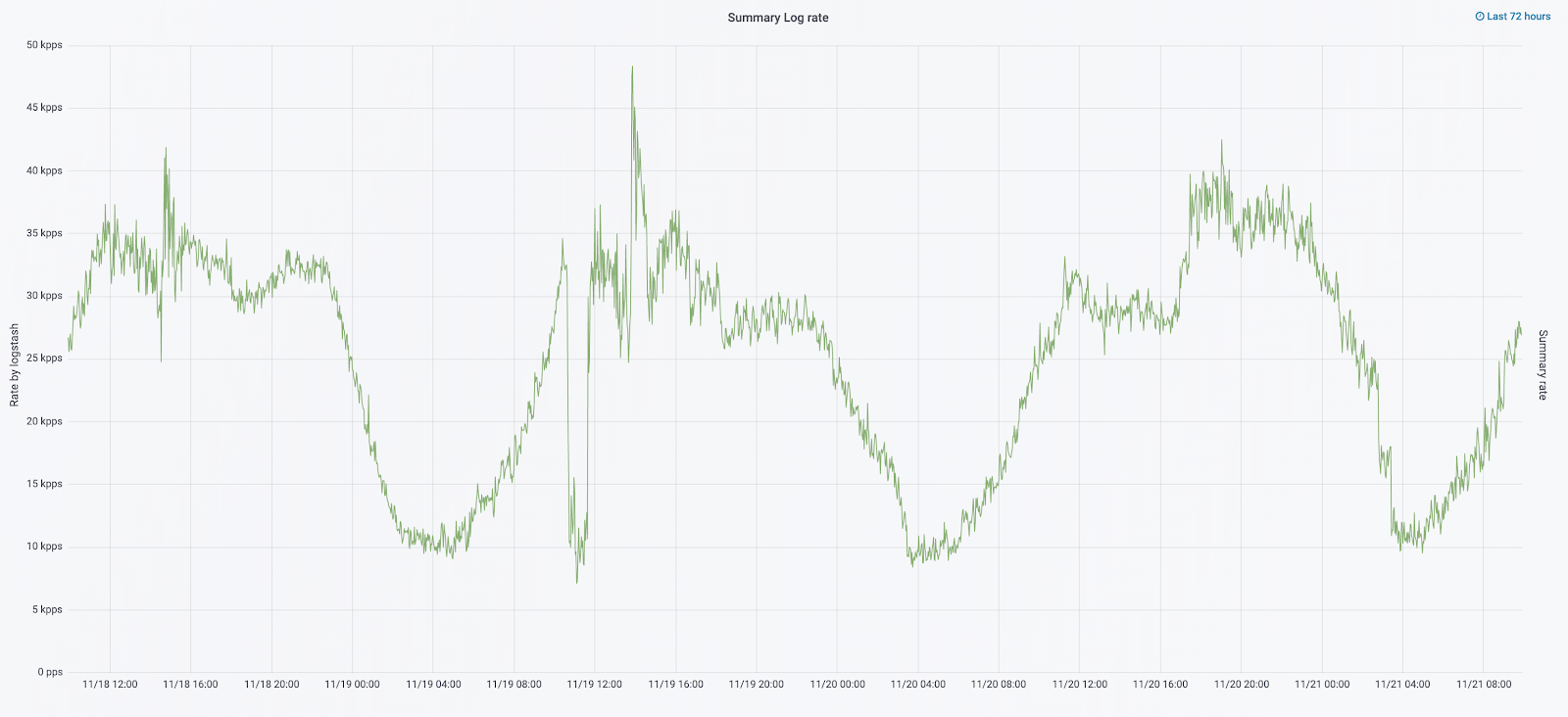
لقد كان التوسع في الحجم هو الذي قادنا إلى حقيقة أن المجموعة أصبحت لا يمكن السيطرة عليها تقريبًا. عندما بدأت السجلات في الوصول بسرعة 20 ألف رسالة في الثانية ، زاد التناوب المتكرر عديم الفائدة من عدد القطع إلى 6 آلاف ، وشكلت عقدة واحدة أكثر من 600 قطعة.
أدى ذلك إلى مشاكل في تخصيص ذاكرة الوصول العشوائي ، وعندما سقطت العقدة ، بدأ التحرك المتزامن لجميع القطع ، مما أدى إلى مضاعفة حركة المرور وتحميل العقد المتبقية ، مما جعل من شبه المستحيل كتابة البيانات إلى الكتلة. وخلال هذه الفترة تركنا دون سجلات. ومع مشكلة الخادم ، فقدنا 1/10 من الكتلة من حيث المبدأ. وأضاف عدد كبير من الفهارس الصغيرة التعقيد.
بدون سجلات ، لم نفهم أسباب الحادثة ويمكننا عاجلاً أو آجلاً أن نخطو على نفس المشكلة مرة أخرى ، لكن في أيديولوجية فريقنا ، كان هذا غير مقبول ، لأن جميع آليات العمل التي شحذناها على العكس تمامًا - لم تكرر نفس المشكلات مطلقًا. للقيام بذلك ، كنا بحاجة إلى حجم كامل من السجلات وإيصالها في الوقت الفعلي تقريبًا ، حيث قام فريق من المهندسين المهتمين بمراقبة التنبيهات ليس فقط من المقاييس ، ولكن أيضًا من السجلات. لفهم حجم المشكلة - في ذلك الوقت ، بلغ إجمالي حجم السجلات حوالي 2 تيرابايت في اليوم.
لقد حددنا هدفًا - ألا وهو التخلص تمامًا من فقدان السجلات وتقليل وقت تسليمها إلى مجموعة ELK لمدة أقصاها 15 دقيقة أثناء القوة القاهرة (اعتمدنا على هذا الرقم في المستقبل باعتباره KPI داخلي).
آلية الدوران الجديدة والعقد الحارة
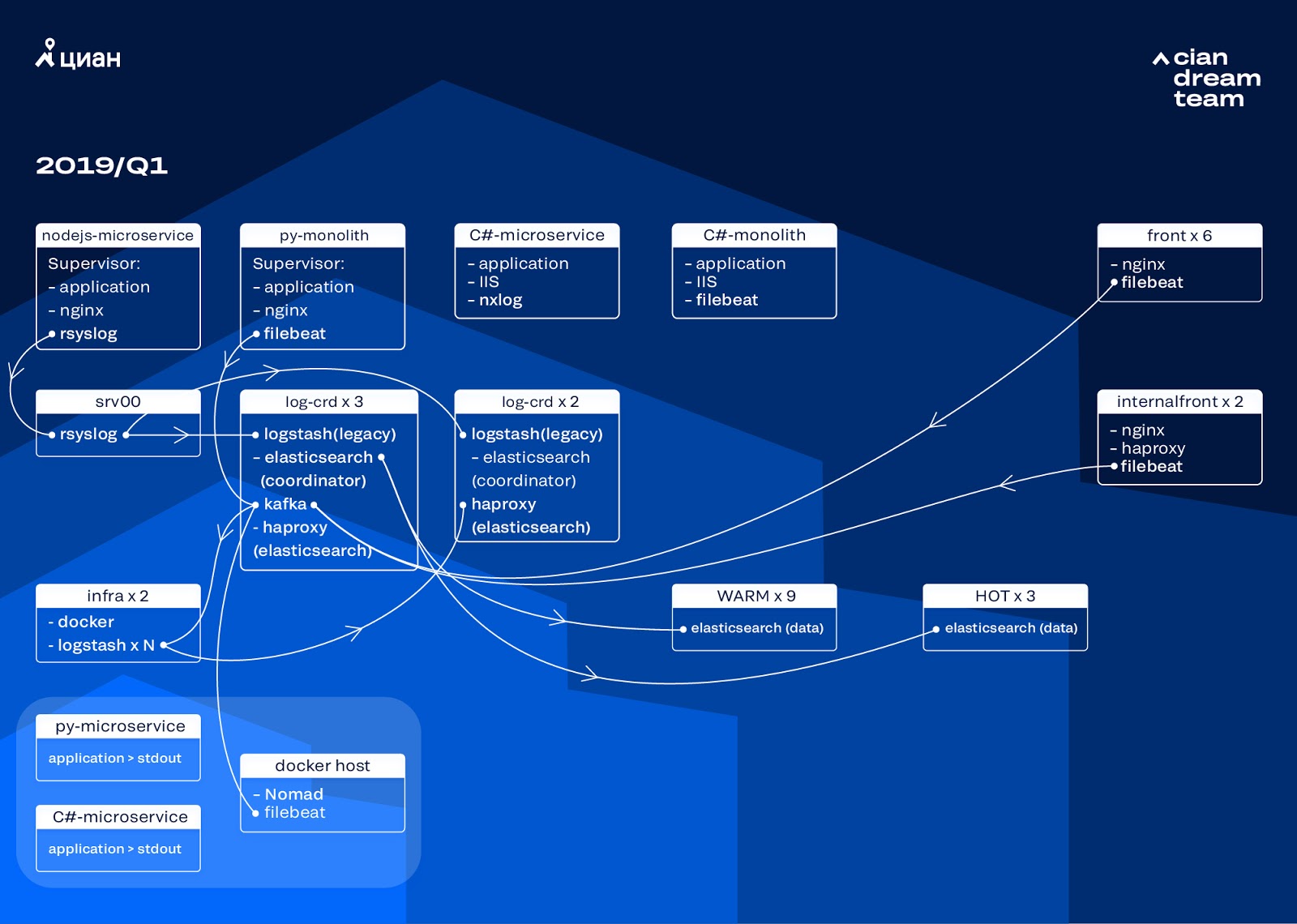
لقد بدأنا عملية تحويل الكتلة من خلال تحديث إصدار ElasticSearch من 5.5.2 إلى 6.4.3. مرة أخرى ، تم إرسال مجموعة من الإصدار 5 إلينا ، وقررنا سدادها وتحديثها بالكامل - لا توجد سجلات حتى الآن. لذلك قمنا بهذا الانتقال في بضع ساعات فقط.
كان التحوّل الأكثر طموحًا في هذه المرحلة هو إدخال ثلاث عقد مع المنسق كمخزن مؤقت وسيط Apache Kafka. أنقذنا وسيط الرسائل من فقدان السجلات أثناء مشاكل تطبيق البحث. في الوقت نفسه ، أضفنا عقدتين إلى الكتلة وتحولنا إلى بنية دافئة مع ثلاث عقد "ساخنة" مرتبة في رفوف مختلفة في مركز البيانات. لقد قمنا بإعادة توجيه السجلات إليهم والتي يجب ألا تضيع في أي حال - nginx ، وكذلك سجلات أخطاء التطبيق. سجلات ثانوية - تصحيح ، تحذير ، وما إلى ذلك ، ذهبت إلى العقد الأخرى ، وكذلك ، بعد 24 ساعة ، انتقلت السجلات "الهامة" من العقد "الساخنة".
من أجل عدم زيادة عدد الفهارس الصغيرة ، تحولنا من دوران الوقت إلى آلية التمرير. كان هناك الكثير من المعلومات في المنتديات أن التناوب حسب حجم الفهرس غير موثوق به للغاية ، لذلك قررنا استخدام التدوير حسب عدد الوثائق في الفهرس. قمنا بتحليل كل فهرس وتسجيل عدد الوثائق التي بعدها يجب أن يعمل التناوب. وبالتالي ، وصلنا إلى الحجم الأمثل للقشرة - لا يزيد عن 50 جيجابايت.
تحسين الكتلة
ومع ذلك ، فإننا لم نتخلص تماما من المشاكل. لسوء الحظ ، ظهرت مؤشرات صغيرة تمامًا: لم تصل إلى الحجم المحدد ، ولم يتم تدويرها وتم حذفها من خلال التنظيف العام للمؤشرات التي يزيد عمرها عن ثلاثة أيام ، نظرًا لأننا أزلنا التناوب حسب التاريخ. أدى هذا إلى فقدان البيانات بسبب حقيقة أن الفهرس من الكتلة قد اختفى تمامًا ، ومحاولة الكتابة إلى فهرس غير موجود حطمت منطق المنسق الذي استخدمناه للتحكم. تم تحويل الاسم المستعار للتسجيل إلى فهرس وكسر منطق التمرير ، مما تسبب في نمو غير منضبط لبعض المؤشرات إلى 600 جيجابايت.
على سبيل المثال ، لتكوين التدوير:
urator-elk-rollover.yaml --- actions: 1: action: rollover options: name: "nginx_write" conditions: max_docs: 100000000 2: action: rollover options: name: "python_error_write" conditions: max_docs: 10000000
في غياب الاسم المستعار للترحيل ، حدث خطأ:
ERROR alias "nginx_write" not found. ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
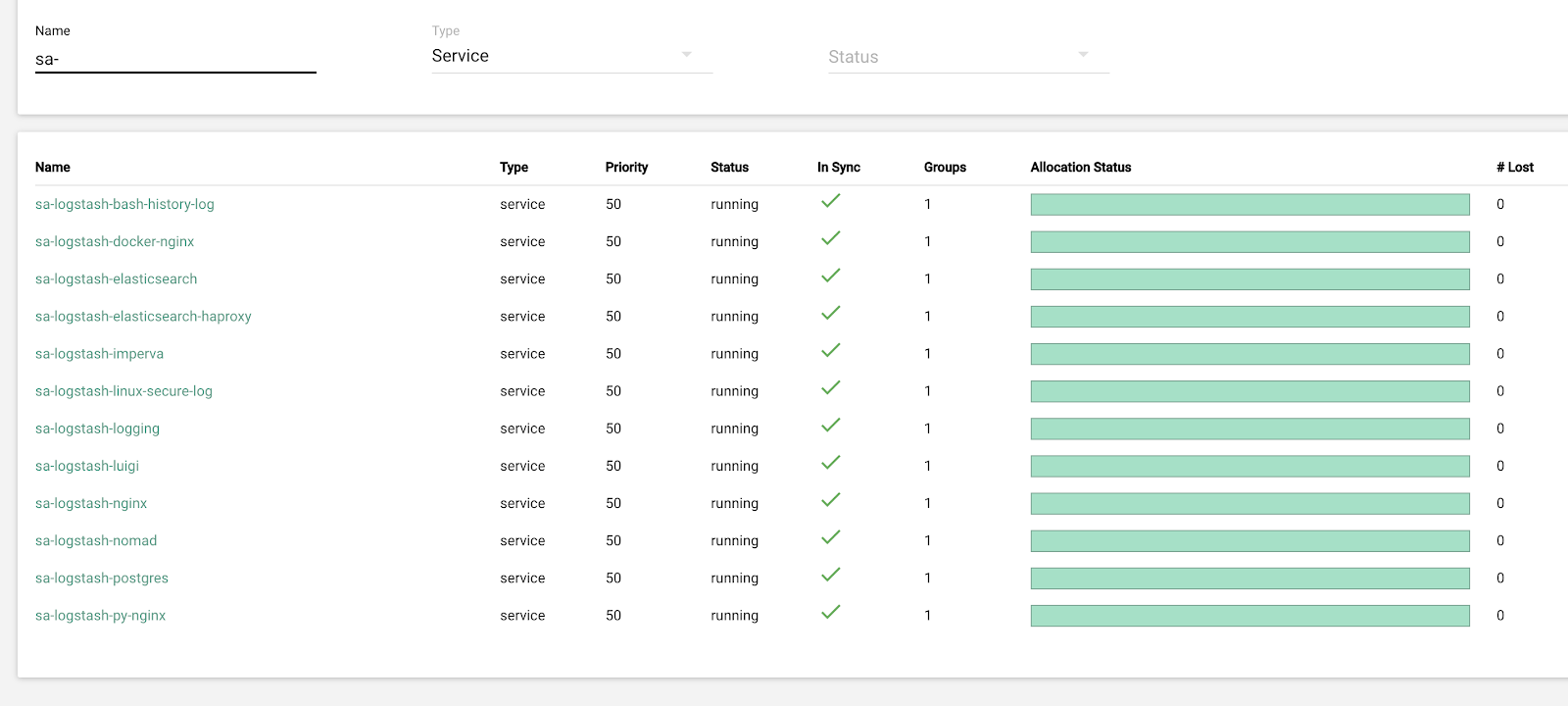
لقد تركنا حل هذه المشكلة للتكرار التالي وتناولنا سؤالًا آخر: لقد تحولنا لسحب منطق Logstash ، الذي يتعامل مع السجلات الواردة (إزالة المعلومات غير الضرورية وإثراءها). لقد وضعناها في عامل ميناء ، نقوم بتشغيله من خلال عامل إنشاء عامل ميناء ، ووضعنا مصدرًا ل logstash في نفس المكان ، والذي يعطي المقاييس لـ Prometheus للمراقبة التشغيلية لتيار السجل. لذا فقد منحنا أنفسنا الفرصة لتغيير عدد مثيلات logstash المسئولة عن معالجة كل نوع من السجلات بسلاسة.
أثناء قيامنا بتحسين المجموعة ، ارتفعت حركة مرور cian.ru إلى 12.8 مليون مستخدم فريد شهريًا. نتيجةً لذلك ، اتضح أن تحويلاتنا لم تواكب التغييرات التي طرأت على الإنتاج قليلاً ، وقد واجهنا حقيقة أن العقد "الدافئة" لم تتمكن من التعامل مع الحمل وأبطأت عملية تسليم السجلات بأكملها. لقد تلقينا البيانات "الساخنة" دون أي عيوب ، ولكن كان علينا التدخل في تسليم الباقي والقيام بالتمرير اليدوي من أجل توزيع المؤشرات بالتساوي.
في الوقت نفسه ، كان تغيير إعدادات مثيلات logstash وتغييرها في الكتلة معقدًا بسبب كونه عامل إنشاء محليًا ، وقد تم تنفيذ جميع الإجراءات يدويًا (لإضافة نهايات جديدة ، كان عليك التنقل بين جميع الخوادم بأيديك والقيام بتجميع عامل الوصول في كل مكان).
إعادة توزيع السجل
في شهر أيلول (سبتمبر) من هذا العام ، ما زلنا نشاهد المتراصة ، زاد الحمل على الكتلة ، وكان دفق السجل يقترب من 30 ألف رسالة في الثانية.
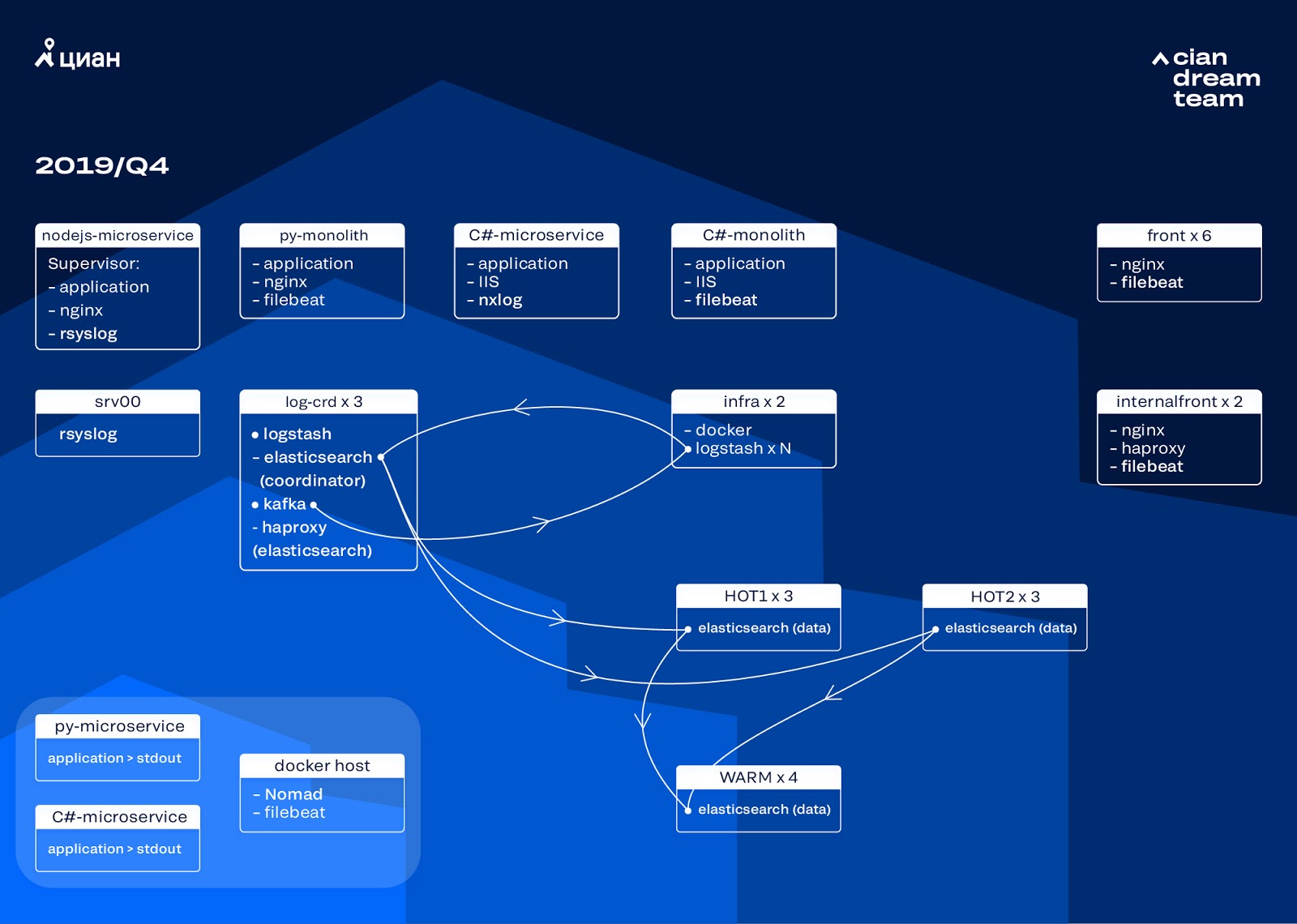
بدأنا التكرار التالي مع تحديث الحديد. لقد تحولنا من خمسة منسقين إلى ثلاثة ، واستبدلنا عقد البيانات وفزنا من حيث المال وحجم التخزين. بالنسبة للعقد ، نستخدم تكوينين:
- للعقد الساخنة: E3-1270 v6 / 960GB SSD / 32 جيجابايت × 3 × 2 (3 لـ Hot1 و 3 لـ Hot2).
- للعقد الدافئة: E3-1230 v6 / 4Tb SSD / 32 جيجابايت × 4.
في هذا التكرار ، أخرجنا الفهرس من خلال سجلات الوصول إلى الخدمات المجهرية ، والتي تشغل مساحة كبيرة مثل سجلات nginx الأمامية ، في المجموعة الثانية المكونة من ثلاثة عقد ساخنة. نقوم الآن بتخزين البيانات على العقد الساخنة لمدة 20 ساعة ، ثم نقلها لتدفئة إلى سجلات أخرى.
لقد حللنا مشكلة اختفاء المؤشرات الصغيرة من خلال إعادة تشكيل تناوبها. يتم تدوير الفهارس الآن على أي حال كل 23 ساعة ، حتى لو كانت البيانات قليلة. أدى هذا إلى زيادة طفيفة في عدد القطع (التي أصبحت حوالي 800) ، ولكن من وجهة نظر أداء نظام المجموعة هذا أمر مقبول.
نتيجةً لذلك ، ظهرت ست عقد "ساخنة" وأربعة "دافئ" في المجموعة. يؤدي هذا إلى تأخير بسيط في الطلبات على فترات زمنية طويلة ، ولكن زيادة عدد العقد في المستقبل سوف يحل هذه المشكلة.
في هذا التكرار ، تم حل مشكلة نقص التدرج شبه التلقائي. للقيام بذلك ، قمنا بنشر مجموعة Nomad للبنية التحتية - على غرار ما قمنا بنشره بالفعل للإنتاج. على الرغم من أن عدد Logstash لا يتغير تلقائيًا حسب الحمل ، إلا أننا سنصل إلى هذا.
الخطط المستقبلية
يتم ضبط التكوين المطبق جيدًا ، والآن نقوم بتخزين 13.3 تيرابايت من البيانات - جميع السجلات في 4 أيام ، وهو أمر ضروري لتحليل حالات الطوارئ من التنبيهات. نقوم بتحويل جزء من السجلات إلى مقاييس ، نضيفها إلى الجرافيت. لتسهيل عمل المهندسين ، لدينا مقاييس لمجموعة البنية التحتية ونصوص لإصلاح المشكلات النموذجية شبه الآلية. بعد زيادة عدد نقاط البيانات ، والتي تم التخطيط لها في العام المقبل ، سننتقل إلى تخزين البيانات من 4 إلى 7 أيام. سيكون هذا كافيًا للعمل التشغيلي ، حيث أننا نحاول دائمًا التحقيق في الحوادث في أقرب وقت ممكن ، وتتوفر بيانات القياس عن بعد للتحقيقات طويلة الأجل.
في أكتوبر 2019 ، ارتفعت حركة مرور cian.ru إلى 15.3 مليون مستخدم فريد شهريًا. كان هذا اختبارًا جادًا للحل المعماري لتسليم السجلات.
نحن الآن بصدد الإعداد لترقية ElasticSearch إلى الإصدار 7. ومع ذلك ، سنضطر إلى تحديث مناظرة العديد من الفهارس في ElasticSearch ، لأنها انتقلت من الإصدار 5.5 وأُعلن عن إهمالها في الإصدار 6 (وهي ببساطة غير موجودة في الإصدار 7). وهذا يعني أنه في عملية التحديث سيكون هناك بالتأكيد بعض الظروف القاهرة التي ستتركنا دون سجلات في الوقت الحالي. من بين الإصدارات السبعة ، نتطلع أكثر إلى Kibana من خلال واجهة محسنة وعوامل تصفية جديدة.
لقد حققنا الهدف الرئيسي: لقد توقفنا عن فقدان السجلات وتقليل وقت توقف مجموعة البنية التحتية من 2-3 قطرات في الأسبوع إلى بضع ساعات من العمل في الشهر. كل هذا العمل على الإنتاج غير مرئي تقريبًا. ومع ذلك ، الآن يمكننا تحديد بدقة ما يحدث مع خدمتنا ، يمكننا القيام بذلك بسرعة في وضع هادئ ولا تقلق من أن السجلات سوف تضيع. بشكل عام ، نحن راضون وسعدون ونستعد لمآثر جديدة ، والتي سنتحدث عنها لاحقًا.