منذ الإصدار الأخير في عالم اللغات جوليا ، حدث الكثير من الأشياء المثيرة للاهتمام:
- أخذت جميع الأماكن الأولى من حيث نمو حزم الدعم. لهذا السبب أحب الإحصاءات - الشيء الرئيسي هو اختيار وحدة قياس ملائمة ، على سبيل المثال ، النسب المئوية كما هو الحال في المورد المحدد
- تم إصدار الإصدار 1.3.0 - من بين الابتكارات واسعة النطاق هناك تحديث مدير الحزم وظهور التزامن متعدد الخيوط
- جوليا تحصل على دعم نفيديا
- خصصت الإدارة الأمريكية للدراسات المتقدمة في مجال الطاقة الكثير من المال لحل مشاكل التحسين
في الوقت نفسه ، هناك زيادة ملحوظة في الاهتمام من قبل المطورين ، والتي يتم التعبير عنها عن طريق قياس وفيرة:
نحن فقط نفرح بأدوات جديدة ومريحة ونواصل دراستها. سيتم تخصيص الليلة لتحليل النص ، والبحث عن المعنى الخفي في خطب الرؤساء وتوليد النصوص بروح شكسبير ومبرمج جوليا ، وبالنسبة للحلوى ، نقوم بإطعام شبكة متكررة من 40،000 فطيرة.
تم إجراء مراجعة الحزم لجوليا مؤخرًا على Habré ، مما سمح بإجراء البحوث في مجال البرمجة اللغوية العصبية NLP - Julia NLP. نحن نعالج النصوص . لذلك دعونا نبدأ العمل على الفور ونبدأ بحزمة TextAnalysis .
TextAnalisys
اترك بعض النص ، والذي نمثله كوثيقة سلسلة:
using TextAnalysis str = """ Ich mag die Sonne, die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher. Ich mag den kalten Mond, wenn der Vollmond rund, Und ich mag dich mit einem Knebel in dem Mund. """; sd = StringDocument(str)
StringDocument{String}("Ich mag die ... dem Mund.\n", TextAnalysis.DocumentMetadata(Languages.Default(), "Untitled Document", "Unknown Author", "Unknown Time"))
للعمل المريح مع عدد كبير من المستندات ، من الممكن تغيير الحقول ، على سبيل المثال ، العناوين ، وكذلك لتبسيط المعالجة ، يمكننا إزالة علامات الترقيم والحروف الكبيرة:
title!(sd, "Knebel") prepare!(sd, strip_punctuation) remove_case!(sd) text(sd)
"ich mag die sonne die palmen und das meer \nich mag den himmel schauen den wolken hinterher \nich mag den kalten mond wenn der vollmond rund \nund ich mag dich mit einem knebel in dem mund \n"
الذي يسمح لك ببناء n- gram غير مرتب لكلمات:
dict1 = ngrams(sd) Dict{String,Int64} with 26 entries: "dem" => 1 "himmel" => 1 "knebel" => 1 "der" => 1 "schauen" => 1 "mund" => 1 "rund" => 1 "in" => 1 "mond" => 1 "dich" => 1 "einem" => 1 "ich" => 4 "hinterher" => 1 "wolken" => 1 "den" => 3 "das" => 1 "palmen" => 1 "kalten" => 1 "mag" => 4 "sonne" => 1 "vollmond" => 1 "die" => 2 "mit" => 1 "meer" => 1 "wenn" => 1 "und" => 2
من الواضح أن علامات الترقيم والكلمات ذات الحروف الكبيرة ستكون وحدات منفصلة في القاموس ، والتي سوف تتداخل مع التقييم النوعي لتكرار تكرارات المصطلحات المحددة في نصنا ، وبالتالي تخلصنا منها. بالنسبة إلى n-gram ، من السهل العثور على الكثير من أنواع التطبيقات المثيرة للاهتمام ، على سبيل المثال ، بمساعدتهم يمكنك إجراء بحث غامض في النص ، حسنًا ، نظرًا لأننا مجرد سائحين ، سنتعرف على بعض أمثلة الألعاب ، أي إنشاء نص باستخدام سلاسل Markov
Procházení modelového grafu
سلسلة Markov هي نموذج منفصل لعملية Markov تتكون من تغيير في نظام يأخذ في الاعتبار فقط حالته السابقة (النموذجية). بالمعنى المجازي ، يمكن للمرء أن ينظر إلى هذا البناء باعتباره آلية خلوية احتمالية. تتعايش N-gram مع هذا المفهوم تمامًا: ترتبط أي كلمة من المعجم مع كل اتصال آخر من السماكة المختلفة ، والتي يتم تحديدها بواسطة تكرار حدوث أزواج محددة من الكلمات (غرام) في النص.

سلسلة ماركوف للسلسلة "ABABD"
إن تنفيذ الخوارزمية نفسها يعد بالفعل نشاطًا رائعًا للمساء ، لكن Julia لديها بالفعل حزمة Markovify الرائعة ، والتي تم إنشاؤها فقط لهذه الأغراض. بالتمرير بعناية من خلال الدليل باللغة التشيكية ، ننتقل إلى عمليات الإعدام اللغوية الخاصة بنا.
تقسيم النص إلى رموز (مثل الكلمات)
using Markovify, Markovify.Tokenizer tokens = tokenize(str, on = words) 2-element Array{Array{String,1},1}: ["Ich", "mag", "die", "Sonne,", "die", "Palmen", "und", "das", "Meer,", "Ich", "mag", "den", "Himmel", "schauen,", "den", "Wolken", "hinterher."] ["Ich", "mag", "den", "kalten", "Mond,", "wenn", "der", "Vollmond", "rund,", "Und", "ich", "mag", "dich", "mit", "einem", "Knebel", "in", "dem", "Mund."]
نؤلف نموذجًا من الدرجة الأولى (يتم أخذ أقرب الجيران فقط في الاعتبار):
mdl = Model(tokens; order=1) Model{String}(1, Dict(["dich"] => Dict("mit" => 1),["den"] => Dict("Himmel" => 1,"kalten" => 1,"Wolken" => 1),["in"] => Dict("dem" => 1),["Palmen"] => Dict("und" => 1),["wenn"] => Dict("der" => 1),["rund,"] => Dict("Und" => 1),[:begin] => Dict("Ich" => 2),["Vollmond"] => Dict("rund," => 1),["die"] => Dict("Sonne," => 1,"Palmen" => 1),["kalten"] => Dict("Mond," => 1)…))
ثم ننتقل إلى تنفيذ وظيفة عبارة التوليد بناءً على النموذج المقدم. يتطلب الأمر ، في الواقع ، نموذجًا ، والحل ، وعدد العبارات التي تريد الحصول عليها:
قانون function gensentences(model, fun, n) sentences = []
قام مطور الحزمة بتوفير وظيفتين walk2 : walk و walk2 (يعمل الثاني لفترة أطول ، لكنه يقدم تصميمات فريدة أكثر) ، ويمكنك دائمًا تحديد الخيار الخاص بك. لنجربها:
gensentences(mdl, walk, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher." "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund." gensentences(mdl, walk2, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag dich mit einem Knebel in dem Mund." "Ich mag den Himmel schauen, den kalten Mond, wenn der Vollmond rund, Und ich mag den Wolken hinterher." "Ich mag die Sonne, die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund."
بطبيعة الحال ، فإن الإغراء رائع في تجربة النصوص الروسية ، خاصة على الآيات البيضاء. بالنسبة للغة الروسية ، نظرًا لتعقيدها ، فإن معظم العبارات غير قابلة للقراءة. بالإضافة إلى ذلك ، كما ذكرنا سابقًا ، تحتاج الأحرف الخاصة إلى عناية خاصة ، وبالتالي فإننا إما نقوم بحفظ المستندات التي يتم من خلالها تجميع النص المشفر في UTF-8 ، أو نستخدم أدوات إضافية .
بناءً على نصيحة أخته ، بعد أن قمت بتنظيف اثنين من كتب Oster من شخصيات خاصة ومن أي فواصل ووضع ترتيب ثانٍ للـ n-gram ، حصلت على المجموعة التالية من الوحدات اللغوية:
", !" ". , : !" ", , , , ?" " !" ". , !" ". , ?" " , !" " ?" " , , ?" " ?" ", . ?"
أكدت أنه بهذه الطريقة تم بناء الأفكار في دماغ الأنثى ... مهم ، ومن أنا لأجادل ...
تحليلها
في دليل حزمة TextAnalysis ، يمكنك العثور على أمثلة للبيانات النصية ، واحدة منها عبارة عن مجموعة من الخطب التي ألقاها الرؤساء الأمريكيون قبل المؤتمر

قانون using TextAnalysis, Clustering, Plots
29-element Array{String,1}: "Bush_1989.txt" "Bush_1990.txt" "Bush_1991.txt" "Bush_1992.txt" "Bush_2001.txt" "Bush_2002.txt" "Bush_2003.txt" "Bush_2004.txt" "Bush_2005.txt" "Bush_2006.txt" "Bush_2007.txt" "Bush_2008.txt" "Clinton_1993.txt" ⋮ "Clinton_1998.txt" "Clinton_1999.txt" "Clinton_2000.txt" "Obama_2009.txt" "Obama_2010.txt" "Obama_2011.txt" "Obama_2012.txt" "Obama_2013.txt" "Obama_2014.txt" "Obama_2015.txt" "Obama_2016.txt" "Trump_2017.txt"
بعد قراءة هذه الملفات وتكوين فيلق منها ، وكذلك تنظيفها من علامات الترقيم ، سنراجع المفردات العامة لجميع الخطب:
قانون crps = DirectoryCorpus(pth) standardize!(crps, StringDocument) crps = Corpus(crps[1:29]);
remove_case!(crps) prepare!(crps, strip_punctuation) update_lexicon!(crps) update_inverse_index!(crps) lexicon(crps)
Dict{String,Int64} with 9078 entries: "enriching" => 1 "ferret" => 1 "offend" => 1 "enjoy" => 4 "limousines" => 1 "shouldn" => 21 "fight" => 85 "everywhere" => 17 "vigilance" => 4 "helping" => 62 "whose" => 22 "'" => 725 "manufacture" => 3 "sleepless" => 2 "favor" => 6 "incoherent" => 1 "parenting" => 2 "wrongful" => 1 "poised" => 3 "henry" => 3 "borders" => 30 "worship" => 3 "star" => 10 "strand" => 1 "rejoin" => 3 ⋮ => ⋮
قد يكون من المثير للاهتمام معرفة الوثائق التي تحتوي على كلمات محددة ، على سبيل المثال ، ألقِ نظرة على كيفية تعاملنا مع الوعود:
crps["promise"]' 1×24 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 1 2 3 4 6 7 9 10 11 12 15 … 21 22 23 24 25 26 27 28 29 crps["reached"]' 1×7 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 12 14 15 17 19 20 22
أو مع ترددات الضمير:
lexical_frequency(crps, "i"), lexical_frequency(crps, "you") (0.010942182388035081, 0.005905479339070189)
لذلك ربما العلماء والصحفيين الاغتصاب وهناك موقف ضار تجاه البيانات التي تجري دراستها.
Matematritsy
تبدأ دلالات التوزيع الحقيقية عندما تتحول النصوص والغرامات والرموز إلى ناقلات ومصفوفات .
مصفوفة وثيقة المصطلح ( DTM ) هي مصفوفة ذات حجم حيث - عدد الوثائق في القضية ، و - حجم القاموس المراد عدد الكلمات (الفريدة) التي توجد في مجموعة لدينا. في الصف الأول ، يكون العمود التاسع من المصفوفة رقمًا - كم مرة تم العثور على الكلمة الأولى في النص الرابع.
قانون dtm1 = DocumentTermMatrix(crps)
D = dtm(dtm1, :dense) 29×9078 Array{Int64,2}: 0 0 1 4 0 0 0 0 0 0 0 0 0 … 1 0 0 16 0 0 0 0 0 0 0 1 4 0 0 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 3 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 5 8 0 0 0 0 0 0 0 0 0 0 0 0 10 38 0 0 0 0 0 3 0 0 0 0 0 0 0 0 5 0 … 0 0 0 22 0 0 0 0 0 0 0 12 4 2 0 0 0 0 0 1 3 0 0 0 0 41 0 0 0 0 0 0 0 1 1 2 1 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 44 0 0 0 0 0 0 0 2 1 1 0 0 0 0 0 0 2 0 0 0 67 0 0 14 1 1 31 2 0 8 2 1 1 0 0 0 0 0 4 0 … 0 0 0 50 0 0 0 0 0 2 0 3 3 0 2 0 0 0 0 0 2 1 0 0 0 11 0 0 0 0 0 0 0 8 3 6 3 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 1 11 5 3 3 0 0 0 1 0 1 0 1 0 0 44 0 0 0 0 0 0 0 11 5 4 5 0 0 0 0 0 1 0 1 0 0 48 0 0 0 0 0 0 0 18 6 8 4 0 0 0 0 0 0 1 1 0 0 80 0 0 0 0 0 0 0 1 2 0 0 0 0 0 0 0 0 0 … 0 0 0 26 0 0 0 0 0 1 0 4 5 5 1 0 0 0 0 0 1 0 0 0 45 0 0 0 0 0 1 1 0 8 2 1 3 0 0 0 0 0 2 0 0 0 47 0 0 170 11 11 1 0 0 7 1 1 1 0 0 0 0 0 0 0 0 0 3 2 0 208 2 2 0 1 0 5 2 0 1 1 0 0 0 0 1 0 0 0 41 0 0 122 7 7 1 0 0 4 3 4 1 0 0 0 0 0 0 0 … 0 0 62 0 0 173 11 11 7 2 0 6 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 3 0 3 0 0 0 0 0 0 0 0 0 0 0 35 0 0 0 0 0 1 0 2 2 0 2 0 0 0 0 0 1 0 0 0 0 30 0 0 0 0 0
هنا الوحدات الأصلية هي الشروط
m.terms[3450:3465] 16-element Array{String,1}: "franklin" "frankly" "frankness" "fraud" "frayed" "fraying" "fre" "freak" "freddie" "free" "freed" "freedom" "freedoms" "freely" "freer" "frees"
انتظر لحظة ...
crps["freak"] 1-element Array{Int64,1}: 25 files[25] "Obama_2013.txt"
سيكون من الضروري قراءة بمزيد من التفاصيل ...
يمكنك أيضًا استخراج جميع أنواع البيانات المهمة من مصطلح المصفوفات. قل عدد مرات تكرار الكلمات المحددة في المستندات
w1, w2 = dtm1.column_indices["freedom"], dtm1.column_indices["terror"] (3452, 8101)
D[:, w1] |> bar
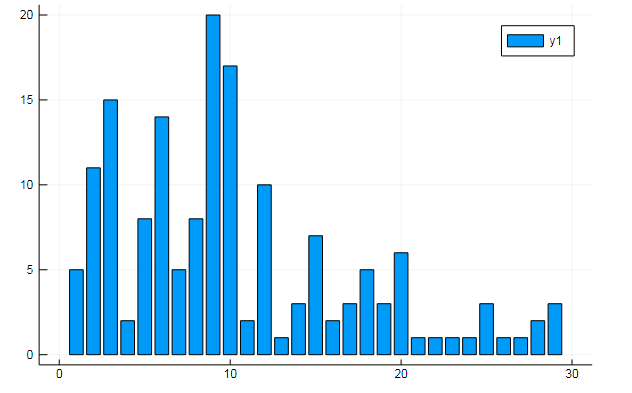
D[:, w1] |> bar
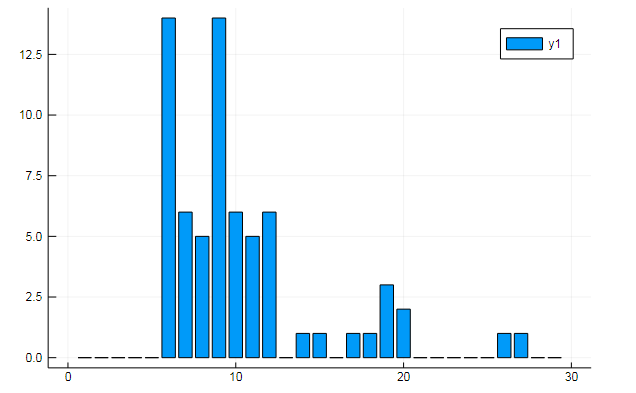
أو تشابه المستندات في بعض الموضوعات المخفية:
k = 3

توضح الرسوم البيانية كيف يتم الكشف عن كل موضوع من الموضوعات الثلاثة في الخطب
أو تجميع الكلمات حسب الموضوع ، أو ، على سبيل المثال ، تشابه المفردات وتفضيل مواضيع معينة في مستندات مختلفة
T = tf_idf(D) cl = kmeans(T, 5)
s1 = scatter(T[10, 1:10:end], assign, yaxis = "Bush 2006") s2 = scatter(T[29, 1:10:end], assign, yaxis = "Obama 2016") s3 = scatter(T[30, 1:10:end], assign, yaxis = "Trump 2017") plot(s1, s2, s3, layout = (3,1), legend=false )
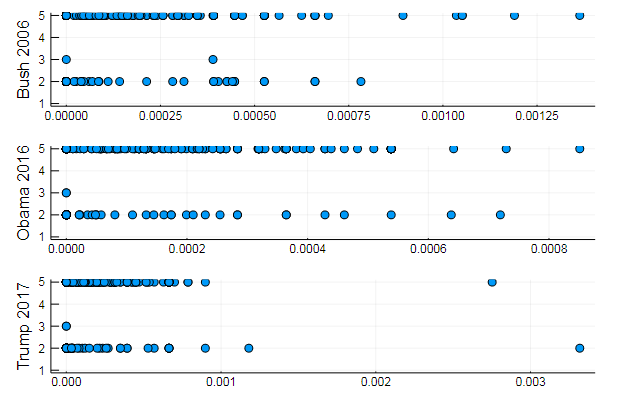
النتائج الطبيعية تماما ، والعروض من نفس النوع. في الواقع ، يعد البرمجة اللغوية العصبية (NLP) علمًا مثيرًا للاهتمام تمامًا ، ويمكنك استخراج الكثير من المعلومات المفيدة من البيانات المعدة بشكل صحيح: يمكنك العثور على العديد من الأمثلة على هذا المورد ( التعرف على المؤلف في التعليقات ، واستخدام LDA ، وما إلى ذلك)
حسنًا ، حتى لا نذهب بعيدًا ، سننشئ عبارات للرئيس المثالي:
قانون function loadfiles(filenames) return ( open(filename) do file text = read(file, String)
7-element Array{Any,1}: "I want harmony and fathers, sons and we mark the jobkilling TransPacific Partnership." "I am asking all across our partners must be one very happy, indeed." "At the health insurance and terrorismrelated offenses since my Inauguration, and the future and pay their jobs, their community." "Millions lifted from this Nation, and Jessica Davis." "It will expand choice, increase access, lower the Director of our aspirations, not working." "We will defend our freedom." "The challenges we will celebrate the audience tonight, has come for a record."
ذاكرة طويلة المدى
حسنًا ، كيف يمكن أن يكون ذلك بدون شبكات عصبية! إنهم يجمعون أمجاد في هذا المجال بسرعة متزايدة ، وتساهم بيئة لغة جوليا في ذلك بكل الطرق. بالنسبة للفضوليين ، يمكنك تقديم المشورة لحزمة Knet ، والتي ، على عكس Flux التي درسناها سابقًا ، لا تعمل مع بنيات الشبكات العصبية كمنشئ من الوحدات ، ولكن في الغالب تعمل مع التكرارات والتدفقات. هذا يمكن أن يكون ذا أهمية أكاديمية ويساهم في فهم أعمق لعملية التعلم ، كما أنه يوفر حوسبة عالية الأداء. من خلال النقر على الرابط المذكور أعلاه ، ستجد الإرشادات والأمثلة والمواد اللازمة للدراسة الذاتية (على سبيل المثال ، تُظهر كيفية إنشاء منشئ نص لشكسبير أو رمز juliac على الشبكات المتكررة). ومع ذلك ، يتم تنفيذ بعض وظائف حزمة Knet فقط من أجل وحدة معالجة الرسومات (GPU) ، لذلك في الوقت الحالي ، دعونا نواصل العمل حول Flux.
أحد الأمثلة النموذجية لتشغيل شبكات التكرار هو النموذج الذي يتم إطعام سوناتات شكسبير فيه رمزيا:
QUEN: Chiet? The buswievest by his seld me not report. Good eurronish too in me will lide upon the name; Nor pain eat, comes, like my nature is night. GRUMIO: What for the Patrople: While Antony ere the madable sut killing! I think, bull call. I have what is that from the mock of France: Then, let me? CAMILLE: Who! we break be what you known, shade well? PRINCE HOTHEM: If I kiss my go reas, if he will leave; which my king myself. BENEDICH: The aunest hathing rouman can as? Come, my arms and haste. This weal the humens? Come sifen, shall as some best smine? You would hain to all make on, That that herself: whom will you come, lords and lafe to overwark the could king to me, My shall it foul thou art not from her. A time he must seep ablies in the genely sunsition. BEATIAR: When hitherdin: so like it be vannen-brother; straight Edwolk, Wholimus'd you ainly. DUVERT: And do, still ene holy break the what, govy. Servant: I fearesed, Anto joy? Is it do this sweet lord Caesar: The dece
إذا كنت تحدق ولا تعرف الإنجليزية ، فإن المسرحية تبدو حقيقية تمامًا .

من السهل أن نفهم باللغة الروسية
ولكن من المثير للاهتمام تجربة الكثير من الأقوياء والأقوياء ، وعلى الرغم من أنه من الصعب للغاية معجميا ، يمكنك استخدام المزيد من الأدبيات البدائية كبيانات ، أي ، التي عرفت مؤخرًا باسم تيار الطليع للشعر الحديث - القوافي الفطرية.
جمع البيانات
الفطائر والمساحيق - رباعيات إيقاعية ، غالبًا بدون قافية ، تكتب في أحرف صغيرة وبدون علامات ترقيم.
انخفض الاختيار على موقع poetory.ru الذي المشرف الرفيق hior . كان الافتقار الطويل إلى الاستجابة لطلب البيانات هو السبب في بدء دراسة تحليل الموقع. تمنحك نظرة سريعة على برنامج HTML التعليمي فهماً أولياً لتصميم صفحات الويب. بعد ذلك ، نجد وسائل لغة جوليا للعمل في مثل هذه المجالات:

ثم ننفذ نصًا يحول صفحات الشعر ويحفظ الفطائر في مستند نصي:
قانون using HTTP, Gumbo, Cascadia function grabit(npages) str = "" for i = 1:npages url = "https://poetory.ru/por/rating/$i"
بمزيد من التفاصيل ، يتم تفكيكها في دفتر ملاحظات كوكب المشتري . دعنا نجمع الفطائر والبارود في سطر واحد:
str = read("pies.txt", String) * read("poroh.txt", String); length(str)
وانظر الأبجدية المستخدمة:
prod(sort([unique(str)..., '_']) )

تحقق من البيانات التي تم تنزيلها قبل بدء العملية.
آه آه آه ، يا له من عار! يخرق بعض المستخدمين القواعد (أحيانًا يعبر الناس عن أنفسهم عن طريق الضوضاء في هذه البيانات). لذلك سوف نقوم بتنظيف علبة الرمز الخاصة بنا من القمامة
str = lowercase(str)
كما نصحت rssdev10 ، يتم تعديل التعليمات البرمجية باستخدام التعبيرات العادية
حصلت على مجموعة أحرف أكثر قبولا. أكبر كشف لليوم هو أنه ، من وجهة نظر كود الآلة ، هناك ثلاثة مساحات مختلفة على الأقل - من الصعب على صيادي البيانات العيش.

يمكنك الآن توصيل Flux بالعرض التقديمي اللاحق للبيانات في شكل متجهات أحادية:
التدفق يأتي في اللعب using Flux using Flux: onehot, chunk, batchseq, throttle, crossentropy using StatsBase: wsample using Base.Iterators: partition texta = collect(str) println(length(texta))
لقد قمنا بتعيين النموذج من عدة طبقات من LSTM ، وإدراكًا متصلاً بالكامل و softmax ، بالإضافة إلى الأشياء الصغيرة اليومية ، ومن أجل وظيفة الفقد والمحسن:
قانون m = Chain( LSTM(N, 256), LSTM(256, 128), Dense(128, N), softmax)
يكون النموذج جاهزًا للتدريب ، لذلك من خلال تشغيل السطر أدناه ، يمكنك ممارسة نشاطك التجاري ، حيث يتم تحديد تكلفته وفقًا لقوة جهاز الكمبيوتر الخاص بك. في حالتي ، هاتان محاضرتان عن الفلسفة ، بالنسبة لبعض الشيء ، تم تسليمها إلينا في وقت متأخر من الليل ...
@time Flux.train!(loss, params(m), zip(Xs, Ys), opt, cb = throttle(evalcb, 30))
بعد تجميع مولد العينات ، يمكنك البدء في جني ثمار عملائك.
مولد barmaglot function sample(m, alphabet, len)
خيبة أمل طفيفة بسبب توقعات عالية بعض الشيء. على الرغم من أن الشبكة لا تحتوي إلا على سلسلة من الأحرف عند الإدخال ولا يمكنها العمل إلا مع ترددات اجتماعهم واحدًا تلو الآخر ، إلا أنها اكتشفت تمامًا هيكل مجموعة البيانات ، وأوضحت بعض مظاهر الكلمات ، وفي بعض الحالات أظهرت القدرة على الحفاظ على الإيقاع. ربما ، وتحديد تقارب الدلالية سوف تساعد في تحسين.

يمكن حفظ أوزان شبكة مدربة على القرص ، ثم قراءتها بسهولة
weights = Tracker.data.(params(model)); using BSON: @save
مع النثر ، أيضا ، فقط cyed psychedelia مجردة يخرج. كانت هناك محاولات لتحسين جودة عرض وعمق الشبكة ، وكذلك تنوع ووفرة البيانات. لفيلق النص المعطى ، شكر خاص لأكبر مشهور للغة الروسية

! . ? , , , , , , , , . , , , , . , . ? , , , , , ,
ولكن إذا قمت بتدريب شبكة عصبية على الكود المصدري للغة جوليا ، فسيظهر ذلك رائعًا:
إضافة إلى هذا إمكانية metaprogramming ، نحصل على برنامج يكتب ويعمل ، وربما حتى الكود الخاص بنا! حسنًا ، أو سيكون بمثابة هبة من السماء لمصممي الأفلام حول المتسللين .
بشكل عام ، تم إجراء البداية ، ثم بالفعل كما يشير الخيال. أولاً ، يجب أن تحصل على معدات عالية الجودة حتى لا تخنق الحسابات الطويلة الرغبة في التجربة. ثانياً ، نحتاج إلى دراسة الأساليب والاستدلال بشكل أعمق ، مما سيتيح لنا تصميم نماذج أفضل وأكثر تحسينًا. على هذا المورد ، يكفي العثور على كل ما يتعلق بمعالجة اللغة الطبيعية ، وبعد ذلك من الممكن تمامًا أن تُعلِّم شبكتك العصبية كيفية توليد الشعر أو الانتقال إلى hackathon لتحليل النص .
على هذا ، اسمحوا لي أن أغادر إجازتي. بيانات للتدريب في السحابة ، والقوائم على جيثب ، والنار في العيون ، وبيضة في بطة ، وكل ليلة سعيدة!