في أي لعبة كمبيوتر حديثة تقريبًا ، يعد وجود محرك مادي شرطًا أساسيًا. الأعلام والأرانب ترفرف في مهب الريح ، قصفتها كرات - كل هذا يتطلب التنفيذ السليم. وبالطبع ، حتى لو لم يكن جميع الأبطال يرتدون معطف واق من المطر ... ولكن أولئك الذين يرتدون ملابس يحتاجون حقًا إلى محاكاة كافية للنسيج المترف.

ومع ذلك ، فإن النمذجة الفيزيائية الكاملة لمثل هذه التفاعلات غالباً ما تصبح مستحيلة ، نظرًا لأن حجمها أبطأ من اللازم للألعاب في الوقت الفعلي. تقدم هذه المقالة طريقة جديدة للنمذجة يمكنها تسريع عمليات المحاكاة البدنية ، وجعلها أسرع بـ 300-5000 مرة. الغرض منه هو محاولة تدريس شبكة عصبية لمحاكاة القوى المادية.
يتم تحديد التقدم في تطوير المحركات الفيزيائية من خلال كل من قوة الحوسبة المتنامية للمعدات الفنية وتطوير أساليب النمذجة السريعة والمستقرة. تتضمن هذه الطرق ، على سبيل المثال ، النمذجة عن طريق قطع المسافة إلى مسافات فرعية والنُهج القائمة على البيانات - أي بناءً على البيانات. السابق يعمل فقط في فضاء فرعي منخفض أو مضغوط ، حيث يتم أخذ أشكال قليلة فقط من التشوه في الاعتبار. بالنسبة للمشاريع الكبيرة ، يمكن أن يؤدي ذلك إلى زيادة كبيرة في المتطلبات الفنية. تستخدم الأساليب المعتمدة على البيانات ذاكرة النظام والبيانات المحسوبة مسبقًا المخزنة فيه ، مما يقلل من هذه المتطلبات.
نحن هنا ننظر إلى نهج يجمع بين الطريقتين: وبهذه الطريقة ، فإنه يهدف إلى الاستفادة من نقاط القوة في كليهما. يمكن تفسير هذه الطريقة بطريقتين: إما كطريقة لنمذجة فضاء فرعي معلمة بواسطة شبكة عصبية ، أو كطريقة DD تعتمد على نمذجة فضاء جزئي لبناء وسيط مضغوط محاكي.
جوهرها هو: أولاً نجمع بيانات محاكاة عالية الدقة باستخدام
Maya nCloth ، ثم نحسب المساحة الفرعية الخطية باستخدام
طريقة المكون الرئيسي (PCA) . في الخطوة التالية ، نستخدم التعلم الآلي استنادًا إلى نموذج الشبكة العصبية الكلاسيكية ومنهجيتنا الجديدة ، وبعد ذلك نقدم النموذج المدرّب في خوارزمية تفاعلية مع العديد من التحسينات ، مثل خوارزمية تخفيف الضغط الفعالة بواسطة وحدة معالجة الرسومات (GPU) وطريقة لتقريب معايير الرأس الطبيعية.
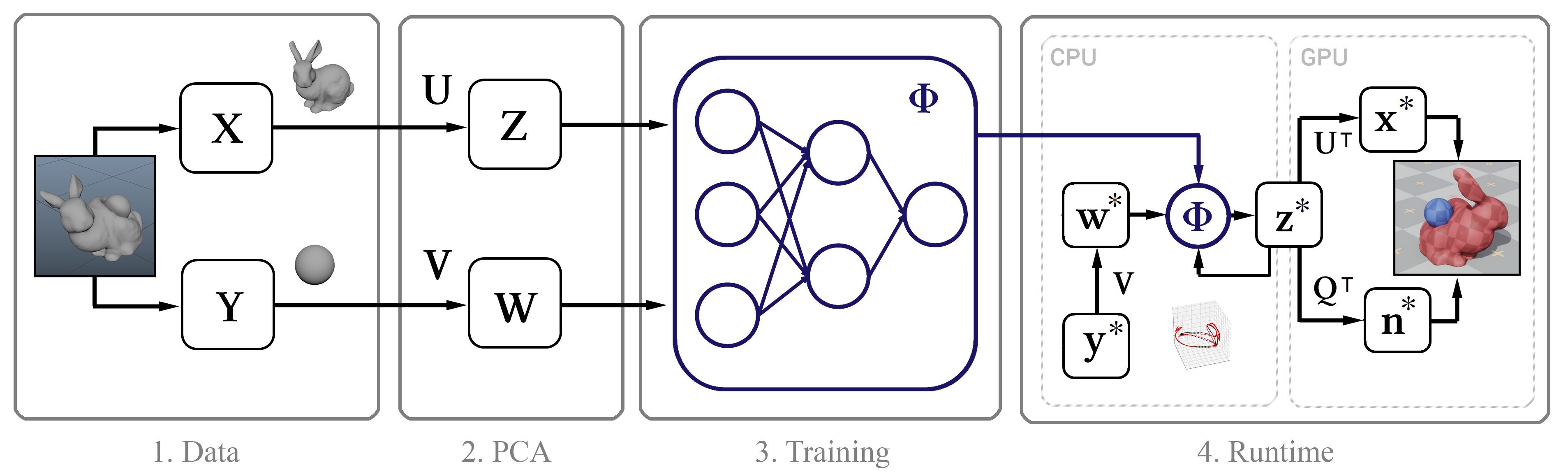 الشكل 1. المخطط الهيكلي للطريقة
الشكل 1. المخطط الهيكلي للطريقةبيانات التدريب
وبصفة عامة ، فإن المدخل الوحيد لهذه الطريقة هو الطوابع الزمنية الأولية لمواقع الإطار حسب الإطار لرؤوس الكائن. بعد ذلك ، نصف عملية جمع هذه البيانات.
نقوم بإجراء المحاكاة في Maya nCloth ، حيث نلتقط البيانات بسرعة 60 إطارًا في الثانية ، مع 5 أو 20 نقطة فرعية و 10 أو 25 تكرارًا للحد من التكرار ، اعتمادًا على ثبات المحاكاة. بالنسبة للأقمشة ، خذ نموذجًا من القمصان مع زيادة طفيفة في وزن المادة ومقاومتها للامتداد ، وللأشياء المشوهة ، مطاط صلب باحتكاك أقل. نقوم بإجراء تصادمات خارجية عن طريق تصادم مثلثات الهندسة الخارجية ، تصادمات ذاتية - رؤوس ذات رؤوس للنسيج ومثلثات مع مثلثات للمطاط. في جميع الحالات ، نستخدم سُمك تصادم كبيرًا - يصل إلى 5 سم - لضمان ثبات النموذج ولمنع سرقة النسيج وتمزيقه.
جدول 1. معلمات العناصر النموذجية
بالنسبة لأنواع مختلفة من تفاعل الكائنات البسيطة (على سبيل المثال ، المجالات) ، سننشئ حركتها بطريقة عشوائية عن طريق اقتصاص إحداثيات عشوائية في أوقات عشوائية. لمحاكاة تفاعل الأنسجة مع شخص ما ، نستخدم قاعدة بيانات لالتقاط الحركة من 6.5 × 10
5 إطارات ، والتي تعد واحدة من الرسوم المتحركة الكبيرة. عند الانتهاء من المحاكاة ، نتحقق من النتيجة ونستبعد الإطارات ذات السلوك غير المستقر أو السيء. بالنسبة للمشهد مع التنورة ، نزيل أيدي الشخصية ، لأنها تتقاطع غالبًا مع هندسة شبكة الساقين وهي الآن غير ذات أهمية.
 الشكل 2. أول اثنين من المشاهد من الجدول
الشكل 2. أول اثنين من المشاهد من الجدولعادة ما نحتاج إلى 10
5 -10
6 إطارات من بيانات التدريب. في تجربتنا ، في معظم الحالات 10
5 إطارات كافية للاختبار ، في حين يتم تحقيق أفضل النتائج مع 10
6 إطارات.
تدريب
بعد ذلك ، سوف نتحدث عن عملية التعلم الآلي: حول وضع المعلمات في شبكتنا العصبية ، حول هندسة الشبكة ومباشرة حول التقنية نفسها.
البارامترات
من أجل الحصول على مجموعة بيانات التدريب ، نقوم بجمع إحداثيات القمم في كل إطار
t في متجه واحد
× t ، ثم ندمج متجهات الإطار حسب الإطار في مصفوفة كبيرة X. تصف هذه المصفوفة حالات الكائن الذي تم نمذجه. بالإضافة إلى ذلك ، يجب أن يكون لدينا فكرة عن حالة الكائنات الخارجية في كل إطار. بالنسبة للكائنات البسيطة (مثل الكرات) ، يمكنك استخدام إحداثياتها ثلاثية الأبعاد ، بينما يتم وصف حالة النماذج المعقدة (حرف) بموقف كل مفصل بالنسبة للنقطة المرجعية: في حالة التنورة ، سيكون مثل هذا الدعم مفصل الورك ، في حالة وجود عباءة - الرقبة. بالنسبة للأجسام ذات النظام المرجعي المتحرك ، يجب أن يؤخذ موقع الأرض بالنسبة إليه في الاعتبار: عندها سيعرف نظامنا اتجاه الجاذبية ، وكذلك سرعته الخطية ، وسرعة دورانه وتسارع الدوران. بالنسبة للعلم ، سوف نأخذ في الاعتبار سرعة الريح واتجاهها. نتيجة لذلك ، نحصل على كل كائن متجه واحد كبير يصف حالة الكائن الخارجي ، ويتم دمج كل هذه المتجهات أيضًا في المصفوفة Y.
نحن الآن نطبق PCA على المصفوفة X و Y ، ونستخدم مصفوفات التحويل الناتجة Z و W لإنشاء صورة فضاء فرعية. إذا تطلب إجراء PCA الكثير من الذاكرة ، فاختبر أولاً بياناتنا.
يؤدي ضغط PCA إلى فقدان التفاصيل ، لا سيما بالنسبة للكائنات التي لها العديد من الظروف المحتملة ، مثل الطيات الرفيعة من القماش. ومع ذلك ، إذا كانت المساحة الفرعية تتكون من 256 متجهًا أساسيًا ، فهذا يساعد عادةً في الحفاظ على معظم التفاصيل. فيما يلي رسوم متحركة للفيزياء القياسية للعباءة والموديلات ذات ناقلات 256 و 128 و 64 ، على التوالي.
 الشكل 3. مقارنة نموذج التحكم (قياسي) مع النماذج التي تم الحصول عليها عن طريق الأسلوب لدينا في مسافات ذات قواعد الأبعاد المختلفة
الشكل 3. مقارنة نموذج التحكم (قياسي) مع النماذج التي تم الحصول عليها عن طريق الأسلوب لدينا في مسافات ذات قواعد الأبعاد المختلفةالمصدر ونموذج الموسعة
كان من الضروري تطوير نموذج يمكنه التنبؤ بحالة ناقلات النموذج في الأطر المستقبلية. ونظرًا لأن الأجسام النموذجية تتميز عادة بالقصور الذاتي مع ميل إلى حالة متوسطة معينة من الراحة (بعد إجراء PCA يأخذ الكائن مثل هذه الحالة عند قيم صفرية) ، فإن النموذج الأولي الجيد سيكون التعبير الذي يمثله السطر 9 من الخوارزمية في الشكل 4. وهنا α و parameters معلمات النموذج ، ⊙ منتج متفجر. سيتم الحصول على قيم هذه المعلمات من بيانات المصدر عن طريق حل
معادلة المربعات الصغرى الخطية بشكل فردي لكل من α و β:
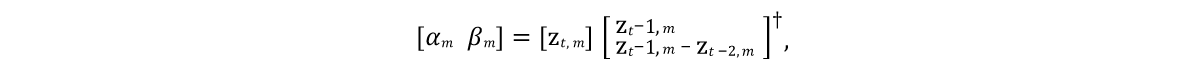
هنا † هو
التحول العكسي المزيف للمصفوفة .
نظرًا لأن مثل هذا التوقع ليس سوى تقريب تقريبي للغاية ولا يأخذ في الاعتبار تأثير الكائنات الخارجية ، فمن الواضح أنه لن يكون قادرًا على نمذجة بيانات التدريب بدقة. لذلك ، نقوم بتدريب الشبكة العصبية Φ لتقريب الآثار المتبقية للنموذج وفقًا للسطر 11 من الخوارزمية. هنا نقوم بمعلمة
شبكة عصبية للتوزيع المباشر المباشر مع 10 طبقات ، لكل طبقة (باستثناء الإخراج) باستخدام وظيفة التنشيط
ReLU . باستثناء طبقات المدخلات والمخرجات ، قمنا بتعيين عدد الوحدات المخفية في كل طبقة متبقية تساوي واحدًا ونصف حجم بيانات PCA ، مما أدى إلى تسوية جيدة بين المساحة المشغولة على القرص الصلب والأداء.
 الشكل 4. خوارزمية التعلم الشبكة العصبية
الشكل 4. خوارزمية التعلم الشبكة العصبيةتدريب الشبكة العصبية
تتمثل الطريقة القياسية لتدريب الشبكة العصبية في التكرار عبر مجموعة البيانات بالكامل وتدريب الشبكة على التنبؤ بكل إطار. بطبيعة الحال ، سوف يؤدي هذا النهج إلى انخفاض خطأ التعلم ، ولكن ردود الفعل في مثل هذا التنبؤ سوف تتسبب في سلوك غير مستقر لنتيجة ذلك. لذلك ، لضمان تنبؤ مستقر طويل الأجل ، تستخدم خوارزمية لدينا
طريقة انتشار الأخطاء عبر عملية التكامل.
بشكل عام ، يعمل مثل هذا: من نافذة صغيرة من بيانات التدريب
z و
w ، نأخذ الإطارين الأولين
z 0 و
z 1 ونضيف القليل من الضوضاء
r 0 ،
r 1 إليهما ، لتعطيل مسار التعلم قليلاً. ثم ، للتنبؤ بالإطارات التالية ، نقوم بتشغيل الخوارزمية عدة مرات ، ونعود إلى النتائج السابقة للتنبؤات في كل خطوة زمنية جديدة. بمجرد أن نحصل على التنبؤ بالمسار بأكمله ، نحسب متوسط خطأ الإحداثيات ، ثم نمرره إلى مُحسِّن AmsGrad باستخدام المشتقات التلقائية المحسوبة باستخدام TensorFlow.
سنكرر هذه الخوارزمية على عينات صغيرة من 16 إطارًا ، باستخدام نوافذ متداخلة من 32 إطارًا ، لمدة 100 عصر أو حتى يتقارب التدريب. نحن نستخدم معدل التعلم البالغ 0.0001 ، ومعامل التوهين لمعدل التعلم عند 0.999 ، والانحراف المعياري للضوضاء المحسوبة من المكونات الثلاثة الأولى لمساحة PCA. يستغرق هذا التدريب من 10 إلى 48 ساعة ، حسب تعقيد التثبيت وحجم بيانات PCA.
 الشكل 5. مقارنة بصرية للتنورة المرجعية وتلك التي استخلصتها شبكتنا العصبية
الشكل 5. مقارنة بصرية للتنورة المرجعية وتلك التي استخلصتها شبكتنا العصبيةتنفيذ النظام
سنشرح بالتفصيل تنفيذ طريقتنا في بيئة تفاعلية ، بما في ذلك تقييم الشبكة العصبية ، وحساب القيم الطبيعية على أسطح الكائنات لتقديمها ، وكيفية تعاملنا مع التقاطعات المرئية.
تقديم التطبيق
نقدم النماذج الناتجة في تطبيق ثلاثي الأبعاد تفاعلي بسيط مكتوب بلغة C ++ و DirectX: ننفذ مرة أخرى العمليات الأولية وعمليات الشبكة العصبية في رمز C ++ أحادي الترابط ونحمل أوزان الشبكة الثنائية التي تم الحصول عليها أثناء إجراء التدريب لدينا. ثم نطبق بعض التحسينات البسيطة لتقدير الشبكة ، على وجه الخصوص ، إعادة استخدام المخازن المؤقتة للذاكرة وبيانات متجهات المصفوفة المتناثرة ، والتي أصبحت ممكنة بسبب وجود وحدات مخفية صفرية تم الحصول عليها بفضل وظيفة تنشيط ReLU.
GPU الضغط
أرسل بيانات حالة z المضغوطة إلى وحدة معالجة الرسومات وفك ضغطها لمزيد من التقديم. تحقيقًا لهذه الغاية ، نستخدم تظليلًا حسابيًا بسيطًا ، حيث يحسب لكل نقطة رأس الكائن المنتج النقطي للناقل z والصفوف الثلاثة الأولى من المصفوفة U
T المطابقة لإحداثيات هذه القمة ، وبعد ذلك نضيف متوسط القيمة
x µ . هذا النهج له ميزتان على
طريقة الضغط
الساذجة . أولاً ، تسارع التوازي في وحدة معالجة الرسومات بشكل كبير في حساب متجه حالة النموذج ، والذي قد يستغرق ما يصل إلى 1 مللي ثانية. ثانياً ، إنه يقلل من وقت نقل البيانات بين المركزي و GPU بترتيب من حيث الحجم ، وهو أمر مهم بشكل خاص للمنصات التي يكون فيها نقل حالة الكائن بالكامل بطيئًا للغاية.
تنبؤ Vertex العادي
أثناء العرض ، لا يكفي الوصول فقط إلى إحداثيات القمم - هناك حاجة أيضًا إلى معلومات حول تشوهات أوضاعها الطبيعية. عادةً ما يتم حذف هذا الحساب في محرك مادي ، أو إجراء إعادة حساب ساذج لكل إطار على حدة من القواعد الطبيعية مع إعادة توزيعها اللاحقة على القمم المجاورة. قد يكون هذا غير فعال ، لأن التنفيذ الأساسي للمعالج المركزي ، بالإضافة إلى تكاليف تخفيف الضغط ونقل البيانات ، يتطلب 150 ثانية أخرى لمثل هذا الإجراء. وعلى الرغم من أنه يمكن إجراء هذا الحساب على وحدة معالجة الرسومات ، إلا أنه يبدو أنه يصعب تنفيذه بسبب الحاجة إلى عمليات موازية.
بدلاً من ذلك ، نقوم بإجراء انحدار خطي لحالة الفضاء الفرعي إلى متجهات الحالة الكاملة الطبيعية على تظليل GPU. مع العلم بقيم القيم الطبيعية للرؤوس في كل إطار ، نقوم بحساب المصفوفة Q ، التي تمثل أفضل تمثيل للمساحة الفرعية على القواعد الطبيعية للرؤوس.
نظرًا لأن التنبؤ بالمعايير الطبيعية في طريقتنا لم يتم عرضه من قبل ، ليس هناك ما يضمن أن هذا النهج سيكون دقيقًا ، ولكن من الناحية العملية ، أثبت أنه جيد حقًا ، كما يتضح من الشكل أدناه.
 الشكل 6. مقارنة بين النماذج المحسوبة من خلال طريقتنا والمرجع (الحقيقة الأساسية) ، وكذلك الفرق بينهما
الشكل 6. مقارنة بين النماذج المحسوبة من خلال طريقتنا والمرجع (الحقيقة الأساسية) ، وكذلك الفرق بينهماتقاطع القتال
تتعلم شبكتنا العصبية أداء تصادمات بكفاءة ، ومع ذلك ، بسبب عدم الدقة في التنبؤات والأخطاء الناجمة عن ضغط الفضاء الفرعي ، قد تحدث التقاطعات بين الكائنات الخارجية وتلك المحاكاة. علاوة على ذلك ، نظرًا لأننا قمنا بتأجيل حساب الحالة الكاملة للمشهد حتى بداية العرض ، لا توجد طريقة لحل هذه المشكلات مسبقًا بفعالية. لذلك ، للحفاظ على الأداء العالي ، يعد التخلص من هذه التقاطعات ضروريًا أثناء التقديم.
لقد وجدنا حلاً بسيطًا وفعالًا لهذا الغرض ، والذي يتكون من حقيقة أن الرؤوس المتقاطعة يتم عرضها على سطح البدائية التي نشكل منها الشخصية. من السهل القيام بهذا الإسقاط على وحدة معالجة الرسومات (GPU) باستخدام نفس التظليل الحسابي الذي يلغي ضغط النسيج ويحسب التظليل العادي.
, - , . - , , -. , , .
, , -.
 7. , -, :
7. , -, :, :
, .
- 16 , 120 240 .
 8. 16 . Party time!
8. 16 . Party time!, , , , .
, PCA. , , , .
 9. , , –
9. , , –― , . , . 300-5000 , . ,
- (HRPD) ,
(LSTM) (GRU) .
, . Intel Xeon E5-1650 3.5 GHz GeForce GTX 1080 Titan.
2.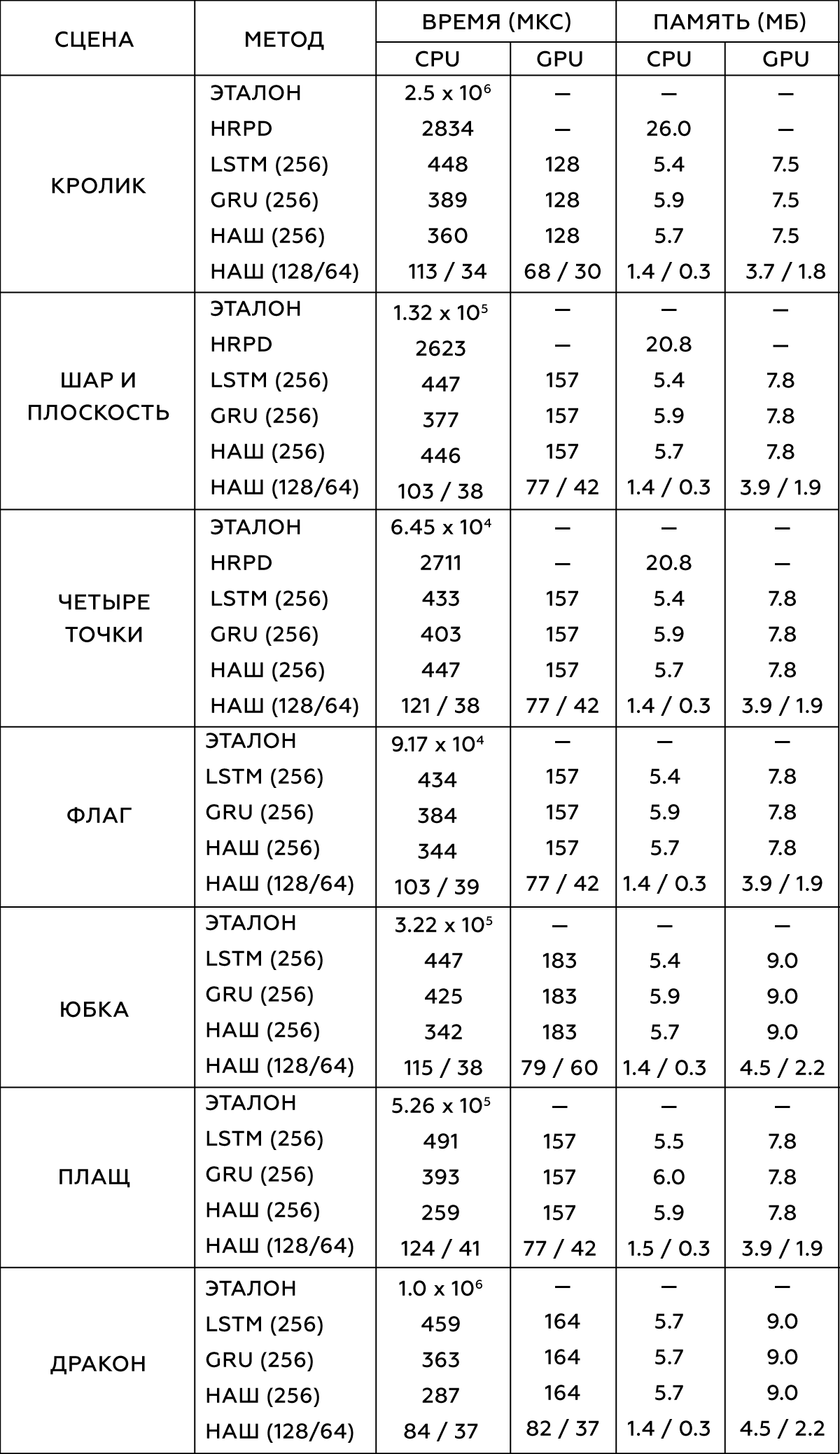
, , . , .
data-driven , . , , , , , . , , ― , .
, , , .
, . data-driven , ― , . , , , . , , , .
, . .
, , , . , , ― , . -, , , - . .
, , , , . , , , , ― , , . .
.
 10. vs : choose your fighter
10. vs : choose your fighter