
لا تتفاجأ ، ولكن العنوان الثاني لهذا المنشور أنشأ شبكة عصبية ، أو بالأحرى خوارزمية التماثيل. وما هو السماير؟
هذا أحد
التحديات الأساسية والكلاسيكية
لمعالجة اللغة الطبيعية (NLP) . يتكون في إنشاء خوارزمية تأخذ النص كمدخلات وتخرج نسخة مختصرة منه. علاوة على ذلك ، يتم الحفاظ على البنية الصحيحة (المقابلة لمعايير اللغة) فيه ويتم نقل الفكرة الرئيسية للنص بشكل صحيح.
تستخدم هذه الخوارزميات على نطاق واسع في الصناعة. على سبيل المثال ، فهي مفيدة لمحركات البحث: باستخدام تقليل النص ، يمكنك بسهولة فهم ما إذا كانت الفكرة الرئيسية للموقع أو الوثيقة مرتبطة باستعلام البحث. يتم استخدامها للبحث عن المعلومات ذات الصلة في دفق كبير من بيانات الوسائط وتصفية البيانات المهملة. يساعد تقليل النصوص في البحث المالي ، وفي تحليل العقود القانونية ، وتعليق الأوراق العلمية ، وغير ذلك الكثير. بالمناسبة ، أنتجت خوارزمية sammarization جميع العناوين الفرعية لهذا المنشور.
لدهشتي ، كان هناك عدد قليل جدًا من المقالات حول حبري عن حبري ، لذلك قررت أن أشارك بحثي ونتائجي في هذا الاتجاه. شاركت هذا العام في مضمار السباق في مؤتمر
الحوار وتجربت مع المولدات الرئيسية للعناوين الإخبارية والقصائد التي تستخدم الشبكات العصبية. في هذا المنشور ، سوف أتطرق أولاً إلى الجزء النظري من عملية وضع العلامات ، ثم سأقدم أمثلة مع توليد العناوين ، وسأخبرك عن الصعوبات التي تواجهها النماذج عند تقليل النص وكيف يمكن تحسين هذه النماذج لتحقيق عناوين أفضل.
فيما يلي مثال لعنصر الأخبار وعنوانه المرجعي الأصلي. النماذج التي سأتحدث عنها ستتدرب على إنشاء رؤوس بهذا المثال:

أسرار لخفض النص seq2seq الهندسة المعمارية
هناك نوعان من أساليب تقليل النص:
- الاستخراجية . يتكون في العثور على الأجزاء الأكثر إفادة من النص وإنشاء الشرح الصحيح للغة المحددة منها. تستخدم مجموعة الطرق هذه الكلمات الموجودة في النص المصدر فقط.
- مجردة. وهو يتألف من استخراج الروابط الدلالية من النص ، مع مراعاة التبعيات اللغوية. باستخدام sammarization المجردة ، لا يتم تحديد كلمات التعليق التوضيحي من النص المختصر ، ولكن من القاموس (قائمة الكلمات الخاصة بلغة معينة) - وبذلك تعيد صياغة الفكرة الرئيسية.
النهج الثاني يعني أن الخوارزمية يجب أن تأخذ في الاعتبار التبعيات اللغوية ، وإعادة صياغتها وتعميمها. إنه يريد أيضًا أن يكون لديه بعض المعرفة بالعالم الحقيقي من أجل منع الأخطاء الواقعية. لفترة طويلة ، كانت هذه مهمة صعبة ، ولم يتمكن الباحثون من الحصول على حل عالي الجودة - نص صحيح نحويًا مع الحفاظ على الفكرة الرئيسية. وهذا هو السبب في أن معظم الخوارزميات في الماضي كانت تعتمد على طريقة استخراج ، حيث أن اختيار أجزاء كاملة من النص ونقلها إلى النتيجة يسمح لك بالحفاظ على نفس مستوى معرفة القراءة والكتابة كمصدر.
ولكن هذا كان قبل طفرة الشبكات العصبية واختراقها الوشيك في البرمجة اللغوية العصبية. في عام 2014 ، تم
تقديم بنية
seq2seq بآلية اهتمام يمكنها قراءة بعض تسلسلات النص وتوليد أخرى (والتي تعتمد على ما تعلمه النموذج لإخراج) (
مقالة من Sutskever et al.). في عام 2016 ، تم تطبيق مثل هذه البنية مباشرةً على حل مشكلة التسميط ، وبالتالي تحقيق مقاربة مجردة والحصول على نتيجة مماثلة لما يمكن أن يكتبه شخص مختص (
مقال من Nallapati et al. ، 2016 ؛
مقال من Rush et al.، 2015؛ ). كيف تعمل هذه العمارة؟
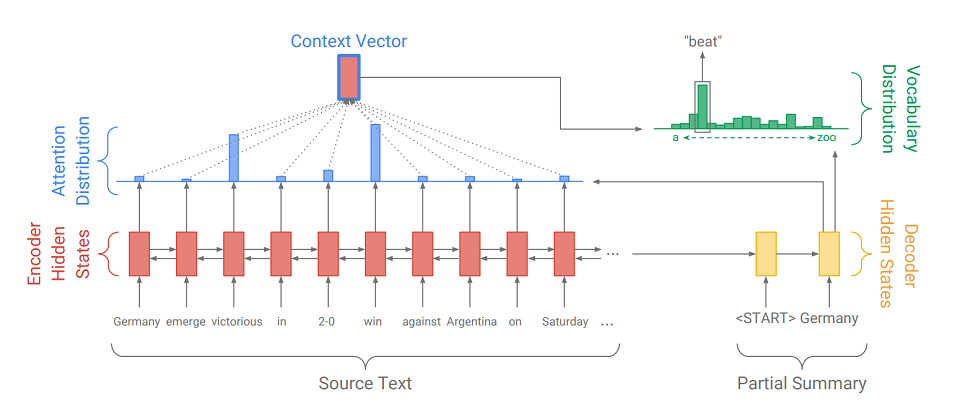
يتكون Seq2Seq من جزأين:
- Encoder (Encoder) - RNN ذو اتجاهين ، والذي يستخدم لقراءة تسلسل الإدخال ، أي يعالج عناصر الإدخال بالتسلسل في وقت واحد من اليسار إلى اليمين ومن اليمين إلى اليسار لأخذ السياق في الاعتبار بشكل أفضل.
- وحدة فك الترميز ( decoder ) - RNN أحادية الاتجاه ، والتي تنتج بالتتابع والعنصر تسلسل إخراج.
أولاً ، يتم ترجمة تسلسل الإدخال إلى تسلسل تضمين (باختصار ، التضمين عبارة عن تمثيل موجز لكلمة متجه). حفلات الزفاف ثم انتقل من خلال شبكة العودية من التشفير. لذلك ، بالنسبة لكل كلمة ، نحصل على حالات التشفير المخفية (
المشار إليها بواسطة المستطيلات الحمراء في الرسم التخطيطي ) ، وتحتوي على معلومات حول الرمز المميز نفسه وسياقه ، مما يسمح لنا بمراعاة الروابط اللغوية بين الكلمات.
بعد معالجة الإدخال ، يقوم المشفر بنقل آخر حالة مخفية (والتي تحتوي على معلومات مضغوطة حول النص بأكمله) إلى وحدة فك الترميز ، والتي تتلقى رمزًا مميزًا

ويخلق الكلمة الأولى من تسلسل الإخراج (
في الصورة هو "ألمانيا" ). ثم يأخذ دوريًا مخرجاته السابقة ، ويطعمها بنفسه ويعرض مرة أخرى عنصر المخرجات التالي (
حتى بعد أن تأتي "ألمانيا" "تغلب" ، وبعد "تغلب" تأتي الكلمة التالية ، إلخ .). يتكرر هذا حتى يتم إصدار رمز مميز خاص
. وهذا يعني نهاية الجيل.
لعرض العنصر التالي ، تقوم وحدة فك الترميز ، مثلها مثل أداة التشفير ، بتحويل رمز الإدخال إلى تضمين ، وتتخذ خطوة من شبكة العودية وتتلقى الحالة المخفية التالية لوحدة فك الترميز (
المستطيلات الصفراء في الرسم التخطيطي ). ثم ، باستخدام طبقة متصلة بالكامل ، يتم الحصول على توزيع الاحتمالات لجميع الكلمات من قاموس نموذج تم تجميعه مسبقًا. سيتم استنتاج الكلمات الأكثر احتمالا بواسطة النموذج.
تساعد إضافة
آلية انتباه وحدة فك الترميز على الاستفادة بشكل أفضل من معلومات الإدخال. تحدد الآلية في كل خطوة من مراحل الجيل ما يسمى
توزيع الانتباه (
المستطيلات الزرقاء في الشكل هي مجموعة من الأوزان المقابلة لعناصر التسلسل الأصلي ، ومجموع الأوزان هو 1 ، جميع الأوزان> = 0 ) ، ومنه يتلقى مجموع موزون من جميع الحالات المخفية من التشفير ، وبالتالي تشكيل متجه السياق (
يعرض الرسم التخطيطي مستطيل أحمر بضربة زرقاء ). يتصل هذا المتجه بتضمين كلمة إدخال وحدة فك الترميز في مرحلة حساب الحالة الكامنة ومع الحالة الكامنة نفسها في مرحلة تحديد الكلمة التالية. لذلك في كل خطوة من مراحل الإخراج ، يمكن للنموذج تحديد حالات التشفير الأكثر أهمية له في الوقت الحالي. بمعنى آخر ، يقرر السياق الذي يجب أن يؤخذ بعين الاعتبار كلمات الإدخال الأكثر (على سبيل المثال ، في الصورة ، عرض كلمة "فوز" ، تعطي آلية الانتباه أوزانًا كبيرة لرموز "المنتصرة" و "الفوز" ، والباقي قريبة من الصفر).
نظرًا لأن توليد الرؤوس هو أيضًا أحد مهام عملية التمييع ، فقط مع الحد الأدنى من الإخراج الممكن (1-12 كلمة) ، قررت تطبيق
seq2seq مع آلية الانتباه لحالتنا . نقوم بتدريب مثل هذا النظام على النصوص ذات العناوين ، على سبيل المثال ، على الأخبار. علاوة على ذلك ، من المستحسن في مرحلة التدريب أن يقدم إلى وحدة فك الترميز ليس إخراجه الخاص ، ولكن كلمات العنوان الحقيقي (إجبار المعلم) ، مما يجعل الحياة أسهل لنفسه وللنموذج. كدالة للخطأ ، نستخدم دالة الفقدان المتقاطع المعياري ، ونبين مدى قرب توزيعات الاحتمال لكلمة الإخراج والكلمة من العنوان الحقيقي:
عند استخدام النموذج المدرب ، نستخدم ميزة البحث عن الأشعة للعثور على تسلسل أكثر احتمالا للكلمات من استخدام الخوارزمية الجشعة. للقيام بذلك ، في كل خطوة من خطوات الجيل ، لا نستمد أكثر الكلمات احتمالا ، ولكن في نفس الوقت ننظر إلى beam_size لتسلسل الكلمات الأكثر احتمالا. عندما تنتهي (كل واحد ينتهي في
) ، نشتق التسلسل الأكثر احتمالا.
تطور النموذج
تتمثل إحدى مشكلات النموذج على seq2seq في عدم القدرة على الاستشهاد بالكلمات غير الموجودة في القاموس. على سبيل المثال ، لا يوجد لدى النموذج أي فرصة لاستنتاج "obamacare" من المقالة أعلاه. الشيء نفسه ينطبق على:
- الألقاب والأسماء النادرة
- شروط جديدة
- الكلمات بلغات أخرى ،
- أزواج مختلفة من الكلمات متصلة بواسطة واصلة (باسم "عضو مجلس الشيوخ الجمهوري")
- وغيرها من التصاميم.
بالطبع ، يمكنك توسيع القاموس ، لكن هذا يزيد بشكل كبير من عدد المعلمات المدربة. بالإضافة إلى ذلك ، من الضروري توفير عدد كبير من المستندات التي توجد بها هذه الكلمات النادرة ، حتى يتعلم المولد استخدامها بطريقة نوعية.
تم تقديم حل آخر وأكثر أناقة لهذه المشكلة في مقال 2017 - "
Get To The Point: Summarization with Pointer-Generator Networks " (Abigail See et al.). إنها تضيف آلية جديدة إلى نموذجنا -
آلية مؤشر ، والتي يمكنها اختيار الكلمات من النص المصدر وإدراجها مباشرة في التسلسل الذي تم إنشاؤه. إذا كان النص يحتوي على OOV (
خارج المفردات - كلمة غير موجودة في القاموس ) ، فيمكن للنموذج ، إذا رأى أنه ضروري ، عزل OOV وإدخاله في الإخراج. يُطلق على هذا النظام اسم
" مولد المؤشر" (مولد المؤشر أو pg) وهو عبارة عن توليفة من طريقتين نحو أخذ العينات. يمكنها أن تقرر بنفسها الخطوة التي ينبغي أن تكون مجردة ، وفي أي خطوة استخراج. كيف تفعل ذلك ، سنكتشفها الآن.
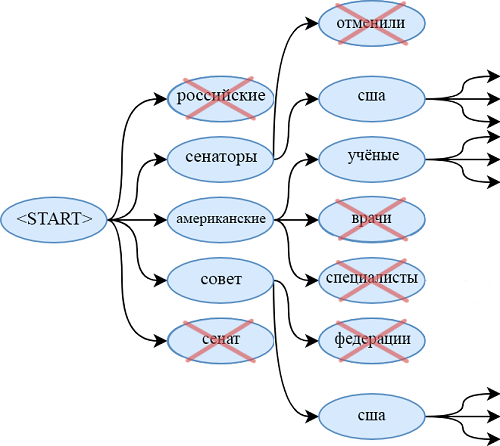
الفرق الرئيسي عن نموذج seq2seq المعتاد هو الإجراء الإضافي الذي يتم احتساب p فيه - احتمال التوليد. يتم ذلك باستخدام الحالة المخفية لوحدة فك التشفير ومتجه السياق. معنى الإجراء الإضافي بسيط. الأقرب p
gen هو 1 ، والأرجح أن النموذج سيصدر كلمة من قاموسه باستخدام الجيل المجرد. الأقرب p
gen هو 0 ، والأرجح أن المولد يستخرج الكلمة من النص ، مسترشداً بتوزيع الانتباه الذي تم الحصول عليه سابقًا. توزيع الاحتمال النهائي للكلمة هو مجموع توزيع الاحتمال الناتج للكلمات (التي لا يوجد فيها OOV) مضروب في p
gen وتوزيع الانتباه (حيث يكون OOV ، على سبيل المثال ، "2-0" في الصورة) مضروبًا (1 - p
الجنرال ).

بالإضافة إلى آلية التأشير ، تقدم المقالة
آلية تغطية ، والتي تساعد على تجنب تكرار الكلمات. لقد جربتها أيضًا ، لكنني لم ألاحظ تحسينات كبيرة في جودة العناوين - ليست هناك حاجة إليها حقًا. على الأرجح ، يرجع ذلك إلى تفاصيل المهمة: نظرًا لأنه من الضروري إخراج عدد صغير من الكلمات ، فالمنشئ ببساطة ليس لديه وقت لتكرار نفسه. لكن بالنسبة لمهام أخرى تتمثل في عملية التفسير ، على سبيل المثال ، التعليق التوضيحي ، يمكن أن تكون مفيدة. إذا كانت مهتمة ، يمكنك أن تقرأ عنها في
المقال الأصلي.

مجموعة كبيرة ومتنوعة من الكلمات الروسية
هناك طريقة أخرى لتحسين جودة رؤوس المخرجات وهي المعالجة المسبقة لتسلسل الإدخال بشكل صحيح. بالإضافة إلى التخلص الواضح من الأحرف الكبيرة ، حاولت أيضًا تحويل الكلمات من النص المصدر إلى أزواج من الأنماط والانعكاسات (مثل الأسس والنهايات). للتقسيم ، استخدم Porter Stemmer.
نحتفل بجميع التصريفات برمز "+" في البداية لتمييزها عن الرموز الأخرى. نحن نعتبر كل موضوع وانعكاس كلمة منفصلة ونتعلم منها بنفس طريقة الكلمات. أي أننا نحصل على حفلات زفاف منها ونشتق تسلسلًا (مقسمًا أيضًا إلى أسس ونهايات) يمكن تحويله بسهولة إلى كلمات.
مثل هذا التحويل مفيد جدًا عند العمل بلغات غنية الشكل مثل الروسية. بدلاً من تجميع القواميس الضخمة مع مجموعة كبيرة ومتنوعة من أشكال الكلمات الروسية ، يمكنك قصر نفسك على عدد كبير من السيقان لهذه الكلمات (فهي أصغر بعدة مرات من عدد أشكال الكلمات) ومجموعة صغيرة جدًا من النهايات (حصلت على 450 تصريفًا كبيرًا). وبالتالي ، نسهل على النموذج العمل مع هذه "الثروة" وفي نفس الوقت لا نزيد من تعقيد البنية وعدد المعلمات.

حاولت أيضًا استخدام تحويل lemma + gramme. أي أنه من كل كلمة قبل المعالجة ، يمكنك الحصول على شكلها الأولي ومعناه النحوي باستخدام حزمة pymorphy (على سبيل المثال ، "كان"
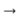
"أن تكون" و "VERB | impf | الماضي | الغناء | femn"). وهكذا ، حصلت على زوج من التسلسلات المتوازية (في واحد - الأشكال الأولية ، في الآخر - القيم النحوية). بالنسبة لكل نوع من التسلسل ، قمت بتجميع حفلاتي ، التي قمت بتسلسلها ثم أرسلتها إلى خط الأنابيب الموضح سابقًا. في ذلك ، لم يتعلم وحدة فك الترميز لإعطاء كلمة ، ولكن ليما والقواعد. ولكن مثل هذا النظام لم يجلب تحسينات واضحة مقارنة مع pg في الموضوع. ربما كانت بنية بسيطة للغاية للعمل مع القيم النحوية ، وكان الأمر يستحق إنشاء مصنف منفصل لكل فئة نحوية في المخرجات. لكنني لم أجرب هذه النماذج أو أكثر تعقيدًا.
لقد جربت إضافة أخرى إلى البنية الأصلية لمولد المؤشر ، والتي ، مع ذلك ، لا تنطبق على المعالجة المسبقة. هذه زيادة في عدد الطبقات (حتى 3) من الشبكات العودية الخاصة بالتشفير وفك الشفرة. يمكن أن تؤدي زيادة عمق الشبكة المتكررة إلى تحسين جودة المخرجات ، نظرًا لأن الحالة الخفية للطبقات الأخيرة يمكن أن تحتوي على معلومات حول مدخلات أطول بكثير من الحالة المخفية لشبكة RNN أحادية الطبقة. يساعد ذلك على مراعاة الاتصالات الدلالية المعقدة الموسعة بين عناصر تسلسل الإدخال. صحيح ، هذا يكلف زيادة كبيرة في عدد المعلمات النموذج ويعقد التعلم.

تجارب مولد الرأس
يمكن تقسيم كل تجاربي على المولدات الرئيسية إلى نوعين: التجارب على المقالات الإخبارية والآيات. سأخبرك عنها بالترتيب.
تجارب الأخبار
عند العمل مع الأخبار ، استخدمت طرزًا مثل seq2seq و pg و pg مع السيقان والعيوب - طبقة واحدة وثلاث طبقات. لقد فكرت أيضًا في النماذج التي تعمل مع غرامات ، ولكن كل ما أردت أن أخبره عنها ، لقد سبق أن وصفت أعلاه. يجب أن أقول على الفور أن جميع الصفحات الموصوفة في هذا القسم استخدمت آلية الطلاء ، على الرغم من أن تأثيرها على النتيجة أمر مشكوك فيه (لأنه بدونها لم يكن الوضع أسوأ بكثير).
لقد تدربت على مجموعة بيانات RIA Novosti ، التي قدمتها وكالة أنباء Rossiya Segodnya لإجراء مسار رئيسي في مؤتمر Dialog. تحتوي مجموعة البيانات على 1،003،869 مقالة إخبارية نشرت من يناير 2010 إلى ديسمبر 2014.
استخدمت جميع النماذج المدروسة نفس الزخارف (128) والمفردات (100k) والحالات الكامنة (256) وتم تدريبهم على نفس عدد العصور. لذلك ، فقط التغييرات النوعية في الهندسة المعمارية أو في المعالجة المسبقة يمكن أن تؤثر على النتيجة.
تعطي النماذج التي تم تكييفها للعمل مع النص الذي تمت معالجته مسبقًا نتائج أفضل من النماذج التي تعمل مع الكلمات. يعمل pg ثلاثة طبقات الذي يستخدم معلومات حول المواضيع والانعكاسات بشكل أفضل. عند استخدام أي pg ، يظهر أيضًا تحسن متوقع في جودة الرؤوس مقارنة بـ seq2seq ، مما يشير إلى الاستخدام المفضل للمؤشر عند إنشاء الرؤوس. فيما يلي مثال على تشغيل جميع الطرز:
بالنظر إلى الرؤوس التي تم إنشاؤها ، يمكننا التمييز بين المشكلات التالية والنماذج قيد الدراسة:
- غالبًا ما تستخدم النماذج أشكالًا غير منتظمة من الكلمات. النماذج مع السيقان (كما في المثال أعلاه) هي أكثر راحة من هذا العيب ؛
- يمكن لجميع النماذج ، باستثناء تلك التي تعمل مع السمات ، إنتاج رؤوس تبدو غير مكتملة ، أو تصميمات غريبة غير موجودة في اللغة (كما في المثال أعلاه) ؛
- غالبًا ما تخلط جميع النماذج المدروسة بين الأشخاص الموصوفين أو تستبدل التواريخ غير الصحيحة أو تستخدم كلمات غير مناسبة تمامًا.


تجارب مع الآيات
نظرًا لأن الصفحات ذات الطبقات الثلاثة تحتوي على أقل دقة في الرؤوس التي تم إنشاؤها ، فهذا هو النموذج الذي اخترته للتجارب مع الآيات. لقد علمتها في هذه القضية ، التي تتكون من 6 ملايين قصيدة روسية من موقع "stihi.ru". وتشمل الحب (حوالي نصف الآيات مكرسة لهذا الموضوع) ، المدنية (حوالي ربع) ، والشعر الحضري والمناظر الطبيعية. فترة الكتابة: يناير 2014 - مايو 2019. سأقدم أمثلة على العناوين التي تم إنشاؤها للآيات:
تبين أن النموذج يستخرج في الغالب: جميع الرؤوس تقريبًا عبارة عن سطر واحد ، وغالبًا ما يتم استخراجه من المقطع الأول أو الأخير. في حالات استثنائية ، يمكن للنموذج توليد كلمات غير موجودة في القصيدة. هذا يرجع إلى حقيقة أن عددًا كبيرًا جدًا من النصوص الموجودة في هذه الحالة يكون له بالفعل أحد الأسطر كاسم.
في الختام ، سأقول إن مولد الفهرس ، الذي يعمل على السيقان ويستخدم وحدة فك ترميز وشفرة أحادية الطبقة ، احتل المرتبة الثانية على
حلبة المنافسة من أجل توليد عناوين الأخبار للمقالات في مؤتمر الحوار العلمي حول اللغويات الحاسوبية "حوار". المنظم الرئيسي لهذا المؤتمر هو ABBYY ، تعمل الشركة في مجال البحوث في جميع المجالات الحديثة تقريبا من معالجة اللغات الطبيعية.
أخيرًا ، أقترح عليك بعض التفاعلات: أرسل الأخبار في التعليقات ، وانظر إلى الرؤوس التي ستولدها الشبكة العصبية لها.
Matvey ، مطور في NLP Group في ABBYY