عند استخراج المعلومات ، تنشأ المهمة غالبًا في العثور على أجزاء النص هذه. في سياق البحث ، يمكن إنشاء استعلام بواسطة المستخدم (على سبيل المثال ، النص الذي يدخله المستخدم في محرك البحث) أو عن طريق النظام نفسه. غالبًا ما نحتاج إلى مطابقة استعلام وارد مع استعلامات مفهرسة بالفعل. في هذه المقالة سنبحث في كيفية بناء نظام يحل هذه المشكلة فيما يتعلق بمليارات الطلبات دون إنفاق ثروة على البنية التحتية للخادم.
أولاً ، نعرّف المشكلة رسميًا:
إعطاء مجموعة ثابتة من الاستعلامات فدولا طلب وارد فدولا و عدد صحيح ك . تحتاج إلى العثور على مثل هذه المجموعة الفرعية من الاستفسارات R = \ left \ {q0 ، q1 ، ... ، qk \ right \} \ subset Q لكل طلب qi inR كان أشبه فدولا من أي طلب آخر في Q∖R .
على سبيل المثال ، مع هذه المجموعة من الاستعلامات
فدولا :
{tesla cybertruck, beginner bicycle gear, eggplant dishes, tesla new car, how expensive is cybertruck, vegetarian food, shimano 105 vs ultegra, building a carbon bike, zucchini recipes}
و
ك=3دولا يمكنك توقع هذه النتيجة:
يرجى ملاحظة أننا لم نحدد بعد معيار
التشابه . في هذا السياق ، يمكن أن يعني هذا أي شيء تقريبًا ، لكنه عادةً ما يأتي إلى شكل من أشكال التشابه استنادًا إلى الكلمات الأساسية أو المتجهات. باستخدام التشابه القائم على الكلمات الرئيسية ، يمكننا أن نجد استبيانين متشابهين إذا كانت تحتوي على كلمات شائعة كافية. على سبيل المثال ، تتشابه استعلامات "فتح مطعم في ميونيخ" و "أفضل مطعم في ميونيخ" لأنها تحتوي على الكلمتين "مطعم" و "ميونيخ". كما أن استفسارات "أفضل مطعم في ميونيخ" و "مكان لتناول الطعام في ميونيخ" أقل تشابهًا بالفعل ، نظرًا لوجود كلمة واحدة مشتركة بينهما. ومع ذلك ، فإن الشخص الذي يبحث عن مطعم في ميونيخ سيكون أفضل حالًا إذا تبين أن الزوج الثاني من الطلبات متشابه. وفي هذا سوف نساعد المقارنة على أساس ناقلات.
ناقلات تمثيل الكلمات
تمثيل المتجهات للكلمات هو أسلوب تعلم آلي يستخدم في معالجة اللغة الطبيعية لتحويل النص أو الكلمات إلى متجهات. بنقل المهمة إلى مساحة المتجهات ، يمكننا استخدام العمليات الرياضية مع المتجهات - جمع المسافات وحسابها. لتأسيس روابط بين الكلمات المتشابهة ، يمكنك استخدام الطرق التقليدية لتجميع الموجه. قد لا يكون
معنى هذه العمليات في مساحة الكلمات الأصلية واضحًا ، ولكن الميزة هي أنه أصبح بإمكاننا الآن الوصول إلى مجموعة واسعة من الأدوات الرياضية. إذا كنت مهتمًا بتفاصيل ناقلات الكلمات وتطبيقها ، فاقرأ عن
word2vec و
GloVe .
لدينا طريقة لإنشاء متجهات من الكلمات ، والآن سنقوم بجمعها في متجهات نصية (متجهات مستندات أو تعبيرات). أسهل طريقة للقيام بذلك هي إضافة (أو حساب) متجهات جميع الكلمات في النص.
 الشكل 1: ناقلات الاستعلام.
الشكل 1: ناقلات الاستعلام.يمكنك الآن تحديد تشابه قطعتين من النص (أو الاستعلامات) من خلال تمثيلهما في مساحة المتجه وحساب المسافة بين المتجهات. عادة ، يتم استخدام المسافة الزاوية لهذا الغرض.
نتيجة لذلك ، يتيح التمثيل المتجه للكلمات مطابقة نصية من نوع مختلف ، مما يكمل المطابقة القائمة على الكلمات الرئيسية. يمكنك استكشاف التشابه الدلالي للطلبات (على سبيل المثال ، "أفضل مطعم في ميونيخ" و "مكان لتناول الطعام في ميونيخ") ، كما لم نتمكن من القيام به من قبل.
البحث التقريبي الأقرب الجار
الآن يمكننا تحسين مشكلة مطابقة الاستعلام الأصلية الخاصة بنا:
إعطاء مجموعة ثابتة من ناقلات الاستعلام فدولا ناقلات واردة فدولا و عدد صحيح ك . تحتاج إلى العثور على مثل هذه المجموعة الفرعية من المتجهات R = \ left \ {q0 ، q1 ، ... ، qk \ right \} \ subset Q بحيث تكون المسافة الزاوية من فدولا لكل ناقل qi inR كان أقصر من المسافة إلى أي ناقل آخر في Q∖R .
وهذا ما يسمى مهمة العثور على أقرب جار. هناك
عدد من الخوارزميات لحلها السريع في المساحات منخفضة الأبعاد. ولكن عند العمل مع تمثيلات الكلمات الموجهة ، فإننا عادة ما نعمل مع متجهات عالية الأبعاد (100-1000 بعدًا). وهنا الأساليب المذكورة لم تعد تعمل.
لا توجد طريقة مناسبة لتحديد أقرب الجيران بسرعة في المساحات عالية الأبعاد. لذلك ، نقوم بتبسيط المشكلة من خلال السماح باستخدام نتائج تقريبية: بدلاً من إرجاع أقرب المتجهات دائمًا ، سنكون راضين فقط عن
بعض الجيران الأقرب أو
إلى حد ما القريبين. وهذا ما يسمى البحث التقريبي لأقرب مهمة الجيران وهو مجال البحث النشط.
العالم الهرمي الصغيرة
يعد الرسم البياني للعالم الصغير ذي التسلسل الهرمي (
HNSW ) أحد أسرع الخوارزميات للبحث التقريبي لأقرب الجيران. مؤشر البحث في HNSW هو هيكل متعدد المستويات يكون فيه كل مستوى رسم بياني قرب. يتوافق كل عقدة الرسم البياني مع أحد متجهات الاستعلام.
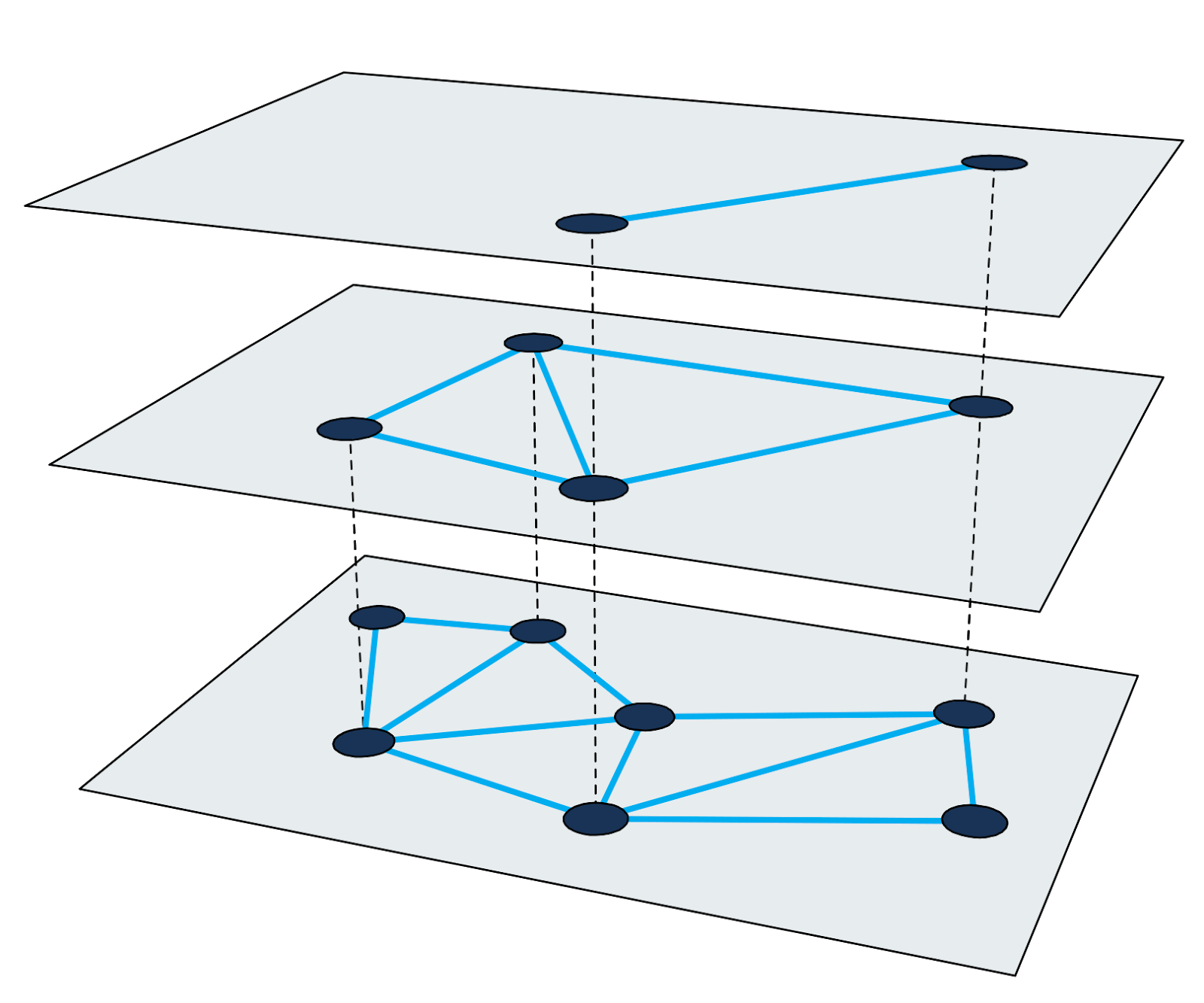 الشكل 2: الرسم البياني القرب متعدد المستويات.
الشكل 2: الرسم البياني القرب متعدد المستويات.البحث عن أقرب الجيران في HNSW يستخدم طريقة التكبير. يبدأ في عقدة الإدخال من أعلى مستوى ويقوم بشكل متكرر اجتياز الرسم البياني الجشع في كل مستوى حتى يصل إلى الحد الأدنى المحلي في الأسفل.
يتم وصف تفاصيل حول الخوارزمية وتقنية البحث بشكل جيد في العمل العلمي. من المهم أن تتذكر أن كل دورة بحث لأقرب الجيران تتكون من اجتياز عقد الرسوم البيانية مع حساب المسافات بين المتجهات. سننظر في هذه الخطوات أدناه لاستخدام هذه الطريقة لإنشاء فهرس واسع النطاق.
صعوبة فهرسة مليارات الاستعلامات
لنفترض أننا بحاجة إلى فهرسة 4 مليارات من متجهات الاستعلام ذات الأبعاد ، مع تمثيل كل بُعد برقم الفاصلة العائمة المكون من أربعة بايت (يكفي 4 مليارات لجعل المهمة ممتعة ، ولكن لا يزال بإمكانك تخزين معرّفات العقدة بأرقام أربعة بايت منتظمة) . يخبرنا حساب تقريبي أن حجم المتجهات وحدها سيكون حوالي 3 تيرابايت. نظرًا لأن معظم المكتبات الحالية تستخدم سعة ذاكرة الوصول العشوائي لإجراء بحث تقريبي لأقرب الجيران ، فسوف نحتاج إلى خادم كبير جدًا لدفع ما لا يقل عن المتجهات إلى ذاكرة الوصول العشوائي. يرجى ملاحظة أن هذا لا يأخذ في الاعتبار فهرس البحث الإضافي ، وهو أمر ضروري لمعظم الطرق.
في التاريخ الكامل لتطوير محرك البحث الخاص بنا ، استخدمنا عدة طرق مختلفة لحل هذه المشكلة. دعونا نفكر في بعضهم.
مجموعة فرعية من البيانات
الطريقة الأولى والأبسط ، التي لم تسمح لنا بحل المشكلة تمامًا ، كانت الحد من عدد المتجهات في الفهرس. أخذ عُشر البيانات ، أنشأنا فهرسًا يحتاج - مفاجأة - إلى 10٪ من الذاكرة. ومع ذلك ، فقد تدهورت جودة البحث ، لأننا نعمل الآن مع عدد أقل من الاستفسارات.
تكميم
استخدمنا جميع البيانات هنا ، لكننا
قللناها باستخدام
القياس الكمي (استخدمنا تقنيات القياس الكمي المختلفة ، على سبيل المثال ، تقدير كميات المنتجات ، لكننا لم نتمكن من تحقيق الجودة المطلوبة للعمل مع هذه الكمية من البيانات). عن طريق تقريب بعض الأخطاء ، تمكنا من استبدال جميع الأرقام الأربعة بايت في المتجهات الأصلية بإصدارات أحادية البايت. انخفضت كمية ذاكرة الوصول العشوائي للمتجهات بنسبة 75 ٪. ومع ذلك ، ما زلنا بحاجة إلى 750 غيغابايت من الذاكرة (لا نحسب حجم الفهرس نفسه) ، وهذا لا يزال خادمًا كبيرًا للغاية.
حل مشاكل الذاكرة مع Granne
كان للنُهج الموصوفة مزاياها ، ولكنها تتطلب الكثير من الموارد وتعطي جودة بحث رديئة. على الرغم من
وجود مكتبات تستجيب في أقل من 1 مللي ثانية ، إلا أننا نستطيع التضحية بالسرعة مقابل متطلبات الأجهزة الأقل.
Granne (يعتمد على الرسم البياني التقريبي لأقرب الجيران) هي مكتبة HNSW تم تطويرها واستخدامها من قبل Cliqz للبحث عن مثل هذه الاستعلامات. لديها شفرة مفتوحة المصدر ، لكن المكتبة لا تزال قيد التطوير النشط. سيتم نشر نسخة محسنة على موقع
crates.io في عام 2020. هو مكتوب في روست مع إدراج بايثون ، والمصممة للتعامل مع مليارات من ناقلات باستخدام القدرة التنافسية. من وجهة نظر متجهات الاستعلام ، من المثير للاهتمام أن Granne لديه وضع خاص يتطلب ذاكرة أقل بكثير مقارنة بالمكتبات الأخرى.
تمثيل مضغوط لمتجهات الاستعلام
تخفيض حجم ناقلات الاستعلام سوف يعطينا العديد من الفوائد. للقيام بذلك ، دعنا نعود ونفكر في إنشاء متجهات. نظرًا لأن الاستعلامات تتكون من الكلمات وأن متجهات الاستعلام هي عبارة عن متجهات للكلمات ، يمكننا رفض صراحة تخزين متجهات الاستعلامات وحسابها عند الضرورة.
يمكنك تخزين الاستعلامات في شكل مجموعات كلمات واستخدام جدول البحث للعثور على المتجهات المقابلة. ومع ذلك ، نتجنب إعادة التوجيه عن طريق تخزين كل استعلام كقائمة من معرفات عدد صحيح المطابقة للكلمات الاتجاهية في الاستعلام. على سبيل المثال ، احفظ الاستعلام "best restaurant of munich" as
[ibest،irestaurant،iof،imunich] حيث
ibest - هذا هو معرف المتجه للكلمة "أفضل" ، إلخ. لنفترض أن لدينا أقل من 16 مليون متجه كلمة (أكثر من هذا سيكلف 1 بايت لكل كلمة) ، ثم يمكنك استخدام 3 بايت لتمثيل جميع معرفات الكلمات. أي أنه بدلاً من تخزين 800 بايت (أو 200 بايت في حالة المتجهات الكمية) ، سنقوم فقط بتخزين 12 بايت لهذا الطلب (هذا غير صحيح تمامًا. نظرًا لأن الطلبات تتكون من عدد مختلف من الكلمات ، نحتاج أيضًا إلى تخزين إزاحة القائمة في فهرس الكلمات. هذا سوف يتطلب 5 بايت لكل طلب).
أما بالنسبة لناقلات الكلمة ، فنحن جميعًا بحاجة إليها. ومع ذلك ، فإن عدد الكلمات أصغر بكثير من عدد الاستعلامات التي يمكن إنشاؤها من خلال الجمع بين هذه الكلمات. وهذا يعني أن حجم الكلمات ليس مهمًا جدًا. إذا قمت بتخزين متجهات الكلمات كإصدارات نقطة عائمة أربعة بايت في صفيف بسيط
v ، نحن بحاجة إلى أقل من 1 غيغابايت لكل مليون كلمة. يمكن أن يصلح هذا الحجم بسهولة في ذاكرة الوصول العشوائي. الآن يبدو متجه الاستعلام كما يلي:
{v _ {{i_ {best}}} + + {v _ {{i_ {restaurant}}} + + {v _ {{i_ {of}}} + + {v _ {{i_ {munich}}}} .
يعتمد الحجم النهائي لإرسال الاستعلام على إجمالي عدد الكلمات في الاستعلام. بالنسبة إلى 4 مليارات استفسار ، يكون هذا حوالي 80 جيجابايت (بما في ذلك متجهات الكلمات). بمعنى آخر ، بالمقارنة مع متجهات الكلمات الأصلية ، انخفض الحجم بنسبة 97 ٪ ، ومقارنة مع المتجهات الكمية - بنسبة 90 ٪.
وأكثر شيء واحد. للبحث واحد ، نحن بحاجة إلى زيارة ما يقرب من 200-300 العقد من الرسم البياني. كل عقدة لديها 20-30 الجيران. لذلك ، نحن بحاجة إلى حساب المسافة من متجه استفسار الإدخال إلى 4000-9000 متجه في الفهرس. وما هو أكثر من ذلك ، نحن بحاجة إلى توليد ناقلات. كم من الوقت يستغرق إنشاء متجهات الاستعلام على الطاير؟
اتضح أنه مع معالج جديد إلى حد ما ، يمكن حل هذه المشكلة في بضع ميلي ثانية. الطلب الذي كان يعمل للتشغيل في 1 مللي ثانية يعمل الآن في حوالي 5 مللي ثانية. ولكن بعد ذلك قمنا بتقليل مقدار الذاكرة للمتجهات بنسبة 90٪. قبلنا بكل سرور مثل هذا الحل الوسط.
عرض في ذكرى ناقلات والفهرس
أعلاه ، قمنا بحل مشكلة تقليل مقدار الذاكرة للمتجهات. ولكن بعد حل هذه المشكلة ، أصبح هيكل الفهرس نفسه عاملاً محددًا. الآن تحتاج إلى تقليل حجمها.
في Granne ، يتم تخزين بنية الرسم البياني بشكل مضغوط في شكل قائمة مجاورة مع عدد متغير من الجوار لكل عقدة. وهذا هو ، بالكاد يضيع الذاكرة على البيانات الوصفية. يعتمد حجم بنية الفهرس إلى حد كبير على معلمات التصميم وخصائص الرسم البياني. ومع ذلك ، للحصول على فكرة عن حجم الفهرس ، يكفي القول أنه يمكننا بناء فهرس لأربعة مليارات من المتجهات بحجم إجمالي يبلغ حوالي 240 جيجابايت. قد يكون هذا مقبولًا للاستخدام في الذاكرة على خادم كبير ، ولكن يمكن القيام به بشكل أفضل.
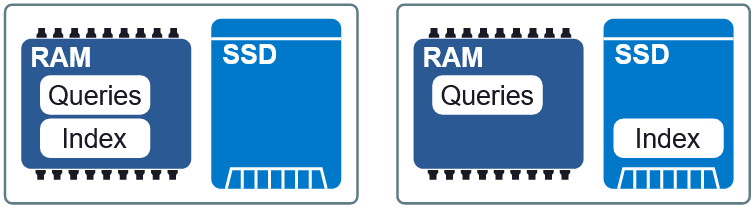 الشكل 3: تخطيطان مختلفان في RAM و SSD.
الشكل 3: تخطيطان مختلفان في RAM و SSD.خاصية مهمة من Granne هي القدرة على
عرض الفهرس والاستعلام عن المتجهات
في الذاكرة . هذا يتيح لنا تحميل الفهرس بتكاسل ومشاركة الذاكرة مع عمليات متعددة. يتم تقسيم ملفات الفهرس والاستعلام إلى ملفات عرض منفصلة في الذاكرة ويمكن استخدامها في تخطيطات مختلفة في RAM وعلى SSD. إذا كانت متطلبات التأخير أقل قليلاً ، ثم وضع الفهرس على SSD ، طلبات الوصول إلى ذاكرة الوصول العشوائي ، فإننا نحافظ على سرعة مقبولة دون استهلاك مفرط للذاكرة. في نهاية المقال سنرى كيف يبدو هذا الحل الوسط.
تحسين محلية البيانات
في التهيئة الحالية ، عندما يكون الفهرس على SSD ، يتطلب كل طلب ما يصل إلى 200-300 قراءة من القرص. يمكنك محاولة زيادة مكان البيانات عن طريق ترتيب العناصر التي تكون متجهاتها قريبة جدًا بحيث توجد عقد HNSW الخاصة بها في الفهرس أيضًا ، وهي ليست بعيدة عن بعضها البعض. تعمل موضع البيانات على تحسين الأداء ، لأن عملية القراءة الواحدة (عادة ما يتم استخراجها من 4 كيلوبايت) من المرجح أن تحتوي على العقد الأخرى اللازمة لاجتياز الرسم البياني. وهذا بدوره يقلل من عدد استرجاع البيانات لكل عملية بحث واحدة.
 الشكل 4: محل البيانات يقلل من استرجاع المعلومات.
الشكل 4: محل البيانات يقلل من استرجاع المعلومات.تجدر الإشارة إلى أن إعادة ترتيب العناصر لا تؤثر على نتائج البحث ، فهذه طريقة لتسريعها. وهذا يعني أن الترتيب يمكن أن يكون موجودًا ، ولكن ليس كل خيار سيسرع البحث. من الصعب جدًا العثور على الترتيب الأمثل. ومع ذلك ، فإن الاستدلال الذي استخدمناه بنجاح هو فرز الاستعلامات حسب الكلمة الأكثر
أهمية في كل استعلام.
استنتاج
نحن نستخدم Granne لإنشاء وصيانة فهارس بمليارات الدولارات باستخدام متجهات الاستعلام من أجل البحث عن استعلامات مماثلة مع انخفاض استهلاك الذاكرة نسبيًا. يوضح الجدول أدناه متطلبات الطرق المختلفة. كن متشككا في القيم المطلقة للتأخيرات أثناء البحث ، لأنها تعتمد بشدة على ما يعتبر استجابة مقبولة. ومع ذلك ، تصف هذه المعلومات الأداء النسبي للطرق.
* تخصيص فهرس ذاكرة أكبر من الكمية المطلوبة أدى إلى التخزين المؤقت لبعض العقد (كثيرا ما زار) ، مما قلل من التأخير في البحث. لم يتم استخدام ذاكرة التخزين المؤقت الداخلية لهذا ، فقط أدوات OS الداخلية (Linux kernel).تجدر الإشارة إلى أن بعض التحسينات المذكورة في المقالة لا تنطبق على حل المشكلة العامة المتمثلة في العثور على أقرب الجيران مع ناقلات غير قابلة للتحلل. ومع ذلك ، فهي قابلة للتطبيق في أي مواقف حيث يمكن إنشاء عناصر من أجزاء أقل (كما هو الحال مع الكلمات والاستعلامات). خلاف ذلك ، لا يزال بإمكانك استخدام Granne مع متجهات المصدر ، حيث يستغرق الأمر المزيد من الذاكرة ، كما هو الحال مع المكتبات الأخرى.