مرحباً هبر!
الائتمان المنزلي هو نظام كبير وديناميكي للغاية ، والذي يصعب في بعض الأحيان تتبعه. لمساعدة الموظفين على مواكبة جميع الأخبار والتغييرات ومواكبة كل مكان ، نحن نقدم بنشاط خوارزميات التعلم الآلي. في مصرفنا ، تأخذ برامج الدردشة بالفعل جزءًا من عمل المشغلين ، ويتم تحليل مراجعات العملاء ليس فقط من قبل الخبراء ، ولكن أيضًا عن طريق الخوارزميات الذكية لمعالجة اللغة الطبيعية.
سأخبرك اليوم كيف ساعدنا متخصصي عمليات الخدمات المصرفية في التخلص من الحاجة إلى النظر باستمرار إلى لوحات معلومات أنظمة المراقبة ، أي أنهم طالبوا بالتعلم الآلي للمساعدة. هذا ما حصلنا عليه.

كيف تعمل المراقبة اليدوية؟
يشبه الصورة أعلاه مكان عمل نموذجي لأحد أخصائي التشغيل ، ويقضي معظم وقته في النظر إلى لوحات المعلومات. أي نشاط مشبوه في النظام ، على سبيل المثال ، عندما تسقط الشبكة أو تمطر NullPointerException ، سوف يجذب الانتباه على الفور - سيبدأ التحقيق على الفور.
الرجل ليس سيارة. يمكن أن يصرف انتباهه ، ويذهب لتناول العشاء ، والرد على الهاتف. وعندما يتجاوز عدد الرسوم البيانية مائة ، يصبح من الصعب ربطها معًا والوصول إلى جوهرها.
مشكلة أخرى هي أن هناك مجموعة من الأخطاء التي تحدث باستمرار ، ولكن لا تؤثر بشكل خطير على سلوك النظام. على سبيل المثال ، سقطت خدمة micros لجهة خارجية وصدمت لوحات المعلومات بشكل ملحوظ ، لكن في الواقع النظام خارج الخطر. للوهلة الأولى ، ليس من الواضح دائمًا مدى أهمية السلوك غير الطبيعي وما وراءه. لتحديد الأسباب بالتفصيل ، تحتاج إلى الانتقال إلى الخادم والتعمق في السجلات. مثل هذه العملية يجب أن تتم عشرات المرات في اليوم. دعونا على الأقل يعهد بها جزئيًا إلى السيارة.
تعلم الآلة كمساعد ذكي
هناك ثلاثة مصادر رئيسية للبيانات: Zabbix و ElasticSearch ونظام مراقبة مقاييس العمل الداخلية. نستخدم Zabbix لمراقبة الأجهزة والشبكة وتوافر نقاط الدخول المختلفة في الأنظمة. باستخدام ElasticSearch ، تحليل واستخراج سجل الرسائل. يتم استخدام العديد من الأخطاء وعمليات الإعدام والاستعلامات كمقاييس. ومع ذلك ، يراقب محللو الأعمال أداء المستخدمين: عدد عمليات النقل والمبيعات والأنشطة التجارية الأخرى. يتم جمع البيانات بتردد مرة واحدة في الدقيقة وإضافتها إلى قاعدة البيانات. حسنًا ، يتم جمع البيانات ، لقد حان الوقت لكتابة مجموعة من if لوضع التعلم الآلي في المعركة.
نقوم بصياغة المشكلة على النحو التالي: عند وجود مقاييس النظام عند الإدخال ، سنقوم بتصنيف الحالة النهائية للنظام: عادية أو غير طبيعية. في هذا الإعداد ، تتناسب المشكلة تمامًا مع نموذج التعلم مع المعلم. هذا يعني أنه يجب تصنيف مجموعة بيانات التدريب الخاصة بنا بأكملها. بمعنى آخر ، يجب أن يكون لكل دقيقة من تشغيل النظام تسمية 0 (سلوك عادي) أو -1 (سلوك غير طبيعي).
في الحياة ، اتضح أنه ليس كل شيء وردية كما نود. كقاعدة عامة ، لا يتم تسجيل جميع الحوادث في JIRA ، ويبقى الكثير في البريد ولا يتجاوزها ، وأحيانًا تكون الحدود الزمنية للشذوذ غير واضحة أو غير دقيقة. اتضح أن بناء مجموعة بيانات عالية الجودة في مجال البيانات التاريخية ليست مهمة تافهة.
على الرغم من أن البيانات الجديدة بدأت للتو في التوضيح ، فلنحاول الضغط على الاستفادة مما لدينا بالفعل. في الحالات التي لا تحتوي فيها البيانات على علامة ، يتم استخدام خوارزميات التعلم بدون معلم. سوف ننطلق من حقيقة أن النظام يعمل في معظم الأوقات بشكل صحيح ، ولكن في بعض الأحيان تحدث أحداث غير متوقعة: الأخطاء (حيث بدونها) ، سقطت القاعدة ، أو على سبيل المثال ، ضرب حفارة Petr كبل مركز البيانات. لذلك ، فنحن نختصر مهمتنا في البحث عن الحالات الشاذة ، أي البحث عن سلوك نظام جديد (الكشف عن الجدة).
للقيام بذلك ، استخدم خوارزمية الغابة المعزولة. تم تنفيذه بالفعل في مكتبة sklearn. سوف نستخدم مقاييس من أنظمة المراقبة كميزات.
clf = IsolationForest(behaviour='new', max_samples=100, random_state=rng, contamination='auto')
سنقوم بتدريب Isolated Forest على البيانات التاريخية ، وسنستخدم البيانات الجديدة التي تمكنا بالفعل من ترميزها لتقييم الجودة. وبالتالي ، يبقى اختيار معلمات النماذج الفائقة وحجم مجموعة البيانات للتدريب.
الآن بيانات الحالة ، التي يتم جمعها كل دقيقة ، هي المدخلات إلى النموذج المدربين والحصول على التسمية 0 أو -1.
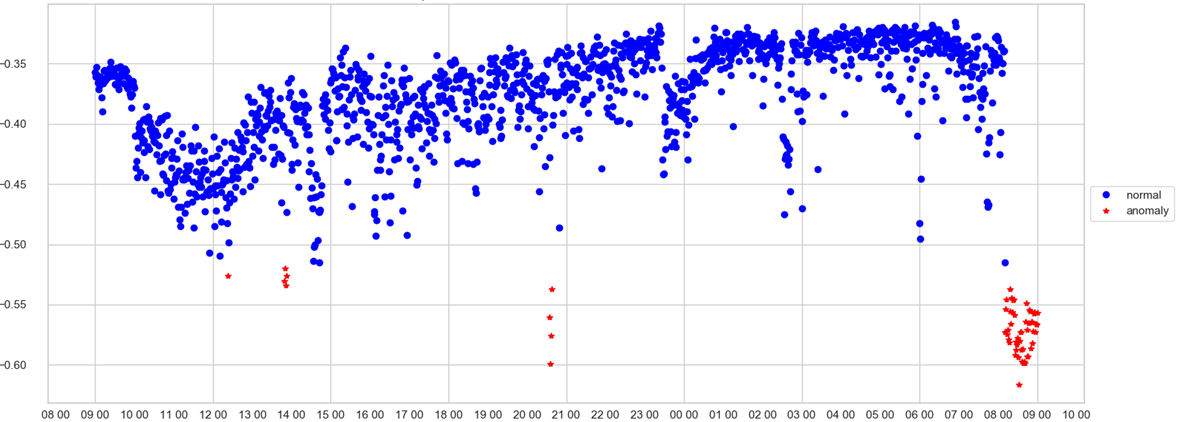
يمكن للمشغل تتبع جدول واحد فقط. على المحور X - الوقت ، على درجة Y - الشذوذ ، أي مدى قوة النموذج في النظر إلى حالة النظام في هذه اللحظة غير الطبيعية. إذا مرت قيمة السرعة من خلال trashhold (التي يختارها النموذج بنفسه) ، تكون النقطة مظللة باللون الأحمر ويتم تسجيل حالة شاذة.
نعلم الآن أن النظام يعمل في وضع غير عادي أو أن حالة الطوارئ حدثت في الوقت الفعلي تقريبًا. هذا جميل جداً ، لكن ماذا عن المشغل في وقت تلقي الإشارة حول الشذوذ؟ ما لوحة القيادة للنظر في؟ دعونا نحاول فتح "الصندوق الأسود" لنموذجنا وفهم كيف يتخذ القرارات.
تفسير نموذج باستخدام LIME
هناك طرق مختلفة لكيفية فتح الصندوق الأسود لنموذج مدرب وفهم ما يدور في أذهان الآلة. مع الانحدار اللوجستي أو شجرة القرار ، كل شيء واضح ، ليس من الصعب فهمه على أساس القرار الذي تم اتخاذه. مع غابة معزولة ، الأمور أكثر تعقيدًا. أولاً ، يوجد حادث داخل الخوارزمية ، وثانياً ، خوارزمية تعلم بدون معلم.
كان المرشح الأول هو مكتبة LIME ، التي تستخدم النهج اللاأدري للنموذج ، والذي يساعد على تفسير أي نماذج ، والشيء الرئيسي هو أن ناتج النموذج له توزيع احتمالي بين الفصول. حسنًا ، بالطبع ، النتيجة ليست احتمالًا ، لكن قريبًا ، لكن دعونا نحاول تطبيعها في النطاق من 0 إلى 1 ونعاملها على أنها احتمال. وبالتالي ، تمكنا من توفير تنسيق إدخال متوافق مع LIME.
الطريقة التي فسر بها LIME النتائج كانت مخيبة للآمال. أولاً ، كتفسير ، كان هناك العديد من العلامات الأكثر أهمية في المخرجات ، وفي معظم الحالات ، واحدة منها فقط تعكس بشكل كافٍ جوهر القرار ، وأضاف الباقي ضوضاء. العيب الثاني هو أن التفسير كان غير مستقر وغالبا ما كان ينتج قوائم مختلفة من العلامات من المدى إلى الركض. للحصول على نتائج أكثر استقرارًا ، كان عليك تشغيل التفسير عدة مرات ومتوسط النتائج بطريقة أو بأخرى. لم أرغب حقًا في القيام بذلك.
SHAP - جسر من شخص لآخر
بعد ذلك ، سقطت أعيننا على مكتبة أخرى لتفسير النماذج - SHAP. جاءت الفكرة وراء المكتبة من نظرية اللعبة. المكتبة لديها أيضا تصور جميل. بعد النظر إلى الأمثلة ، أدركنا بإحباط أن SHAP لا تستطيع تفسير غابة معزولة ، وأردنا حقًا! ولكن ، من ناحية أخرى ، يمكن SHAP تشريح بثقة XGBoost. كنا نظن ، ماذا لو تعلمنا أن نفعل XGBoost نفس الشيء الذي يمكن أن تفعله الغابات المعزولة؟ للقيام بذلك ، اتخذنا مجموعة البيانات الخاصة بنا بأكملها ووضعنا علامة عليها مع الغابات المعزولة. علاوة على ذلك ، كهدف لم يأخذوا فئة ، ولكن سجل ، الذي تم تعيينه للغابات المعزولة. سوف نتنبأ بكل المقاييس بالسرعة التي ستقدمها الغابات المعزولة ، ولكن فقط مع XGBoot! لم يقل قال من القيام به. سنقوم بتشغيل مجموعة البيانات الموسومة الخاصة بنا من خلال XGBoost. والآن ، يعرف الآن كيف يتنبأ بالسرعة بنفس طريقة غابة معزولة. الصيحة ، الآن يمكننا استخدام SHAP!
الخطوة الأولى هي إنشاء كائن TreeExplainer ، بتمرير النموذج نفسه كمعلمة. بعد ذلك ، يتم حساب قيم الأشكال ، والتي تسمح لنا بتقديم شرح لكيفية اتخاذ النموذج لهذا القرار أو ذاك.
explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X)
يتيح لك SHAP تفسير النموذج ككل والنتائج المتعلقة بأمثلة محددة. على سبيل المثال ، يمكنك الحصول على شرح لمثال محدد باستخدام طريقة force_plot () ، التي تتلقى قيم الإدخال وقيم المثال نفسه.
shap.force_plot(explainer.expected_value,shap_values[0,:], X.iloc[0,:])
اتضح الرسم البياني التالي ، الذي يعرض ميزات النموذج ومدى تأثير القرار.

نحن نساعد العمل
الآن ، ومعرفة المقاييس التي ساهمت بشكل كبير في المعدل الإجمالي للخلل ، يصبح من الممكن تحديد المستوى الذي نشأت فيه المشكلة ، والأهم من ذلك ما إذا كان لها تأثير على المستخدمين النهائيين للنظام.

في كل مرة يتم فيها اكتشاف حالة شاذة ، يتم الحصول على قائمة المقاييس التي لها أكبر تأثير على القرار. إذا كانت القائمة تحتوي على مقاييس تتبع مباشرة المؤشرات المتعلقة بالأعمال ، فسيتم ذكر ذلك في التنبيه بطريقة خاصة ، وبالتالي زيادة أولوية الشذوذ تلقائيًا.
هذه ليست سوى الخطوة الأولى ولكن المهمة في تعزيز وأتمتة نظام المراقبة باستخدام التعلم الآلي ، والتي يمكن أن تزيد بشكل كبير من سرعة تحديد أسباب وتأثير سلوك النظام غير الطبيعي.
المراجع:scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.htmlgithub.com/marcotcr/limegithub.com/slundberg/shap