 مصدر
مصدرمرحبا يا هبر! اسمي Maxim Pchelin ، وأقود تطوير BI-DWH في MyGames (قسم الألعاب في Mail.ru Group). في هذه المقالة سوف أتحدث عن كيف ولماذا قمنا ببناء وحدة تخزين DataLake موجهة نحو العميل.
المقالة تتكون من ثلاثة أجزاء. أولاً ، سأشرح لماذا قررنا تطبيق DataLake. في الجزء الثاني سوف أصف التقنيات والحلول التي نستخدمها حتى يعمل التخزين ويمكن أن يملأ بالبيانات. وفي الجزء الثالث سوف أصف ما نقوم به لتحسين جودة خدماتنا.
ما الذي أوصلنا إلى DataLake
نحن في
MyGames نعمل في قسم BI-
DWH ونقدم خدمات لفئتين: مستودع لمحللي البيانات وخدمات التقارير المنتظمة لمستخدمي الأعمال (المديرين والمسوقين ومطوري الألعاب وغيرهم).
لماذا هذا التخزين غير قياسي؟
عادةً ، لا يعني BI-DWH تنفيذ تخزين DataLake ؛ لا يمكن أن يسمى هذا حلاً نموذجيًا. وكيف يتم بناء هذه الخدمات؟
عادة ما يكون لدى الشركة مشروع - في حالتنا ، هذه لعبة. يحتوي المشروع على نظام تسجيل يقوم غالبًا بكتابة البيانات إلى قاعدة البيانات. في الجزء العلوي من هذه القاعدة ، يتم إنشاء واجهات المتاجر للمجاميع والمقاييس والكيانات الأخرى للتحليلات المستقبلية. يتم إعداد التقارير المنتظمة ، بالإضافة إلى أنظمة تحليل Ad-Hoc ، بدءًا من استعلامات SQL وجداول Excel البسيطة ، والتي تنتهي بـ Jupyter Notebook لـ DS و ML ، على أساس واجهات المتاجر باستخدام أي أداة BI مناسبة. يدعم النظام بأكمله فريق تطوير واحد.
لنفترض أن شركة أخرى ولدت في شركة. وجود فريق تطوير وبنية تحتية أخرى أمر جذاب ، لكنه مكلف. لذلك ، يحتاج المشروع إلى "التوصيل". يمكن القيام بذلك بطرق مختلفة: على مستوى قاعدة البيانات ، على مستوى واجهة المتجر ، أو على الأقل على مستوى العرض - تم حل المشكلة.
وإذا كانت الشركة لديها مشروع ثالث؟ "المشاركة" قد تنتهي بالفعل بشكل سيئ: قد تكون هناك مشاكل في تخصيص الموارد أو حقوق الوصول. على سبيل المثال ، يتم تنفيذ أحد المشاريع بواسطة فريق خارجي لا يحتاج إلى معرفة أي شيء عن المشروعين الأولين. الوضع أصبح أكثر خطورة.
الآن تخيل أنه لا يوجد ثلاثة مشاريع ، ولكن أكثر من ذلك بكثير. وحدث أن هذا هو حالنا بالضبط.
MyGames هي واحدة من أكبر أقسام Mail.ru Group ، لدينا 150 مشروعًا في محفظتنا. علاوة على ذلك ، فهي مختلفة تمامًا: تنميتها وشرائها للعمليات في روسيا. وهي تعمل على منصات مختلفة: أجهزة الكمبيوتر الشخصية وأجهزة Xbox و Playstation و iOS و Android. تم تطوير هذه المشاريع في عشرة مكاتب حول العالم مع مئات من صانعي القرار.

بالنسبة للأعمال ، يعد هذا أمرًا رائعًا ، ولكنه يعقد المهمة بالنسبة لفريق BI-DWH.
في ألعابنا ، يتم تسجيل الكثير من تصرفات اللاعب: عندما دخل اللعبة ، وأين وكيف حصل على المستويات ، ومع من وكيف نجح في القتال ، ولماذا وبأي عملة اشتراها. نحن بحاجة إلى جمع كل هذه البيانات لكل الألعاب.
نحتاج إلى ذلك حتى يتمكن العمل من تلقي إجابات لأسئلته حول المشاريع. ماذا حدث الأسبوع الماضي بعد إطلاق الحدث؟ ما هي توقعاتنا للإيرادات أو استخدام قدرات خادم اللعبة للشهر القادم؟ ما الذي يمكن عمله للتأثير على هذه التوقعات؟
من المهم ألا تفرض MyGames نموذجًا للتطوير على المشروعات. يسجل كل استوديو للألعاب البيانات لأنه يعتبرها أكثر فاعلية. تقوم بعض المشروعات بإنشاء سجلات من جانب العميل ، وبعضها من جانب الخادم. تستخدم بعض المشروعات RDBMS لجمعها ، بينما يستخدم البعض الآخر أدوات مختلفة تمامًا: Kafka أو Elasticsearch أو Hadoop أو Tarantool أو Redis. وننتقل إلى هذه المصادر للبيانات من أجل تحميلها على المستودع.
ماذا تريد من BI-DWH لدينا؟
أولاً وقبل كل شيء ، من قسم BI-DWH ، يريدون تلقي بيانات عن جميع الألعاب لحل المهام التشغيلية اليومية والمهام الإستراتيجية. بدءاً من عدد الأرواح لإعطاء وحش رهيب في نهاية المستوى ، وينتهي بكيفية توزيع الموارد بشكل صحيح داخل الشركة: أي المشاريع ينبغي أن تعطي المزيد من المطورين أو الذين يجب عليهم تخصيص ميزانية تسويقية.
ومن المتوقع أيضا موثوقية منا. نحن نعمل في شركة كبيرة ولا يمكننا أن نلتزم بمبدأ "بالأمس عملنا ، لكن النظام اليوم قائم ولن يرتفع إلا بعد أسبوع إذا توصلنا إلى شيء ما."
انهم يريدون مدخرات منا. سنكون سعداء لحل جميع المشاكل عن طريق شراء الحديد أو استئجار الناس. لكننا منظمة تجارية ولا يمكننا تحمل كلفتها. نحاول تحقيق ربح الشركة.
الأهم من ذلك ، أنهم يريدون التركيز على العملاء منا. العملاء في هذه الحالة هم عملائنا ، العملاء: المديرون ، المحللون ، وما إلى ذلك. يجب علينا أن نتكيف مع ألعابنا وأن نعمل بطريقة ملائمة للعملاء للتعاون معنا. على سبيل المثال ، في بعض الحالات ، عندما نشتري مشاريع في السوق الآسيوية للعمليات ، إلى جانب اللعبة ، يمكننا الحصول على قواعد بأسماء باللغة الصينية. والوثائق لهذه القواعد باللغة الصينية. يمكن أن نبحث عن مطور ETL مع معرفة باللغة الصينية أو نرفض تنزيل البيانات على اللعبة ، ولكن بدلاً من ذلك ، أقفل الفريق وأنا أنفسنا في غرفة الاجتماعات ، ونقضي الوقت ونبدأ اللعب. دخول والخروج من اللعبة ، وشراء ، واطلاق النار ، ويموت. ونحن ننظر ، ماذا ومتى يظهر في هذا الجدول أو ذاك. ثم نكتب الوثائق وعلى أساسها نبني ETL.
في هذه الحالة ، من المهم أن تشعر بالحافة. يعد التعمق في التسجيل الفريد للعبة مع DAU من 50 شخصًا ، عندما تحتاج إلى مساعدة في مشروع مع DAU من 500000 قريب ، ترفًا غير مقبول. لذلك ، بالطبع ، يمكننا أن نبذل الكثير من الجهد في بناء حل مخصص ، ولكن فقط إذا كانت الأعمال بحاجة إليه بالفعل.
ومع ذلك ، بمجرد أن يسمع المطورون ، وخاصة المبتدئين ، أنه سيتعين عليهم التكيف بهذه الطريقة ، فإن لديهم الرغبة في عدم القيام بذلك أبدًا. يريد أي مطور إنشاء بنية مثالية ، ولا يغيرها أبدًا ويكتب مقالات عنها حول Habr.
ولكن ماذا يحدث إذا توقفنا عن التكيف مع ألعابنا؟ لنفترض أننا بدأنا نطلب منهم إرسال البيانات إلى واجهة برمجة تطبيقات إدخال واحد؟ ستكون النتيجة واحدة - سيبدأ الجميع بالتشتت.
- ستبدأ بعض المشروعات في خفض حلول BI-DWH ، مع تفضيل وشاعرات. سيؤدي ذلك إلى ازدواجية الموارد وصعوبات في تبادل البيانات بين النظم.
- لن تسحب المشاريع الأخرى إنشاء BI-DWH ، لكنها لن ترغب في التكيف مع مشروعنا أيضًا. وسيظل الآخرون يتوقفون عن استخدام البيانات ، وهو أمر أسوأ.
- حسنًا ، والأهم من ذلك ، لن يكون لدى الإدارة معلومات منتظمة حديثة حول ما يحدث في المشاريع.
هل يمكننا تنفيذ التخزين بطريقة بسيطة؟
150 مشروعا الكثير. تنفيذ الحل فورًا للجميع طويل جدًا. لن تنتظر الشركة عامًا حتى تظهر النتائج الأولى. لذلك ، أخذنا 3 مشاريع تحقق أقصى قدر من الإيرادات ، ونفّذ أول نموذج لها. لقد أردنا جمع البيانات الأساسية منها وإنشاء لوحات معلومات أساسية باستخدام المقاييس الأكثر شيوعًا - DAU و MAU والإيرادات والتسجيلات والاحتفاظ بها ، بالإضافة إلى القليل من الاقتصاد والتنبؤات.
لم نتمكن من استخدام قواعد اللعبة للمشاريع نفسها لهذا الغرض. أولاً ، من شأن ذلك أن يجعل تحليل التصميم المتقاطع أكثر صعوبة بسبب الحاجة إلى تجميع البيانات من عدة قواعد بيانات. ثانياً ، تعمل الألعاب نفسها على قمة قواعد البيانات هذه ، وهو أمر مهم حتى لا يتم تحميل البيانات الرئيسية والنسخ المتماثلة بشكل زائد. أخيرًا ، تحذف جميع الألعاب في مرحلة ما جميع محفوظات البيانات التي لا تحتاج إليها في قواعد بياناتها ، وهو أمر غير مقبول للتحليلات.
لذلك ، فإن الخيار الوحيد هو جمع كل ما تحتاجه للتحليل في مكان واحد. في هذه المرحلة ، تناسبنا أي قاعدة بيانات علائقية أو مستودع نص عادي. كنا المسمار BI وبناء لوحات المعلومات. هناك العديد من الخيارات لمجموعات من هذه الحلول:

لكننا أدركنا أننا سنحتاج لاحقًا إلى تغطية جميع الألعاب الـ 150 الأخرى. ربما يمكن معالجة بعض قاعدة البيانات الترابط الكتلة مقدار البيانات التي تم إنشاؤها. لكن المصادر ليست فقط موجودة في أنظمة مختلفة تمامًا ، ولكن لها أيضًا هياكل بيانات مختلفة جدًا. نلتقي الهياكل العلائقية ، البيانات المدفن وغيرها. لن تعمل على وضع كل هذا في قاعدة بيانات واحدة دون حيل معقدة وشاقة.
كل هذا دفعنا إلى فهم أننا بحاجة إلى بناء DataLake.
تنفيذ DataLake
بادئ ذي بدء ، تعد مساحة تخزين DataLake مناسبة لظروفنا ، لأنها تتيح لنا تخزين البيانات غير المنظمة. يمكن أن تصبح DataLake نقطة دخول واحدة لجميع المصادر المتنوعة ، من الجداول من RDBMS إلى JSON ، والتي نقوم بشحنها من Kafka أو Mongo. ونتيجة لذلك ، يمكن أن تصبح DataLake أساسًا لتحليلات التصميم المتقاطع التي يتم تنفيذها على أساس واجهات لمختلف المستهلكين: SQL و Python و R و Spark وما إلى ذلك.
التبديل إلى Hadoop
بالنسبة لـ DataLake ، اخترنا الحل الواضح - Hadoop. على وجه التحديد ، وتجميعها من Cloudera. يتيح لك Hadoop العمل مع البيانات غير المهيكلة ويمكن توسيعه بسهولة عن طريق إضافة عقد البيانات. بالإضافة إلى ذلك ، تمت دراسة هذا المنتج جيدًا ، لذا يمكن العثور على إجابة أي سؤال على Stackoverflow ، ولا تنفق الموارد على البحث والتطوير.
بعد تطبيق Hadoop ، حصلنا على الرسم البياني التالي لتخزيننا الموحد الأول:

تم جمع البيانات في Hadoop من عدد قليل من المصادر ، ثم تم وضع واجهات متعددة عليها: أدوات وخدمات BI لتحليلات Ad-Hoc.
تطورت أحداث أخرى بشكل غير متوقع: بدأ Hadoop لدينا تمامًا ، حيث تخلى المستهلكون الذين تدفقت بياناتهم إلى المتجر عن الأنظمة التحليلية القديمة وبدأوا في استخدام المنتج الجديد يوميًا لعملهم.
ولكن نشأت مشكلة: كلما زاد ما تفعله ، زاد ما تريده منك. بسرعة كبيرة ، بدأت المشروعات التي تم دمجها بالفعل في Hadoop في طلب المزيد من البيانات. وتلك المشروعات التي لم تتم إضافتها بعد ، بدأت تطلب ذلك. بدأت متطلبات الاستقرار في النمو بشكل حاد.
في الوقت نفسه ، ليس من المعقول ببساطة زيادة الفريق خطيًا. إذا كان هناك مطوران تابعان لشركة DWH يتعاملان مع مشروعين ، فلن نتمكن من توظيف أربعة مطورين آخرين في أربعة مشاريع. لذلك ، أولاً ذهبنا في الاتجاه الآخر.
إنشاء العملية
مع الموارد المحدودة ، فإن الحل الأقل هو ضبط العمليات. علاوة على ذلك ، في شركة كبيرة يستحيل التوصل إلى بنية تخزين وتنفيذها. يجب أن تتفاوض مع عدد كبير من الناس.
- بادئ ذي بدء ، مع ممثلي الأعمال الذين يخصصون الموارد للتحليلات. سيتعين عليك إثبات أنك بحاجة إلى تنفيذ تلك المهام فقط من عملائك والتي ستفيد الشركة.
- تحتاج أيضًا إلى التفاوض مع المحللين حتى يقدموا لك شيئًا مقابل الخدمات التي تقدمها لهم - تحليل النظام وتحليل الأعمال والاختبار. على سبيل المثال ، قدمنا تحليل النظام لمصادر البيانات الخاصة بنا للمحللين. بالطبع ، ليسوا سعداء ، ولكن لن يكون هناك أحد للقيام بذلك.
- أخيرًا وليس آخرًا ، يجب عليك التفاوض مع مطوري الألعاب: تثبيت SLAs والاتفاق على بنية بيانات. إذا كانت الحقول تختفي باستمرار وتظهر وتسميها ، فبغض النظر عن حجم الفريق ، فستفقد يديك دائمًا.
- تحتاج أيضًا إلى التفاوض مع فريقك: البحث عن حل وسط بين الحلول المثالية التي يرغب جميع المطورين في إنشائها ، والحلول القياسية التي ليست مثيرة للاهتمام ، ولكنها يمكن أن تنشط بثمن بخس وبسرعة.
- سيكون من الضروري الاتفاق مع المسؤولين حول مراقبة البنية التحتية. على الرغم من أنه بمجرد توفر موارد إضافية ، فمن الأفضل تعيين اختصاصي DevOps الخاص بك في فريق التخزين.
في هذه المرحلة ، يمكنني إنهاء المقال إذا كان هذا البديل من المستودع يحقق جميع الأهداف المحددة له. لكن هذا ليس كذلك. لماذا؟
قبل Hadoop ، يمكننا توفير البيانات والإحصاءات لخمسة مشاريع. مع تنفيذ Hadoop وبدون زيادة في الفريق ، تمكنا من تغطية 10 مشاريع. بعد إنشاء العمليات ، قدم فريقنا بالفعل 15 مشروعًا. هذا رائع ، لكن لدينا 150 مشروعًا ، كنا بحاجة إلى شيء جديد.
تنفيذ تدفق الهواء
في البداية ، قمنا بجمع البيانات من مصادر باستخدام Cron. مشروعان أمر طبيعي. 10 - هذا مؤلم ، لكن حسنا. ومع ذلك ، يتم الآن تحميل حوالي 12 ألف عملية يوميًا للتحميل من 150 مشروعًا إلى DataLake. كرون لم تعد مناسبة. للقيام بذلك ، نحتاج إلى أداة قوية لإدارة تدفقات تنزيل البيانات.
لقد اخترنا إدارة مهام Airflow مفتوحة المصدر. ولد في أحشاء Airbnb ، وبعد ذلك تم نقله إلى أباتشي. هذا هو أداة ل ETL يحركها رمز. أي أنك تكتب نصًا في Python ، ويتم تحويله إلى DAG (رسم بياني موجه). تعد DAGs مهمة للحفاظ على التبعيات بين المهام - لا يمكنك إنشاء واجهة باستخدام بيانات لم يتم تحميلها بعد.
يحتوي Airflow على معالج خطأ كبير. في حالة تعطل إحدى العمليات أو وجود مشكلة في الشبكة ، يقوم المرسل بإعادة تشغيل العملية بعدد المرات التي تحددها. إذا كان هناك الكثير من حالات الفشل ، على سبيل المثال ، تم تغيير الجدول في المصدر ، ثم تصل رسالة إعلام.
يحتوي Airflow على واجهة مستخدم رائعة: فهو يعرض بشكل مناسب العمليات التي تعمل ، أو تلك التي أكملت بنجاح أو مع وجود خطأ. إذا سقطت المهام بسبب الأخطاء ، يمكنك إعادة تشغيلها من الواجهة والتحكم في العملية من خلال المراقبة دون الدخول في الشفرة.
Airflow قابل للتخصيص ، وهو مبني على أعلى المشغلين - هذه مكونات إضافية للعمل مع مصادر محددة. يخرج بعض المشغلين من الصندوق ، وقد كتب الكثيرون منهم مجتمع Airflow. إذا كنت ترغب في ذلك ، يمكنك إنشاء المشغل الخاص بك ، واجهة هذا بسيطة للغاية.
كيف نستخدم تدفق الهواء؟
على سبيل المثال ، نحتاج إلى تحميل جدول من PostgreSQL إلى Hadoop. تقوم مهمة
sql_sensor_battle_log بالتحقق مما إذا كان المصدر لديه البيانات التي نحتاجها أمس. إذا كان الأمر كذلك ، فإن مهمة
load_stg_data_from_battle_log البيانات من PG
load_stg_data_from_battle_log إلى Hadoop. أخيرًا ، يقوم
load_oda_data_from_battle_log بإجراء المعالجة الأولية: على سبيل المثال ، التحويل من وقت Unix إلى وقت مقروء بشري.
في سلسلة المهام هذه ، تؤخذ البيانات من كيان واحد في مصدر واحد:

وهكذا - من جميع الكيانات التي نحتاجها من مصدر واحد:
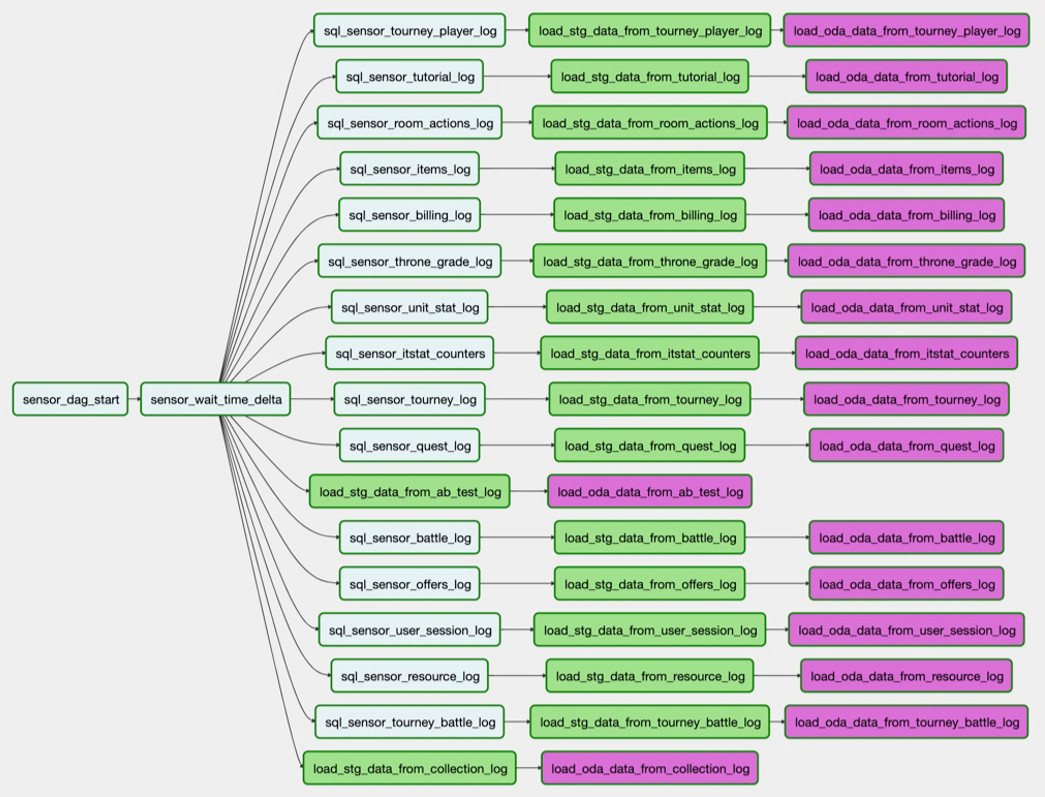
هذه المجموعة من التنزيلات هي DAG. وفي الوقت الحالي ، لدينا 250 من DAGs لتحميل البيانات الخام ومعالجتها وتحويلها وإنشاء واجهات متاجر عليها.
نظام التخزين الموحد المحدث كما يلي:
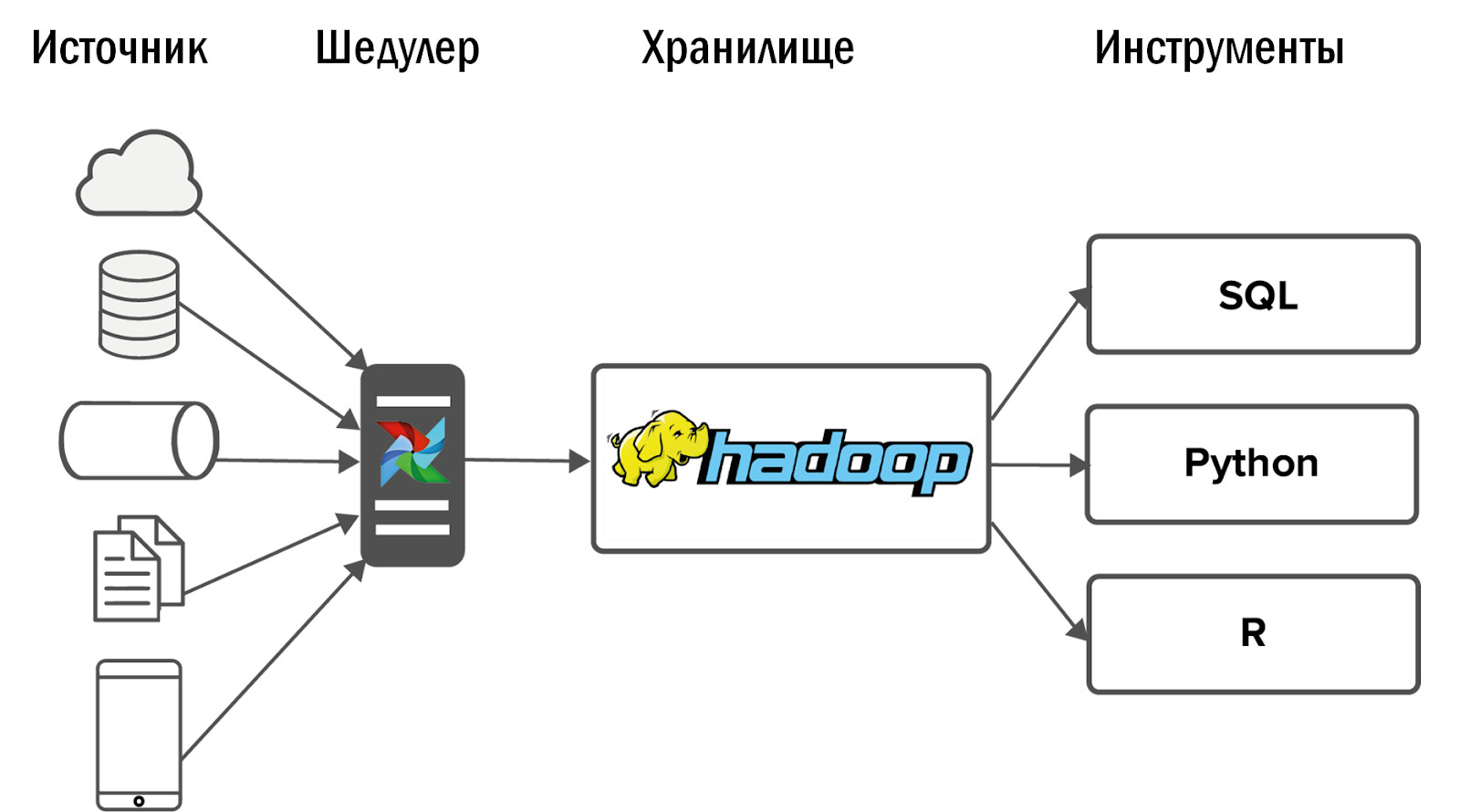
- بعد إدخال Airflow ، تمكنا من تحمل زيادة حادة في عدد المصادر - حتى 400 قطعة. مصادر البيانات داخلية (من ألعابنا) وخارجية: أنظمة الإحصاء المشتراة ، واجهات برمجة التطبيقات غير المتجانسة. إن Airflow هو الذي يسمح لنا بالتنفيذ والتحكم بشكل يومي في 12 ألف عملية تقوم بمعالجة البيانات من جميع ألعابنا البالغ عددها 150 لعبة.
- بمزيد من التفاصيل حول Airflow ، كتبت دين سافينا في مقالها ( https://habr.com/ru/company/mailru/blog/344398/ ). وانضم أيضًا إلى مجتمع Airflow على Telegram ( https://t.me/ruairflow ). يمكن حل العديد من الأسئلة حول Airflow بمساعدة الوثائق ، ولكن في بعض الأحيان تظهر المزيد من الطلبات المخصصة: كيف يمكنني حزم Airflow في عامل ميناء ، ولماذا لا يعمل في اليوم الثالث وكل ذلك. يمكن الرد على هذا في هذا المجتمع.
ما يجب تحسينه في DataLake
في هذه المرحلة ، يكون مطورو DWH واثقين من أن كل شيء جاهز ويمكنك الآن التهدئة. لسوء الحظ أو لحسن الحظ ، لا يزال هناك شيء لتشديده في DataLake.
جودة البيانات
مع وجود عدد كبير من الجداول في DataLake ، تعد جودة البيانات أول من يعاني. على سبيل المثال ، خذ الجدول مع المدفوعات. يحتوي على user_id والمبلغ والتاريخ ووقت الدفع:
حوالي 10 آلاف دفعة تحدث يوميًا:

مرة واحدة في الجدول لهذا اليوم جاء فقط 28 إدخالات. نعم ، وكل المستخدم فارغ:
إذا حدث شيء ما فجأة في مصدرنا ، فبفضل Airflow ، سنعرفه على الفور. ولكن إذا كانت هناك بيانات بشكل رسمي ، وحتى بالتنسيق الصحيح ، فإننا لا نتعلم على الفور عن التعطل بالفعل من مستهلكي البيانات بالفعل. ليس من الواقعي مراجعة طاولاتنا الـ 5000 بأيدينا.
لمنع هذا ، قمنا بتطوير نظام مراقبة جودة البيانات (DQ) الخاص بنا. كل يوم يراقب التنزيلات الرئيسية لمستودعنا: يتتبع التغييرات المفاجئة في عدد الصفوف ، ويبحث عن الحقول الفارغة ، ويتحقق من تكرار البيانات. يطبق النظام أيضًا الشيكات المخصصة من المحللين. بناءً على ذلك ، ترسل إعلامات إلى البريد الإلكتروني بشأن الخطأ الذي حدث وأين. يذهب المحللون إلى المشاريع ويكتشفون ، على سبيل المثال ، قلة البيانات ، وإزالة الأسباب ، وإعادة تحميل البيانات.
تحديد أولويات التنزيلات
مع تزايد عدد المهام لتحميل البيانات في DataLake ، ينشأ تعارض سريع في الأولوية. الموقف المعتاد: بعض المشاريع غير المهمة استغرقت جميع الموارد مع تنزيلاته في الليل ، والجداول اللازمة لحساب مقاييس الإدارة العليا ليس لديها وقت للتحميل بحلول بداية يوم العمل. نحن نتعامل مع هذا بعدة طرق.
- مراقبة التنزيلات الرئيسية. يحتوي Airflow على نظام SLA الخاص به ، والذي يسمح لك بتحديد ما إذا كان كل المفتاح قد جاء في الوقت المحدد. إذا لم يتم تحميل بعض البيانات ، فسنتعرف على ذلك قبل ساعات قليلة من المستخدمين وسيكون لدينا وقت لإصلاحه.
- تحديد الأولويات. للقيام بذلك ، نستخدم قائمة انتظار Airflow ونظام الأولوية. يسمح لنا بتحديد ترتيب تحميل DAGs وعدد العمليات الموازية فيها. لا معنى لتحميل السجلات التي يتم تحليلها مرة واحدة كل ثلاثة أشهر ، قبل تنزيل البيانات لمقاييس الإدارة العليا.
مراقبة مدة الدفعة الليلية
لدينا تخزين دفعي. في الليل ، نحن بصدد بناءه ، ومن المهم بالنسبة لنا التأكد من وجود ليلة كافية لمعالجة الدفعة اليومية. خلاف ذلك ، خلال ساعات العمل ، لن يكون لدى المحللين موارد تخزين كافية للعمل. نحل هذه المشكلة بانتظام بعدة طرق:
- عكس التحجيم. نحن لا شحن جميع البيانات ، ولكن فقط ما يحتاج المحللون. نحن نراقب جميع الجداول المحملة ، وإذا لم يتم استخدام أحدها لمدة ستة أشهر ، فإننا نوقف تحميله.
- بناء القدرات. إذا فهمنا أننا مقيدون بقدرات الشبكة أو عدد النوى أو سعة القرص ، فإننا نضيف عقد البيانات إلى Hadoop.
- تعظيم تدفق العمال. نحن نفعل كل شيء حتى يتم استخدام كل جزء من نظامنا إلى أقصى حد في كل لحظة من وقت إنشاء التخزين.
- إعادة بيع العمليات غير المثلى. على سبيل المثال ، نحن نعتبر اقتصاد لعبة جديدة ، ويستغرق منا 5 دقائق. ولكن بعد عام ، تنمو البيانات ، ويتم معالجة الطلب نفسه لمدة ساعتين. في مرحلة ما ، يجب علينا أن نتكيف مع إعادة الحساب التدريجية ، رغم أن هذا قد يبدو في البداية بمثابة تعقيد غير ضروري.
التحكم في الموارد
من المهم ليس فقط الحصول على وقت لإنهاء إعداد المستودع لبداية يوم العمل ، ولكن أيضًا لمراقبة توفر موارده بعد ذلك. مع هذا ، قد تنشأ صعوبات مع مرور الوقت. بادئ ذي بدء ، السبب هو أن المحللين يكتبون استفسارات دون المستوى الأمثل. مرة أخرى ، أصبح المحللون أنفسهم أكثر فأكثر. أبسط شيء في هذه الحالة: زيادة سعة الأجهزة. ومع ذلك ، سيستمر الطلب غير الأمثل في تناول جميع الموارد المتاحة. وهذا هو ، عاجلاً أم آجلاً ، سوف تبدأ في إنفاق الأموال على الحديد دون فائدة كبيرة. لذلك ، نحن نستخدم عدة طرق أخرى.
- اقتباس: نترك للمستخدمين موارد قليلة على الأقل. نعم ، سيتم تنفيذ الطلبات ببطء ، لكن على الأقل سيتم تنفيذها.
- مراقبة الموارد المستهلكة: كم عدد النوى التي تستخدمها طلبات المستخدمين ، الذين نسوا استخدام الأقسام في Hadoop وأخذوا كل ذاكرة الوصول العشوائي ، وما إلى ذلك ... علاوة على ذلك ، فإن هذه المراقبة مرئية للمحللين أنفسهم ، وعندما لا يعمل شيء ما لصالحهم ، فإنهم يعثرون على الجاني ويتعاملون معه منهم. إذا كان لدينا عدد قليل من المشاريع ، لكنا تتبع استهلاك الموارد بأنفسنا. ولكن مع وجود الكثير ، سيتعين علينا تعيين فريق مراقبة منفصل ومتسع باستمرار. وعلى المدى الطويل ، هذا غير معقول.
- تدريب المستخدم الإلزامي. مهمة المحللين ليست كتابة استعلامات الجودة إلى مستودعك. مهمتهم هي الإجابة على أسئلة العمل. وإلى جانب أنفسنا - فريق المستودعات - لا أحد يهتم بجودة طلبات المحللين. لذلك ، نقوم بإنشاء أسئلة وأجوبة وعروض تقديمية وإجراء محاضرات للمحللين ، وشرح كيف يمكننا العمل مع DataLake ، وكيف لا.
في الواقع ، إن قضاء الوقت في إتاحة البيانات يعد أكثر أهمية من ملء البيانات. إذا كانت هناك بيانات موجودة في وحدة التخزين ، ولكنها غير متوفرة ، فلا تزال هناك من وجهة نظر العمل ، وقد تم بالفعل إنفاق جهود التنزيل لديك.
مرونة الهندسة المعمارية
من المهم عدم نسيان مرونة DataLake المضمنة وعدم الخوف من تغيير الهيكل عند تغيير عوامل الإدخال: ما هي البيانات التي يلزم تحميلها إلى وحدة التخزين ومن يستخدمها وكيف. نحن لا نعتقد أن الهندسة المعمارية لدينا ستبقى دائما دون تغيير.
على سبيل المثال ، أطلقنا لعبة جديدة للهاتف المحمول. تكتب JSON إلى Nginx من العملاء ، تقوم Nginx بإلقاء البيانات على Kafka ، نقوم بتحليلها باستخدام Spark ووضعها في Hadoop. كل شيء يعمل ، تم إغلاق المهمة.
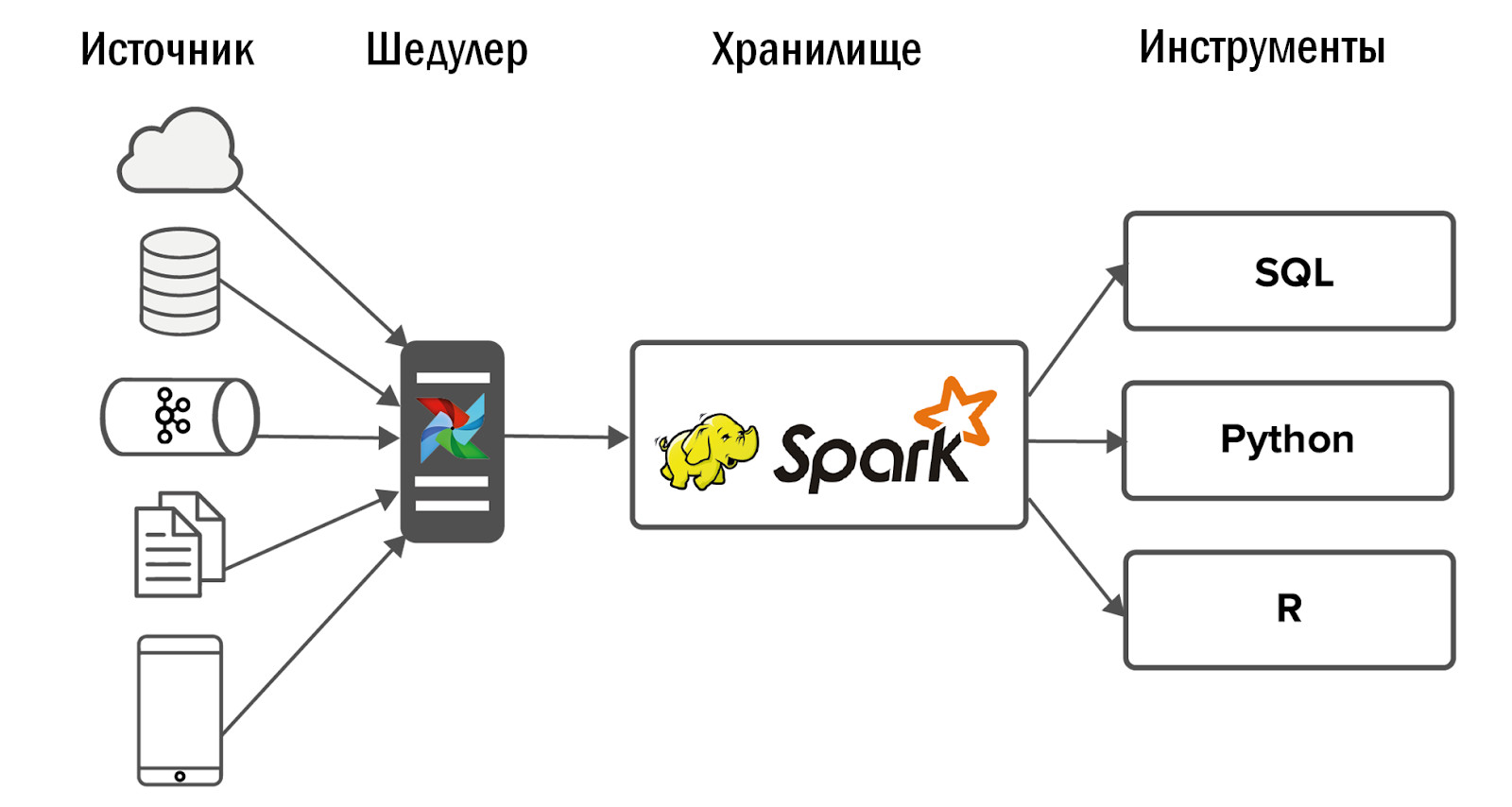
مر بضعة أشهر ، وفي التخزين ، بدأت جميع عمليات الدُفعات الليلية تعمل لفترة أطول. لقد بدأنا في معرفة الأمر: تبين أن اللعبة "تم التقاطها" ، تم إنشاء بيانات أكثر بمقدار 50 مرة ، ولم يتمكن Spark من التعامل مع تحليل JSON ، مما أدى إلى سحب نصف موارد التخزين. في البداية ، تم إرسال جميع البيانات إلى موضوع كافكا واحد ، وصنفها سبارك في كيانات مختلفة. طلبنا من مطوري اللعبة مشاركة البيانات حول العملاء مع كيانات مختلفة وصبهم في موضوعات كافكا منفصلة. أصبح الأمر أسهل ، ولكن ليس لفترة طويلة. ثم قررنا التبديل من تحليل JSON اليومي إلى كل ساعة. ومع ذلك ، بدأ بناء منشأة التخزين ليس فقط في الليل ، ولكن على مدار الساعة ، وهو أمر غير مرغوب فيه بالنسبة لنا. بعد هذه المحاولات ، لحل هذه المشكلة ، تخلينا عن Spark وقمنا بتنفيذ ClickHouse.

لديه محرك تحليل JSON رائع يقوم على الفور بتحليل البيانات في الجداول. نرسل أولاً معلومات من كافكا إلى ClickHouse ، ومن هناك نستلمها في Hadoop. هذا حل مشكلتنا تماما.
بالطبع ، نحن نحاول عدم تربية أنظمة حديقة الحيوان في وحدة تخزين DataLake الخاصة بنا ، لكننا نحاول اختيار أكثر التقنيات ملاءمة لمهام محددة.
هل كان يستحق كل هذا العناء؟
هل كان يستحق الأمر نشر Hadoop ، وهو نظام لمراقبة الجودة ، والتعامل مع Airflow ، وإنشاء عمليات تجارية؟ بالطبع كان يستحق:
- يحتوي النشاط التجاري على معلومات محدثة عن جميع المشاريع ، والتي تتوفر في خدمات واحدة.
- توقف مستخدمو نظامنا ، بدءًا من مصممي الألعاب إلى المديرين ، عن اتخاذ القرارات فقط على أساس الحدس والتحول إلى نهج يحركها البيانات.
- قدمنا المحللين الأدوات اللازمة لصنع علم الصواريخ الخاصة بهم. الآن يجيبون على استفسارات الأعمال المعقدة ، وبناء نماذج للتنبؤ ، وأنظمة التوصية ، وتحسين الألعاب. في الواقع ، لهذا نحن نعمل في BI-DWH.