في بعض الأحيان تنشأ مهمة "الغراء" لاختيار متكامل مع نفس البيانات "في الأعمدة" من المصفوفات الخطية التي تم تمريرها كمعلمات في استعلام SQL.
كيف يتم ذلك في بعض الأحيان:
WITH T1 AS ( SELECT row_number() OVER() rn , unnest v1 FROM unnest('{1,2,3,4}'::integer[]) ) , T2 AS ( SELECT row_number() OVER() rn , unnest v2 FROM unnest('{5,6}'::integer[]) ) SELECT T1.v1 , T2.v2 FROM T1 LEFT JOIN T2 USING(rn);
v1 | v2 ------- 1 | 5 2 | 6 3 | 4 |
وهذا هو ، أولاً ، تم "توسيع" كل صفيف في العينة ، مرقمة ، ثم تم استخدام هذا الرقم كمفتاح اتصال CTE ...
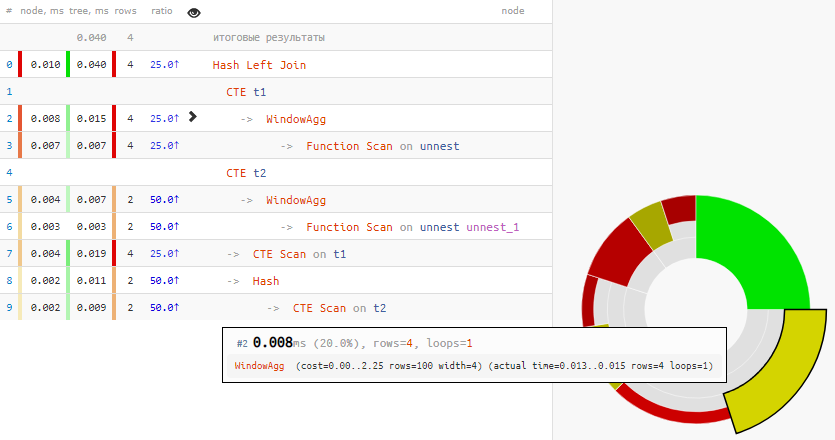 [انظروا شرح.tensor.ru]
[انظروا شرح.tensor.ru]مع الاعتيادية
تم إنفاق أكثر من ربع الوقت على برنامج WindowAgg!
ولكن إذا استخدمنا إصدار PG لا يقل عن 9.4 ، فيمكننا
استخدام WITH ORDINALITY لترقيم نتائج أي SRF ، بما في ذلك nnest:
WITH T1 AS ( SELECT * FROM unnest('{1,2,3,4}'::integer[]) WITH ORDINALITY T(v1, rn) ) , T2 AS ( SELECT * FROM unnest('{5,6}'::integer[]) WITH ORDINALITY T(v2, rn) ) SELECT T1.v1 , T2.v2 FROM T1 LEFT JOIN T2 USING(rn);
 [انظروا شرح
[انظروا شرح .
tensor.ru] .
وبالتالي ، تخلصنا تمامًا من استخدام وظائف النافذة.
حجة متعددة UNNEST
ولكن من وجهة نظر الكفاءة ، ليس كل شيء جيدًا حتى الآن - فقد مضى نصف الوقت تقريبًا على Hash Left Join.
وانطلق المؤلف بوضوح من الافتراض بأن الصفيف الأول أطول تمامًا - لهذا السبب استخدم LEFT JOIN. لكن هذا الافتراض ليس صحيحًا دائمًا ويمكن أن يسبب مشاكل.
للالتفاف حوله ، سوف نستخدم
nnest لعدة صفائف في نفس الوقت ، والتي ظهرت من نفس الإصدار 9.4:
SELECT * FROM unnest( '{1,2,3,4}'::integer[] , '{5,6}'::integer[] ) T(v1, v2);
نتيجة لذلك ، لم يبق شيء تقريبًا من الطلب ، ومن الخطة:
Function Scan on t (cost=0.01..1.00 rows=100 width=8) (actual time=0.006..0.007 rows=4 loops=1)
وبالتالي ، فإن فرص ارتكاب خطأ أقل بكثير. نعم ، وتم تحسين وقت التنفيذ عدة مرات - وفي المصفوفات الأطول ، سيكون التأثير أكثر وضوحًا.