نعمل في
People & Screens مع شركات على الإنترنت لسنوات عديدة كشريك إعلاني. عندما كانت لدينا فكرة لتقييم مساهمة الإعلانات المصوّرة في مبيعات المتاجر عبر الإنترنت ، بدا الأمر غير قابل للتحقيق بل ومجنون. بمجرد أن أدركنا أنه يمكن العثور على جميع عناصر الفسيفساء ووضعها معًا ، قررنا تجربتها. بدأ تأكيد الفرضيات الأولى ، إلى جانب
Data Insight ، بحثنا في هذه القصة وفي غضون أشهر قليلة من العمل المضني خلقت هذه الدراسة ، التي هي في الواقع أداة عمل مطبقة - نموذج لتقييم أداء الإعلان في 12 فئة من فئات منتجات التجارة الإلكترونية. في هذه المقالة سوف نتحدث عن النتائج وطرق التحليل المستخدمة.
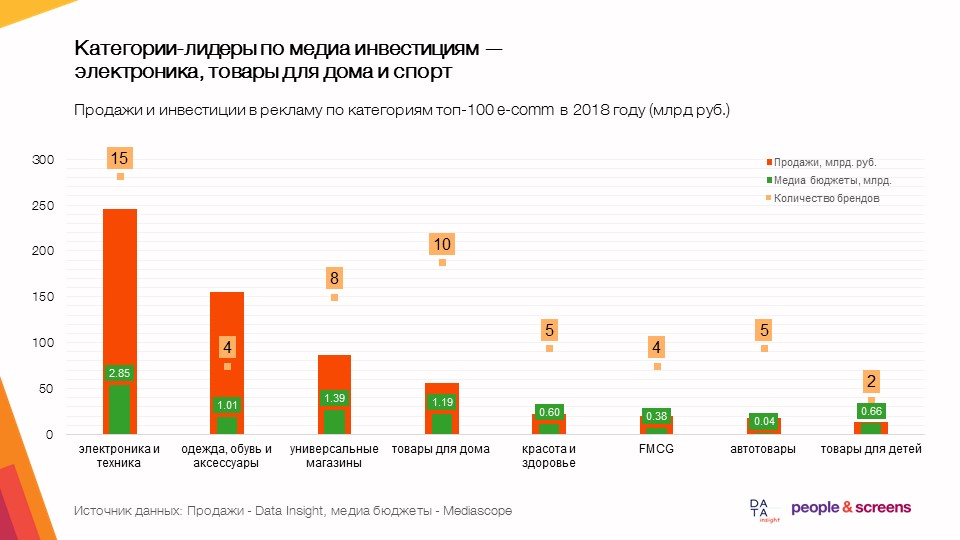
أهداف ونتائج البحث
الفرضية الأساسية لدراستنا: الإعلانات المصوّرة ، وتطوير العلامة التجارية لمتجر على الإنترنت ، تزيد من التحويل في مسار المبيعات بأكمله. في تحليل بيانات المبيعات والإعلانات والبيانات الخارجية على مدار السنوات الأربع الماضية ، تم تأكيد الفرضية. نتيجة لذلك ، قمنا ببناء نماذج مبيعات قياسية لـ 60 متجر عبر الإنترنت في 12 فئة من فئات المنتجات.
- بلغت المساهمة القصيرة الأجل للإعلانات المصوّرة نموًا بنسبة 39٪ في المتاجر على الإنترنت بمتوسط ديناميكي للسوق يتراوح بين 50 و 60٪.
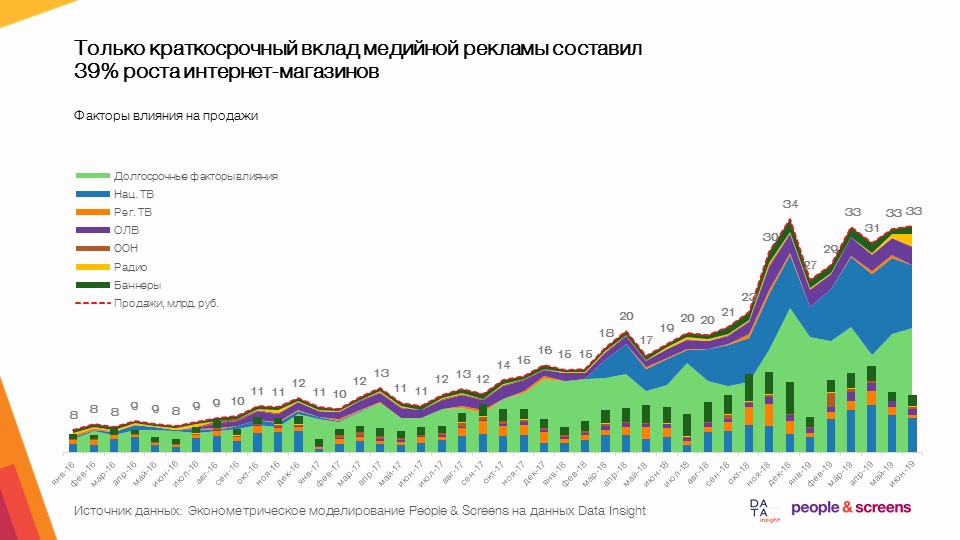
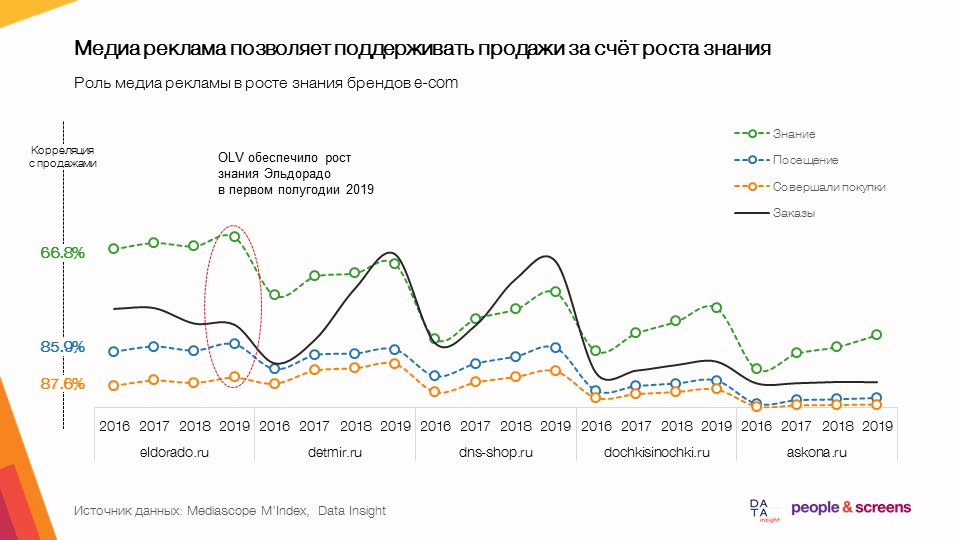
- تتيح لك الإعلانات المصوّرة دعم المبيعات من خلال زيادة المعرفة.
- أكبر عائد على الإطلاق في التجارة الإلكترونية يأتي من إعلانات الفيديو عبر الإنترنت.
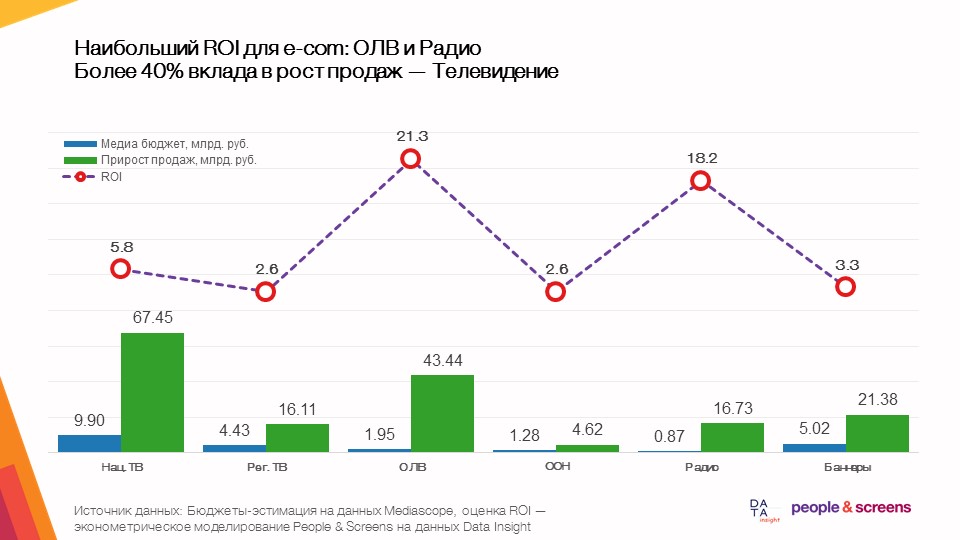
- تعتمد كفاءة الوسائط اعتمادًا كبيرًا على الفئة: في فئات الملابس ومحلات السوبر ماركت عبر الإنترنت ، أظهر التليفزيون كفاءة عالية في الإلكترونيات ومنتجات السيارات - إعلانات الفيديو عبر الإنترنت.
ما قمنا بتحليله
وقد تم جمع البيانات للدراسة من قبل الشركتين المشاركين في الدراسة. تم جمع البيانات التالية بواسطة People & Screens:
- خروج الإعلانات الصورية. استخدمنا التنزيلات من قواعد بيانات Mediascope التي يمكن لجميع المجموعات الإعلانية الوصول إليها. قمنا بتفريغ تكاليف الإعلانات لجميع وسائل الإعلام وجهات الاتصال الإعلانية لجمهور مستهدف واسع (الكل 18+) بالتفصيل حسب اليوم (للإعلان على التلفزيون والراديو والصحافة والإنترنت) والشهر (للإعلان في الهواء الطلق) للفترة من يناير 2016 حتى يونيو 2019. لزيادة سرعة العمل في هذه المرحلة ، استخدمنا التطوير الداخلي لشبكة Dentsu Aegis Network Russia للعمل مع البيانات الصناعية ، وخاصة منصة Atomizer.
- تفريغ البيانات من موقع مشابه يوميا لمدة 18 شهرا الماضية. نظرنا إلى ديناميكيات أيام الزيارات على سطح المكتب / المحمول ، وديناميات أيام المرور على سطح المكتب حسب المصدر (القناة) ، وديناميات عمليات التثبيت على Android.
- ديناميات المعرفة / الزيارات / المشتريات من قاعدة بيانات TGI / Marketing Index للفترة 2016-2019 حسب الجهات. هذا تنزيل من البرنامج الصناعي Mediascope's Gallileo.
- استفسارات بحث Google Trends عن يناير 2016 - يوليو 2019 في جميع أنحاء روسيا.
على جانب Data Insight ، تم جمع البيانات التالية وتوفيرها:
- ديناميات الطلبات لـ 72 متجراً عبر الإنترنت من أعلى 100 تصنيف حسب الشهر للفترة من يناير 2016 إلى أغسطس 2019.
- بيانات عداد li.ru للفترة من يناير 2018 إلى أغسطس 2019 (حركة المرور إلى الموقع ، بشكل إجمالي ، فقط في روسيا والجوال فقط) لمواقع TOP-11.
- بيانات عداد mail.ru للفترة من يونيو 2017 إلى سبتمبر 2019 لـ 53 موقعًا.
- بيانات عداد Rambler للفترة من يونيو 2017 إلى سبتمبر 2019 لـ 38 موقعًا.
- بيانات استعلام بحث Yandex Wordstat لمدة 24 شهرًا من أكتوبر 2017 إلى سبتمبر 2019.
- تقييم متوسط الشيكات لمتاجر TOP-100 على الإنترنت اعتبارًا من 2018.
خوارزمية البيانات
تم جمع البيانات للدراسة على عدة مراحل. سنترك خارج نطاق المقالة العمل الذي قام به زملاؤنا من Data Insight لإنشاء البيانات اللازمة للدراسة ، لكننا سنخبرك بما تم عمله على جانب الأشخاص والشاشات:
- ابحث عن جميع المتاجر عبر الإنترنت من تصنيف TOP-100 في قواعد البيانات الصناعية المتاحة لنا وتجميع قواميس مطابقة الاسم. لهذا ، استخدمنا محرك البحث الدلالي Elasticsearch .
- تشكيل القوالب وتحميل البيانات عليها. في هذه المرحلة ، كان أهم شيء هو التفكير المسبق في بنية جداول البيانات.
- دمج البيانات من جميع المصادر في مجموعة بيانات واحدة (مجموعة بيانات).
للقيام بذلك ، استخدمنا معالجة البيانات التي تم تحميلها في بيثون باستخدام حزم الباندا و sqlalchemy . مجموعة الخارقة الحياة هنا هو معيار تماما:
عند معالجة البيانات الأولية من جداول csv التي يزيد حجمها عن مليون صف ، قمنا أولاً بتحميل أسماء أعمدة الجدول مع استعلام من النموذج:
col_names = pd.read_csv(FILE_PATH,sep=';', nrows=0).columns
ثم تمت إضافة أنواع البيانات من خلال القاموس:
types_dict = {'Cost RUB' : int } types_dict.update({col: str for col in col_names if col not in types_dict})
والبيانات نفسها تحميل وظيفة
pd.read_csv(FILE_PATH, sep=';', usecols=col_names, dtype=types_dict, chunksize=chunksize)
تم تحميل نتائج التحويل إلى PostgreSQL. - التحقق من صحة ديناميكيات الطلب بناءً على تحليل ديناميات حركة المرور واستعلامات البحث والمبيعات الفعلية عبر مجموعة عملاء وكالة الأشخاص والشاشات. قمنا هنا ببناء مصفوفات الارتباط باستخدام df.corr () على مجموعات بيانات مختلفة داخل موقع ثابت ، ثم قمنا بتحليل بالتفصيل السلسلة "المشبوهة" ذات القيم الخارجية. هذه هي واحدة من المراحل الرئيسية للدراسة ، حيث فحصنا موثوقية ديناميات المؤشرات المدروسة.
- بناء نماذج الاقتصاد القياسي على البيانات التحقق من صحتها. استخدمنا هنا تحويل فورييه المباشر والعكسي من الحزمة numpy ( np.fft.fft و np.fft.ifft ) لاستخراج الموسمية وتقريبًا سلسًا تقديريًا لتقدير الاتجاه ونموذج الخطي لحزمة sklearn لتقدير مساهمة الإعلان. عند اختيار فئة من النماذج لهذه المهمة ، انتقلنا من حقيقة أنه ينبغي تفسير نتيجة المحاكاة بسهولة واستخدامها لتقييم عددي لفعالية الإعلان مع مراعاة جودة البيانات. لقد بحثنا في مدى موثوقية النماذج من خلال تقسيم البيانات إلى عينات تدريب واختبار من فترة زمنية متغيرة. أي قمنا بمقارنة الطريقة التي يتصرف بها النموذج المدربين على البيانات من يناير 2016 إلى ديسمبر 2018 في الفترة الزمنية للاختبار من يناير إلى أغسطس 2019 ، ثم قمنا بتدريب النموذج في الفترة الزمنية من يناير 2016 إلى يناير 2019 ونظرنا في كيفية تصرف النموذج في البيانات من فبراير إلى أغسطس 2019. تمت دراسة جودة النماذج من خلال ثبات مساهمة عوامل الإعلان في عينات التدريب المختلفة كما هو متوقع في عينة الاختبار
- الخطوة الأخيرة كانت إعداد عرض تقديمي بناءً على النتائج. قمنا هنا بوضع جسر من النماذج الرياضية لاستنتاجات الأعمال العملية واختبرنا النماذج مرة أخرى من وجهة نظر الفطرة السليمة للنتائج.
تفاصيل تحليل التجارة الإلكترونية والصعوبات التي تنشأ في هذه العملية
- في مرحلة جمع البيانات ، نشأت صعوبات في التقييم الصحيح لاهتمام البحث في المورد. في Google Trends ، لا توجد طريقة لتجميع استعلامات البحث واستخدام الكلمات الرئيسية السلبية كما في Yandex Wordstat. كان من المهم دراسة النواة الدلالية لكل متجر على الإنترنت وتحميل الطلب المركزي. على سبيل المثال ، يجب كتابة M.Video باللغة الروسية - هذا هو الطلب الرئيسي لهذا الموقع.
بالنسبة إلى المتاجر التي تبيع السلع عبر الإنترنت وغير متصل ، اتبع الزملاء من Data Insight النهج التالي في بيانات wordstat Yandex:
تأكد من عدم وجود أسئلة غير ذات صلة (الشيء الرئيسي هو عدم تقدير حجم الطلب ، ولكن لتتبع التغييرات في الديناميات). نحن قوية بما يكفي لتصفية كلمات البحث. عندما كان هناك خطر من جانب اسم العلامة التجارية لالتقاط طلبات غير لائقة ، أخذنا إحصاءات عن المجموعات الرئيسية. على سبيل المثال ، "مخزن الأوزون" بدلاً من "الأوزون" - مع هذا النهج ، يتم التقليل من شعبية بحث بائع التجزئة ، ولكن يتم قياس ديناميكيات الطلب بشكل أكثر موثوقية ويتم التخلص من "الضوضاء". فيما يتعلق بإحصائيات البحث ، هناك مشكلة منهجية لا يبدو أن لها حلاً يعتمد عليه - بالنسبة للعديد من تجار التجزئة ، يتم تشويه هذه الإحصائيات بواسطة أدوات تحسين محركات البحث (SEO) التي تعمل على تحسين نتائج البحث من خلال العوامل السلوكية ، ولكنها تشوه الإحصاءات عند الطلب الحقيقي. - في مرحلة الجمع بين البيانات من مصادر مختلفة ، أصبح من الضروري إحضار البيانات إلى محببة واحدة: كانت البيانات المتعلقة بالإعلانات التلفزيونية وحركة المرور من موقع LikeWeb يومية ، وكانت بيانات طلبات البحث أسبوعية ، وكانت بيانات الطلبات وبيانات العدادات شهرية. نتيجة لذلك ، قمنا بتكوين قاعدة بيانات منفصلة مع حقول التاريخ التي تسمح لك بتجميع البيانات على المستوى المطلوب ، وقاعدة بيانات تجميع شهرية مخزنة مؤقتًا لمزيد من العمل مع جميع تفاصيل بيانات المبيعات.
- في مرحلة التحقق من صحة البيانات ، وجدنا تباينات ملحوظة في ديناميات المبيعات مع بياناتنا. هذا يتطلب مناقشة الموقف مع الزملاء من Data Insight. نتيجة لذلك ، وبفضل فهم دقيق للأشهر التي تحدث فيها أكبر الأخطاء ، حدد المحللون خطأين عميقين في أسفل الخوارزمية لتقييم ديناميات المبيعات الشهرية.
- في مرحلة تطوير النموذج ، ظهرت صعوبات عديدة. لتقييم تأثير الإعلان بشكل صحيح ، كان من الضروري عزل العوامل الخارجية. ترتبط أي ديناميات المبيعات (والتجارة الإلكترونية ليست استثناء) ليس فقط بالإعلانات ، ولكن أيضًا بالعديد من العوامل الأخرى: تغييرات UX / UI على الموقع ، والأسعار ، والتشكيلة ، والمنافسة ، وتقلبات العملة ، إلخ.
لحل هذه المشكلة ، استخدمنا نهجًا يستند إلى تحليل الانحدار للبيانات لفترة طويلة - من يناير 2016 إلى أغسطس 2019. كجزء من هذا النهج ، قمنا بتحليل التغييرات (الزيادات) في ديناميات الطلبات التي يمكن عزوها إلى الإعلانات في هذه الفترة.
من المهم أن نفهم أنه إذا بدأ الإعلان في مرحلة ما ، ولكن القيمة المتوقعة للمبيعات ، وفقًا للنموذج ، لم تكن أعلى من القيمة الفعلية ، فسيظهر النموذج أن هذا الإعلان لم ينجح خلال هذه الفترة. بالطبع ، قد يكون سلوك المبيعات هذا بمثابة تراكب لعدة عوامل (على سبيل المثال ، زيادة / إطلاق الأسعار للمنافسين في نفس الوقت الذي تبدأ فيه الحملة الإعلانية ، أو أن الموقع "انخفض" من تدفق العملاء).
نظرًا لأننا نقوم بتقييم التأثيرات على مدى فترة طويلة من الزمن على عدد كبير من العلامات التجارية ، فيجب تسوية تأثير هذه المصادفات العشوائية على عينة كبيرة ، على الرغم من أن ذلك قد يؤدي إلى تأثيرات مفرطة في التقدير أو تقلل من قيمة العلامات التجارية الفردية. ونتيجة لذلك ، سمح لنا ذلك بتحديد القواعد والأنماط العامة لفئة التجارة الإلكترونية ككل. في الوقت نفسه ، لإجراء تحليل مفصل لتأثير الإعلان داخل العلامات التجارية الفردية ، بالطبع ، لا يزال من الضروري دراسة مجموعة عوامل التأثير بالكامل.
استنتاج
كجزء من هذه الدراسة ، وضعنا لأنفسنا هدفًا للحصول على أكثر النتائج موثوقية استنادًا إلى بيانات من مصادر غير متجانسة. هذه البيانات في حد ذاتها ليست قيمًا دقيقة ، ولكنها مجرد تقييم لهذه القيم عن طريق مراقبة الجهات الخارجية (مراقبة مخرجات الإعلانات ، وديناميات الزيارات ، واهتمامات البحث ، وأخيرا الطلبات).
كل رابط له قيود على جودة البيانات ، وهذه مشكلة يواجهها المحللون والباحثون على نطاق أو آخر كل يوم. نأمل في إطار هذه المقالة أن نتمكن من إظهار الطرق التي يمكن أن تضمن موثوقية استنتاجات الدراسة التحليلية ، مع الحفاظ على القوة التفسيرية للنتائج.