كتب زميلي رفائيل غريغوريان إجدود مؤخرًا مقالًا عن سبب احتياج البشرية إلى التخطيط الدماغي وما هي الظواهر المهمة التي يمكن تسجيلها فيها. اليوم ، واستمرارًا لموضوع الواجهات العصبية ، نستخدم إحدى مجموعات البيانات المفتوحة المسجلة على لعبة ما باستخدام ميكانيكيات P300 لتصور إشارة EEG ، ونرى هيكل الإمكانات المزعومة ، وبناء المصنفات الرئيسية ، وتقييم الجودة التي يمكننا من خلالها التنبؤ بوجود مثل هذه الإمكانات المحتملة.
واسمحوا لي أن أذكرك بأن P300 هي إمكانات تسمى (VP) ، وهي استجابة محددة للدماغ مرتبطة باتخاذ القرارات والمحفزات المميزة (التي سنرىها أدناه). وعادة ما تستخدم لبناء BCI الحديثة.
من أجل القيام بتصنيف EEG ، يمكنك الاتصال بالأصدقاء ، وكتابة لعبة حول الراكون والشياطين في الواقع الافتراضي ، وكتابة ردود الفعل الخاصة بك وكتابة مقال علمي (سأتحدث عن هذا في وقت آخر) ، ولكن لحسن الحظ ، العلماء من جميع أنحاء العالم أجرى بعض التجارب بالنسبة لنا ويبقى فقط لتنزيل البيانات.
يمكن العثور على تحليل لكيفية بناء واجهة عصبية على P300 مع رمز خطوة بخطوة وتصورات ، وكذلك رابط إلى مستودع تحت القط.
تعرض المقالة فقط النقاط الرئيسية من التعليمات البرمجية ، النسخة الكاملة القابلة للتكرار في دفتر ملاحظات jupyter للبحث هنا
من وجهة نظر EEG ، فإن P300 هو مجرد رشقة في وقت معين في قنوات معينة. هناك العديد من الطرق للاتصال بها ، على سبيل المثال ، إذا كنت تركز على كائن واحد ، ويتم تنشيطه في لحظة عشوائية (تغيير الشكل أو اللون أو السطوع أو الانتقال في مكان ما). وإليك كيف تم تنفيذه في العصور القديمة.
بشكل عام ، يكون المخطط كما يلي: هناك العديد من المحفزات (عادة من 3 إلى 7) في مجال رؤية الشخص. يختار الشخص أحدهم ويركز عليه (من الطرق الجيدة حساب عدد مرات التنشيط) ، ثم يومض كل كائن بترتيب عشوائي. مع العلم بوقت التنشيط لكل حافز ، يمكننا الآن أن ننظر إلى EEG التالي وتحديد ما إذا كانت هناك ذروة مميزة فيه (سنراه في التصورات أدناه). نظرًا لأن الشخص يركز على حافز واحد فقط ، يجب أن تكون الذروة واحدة. وهكذا ، في هذه الواجهات العصبية الخاصة بك ، يتم تحديد أحد الخيارات العديدة (رسائل للكتابة ، إجراءات في اللعبة ، والله يعرف ماذا). إذا كان هناك أكثر من سبعة خيارات ، يمكنك وضعها على الشبكة وتقليل المهمة لتحديد صف + عمود. هذه هي الطريقة المصفوفة الكلاسيكية P300 سبيلر ، هو مبين أعلاه.
في حالة مجموعة البيانات التي تم النظر فيها اليوم ، تم استعارة الجزء المرئي (وكذلك الاسم) من مستعملي مساحة اللعبة الشهيرة. بدا الأمر مثل هذا

في الواقع ، هذا هو نفس المتهجى ، فقط يتم استبدال الحروف من قبل الأجانب اللعبة.
كما تم حفظ الفيديو الخاص بعملية اللعبة والتقارير الفنية .
بطريقة أو بأخرى ، ظهرت البيانات التي تم جمعها باستخدام هذه اللعبة على الإنترنت ويمكننا الوصول إليها. تتكون البيانات من 16 قناة EEG وقناة حدث واحدة ، والتي تظهر في لحظات تم تنشيط الهدف (الذي قدمه اللاعب) والحوافز غير المستهدفة ، وسنعمل معها.
تم تسجيل معظم مجموعات بيانات BCI من قِبل علماء الفيزيولوجيا العصبية ، وهم أشخاص لا يهتمون حقًا بالتوافق ، لذلك تنسيقات البيانات متنوعة للغاية: من الإصدارات المختلفة من ملفات .mat إلى التنسيقات "القياسية" .edf و .gdf .
أهم شيء تحتاج إلى معرفته حول هذه التنسيقات هو أنك لا تريد تحليلها أو التعامل معها مباشرةً.
لحسن الحظ ، قامت مجموعة من المتحمسين من NeuroTechX بكتابة التنزيلات لبعض مجموعات البيانات مباشرة في numpy.
تعتبر أدوات تحميل التشغيل هذه جزءًا من مشروع moabb الذي يزعم أنه حل عالمي لشركة BCI.
تحميل مجموعة البيانات الخام
import moabb.datasets sampling_rate = 512 m_dataset = moabb.datasets.bi2013a( NonAdaptive=True, Adaptive=True, Training=True, Online=True, ) m_dataset.download() m_data = m_dataset.get_data()
في هذه المرحلة ، حصلنا على بنية RawEDF تحتوي على سجلات EEG. هذا هيكل من حزمة mne ، وعادة ما يستخدمه علماء الأحياء للتفاعل مع الإشارات: يحتوي هذا الهيكل على أساليب مدمجة لتصفية الملصقات وتصورها وتخزينها ، ولا تعرفها أبدًا. لكننا لن نذهب بهذه الطريقة منذ ذلك الحين تميل واجهة الحزمة إلى أن تكون غير مستقرة (الإصدار الحالي هو 0.19 ، لكننا سنستخدم 0.17 لأن مجموعة البيانات لم تعد تقرأ من قبل الإصدار الجديد) وسوء التوثيق ، من خلال هذا قد تصبح نتائجنا غير قابلة للإنتاج.
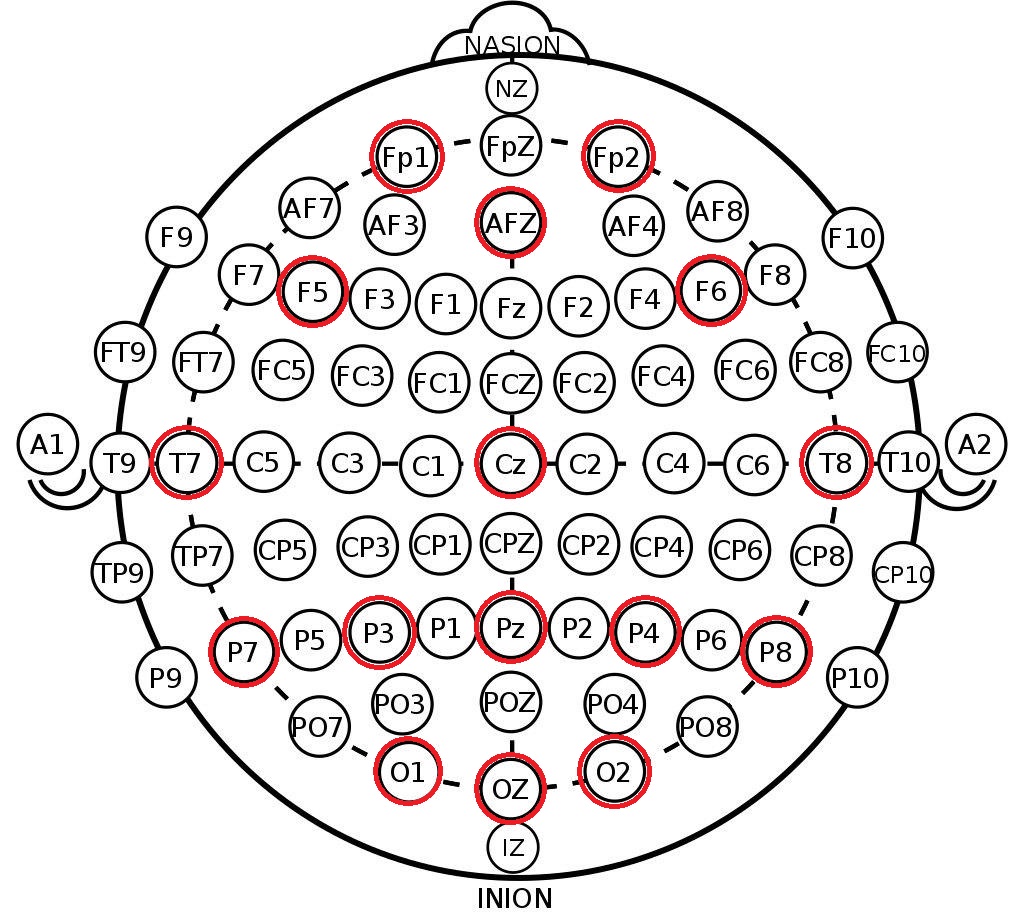
ما نأخذه من الهيكل الناتج هو تسميات القنوات في نظام 10-20 . هذا ترتيب دولي للأقطاب الكهربائية على رأس الشخص ، تم إنشاؤه حتى يتمكن العلماء من ربط مناطق المخ ومواقع قناة EEG. يوجد أدناه ترتيب الأقطاب الكهربائية في نظام 10-10 (يختلف من 10 إلى 20 ضعف كثافة العلامات) والقنوات المسجلة في مجموعة البيانات هذه باللون الأحمر.
print(m_data[1]['session_1']['run_1'])
أولاً ، من البيانات التي تم تنزيلها لكل موضوع ، نقوم بتخصيص صفيف من EEG المستمر لمدة 16 ثانية وجميع التسميات لهذا الفاصل (في البيانات هذه مجرد قناة أخرى يتم فيها ملاحظة بداية الأحداث التي تهمنا).
في هذه المرحلة ، نحافظ على الحد الأقصى لطول EEG المستمر حتى لا نواجه تأثيرات الحافة أثناء التصفية الإضافية.
raw_dataset = [] for _, sessions in sorted(m_data.items()): eegs, markers = [], [] for item, run in sorted(sessions['session_1'].items()): data = run.get_data() eegs.append(data[:-1]) markers.append(data[-1]) raw_dataset.append((eegs, markers))
الترشيح والفصل
بشكل عام ، لمراجعة طرق المعالجة المسبقة وتصنيف مخطط كهربية الدماغ ، يمكنني أن أوصي بنظرة عامة ممتازة من أساتذة الحواسيب العصبية. أيضا منذ وقت ليس ببعيد صدر استعراض أكثر حداثة من اختبارات الشبكة العصبية.
يتضمن الحد الأدنى للمعالجة المسبقة لإشارة EEG للتصنيف 3 خطوات:
لتنفيذ هذه الخطوات ، سوف نستخدم sklearn القديمة الجيدة sklearn للمحولات وخطوط الأنابيب بحيث تكون المعالجة المسبقة لدينا سهلة الامتداد.
يتم وضع رمز المحولات في ملف منفصل ، فيما يلي وصف لبعض التفاصيل.
هلاك
لسبب ما ، في بعض المقالات وأمثلة المعالجة ، قابلت انخفاضًا في وتيرة الإشارة من خلال رمي العينات ببساطة في النمط eeg = eeg[:, ::10] . هذا غير صحيح تمامًا (لماذا - راجع أي كتاب عن معالجة الإشارات). نحن نستخدم scipy القياسي scipy .
تصفية
هنا ، نعتمد أيضًا على مرشحات scipy عن طريق اختيار مرشح ممر بتروورث filtfilt الاتجاه filtfilt ( filtfilt ) للحفاظ على المرحلة. ترددات القطع - من 0.5 إلى 20 هرتز ، هذا هو النطاق القياسي لمهمتنا.
تدريج
استخدمنا StandardScaler لكل قناة (يطرح المتوسط ، يقسم على الانحراف المعياري) ، والذي يرى كل الإشارات من العينة. في الواقع ، يتم تقديم تسرب بيانات صغير في هذه المرحلة. بشكل رسمي ، يرى المتسلق أيضًا بيانات من عينة الاختبار ، ولكن مع وجود أحجام بيانات كبيرة بما فيه الكفاية ، يكون المتوسط والانحراف متماثلين.
يتم إجراء الاستمناء كل قناة على حدة ، بحيث يمكن ضمن مجموعة البيانات نفسها تجميع البيانات من أجهزة استشعار مختلفة لها ترتيبات مختلفة من حيث الحجم والطبيعة (على سبيل المثال ، تفاعل كلفان الجلد (RAG) )
بالإضافة إلى العمليات المذكورة أعلاه ، كان من الممكن أيضًا تمييز القطع الأثرية في EEG (الحركات الوامضة والمضغية وحركات الرأس) ، ولكن مجموعة البيانات هذه نظيفة للغاية بالفعل ، لذلك دعونا نتركها حتى المرة القادمة.
reload(transformers) decimation_factor = 10 final_rate = sampling_rate // decimation_factor epoch_duration = 0.9
بعد ذلك ، سنطبق خط أنابيب المعالجة المسبقة على بياناتنا ونقطع إشارة EEG المستمرة إلى فترات. سنطلق على الفترة الزمنية فترة مباشرة بعد تنشيط المنبه مع مدة مميزة تبلغ 0.5-1 ثانية ، في حالتنا ، تكون المدة 900 مللي ثانية ، على الرغم من أنه يمكن تقصيرها.
يوجد في مجموعة البيانات الخاصة بنا 16 قناة EEG ، بعد تطبيق الكسر العشري ، سينخفض التردد إلى 50 هرتز ، لذلك سيتم وصف فترة واحدة بمصفوفة (16, 45) - 900 مللي ثانية عند 50 هرتز ، 45 عينة زمنية.
العلامات الموجودة في مجموعة البيانات هذه عبارة عن ثنائيات فقط - فهي تحدد الهدف (مخفي بواسطة اللاعب ، نشط ، 1) وإشارات غير مستهدفة (فارغة ، 0).
for eegs, _ in raw_dataset: eeg_pipe.fit(eegs) dataset = [] for eegs, markers in raw_dataset: epochs = [] labels = [] filtered = eeg_pipe.transform(eegs) markups = markers_pipe.transform(markers) for signal, markup in zip(filtered, markups): epochs.extend([signal[:, start:(start + epoch_count)] for start in markup[:, 0]]) labels.extend(markup[:, 1]) dataset.append((np.array(epochs), np.array(labels)))
dataset[0][0].shape, dataset[0][1].shape
إذن ، حصلنا على Pytorch غرار Pytorch ، حيث يقوم المؤشر الأول بحساب أشخاص مختلفين. من خلال هذا الهيكل ، يمكننا إجراء التحقق من صحة البيانات داخل شخص واحد ، واختبار تحمل المصنف بين مختلف الأشخاص (ما يسمى تعلم النقل ، والتنبؤ دون المعايرة). تتكون بيانات شخص واحد من مجموعة من العصور والتسميات الصفية. يختلف عدد العصور لكل شخص بشكل طفيف نظرًا لخصائص التسجيل.
بحوث البيانات والتصور
أولاً ، ألقِ نظرة على إحدى الإشارات المستمرة قبل تقطيعها إلى عصور.
على الرغم من حقيقة أنه قد تمت تصفيته بالفعل ، فإنه لا يظهر أي تنشيط على العين ويبدو وكأنه نوع من الضوضاء.
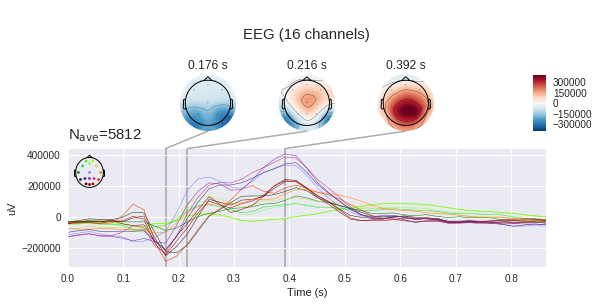
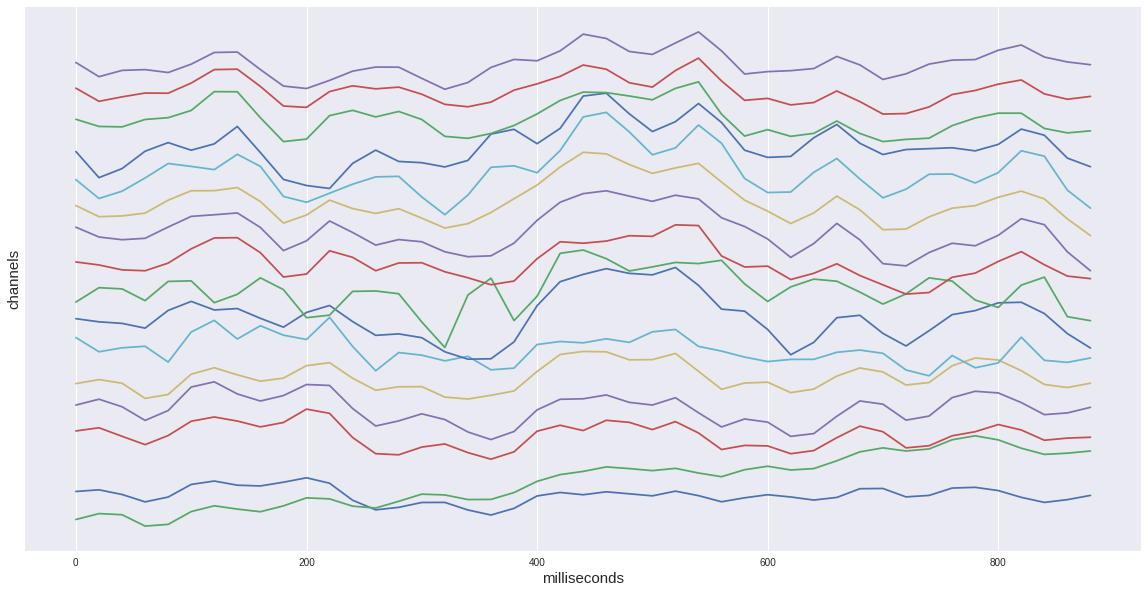
إذا أخذنا بعين الاعتبار عصرًا مستهدفًا واحدًا فقط من مجموعة البيانات الخاصة بنا ، فسنرى ارتفاعًا مميزًا في الفاصل الزمني 400-600 مللي ثانية. هذا هو P300 لدينا المحتملة المحتملة.
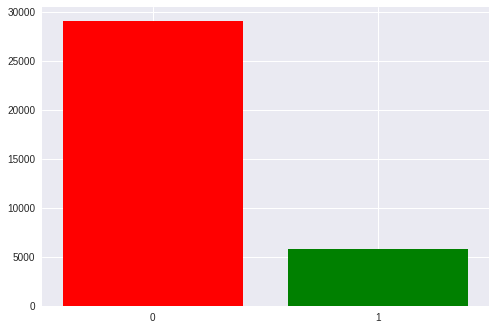
كل ما في مجموعة البيانات لدينا حوالي 35 ألف حقبة ، أي تنشيط التحفيز. كل شخص لديه حوالي 1300 حتي 1750 (وهذا يرجع إلى حقيقة أن شخصا ما أسقطت الأجانب بشكل أسرع وأبطأ شخص).
هناك أيضًا اختلال ملحوظ في الفصول: من 1 إلى 5 لصالح المنبهات الفارغة. لدينا 6 صفوف وعمود في المصفوفة وفقط واحد منهم هو الهدف. سنعود لاحقًا إلى هذا عند مناقشة المقاييس التي تم الحصول عليها.
حان الوقت الآن للنظر في الفرق بين الإشارة المستهدفة وغير المستهدفة
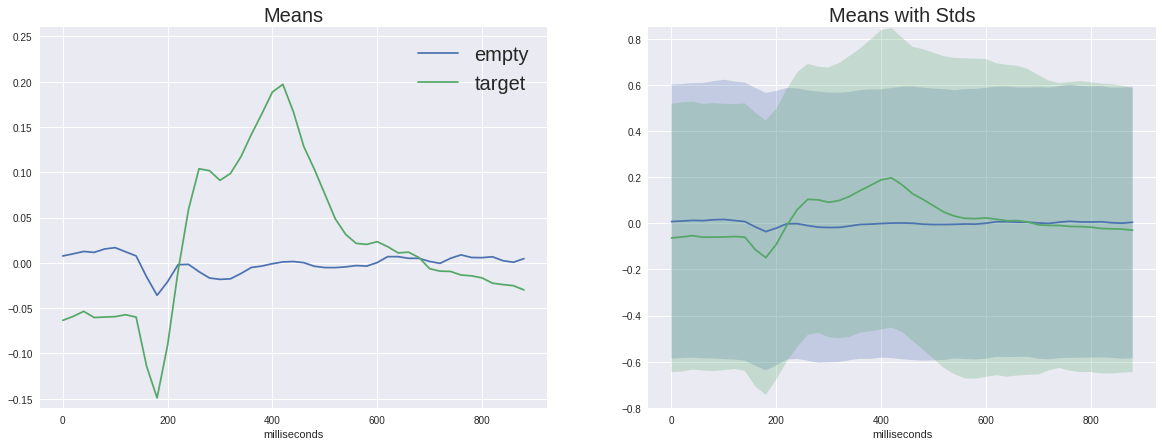
على الرسم البياني الأيسر ، يمكنك أن ترى أن متوسط الإشارات يتغير كثيرًا ، ولكل منهما استجابة غير محددة في منطقة تبلغ 180 مللي ثانية ، ولكن الهدف هو أكبر من ذلك بكثير ، والهدف لديه أيضًا سنام مميز من 250 إلى 500 مللي ثانية - وهذا هو P300 سيئ السمعة.
مع وجود مثل هذا الاختلاف في الإشارة ، قد تبدو مهمتنا مثل تافه ، ولكن إذا أضفنا الانحراف المعياري في كل نقطة إلى الرسم البياني ، فسنرى أن الصورة ليست وردية للغاية - الإشارة صاخبة للغاية. وهذا على الرغم من حقيقة أن نسبة الإشارة إلى الضوضاء في P300 تعتبر واحدة من أعلى النسب في الفسيولوجيا العصبية.
(في الواقع ، لا يتم بناء هذه الرسوم البيانية بأمانة إلى حد ما ، لأن الإشارة الفارغة يبلغ متوسطها أكثر من خمسة أضعاف العديد من العينات المختلفة ، لذلك يتم اختناق الانحرافات العشوائية أكثر ، ولكن كما نرى من تشتت نفس الترتيب ، فإن هذا لا يساعد كثيرًا)

من المفيد أيضًا النظر إلى متوسط إشارات شخص واحد.
تم العثور هنا على الملاحظة السابقة حول المتوسط "غير أمين" - الإشارة الفارغة هي أكبر بكثير من السعة مقارنة مع المتوسط. أيضا ، ذروة P300 في شخص واحد أعلى بسبب انخفاض المتوسط.
من المهم أن نلاحظ ميزة أخرى لإشارة شخص واحد - لها شكل مختلف قليلاً عن الشكل المعمم. التباين بين الأفراد للتفاعلات الفسيولوجية العصبية مرتفع للغاية ، سنرى تأثير هذا العامل في عمل المصنفات. ومع ذلك ، فإن الاختلافات الشخصية (شخص واحد في مزاج مختلف ، ومستوى التوتر ، والتعب) هي أيضًا كبيرة جدًا.

بعد ذلك ، نرى اكتساح كل قناة على حدة للإشارات. تتوافق وجهة النظر هنا مع الصورة أعلاه ، والتي توضح موقع الأقطاب الكهربائية - الأنف أعلاه ، إلخ.
استجابة كل جزء من الرأس مختلفة. عند Fp1،2 ، يتم إظهار ذروتين سالبين قبل القمة الإيجابية. أيضًا ، يوجد في بعض القنوات قمتان إيجابيتان ، وفي بعضهما - واحدة أو شيء انتقالي.
القنوات المختلفة لها أهمية مختلفة لتحديد وجود P300 ، ويمكن تقديرها باستخدام طرق مختلفة - حساب المعلومات المتبادلة (المعلومات المتبادلة) أو طريقة الإضافة - الحذف (ويعرف أيضًا باسم الانحدار التدريجي). تطبيق هذه الأساليب سنتعامل مع وقت آخر.
تجدر الإشارة إلى أننا نقيس الفرق المحتمل بين الأقطاب الكهربائية مع الأقطاب الكهربائية ، مما يعني أنه يمكننا بناء خرائط الجهد للرأس كله في بعض النقاط الزمنية باستخدام تغييرات الجهد عند نقاط فردية. من الواضح أنه إذا كان هناك 16 قطبًا ، فإن دقة هذه البطاقة تترك الكثير مما هو مرغوب فيه ، ولكن يجب تكوين بعض الفهم. (يتوقع mne بشكل افتراضي رؤية microvolts ، لكننا قمنا بالفعل بتطبيق القياس ، وبالتالي فإن القيم المطلقة غير صحيحة)

تصنيف
أخيرًا ، لقد حان الوقت لتطبيق أساليب التعلم الآلي على نموذجنا.
تم اختيار العديد من العناصر الأساسية مثل المصنفات - سجل. الانحدار ، طريقة متجه الدعم (SVM) ، والعديد من الطرق التي تستخدم تحليل الارتباط من حزمة pyriemann (يمكن الاطلاع على تفاصيل كل طريقة في الوثائق) ، تجدر الإشارة إلى أن هذه الطرق تم تطويرها خصيصًا للتطبيق على EEG وبمساعدتهم تم الفوز بالعديد من المسابقات kaggle.
clfs = { 'LR': ( make_pipeline(Vectorizer(), LogisticRegression()), {'logisticregression__C': np.exp(np.linspace(-4, 4, 9))}, ), 'LDA': ( make_pipeline(Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'SVM': ( make_pipeline(Vectorizer(), SVC()), {'svc__C': np.exp(np.linspace(-4, 4, 9))}, ), 'CSP LDA': ( make_pipeline(CSP(), LDA(shrinkage='auto', solver='eigen')), {'csp__n_components': (6, 9, 13), 'csp__cov_est': ('concat', 'epoch')}, ), 'Xdawn LDA': ( make_pipeline(Xdawn(2, classes=[1]), Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'ERPCov TS LR': ( make_pipeline(ERPCovariances(estimator='oas'), TangentSpace(), LogisticRegression()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), 'ERPCov MDM': ( make_pipeline(ERPCovariances(), MDM()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), }

المخطط الأكثر شيوعًا للواجهات العصبية هو "المعايرة + العمل" أي أولاً ، من الضروري أن يركز الشخص على المنبهات الموضحة مسبقًا لبعض الوقت ، وبعد ذلك فقط نتوقع اختياره. هذا النهج لديه عيب واضح للمرحلة الأولية مملة.
لتقييم أداء أساليبنا في هذا الوضع ، سنقوم بإجراء التحقق المتبادل في عصور شخص واحد.
لا يتوافق مقياس الدقة في هذه الحالة نظرًا لخلل مجموعة البيانات (خط الأساس هو 5/6 ~ 83٪ هنا) ، ولذا فإنني أفضل أن أنظر إلى الدقة-استدعاء-f1 الثلاثة.
لمراجعة مجموعة البيانات بأكملها ، نقوم بتقييم نتائج هذا التحقق المتبادل عبر جميع الأشخاص. بشكل عام ، أداء أفضل الموديلات مرتفع جدًا مقارنة بما لدينا في Neiry في ظروف "المجال" في متنزه (أذكر أنه تم تسجيل مجموعة البيانات هذه في المختبر).
في مجموعة البيانات هذه ، يوجد فقط تسميات ثنائية للبيانات. بشكل عام ، نحتاج إلى حل المشكلة متعددة الطبقات المتمثلة في اختيار أحد المحفزات (بالمناسبة ، يتم موازنته لأن كل محفز يتم تنشيطه بنفس عدد المرات). لحلها ، يتم عادةً تحديد عدد مرات تنشيط كل محفز (على سبيل المثال ، 6 محفزات لكل 5 تنشيط لكل منها) ويتم تنشيط جميع المحفزات بشكل عشوائي (30 مرة) ، ويتم الحصول على 30 حقبة ، وتضاف احتمالات تنشيطها إلى الهدف ، وبعد ذلك يتم تنشيط المحفزات يتم التعرف على المبلغ كهدف. سنبين تنفيذ هذا النهج في منشور مستقبلي على مجموعة بيانات مناسبة.

والمخطط الثاني يسمى نقل التعلم - أي نقل المصنف بين الناس. والحقيقة هي أنه عندما نقوم بالمعايرة ، فإننا نعود في الواقع إلى أعلى درجة لشخص واحد ، حتى نتمكن من التنبؤ بها جيدًا في الاختبارات اللاحقة. في حالة عدم وجود معايرة ، يجب أن يكون المصنف المُدرَّب مسبقًا قادرًا على عزل مفهوم P300 دون معرفة مسبقًا شكل الموجة لشخص معين.
سنجري تجربتين - سنقوم بتدريب المصنف على شخص واحد ، وسوف نتوقع خمسة ، ثم سنزيد عينة التدريب إلى 10 أشخاص ومقارنة النتائج للتأكد من أن النماذج كانت قادرة على زيادة قدرتها على التعميم
تدريب لشخص واحد

تدريب لمدة 10 أشخاص
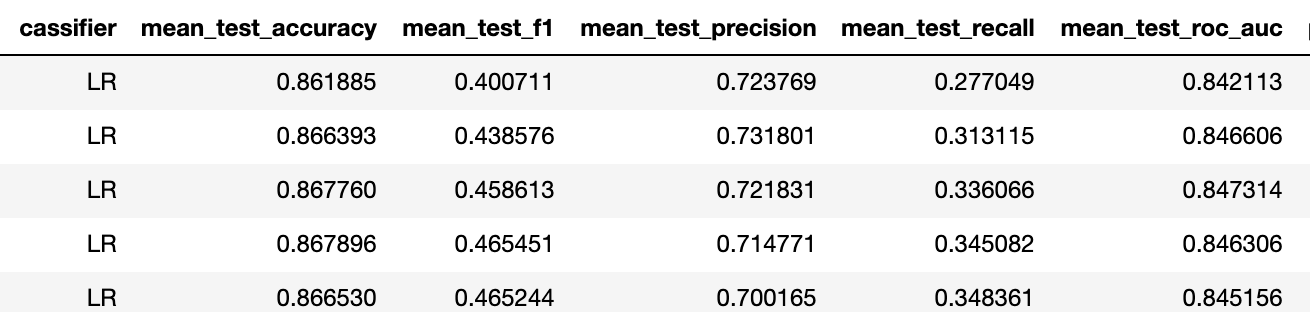
لذلك ارتفعت f1 من 0.23 إلى 0.4 لتصنيف أفضل (في كلتا الحالتين هو انحدار سجل مع نفس التنظيم).
هذا يعني أن القدرة التنبؤية زادت من "لا" إلى "مقبول". بناءً على تجربتنا ، مع مقاييس المهام الثنائية هذه ، فإن 5 عمليات تنشيط لكل محفز كافية لتحقيق دقة مشكلة متعددة الفئات تبلغ حوالي 75٪.
في النهاية ، أود أن أشير إلى أن الطريقة المذكورة أعلاه بدائية تمامًا ، والتي يمكن رؤيتها ، على سبيل المثال ، من خلال درجة عالية من تنظيم انحدار السجل - ترتبط القنوات الموجودة في البيانات بقوة شديدة وهناك عدة طرق لحل هذا الظرف.
استنتاج
اليوم ، أصبحنا أكثر دراية بالإمكانات التي أثارتها P300 وقمنا ببناء خط أنابيب بسيط للواجهة العصبية. أوصي المهتمين بفتح جهاز كمبيوتر محمول بمفردهم (الموجود في المستودع ) وتجربة خيارات التصور والمصنفات.
من خلال فهمنا الأساسي لأساليب العمل مع إشارة EEG ، سنكون قادرين على دراسة هذا الموضوع بمزيد من التعمق - لتطبيق أساليب المعالجة المسبقة المتقدمة ، وكذلك الشبكات العصبية ، لحل مشاكل بناء واجهات عصبية. أن تستمر ...