على مدار الأعوام القليلة الماضية ، قمت بتصميم وتصنيع آلة يمكنها التعرف على أجزاء LEGO وفرزها. الجزء الأكثر أهمية في الجهاز هو
Capture Unit ، وهي عبارة عن مقصورة صغيرة مغلقة بالكامل تقريبًا يوجد بها حزام ناقل وإضاءة وكاميرا.
الإضاءة سترى أقل قليلا.تلتقط الكاميرا صوراً لأجزاء LEGO القادمة عبر الناقل ، ثم تنقل الصور لاسلكيًا إلى خادم يقوم بتشغيل خوارزمية ذكاء اصطناعية للتعرف على الجزء بين الآلاف من عناصر LEGO المحتملة. سوف أخبركم المزيد عن خوارزمية الذكاء الاصطناعي في المقالات المستقبلية ، وسوف تركز هذه المقالة على المعالجة التي تتم بين الإخراج الخام لكاميرا الفيديو والإدخال إلى الشبكة العصبية.
كانت المشكلة الرئيسية التي كنت بحاجة إلى حلها هي تحويل دفق الفيديو من الناقل إلى صور منفصلة لأجزاء يمكن لشبكة عصبية استخدامها.
الهدف النهائي: التبديل من فيديو خام (على اليسار) إلى مجموعة من الصور من نفس الحجم (على اليمين) لنقلها إلى شبكة عصبية. (مقارنةً بالعمل الحقيقي ، فإن gif بطيئة تقريبًا)هذا مثال رائع لمهمة تبدو على السطح بسيطة ، ولكنها تفرض في الواقع العديد من العقبات الفريدة والمثيرة للاهتمام ، والكثير منها فريد في منصات رؤية الماكينة.
غالبًا ما يسمى استرداد الأجزاء الصحيحة من الصورة بهذه الطريقة "اكتشاف الكائنات". هذا هو بالضبط ما أحتاج إليه: التعرف على وجود الكائنات وموقعها وحجمها ، بحيث يمكنك إنشاء
مستطيلات محاطة لكل جزء في كل إطار.
الشيء الأكثر أهمية هو العثور على مربعات جيدة الربط (كما هو موضح أعلاه باللون الأخضر)سوف أفكر في ثلاثة جوانب لحل المشكلة:
- الاستعداد للقضاء على المتغيرات غير الضرورية
- إنشاء عملية من عمليات رؤية الماكينة البسيطة
- الحفاظ على الأداء الكافي على منصة Raspberry Pi ذات الموارد المحدودة
القضاء على المتغيرات غير الضرورية
في حالة هذه المهام ، من الأفضل إزالة أكبر عدد ممكن من المتغيرات قبل استخدام تقنيات رؤية الماكينة. على سبيل المثال ، لا ينبغي علي القلق بشأن الظروف البيئية ، ومواقع الكاميرا المختلفة ، وفقدان المعلومات بسبب تداخل بعض الأجزاء من قبل الآخرين. بالطبع ، من الممكن (وإن كان من الصعب جدًا) حل جميع هذه المتغيرات برمجيًا ، لكن لحسن الحظ ، يتم إنشاء هذا الجهاز من البداية. أنا شخصيا يمكنني الاستعداد لحل ناجح ، مع إزالة كل التداخل حتى قبل أن أبدأ كتابة التعليمات البرمجية.
تتمثل الخطوة الأولى في إصلاح موضع الكاميرا وزاوية الكاميرا وتركيزها. مع هذا ، كل شيء بسيط - في النظام ، يتم تثبيت الكاميرا فوق الناقل. لا داعي للقلق بشأن التدخل من أجزاء أخرى ؛ الكائنات غير المرغوب فيها ليس لها أي فرصة تقريبًا للدخول إلى وحدة الالتقاط. أكثر تعقيدًا قليلاً ، ولكن من المهم جدًا ضمان
ظروف إضاءة ثابتة . لا أحتاج إلى أداة التعرف على الكائنات لتفسير ظل الجزء المتحرك على طول الشريط ككائن مادي عن طريق الخطأ. لحسن الحظ ، وحدة الالتقاط صغيرة جدًا (مجال الرؤية الكامل للكاميرا أصغر من رغيف الخبز) ، لذلك كان لدي تحكم أكثر من اللازم في الظروف المحيطة.
التقاط وحدة ، المنظر الداخلي. الكاميرا في الثلث العلوي من الإطار.يتمثل أحد الحلول في جعل المقصورة مغلقة تمامًا بحيث لا توجد إضاءة خارجية. جربت هذا النهج باستخدام شرائط LED كمصدر إضاءة. لسوء الحظ ، تحول النظام إلى حالة مزاجية للغاية - يكفي وجود ثقب صغير واحد في العلبة ويكتفي الضوء داخل المقصورة ، مما يجعل من المستحيل التعرف على الأشياء.
في النهاية ، كان أفضل حل هو "تسد" جميع مصادر الإضاءة الأخرى عن طريق ملء المقصورة الصغيرة بضوء قوي. اتضح أن مصادر الإضاءة التي يمكن استخدامها لإضاءة المباني السكنية رخيصة جدًا وسهلة الاستخدام.
الحصول على الظل!عندما يتم توجيه المصدر إلى المقصورة الصغيرة ، فإنه يسد تمامًا كل التداخل المحتمل للضوء الخارجي. يكون لهذا النظام أيضًا تأثير جانبي مريح: نظرًا للكمية الكبيرة من الضوء في الكاميرا ، يمكنك استخدام سرعة الغالق العالية جدًا ، والحصول على صور واضحة تمامًا للأجزاء حتى عند التحرك بسرعة على طول الناقل.
التعرف على الأشياء
كيف تمكنت من تحويل هذا الفيديو الجميل ذي الإضاءة الموحدة إلى الصناديق المحيطة التي أحتاجها؟ إذا كنت تعمل مع AI ، فيمكنك اقتراح أن أقوم بتطبيق شبكة عصبية للتعرف على الكائنات مثل
YOLO أو
Faster R-CNN . يمكن لهذه الشبكات العصبية التعامل بسهولة مع المهمة. لسوء الحظ ، أنا تنفيذ رمز التعرف على الكائن على
توت العليق بي . حتى الكمبيوتر القوي سيواجه مشاكل في تنفيذ هذه الشبكات العصبية التلافيفية بتردد احتاجه حوالي 90 إطارًا في الثانية. ولم يتمكن Raspberry pi ، الذي لا يحتوي على وحدة معالجة الرسومات (GPU) المتوافقة مع AI ، من التعامل مع إصدار متجرد جدًا من إحدى خوارزميات AI هذه. يمكنني دفق الفيديو من Pi إلى كمبيوتر آخر ، ولكن نقل الفيديو في الوقت الفعلي هو عملية مزاجية للغاية ، والتأخير وحدود النطاق الترددي تسبب مشاكل خطيرة ، لا سيما عندما تحتاج إلى سرعة نقل بيانات عالية.
YOLO رائع جدا! لكنني لست بحاجة إلى كل وظائفها.لحسن الحظ ، يمكنني تجنب حل صعب قائم على الذكاء الاصطناعي باستخدام تقنيات رؤية الماكينات "القديمة". الأسلوب الأول هو
الطرح في الخلفية ، والذي يحاول عزل جميع الأجزاء التي تم تغييرها في الصورة. في حالتي ، الشيء الوحيد الذي يتحرك في مجال رؤية الكاميرا هو تفاصيل LEGO. (بالطبع ، يتحرك الشريط أيضًا ، ولكن نظرًا لأنه يحتوي على لون موحد ، يبدو أنه ثابت للكاميرا). افصل تفاصيل LEGO هذه عن الخلفية ، وتم حل نصف المشكلة.
لطرح الخلفية للعمل ، يجب أن تكون الكائنات الأمامية مختلفة بشكل كبير عن الخلفية. تحتوي تفاصيل LEGO على مجموعة واسعة من الألوان ، لذلك اضطررت إلى اختيار لون الخلفية بعناية فائقة بحيث كان بعيدًا قدر الإمكان عن ألوان LEGO. هذا هو السبب في أن الشريط الموجود أسفل الكاميرا مصنوع من الورق - فهو لا يحتاج فقط إلى أن يكون متجانسًا جدًا ، ولكن لا يمكن أن يتكون من LEGO ، وإلا فإنه سيكون له لون واحد من الأجزاء التي أحتاج إلى التعرف عليها! اخترت اللون الوردي الفاتح ، ولكن أي لون باستيل آخر ، على عكس ألوان LEGO العادية ، سيفعل.
تحتوي مكتبة OpenCV الرائعة بالفعل على عدة خوارزميات للطرح في الخلفية. MOG2 Background Subtractor هو أكثرها تعقيدًا ، وفي الوقت نفسه يعمل بسرعة مذهلة حتى في بي التوت. ومع ذلك ، فإن تغذية إطارات الفيديو مباشرة إلى MOG2 لا يعمل بشكل جيد للغاية. الأشكال الرمادية والأبيض الفاتحة قريبة جدًا من سطوع الخلفية الشاحبة وتضيع عليها. كنت بحاجة إلى الخروج بطريقة أكثر وضوحًا لفصل الشريط عن الأجزاء الموجودة عليه ، وطلبًا من مُطرح الخلفية أن ينظر عن كثب إلى
اللون ، وليس إلى
السطوع . للقيام بذلك ، كان يكفي بالنسبة لي زيادة تشبع الصور قبل نقلها إلى مُطرح الخلفية. تحسنت النتائج بشكل كبير.
بعد طرح الخلفية ، كنت بحاجة لاستخدام العمليات المورفولوجية للتخلص من أكبر قدر ممكن من الضوضاء. للعثور على حدود المناطق البيضاء ، يمكنك استخدام وظيفة findContours () لمكتبة OpenCV. من خلال تطبيق الأساليب البحثية المختلفة لتحويل الحلقات التي تحتوي على الضوضاء ، يمكنك بسهولة تحويل هذه الحلقات إلى مربعات محيط محددة مسبقًا.
إنتاجية
الشبكة العصبية هي مخلوق شره. للحصول على أفضل النتائج في التصنيف ، فإنها تحتاج إلى صور ذات الدقة القصوى وبكميات كبيرة قدر الإمكان. هذا يعني أنني بحاجة إلى إطلاق النار عليهم بمعدل إطارات مرتفع للغاية ، مع الحفاظ على جودة الصورة ودقة الوضوح. لا بد لي من الضغط على أقصى حد ممكن للخروج من الكاميرا و GPU Raspberry PI.
تشير
وثائق مفصلة للغاية
عن بيكاميرا إلى أن شريحة كاميرا V2 يمكنها إنتاج صور بحجم 1280 × 720 بكسل بحد أقصى 90 إطارًا في الثانية. هذه كمية لا تصدق من البيانات ، وعلى الرغم من أن الكاميرا يمكن أن تنشئها ، فإن هذا لا يعني أن الكمبيوتر يمكنه التعامل معها. إذا كنت سأقوم بمعالجة صور RGB خام 24 بت ، فسيتعين علي نقل البيانات بسرعة تبلغ حوالي 237 ميجابايت / ثانية ، وهذا أكثر من اللازم لكل من وحدة معالجة الرسومات الضعيفة للكمبيوتر Pi و SDRAM. حتى عند استخدام الضغط المتسارع GPU في JPEG ، لا يمكن تحقيق 90 إطارًا في الثانية.
Raspberry Pi قادر على عرض صور YUV خام غير مصفاة. على الرغم من صعوبة العمل مع RGB ، فإن YUV لديها بالفعل العديد من الخصائص المريحة. الأكثر أهمية هو أنه يخزن فقط 12 بت لكل بكسل (RGB هو 24 بت).
كل أربعة بايتات من Y تحتوي على بايت واحد U وواحد بايت ، أي 1.5 بايت لكل بكسل.هذا يعني أنه بالمقارنة بإطارات RGB ، يمكنني معالجة
ضعف عدد إطارات YUV ، وهذا لا يحسب الوقت الإضافي الذي يوفره GPU عند التحويل إلى صورة RGB.
ومع ذلك ، يفرض هذا الأسلوب قيودًا فريدة على عملية المعالجة. تستهلك معظم العمليات باستخدام إطار فيديو بالحجم الكامل مقدارًا كبيرًا جدًا من الذاكرة وموارد وحدة المعالجة المركزية. ضمن الحدود الزمنية الصارمة ، لا يمكن فك تشفير إطار YUV بملء الشاشة.
لحسن الحظ ، لست بحاجة إلى معالجة الإطار بأكمله! للتعرف على الكائنات ، لا يجب أن تكون المستطيلات المحيطية دقيقة ، فالدقة التقريبية كافية ، وبالتالي يمكن تنفيذ العملية الكاملة للتعرف على الكائنات باستخدام إطار أصغر بكثير. لا يلزم تشغيل عملية التصغير لأخذ جميع وحدات البكسل في إطار بالحجم الكامل في الاعتبار ، بحيث يمكن تقليل الإطارات بسرعة كبيرة وبدون تكلفة. ثم يزداد حجم المستطيلات المحيطية الناتجة مرة أخرى ويستخدم لقطع الكائنات من إطار YUV كامل الحجم. بفضل هذا ، لست بحاجة إلى فك تشفير أو معالجة الإطار عالي الدقة بالكامل.
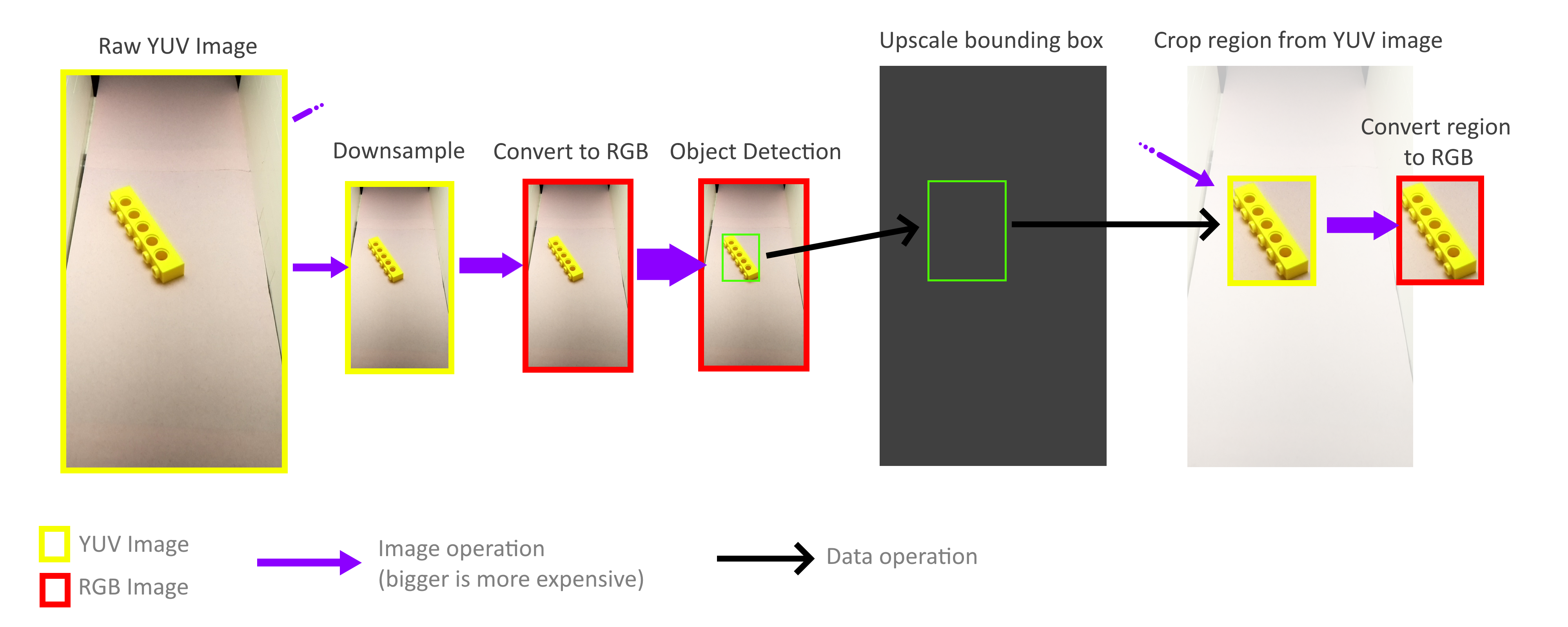
لحسن الحظ ، بفضل طريقة التخزين في تنسيق YUV هذا (انظر أعلاه) ، من السهل جدًا تنفيذ عمليات الاقتصاص والتكبير السريعة التي تعمل مباشرةً مع تنسيق YUV. بالإضافة إلى ذلك ، يمكن موازاة العملية برمتها إلى أربعة مراكز أساسية بدون أي مشاكل. ومع ذلك ، اكتشفت أنه لا يتم استخدام جميع النوى لتحقيق إمكاناتها الكاملة ، وهذا يخبرنا أن عرض النطاق الترددي للذاكرة لا يزال عنق الزجاجة. ولكن رغم ذلك ، تمكنت من تحقيق 70-80FPS في الممارسة العملية. قد يساعد التحليل الأعمق لاستخدام الذاكرة في تسريع الأمور بشكل أكبر.
إذا كنت تريد معرفة المزيد عن المشروع ، فاقرأ مقالتي السابقة ،
"كيف صنعت أكثر من 100 ألف صورة LEGO للتعلم" .
فيديو لتشغيل آلة الفرز بأكملها: