سأستمر في تحليل غير مستعجل لتنفيذ الأنواع الأساسية في CPython ، وكانت
القواميس والأعداد الصحيحة تعتبر في السابق. أولئك الذين يعتقدون أنه لا يمكن أن يكون هناك شيء مثير للاهتمام ومكر في تنفيذها يتم تشجيعهم على الانضمام إلى هذه المقالات. أولئك الذين قرأوهم بالفعل يعرفون أن CPython لديه العديد من الميزات وميزات التطبيق المثيرة للاهتمام. قد يكون من المفيد معرفتها عند كتابة البرامج النصية الخاصة بك ، أو كدليل للحلول المعمارية والخوارزمية. السلاسل ليست استثناء هنا.
لنبدأ باستطراد قصير في التاريخ. ظهر بيثون في 1990-1991. في البداية ، عند تطوير ترميز القاعدة في بيثون ، كان هناك أسكي القديم ذو البايت الواحد. ولكن في الوقت نفسه تقريبًا (بعد ذلك بقليل) ، سئمت البشرية من التعامل مع "حديقة الحيوان" الخاصة بالتشفيرات ، وفي عام 1991 تم اقتراح معيار Unicode. ومع ذلك ، في المرة الأولى التي لم تنجح أيضا. بدأ إدخال ترميزات ثنائية البايت ، لكن سرعان ما أصبح من الواضح أن وحدتي بايت لن تكون كافية للجميع ، تم اقتراح ترميز ذي 4 بايت. لسوء الحظ ، يبدو تخصيص 4 بايت لكل حرف بمثابة مضيعة لمساحة القرص والذاكرة ، خاصة في تلك البلدان حيث كان ascii بايت واحد يكفي قبل. تم نشر العديد من العكازات في ترميز ثنائي البايت لدعم المزيد من الشخصيات ، وبدأ كل هذا في تشبيه الوضع السابق بـ "حديقة الحيوان" الخاصة بالترميزات.
ولكن في عام 1993 تم تقديم برنامج utf-8. كان هذا حلاً وسطًا: لقد كانت ascii مجموعة فرعية صالحة من utf-8 ، وسعت جميع الشخصيات الأخرى ، ومع ذلك ، لدعم هذا الاحتمال ، اضطررت إلى الفصل بطول ثابت من كل حرف. ولكن كان هو الذي كان مقدراً له أن
يحكم الجميع ليصبح Unicode بالضبط ، أي ترميز واحد يدعمه معظم البرامج التي يتم تخزين معظم الملفات فيها. وقد تأثر هذا بشكل خاص بتطور الإنترنت ، لأن صفحات الويب عادة ما تستخدم فقط utf-8.
تم تقديم دعم هذا الترميز تدريجيًا إلى لغات البرمجة التي تم تطويرها ، مثل بيثون ، قبل utf-8 ، وبالتالي استخدمت ترميزات أخرى. هناك
PEP مع رقم 100 لطيف ناقش دعم Unicode. وفي
PEP-0263 ، أصبح من الممكن إعلان ترميز الملفات المصدر. كان الترميز لا يزال هو الترميز الأساسي ، حيث تم استخدام البادئة "u" لإعلان سلاسل يونيكود ، والعمل معها لم يكن مريحًا وطبيعيًا بدرجة كافية. ولكن كانت هناك فرصة لإنشاء البدعة التالية:
class 비빔밥: _ = 2 א = 비빔밥() print(א)
في 3 كانون الأول (ديسمبر) 2008 ، وقع حدث تاريخي لمجتمع الثعبان بأكمله (وبالنظر إلى مدى انتشار هذه اللغة الآن ، ربما ، للعالم بأسره) - تم إصدار الثعبان 3. تم تحديد وضع حد للمشاكل مرة واحدة وإلى الأبد بسبب العديد من الترميزات ، وبالتالي أصبح Unicode الترميز الأساسي. لكننا نتذكر أن الترميز معقد ولا ينجح في المرة الأولى. لم تنجح هذه المرة أيضًا.
العيب الكبير في utf-8 هو أن طول الحرف غير ثابت ، مما يؤدي إلى حقيقة أن مثل هذه العملية البسيطة مثل الوصول إلى الفهرس لها تعقيد O (N) ، لأن إزاحة العنصر غير معروف مقدمًا ، بالإضافة إلى معرفة حجم المخزن المؤقت ، المخصصة لتخزين سلسلة ، لا يمكنك حساب طولها في الأحرف.
من أجل تجنب كل هذه المشاكل في الثعبان ، تقرر استخدام ترميزات ثنائية و 4 بايت (حسب النظام الأساسي). تم تبسيط التعامل مع الفهرس - كان من الضروري فقط مضاعفة الفهرس بمقدار 2 أو 4. ومع ذلك ، فقد استتبع هذا مشاكله:
- كان لكل نظام أساسي ترميز خاص به ، مما قد يؤدي إلى مشاكل في إمكانية نقل التعليمات البرمجية
- زيادة استهلاك الذاكرة و / أو مشاكل الترميز للأحرف الصعبة التي لا تنسجم مع وحدتي بايت
تم اقتراح حل لهذه المشكلات في
PEP-393 ، وسوف نتحدث عنها.
تقرر ترك الأسطر كصفيف من الأحرف ، لتسهيل الوصول حسب الفهرس والعمليات الأخرى ، ومع ذلك ، بدأ طول الأحرف يتغير. عند إنشاء سلسلة ، يقوم المترجم بمسح جميع الأحرف ويخصص لكل عدد من وحدات البايت الضرورية لتخزين "الأكبر" ، أي إذا أعلنت سلسلة ascii ، فستكون جميع الأحرف أحادية البايت ، ولكن إذا قررت إضافة حرف واحد إلى السلسلة من السيريلية ، ستكون جميع الشخصيات بالفعل ثنائية البايت. هناك ثلاثة خيارات ممكنة: 1 و 2 و 4 بايت لكل حرف.
يتم تعريف نوع السلسلة (PyUnicodeObject)
كما يلي :
typedef struct { PyCompactUnicodeObject _base; union { void *any; Py_UCS1 *latin1; Py_UCS2 *ucs2; Py_UCS4 *ucs4; } data; } PyUnicodeObject;
بدوره ، يمثل PyCompactUnicodeObject
البنية التالية (المتوفرة مع بعض التبسيط وتعليقاتي):
typedef struct { PyASCIIObject _base; Py_ssize_t utf8_length; char *utf8; Py_ssize_t wstr_length; } PyCompactUnicodeObject; typedef struct { PyObject_HEAD Py_ssize_t length; Py_hash_t hash; struct { unsigned int interned:2; unsigned int kind:3; unsigned int compact:1; unsigned int ascii:1; unsigned int ready:1; unsigned int :24; } state; wchar_t *wstr; } PyASCIIObject;
وبالتالي ، يمكن تمثيل 4 خطوط:
- سلسلة إرث ، جاهزة
* structure = PyUnicodeObject structure * : !PyUnicode_IS_COMPACT(op) && kind != PyUnicode_WCHAR_KIND * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 0 * ready = 1 * data.any is not NULL * utf8 data.any utf8_length = length ascii = 1 * utf8_length = 0 utf8 is NULL * wstr with data.any wstr_length = length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_4)=4 * wstr_length = 0 wstr is NULL
- سلسلة إرث ، ليست جاهزة
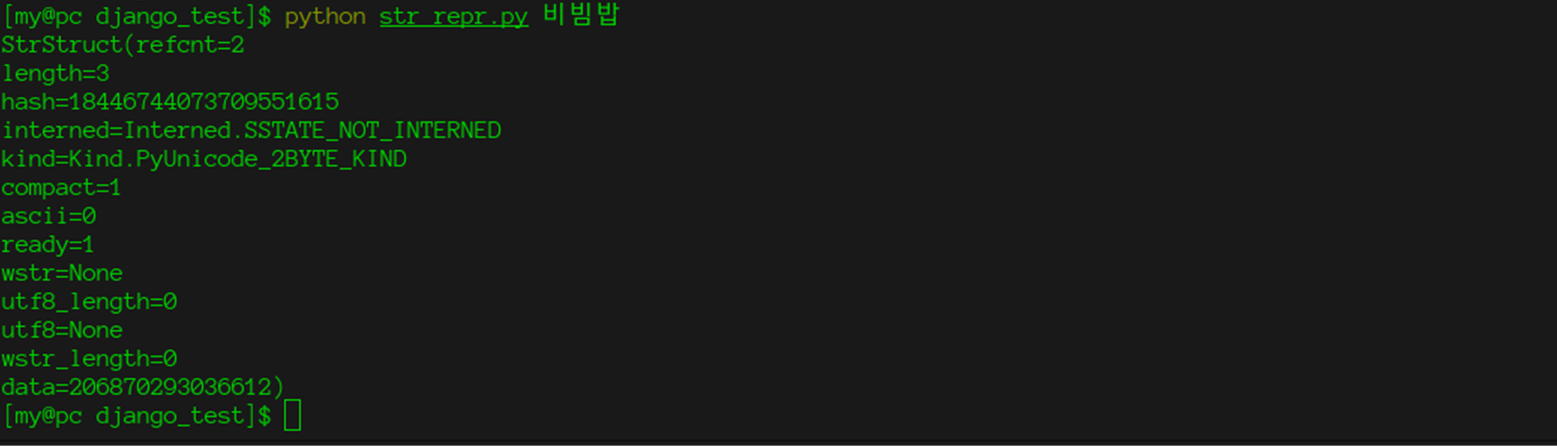
* structure = PyUnicodeObject * : kind == PyUnicode_WCHAR_KIND * length = 0 (use wstr_length) * hash = -1 * kind = PyUnicode_WCHAR_KIND * compact = 0 * ascii = 0 * ready = 0 * interned = SSTATE_NOT_INTERNED * wstr is not NULL * data.any is NULL * utf8 is NULL * utf8_length = 0
- أسكي المدمجة
* structure = PyASCIIObject * : PyUnicode_IS_COMPACT_ASCII(op) * kind = PyUnicode_1BYTE_KIND * compact = 1 * ascii = 1 * ready = 1 * (length — utf8 wstr ) * (data ) * ( ascii utf8 string data)
- اتفاق
* structure = PyCompactUnicodeObject * : PyUnicode_IS_COMPACT(op) && !PyUnicode_IS_ASCII(op) * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 1 * ready = 1 * ascii = 0 * utf8 data * utf8_length = 0 utf8 is NULL * wstr data wstr_length=length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_t)=4 * wstr_length = 0 wstr is NULL * (data )
تجدر الإشارة إلى أن python 3 يدعم أيضًا بناء الجملة لإعلان سلاسل يونيكود عبر بادئة "u".
>>> b = u"" >>> b ''
تمت إضافة هذه الميزة لتسهيل رمز النقل من الإصدار الثاني إلى الإصدار الثالث في
PEP-414 في python 3.3 فقط في فبراير 2012 ، واسمحوا لي أن أذكركم بأن python 3 قد تم إصداره في ديسمبر 2008 ، ولكن لم يكن أحد في عجلة من أمره مع الانتقال.
مسلحين بهذه المعرفة ووحدة ctypes القياسية ، يمكننا الوصول إلى الحقول الداخلية للسلسلة.
import ctypes import enum import sys class Interned(enum.Enum):
وحتى "كسر" المترجم ، كما فعلت في
الجزء السابق .
إخلاء المسئولية: يتم توفير الكود التالي كما هو ، لا يتحمل المؤلف أية مسؤولية ولا يمكنه ضمان حالة المترجم الشفهي ، وكذلك الصحة النفسية لك ولزملائك ، بعد تشغيل هذا الكود. تم اختبار الكود على cpython الإصدار 3.7 ، وللأسف ، لا يعمل مع سلاسل ascii.
للقيام بذلك ، قم بتغيير الكود الموضح أعلاه إلى:
def make_some_magic(str1, str2): s1 = StrStruct.from_address(id(str1)) s2 = StrStruct.from_address(id(str2)) s2.data = s1.data if __name__ == '__main__': string = "비빔밥" string2 = "háč" print(string == string2)
تستخدم هذه الأمثلة الاستيفاء سلسلة المضافة في
بيثون 3.6 . لم يأت Python على الفور إلى طريقة إخراج السلاسل:٪ بناء جملة ، تنسيق ، شيء
مثل perl جرب (يمكن العثور على وصف أكثر تفصيلًا مع أمثلة
هنا ).
ربما كان هذا التغيير لوقته (قبل الثعبان 3.8 مع عامل التشغيل `: =`) هو الأكثر إثارة للجدل. وقد أجريت المناقشة (والإدانة) على حد سواء على
reddit وحتى في شكل
PEP . تم التعبير عن أفكار التحسين / التصحيح في شكل إضافة
خطوط i يمكن للمستخدمين من خلالها كتابة محللاتهم ، من أجل التحكم بشكل أفضل وتجنب حقن SQL والمشاكل الأخرى. ومع ذلك ، تم تأجيل هذا التغيير ، بحيث يعتاد الناس على الخطوط وتحديد المشاكل ، إن وجدت.
تحتوي السطور F على خصوصية واحدة (العيب): لا يمكنك تحديد أحرف خاصة بها مائلة ، على سبيل المثال ، \ \ '' \ t '. ومع ذلك ، يمكن التحايل على ذلك بسهولة عن طريق إعلان سطر منفصل يحتوي على أحرف خاصة ونقله إلى السطر f ، والذي تم في المثال أعلاه ، ولكن يمكنك استخدام الأقواس المتداخلة.
>>> number = 2 >>> precision = 3 >>> f"{number:.{precision}f}" 2.000
كما ترون ، تخزن السلاسل التجزئة الخاصة بهم ؛ كان هناك
اقتراح لاستخدام هذه القيمة لمقارنة السلاسل ، استنادًا إلى قاعدة بسيطة: إذا كانت السلاسل متماثلة ، عندها تحتوي على نفس العلامة ، ويترتب على ذلك أن السلاسل ذات تجزئة مختلفة ليست هي نفسها. ومع ذلك ، فإنه لم يتحقق.
عند مقارنة سلسلتين ، يتم التحقق مما إذا كانت المؤشرات إلى السلاسل تشير إلى نفس العنوان ، إن لم يكن ، فستبدأ مقارنة حرف بحرف أو memcmp في الحالات التي يُسمح فيها بذلك.
int PyUnicode_Compare(PyObject *left, PyObject *right) { if (PyUnicode_Check(left) && PyUnicode_Check(right)) { if (PyUnicode_READY(left) == -1 || PyUnicode_READY(right) == -1) return -1; if (left == right) return 0; return unicode_compare(left, right);
ومع ذلك ، فإن قيمة التجزئة تؤثر بشكل غير مباشر على المقارنة. والحقيقة هي أنه في cpython ، يتم تدوين السلاسل ، أي تخزينها في قاموس واحد. لا ينطبق هذا على جميع الأسطر ، حيث يتم تدريب جميع الثوابت ومفاتيح القاموس والحقول والمتغيرات وخطوط أسكي بطول أقل من 20.
if __name__ == '__main__': string = sys.argv[1] string2 = sys.argv[2] print(id(string) == id(string2))
$ python check_interned.py aa True $ python check_interned.py 비빔밥 비빔밥 False $ python check_interned.py aaaaaaaaaaaaaaaaaaaaaaaaaaaaa aaaaaaaaaaaaaaaaaaaaaaaaaaaaa False
والسلسلة الفارغة عمومًا مفردة
static PyUnicodeObject * _PyUnicode_New(Py_ssize_t length) { PyUnicodeObject *unicode; size_t new_size; if (length == 0 && unicode_empty != NULL) { Py_INCREF(unicode_empty); return (PyUnicodeObject*)unicode_empty; } ... }
كما نرى ، كان cpython قادراً على إنشاء تطبيق بسيط ولكن فعال في نفس الوقت لنوع السلسلة. كان من الممكن تقليل الذاكرة المستخدمة وتسريع العمليات في بعض الحالات ، وذلك بفضل memcmp ، وظائف memcpy ، بدلاً من العمليات التي تتم على أساس حرف. كما ترون ، فإن نوع السلسلة ليس سهلاً على الإطلاق لأنه قد يبدو في المرة الأولى. لكن المطورين cpython قد اقتربوا بمهارة من أعمالهم ، وبالتالي يمكننا استخدامها ولا حتى التفكير في ما تحت غطاء محرك السيارة.