 ماذا؟
ماذا؟ برنامج ترميز الفيديو هو جزء من البرامج / الأجهزة التي تعمل على ضغط و / أو إلغاء ضغط الفيديو الرقمي.
من اجل ماذا؟ على الرغم من بعض القيود من حيث عرض النطاق الترددي ،
ومن حيث مساحة التخزين ، يتطلب السوق المزيد والمزيد من الفيديو عالي الجودة. تذكر كيف في آخر مشاركة قمنا بحساب الحد الأدنى الضروري لمدة 30 لقطة في الثانية الواحدة ، 24 بت لكل بكسل ، بدقة 480 × 240؟ تلقى 82.944 ميغابت في الثانية دون ضغط. يعد الضغط هو الطريقة الوحيدة لنقل HD / FullHD / 4K إلى شاشات التلفزيون والإنترنت. كيف يتحقق هذا؟ الآن سوف ننظر لفترة وجيزة في الطرق الرئيسية.

تمت الترجمة بدعم من برنامج EDISON.
نحن منخرطون في تكامل أنظمة المراقبة بالفيديو ، بالإضافة إلى تطوير صورة مجهرية .
حاوية الترميز مقابل الحاوية
من الأخطاء الشائعة للمبتدئين الخلط بين برنامج ترميز الفيديو الرقمي وحاوية الفيديو الرقمية. الحاوية هي تنسيق معين. غلاف يحتوي على بيانات تعريف الفيديو (وربما الصوت). يمكن اعتبار الفيديو المضغوط بمثابة حمولة حاوية.
عادةً ما يشير امتداد ملف الفيديو إلى نوع الحاوية. على سبيل المثال ، من المرجح أن يكون ملف video.mp4 عبارة عن حاوية
MPEG-4 Part 14 ، ويكون الملف المسمى video.mkv
دمية روسية على الأرجح. لكي تكون واثقًا تمامًا من تنسيق برنامج الترميز والحاوية ، يمكنك استخدام
FFmpeg أو
MediaInfo .
قليلا من التاريخ
قبل أن نصل إلى
كيف؟ ، دعنا نتعمق في التاريخ لنفهم بعضًا من بعض برامج الترميز القديمة.
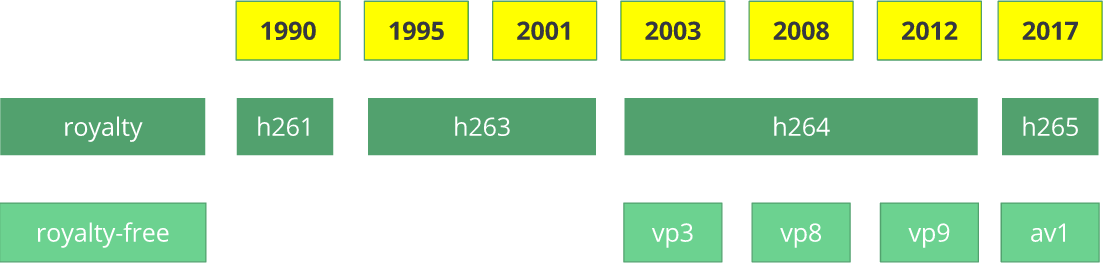
ظهر برنامج ترميز الفيديو
H.261 في عام 1990 (تقنيًا - في عام 1988) وتم إنشاؤه للعمل بمعدل نقل بيانات يبلغ 64 كيلوبت في الثانية. لقد استخدم بالفعل أفكارًا مثل أخذ العينات الفرعية للألوان ، و macroblocks ، إلخ. في عام 1995 ، تم نشر معيار ترميز الفيديو
H.263 ، والذي تم تطويره حتى عام 2001.
في عام 2003 ، تم الانتهاء من الإصدار الأول من
H.264 / AVC . في نفس العام ، أصدرت TrueMotion فيديو ترميز ضغط الفيديو الفاسد المجاني والذي يدعى
VP3 . في عام 2008 ، اشترت Google هذه الشركة ، وأصدرت
VP8 في نفس العام. في ديسمبر 2012 ، أصدرت Google
VP9 ، وهي مدعومة في حوالي
نصف سوق المتصفح (بما في ذلك الأجهزة المحمولة).
AV1 هو برنامج ترميز فيديو مجاني ومفتوح المصدر تم تطويره
بواسطة Open Media Alliance (
AOMedia ) ، والذي يتضمن شركات معروفة مثل Google و Mozilla و Microsoft و Amazon و Netflix و AMD و ARM و NVidia و Intel و Cisco . تم نشر الإصدار الأول من برنامج الترميز 0.1.0 في 7 أبريل 2016.
ولادة AV1
في أوائل عام 2015 ، عملت Google على
VP10 ، وعملت
Xiph (التي تنتمي إلى Mozilla) على
Daala ،
وأعدت Cisco برنامج ترميز الفيديو المجاني المسمى
Thor .
ثم أعلنت
MPEG LA لأول مرة عن حدود سنوية لـ
HEVC (
H.265 ) ورسم أعلى بمقدار 8 أضعاف عن H.264 ، لكنها سرعان ما غيرت القواعد مرة أخرى:
لا يوجد حد سنوي ،
رسوم المحتوى (0.5 ٪ من الإيرادات) و
تكاليف الوحدة أعلى بحوالي 10 أضعاف من تكلفة H.264.
تم إنشاء
Open Media Alliance من قبل شركات من مختلف المجالات: الشركات المصنعة للمعدات (Intel و AMD و ARM و Nvidia و Cisco) وموفري المحتوى (Google و Netflix و Amazon) وصانعي المستعرضات (Google و Mozilla) وغيرها.
كان للشركات هدف مشترك - ترميز الفيديو دون حقوق. ثم تأتي
AV1 بترخيص براءة اختراع أبسط بكثير. قدم Timothy B. Terriberry عرضًا مذهلاً ، والذي أصبح مصدر المفهوم الحالي لـ AV1 ونموذج الترخيص الخاص به.
ستندهش عندما تعلم أنه يمكنك تحليل برنامج ترميز AV1 من خلال متصفح (يمكن للمهتمين الانتقال إلى
aomanalyzer.org ).

الترميز العالمي
دعونا نحلل الآليات الأساسية الكامنة وراء برنامج ترميز الفيديو العالمي. معظم هذه المفاهيم مفيدة وتستخدم في برامج الترميز الحديثة مثل
VP9 و
AV1 و
HEVC . أحذرك من أن الكثير من الأشياء الموضحة سيتم تبسيطها. في بعض الأحيان ، سيتم استخدام أمثلة من العالم الحقيقي (كما هو الحال مع H.264) لإظهار التكنولوجيا.
الخطوة الأولى - تقسيم الصورة
تتمثل الخطوة الأولى في تقسيم الإطار إلى عدة أقسام وأقسام فرعية والمزيد.

من اجل ماذا؟ هناك العديد من الأسباب. عندما نقوم بتقسيم الصورة ، يمكننا التنبؤ بدقة أكبر بموجه الحركة باستخدام مقاطع صغيرة للأجزاء المتحركة الصغيرة. بينما للحصول على خلفية ثابتة ، يمكنك قصر نفسك على أقسام أكبر.
عادةً ما تقوم برامج الترميز بتنظيم هذه المقاطع إلى أقسام (أو أجزاء) ، وحدات الماكرو (أو كتل شجرة الترميز) والعديد من الأقسام الفرعية. يختلف الحد الأقصى لحجم هذه الأقسام ، حيث يحدد HEVC 64 × 64 ، بينما يستخدم AVC 16 × 16 ، ويمكن تقسيم الأقسام الفرعية إلى 4x4.
تذكر أصناف الإطارات من المادة الأخيرة؟! يمكن تطبيق الشيء نفسه على الكتل ، حتى نتمكن من الحصول على جزء I ، جزء B ، كتلة P ، macroblock ، إلخ.
بالنسبة لأولئك الذين يريدون التدريب ، انظروا كيف سيتم تقسيم الصورة إلى أقسام وأقسام فرعية. للقيام بذلك ، يمكنك استخدام
محلل Intel Video Pro Analyzer ، الذي سبق ذكره في مقال سابق (المقال الذي يتم دفعه ، ولكن مع إصدار تجريبي مجاني ، له حد أقصى على الإطارات العشرة الأولى). يتم تحليل أقسام
VP9 هنا:

الخطوة الثانية - التنبؤ
بمجرد أن يكون لدينا أقسام ، يمكننا أن نجعل التنبؤات
الفلكية عليها. بالنسبة
للتنبؤ البيني ، من الضروري نقل
متجهات الحركة والباقي ، وينتقل
اتجاه التنبؤ والباقي إلى INTRA.
الخطوة الثالثة - التحويل
بعد أن نحصل على الكتلة المتبقية (القسم المتوقع → القسم الحقيقي) ، يمكن تحويله بطريقة تعرف على البكسلات التي يمكن التخلص منها ، مع الحفاظ على الجودة الشاملة. هناك بعض التحولات التي توفر سلوك دقيق.
على الرغم من وجود طرق أخرى ، دعنا نفكر بمزيد من التفصيل في
تحويل جيب التمام المنفصل (
DCT - من
تحويل جيب التمام المنفصل ). الملامح الرئيسية ل DCT:
- يحول كتل البكسل إلى كتل متساوية الحجم لمعاملات التردد.
- الأختام السلطة ، مما يساعد في القضاء على التكرار المكاني.
- يوفر انعكاس.
2 فبراير ، 2017 سينترا ر. (سينترا ، الملكية الأردنية) وباير إف إم (Bayer FM) نشر مقالة حول التحويلات المشابهة لـ DCT لضغط الصور ، والتي لا تتطلب سوى 14 إضافة.
لا تقلق إذا كنت لا تفهم فوائد كل عنصر. الآن ، مع أمثلة ملموسة ، سوف نتحقق من قيمتها الحقيقية.
دعنا نأخذ كتلة 8 × 8 بكسل مثل هذا:
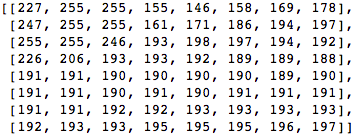
يتم عرض هذه الكتلة في الصورة التالية 8 × 8 بكسل:
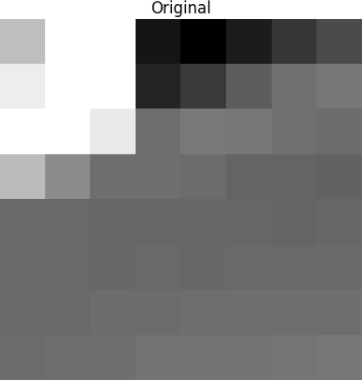
قم بتطبيق DCT على مجموعة البكسل هذه واحصل على مجموعة من المعاملات بحجم 8 × 8:
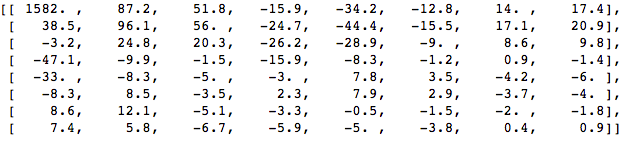
وإذا عرضنا مجموعة المعاملات هذه ، فسنحصل على الصورة التالية:
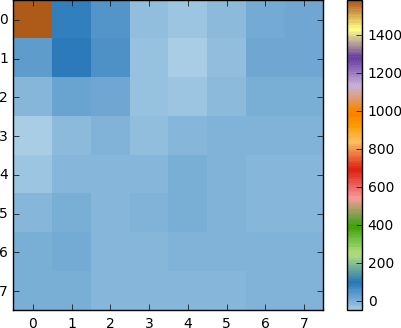
كما ترون ، هذا ليس مثل الصورة الأصلية. قد تلاحظ أن المعامل الأول يختلف اختلافًا كبيرًا عن المعامل الأخرى. يُعرف هذا المعامل الأول بأنه معامل DC الذي يمثل جميع العينات في صفيف الإدخال ، وهو ما يشبه القيمة المتوسطة.
هذه المجموعة من المعاملات لها خاصية مثيرة للاهتمام: فهي تفصل المكونات عالية التردد عن المكونات المنخفضة التردد.
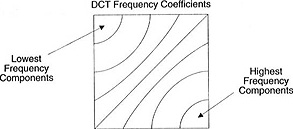
في الصورة ، تتركز معظم الطاقة عند الترددات المنخفضة ، لذلك ، إذا قمت بتحويل الصورة إلى مكونات ترددها وتجاهلت معاملات التردد الأعلى ، فيمكنك تقليل كمية البيانات اللازمة لوصف الصورة دون التضحية بجودة الصورة أكثر من اللازم.
التردد يعني سرعة تغير الإشارة.
دعونا نحاول تطبيق المعرفة المكتسبة في مثال الاختبار عن طريق تحويل الصورة الأصلية إلى ترددها (كتلة المعاملات) باستخدام DCT ، ثم تجاهل بعض المعاملات الأقل أهمية.
أولاً ، قم بتحويله إلى مجال التردد.
بعد ذلك ، نتخلص من جزء (67 ٪) من المعاملات ، وخاصة الجانب السفلي الأيمن.
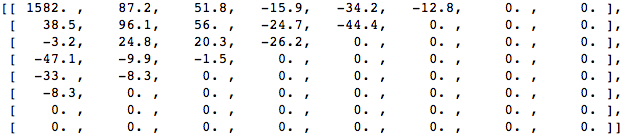
أخيرًا ، نستعيد الصورة من مجموعة المعاملات المهملة هذه (تذكر ، يجب أن تكون قابلة للعكس) ومقارنتها بالأصل.
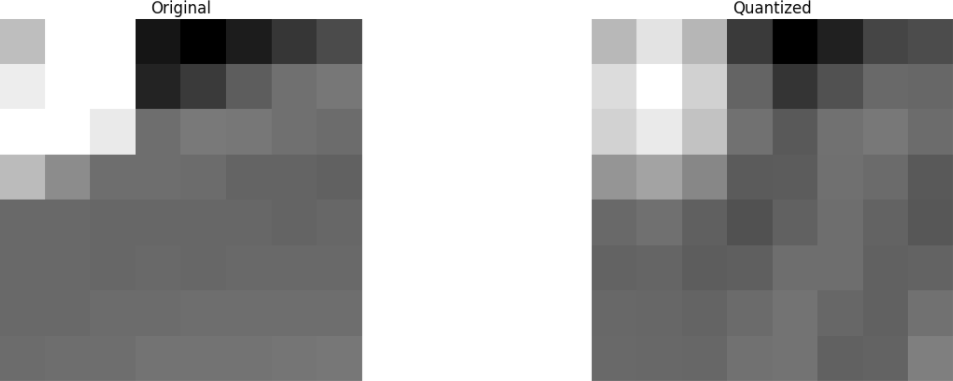
نرى أنها تشبه الصورة الأصلية ، ولكن هناك العديد من الاختلافات عن الصورة الأصلية. ألقينا 67.1875 ٪ وما زال لدينا شيء يشبه المصدر الأصلي. يمكنك تجاهل المعاملات بشكل متعمد للحصول على صورة ذات جودة أفضل ، ولكن هذا هو الموضوع التالي.
يتم إنشاء كل معامل باستخدام جميع بكسل.
هام: لا يتم عرض كل معامل مباشرةً على بكسل واحد ، ولكنه عبارة عن مجموع موزون لكل وحدات البكسل. يوضح هذا الرسم البياني المدهش كيف يتم حساب المعاملتين الأولى والثانية باستخدام أوزان فريدة لكل مؤشر.
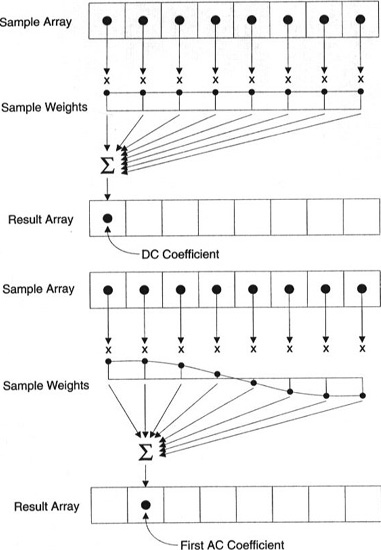
يمكنك أيضًا محاولة تصور DCT من خلال النظر إلى التصوير البسيط بناءً عليه. على سبيل المثال ، إليك الرمز A الذي تم إنشاؤه باستخدام كل وزن للمعامل:

4th الخطوة - الكمي
بعد أن نطرح بعض المعاملات في الخطوة السابقة ، في الخطوة الأخيرة (التحول) ، ننتج نموذجًا خاصًا للتكميم. في هذه المرحلة ، يجوز فقدان المعلومات. أو ، ببساطة أكثر ، سنقوم بتحديد المعاملات لتحقيق الضغط.
كيف يمكن قياس مجموعة من المعاملات؟ ستكون إحدى الطرق البسيطة هي القياس الكمي الموحد ، عندما نأخذ كتلة ونقسمها على قيمة واحدة (بنسبة 10) ونقلب ما حدث.
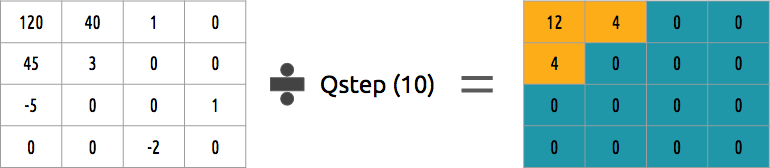
هل يمكننا عكس هذه الكتلة من المعاملات؟ نعم ، يمكننا ذلك ، بضرب نفس القيمة التي قسمناها.
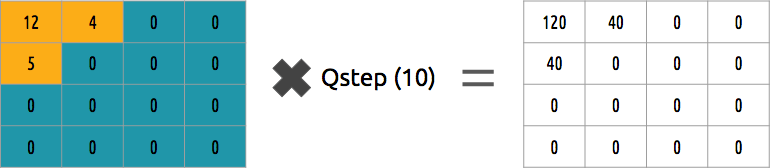
هذا النهج ليس هو الأفضل ، لأنه لا يأخذ في الاعتبار أهمية كل معامل. يمكن للمرء استخدام مصفوفة الكمي بدلاً من قيمة واحدة ، ويمكن أن تستخدم هذه المصفوفة خاصية DCT ، والتي تقيس معظم اليمين السفلي وأقلية من أعلى اليسار.
5 خطوة - الترميز الانتروبيا
بعد قيامنا بتقييم البيانات (كتل الصور ، الأجزاء ، الإطارات) ، لا يزال بإمكاننا ضغطها دون فقدها. هناك العديد من الطرق الخوارزمية لضغط البيانات. سنتعرف لفترة وجيزة على بعضهم ، لفهم أعمق ، يمكنك قراءة كتاب "
فهم الضغط: ضغط البيانات للمطورين الحديثين " ("
فهم الضغط: ضغط البيانات للمطورين الحديثين ").
ترميز الفيديو مع VLC
افترض أن لدينا مجموعة من الأحرف:
a و
e و
r و
t . يتم تقديم احتمال (يتراوح من 0 إلى 1) لمدى تكرار حدوث كل رمز في الدفق في هذا الجدول.
يمكننا تعيين رموز ثنائية فريدة (ويفضل أن تكون صغيرة) للرموز الأكثر احتمالًا ، والأكبر حجمًا أقل احتمالًا.
نقوم بضغط الدفق ، على افتراض أننا في النهاية ننفق 8 بتات لكل حرف. بدون ضغط على حرف ، ستكون هناك حاجة إلى 24 بت. إذا تم استبدال كل حرف برمزه ، فسوف نحقق وفورات!
تتمثل الخطوة الأولى في تشفير الحرف
e ، وهو 10 ، والحرف الثاني هو ، الذي يتم إضافته (وليس رياضياً): [10] [0] ، وأخيراً ، الحرف الثالث
t ، والذي يجعل تيار البتات المضغوط النهائي لدينا متساويًا [10] [0] [1110] أو
1001110 ، والذي يتطلب 7 بت فقط (مساحة أقل بمقدار 3.4 أضعاف من المساحة الأصلية).
يرجى ملاحظة أن كل رمز يجب أن يكون رمزًا فريدًا مع بادئة. سوف تساعد
خوارزمية هوفمان في العثور على هذه الأرقام. على الرغم من أن هذه الطريقة لا تخلو من العيوب ، إلا أن هناك برامج ترميز فيديو لا تزال تقدم طريقة حسابية للضغط.
يجب أن يكون لكل من المشفر ووحدة فك الترميز إمكانية الوصول إلى جدول الرموز باستخدام الأكواد الثنائية. لذلك ، من الضروري أيضًا إرسال جدول في الإدخال.
الترميز الحسابي
افترض أن لدينا مجموعة من الأحرف:
a و
e و
r و
s و
t ، واحتمالها يمثله هذا الجدول.
باستخدام هذا الجدول ، نقوم بإنشاء نطاقات تحتوي على جميع الأحرف الممكنة ، مرتبة حسب أكبر عدد.

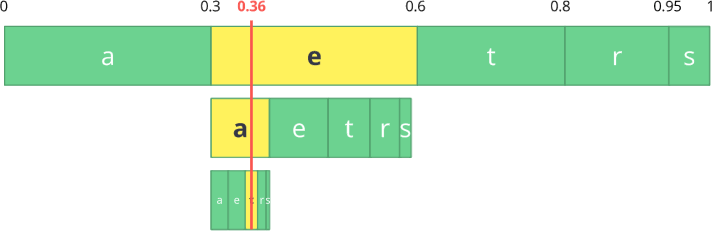
الآن دعنا نرمز لثلاثة أحرف:
أكل .
أولاً ، حدد الحرف الأول
e ، الموجود في النطاق الفرعي من 0.3 إلى 0.6 (لا يشمل ذلك). نأخذ هذا الغريب ونقسمه مرة أخرى بنفس النسب كما كان من قبل ، ولكن بالفعل لهذا النطاق الجديد.

دعنا نستمر في كود تيارنا
للأكل . الآن نأخذ الرمز الثاني
a ، الموجود في subrange الجديد من 0.3 إلى 0.39 ، ثم نأخذ الرمز الأخير
t و ، ونكرر نفس العملية مرة أخرى ، نحصل على آخر subrange من 0.354 إلى 0.372.
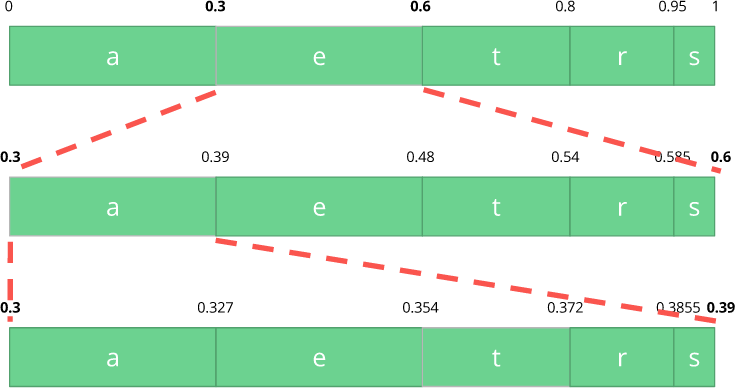
نحتاج فقط إلى تحديد رقم في النطاق الفرعي الأخير من 0.354 إلى 0.372. دعنا نختار 0.36 (ولكن يمكنك اختيار أي رقم آخر في هذا النطاق الفرعي). فقط مع هذا الرقم يمكننا استعادة التدفق الأصلي لدينا. يبدو الأمر كما لو كنا نرسم خطًا داخل النطاقات لتشفير جدولنا.
العملية العكسية (أي
فك التشفير ) هي بنفس البساطة: مع رقمنا 0.36 ومجموعتنا الأصلية ، يمكننا أن نبدأ نفس العملية. لكن الآن ، باستخدام هذا الرقم ، نكشف عن الدفق المشفر باستخدام هذا الرقم.
مع النطاق الأول ، نلاحظ أن رقمنا يتوافق مع شريحة ، وبالتالي ، هذا هو أول شخص لدينا. الآن مرة أخرى ، نشارك هذا النطاق الفرعي ، وننفذ نفس العملية كما كان من قبل. هنا يمكنك أن ترى أن 0.36 يتوافق مع الحرف
a ، وبعد تكرار العملية ، وصلنا إلى الحرف الأخير
t (تشكيل تيارنا المشفر الأصلي).
يجب أن يحتوي كل من المشفر وجهاز فك التشفير على جدول لاحتمالات الرمز ، لذلك ، من الضروري إرساله في بيانات الإدخال.
أنيقة جدا ، أليس كذلك؟ الشخص الذي توصل إلى هذا الحل كان لعنة ذكية. تستخدم بعض برامج ترميز الفيديو هذه التقنية (أو ، على أي حال ، تقدمها كخيار).
والفكرة هي لضغط تيار الأرقام الكمي بلا خسائر. من المؤكد أنه لا يوجد في هذه المقالة أطنان من التفاصيل والأسباب والحلول الوسط وما إلى ذلك. لكنك ، إذا كنت مطورًا ، يجب أن تعرف المزيد. تحاول برامج الترميز الجديدة استخدام خوارزميات ترميز إنتروبيا مختلفة ، مثل
ANS .
6 خطوة - تنسيق تيار الأرقام الثنائية
بعد القيام بكل هذا ، يبقى فك الإطارات المضغوطة في سياق الخطوات المتخذة. يجب أن يكون مفكك التشفير على علم صريح بالقرارات التي يتخذها المشفر. يجب تزويد وحدة فك الترميز بجميع المعلومات اللازمة: عمق البت ، فراغ اللون ، الاستبانة ، معلومات التنبؤ (متجهات الحركة ، توقع اتجاهي) ، المظهر الجانبي ، المستوى ، معدل الإطار ، نوع الإطار ، رقم الإطار ، وأكثر من ذلك بكثير.
سوف نلقي نظرة على تيار البتات
H.264 . خطوتنا الأولى هي إنشاء الحد الأدنى من تدفق البتات H.264 (يضيف FFmpeg افتراضيًا جميع معلمات الترميز ، مثل
SEI NAL -
سنكتشف قليلاً ما هو عليه). يمكننا القيام بذلك باستخدام مستودعنا الخاص و FFmpeg.
./s/ffmpeg -i /files/i/minimal.png -pix_fmt yuv420p /files/v/minimal_yuv420.h264سيقوم هذا الأمر بإنشاء
تيار بتنسيق H.264 خام بإطار واحد ، بدقة 64 × 64 ، مع مساحة اللون
YUV420 . يتم استخدام الصورة التالية كإطار.

H.264 تيار الأرقام الثنائية
يحدد
معيار AVC (
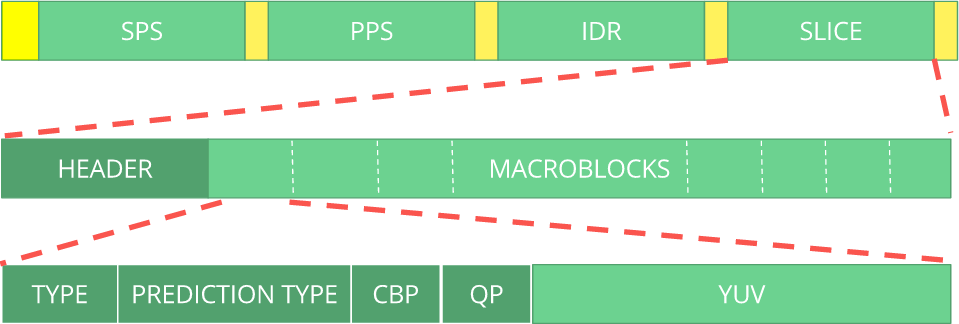
H.264 ) أنه سيتم إرسال المعلومات في إطارات ماكرو (في فهم الشبكة) تسمى
NAL (وهذا هو مستوى تجريد الشبكة هذا). الهدف الرئيسي من NAL هو تقديم عرض "صديق للشبكة" للفيديو. يجب أن يعمل هذا المعيار على أجهزة التلفزيون (القائمة على التدفقات) ، وعلى الإنترنت (على أساس الحزم).

هناك علامة التزامن لتحديد حدود عناصر NAL. تحتوي كل علامة التزامن على القيمة
0x00 0x00 0x01 ، باستثناء الأول ، وهو
0x00 0x00 0x00 0x01. إذا قمنا بتشغيل
hexdump لدفق البتات H.264 الذي تم إنشاؤه ، فسوف نحدد ثلاثة أنماط NAL على الأقل في بداية الملف.
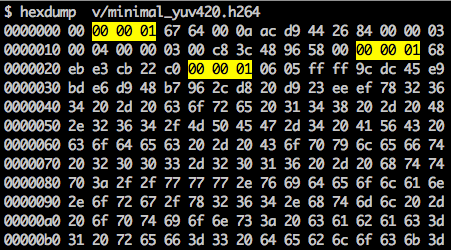
كما هو مذكور ، يجب أن لا يعرف وحدة فك الترميز بيانات الصورة فقط ، ولكن أيضًا تفاصيل الفيديو والإطار واللون والمعلمات المستخدمة وغير ذلك الكثير. البايت الأول من كل NAL يحدد فئته ونوعه.
عادةً ما يكون أول تدفق NAL هو
SPS . هذا النوع من NAL مسؤول عن الإبلاغ عن متغيرات الترميز الشائعة ، مثل ملف التعريف والمستوى والدقة والمزيد.
إذا تخطينا الرمز المميز للتزامن الأول ، فيمكننا فك تشفير البايت الأول لمعرفة نوع NAL الأول.
على سبيل المثال ، البايتة الأولى بعد علامة التزامن هي
01100111 ، حيث البتة الأولى (
0 ) في الحقل f
orbidden_zero_bit . تخبرنا
البتاتان التاليتان (
11 )
بحقل nal_ref_idc ، والذي يشير إلى ما إذا كانت NAL عبارة عن حقل مرجعي أم لا.
ويخبرنا الـ 5 بتات المتبقية (
00111 ) بمجال
nal_unit_type ، وفي هذه الحالة فإنه عبارة عن كتلة SPS (
7 ) NAL.
البايت الثاني (
ثنائي =
01100100 ،
hex =
0x64 ،
dec =
100 ) في SPS NAL هو حقل
profile_idc ، والذي يُظهر ملف التخصيص الذي يستخدمه المشفر. في هذه الحالة ، تم استخدام ملف تعريف مرتفع محدود (على سبيل المثال ملف تعريف عالي بدون دعم لشريحة B ثنائية الاتجاه).

إذا كنا على دراية بمواصفات دفق البتات
H.264 لـ SPS NAL ، فسنجد العديد من القيم لاسم المعلمة والفئة والوصف. على سبيل المثال ، دعنا ننظر إلى
حقول pic_width_in_mbs_minus_1 و
pic_height_in_map_units_minus_1 .
إذا أجرينا بعض العمليات الرياضية بقيم هذه الحقول ، فسنحصل على إذن. يمكنك أن تتخيل
1920 × 1080 باستخدام
pic_width_in_mbs_minus_1 بقيمة
119 ((119 + 1) * macroblock_size = 120 * 16 = 1920) . مرة أخرى ، توفير مساحة ، بدلاً من الترميز 1920 فعلوا ذلك مع 119.
إذا واصلنا التحقق من الفيديو الذي تم إنشاؤه في شكل ثنائي (على سبيل المثال:
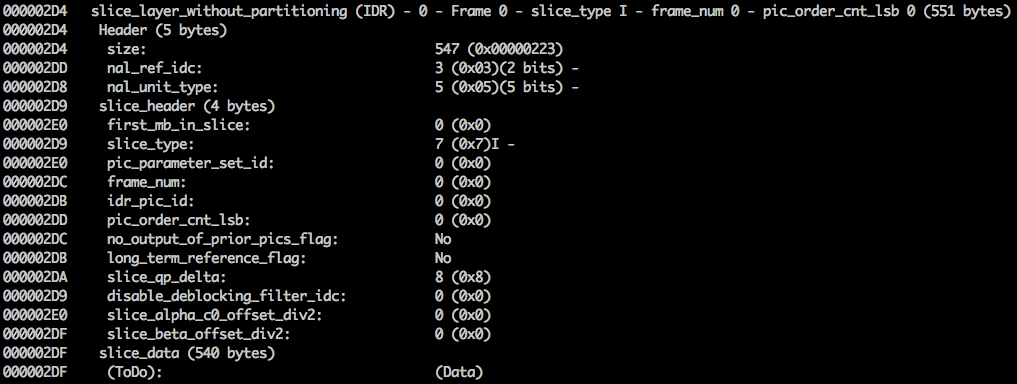
xxd -b -c 11 v / minimal_yuv420.h264 ) ، فيمكننا الانتقال إلى آخر NAL ، وهو الإطار نفسه.

هنا نرى قيم البايت 6 الأولى:
01100101 10001000 10000100 00000000 00100001 11111111 . نظرًا لأنه من المعروف أن البايتة الأولى تشير إلى نوع NAL ، في هذه الحالة (
00101 ) هذا جزء من IDR (5) ، ومن ثم سيكون من الممكن دراسته مرة أخرى:

باستخدام معلومات المواصفات ، سيكون من الممكن فك تشفير نوع الجزء (
slice_type ) ورقم الإطار (
frame_num ) بين الحقول المهمة الأخرى.
للحصول على قيم بعض الحقول (
ue (
v ) أو
me (
v ) أو
se (
v ) أو
te (
v )) ، نحتاج إلى فك تشفير الجزء باستخدام وحدة فك ترميز خاصة تستند إلى
شفرة Golomb الأسية . هذه الطريقة فعالة للغاية لترميز القيم المتغيرة ، خاصةً عندما يكون هناك العديد من القيم الافتراضية.
قيمتي slice_type و
frame_num لهذا الفيديو هما 7 (الجزء الأول) و 0 (الإطار الأول).
يمكن اعتبار تيار الأرقام الثنائية بمثابة بروتوكول. إذا كنت تريد معرفة المزيد عن تدفق البتات ، يجب عليك الرجوع إلى مواصفات
الاتحاد الدولي للاتصالات H.264 . فيما يلي ماكرو يوضح مكان بيانات الصورة (
YUV في شكل مضغوط).
يمكنك استكشاف تدفقات
بتات أخرى ، مثل
VP9 أو
H.265 (
HEVC ) أو حتى أفضل
دفق بتنسيق AV1 جديد. هل هم جميعا على حد سواء؟ لا ، ولكن التعامل مع واحد على الأقل هو أسهل بكثير لفهم البقية.
تريد ممارسة؟ استكشاف H.264 تيار الأرقام الثنائية
يمكنك إنشاء فيديو أحادي الإطار واستخدام MediaInfo لفحص تدفق البتات H.264 . في الحقيقة ، لا يوجد شيء يمنعك من النظر إلى الكود المصدري الذي يحلل دفق البتات H.264 ( AVC ).
للتمرين ، يمكنك استخدام Intel Video Pro Analyzer (لقد قلت بالفعل أن البرنامج مدفوع ، ولكن هل هناك نسخة تجريبية مجانية بحد أقصى 10 إطارات؟).
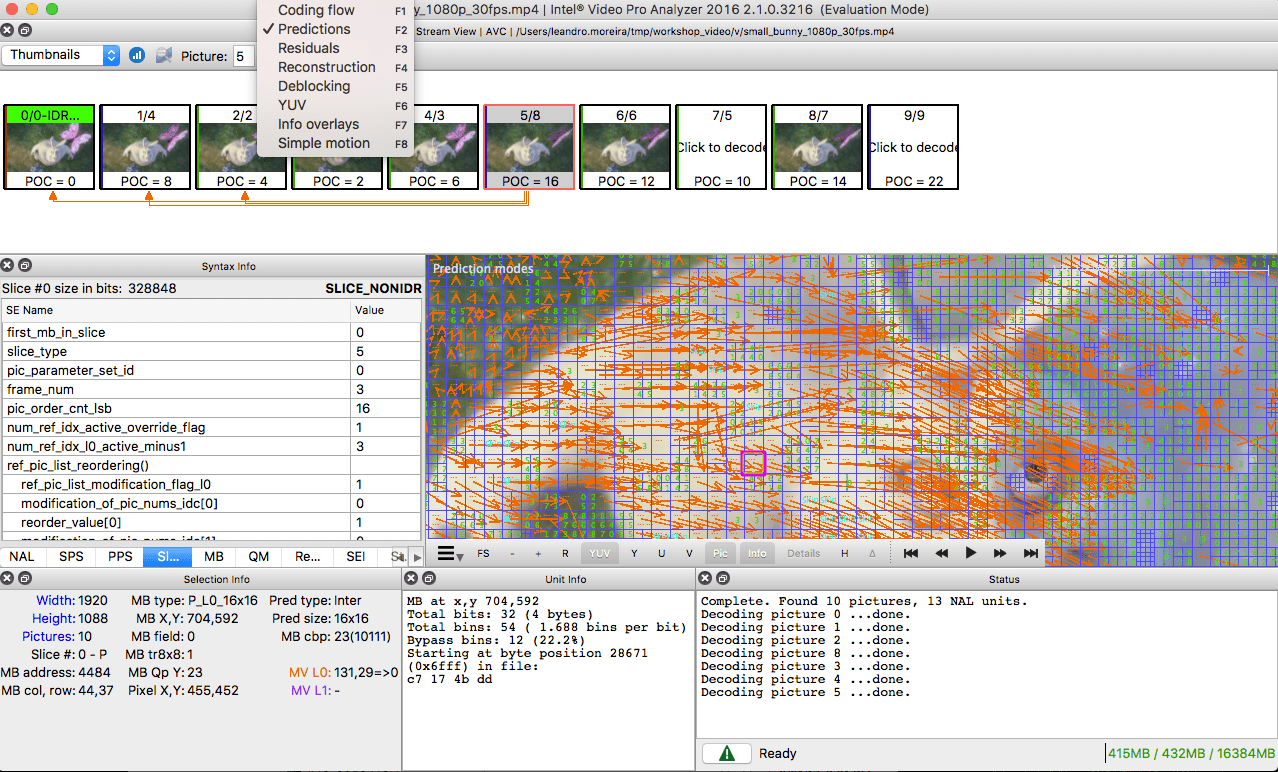
نظرة عامة
لاحظ أن العديد من برامج الترميز الحديثة تستخدم نفس النموذج الذي تعلموه للتو. هنا ، دعونا نلقي نظرة على الرسم التخطيطي للكتلة لبرنامج ترميز الفيديو
Thor . أنه يحتوي على جميع الخطوات التي اتخذناها. الهدف من هذا المنشور هو فهمك للابتكارات والوثائق في هذا المجال على الأقل.
سابقًا ، تم تقدير أن 139 جيجابايت من مساحة القرص ستكون مطلوبة لتخزين ملف فيديو لمدة ساعة واحدة بجودة 720 بكسل و 30 إطارًا في الثانية. إذا كنت تستخدم الطرق التي تمت مناقشتها في هذه المقالة (بين الإطارات الداخلية والتنبؤات الداخلية والتحويل والكميات وترميز الإنتروبيا وما إلى ذلك) ، فيمكنك تحقيق ذلك (على افتراض أننا ننفق 0.031 بت لكل بكسل) ، يكون الفيديو بجودة مرضية تمامًا ، والتي تستهلك فقط 367.82 ميغابايت ، وليس 139 جيجابايت من الذاكرة.
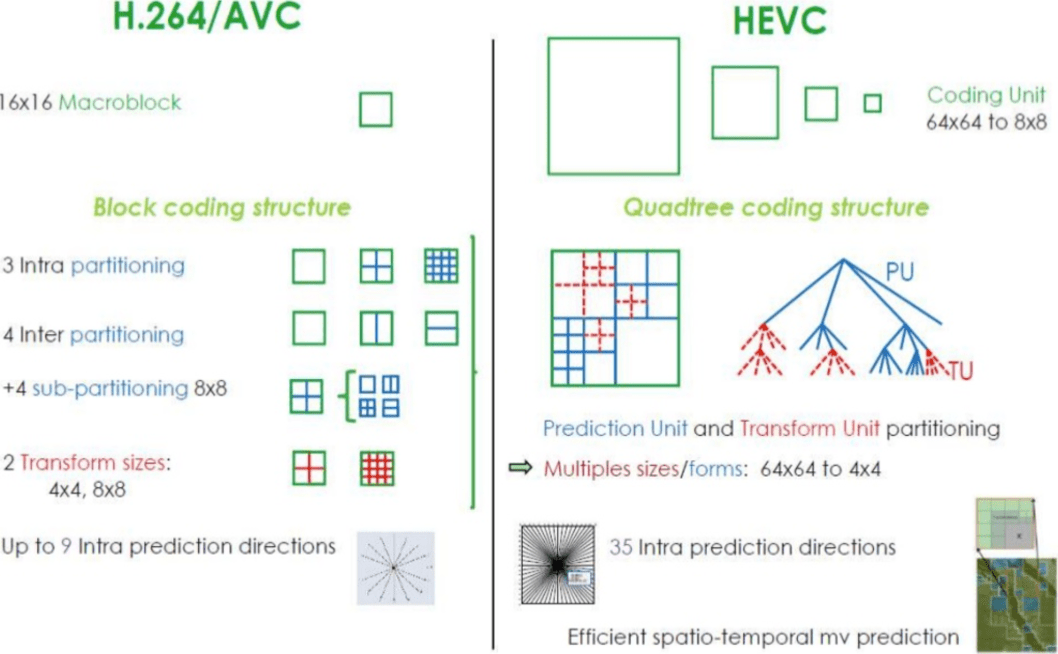
كيف يحقق H.265 نسبة ضغط أفضل من H.264؟
الآن بعد أن تعرف المزيد حول كيفية عمل برامج الترميز ، أصبح من السهل فهم كيف يمكن أن توفر برامج الترميز الجديدة دقة أعلى مع عدد أقل من وحدات البت.
عند مقارنة
AVC و
HEVC ، يجب ألا تنسى أن هذا هو دائمًا الاختيار بين تحميل وحدة المعالجة المركزية أعلى ونسبة الضغط.
لدى
HEVC خيارات أكثر للأقسام (والأقسام الفرعية) من
AVC ، والمزيد من التوجيهات للتنبؤ الداخلي ، وتحسين ترميز الإنتروبيا ، وأكثر من ذلك بكثير. كل هذه التحسينات جعلت
H.265 قادرة على ضغط 50 ٪ أكثر من
H.264 .

اقرأ أيضا بلوق
شركة إديسون:
20 مكتبة لل
مذهلة تطبيق دائرة الرقابة الداخلية