نحن نستخدم الخدمات السحابية لفترة طويلة: البريد والتخزين والشبكات الاجتماعية والمراسلات الفورية. تعمل جميعها عن بُعد - نرسل الرسائل والملفات ، ويتم تخزينها ومعالجتها على خوادم بعيدة. تعمل الألعاب السحابية أيضًا: يتصل المستخدم بالخدمة ، ويحدد اللعبة ويطلقها. هذا مناسب للاعب ، لأن الألعاب تبدأ على الفور تقريبًا ، ولا تشغل الذاكرة ، ولا تحتاج إلى كمبيوتر ألعاب قوي.

بالنسبة إلى الخدمة السحابية ، كل شيء مختلف - يحتوي على مشاكل في تخزين البيانات. يمكن أن تزن كل لعبة عشرات أو مئات غيغا بايت ، على سبيل المثال ، "The Witcher 3" يستغرق 50 جيجابايت ، و "Call of Duty: Black Ops III" - 113. في الوقت نفسه ، لن يستخدم اللاعبون الخدمة مع 2-3 ألعاب ، وهناك حاجة إلى عشرات على الأقل . بالإضافة إلى تخزين مئات الألعاب ، يجب أن تقرر الخدمة مقدار المساحة المخصصة لتخصيصها لكل لاعب ، وتوسيع نطاقها عند وجود الآلاف منها.
هل يجب تخزين كل هذا على الخوادم الخاصة بهم: كم منهم يحتاجون ، وأين يضعون مراكز البيانات ، وكيفية "مزامنة" البيانات بين العديد من مراكز البيانات أثناء الطيران؟ شراء "الغيوم"؟ استخدام الأجهزة الافتراضية؟ هل من الممكن تخزين بيانات المستخدم مع ضغط 5 مرات وتزويدها في الوقت الحقيقي؟ كيفية استبعاد أي تأثير للمستخدمين على بعضهم البعض أثناء الاستخدام المتسق لنفس الجهاز الظاهري؟
تم حل جميع هذه المهام بنجاح في Playkey.net - منصة ألعاب قائمة على السحابة.
سيتحدث فلاديمير ريابوف (
Graymansama ) - رئيس قسم إدارة النظام - بالتفصيل عن تقنية ZFS لـ FreeBSD ، والتي ساعدت في ذلك ، وشوكة جديدة من ZOL (ZFS على Linux).
يوجد ألف خادم للشركة في مراكز البيانات عن بعد في موسكو ولندن وفرانكفورت. هناك أكثر من 250 لعبة في الخدمة ، والتي يلعبها 100 ألف لاعب شهريًا.
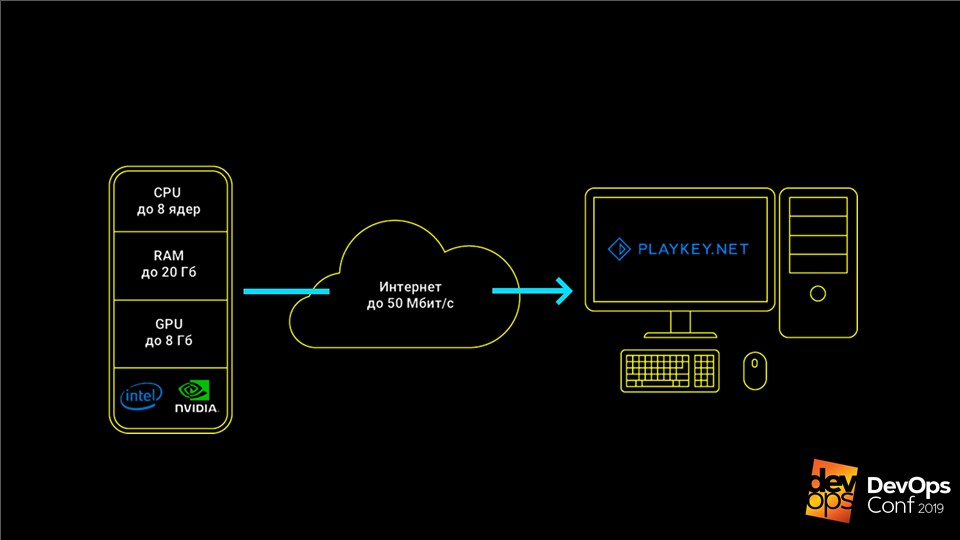
تعمل الخدمة على النحو التالي: يتم تشغيل اللعبة على خوادم الشركة ، ويتلقى المستخدم مجموعة من عناصر التحكم من لوحة المفاتيح أو الماوس أو لوحة اللعبة ، ويتم إرسال دفق الفيديو استجابةً لذلك. يسمح لك هذا بممارسة الألعاب الحديثة المتطورة على أجهزة الكمبيوتر ذات الأجهزة الضعيفة أو أجهزة الكمبيوتر المحمولة المزودة بفيديو مدمج أو على أجهزة Mac التي لا يتم إصدار هذه الألعاب على الإطلاق.
يجب تخزين الألعاب وتحديثها
البيانات الرئيسية لخدمة الألعاب السحابية هي توزيعات اللعبة ، والتي يمكن أن تتجاوز مئات غيغابايت ، وحفظ المستخدم.
عندما كنا صغيرين ، كان لدينا فقط عشرة خوادم وكتالوج متواضع يضم 50 لعبة. قمنا بتخزين جميع البيانات محليا على الخوادم ، وتحديثها يدويا ، كل شيء على ما يرام. لكن الوقت قد حان للنمو
وانطلقنا في السحب AWS .
مع AWS ، حصلنا على عدة مئات من الخوادم ، ولكن لم يتغير الهيكل. كانوا أيضًا خوادم ، لكنهم أصبحوا الآن افتراضيين ، مع أقراص محلية تعتمد عليها توزيعات اللعبة. ومع ذلك ، سوف تفشل التحديث يدوياً على مائة خوادم.
بدأنا في البحث عن حل. في البداية حاولنا التحديث عبر
rsync . لكن اتضح أن هذا بطيء للغاية ، والحمل على العقدة الرئيسية كبير جدًا. ولكن هذا ليس هو الأسوأ: عندما كان لدينا انخفاض في الاتصال بالإنترنت ، أوقفنا تشغيل بعض الأجهزة الافتراضية حتى لا ندفع مقابلها ، وعند التحديث ، لم يتم سكب البيانات على الخوادم التي تم إيقاف تشغيلها. تم ترك كل منهم دون تحديثات.
كان الحل السيول - برنامج
BTSync . يسمح لك بمزامنة مجلد على عدد كبير من العقد دون تحديد عقدة مركزية بشكل صريح.
مشاكل النمو
لفترة من الوقت ، كل هذا يعمل بشكل رائع. لكن الخدمة كانت تتطور ، كان هناك المزيد من الألعاب والخوادم. زاد عدد المتاجر المحلية أيضًا ، وكان علينا دفع المزيد والمزيد. في الغيوم أنها مكلفة ، وخاصة بالنسبة لمحركات الأقراص الصلبة. عند نقطة واحدة ، حتى الفهرسة المعتادة للمجلد لبدء مزامنته بدأت تستغرق أكثر من ساعة ، ويمكن تحديث جميع الخوادم لعدة أيام.
خلقت BTSync مشكلة أخرى مع حركة مرور الشبكة الزائدة. في ذلك الوقت ، في أمازون دفعت حتى بين الافتراضية الافتراضية. إذا قام مشغل اللعبة الكلاسيكي بإجراء تغييرات صغيرة على الملفات الكبيرة ، فإن BTSync تعتقد على الفور أن الملف بأكمله قد تغير ، ويبدأ في نقله بالكامل إلى جميع العقد. نتيجة لذلك ، يمكن أن تؤدي الترقية التي تصل إلى 15 ميغابايت إلى توليد عشرات غيغابايت من حركة التزامن.
أصبح الموقف حرجًا عندما نما التخزين إلى 1 تيرابايت. صدر للتو لعبة جديدة عالم السفن الحربية. وكان توزيعها عدة مئات الآلاف من الملفات الصغيرة. تعذر على BTSync هضمه وتوزيعه على جميع الخوادم الأخرى - مما أدى إلى إبطاء توزيع الألعاب الأخرى.
كل هذه العوامل خلقت مشكلتين:
- إنتاج التخزين المحلي باهظ الثمن وغير مريح ويصعب تحديثه ؛
- كانت الغيوم باهظة الثمن.
قررنا العودة إلى مفهوم خوادمنا المادية.
نظام التخزين الخاصة
قبل الانتقال إلى الخوادم الفعلية ، نحتاج إلى التخلص من التخزين المحلي. هذا يتطلب
نظام التخزين الخاص به
- التخزين . هذا هو النظام الذي يخزن جميع التوزيعات ويوزعها مركزيا على جميع الخوادم.
يبدو أن المهمة بسيطة - لقد تم حلها بالفعل بشكل متكرر. ولكن مع الألعاب هناك فروق دقيقة. على سبيل المثال ، ترفض معظم الألعاب العمل ببساطة إذا مُنحت حق الوصول للقراءة فقط. حتى مع بدء التشغيل المعتاد ، فإنهم يحبون كتابة شيء ما على ملفاتهم ، وبدون ذلك يرفضون العمل. على العكس من ذلك ، إذا مُنح عدد كبير من المستخدمين حق الوصول إلى مجموعة واحدة من التوزيعات ، فإنهم يبدأون في التغلب على ملفات بعضهم البعض عن طريق الوصول التنافسي.
فكرنا في المشكلة ، ودققنا في العديد من الحلول الممكنة ،
وتوصلنا إلى
ZFS - Zettabyte File System على FreeBSD .
ZFS على فري
هذا ليس نظام ملفات عادي. يتم تثبيت الأنظمة الكلاسيكية في البداية على جهاز واحد ، وللعمل مع العديد من الأقراص بالفعل يتطلب مدير وحدة تخزين.
تم بناء ZFS في الأصل على حمامات افتراضية.
يطلق عليهم
zpool وتتكون من مجموعات الأقراص أو صفائف RAID. الحجم الكامل لهذه الأقراص متاح لأي نظام ملفات داخل zpool. ذلك لأنه تم تطوير ZFS في الأصل كنظام سيعمل مع كميات كبيرة من البيانات.
كيف ساعد ZFS في حل مشكلاتنا
يحتوي هذا النظام على
آلية رائعة
لإنشاء لقطات ونسخ . يتم إنشاؤها
على الفور ، وتزن فقط عدد قليل من كيلوبايت. عندما نجري تغييرات على أحد الحيوانات المستنسخة ، يزداد حجم هذه التغييرات. في الوقت نفسه ، لا تتغير البيانات الموجودة في الحيوانات المستنسخة المتبقية وتظل فريدة. يتيح لك ذلك توزيع قرص
بسعة 10 تيرابايت مع وصول خاص للمستخدم النهائي ، مع إنفاق بضعة كيلوبايت فقط.
إذا نمت الحيوانات المستنسخة أثناء إجراء تغييرات على جلسة لعبة ، ألا تشغل مساحة كبيرة مثل كل الألعاب؟ لا ، وجدنا أنه حتى في جلسات اللعب الطويلة إلى حد ما ، نادراً ما تتجاوز مجموعة التغييرات 100-200 ميجابايت - وهذا ليس بالأمر الحاسم. لذلك ، يمكننا منح الوصول الكامل إلى محرك أقراص صلبة عالي السعة كامل لمئات المستخدمين في نفس الوقت ، مع إنفاق 10 تيرابايت فقط بذيل.
كيف يعمل ZFS
يبدو الوصف معقدًا ، لكن ZFS يعمل بكل بساطة. دعنا نحلل عملها بمثال بسيط - إنشاء
zpool data من أقراص
zpool create data /dev/da /dev/db /dev/dc المتاحة -
zpool create data /dev/da /dev/db /dev/dc .
المذكرة. هذا ليس ضروريًا للإنتاج ، لأنه في حالة وفاة قرص واحد على الأقل ، فإن المجموعة بأكملها ستغفل معها. أفضل استخدام مجموعات RAID.نقوم بإنشاء
zfs create data/games نظام ملفات
zfs create data/games ،
zfs create data/games جهاز كتلة مع اسم
data/games/disk من 10 تيرابايت. يتوفر الجهاز على
/dev/zvol/data/games/disk عادي - يمكنك تنفيذ نفس العمليات باستخدامه.
ثم تبدأ المتعة. نقدم هذا القرص عبر
iSCSI إلى معالج التحديث الخاص بنا - وهو جهاز افتراضي منتظم يعمل بنظام Windows. نقوم بتوصيل القرص ووضع الألعاب عليه ببساطة من Steam ، كما هو الحال على جهاز كمبيوتر منزلي منتظم.
ملء القرص مع الألعاب. الآن يبقى توزيع هذه البيانات على
200 خادم للمستخدمين النهائيين.
- قم بإنشاء لقطة لهذا القرص
zfs snapshot data/games/disk@ver1 الإصدار الأول - zfs snapshot data/games/disk@ver1 . قم zfs clone data/games/disk@ver1 data/games/disk-vm1 clone zfs clone data/games/disk@ver1 data/games/disk-vm1 ، والذي سينتقل إلى أول جهاز افتراضي. - نعطي الاستنساخ عبر iSCSI و KVM تطلق آلة افتراضية مع هذا القرص . يتم تحميله ، وينتقل إلى مجموعة من الخوادم التي يمكن الوصول إليها للمستخدمين ، ويتوقع وجود لاعب.
- عند اكتمال جلسة المستخدم ، نأخذ جميع عمليات حفظ المستخدم من هذا الجهاز الظاهري ونضعها في خادم منفصل . نقوم بإيقاف تشغيل الجهاز الظاهري وتدمير الاستنساخ -
zfs destroy data/games/disk-vm1 . - نعود إلى الخطوة الأولى ، وننشئ استنساخًا مرة أخرى ونبدأ تشغيل الجهاز الظاهري.
يسمح لنا ذلك بتزويد كل مستخدم آخر بجهاز
نظيف دائمًا ، لا توجد فيه تغييرات من المشغل السابق. يتم حذف القرص بعد كل جلسة مستخدم ، ويتم تحرير المساحة التي يشغلها على نظام التخزين. كما نقوم بتنفيذ عمليات مماثلة باستخدام قرص النظام وبجميع الأجهزة الافتراضية لدينا.
لقد شاهدت مؤخرًا مقطع فيديو على YouTube ، حيث قام أحد المستخدمين بالرضا أثناء إحدى جلسات اللعبة بتنسيق محركات الأقراص الصلبة لدينا على الخوادم ، وكنت سعيدًا للغاية لأنه كسر كل شيء. نعم ، من فضلك ، فقط للدفع - يمكنه اللعب والاستمتاع. في أي حال ، سيحصل المستخدم التالي دائمًا على جهاز ظاهري نظيف وظيفي ، بغض النظر عن ما يفعله الجهاز السابق.
وفقًا لهذا المخطط ، يتم توزيع الألعاب على 200 خادم فقط. لقد قمنا بحساب الرقم 200 بشكل تجريبي: هذا هو عدد الخوادم التي لا تحدث فيها الأحمال الحرجة على محركات التخزين. هذا لأن
الألعاب لها ملف تعريف تحميل محدد إلى حد ما : فهي تقرأ كثيرًا في مرحلة الإطلاق أو في مرحلة تحميل المستوى ، وخلال اللعبة ، على العكس من ذلك ، لا تستخدم قرصًا من الناحية العملية. إذا كان ملف تعريف التحميل مختلفًا ، فسيكون الرقم مختلفًا.
في المخطط القديم ، من أجل الصيانة المتزامنة لـ 200 مستخدم ، نحتاج إلى 2000 تيرابايت من السعة التخزينية المحلية. الآن يمكننا أن ننفق أكثر قليلاً من 10 تيرابايت لمجموعة البيانات الرئيسية ، ولا يزال هناك 0.5 تيرابايت في المخزون من أجل تغييرات المستخدم. على الرغم من أن ZFS تحب عندما يكون لديها 15٪ على الأقل من المساحة الحرة في مجموعتها ، إلا أنه يبدو لي أننا قمنا بتوفير الكثير.
ماذا لو كان لدينا العديد من مراكز البيانات؟
ستعمل هذه الآلية فقط داخل مركز بيانات واحد ، حيث يتم توصيل الخوادم التي بها نظام تخزين بواجهة 10 جيجابت على الأقل. ماذا تفعل إذا كان هناك العديد من البلدان النامية؟ كيفية تحديث القرص الرئيسي مع الألعاب (مجموعة البيانات) بينهما؟
لهذا ، لدى ZFS حلها الخاص -
آلية الإرسال
/ التلقي . أمر التنفيذ بسيط للغاية:
zfs send -v data/games/disk@ver1 | ssh myzfsuser@myserverip zfs receive data/games/disk
تتيح لك الآلية نقل لقطة من النظام الأساسي من نظام تخزين إلى آخر. لأول مرة ، يجب أن ترسل إلى نظام تخزين فارغ جميع البيانات البالغة 10 تيرابايت التي يتم تسجيلها على العقدة الرئيسية. ولكن مع التحديثات القادمة ، سنرسل فقط التغييرات من لحظة إنشاء اللقطة السابقة.
نتيجة لذلك ، نحصل على:
- يتم إجراء جميع التغييرات مركزيًا على نظام تخزين واحد . بعد ذلك يتم تفريقهم إلى جميع مراكز البيانات الأخرى بأي كمية ، وتكون البيانات الموجودة على جميع العقد متطابقة دائمًا.
- آلية إرسال / تلقي ليست خائفة من انقطاع الاتصال . لا يتم تطبيق البيانات على مجموعة البيانات الرئيسية حتى يتم نقلها بالكامل إلى عقدة العبيد. في حالة فقد الاتصال ، يكون من المستحيل إتلاف البيانات وتكرار إجراء الإرسال.
- يمكن أن تصبح أي عقدة بسهولة عقدة رئيسية خلال حادث في بضع دقائق فقط ، لأن البيانات الموجودة على جميع العقد متطابقة دائمًا.
إلغاء البيانات المكررة والنسخ الاحتياطي
ZFS لديه ميزة أخرى مفيدة -
إلغاء البيانات المكررة . هذه الوظيفة
لا تساعد
على تخزين كتلتين متطابقتين للبيانات . بدلاً من ذلك ، يتم تخزين الكتلة الأولى فقط ، وبدلاً من الثانية ، يتم تخزين رابط إلى الأول. سيشغل ملفان متطابقان مساحة واحدة ، وإذا كانا متطابقين بنسبة 90٪ ، فسيملآن 110٪ من الحجم الأصلي.
ساعدتنا الوظيفة كثيرًا في تخزين المستخدم. في لعبة واحدة ، لدى المستخدمين المختلفين نفس الحفظ ، العديد من الملفات متشابهة. من خلال استخدام إلغاء البيانات المكررة ، يمكننا تخزين خمسة أضعاف البيانات. نسبة إلغاء البيانات المكررة هي 5.22. فعليًا ، لدينا 4.43 تيرابايت ، ونتضاعف بعامل ، ونحصل على ما يقرب من 23 تيرابايت من البيانات الحقيقية. هذا يوفر مساحة عن طريق تجنب التخزين المكرر.
لقطات جيدة للنسخ الاحتياطي . نحن نستخدم هذه التكنولوجيا على تخزين الملفات لدينا. على سبيل المثال ، إذا قمت بحفظ صورة واحدة يوميًا لمدة شهر ، فيمكنك نشر نسخة في أي وقت في أي يوم من هذا الشهر وسحب الملفات المفقودة أو التالفة. هذا يلغي الحاجة إلى استعادة التخزين بأكمله أو نشر نسخة كاملة منه.
نحن نستخدم الحيوانات المستنسخة لمساعدة المطورين لدينا . على سبيل المثال ، يريدون تجربة هجرة محتملة الخطورة في قاعدة قتالية. ليس من السهل نشر نسخة احتياطية تقليدية لقاعدة بيانات تقترب من 1 تيرابايت. لذلك ، ببساطة نقوم بإزالة clone من القرص الأساسي وإضافته على الفور إلى المثيل الجديد. الآن يمكن للمطورين اختبار كل شيء هناك بأمان.
ZFS API
بالطبع ، كل هذا يجب أن يكون آليا. لماذا تسلق على الخوادم ، والعمل بيديك ، وكتابة البرامج النصية ، إذا كان هذا يمكن أن تعطى للمبرمجين؟ لذلك ، كتبنا
واجهة برمجة تطبيقات الويب البسيطة الخاصة بنا.
لفنا جميع وظائف ZFS القياسية فيه ، وقطعنا الوصول إلى تلك التي يحتمل أن تكون خطرة ويمكن أن يكسر نظام التخزين بأكمله ، وقدمنا كل هذا للمبرمجين. الآن
جميع عمليات القرص مركزية بدقة وتنفذ عن طريق الكود ، ونحن
دائما نعرف حالة كل قرص . كل شيء يعمل بشكل رائع.
ZoL - ZFS على نظام Linux
نحن مركزية النظام والفكر ، هل هو جيد جدا؟ في الواقع ، الآن لأي تمديد ، نحتاج على الفور إلى شراء العديد من رفوف الخادم: فهي مرتبطة بأنظمة التخزين ، وليس من المنطقي تقسيم النظام. ماذا تفعل عندما نقرر نشر منصة تجريبية صغيرة لإظهار التكنولوجيا للشركاء في البلدان الأخرى؟
التفكير ، توصلنا إلى الفكرة القديمة -
لاستخدام محركات الأقراص المحلية ، ولكن فقط مع كل الخبرة والمعرفة التي تلقيناها. إذا قمت بتوسيع الفكرة على نطاق عالمي ، فلماذا لا تمنح مستخدمينا الفرصة ليس فقط لاستخدام خوادمنا ، ولكن أيضًا لاستئجار أجهزة الكمبيوتر الخاصة بهم؟
ساعدنا الشوكة الحديثة نسبيًا لـ
ZFS على Linux - ZoL كثيرًا في هذا.
الآن كل خادم لديه التخزين الخاصة به.
فقط لا يخزن 10 تيرابايت من البيانات ، كما في حالة التثبيت المركزي ، ولكن فقط 1-2 توزيعات للألعاب التي تخدمها. SSD واحد يكفي لهذا. كل هذا يعمل بشكل جيد: يحصل كل مستخدم تالي دائمًا على جهاز ظاهري نظيف ، وكذلك على التثبيت القتالي.
ومع ذلك ، هنا واجهنا مشكلتين.
كيفية التحديث؟
التحديث مركزيًا عبر SSH ، كما نفعل في مراكز البيانات لن ينجح . يمكن توصيل المستخدمين بالشبكة المحلية أو إيقاف تشغيلهم ، على عكس أنظمة التخزين ، ولا تريد رفع العديد من اتصالات SSH.
واجهنا نفس المشكلات عند استخدام rsync. ومع ذلك ، لم يعد يمكن الحصول على السيول أعلى ZFS. لقد فكرنا بعناية في كيفية عمل آلية الإرسال: حيث تقوم بإرسال جميع كتل البيانات التي تم تغييرها إلى التخزين النهائي ، حيث يقوم Receive بتطبيقها على مجموعة البيانات الحالية. لماذا لا تكتب البيانات إلى ملف ، بدلاً من إرسالها إلى المستخدم النهائي؟
والنتيجة هي ما نسميه
فرق . هذا ملف يتم فيه كتابة جميع الكتل المتغيرة بين اللقطتين الأخيرتين بالتتابع. وضعنا هذا الفرق على CDN ، وأرسلناه إلى جميع مستخدمينا عبر HTTP: لقد قام بتشغيل الجهاز ، ورأينا أنه كانت هناك تحديثات ، وقلص حجمه وطبقه على مجموعة البيانات المحلية باستخدام Receive.
ماذا تفعل مع السائقين؟
تتمتع الخوادم المركزية بنفس التكوين ، ويكون لدى
المستخدمين النهائيين دائمًا أجهزة كمبيوتر وبطاقات فيديو مختلفة . حتى إذا ملأنا توزيع نظام التشغيل بكل برامج التشغيل الممكنة بقدر الإمكان ، فحينما يبدأ تشغيله ، سيظل بحاجة إلى تثبيت برامج التشغيل هذه ، ثم إعادة التشغيل ، ثم ، ربما ، مرة أخرى. نظرًا لأن كل مرة نقدم فيها استنساخًا نظيفًا ، فسيحدث كل هذا دائري بعد كل جلسة مستخدم - وهذا أمر سيء.
لقد أردنا القيام ببعض عمليات التهيئة: الانتظار حتى يتم تشغيل Windows ، وتثبيت جميع برامج التشغيل ، ويفعل كل ما تريده ، ثم يعمل فقط على محرك الأقراص هذا. ولكن المشكلة هي أنه إذا أجريت تغييرات على مجموعة البيانات الرئيسية ، فستتوقف التحديثات ، لأن البيانات الموجودة على المصدر وعلى المتلقي ستكون مختلفة ، ولن يتم تطبيق الفرق ببساطة.
ومع ذلك ، ZFS هو نظام مرن وسمح لنا بعمل عكاز صغير.
- كالعادة ، قم بإنشاء لقطة:
zfs snapshot data/games/os@init . - قم
zfs clone data/games/os@init data/games/os-init - zfs clone data/games/os@init data/games/os-init - وتشغيله في وضع التهيئة. - نحن في انتظار تثبيت جميع برامج التشغيل وسيتم إعادة تشغيل كل شيء.
- قم بإيقاف تشغيل الجهاز الظاهري والتقاط لقطة مرة أخرى. ولكن هذه المرة ، ليس من مجموعة البيانات الأصلية ، ولكن من نسخة التهيئة:
zfs snapshot data/games/os-init@ver1 . - نقوم بإنشاء استنساخ لقطة مع جميع برامج التشغيل المثبتة. لن يتم إعادة التشغيل:
zfs clone data/games/os-init@ver1 data/games/os-vm1 . - ثم نحن نعمل على حفنة الكلاسيكية.
الآن هذا النظام في مرحلة اختبار ألفا. نحن نختبرها على مستخدمين حقيقيين دون معرفة لينكس ، لكنهم ينجحون في نشره في المنزل. هدفنا النهائي هو أن يقوم أي مستخدم ببساطة بتوصيل محرك أقراص فلاش USB قابل للتمهيد في أجهزة الكمبيوتر الخاصة بهم ، وتوصيل محرك أقراص SSD إضافي واستئجاره على نظامنا الأساسي السحابي.
ناقشنا فقط جزء صغير من وظيفة ZFS. يمكن لهذا النظام أن يفعل أشياء أكثر إثارة للاهتمام ومختلفة ، لكن قلة من الناس يعرفون عن ZFS - لا يريد المستخدمون التحدث عنه. آمل أنه بعد هذه المقالة سوف يظهر مستخدمون جدد في مجتمع ZFS.
اشترك في قناة برقية أو رسالة إخبارية للتعرف على المقالات ومقاطع الفيديو الجديدة من مؤتمر DevOpsConf . بالإضافة إلى النشرة الإخبارية ، نقوم بجمع الأخبار من المؤتمرات القادمة ونقول ، على سبيل المثال ، ما سيكون مثيراً للاهتمام لمحبي DevOps في Saint HighLoad ++ .