
كان عام 2019 ، وما زلنا لا نملك حلاً قياسيًا لتجميع السجلات في Kubernetes. في هذه المقالة ، نود ، باستخدام أمثلة من الممارسة الحقيقية ، مشاركة عمليات البحث التي أجريناها والمشاكل التي واجهناها وحلولها.
ومع ذلك ، في البداية ، سأقوم بالحجز لفهم العملاء المختلفين لأشياء مختلفة تمامًا من خلال جمع السجلات:
- شخص ما يريد أن يرى سجلات الأمن والتدقيق.
- شخص ما - تسجيل مركزي للبنية التحتية بأكملها.
- وبالنسبة لشخص ما يكفي جمع سجلات التطبيق فقط ، باستثناء ، على سبيل المثال ، الموازنات.
حول كيفية قيامنا بتطبيق مختلف "قائمة الامنيات" وما الصعوبات التي واجهناها ، في ظل الخفض.
النظرية: حول أدوات التسجيل
خلفية عن مكونات نظام التسجيل
قطعت قطع الأشجار شوطًا طويلاً ، ونتيجة لذلك قمنا بتطوير منهجيات لجمع السجلات وتحليلها ، والتي نستخدمها اليوم. في الخمسينيات من القرن الماضي ، قدم فورتران تماثلًا لتيارات الإدخال / الإخراج القياسية التي ساعدت المبرمج على تصحيح برنامجه. كانت هذه هي سجلات الكمبيوتر الأولى التي جعلت الحياة أسهل للمبرمجين في تلك الأوقات. اليوم نرى فيها المكون الأول لنظام التسجيل -
المصدر أو "المنتج" للسجلات .
علوم الكمبيوتر لم تقف مكتوفة الأيدي: ظهرت شبكات الكمبيوتر ، والمجموعات الأولى ... بدأت النظم المعقدة التي تتكون من عدة أجهزة كمبيوتر في العمل. الآن تم إجبار مسؤولي النظام على جمع السجلات من العديد من الأجهزة ، وفي حالات خاصة يمكنهم إضافة رسائل kernel لنظام التشغيل في حال احتاجوا إلى التحقيق في فشل النظام. لوصف أنظمة جمع السجلات المركزية ، خرج
RFC 3164 في أوائل العقد الأول من القرن العشرين ، والذي قام بتوحيد remote_syslog. لذلك ظهر مكون مهم آخر:
جامع (جامع) السجلات وتخزينها.
مع ازدياد حجم السجلات واعتماد تقنيات الويب على نطاق واسع ، نشأ السؤال حول أي السجلات يجب أن يتم عرضها بسهولة للمستخدمين. تم استبدال أدوات وحدة التحكم البسيطة (awk / sed / grep) بمشاهدة
سجل أكثر تقدماً - المكون الثالث.
فيما يتعلق بزيادة حجم السجلات ، أصبح هناك شيء آخر واضح: هناك حاجة إلى سجلات ، ولكن ليس كلها. تتطلب السجلات المختلفة مستويات مختلفة من الأمان: يمكن فقد بعضها كل يوم ، بينما يحتاج البعض الآخر إلى تخزينه لمدة 5 سنوات. لذلك ، تمت إضافة مكون الترشيح والتوجيه لدفق البيانات إلى نظام التسجيل - دعنا نسميها
عامل تصفية .
حققت المستودعات أيضًا قفزة كبيرة: فقد تحولت من الملفات العادية إلى قواعد البيانات العلائقية ، ثم إلى مستودعات موجهة للمستندات (على سبيل المثال ، Elasticsearch). لذلك تم فصل التخزين عن المجمع.
في النهاية ، امتد مفهوم السجل نفسه إلى مجموعة مجردة من الأحداث التي نريد الاحتفاظ بها للتاريخ. بتعبير أدق ، في حالة ما إذا كان من الضروري إجراء تحقيق أو إعداد تقرير تحليلي ...
نتيجة لذلك ، تطورت مجموعة السجلات على مدى فترة زمنية قصيرة نسبيًا إلى نظام فرعي مهم ، يمكن أن يسمى بحق أحد الأقسام الفرعية في البيانات الكبيرة.
 إذا كانت المطبوعات العادية يمكن أن تكون كافية لـ "نظام التسجيل" ، فقد تغير الوضع الآن كثيرًا.
إذا كانت المطبوعات العادية يمكن أن تكون كافية لـ "نظام التسجيل" ، فقد تغير الوضع الآن كثيرًا.Kubernetes وسجلات
عندما دخل Kubernetes إلى البنية التحتية ، لم تمر المشكلة الحالية المتمثلة في جمع السجلات. إلى حد ما ، أصبح الأمر أكثر إيلامًا: إدارة منصة البنية التحتية لم تكن مبسطة فحسب ، بل كانت معقدة أيضًا. بدأت العديد من الخدمات القديمة في الهجرة إلى مسارات الخدمات الصغيرة. في سياق السجلات ، نتج عن هذا العدد المتزايد من مصادر السجل ، ودورة حياتها الخاصة ، والحاجة إلى تتبع الروابط بين جميع مكونات النظام من خلال السجلات ...
بالنظر إلى المستقبل ، يمكنني القول أنه الآن ، لسوء الحظ ، لا يوجد خيار تسجيل موحد لـ Kubernetes من شأنه أن يقارن بشكل إيجابي مع الجميع. المخططات الأكثر شعبية في المجتمع هي كما يلي:
- يقوم شخص ما بنشر مكدس EFK (Elasticsearch ، Fluentd ، Kibana) ؛
- شخص ما يحاول Loki الذي تم إصداره مؤخرًا أو يستخدم مشغل Logging ؛
- نحن (وربما ليس فقط نحن؟ ..) راضون إلى حد كبير عن التنمية الخاصة بنا - loghouse ...
كقاعدة عامة ، نستخدم هذه الحزم في مجموعات K8s (للحلول المستضافة ذاتيًا):
ومع ذلك ، لن أتطرق إلى تعليمات التثبيت والتكوين. بدلاً من ذلك ، سأركز على أوجه قصورهم واستنتاجات عالمية أكثر حول الموقف مع سجلات بشكل عام.
تدرب مع سجلات في K8s

"سجلات كل يوم" ، كم منكم؟ ..
يتطلب الجمع المركزي للسجلات مع بنية تحتية كبيرة بما يكفي موارد كبيرة سيتم إنفاقها على جمع السجلات وتخزينها ومعالجتها. خلال تشغيل مختلف المشاريع ، واجهنا متطلبات مختلفة والمشاكل التشغيلية الناتجة.
دعونا نحاول ClickHouse
دعنا ننظر إلى مستودع مركزي في مشروع مع تطبيق يولد الكثير من السجلات: أكثر من 5000 سطر في الثانية الواحدة. لنبدأ العمل مع سجلاته ، وإضافتها إلى ClickHouse.
بمجرد الحد الأقصى المطلوب من الوقت الفعلي ، سيتم تحميل خادم ClickHouse رباعي النواة بالفعل على النظام الفرعي للقرص:

يرجع هذا النوع من التنزيل إلى حقيقة أننا نحاول الكتابة إلى ClickHouse في أسرع وقت ممكن. وتستجيب قاعدة البيانات لهذا مع زيادة تحميل القرص ، والذي يمكن أن يسبب الأخطاء التالية:
DB::Exception: Too many parts (300). Merges are processing significantly slower than insertsالحقيقة هي أن
جداول MergeTree في ClickHouse (تحتوي على بيانات السجل) تواجه صعوباتها الخاصة أثناء عمليات الكتابة. تنشئ البيانات التي يتم إدخالها فيها قسمًا مؤقتًا ، ثم يتم دمجه مع الجدول الرئيسي. نتيجةً لذلك ، يكون التسجيل مطلوبًا للغاية على القرص ، وينطبق التقييد عليه ، والإخطار الذي تلقيناه أعلاه: لا يمكن دمج أكثر من 300 جزء فرعي في ثانية واحدة (في الواقع ، 300 insert'ov في الثانية الواحدة).
لتجنب هذا السلوك ،
يجب أن تكتب في ClickHouse أكبر عدد ممكن من القطع وليس أكثر من مرة واحدة في ثانيتين. ومع ذلك ، تشير الكتابة على دفعات كبيرة إلى أننا يجب أن نكتب أقل في ClickHouse. هذا ، بدوره ، يمكن أن يؤدي إلى تجاوزات المخزن المؤقت وفقدان السجلات. الحل هو زيادة المخزن المؤقت Fluentd ، ولكن بعد ذلك سوف يزيد استهلاك الذاكرة.
ملاحظة : هناك مشكلة أخرى في حل ClickHouse لدينا وهي أن التقسيم في حالتنا (loghouse) تم تنفيذه من خلال جداول خارجية مرتبطة بجدول دمج . يؤدي ذلك إلى حقيقة أنه عند أخذ عينات من الفواصل الزمنية الكبيرة ، تكون ذاكرة الوصول العشوائي الزائدة مطلوبة ، نظرًا لأن metatable يمر بجميع الأقسام - حتى تلك التي لا تحتوي بوضوح على البيانات الضرورية. ومع ذلك ، الآن يمكن الإعلان عن هذا النهج بأمان للإصدارات الحالية من ClickHouse (منذ 18.16 ).نتيجة لذلك ، يصبح من الواضح أن ClickHouse لا تملك موارد كافية لكل مشروع لجمع السجلات في الوقت الفعلي (وبشكل أكثر دقة ، لن يكون توزيعها مناسبًا). بالإضافة إلى ذلك ، سوف تحتاج إلى استخدام
بطارية ، والتي سنعود إليها. الحالة المذكورة أعلاه حقيقية. وفي ذلك الوقت ، لم نتمكن من تقديم حل موثوق ومستقر يلائم العميل ويسمح بجمع السجلات بأقل تأخير ...
ماذا عن Elasticsearch؟
ومن المعروف Elasticsearch للتعامل مع الأحمال الثقيلة. دعونا نجربه في نفس المشروع. الآن الحمل على النحو التالي:
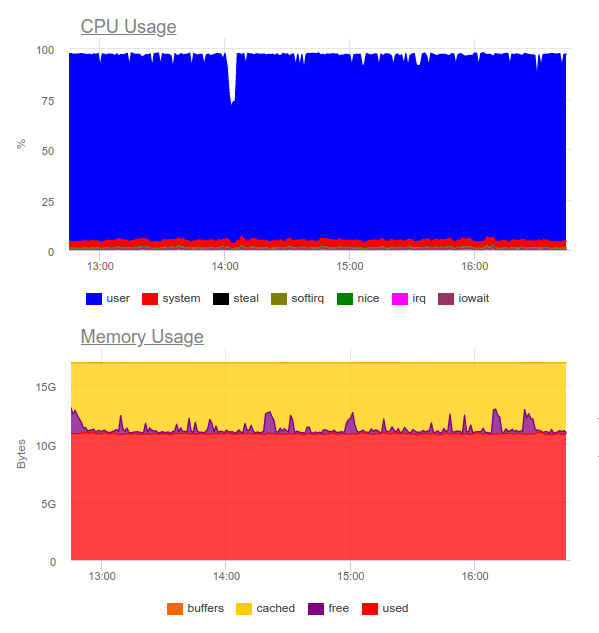
كان Elasticsearch قادرًا على هضم دفق البيانات ، ومع ذلك ، فإن كتابة مثل هذه الكميات له يستخدم وحدة المعالجة المركزية بشكل كبير. تقرر هذا من خلال تنظيم الكتلة. من الناحية الفنية ، هذه ليست مشكلة ، ولكن اتضح أنه فقط لتشغيل نظام جمع السجلات ، نستخدم بالفعل حوالي 8 مراكز ولدينا مكون إضافي محمّل بدرجة عالية في النظام ...
خلاصة القول: يمكن تبرير هذا الخيار ، ولكن فقط إذا كان المشروع كبيرًا وإدارته جاهزة لإنفاق موارد كبيرة على نظام تسجيل مركزي.
ثم ينشأ سؤال منطقي:
ما هي السجلات اللازمة حقا؟

دعنا نحاول تغيير النهج نفسه: يجب أن تكون السجلات مفيدة في نفس الوقت ، ولا تغطي
كل حدث في النظام.
دعنا نقول لدينا متجر مزدهر على الانترنت. أي سجلات مهمة؟ يعد جمع أكبر قدر ممكن من المعلومات ، على سبيل المثال ، من بوابة الدفع فكرة رائعة. ولكن من خدمة تشريح الصور في كتالوج المنتجات ، ليست كل السجلات مهمة بالنسبة لنا: فقط الأخطاء والمراقبة المتقدمة كافية (على سبيل المثال ، النسبة المئوية للأخطاء 500 التي يولدها هذا المكون).
لذلك توصلنا إلى
استنتاج مفاده أن
التسجيل المركزي ليس مبررًا دائمًا . في كثير من الأحيان ، يرغب العميل في جمع كل السجلات في مكان واحد ، على الرغم من أنه في الواقع لا يلزم سوى 5٪ من الرسائل المهمة للأعمال من السجل بأكمله:
- في بعض الأحيان ، يكفي تكوين حجم سجل الحاوية ومجمع الأخطاء (على سبيل المثال ، ترقب).
- للتحقيق في الحوادث ، يمكن أن تكون تنبيهات الخطأ وسجل محلي كبير بحد ذاته كافية.
- كان لدينا مشاريع لا تكلف سوى الاختبارات الوظيفية وأنظمة جمع الأخطاء. لم يكن المطور بحاجة إلى السجلات على هذا النحو - لقد رأوا كل شيء على آثار الخطأ.
التوضيح الحياة
مثال جيد هو قصة أخرى. لقد تلقينا طلبًا من فريق الأمان لأحد العملاء الذين لديهم بالفعل حل تجاري تم تطويره قبل فترة طويلة من تطبيق Kubernetes.
استغرق الأمر "تكوين صداقات" نظامًا مركزيًا لجمع السجلات مزودًا بمستشعر مشترك لاكتشاف المشكلات - QRadar. هذا النظام قادر على استقبال السجلات باستخدام بروتوكول syslog ، لأخذه من FTP. ومع ذلك ، دمجها مع البرنامج المساعد remote_syslog لـ fluentd لم ينجح على الفور
(كما اتضح ، لسنا الوحيدين ) . كانت مشاكل تكوين QRadar إلى جانب فريق أمان العميل.
نتيجة لذلك ، تم تحميل جزء من السجلات المهمة للأعمال على FTP QRadar ، وتم إعادة توجيه الجزء الآخر عبر syslog عن بعد مباشرة من العقد. للقيام بذلك ، قمنا حتى بكتابة
مخطط بسيط - ربما سيساعد شخص ما على حل مشكلة مماثلة ... بفضل المخطط الناتج ، تلقى العميل نفسه وقام بتحليل السجلات الهامة (باستخدام أدواته المفضلة) ، وتمكنا من خفض تكلفة نظام التسجيل ، مع الاحتفاظ بالأخير فقط الشهر.
مثال آخر يدل تماما على كيفية عدم القيام بذلك. قام أحد عملائنا بمعالجة
كل حدث قادم من المستخدم ،
بإخراج معلومات
غير منظمة متعددة الأسطر إلى السجل. كما تعتقد ، كانت هذه السجلات غير مريحة للغاية للقراءة والتخزين.
معايير للسجلات
هذه الأمثلة تؤدي إلى استنتاج أنه ، بالإضافة إلى اختيار نظام لجمع السجلات ، يجب عليك أيضًا
تصميم السجلات بنفسها ! ما هي المتطلبات هنا؟
- يجب أن تكون السجلات بتنسيق قابل للقراءة آليًا (على سبيل المثال JSON).
- يجب أن تكون السجلات مضغوطة ولديها القدرة على تغيير درجة التسجيل من أجل تصحيح المشكلات المحتملة. في نفس الوقت ، في بيئات الإنتاج ، يجب تشغيل أنظمة بمستوى تسجيل مثل تحذير أو خطأ .
- يجب تطبيع السجلات ، أي أنه في كائن السجل ، يجب أن تحتوي جميع الأسطر على نفس نوع الحقل.
يمكن أن تؤدي السجلات غير المهيكلة إلى حدوث مشكلات في تحميل سجلات الدخول إلى المستودع وإيقاف معالجتها تمامًا. للتوضيح ، إليك مثال على خطأ 400 ، واجهه الكثيرون بالتأكيد في سجلات fluentd:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"خطأ يعني أنك تقوم بإرسال حقل غير مستقر إلى الفهرس مع تعيين جاهز. أبسط مثال هو حقل في سجل nginx مع المتغير
$upstream_status . يمكن أن يكون إما رقم أو سلسلة. على سبيل المثال:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}توضح السجلات أن الخادم 10.100.0.10 استجاب لخطأ 404 وأن الطلب ذهب إلى متجر محتوى آخر. نتيجة لذلك ، في السجلات ، أصبح المعنى مثل هذا:
"upstream_response_time": "0.001, 0.007"هذا الموقف واسع الانتشار لدرجة أنه حصل على
ذكر منفصل
في الوثائق .
وماذا عن الموثوقية؟
هناك أوقات تكون فيها جميع السجلات حيوية دون استثناء. ومع هذا ، تواجه مخططات جمع السجلات النموذجية لـ K8s المقترحة / التي تمت مناقشتها أعلاه مشاكل.
على سبيل المثال ، لا يمكن لـ fluentd جمع سجلات من حاويات قصيرة العمر. في أحد مشاريعنا ، ظلت الحاوية التي تحتوي على ترحيل قاعدة البيانات لمدة تقل عن 4 ثوانٍ ، ثم تم حذفها - وفقًا للتعليق التوضيحي المقابل:
"helm.sh/hook-delete-policy": hook-succeededلهذا السبب ، لم يدخل سجل الترحيل في المستودع. يمكن أن تساعد سياسة
before-hook-creation المسبق في هذه الحالة.
مثال آخر هو دوران سجلات Docker. افترض أن هناك تطبيقًا يكتب بنشاط في السجلات. في ظل الظروف العادية ، نتمكن من معالجة جميع السجلات ، ولكن بمجرد ظهور مشكلة - على سبيل المثال ، كما هو موضح أعلاه بالتنسيق الخطأ - توقف المعالجة ، ويقوم Docker بتدوير الملف. خلاصة القول - قد تضيع سجلات العمل الهامة.
هذا هو السبب في
أنه من المهم فصل تدفق السجلات ، ودمج إرسال الأكثر قيمة مباشرة في التطبيق لضمان سلامتهم. بالإضافة إلى ذلك ، لن يكون من الضروري إنشاء نوع من
"تراكم" السجلات التي يمكن أن تصمد أمام عدم توفر التخزين لفترة وجيزة مع الحفاظ على الرسائل الهامة.
أخيرًا ، لا تنسَ أنه
من المهم مراقبة أي نظام فرعي بطريقة جيدة . خلاف ذلك ، من السهل مواجهة موقف يكون فيه fluentd في حالة
CrashLoopBackOff ولا يرسل أي شيء ، مما يعد بفقدان معلومات مهمة.
النتائج
في هذه المقالة ، لا نعتبر حلول SaaS مثل Datadog. تم بالفعل حل العديد من المشكلات الموضحة هنا بطريقة أو بأخرى بواسطة شركات تجارية متخصصة في جمع السجلات ، ولكن لا يمكن للجميع استخدام SaaS لأسباب مختلفة
(أهمها التكلفة والامتثال لـ 152-) .
تبدو المجموعة المركزية من السجلات في البداية وكأنها مهمة بسيطة ، ولكنها ليست على الإطلاق. من المهم أن تتذكر ما يلي:
- تسجيل التفاصيل هو فقط مكونات مهمة ، وبالنسبة للأنظمة الأخرى ، يمكنك تكوين المراقبة وجمع الأخطاء.
- يجب تقليل سجلات الإنتاج إلى الحد الأدنى حتى لا تعطي حمولة إضافية.
- يجب أن تكون السجلات قابلة للقراءة آليًا وتطبيعها وأن يكون لها تنسيق صارم.
- يجب إرسال السجلات الهامة بالفعل في دفق منفصل ، يجب فصله عن السجلات الرئيسية.
- يجدر النظر في بطارية السجل ، والتي يمكن أن توفر من رشقات عالية الحمل وجعل الحمل على التخزين أكثر اتساقا.

هذه القواعد البسيطة ، إذا طبقت في كل مكان ، ستسمح للدوائر المذكورة أعلاه بالعمل - على الرغم من افتقارها إلى المكونات المهمة (البطارية). إذا لم تلتزم بمثل هذه المبادئ ، فإن المهمة ستقودك بسهولة والبنية الأساسية إلى مكون آخر محمّل للغاية (وفي نفس الوقت غير فعال) من النظام.
PS
اقرأ أيضًا في مدونتنا: