
في مؤتمر لمطوري نظام البرمجيات والأدوات - OS DAY 2016 ، الذي عقد في Innopolis في 9-10 يونيو 2016 (كازان) عند مناقشة تقرير عن الهندسة متعددة الخلايا ، تم التعبير عن الفكرة القائلة بأنها ستكون أكثر فعالية في حل مشاكل الذكاء الاصطناعي. تطورت شروط تطوير معالج عام جديد يركز على مهام الذكاء الاصطناعى هذا العام.
يعد المعالج العصبي S2 Multiclet ، والذي تم عرض مشروعه لأول مرة في منتدى Huawei Innovation Forum 2019 ، بمثابة تطور آخر للهندسة متعددة الخلايا. إنه يختلف عن الخلايا المتعددة التي تم إنشاؤها مسبقًا باستخدام نظام من الأوامر ، أي إدخال أنواع جديدة من البيانات صغيرة الحجم (ذات نقطة ثابتة وعائمة) والعمليات معهم. تمت زيادة عدد الخلايا - 256 والتردد - 2.5 جيجا هرتز ، مما ينبغي أن يوفر أداءً فائقًا قدره 81.9 TFlops عند 16F ، وبالتالي ، يجعله قابلاً للمقارنة ، من حيث الحسابات العصبية ، مع إمكانات ASIC TPUs الحديثة المتخصصة (TPU-3: 90 TFlops في 16F).
نظرًا لأن كفاءة استخدام المعالجات تعتمد إلى حد كبير على أمثلية برنامج التحويل البرمجي ، فقد تم تطوير نظام أمثل لتطوير التعليمات البرمجية.
لننظر في الأمر بمزيد من التفصيل.
المقالة السابقة المذكورة تحسينات برنامج التحويل البرمجي التي تستحق التنفيذ. هناك يمكنك العثور على مواد في الهندسة المعمارية متعددة الخلايا إذا لم تكن على دراية بها بالفعل.
توليد أوامر وسيطة ثنائية مع اثنين من الثوابت
تم تقديم تنسيق تعليمي جديد باستخدام المعالج S1 ، مما يسمح بتحديد الوسيطتين كقيمة ثابتة. يتيح لك ذلك تقليل عدد الأوامر في التعليمات البرمجية ، والتخلص من الأوامر غير الضرورية مثل التحميل لتحميل الثوابت في المحول.
على سبيل المثال:
load_l func wr_l @1, #SP
يمكن استبداله بـ:
wr_l func, #SP
أو حتى فريقين في وقت واحد:
load_l [foo] load_l [bar] add_l @1, @2
هناك عنوانان ثابتان ، والقراءة منها يمكن أيضًا استبدالها مباشرةً في وسيطات الأمر:
add_l [foo], [bar]
تم تنفيذ هذا التحسين لكل من يدعم هذا التنسيق. لسوء الحظ ، تبين أنها غير فعالة للغاية ، لسببين:
- عدد الحالات التي يمكن فيها إجراء مثل هذا التحسين صغير جدًا. في قانون التحكيم ، نادراً ما تنشأ المواقف عندما تحتاج إلى معالجة قيمتين معروفتين مسبقًا. في معظم الأحيان ، يتم تحديد مثل هذه الأشياء في مرحلة الترجمة ، ولا يزال هناك سوى القليل من العمل الذي يتعين القيام به في وقت التشغيل. عادة ما تكون هذه بعض العمليات على العناوين ، مرة أخرى ، ثابتة.
- لا تؤدي إزالة أمر التحميل إلى تحرير المعالج من عملية توليد الثابت ، ولكن فقط من إحضار أمر تحميل منفصل ، والذي يعطي تسارعًا ضعيفًا ، وحتى في حالة عدم ذلك دائمًا.
تعظيم نقل السجلات الافتراضية بين الوحدات الأساسية
في LLVM ، الكتل الأساسية هي أقسام خطية يتم فيها تنفيذ التعليمات البرمجية دون المتفرعة. تؤدي الفقرات في بنية متعددة الخلايا نفس الوظيفة تمامًا ، لذلك في أغلب الأحيان عند إنشاء رمز ، تعكس فقرة واحدة كتلة أساسية واحدة. في المعالج R1 ، تم إجراء أي نقل للسجلات الافتراضية بين الفقرات من خلال الذاكرة عن طريق كتابة قيمة السجل المطلوب إلى المكدس وقراءته مرة أخرى في الفقرة التي تحتاج إلى هذا السجل. تنقسم هذه الآلية إلى جزأين: نقل السجل الافتراضي إلى فقرة أخرى للاستخدام المباشر ونقل السجل الظاهري كمعلمة لعقدة فاي.
تُعد عقد Phi نتيجة
لنموذج SSA (التعيين الفردي الثابت) الذي يتم تمثيل لغة عرض LLVM فيه. في هذا النموذج ، يمكن كتابة متغير (أو ، كما في حالة LLVM IR - سجلات افتراضية) مرة واحدة فقط. على سبيل المثال ، هذا الرمز الزائف:
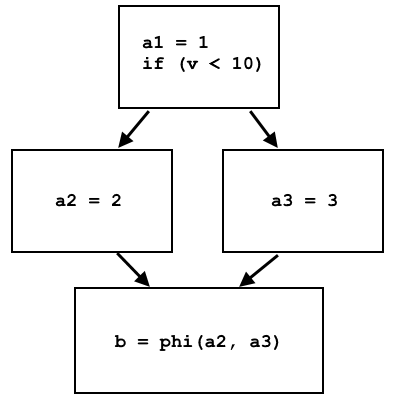
a = 1; if (v < 10) a = 2; else a = 3; b = a;
لم يتم تقديمه في نموذج SSA ، لأنه يمكن الكتابة فوق قيمة المتغير
a . يمكن إعادة كتابة الكود في هذا النموذج ، إذا كنت تستخدم العقدة phi:
a1 = 1; if (v < 10) a2 = 2; else a3 = 3; b = phi(a2, a3);
تحدد العقدة phi a2 أو a3 ، بناءً على مصدر تدفق التحكم:
في LLVM IR phi ، يتم تنفيذ العقد كتعليمات منفصلة ، والتي تختار سجلات افتراضية مختلفة حسب الوحدة الأساسية التي أتى عنصر التحكم منها. إن التنفيذ على معالج هذه التعليمات من خلال الذاكرة بسيط للغاية: كتل أساسية مختلفة تكتب بيانات مختلفة إلى خلية الذاكرة نفسها ، وبدلاً من العقدة phi ، تتم قراءة خلية الذاكرة هذه ، وستكون البيانات مختلفة اعتمادًا على الكتلة الأساسية السابقة.
يشير نموذج SSA إلى أنه عند تهيئة السجل ، ستكون القيمة هناك هي نفسها دائمًا. عند إجراء النقل المباشر للسجلات الافتراضية ، عند كتابة قيمة كل سجل افتراضي على خلية الذاكرة المنفصلة الخاصة بها ، يتم استيفاء شرط SSA دون مشاكل: البيانات في الذاكرة حتى يتم الكتابة فوقه. ومع ذلك ، إذا أردنا نقل السجل من خلال التبديل ، يجب أن نتذكر: حجمه 63 خلية فقط ، وتختفي أي قيمة عند تنفيذ أي أمر 63 أمر. لذلك ، إذا كان السجل الافتراضي مكتوبًا في الفقرة الأولى ، وتم استخدامه بعد اكتمال مئات آخرين ، فمن المستحيل نقله من خلال رمز التبديل ؛ تبقى الذاكرة فقط.
بدأ تنفيذ هذا التحسين بالتحديد بتحسين عقد phi ، لأنه على عكس النقل المباشر للسجلات الافتراضية ، يتم دائمًا تهيئة قيم المعلمات لعقدة phi مباشرةً في الفقرات السابقة (الكتل الأساسية) ، والتي تتيح لك عدم التفكير كثيرًا فيما إذا كان رمز التبديل كبيرًا بدرجة كافية إذا كنا نريد تمرير هذه المعلمات من خلال ذلك.
يسمح لك المجمّع متعدد الخلايا بتعيين أسماء لنتائج الأوامر ، واستخدام نتائجها بهذا الاسم. بدلاً من أن يضطر كل مبرمج إلى حساب عدد الأوامر التي تم الحصول عليها من هذه النتيجة ، يقوم المجمّع بحساب ذلك بمفرده:
result := add_l [A], [B] ; ; ; wr_l @result, C
تعمل هذه الآلية تمامًا ضمن الفقرة الحالية ، لأنها قسم خطي وترتيب الأوامر معروف هناك. يتم استخدام هذا بنشاط عندما ينشئ برنامج التحويل البرمجي رمزًا: يتم تعيين جميع الأوامر أسماء ولا يحتاج برنامج التحويل البرمجي إلى القلق بشأن ترقيم الأوامر. بتعبير أدق ، لم يكن ذلك ضروريًا ، لأنه إذا أردنا الحصول على نتيجة أمر تم تنفيذه في فقرة أخرى ، فلن تعمل الآلية: في مرحلة التجميع ، من المستحيل معرفة أي فقرة تم تنفيذها فعليًا من قبل السابقة إذا كانت هناك عدة مدخلات في الفقرة الحالية. لذلك ، فإن الخيار الوحيد هو الوصول إلى نتائج الفرق من خلال الرقم. لهذا السبب ، لا يمكنك رمي سجلات / قراءات إضافية من الذاكرة في الفقرات المجاورة واستبدال مراجع التسجيل من أمر القراءة بالأمر في الفقرة السابقة.
تجدر الإشارة هنا إلى نتيجة مهمة للغاية: إذا كان للفقرة عدة مدخلات ، فيمكن أن تشير
@ 1 في الأمر الأول من هذا القسم إلى نتائج مختلفة تمامًا ، وفقًا للفقرة السابقة. فاي فاي هو مجرد مثل هذا الموقف. سابقًا ، في جميع الكتل الأساسية التي تهيئ عقدة phi ، تمت كتابة البيانات إلى خلية الذاكرة نفسها ، وبدلاً من العقدة phi ، كانت هناك قراءة من هذه الخلية. وبالتالي ، لم يكن من المهم على الإطلاق المكان الذي كان يوجد به سجل في هذه الخلية في الفقرات السابقة ، تمامًا مثل المكان الذي تمت فيه قراءة هذه الخلية. إذا تخلصت من استخدام الذاكرة - فإنه يتغير.
للسماح للمضيفين phi باستخدام رمز التبديل بدلاً من الذاكرة ، تم القيام بما يلي:
- يتم حساب جميع عقد phi الموجودة في الوحدة الأساسية الحالية (وقد يكون هناك عدة) ، ويتم تمييزها برقم تسلسلي وترتيبها بهذا الترتيب
- لكل عقدة phi ، يتم تجاوز الكتل الأساسية التي تهيئها ؛ تتم إضافة أوامر لتحميل القيم في المحول ( loadu_q ) ، مع وضع علامة بالرقم التسلسلي لعقدة phi المقابلة لها
- يتم أيضًا استبدال تعليمة phi الخاصة بالعقدة نفسها بـ loadu_q برقمها التسلسلي
- يتم إعادة ترتيب جميع الأوامر المضافة بالترتيب المحدد
النقطة الرابعة ضرورية للسبب الموضح بالفعل: إذا كنا نريد أن
يصل الأمر
loadu_q @ 3 إلى النتيجة المحددة لعقدة phi الخاصة به ، فيجب أن تكون جميع فقرات تهيئة الأمر التي تقوم بتحميل البيانات إلى المحول بنفس الترتيب تمامًا. دعنا نعطي مثالاً على النتيجة الحقيقية لتجميع التعليمات البرمجية التي يوجد بها عقدتان من phi في وحدة أساسية واحدة.
الفقرات ذات العُقد المُبدِّلة:
LBB1_27: LBB1_30: SR4 := loadu_q @1 setjf_l @0, LBB1_31 setjf_l @0, LBB1_31 SR4 := loadu_q [#SP + 8] SR5 := loadu_q [#SP + 16] SR5 := loadu_q [#SP] SR6 := loadu_l 0x1 SR6 := add_l @SR4, 0xffffffff SR7 := add_l @SR6, [@SR4] loadu_q @SR5 wr_l @SR7, @SR4 loadu_q @SR6 loadu_q @SR6 complete loadu_q @SR5 complete
فقرة مع اثنين من العقد فاي:
LBB1_31: SR4 := loadu_q @2 SR5 := loadu_q @2 SR6 := loadu_l [#SP + 124] SR7 := loadu_l [#SP + 120] setjf_l @0, @SR7 setrg_q #RETV, @SR4 wr_l @SR5, @SR6 setrg_q #SP, #SP + 120 complete
في السابق ، بدلاً من أوامر
loadu_q ، سيكون هناك عمليات كتابة على الذاكرة وقراءتها.
في عملية تنفيذ هذا التحسين ، كانت هناك أيضًا بعض المشكلات التي لم تكن متوقعة مسبقًا:
- تقوم بعض التحسينات البرمجية الحالية بإعادة ترتيب الأوامر في الأماكن ، على سبيل المثال ، وضع عنوان الفقرة التالية في بداية الفقرة الحالية ، أو تعليمات القراءة / الكتابة مع الذاكرة في بداية / نهاية الفقرة ، على التوالي. تحدث هذه التحسينات بعد العمليات التي تتم باستخدام عقد phi (ما يسمى بتعليمات خفض LLVM قبل إرشادات المعالج) ، لذا فإنها غالبًا ما تؤدي إلى تعطيل الترتيب المدمج لأوامر loadu_q . من أجل عدم تعطيل عمل هذه التحسينات ، اضطررت إلى إنشاء ممر LLVM منفصل ، والذي يرتب أوامر العقد phi في الترتيب الصحيح بعد كل التلاعب الأخرى مع الأوامر.
- اتضح أنه قد ينشأ موقف حيث تقوم وحدة أساسية واحدة بتهيئة عقد phi لوحدتين أساسيتين مختلفتين. أي بعد الخوارزمية المشار إليها ، ستتم إضافة هذه الكتل الأساسية إلى أمر تهيئة loadu_q لكل عقدة phi. في هذه الحالة ، حتى لو كان لديهم عقدة phi واحدة فقط ، في قسم التهيئة ، سيكون هناك أمران loadu_q ، ومن المنطقي أن يكون كلاهما في مكان أخير ، وهو أمر مستحيل بالطبع. لحسن الحظ ، فإن مثل هذه المواقف نادرة جدًا ، لذلك إذا كانت هناك وحدة أساسية تتم فيها تهيئة عقد phi لأكثر من وحدة أساسية أخرى ، فإن الأولى فقط هي التي تستخدم المحول وفقًا للخوارزمية - كما في السابق - من خلال الذاكرة.
كل هذا الأمثل للعقد فاي يمكن أن تستكمل أكثر قليلا. على سبيل المثال ، إذا نظرت إلى الفقرة
LBB1_30 أعلاه ، يمكنك أن ترى أن
أوامر loadu_q تحمل قيم التحميل التي لا يتم استخدامها في أي مكان آخر. أي إذا قمت بإزالة
loadu_q وقمت بتعيين الأوامر التي تنشئ هذه القيم بنفس الترتيب ، فإن أوامر
loadu_q @ 2 في القسم التالي ستقوم أيضًا بتحميل القيم الصحيحة.
المعايير
تم اختبار نتائج التحسين الحالية وفقًا لمعايير CoreMark و WhetStone ، والتي يمكن العثور عليها في
المقال السابق . لنبدأ بنتائج CoreMark على S2 core مقارنة بالنتائج القديمة (الإصدار السابق من المحول البرمجي على S1 core).
يتم عرض قيم CoreMark / MHz النسبية في الرسم البياني:

للحصول على تقدير للتسريع فقط بسبب تحسين عقد phi ، يمكنك إعادة حساب مؤشر CoreMark على واحد متعدد الخلايا على S1 و S2 النوى لتردد 1600 MHz: وهما 1147 و 1224 ، على التوالي ، مما يعني زيادة قدرها 6.7 ٪.
مع WhetStone ، فإن الوضع مختلف إلى حد ما. لقد أثرت التغييرات التي طرأت على النواة هنا على النتيجة ، بالإضافة إلى ذلك ، يعمل هذا المعيار على نواة واحدة (متعددة الخلايا) ويتم حسابه من حيث ميغاهرتز ، وبالتالي فإن تردد المعالج لا يلعب أي دور.
بطاقة النتائج المشحذ:
من الواضح الآن أنه حتى عند استخدام الإصدار السابق من المحول البرمجي على S1 kernel ، يكون المؤشر الكلي أعلى ، ويرجع ذلك بشكل رئيسي إلى اختبارات الفاصلة العائمة MFLOPS1-3. وقد لوحظ هذا العيب أثناء الاختبار وهو ناتج عن حقيقة أن الناقل الداخلي لكتلة الفاصلة العائمة في S2 ، مقارنة بـ S1 ، يعد خطوة واحدة. نتيجة لذلك ، فقدت السلاسل المتعاقبة للأوامر المتعلقة بالبيانات مقياسًا واحدًا لكل أمر. سبب الحاجة إلى هذه الخطوة هو انخفاض في مدة دورة الساعة (زيادة في تردد المعالج من 1.6 جيجاهيرتز إلى 2.5 جيجاهيرتز وزيادة في أوامر التسمية ، على سبيل المثال ، ظهور أمر الضرب مع تراكم MAC). هذا القرار مؤقت. يجري العمل على تقليل طول خط الأنابيب ، وسيتم إصلاح ذلك في المستقبل ، ولكن تم إجراء الاختبارات على الإصدار الحالي من S2.
لتقييم تسريع تحسين برنامج التحويل البرمجي ، تم تجميع WhetStone أيضًا على إصدار سابق وتم إطلاقه على الإصدار الحالي من S2. كان المؤشر الكلي 0.3068 MWIPS / MHz مقابل 0.3267 MWIPS / MHz على المترجم الجديد ، أي مما يدل على تسارع بنسبة 6.5 ٪ بسبب التحسينات المذكورة أعلاه.
يتيح لك نظام التحسين الذي تم تطويره واختباره تنفيذ مخطط التحسين التالي في المستقبل ، أي النقل المباشر للسجلات الافتراضية من خلال المفتاح. كما ذكرنا سابقًا ، لا يمكن إجراء كل نسخة من السجل الافتراضي من خلال المفتاح. نظرًا للحجم المحدود للمفتاح وعدم القدرة على الوصول بشكل صحيح إلى نتائج الفقرات السابقة في حالة وجود العديد من نقاط الدخول إلى النقطة الحالية (يتم حل هذا جزئيًا بواسطة عقد phi) ، فإن الخيار الوحيد الممكن هو نسخ السجلات الافتراضية من فقرة واحدة إلى أخرى ، ولكن يوجد واحد فقط سابق . مثل هذه الحالات ، في الواقع ، ليست قليلة ، وغالبًا ما يكون من الضروري نقل البيانات بشكل مباشر ، على الرغم من أن مقدار تسريع الكود الذي ستمنحه لتقول مقدمًا صعب بالطبع.