من وقت لآخر ، يحتاج المطور
إلى تمرير مجموعة من المعلمات إلى الطلب أو حتى مجموعة كاملة من "الإدخال". حلول غريبة جدا لهذه المشكلة تأتي في بعض الأحيان.
دعنا نذهب "من الجهة المقابلة" ونرى كيف لا يستحق القيام به ولماذا وكيف يمكنك القيام بعمل أفضل.
الإدراج المباشر للقيم في نص الطلب
عادة ما يبدو شيء مثل هذا:
query = "SELECT * FROM tbl WHERE id = " + value
... أو نحو ذلك:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)
حول هذه الطريقة يقال ، مكتوبة
وحتى مرسومة بكثرة:

دائمًا ما يكون هذا
مسارًا مباشرًا لحقن SQL وتحميلًا إضافيًا على منطق العمل ، والذي يُجبر على "الغراء" بسلسلة الاستعلام.
يمكن تبرير هذا النهج جزئيًا فقط إذا كان من الضروري
استخدام التقسيم في إصدارات PostgreSQL 10 أو أقل للحصول على خطة أكثر فاعلية. في هذه الإصدارات ، يتم تحديد قائمة المقاطع الممسوحة ضوئيًا حتى دون مراعاة المعلمات المرسلة ، فقط على أساس نص الطلب.
الحجج $ n
يعد استخدام
العناصر النائبة للمعلمات جيدًا ، فهو يتيح لك استخدام
البيانات المعدة مسبقًا ، مما يقلل من العبء على منطق الأعمال (يتم إنشاء سلسلة استعلام وإرسالها مرة واحدة فقط) ولا يلزم خادم قاعدة البيانات (إعادة التحليل والجدولة لكل مثيل من الطلب).
عدد متغير من الحجج
سوف تنتظرنا المشكلات عندما نريد تمرير عدد غير معروف من الحجج مقدمًا:
... id IN ($1, $2, $3, ...)
إذا تركت الطلب في هذا النموذج ، فعلى الرغم من أنه سيوفر لنا الحقن المحتملة ، إلا أنه سيؤدي إلى الحاجة إلى الإلصاق / تحليل الطلب
لكل خيار من عدد الحجج . بالفعل أفضل من القيام بذلك في كل مرة ، ولكن يمكنك الاستغناء عنه.
يكفي تمرير معلمة واحدة فقط تحتوي على
التمثيل المتسلسل للصفيف :
... id = ANY($1::integer[])
الفرق الوحيد هو الحاجة إلى تحويل الوسيطة بشكل صريح إلى نوع الصفيف المطلوب. لكن هذا لا يسبب مشاكل ، لأننا نعرف مسبقاً مقدماً أين نتصدى.
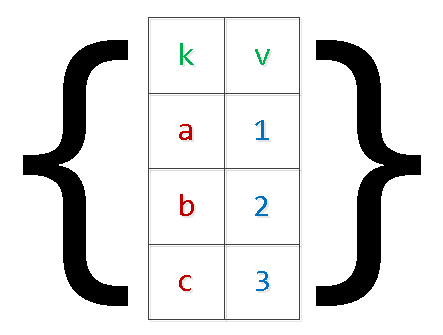
نقل العينة (المصفوفات)
عادة ما تكون هذه هي كل أنواع الخيارات لنقل مجموعات البيانات لإدراجها في قاعدة البيانات "في طلب واحد":
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...
بالإضافة إلى المشكلات الموضحة أعلاه مع "إعادة الالتزام" بالطلب ، يمكن أن يؤدي ذلك أيضًا إلى
نفاد الذاكرة وتعطل الخادم. السبب بسيط - يحتفظ PG بذاكرة إضافية للوسائط ، ويقتصر عدد السجلات في المجموعة فقط على منطق الأعمال المطبق في قائمة الأمنيات المطبقة. في الحالات السريرية بشكل خاص ، كان على المرء أن يرى
الحجج "المرقمة" أكبر من 9000 دولار - لا حاجة لذلك.
نعيد كتابة الطلب ، مع تطبيق
التسلسل "ثنائي المستوى" :
INSERT INTO tbl SELECT unnest[1]::text k , unnest[2]::integer v FROM ( SELECT unnest($1::text[])::text[]
نعم ، في حالة وجود قيم "معقدة" داخل المصفوفة ، يجب أن تكون محاطة بعلامات اقتباس.
من الواضح أنه بهذه الطريقة يمكنك "توسيع" التحديد بعدد عشوائي من الحقول.
غير عش ، عش ، ...
بشكل دوري ، توجد خيارات نقل بدلاً من "مجموعة من المصفوفات" للعديد من "صفائف الأعمدة" ، والتي ذكرتها
في مقال سابق :
SELECT unnest($1::text[]) k , unnest($2::integer[]) v;
باستخدام هذه الطريقة ، عند ارتكاب خطأ عند إنشاء قوائم قيم لأعمدة مختلفة ، من السهل جدًا الحصول على
نتائج غير متوقعة تمامًا ، والتي تعتمد أيضًا على إصدار الخادم:
JSON
بدءًا من الإصدار 9.3 ، قدمت PostgreSQL وظائف كاملة للعمل مع نوع json. لذلك ، إذا حدث تعريف لمعلمات الإدخال في المستعرض الخاص بك ، يمكنك إنشاء
كائن json لاستعلام SQL هناك:
SELECT key k , value v FROM json_each($1::json);
بالنسبة للإصدارات السابقة ، يمكن استخدام نفس الطريقة
لكل (hstore) ، ولكن "
الإلتفاف " الصحيح مع الهروب من الكائنات المعقدة في hstore يمكن أن يسبب مشاكل.
json_populate_recordset
إذا كنت تعلم مقدمًا أن البيانات من صفيف json "الإدخال" ستذهب لملء نوع من الجداول ، يمكنك حفظ الكثير في "إلغاء التسجيل" في الحقول والانتقال إلى الأنواع اللازمة باستخدام وظيفة json_populate_recordset:
SELECT * FROM json_populate_recordset( NULL::pg_class , $1::json
json_to_recordset
وهذه الوظيفة ببساطة "توسع" مجموعة الكائنات المنقولة في التحديد ، دون الاعتماد على تنسيق الجدول:
SELECT * FROM json_to_recordset($1::json) T(k text, v integer);
الجدول المؤقت
ولكن إذا كانت كمية البيانات في العينة المرسلة كبيرة جدًا ، فإن رميها في معلمة متسلسلة واحدة أمر صعب ، وأحيانًا مستحيل ، لأنه يتطلب
تخصيص كمية كبيرة من الذاكرة لمرة واحدة. على سبيل المثال ، تحتاج إلى جمع حزمة كبيرة من البيانات حول الأحداث من نظام خارجي لفترة طويلة ، ثم تريد معالجتها مرة واحدة على جانب قاعدة البيانات.
في هذه الحالة ، سيكون أفضل حل هو استخدام
الجداول المؤقتة :
CREATE TEMPORARY TABLE tbl(k text, v integer); ... INSERT INTO tbl(k, v) VALUES($1, $2);
هذه الطريقة جيدة
لنقل نادر من كميات كبيرة من البيانات.
من وجهة نظر وصف بنية بياناته ، يختلف الجدول المؤقت عن الجدول "المعتاد" فقط بميزة واحدة فقط
في جدول نظام pg_class ، وفي
pg_type ، pg_depend ، pg_attribute ، pg_attrdef ، ... إنه لا شيء على الإطلاق.
لذلك ، في أنظمة الويب التي تحتوي على عدد كبير من الاتصالات قصيرة الأجل لكل منها ، سينشئ هذا الجدول سجلات نظام جديدة في كل مرة ، يتم حذفها مع إغلاق قاعدة البيانات. نتيجة لذلك ، يؤدي
الاستخدام غير المنضبط لـ TEMP TABLE إلى "تورم" الجداول في pg_catalog وإبطاء العديد من العمليات التي تستخدمها.
بالطبع ، يمكن قتال هذا بمساعدة
التمرير الدوري VACUUM FULL من خلال جداول كتالوج النظام.
متغيرات الجلسة
افترض أن معالجة البيانات من الحالة السابقة معقدة إلى حد ما بالنسبة لاستعلام SQL واحد ، لكنك تريد القيام بذلك كثيرًا بما فيه الكفاية. بمعنى أننا نريد استخدام المعالجة الإجرائية في
كتلة DO ، ولكن استخدام نقل البيانات عبر الجداول المؤقتة سيكون مكلفًا للغاية.
لن نتمكن من استخدام معلمات $ n لنقلها إلى الكتلة المجهولة أيضًا. سوف تساعدنا متغيرات الجلسة ووظيفة
الإعداد الحالية في الخروج من هذا الموقف.
قبل الإصدار 9.2 ، كان عليك
تكوين مساحة اسم custom_variable_classes مسبقًا
لمتغيرات الجلسة "your". في الإصدارات الحالية ، يمكنك كتابة شيء مثل هذا:
SET my.val = '{1,2,3}'; DO $$ DECLARE id integer; BEGIN FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP RAISE NOTICE 'id : %', id; END LOOP; END; $$ LANGUAGE plpgsql;
يمكن أن تجد اللغات الإجرائية الأخرى المدعومة حلولًا أخرى.
هل تعرف المزيد من الطرق؟ شارك في التعليقات!