عاجلاً أم آجلاً ، يجب على أي خدمة متنامية تقييم قدراتها الفنية. كم عدد الزوار الذين يمكن أن نخدمهم؟ ما هي قدرة النظام؟ هل وصلنا إلى الحد الأقصى ولن نسقط إذا جذبنا عدة آلاف من المستخدمين؟ كم عدد موارد الحوسبة الإضافية المدرجة في الميزانية للعام المقبل لتلبية خطط النمو؟
يمكن الحصول على الإجابات بشكل تحليلي عن طريق توجيه الأسئلة إلى مطور متمرس / DevOps / SRE / admin. تعتمد موثوقية التقييم على عدد كبير من العوامل: بدءًا من سرعة ملء النظام بالوظيفة والرسم البياني للعلاقات بين المكونات وتنتهي بالوقت الذي أمضاه الخبير صباحًا في حركة المرور. وكلما زاد تعقيد النظام ، زاد الشكوك في مدى كفاية التقييم التحليلي.
اسمي مكسيم كوبريانوف ، منذ خمس سنوات ، كنت أعمل في Yandex.Market. سأخبر اليوم قراء هبر كيف تعلمنا تقييم قدرة خدماتنا وما الذي جاء منها.
نذهب إلى هذا المنصب
هيكل مكونات السوق معقد إلى حد ما ، لذلك قررنا تقييم قدرة أكبر وأغلى الخدمات في التوسع. علاوة على ذلك ، يجب أن يعتمد عدد الطلبات اليومية بشكل واضح على حجم الجمهور اليومي للسوق (المستخدمون النشطون يوميًا ، DAU). لماذا بالضبط من DAU؟ لأن المحللين ، الذين يضعون توقعات للأشهر والسنوات المقبلة ، يحسبون دائمًا الحجم المستقبلي للجمهور ، وسوف نستفيد من هذا الظرف اللطيف.
الآن دعنا نتحدث عن بدونها يستحيل بناء تقييمات موضوعية: حول مقاييس الخدمة. إذا كان عدد طلبات الخدمة يعتمد على DAU ، فإننا نحتاج بالتأكيد إلى "الطلبات في الثانية" (طلبات في الثانية ، RPS). بالإضافة إلى ذلك ، لتقييم جودة الخدمة ، تحتاج إلى معرفة النسبة المئوية للأخطاء وأوقات الاستجابة (توقيت الطلب). سيتم اعتبار الخطأ استجابة برمز HTTP 500 أو أعلى. الأخطاء من مجموعة 4xx هي من جانب العميل وفي نظام العمل العادي عادة لا تقول أي شيء عن مشاكل الخدمة. بالنسبة إلى التوقيت ، من المعتاد بالنسبة لنا حساب وتخزين النسب المئوية 80 و 95 و 99 و 99.9 من أوقات الاستجابة ، ولكن قد تختلف مجموعة معينة قليلاً من خدمة إلى أخرى.
لذلك ، لدينا مقاييس لتكرار الطلب ، ونسبة الأخطاء ومجموعة من النسب المئوية لوقت الاستجابة. ونعرف أيضًا خدمة DAU لكل يوم وللفترات المستقبلية (في شكل تنبؤات). نظرًا لأن أنماط سلوك المستخدم المتوسطة لا تتغير كثيرًا من يوم لآخر ، دعنا نقول ما يلي: معرفة RPS في الفترة الأكثر نشاطًا في يوم العمل (ذروة RPS) ، يمكننا التنبؤ بذروة RPS للفترات المستقبلية ، بشرط أن يكون لدينا توقعات DAU. والعكس بالعكس: إذا عرفنا عدد الطلبات في الثانية الواحدة التي يمكن للنظام تحملها دون الإخلال بالاتفاق على وقت الاستجابة والنسبة المئوية للأخطاء ، فيمكننا تقدير مقدار الجمهور الذي يمكننا تقديمه ، أي أننا نعرف سعة النظام.
حسنًا ، قررنا المهمة: إصلاح توقيت الاستجابة والنسبة المئوية للأخطاء في شكل اتفاقيات والعثور على الحد الأقصى RPS الذي يمكن للنظام تحمله في ظل هذه الظروف. كيف سنقرر؟
نحن اطلاق النار على الهدف
إليك طريقة كلاسيكية لحل المشكلة: نقوم بتجميع موقع اختبار ، ونأخذ سجلات الوصول إلى النظام من بيئة الإنتاج ، ونصنع خراطيشها ونطلق النظام ، ونزيد من تكرار الطلبات ، حتى يظهر الموقع تدهورًا كبيرًا في توقيت الاستجابة و / أو الأخطاء. في هذه المرحلة ، نوقف ونصلح تكرار الطلبات (نفس RPS). الفوز؟ لا يهم كيف. وهنا السبب:
- موقع الاختبار ، كقاعدة عامة ، لا يتطابق مع النظام الأساسي تحت الخدمة في بيئة الإنتاج ؛
- يتغير رمز الخدمة كل يوم ، أو أكثر من ذلك ؛
- التجارب قد تؤثر على الحمل ؛
- تعتمد شدة طلبات المستخدم على الوقت من اليوم وظروف أخرى ؛
- نادراً ما تعمل الخدمات الحديثة بمعزل عن غيرها ، وغالبًا ما تقدم استعلامات فرعية للخدمات الأخرى ، ويجب أن يؤخذ ذلك في الاعتبار بطريقة أو بأخرى.
التحسين: سنطلق الخدمة تلقائيًا كل يوم ، ونجمع الخراطيش من المجلات في ساعات الذروة. وحتى لا نضيع الموارد في موقع الاختبار ، سنبدأ في قصف المكونات التي تهمنا في نفس الموقف بدوره. هذا يبدو معقدًا ولا يحل جميع المشكلات. ولكن ما هي الخيارات الأخرى هناك؟
محاكاة الواقع
الفكرة العامة هي: نقوم بنسخ جزء من حركة المرور من الموازنات إلى الموقع ، حيث نقوم بتجميع التناظرية الكاملة لبيئة الإنتاج في صورة مصغرة ، وضبط حجم حركة المرور المنسوخة ، نبحث عن نقطة الانحطاط. الفكرة جميلة ، ونحن في السوق نفعل ذلك لاختبار وظائف جديدة ومقارنة سلوك الإصدارات الجديدة مع الإصدارات القديمة.
تحدث زميلي يوجين
عن ذلك بالتفصيل - انظر القسم الموجود على مجموعة الظل. ولكن هناك صعوبات واضحة للغاية:
- مشكلة التفاعل مع المكونات الخارجية لم يتم حلها ، لأنه مكلف للغاية لعمل نسخة من بيئة الإنتاج بأكملها ؛
- يمكن خلط سجلات الاستعلام من نظام النسخ المتطابق عن طريق الخطأ مع سجلات بيئة الإنتاج ، مما يعني أنه من الضروري إنشاء نظام مع وضع علامة على حركة مرور النسخ المتطابق بحيث يمكن العثور عليه وتنظيفه لاحقًا
- عادة ما يتم عكس الطلبات إما كاملة أو كنسبة مئوية من الإجمالي ، وهذه الدقة لا تناسبنا (ولكن يمكن حلها ، نحن نعمل في هذا الاتجاه).
بشكل عام ، يعتبر تقليد الإنتاج طريقة جيدة جدًا وواعدة ، ولكنه مكلف للغاية وذو قيود كبيرة.
اختبار مباشرة في الإنتاج
ثم وصلنا في النهاية إلى لذيذ. لكل مكون تم اختباره ، نرفع مثيلًا منفصلاً في الإنتاج ، يتم تنظيم تكرار الطلبات من الموازن بدقة عالية. آخر مرة ،
سألنا القراء : "هل HAProxy يكفي لك؟ هل كانت هناك حاجة لكتابة شيء خاص بك؟ " لذلك ، هذه هي الحالة النادرة للغاية عندما لم تكن كافية واضطررت إلى الكتابة.
في الوقت نفسه ، هناك خدمة منفصلة تراقب عن كثب مقاييس المثيل المحمل ، وعندما تقترب المؤشرات من القيم الحرجة ، فإنها تغلق الصمام على الموازن ، مما يقلل من تكرار الطلبات. إذا كانت الخدمة تعمل ضمن حدود مقبولة ، يتم فتح الصمام ، على العكس من ذلك. بطبيعة الحال ، فإن عتبات التوقيت والأخطاء عند تحميل الخدمة المباشرة تكون أكثر تحفظًا بشكل ملحوظ (عادة بنسبة 5-10٪) منها في أرض التدريب ، لأننا لا نريد أن نزيد التفاعل مع المستخدمين. وبالتالي ، يعمل المثيل المحمّل دائمًا إلى الحد الأقصى. نصلح هذه المؤشرات. ثم لدينا حسابي: نحن نعرف عدد مراكز الخدمة تحت الحمل في كل لحظة ، ونحن نعرف DAU أمس. من هذا ، نحن نعتبر إعادة التدوير واحتياطيات السعة وخيارات سلوك النظام عند تعطيل موقع أو آخر. كل هذا يضع في القاعدة حيث يتم بناء رسومات جميلة من. بناءً على هذه البيانات ، عندما تنخفض السعة إلى ما دون العتبة ، يتم تشغيل التنبيهات.
دعونا نلقي نظرة على الرسوم البيانية
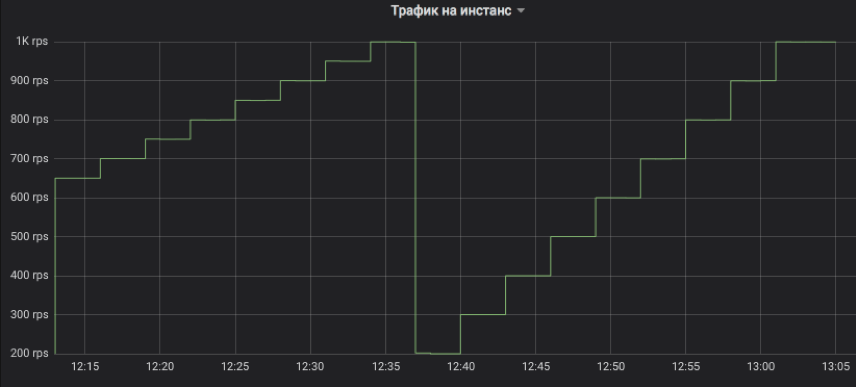
هذه هي الطريقة التي نتحكم بها في تدفق حركة المرور إلى المثيل الذي تم اختباره. يمكن أن تكون الخطوة أي مضاعفات لـ 1 RPS. على الرسم البياني ، على سبيل المثال ، قمنا بتصميم نموذج للتسلق بفاصل زمني مدته ثلاث دقائق: أولاً ، من 650 إلى 1K RPS بزيادات قدرها 50 ، ثم من 200 إلى 1K RPS بزيادات 100. واسمحوا لي أن أذكركم ، هذه هي حركة مرور مستخدم حقيقية تلقاها العملاء إجابات.
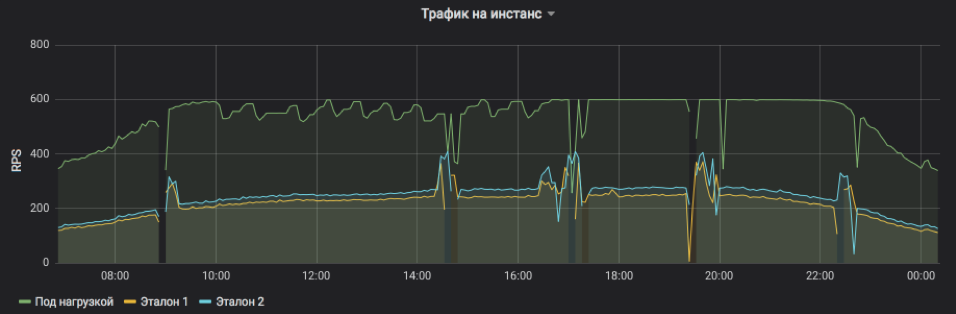
هذا يدل على RPS لثلاث حالات: واحدة تحت الحمل واثنين من السيطرة. تم تعيين الموضوع بشكل مصطنع الحد الأقصى من 600 RPS. قد تكون الخدمة أكثر ، لكنها تصبح غير مستقرة وتعتمد على التأثيرات الخارجية. من الواضح أن طلبات الخدمة في النصف الأول من اليوم ، في المتوسط ، أثقل ولا يمكن أن يصل المثيل إلى ذروته في ظل ظروف مقبولة ، ولكن في المساء ، يعود كل شيء إلى طبيعته. يعد الاندفاع والإغفالات على المخطط بمثابة إعادة تشغيل مثيل لتخطيط الإصدارات والتحديثات الأخرى (كلها تحت التوازن ، ولم يصب أحد بأذى). وتعد تعديلات RPS خطوة بخطوة على موضوع الاختبار مجرد عمل لخوارزمية تسعى إلى الحد من الاحتمالات.

من الواضح أن عدد مرات تكرار طلبات الخدمة والحمل الذي يمكن لمثيل واحد تحمله.
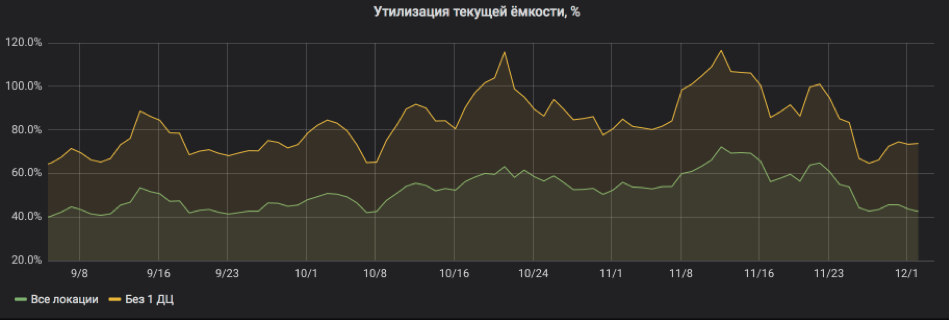
وهنا نعيد حساب كل شيء في المئة من الاستخدام. يوضح الرسم البياني أن الخدمة قد تم تحميلها بشكل كبير جدًا ، وعندما تم إيقاف تشغيل أحد المواقع ، كانت هناك مخاطر لمغادرة جيش لبنان الجنوبي. ولكن الآن أصبح كل شيء على ما يرام: لقد تمت إضافة الموارد إلى الخدمة ، وعادت عمليات إعادة التدوير إلى حدود مقبولة.
وبالتالي ، فإن اختبار الحمل في الإنتاج يسمح لك بتقييم قدرة النظام بسرعة والتنبؤ باستهلاك الموارد للفترات المستقبلية. في الوقت نفسه ، لا يضيف النظام فعليًا نفقات ملحوظة ويمكنك العمل بأمان مع خدمات جيدة ، حيث أننا لا ننشئ حركة مرور جديدة ، ولكننا نعيد توزيعها بدقة. وأخيراً: للعمل ، كقاعدة عامة ، ليس مطلوبًا تغيير رمز النظام التجريبي نفسه ، والذي يسمح باختبار التطبيقات القديمة.
Refleksiruem
لم تنجح هذه المنهجية في السوق منذ أكثر من عام ، ويمكننا مشاركة الملاحظات والتوصيات:
- بجانب المثيل المحمّل ، يجب أن يكون هناك تحكم واحد عادي ، ويفضل أن يكون البخار ، لأن التدهور غالبًا ما يحدث ليس بسبب زيادة تحميل المثيل ، ولكن بسبب مشاكل عامة في الخدمة ككل.
- تعمل هذه التقنية بشكل جيد فقط مع تلك المكونات التي يزيد حملها عن مئات الطلبات في الثانية الواحدة للموقع. السبب بسيط للغاية: نحتاج إلى تحميل كل من مثيل تم اختباره وواحد أو اثنين من عناصر التحكم. إذا لم يكن هناك ما يكفي من حركة المرور ، فلن نصل إلى التشبع أو لن نكون قادرين على المقارنة بصدق. وإذا كان حد RPS لكل مثيل صغيرًا جدًا ، فقد تكون الخطوة الدنيا لتغيير وتيرة الطلب إلى 1 RPS صعبة للغاية.
- من الأفضل اختبار الجبهات والواجهات الخلفية في مواقع مختلفة ، بحيث لا تؤثر القطع الأثرية للواجهات الخلفية لاختبار الحمل على تقدير السعة الأمامية.
- عندما نحلل توقيت الاستجابة ونبحث عن علامات التدهور ، نأخذ عادةً مجاميع مدتها خمس دقائق ونحسب الوسيط حتى لا نتفاعل مع رشقات عشوائية.
- السبب الرئيسي أن تعطل مثيل تحميل الخدمة هو مساحة القرص لملفات السجل (سجلات). ينسون دائما عنه.
- يعد تسجيل الدخول إلى قرص خوادم الويب المحملة بالإدخال / الإخراج سببًا شائعًا للغاية لتدهور التوقيت ، حتى على محركات أقراص الحالة الصلبة. قم دائمًا بتشغيل التخزين المؤقت والتسجيل غير المتزامن وأي شيء آخر ، فقط لعدم الانتظار حتى ينتهي التسجيل.
- الحمل الليلي ليس مؤشراً ، لأن الطلبات في المتوسط أثقل نظرًا لحصة أكبر من الروبوتات. لذلك ، من أجل تقدير السعة ، من الأفضل تحديد النطاق من وقت الإضاءة التقليدي من اليوم ، وفي الليل فقط لتقليل تدفق الطلبات في حالة ظهور علامات التدهور.
- إن النسبة المئوية 99.9 من توقيت الاستجابة غير مجدية لتقدير السعة ، نظرًا لأن ضمانات توفر الشبكة نادراً ما تتجاوز 99٪.
- بدء جدول زمني وتسجيل إصدارات الخدمة والأحداث الهامة الأخرى. يساعد في العثور على ما أدى إلى انخفاض في السعة.
- في تحليل تفصيلي لأسباب التدهور ، يكون التتبع مفيدًا أيضًا: يتم إضافة رأس علامة إلى كل طلب خدمة ، والذي ينتقل من المقدمة إلى آخر الخلفية ويدخل جميع السجلات. وبهذه الطريقة يمكنك تتبع مسار الطلب بالكامل وفهم أسباب التأخير.