يمكن تمثيل أي
صورة نقطية
كمصفوفة ثنائية الأبعاد . عندما يتعلق الأمر بالألوان ، يمكن تطوير الفكرة من خلال النظر إلى الصورة في شكل
مصفوفة ثلاثية الأبعاد ، حيث يتم استخدام قياسات إضافية لتخزين البيانات لكل من الألوان.
إذا اعتبرنا أن اللون النهائي هو مزيج من ما يسمى الألوان الأساسية (الأحمر والأخضر والأزرق) ، في المصفوفة ثلاثية الأبعاد لدينا ، نحدد ثلاث طائرات: الأولى للأحمر والثانية للخضرة والأخيرة للأزرق.
سوف نسمي كل نقطة في هذه المصفوفة بكسل (عنصر صورة). كل بكسل يحتوي على معلومات الكثافة (عادة في شكل قيمة عددية) من كل لون. على سبيل المثال ، تعني
البيكسل الأحمر أنه يحتوي على 0 أخضر و 0 أزرق وحد أقصى أحمر. يمكن تشكيل
بكسل وردي باستخدام مزيج من ثلاثة ألوان. باستخدام نطاق رقمي من 0 إلى 255 ، يتم تعريف البيكسل الوردي على أنه
الأحمر = 255 ،
والأخضر = 192 ، والأزرق = 203 .

تم نشر هذا المقال بدعم من EDISON.
نقوم بتطوير تطبيقات للمراقبة بالفيديو ، وتدفق الفيديو ، وكذلك تسجيل الفيديو في غرفة العمليات الجراحية .
تقنيات الترميز اللوني البديلة
لتمثيل الألوان التي تشكل الصورة ، هناك العديد من الطرز الأخرى. على سبيل المثال ، يمكنك استخدام لوحة مفهرسة يلزم فيها بايت واحد فقط لتمثيل كل بكسل ، بدلاً من الثلاثة اللازمة عند استخدام نموذج RGB. في مثل هذا النموذج ، يمكنك استخدام مصفوفة ثنائية الأبعاد بدلاً من مصفوفة ثلاثية الأبعاد لتمثيل كل لون. هذا يحفظ الذاكرة ، لكنه يعطي لون أقل.

RGB
على سبيل المثال ، ألق نظرة على هذه الصورة أدناه. الوجه الأول هو رسمت تماما. البعض الآخر هو الأحمر والأحمر والأزرق الطائرات (شدة الألوان المقابلة هو مبين في الرمادي).

نرى أن ظلال اللون الأحمر في الأصل ستكون في نفس الأماكن التي يتم فيها ملاحظة الأجزاء اللامعة من الشخص الثاني. بينما يمكن ملاحظة مساهمة اللون الأزرق بشكل أساسي فقط في عيون ماريو (الوجه الأخير) وعناصر ملابسه. لاحظ عندما تكون مستويات الألوان الثلاثة أقل مساهمة (أحلك أجزاء من الصور) - هذا هو شارب ماريو.
لتخزين شدة كل لون ، يلزم عدد معين من وحدات البت - تسمى هذه القيمة
عمق البت . لنفترض أنه تم إنفاق 8 بتات (بناءً على قيمة من 0 إلى 255) على مستوى لون واحد. ثم لدينا عمق اللون 24 بت (8 بت * 3 R / G / B الطائرة).
خاصية أخرى للصورة هي
الدقة ، وهي عدد البكسل في بعد واحد. يشار إليها غالبًا
بالعرض × الارتفاع ، كما هو موضح في المثال التالي بالصورة 4 في 4.

خاصية أخرى نتعامل معها عند العمل مع الصور / الفيديو هي
نسبة العرض إلى الارتفاع ، التي تصف العلاقة التناسبية المعتادة بين عرض الصورة وارتفاعها أو بكسلها.
عندما يقولون أن فيلمًا أو صورة 16 × 9 ، يشير عادةً إلى
نسبة العرض إلى الارتفاع (
DAR - من
نسبة العرض إلى الارتفاع ). ومع ذلك ، في بعض الأحيان قد تكون هناك أشكال مختلفة من البيكسلات الفردية - في هذه الحالة ، نتحدث عن
نسبة البيكسلات (
PAR - من
Pixel Aspect Ratio ).


ملاحظة إلى المضيفة: يتوافق DVD مع DAR 4 في 3
على الرغم من أن الدقة الفعلية للقرص الرقمي هي 704 × 480 ، إلا أنها تحتفظ بنسبة عرض إلى ارتفاع تبلغ 4: 3 حيث تم ضبط PAR على 10:11 (704 × 10/480 × 11).
وأخيرًا ، يمكننا تعريف
مقطع فيديو على أنه سلسلة من الإطارات
n خلال فترة
زمنية ، والتي يمكن اعتبارها بُعدًا إضافيًا. ثم
n هو معدل الإطارات أو عدد الإطارات في الثانية (
FPS - من
إطارات في الثانية ).

عدد البتات في الثانية المطلوبة لعرض الفيديو هو
معدل بته.
معدل البت = العرض * الارتفاع * عمق البت * الإطارات في الثانية الواحدة
على سبيل المثال ، لمقاطع الفيديو التي تحتوي على 30 إطارًا في الثانية ، ستكون هناك حاجة إلى 24 بت لكل بكسل ، بدقة 480 × 240 ، 82،944،000 بت في الثانية أو 82،944 ميغابت في الثانية (30 × 480 × 240 × 24) - ولكن هذا إذا كنت لا تستخدم أي من طرق الضغط.
إذا كان معدل البت
ثابتًا تقريبًا ، فيُطلق عليه
معدل بتات ثابت (
CBR - من
معدل بت ثابت ). ولكن يمكن أن يختلف أيضًا ، في هذه الحالة يُطلق عليه
معدل بتات متغير (
VBR - من
معدل بت متغير ).
يوضح هذا الرسم البياني VBR محدودة عندما لا يتم إنفاق الكثير من البتات في حالة وجود إطار مظلم تمامًا.

في البداية ، طور المهندسون طريقة لمضاعفة معدل الإطارات المتصورة لعرض الفيديو دون استخدام نطاق ترددي إضافي. تُعرف هذه الطريقة باسم
الفيديو المتشابك ؛ في الأساس ، يرسل نصف الشاشة في "الإطار" الأول ، والنصف الآخر في "الإطار" التالي.
حاليا ، يتم تنفيذ تصوير المشهد بشكل رئيسي باستخدام
تقنية المسح التدريجي . هذه طريقة لعرض الصور المتحركة أو تخزينها أو نقلها حيث يتم رسم جميع خطوط كل إطار بالتتابع.

حسنا اذن! الآن نحن نعرف كيف يتم تمثيل الصورة في شكل رقمي ، وكيف يتم ترتيب ألوانها ، وعدد البتات في الثانية التي ننفقها لإظهار الفيديو إذا كانت سرعة البث ثابتة (CBR) أو متغير (VBR). نحن نعلم بدقة معينة باستخدام معدل إطارات معين ، تعرفنا على العديد من المصطلحات الأخرى ، مثل الفيديو المتشابك ، PAR وبعض المصطلحات الأخرى.
إزالة التكرار
من المعروف أن الفيديو بدون ضغط لا يمكن استخدامه بشكل طبيعي. سيشغل الفيديو بالساعة بدقة 720 بكسل وتردد 30 لقطة في الثانية 278 جيجابايت. نصل إلى هذه القيمة عن طريق ضرب 1280 × 720 × 24 × 30 × 3600 (العرض ، الارتفاع ، البتات لكل بكسل ، FPS والوقت بالثواني).
باستخدام
خوارزميات ضغط ضياع مثل DEFLATE (المستخدمة في PKZIP ، Gzip ، و PNG) لن يقلل بما فيه الكفاية من عرض النطاق الترددي المطلوب. عليك أن تبحث عن طرق أخرى لضغط الفيديو.
لهذا ، يمكنك استخدام ميزات رؤيتنا. نحن نميز السطوع أفضل من الألوان. الفيديو هو مجموعة من الصور المتسلسلة التي تتكرر بمرور الوقت. هناك اختلافات صغيرة بين الإطارات المجاورة لنفس المشهد. بالإضافة إلى ذلك ، يحتوي كل إطار على العديد من المساحات التي تستخدم نفس اللون (أو ما شابه).
اللون والسطوع وعيوننا
عيوننا أكثر حساسية للسطوع من اللون. يمكنك أن ترى بنفسك من خلال النظر إلى هذه الصورة.
إذا كنت لا ترى أنه في النصف الأيسر من الصورة ، تكون ألوان المربعات
A و
B متماثلة بالفعل ، فهذا أمر طبيعي. دماغنا يجعلنا نولي المزيد من الاهتمام ل chiaroscuro بدلا من اللون. على الجانب الأيمن بين المربعات المحددة ، يوجد رابط من نفس اللون - لذلك ، (أي دماغنا) نحدد بسهولة أنه في الواقع ، يوجد نفس اللون.
دعنا ننظر إلى (مبسطة) كيف تعمل أعيننا. العين هي عضو معقد يتكون من أجزاء كثيرة. ومع ذلك ، نحن مهتمون أكثر في المخاريط والعصي. تحتوي العين على حوالي 120 مليون قضيب و 6 ملايين مخروط.
النظر في تصور اللون والسطوع كوظائف منفصلة لأجزاء معينة من العين (في الواقع ، كل شيء أكثر تعقيدًا إلى حد ما ، لكننا سنبسط). خلايا قضيب هي المسؤولة أساسا عن السطوع ، في حين أن الخلايا المخروطية هي المسؤولة عن اللون. يتم تقسيم المخاريط إلى ثلاثة أنواع ، اعتمادًا على الصبغة الموجودة: S-cones (اللون الأزرق) ، M-cones (اللون الأخضر) و L-cones (اللون الأحمر).
نظرًا لأن لدينا قضبان (سطوع) أكثر بكثير من الأقماع (اللون) ، يمكننا أن نستنتج أننا قادرون على التمييز بين التحولات بين الظلام والضوء أكثر من الألوان.

وظائف حساسية التباين
طور الباحثون في علم النفس التجريبي والعديد من المجالات الأخرى نظريات حول الرؤية البشرية. واحد منهم يسمى وظائف حساسية التباين . ترتبط بالإضاءة المكانية والزمانية. باختصار ، يتعلق الأمر بعدد التغييرات المطلوبة قبل أن يراها المراقب. لاحظ الجمع لكلمة "وظيفة". هذا يرجع إلى حقيقة أنه يمكننا قياس وظائف الحساسية للتناقض ليس فقط مع الصور بالأبيض والأسود ، ولكن أيضًا للون. تظهر نتائج هذه التجارب أنه في معظم الحالات ، تكون أعيننا أكثر حساسية للسطوع من اللون.
نظرًا لأنه من المعروف أننا أكثر حساسية لسطوع الصورة ، يمكنك محاولة استخدام هذه الحقيقة.
نموذج اللون
اكتشفنا بعض الشيء كيفية التعامل مع الصور الملونة باستخدام مخطط RGB. هناك نماذج أخرى. يوجد نموذج يفصل النصوع عن اللون ويعرف باسم
YCbCr . بالمناسبة ، هناك نماذج أخرى تقوم بعمل فصل مماثل ، لكننا سننظر في هذا النموذج فقط.
في نموذج الألوان هذا ، تمثل
Y درجة السطوع ، وتستخدم قناتان للألوان:
Cb (أزرق مشبع) و
Cr (أحمر مشبع). يمكن الحصول على YCbCr من RGB ، وكذلك التحويل العكسي ممكن. باستخدام هذا النموذج ، يمكننا إنشاء صور بالألوان الكاملة ، كما نرى أدناه:

تحويل بين YCbCr و RGB
يعترض شخص ما: كيف يمكن الحصول على كل الألوان إذا لم يتم استخدام اللون الأخضر؟
للإجابة على هذا السؤال ، قم بتحويل RGB إلى YCbCr. نستخدم المعاملات المعتمدة في
المعيار BT.601 ، الذي أوصت به وحدة
قطاع الاتصالات الراديوية . تحدد هذه الوحدة معايير الفيديو الرقمية. على سبيل المثال: ما هو 4K؟ ما ينبغي أن يكون معدل الإطار ، القرار ، نموذج اللون؟
أولاً ، نحسب السطوع. نستخدم الثوابت التي اقترحها الاتحاد الدولي للاتصالات ونستبدل قيم RGB.
Y = 0.299
R + 0.587
G + 0.114
Bبعد أن حصلنا على السطوع ، سوف نفصل بين اللونين الأزرق والأحمر:
Cb = 0.564 (
B -
Y )
Cr = 0.713 (
ص -
ص )
ويمكننا أيضًا التحويل مرة أخرى وحتى الحصول على اللون الأخضر باستخدام YCbCr:
R =
Y + 1.402
CrB =
Y + 1.772
CbG =
Y - 0.344
Cb - 0.714
Crكقاعدة عامة ، تستخدم شاشات العرض (الشاشات وأجهزة التلفزيون والشاشات وما إلى ذلك) طراز RGB فقط. ولكن يمكن تنظيم هذا النموذج بطرق مختلفة:

اختزال اللون
من خلال تقديم الصورة كمزيج من السطوع والألوان ، يمكننا استخدام حساسية أعلى للنظام البصري البشري للسطوع مقارنة بالألوان إذا قمنا بحذف المعلومات بشكل انتقائي. اختزال الألوان هو طريقة لترميز الصور باستخدام دقة أقل للون مقارنة بالسطوع.
كم هو مقبول لتقليل دقة اللون؟ اتضح أن هناك بالفعل بعض المخططات التي تصف كيفية التعامل مع الدقة والدمج
(اللون النهائي = Y + Cb + Cr).تُعرف هذه المخططات
بأنظمة أخذ
العينات الفرعية ويتم التعبير عنها في شكل نسبة 3 أضعاف -
a : x : y ، والتي تحدد عدد عينات إشارات النصوع وفرق اللون.
أخذ العينات الأفقية القياسية (عادة تساوي 4)
x - عدد عينات الألوان في الصف الأول من البكسل (الدقة الأفقية بالنسبة لـ
a )
y هو عدد التغييرات في عينات الألوان بين الصفين الأول والثاني من وحدات البكسل.
الاستثناء هو 4 : 1 : 0 ، والذي يوفر عينة لون واحد في كل كتلة دقة سطوع 4 × 4.
المخططات الشائعة المستخدمة في برامج الترميز الحديثة:
- 4 : 4 : 4 (بدون اختزال)
- 4 : 2 : 2
- 4 : 1 : 1
- 4 : 2 : 0
- 4 : 1 : 0
- 3 : 1 : 1
YCbCr 4: 2: 0 - دمج مثال
هنا هو جزء الصورة المدمجة باستخدام YCbCr 4: 2: 0. يرجى ملاحظة أننا ننفق 12 بت فقط لكل بكسل.
هذه هي الطريقة التي تبدو بها نفس الصورة المشفرة بواسطة الأنواع الرئيسية لأخذ عينات الألوان. الصف الأول هو YCbCr النهائي ، يعرض الصف السفلي دقة الألوان. نتائج لائقة جدا ، بالنظر إلى خسارة صغيرة في الجودة.

تذكر ، لقد عدنا مساحة تخزين تبلغ 278 غيغابايت لملف فيديو مدته ساعة مع دقة 720 بكسل و 30 إطارًا في الثانية؟ إذا استخدمنا YCbCr 4: 2: 0 ، فسيتم تقليل هذا الحجم بمقدار النصف - 139 جيجابايت. حتى الآن ، لا تزال بعيدة عن نتيجة مقبولة.
يمكنك الحصول على الرسم البياني YCbCr نفسك مع FFmpeg. في هذه الصورة ، يسود اللون الأزرق على اللون الأحمر ، والذي يكون واضحًا على الرسم البياني نفسه.

اللون ، السطوع ، التدرج اللوني - مراجعة الفيديو
يوصى بمشاهدة هذا الفيديو الرائع. هذا ما يفسر السطوع ، وبالفعل يتم وضع جميع النقاط عليه حول السطوع واللون.
أنواع الإطار
نحن نمضي قدما. دعونا نحاول القضاء على التكرار في الوقت المناسب. لكن أولاً ، دعونا نحدد بعض المصطلحات الأساسية. لنفترض أن لدينا فيلمًا يحتوي على 30 إطارًا في الثانية ، فيما يلي أول 4 إطارات:




يمكننا أن نرى العديد من التكرار في الإطارات: على سبيل المثال ، خلفية زرقاء لا تتغير من إطار إلى إطار. لحل هذه المشكلة ، يمكننا تصنيفها بشكل مجرد على أنها ثلاثة أنواع من الإطارات.
I- الإطار ( I ntro الإطار)
الإطار I (الإطار المرجعي ، الإطار الرئيسي ، الإطار الداخلي) مستقل. بصرف النظر عما يحتاج إلى تصور ، فإن الإطار الأول هو في الواقع صورة ثابتة. يكون الإطار الأول عادةً عبارة عن إطار I ، لكننا سنلاحظ بانتظام الإطارات I بين الإطارات البعيدة عن الإطارات الأولى.
ف - الإطار ( ف المعاد تدويرها الإطار)
يستفيد الإطار P (الإطار المتوقع) من حقيقة أنه يمكن دائمًا تشغيل الصورة الحالية باستخدام الإطار السابق تقريبًا. على سبيل المثال ، في الإطار الثاني ، التغيير الوحيد هو الكرة الأمامية. يمكننا الحصول على الإطار 2 فقط عن طريق تعديل الإطار 1 قليلاً ، فقط باستخدام الفرق بين هذه الإطارات. لإنشاء الإطار 2 ، راجع الإطار 1 الذي يسبقه.
←

الإطار B (الإطار B التنبؤي)
ماذا عن الروابط ليس فقط بالماضي ، ولكن أيضًا بالإطارات المستقبلية ، لتوفير ضغط أفضل؟! هذا هو الأساس B الإطار (إطار ثنائي الاتجاه).
←
→
انسحاب وسيط
يتم استخدام أنواع الإطارات هذه لتوفير أفضل ضغط. سنناقش كيف يحدث هذا في القسم التالي. في غضون ذلك ، نلاحظ أن الإطار الأول هو "الأغلى" من حيث الذاكرة ، والإطار ف أرخص بكثير ، ولكن الإطار ب هو الخيار الأكثر ربحية للفيديو.

التكرار الزمني (التنبؤ بين الإطارات)
دعونا نلقي نظرة على الفرص المتاحة لتقليل تكرار الوقت. يمكن حل هذا النوع من التكرار باستخدام طرق التنبؤ المتبادل.
سنحاول إنفاق أقل عدد ممكن من البتات لتشفير سلسلة من الإطارات 0 و 1.

يمكننا
طرح ، فقط طرح الإطار 1 من الإطار 0. نحصل على الإطار 1 ، نستخدم فقط الفرق بينه وبين الإطار السابق ، في الواقع ، نحن فقط نشفر الباقي الناتج.

ولكن ماذا لو قلت لك أن هناك طريقة أفضل تستخدم عددًا أقل من البتات ؟! أولاً ، دعنا نقسم الإطار 0 إلى شبكة واضحة من الكتل. ثم نحاول مقارنة الكتل من الإطار 0 بالإطار 1. بمعنى آخر ، نقيم الحركة بين الإطارات.
من ويكيبيديا - بلوك تعويض الحركة
يقسم تعويض حركة الكتل الإطار الحالي إلى كتل مفككة ويبلغ متجه تعويض الحركة أصل الكتل (الاعتقاد الخاطئ الشائع هو أن الإطار السابق مقسم إلى كتل مفككة ، وأن ناقلات تعويض الحركة تحدد أين تذهب هذه الكتل. في الواقع ، على العكس ، يتم تحليل الكتل السابقة الإطار ، والإطار التالي ، اتضح ليس من أين تتحرك الكتل ، ولكن من أين أتت). عادةً ما تتداخل كتل المصدر في إطار المصدر. تقوم بعض خوارزميات ضغط الفيديو بجمع الإطار الحالي من أجزاء ليست واحدة فقط ، ولكن أيضًا عدة إطارات مرسلة مسبقًا.

في عملية التقييم ، نرى أن الكرة قد انتقلت من
( x = 0 ، y = 25) إلى
( x = 6 ، y = 26) ، وقيم
x و
y تحدد متجه الحركة. تتمثل الخطوة الأخرى التي يمكننا اتخاذها لحفظ البتات في ترميز الفرق بين ناقلات الحركة فقط بين الموضع الأخير للكتلة والموقع المتنبأ به ، وبالتالي سيكون ناقل الحركة النهائي
(x = 6-0 = 6 ، y = 26-25 = 1).في الوضع الحقيقي ، سيتم تقسيم هذه الكرة إلى كتل
n ، لكن هذا لا يغير جوهر المسألة.
الكائنات في الإطار تتحرك في ثلاثة أبعاد ، لذلك عندما تتحرك الكرة ، يمكن أن تصبح أصغر بصريًا (أو أكثر إذا تحركت باتجاه العارض). من الطبيعي ألا يكون هناك تطابق تام بين الكتل. فيما يلي عرض مشترك لتقييمنا والصورة الحقيقية.

لكننا نرى أنه عند تطبيق تقدير الحركة ، تكون بيانات الترميز أقل بشكل ملحوظ من استخدام الطريقة الأبسط لحساب الدلتا بين الإطارات.

كيف سيكون التعويض عن الحركة الحقيقية؟
هذه التقنية تنطبق على الفور على جميع الكتل. في كثير من الأحيان ، سيتم تقسيم الكرة المتحركة الشرطية لدينا إلى عدة كتل في وقت واحد.

يمكنك أن تشعر بهذه المفاهيم بنفسك باستخدام
Jupyter .
لمشاهدة متجهات الحركة ، يمكنك إنشاء فيديو
بتنبؤ خارجي باستخدام
ffmpeg .
 مع ffmpeg")
يمكنك أيضًا استخدام
محلل Intel Video Pro Analyzer (يتم دفعه ، لكن هناك إصدارًا تجريبيًا مجانيًا ، يقتصر فقط على الإطارات العشرة الأولى).

التكرار المكاني (التنبؤ الداخلي)
إذا قمنا بتحليل كل إطار في الفيديو ، فسوف نجد العديد من المناطق المترابطة.

دعنا نذهب هذا المثال. يتكون هذا المشهد بشكل رئيسي من الأزرق والأبيض.

هذا هو الإطار الأول. لا يمكننا أن نأخذ الإطارات السابقة للتنبؤ ، ولكن سيتحول الأمر إلى ضغطه. . , , - .
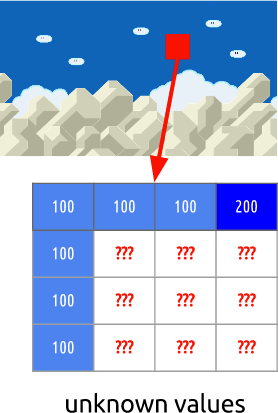
, . , .
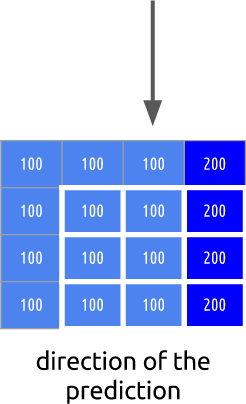
. ( ), . , .
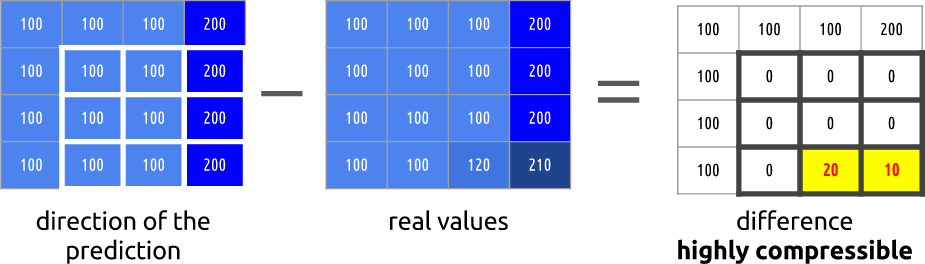
, ffmpeg. ffmpeg.
 مع ffmpeg") أو يمكنك استخدام محلل Intel Video Pro Analyzer (كما ذكرت أعلاه ، يوجد في الإصدار التجريبي المجاني حد أقصى للإطارات العشرة الأولى ، لكن هذا يكفي لك في البداية).
أو يمكنك استخدام محلل Intel Video Pro Analyzer (كما ذكرت أعلاه ، يوجد في الإصدار التجريبي المجاني حد أقصى للإطارات العشرة الأولى ، لكن هذا يكفي لك في البداية).

اقرأ أيضا بلوق
شركة إديسون:
20 مكتبة لل
مذهلة تطبيق دائرة الرقابة الداخلية