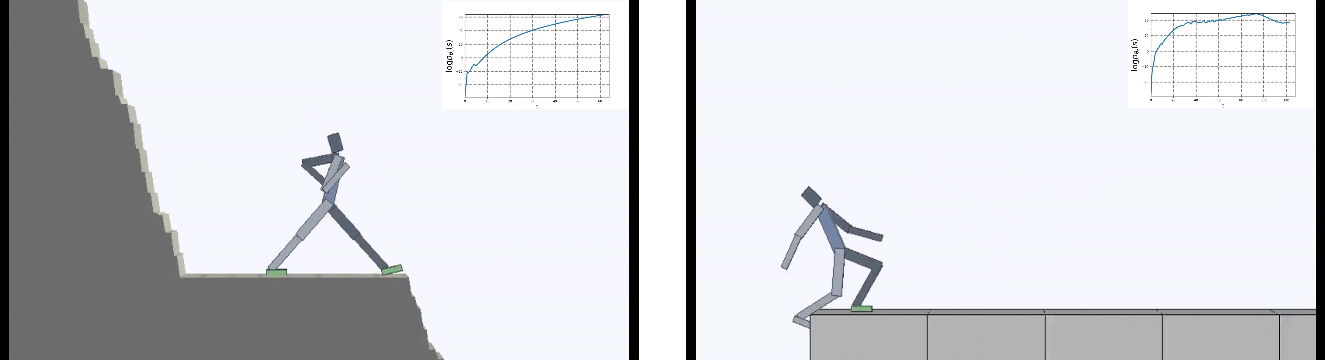
غالبًا ما يستخدم التعلم المعزز الفضول كحافز لمنظمة العفو الدولية. إجباره على البحث عن أحاسيس جديدة واستكشاف العالم. لكن الحياة مليئة بالمفاجآت غير السارة. يمكنك أن تسقط على منحدر ومن وجهة نظر الفضول ، ستكون دائمًا أحاسيس جديدة ومثيرة للاهتمام للغاية. ولكن من الواضح أن ليس ما يجب السعي إليه.
قلب المطورون من بيركلي مهمة الوكيل الافتراضي رأسًا على عقب: لم يكن الفضول هو الذي جعل القوة الدافعة الرئيسية ، بل الرغبة في تجنب أي حداثة بكل الوسائل. لكن "عدم القيام بأي شيء" كان أصعب مما يبدو. من خلال وضعها في بيئة دائمة التغير ، كان على الذكاء الاصطناعي أن يتعلم السلوك المعقد لتجنب الأحاسيس الجديدة.
التعلم التعزيز يأخذ خطوات خجولة نحو بناء الذكاء الاصطناعى القوي. وبينما يقتصر كل شيء على أبعاد منخفضة للغاية ، بالمعنى الحرفي للوحدات التي يجب أن يتصرف فيها الوكيل الافتراضي (يفضل بشكل معقول) ، تظهر الأفكار الجديدة من وقت لآخر كيفية تحسين تدريب الذكاء الاصطناعي.
ولكن ليس فقط خوارزميات التعلم معقدة. البيئة تزداد صعوبة أيضا. معظم بيئات التعلم المعززة بسيطة للغاية وتحفز الوكيل على استكشاف العالم. يمكن أن تكون متاهة يجب التحايل عليها بالكامل من أجل إيجاد مخرج ، أو لعبة كمبيوتر يجب إكمالها حتى النهاية.
ولكن على المدى الطويل ، تسعى الكائنات الحية (معقولة وغير ذلك) ليس فقط لاستكشاف العالم من حولهم. ولكن أيضا للحفاظ على كل الخير الذي هو في حياتهم القصيرة (أو غير ذلك).
وهذا ما يسمى التوازن - رغبة الجسم في الحفاظ على حالة ثابتة. بشكل أو بآخر ، هذا أمر شائع لجميع الكائنات الحية. يقدم المطورون من بيركلي مثالاً غريبًا: كل إنجازات البشرية ، بشكل عام ، مصممة للحماية من المفاجآت غير السارة. للحماية من الانتروبيا المتزايدة للبيئة. نبني المنازل حيث نحافظ على درجة حرارة ثابتة ، محمية من التغيرات المناخية. نحن نستخدم الدواء ليكون بصحة جيدة وهلم جرا.
يمكن للمرء أن يجادل مع هذا ، ولكن هناك حقا شيء في هذا القياس.
سأل الرجال السؤال - ماذا سيحدث إذا كان الدافع الرئيسي لمنظمة العفو الدولية هو محاولة تجنب أي حداثة؟ قلل الفوضى كدالة تعليمية موضوعية ، بمعنى آخر.
ووضعوا العميل في عالم خطير دائم التغير.
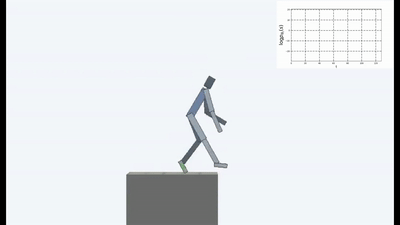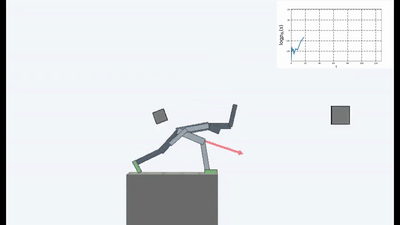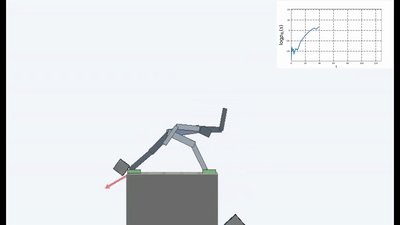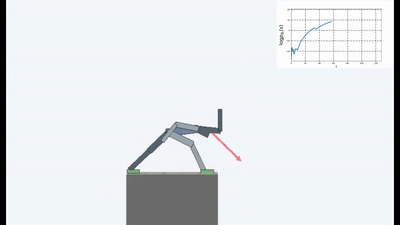
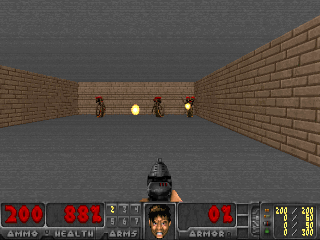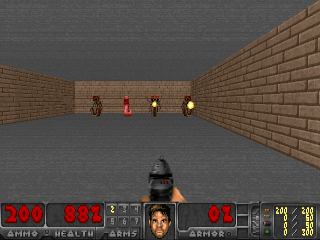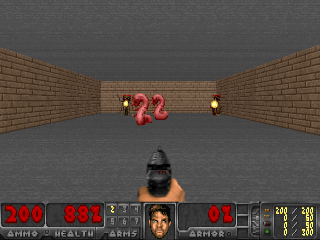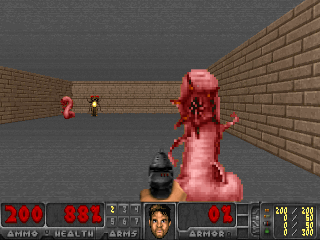
وكانت النتائج مثيرة للاهتمام. في العديد من الحالات ، تجاوز هذا التعلم التعلم القائم على المناهج الدراسية ، وفي أكثر الأحيان ، من حيث الجودة ، يقترب من التعلم مع المعلم. وهذا هو ، للتدريب المتخصص لتحقيق هدف محدد - الفوز في اللعبة ، انتقل من خلال المتاهة.
هذا أمر منطقي بالطبع ، لأنه إذا كنت تقف على جسر متداعي ، ثم تستمر في ذلك (للحفاظ على ثباتك وتجنب إحساسات جديدة من السقوط) ، فأنت بحاجة إلى الابتعاد باستمرار عن الحافة. هرب بكل قوتها للحفاظ على الوقوف ، كما قالت أليس.

وفي الواقع ، في أي خوارزمية التعلم التعزيز ، هناك مثل هذه اللحظة. لأن الوفيات في اللعبة والنهاية السريعة للحلقة يتم تغريمها بمكافأة سلبية. أو اعتمادًا على الخوارزمية ، عن طريق تقليل الحد الأقصى للمكافأة التي يمكن أن يحصل عليها الوكيل إذا لم يسقط بشكل مستمر من الهاوية.
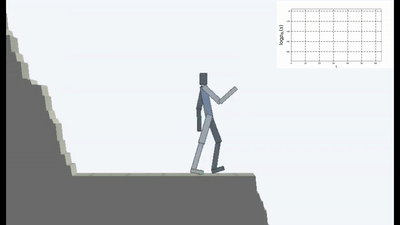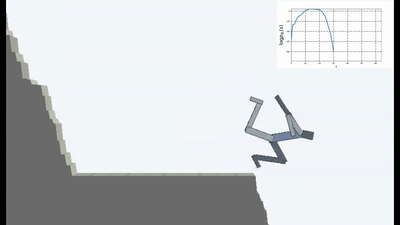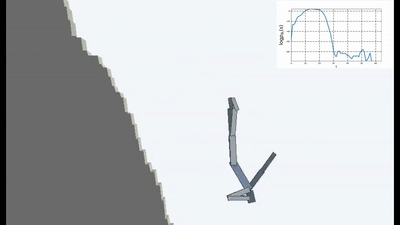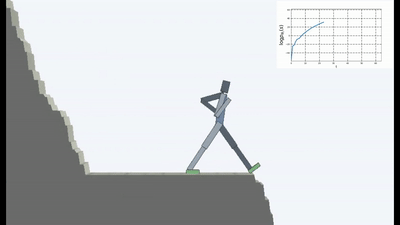
ولكن في مثل هذه الصياغة ، عندما لا يكون لمنظمة العفو الدولية أهداف أخرى غير الرغبة في تجنب الجدة ، يبدو أنه تم استخدامه لأول مرة في التعلم المعزز.
ومن المثير للاهتمام ، مع هذا الدافع ، تعلم العامل الافتراضي لعب العديد من الألعاب التي لديها هدف لتحقيق الفوز. على سبيل المثال ، تتريس.

أو البيئة من Doom ، حيث تحتاج إلى تفادي الكرات النارية الطائرة وإطلاق النار على المعارضين المقتربين. لأنه يمكن صياغة العديد من المهام باعتبارها مهام الحفاظ على الثبات. بالنسبة لـ Tetris ، هذه هي الرغبة في إبقاء الحقل فارغًا. هل تملأ الشاشة باستمرار؟ يا عزيزي ، ماذا سيحدث عندما تملأ حتى النهاية؟ لا ، لا ، لسنا بحاجة إلى مثل هذه السعادة. الكثير من الصدمة.
من الجانب الفني ، يتم ترتيبها بكل بساطة. عندما يتلقى الوكيل حالة جديدة ، يقوم بتقييم مدى معرفة هذه الحالة. وهذا يعني ، مقدار الدولة الجديدة يتم تضمينها في توزيع الحالة التي زارها في وقت سابق. يحصل الوكيل في حالة أكثر دراية ، وكلما زادت المكافأة. ومهمة سياسة التعلم (هذه كلها مصطلحات من Reinforcement Learning ، إن لم يكن أحد يعرف) هي اختيار الإجراءات التي من شأنها أن تؤدي إلى الانتقال إلى الحالة الأكثر دراية. بالإضافة إلى ذلك ، يتم استخدام كل حالة جديدة تم الحصول عليها لتحديث إحصائيات الحالات المألوفة التي تتم مقارنة الحالات الجديدة بها.
ومن المثير للاهتمام ، في عملية الذكاء الاصطناعى ، تعلمت تلقائيًا أن أفهم أن الدول الجديدة تؤثر على ما يعتبر حداثة. ويمكنك تحقيق حالات مألوفة بطريقتين: إما الانتقال إلى حالة معروفة بالفعل. أو انتقل إلى حالة ستقوم بتحديث مفهوم الثبات / الإلمام بالبيئة ، وسيصبح الوكيل في حالة جديدة ، تكونت من خلال أفعاله ، الحالة المألوفة.
هذا يجبر العميل على اتخاذ إجراءات منسقة معقدة ، إذا كان فقط لفعل أي شيء في الحياة.
ومن المفارقات أن هذا يؤدي إلى تناظر الفضول من التعلم العادي ، ويفرض على الوكيل استكشاف العالم من حوله. فجأة في مكان ما يوجد مكان أكثر أمانًا من هنا والآن؟ هناك يمكنك الانغماس التام في الكسل وعدم القيام بأي شيء على الإطلاق ، وبالتالي تجنب أي مشاكل وأحاسيس جديدة. لن يكون من قبيل المبالغة القول إن مثل هذه الأفكار ربما حدثت لأي منا. وبالنسبة للكثيرين ، هذه هي القوة الدافعة الحقيقية في الحياة. على الرغم من أنه في الحياة الواقعية ، لم يكن على أي منا التعامل مع تتريس تملأ الجزء العلوي ، بالطبع.
أن نكون صادقين ، هذه قصة معقدة. لكن الممارسة تبين أنها تعمل. قارن الباحثون هذه الخوارزمية بأفضل الممثلين استنادًا إلى الفضول: ICM و RND . الأول هو آلية فعالة للفضول التي أصبحت بالفعل كلاسيكية في التعلم مع التعزيز. لا يسعى الوكيل ببساطة إلى حالات جديدة غير مألوفة ومثيرة للاهتمام. يتم تقدير عدم معرفة الموقف في مثل هذه الخوارزميات من خلال ما إذا كان يمكن للعامل أن يتنبأ بها (في الحالات السابقة كانت هناك عدادات فعلية للحالات التي تمت زيارتها ، ولكن الآن أصبح كل شيء يرجع إلى التقدير المتكامل الذي توفره الشبكة العصبية). ولكن في هذه الحالة ، فإن الأوراق المتحركة على الأشجار أو الضوضاء البيضاء على التلفزيون سيكون لها حداثة لا نهاية لها لمثل هذا العامل ، وقد تسبب ذلك في شعور لا نهاية له من الفضول. لأنه لا يمكنه أبدًا التنبؤ بجميع الحالات الجديدة الممكنة في بيئة عشوائية تمامًا.
لذلك ، في ICM ، يبحث الوكيل عن تلك الحالات الجديدة فقط التي يمكنه التأثير عليها من خلال تصرفاته. هل يمكن أن يؤثر الذكاء الاصطناعي على الضوضاء البيضاء على التلفزيون؟ لا. رتيبا جدا. وهل يمكن أن تؤثر على الكرة إذا قمت بتحريكها؟ نعم. اللعب مع الكرة مثير للاهتمام. للقيام بذلك ، تستخدم ICM فكرة رائعة للغاية مع النموذج العكسي ، الذي يُقارن به النموذج الأمامي. مزيد من التفاصيل في العمل الأصلي .
RND هو تطور أحدث لآلية الفضول. والتي في الممارسة قد تجاوزت ICM. باختصار ، تحاول الشبكة العصبية التنبؤ بمخرجات شبكة عصبية أخرى ، والتي تبدأ بأوزان عشوائية ولا تتغير أبدًا. من المفترض أنه كلما كان الوضع أكثر دراية (تغذي مدخلات كل من الشبكات العصبية ، الحالية والمستهلكة بشكل عشوائي) ، كلما كانت الشبكة العصبية الحالية أكثر قدرة على التنبؤ بالمخرجات التي بدأت بشكل عشوائي. أنا لا أعرف من يخترع كل هذا. من ناحية ، أريد مصافحة مثل هذا الشخص ، ومن ناحية أخرى ، ركلة لمثل هذه التشوهات.
ولكن بطريقة أو بأخرى ، والتدريب على فكرة الحفاظ على التوازن ومحاولة تجنب أي حداثة ، في كثير من الحالات في الممارسة العملية حققت نتائج أفضل من المناهج الدراسية القائمة على ICN أو RND. ما ينعكس في الرسوم البيانية.
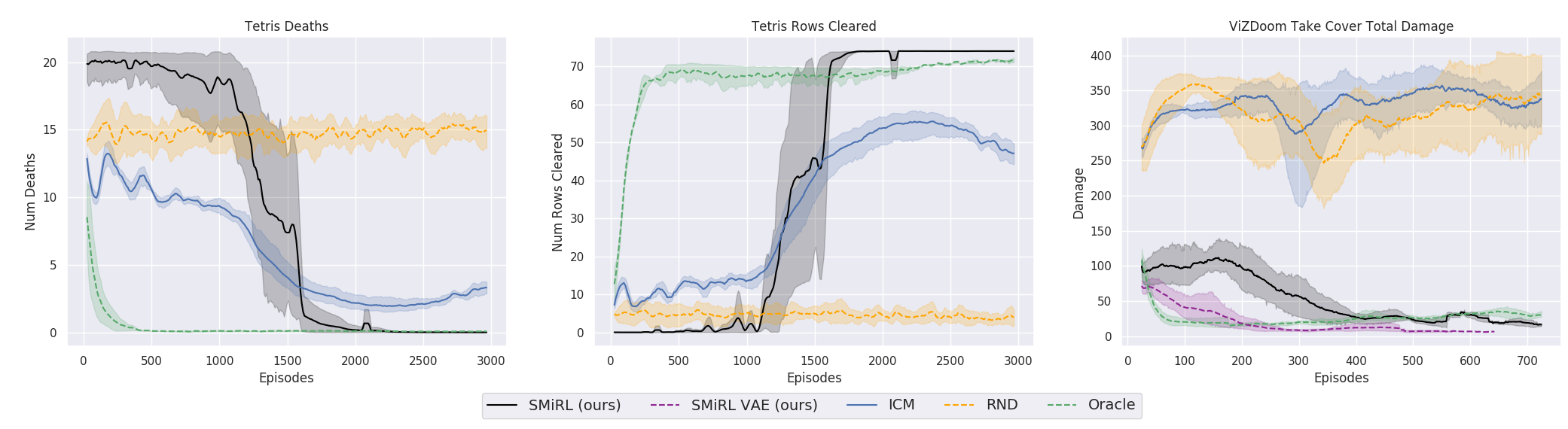
ولكن من الضروري هنا توضيح أن هذا فقط للبيئات التي استخدمها الباحثون في عملهم. فهي خطيرة وعشوائية وصاخبة ومع تزايد الانتروبيا. حقا يمكن أن يكون أكثر ربحية لعدم القيام بأي شيء فيها. وفي بعض الأحيان فقط تتحرك بشكل نشط عندما تطير كرة النار معك أو يبدأ الجسر الذي خلفك في الانهيار. ومع ذلك ، يصر الباحثون من بيركلي ، على ما يبدو من تجربتهم الحياتية الصعبة ، على أن هذه البيئات أقرب بكثير إلى الحياة الواقعية المعقدة من تلك المستخدمة سابقًا في التدريب على التعزيز. حسنًا ، لا أعرف ، لا أعرف. في حياتي ، تم العثور على كرات النار من الوحوش التي تطير في وجهي والمتاهات غير المأهولة مع مخرج واحد بنفس التردد تقريبًا. ولكن لا يمكن إنكار أن النهج المقترح ، بكل بساطته ، أظهر نتائج مذهلة. ربما في المستقبل يجب الجمع بين كلا النهجين بشكل معقول - التوازن مع الحفاظ على الثبات الإيجابي على المدى الطويل والفضول للدراسات البيئية الحالية.
رابط إلى العمل الأصلي