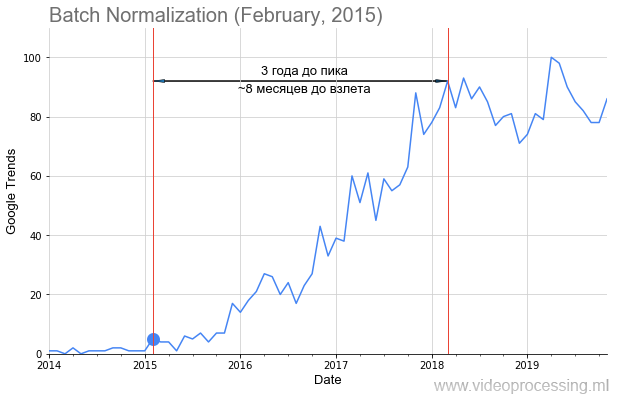
يقترب العام الجديد من نهايته ، ستنتهي قريباً 2010 ، مما يمنح العالم النهضة المثيرة للشبكات العصبية. شعرت بالقلق
والحرمان من النوم من خلال فكرة بسيطة: "كيف يمكن للمرء أن يقدر بأثر رجعي سرعة تطور الشبكات العصبية؟" لأن "من يعرف الماضي يعرف المستقبل". كيف بسرعة خوارزميات مختلفة تقلع؟ كيف يمكن للمرء تقييم سرعة التقدم في هذا المجال وتقدير سرعة التقدم في العقد القادم؟

من الواضح أنه يمكنك حساب عدد المقالات تقريبًا في مناطق مختلفة تقريبًا. الطريقة ليست مثالية ، تحتاج إلى أن تأخذ في الاعتبار المجالات الفرعية ، ولكن بشكل عام يمكنك أن تجرب. أعطي فكرة ، على
Google Scholar (BatchNorm) أنها حقيقية تمامًا! يمكنك التفكير في مجموعات بيانات جديدة ، ويمكنك دورات تدريبية جديدة. استقر خادمك المتواضع ، من
خلال عدة خيارات ، على
Google Trends (BatchNorm) .
تلقيت أنا وزملائي طلبات من تقنيات ML / DL الرئيسية ، على سبيل المثال ،
Batch Normalization ، كما في الصورة أعلاه ، أضفت تاريخ نشر المقال بنقطة ، وحصلنا على جدول زمني لإقلاع شعبية الموضوع. ولكن ليس لكل هؤلاء ، فإن
الطريق مليء بالورود ، والإقلاع واضح وجميل للغاية ، مثل العاصفة. لا يمكن بناء بعض المصطلحات ، مثل التنظيم أو تخطي الاتصالات ، على الإطلاق بسبب ضجيج البيانات. ولكن بشكل عام ، تمكنا من جمع الاتجاهات.
من يهتم بما حدث - مرحبًا بك في القص!
بدلا من تقديم أو عن التعرف على الصور
لذلك! كانت البيانات الأولية صاخبة للغاية ، وكانت هناك في بعض الأحيان قمم حادة.
 المصدر: أندريه كارباتي على تويتر - يقف الطلاب في ممرات جمهور كبير للاستماع إلى محاضرة عن الشبكات العصبية التلافيفيةتقليديا
المصدر: أندريه كارباتي على تويتر - يقف الطلاب في ممرات جمهور كبير للاستماع إلى محاضرة عن الشبكات العصبية التلافيفيةتقليديا ، كان يكفي
لأندري كارباتي لإلقاء محاضرة عن
CS231n الأسطوري
: الشبكات العصبية التلافيفية للتعرف البصري على 750 شخصا مع تعميم مفهوم كيف تسير ذروة حادة. لذلك ، تم تنعيم البيانات باستخدام
فلتر صندوقي بسيط (يتم تمييز جميع النقاط الخارجية الملساء على أنها Smoothed على المحور). بما أننا مهتمون بمقارنة معدل نمو الشعبية - بعد التجانس ، فقد تم تطبيع جميع البيانات. اتضح مضحك جدا. فيما يلي رسم بياني للمباني الرئيسية التي تتنافس على ImageNet:
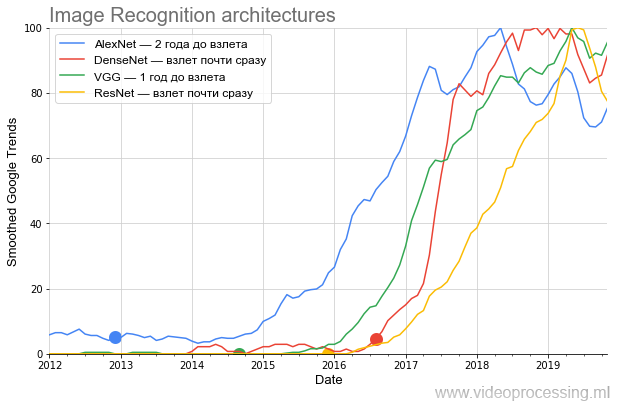 المصدر: فيما يلي - حسابات المؤلف وفقًا لـ Google Trends
المصدر: فيما يلي - حسابات المؤلف وفقًا لـ Google Trendsيظهر الرسم البياني بوضوح شديد أنه بعد النشر
المثير AlexNet ، الذي صنع عصيدة من الضجيج الحالي للشبكات العصبية في نهاية عام 2012 ، كان ما يقرب من عامين ، على
النقيض من تأكيدات الكومة ، انضم فقط دائرة ضيقة نسبيا من المتخصصين. ذهب الموضوع إلى الجمهور العام فقط في شتاء 2014-2015. انتبه لمدى سريان الجدول الزمني اعتبارًا من 2017: المزيد من القمم كل ربيع.
في الطب النفسي ، يسمى هذا التفاقم الربيعي ... هذه علامة أكيدة على أن المصطلح يستخدم الآن في الغالب من قبل الطلاب ، وفي المتوسط ، يقل الاهتمام ببرنامج AlexNet مقارنة بذروة الشعبية.
علاوة على ذلك ، في النصف الثاني من عام 2014 ، ظهرت
VGG . بالمناسبة ، شاركت
VGG في تأليف مع المشرف على
الدراسات طالبي السابق
كارين سيمونيان ، التي تعمل الآن في Google DeepMind (
AlphaGo ،
AlphaZero ، إلخ). أثناء الدراسة في جامعة موسكو الحكومية في السنة الثالثة ، نفذت كارين
خوارزمية جيدة
لتقدير الحركة ، والتي كانت بمثابة مرجع للطلاب لمدة عامين لمدة 12 عامًا. علاوة على ذلك ، فإن المهام هناك متشابهة إلى حد ما. قارن:
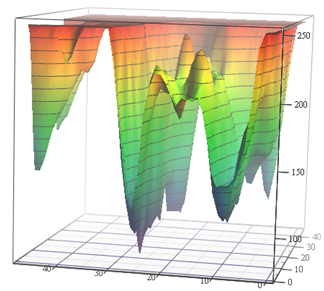
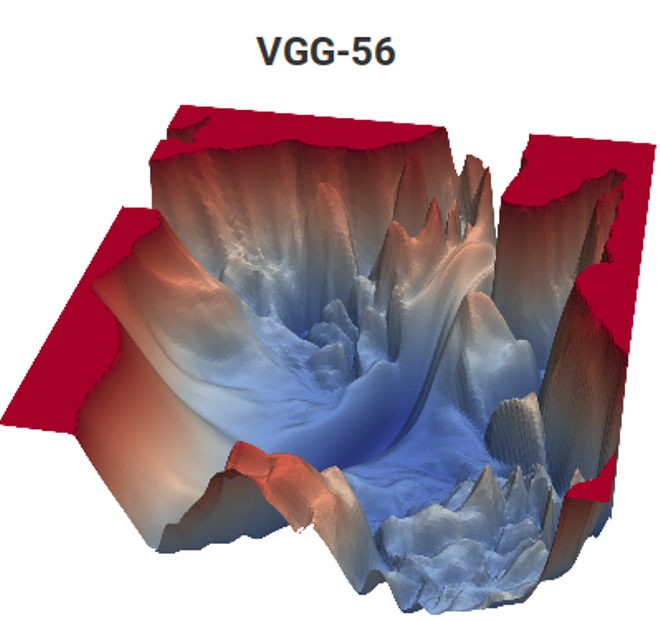 المصدر: دالة الخسارة لمهام تقدير الحركة (مواد المؤلف) و VGG-56
المصدر: دالة الخسارة لمهام تقدير الحركة (مواد المؤلف) و VGG-56على اليسار ، تحتاج إلى العثور على أعمق نقطة في سطح غير تنافسي اعتمادًا على بيانات الإدخال لأدنى عدد من القياسات (من الممكن أن تكون هناك العديد من الحدود الدنيا المحلية) ، وعلى اليمين تحتاج إلى العثور على نقطة أقل مع الحد الأدنى من الحسابات (وأيضًا مجموعة من الحدود الدنيا المحلية ، والسطح يعتمد أيضًا على البيانات) . على اليسار ، نحصل على ناقل الحركة المتوقع ، وعلى اليمين ، الشبكة المدربة. والفرق هو أنه على اليسار لا يوجد سوى قياس ضمني لمساحة اللون ، وعلى اليمين يوجد زوج من القياسات من مئات الملايين. حسنًا ، التعقيد الحسابي على اليمين هو حوالي 12 أمرًا من حيث الحجم (!) أعلى. يشبه هذا قليلاً ... لكن في السنة الثانية ، حتى مع مهمة بسيطة ، يتأرجح مثل ... [قطعته الرقابة]. وقد انخفض مستوى برمجة تلاميذ الأمس لأسباب غير معروفة على مدى السنوات الـ 15 الماضية بشكل ملحوظ. يجب عليهم أن يقولوا: "أنت ستفعل ذلك بشكل جيد ، وسوف يأخذك إلى DeepMind!" يمكن للمرء أن يقول "اخترع VGG" ، ولكن "سوف يأخذون إلى DeepMind" لسبب ما يحفز بشكل أفضل. هذا ، بالطبع ، هو تناظرية متطورة حديثة للكلاسيكية "سوف تأكل سميد ، ستصبح رائد فضاء!". ومع ذلك ، في حالتنا ، إذا عدنا عدد الأطفال في البلاد وحجم سلاح رواد الفضاء ، فإن الفرص أعلى بملايين المرات ، لأن اثنين منا يعملان بالفعل في DeepMind من مختبرنا.
ثم كان
ResNet ، حيث كسر شريط عدد الطبقات وبدأ في الإقلاع بعد ستة أشهر. وأخيرًا ، أقلعت DenseNet ، التي جاءت في بداية الضجيج
، على الفور تقريبًا ، حتى كانت أكثر برودة من ResNet.
إذا كنا نتحدث عن شعبية ، أود أن أضيف بضع كلمات حول خصائص الشبكة والأداء ، والتي تعتمد عليها شعبية أيضا. إذا نظرت إلى كيفية
التنبؤ بفئة
ImageNet اعتمادًا على عدد العمليات على الشبكة ، فسيكون التخطيط مثل هذا (أعلى وإلى اليسار - أفضل):
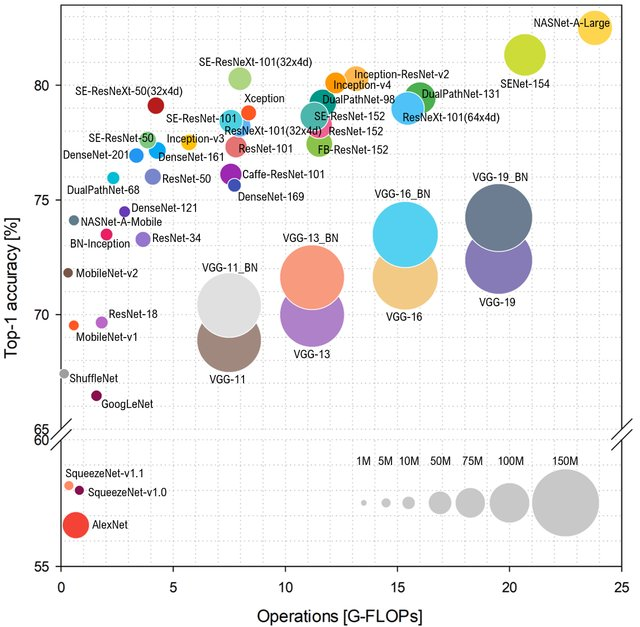 المصدر: تحليل المعيار للبنية التمثيلية للشبكات العصبية العميقة
المصدر: تحليل المعيار للبنية التمثيلية للشبكات العصبية العميقةاكتب AlexNet لم يعد كعكة ، وأنها تحكم الشبكات على أساس ResNet. ومع ذلك ، إذا نظرت إلى التقييم العملي لـ
FPS أقرب إلى قلبي ، يمكنك أن ترى بوضوح أن VGG أقرب إلى الحد الأمثل هنا ، وبشكل عام ، تتغير المحاذاة بشكل ملحوظ. بما في ذلك AlexNet بشكل غير متوقع على المغلف Pareto- الأمثل (النطاق الأفقي هو لوغاريتمي ، أفضل من أعلى وإلى اليمين):
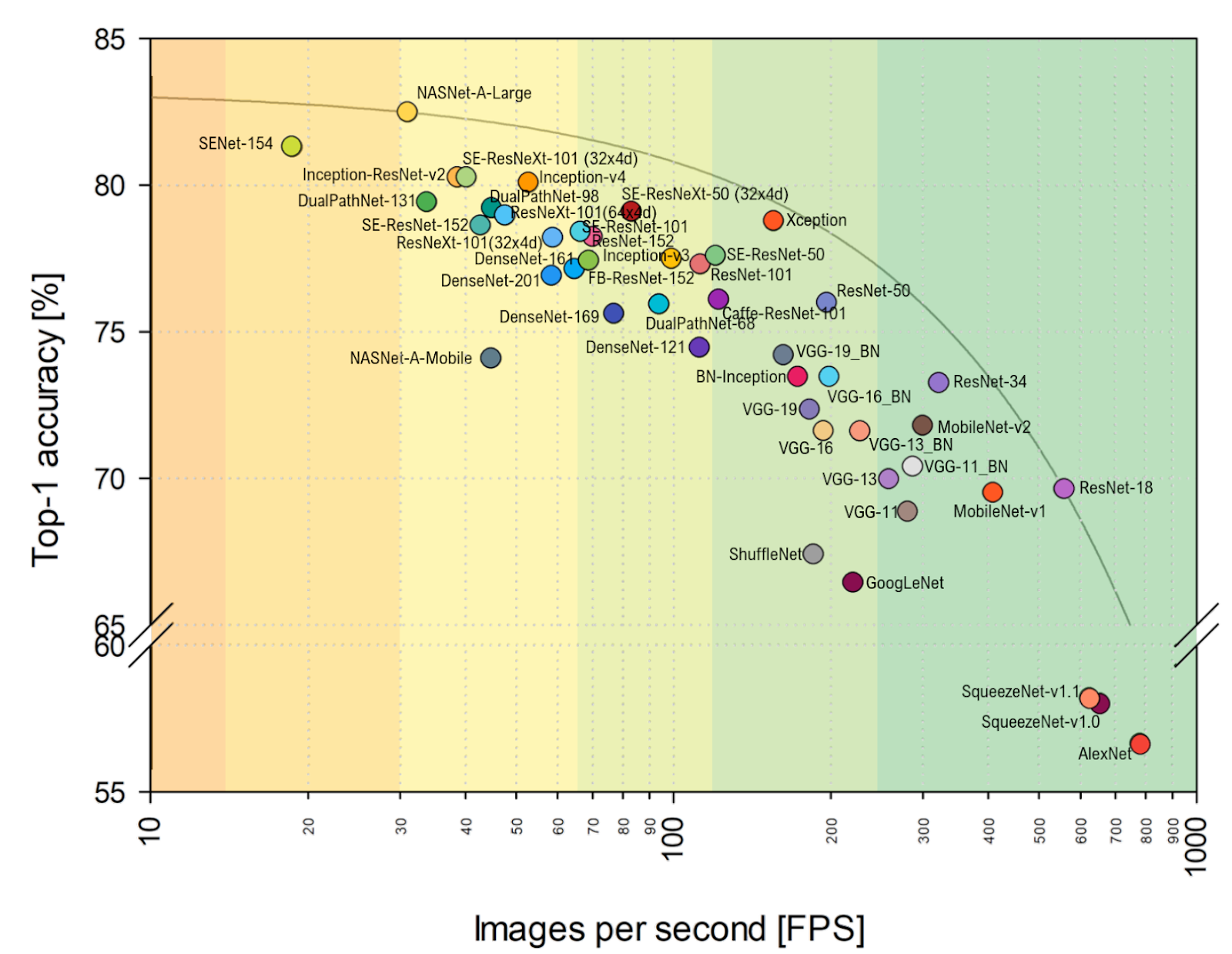 المصدر: تحليل المعيار للبنية التمثيلية للشبكات العصبية العميقةالمجموع:
المصدر: تحليل المعيار للبنية التمثيلية للشبكات العصبية العميقةالمجموع:
- في السنوات القادمة ، سوف يتغير تمازج البنى مع الاحتمال الكبير بدرجة كبيرة بسبب تقدم معجلات الشبكة العصبية ، عندما تذهب بعض البنى إلى السلال وبعضها ينطلق فجأة ، ببساطة لأنه من الأفضل وضع الأجهزة الجديدة. على سبيل المثال ، في المقالة المذكورة ، تم إجراء مقارنة على NVIDIA Titan X Pascal ولوحة NVIDIA Jetson TX1 ، والتخطيط يتغير بشكل ملحوظ. في الوقت نفسه ، بدأ تقدم TPU و NPU وغيرها فقط.
- كممارس ، لا يسعني إلا ملاحظة أن المقارنة على ImageNet تتم افتراضيًا على ImageNet-1k ، وليس على ImageNet-22k ، وذلك ببساطة لأن معظمهم يقومون بتدريب شبكاتهم على ImageNet-1k ، حيث يوجد عدد أقل بمقدار 22 مرة من الفصول (هذا كلا أسهل وأسرع). سيؤدي التبديل إلى ImageNet-22k ، والذي هو أكثر ملاءمة للعديد من التطبيقات العملية ، إلى تغيير المحاذاة (بالنسبة لأولئك الذين يتم شحذهم بمقدار 1k - كثيرًا).
أعمق في التكنولوجيا والهندسة المعمارية
ومع ذلك ، العودة إلى التكنولوجيا. المصطلح
Dropout ككلمة بحث صاخبة للغاية ، ولكن النمو 5 أضعاف يرتبط بوضوح بالشبكات العصبية. وعلى الأرجح يكون الانخفاض في الاهتمام به من خلال
براءة اختراع Google وظهور طرق جديدة. يرجى ملاحظة أن حوالي عام ونصف العام قد انتقل من نشر
المقال الأصلي إلى زيادة الاهتمام بالطريقة:
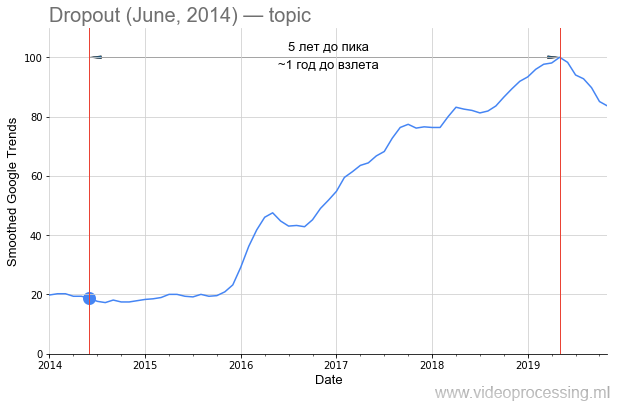
ومع ذلك ، إذا تحدثنا عن الفترة السابقة للارتفاع في شعبيتها ، فحينها يتم اختيار DL في واحدة من الأماكن الأولى بشكل واضح بواسطة
الشبكات المتكررة و
LSTM :
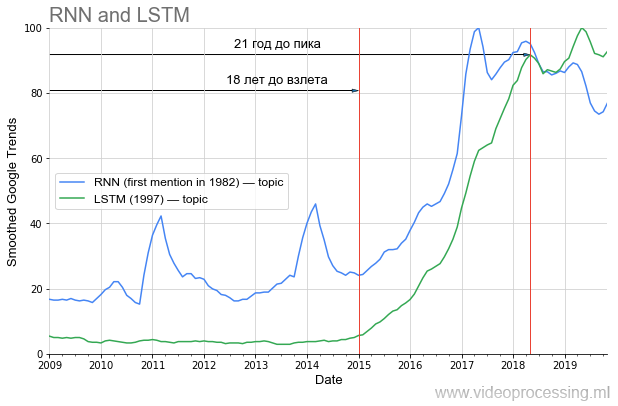
قبل فترة طويلة من 20 عامًا من ذروة الشعبية الحالية ، والآن ، باستخدامها ، الترجمة الآلية ، تحليل الجينوم ، تم تحسينه بشكل جذري ، وفي المستقبل القريب (إذا كنت تستقل من منطقتي) ، سوف ينخفض عدد زيارات Netflix على YouTube مرتين بنفس الجودة المرئية. إذا كنت تتعلم دروس التاريخ بشكل صحيح ، فمن الواضح أن جزءًا من الأفكار من مجموعة المقالات الحالية "لن ينطلق" إلا بعد 20 عامًا. تمتع بنمط حياة صحي ، اعتن بنفسك ، وسوف ترى ذلك شخصيًا!
الآن أقرب إلى الضجيج الموعود.
تم خلع شبكات GAN مثل:
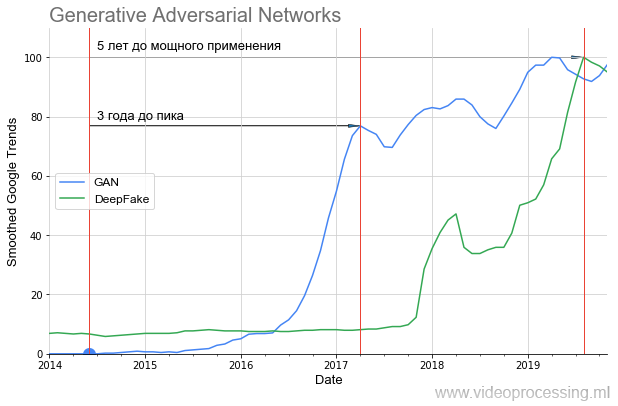
يمكن أن نرى بوضوح أنه كان هناك صمت لمدة عام تقريبًا وفقط في عام 2016 ، بعد عامين ، بدأ الارتفاع الحاد (تحسنت النتائج بشكل ملحوظ). هذا الانطلاق بعد عام أعطى DeepFake المثيرة ، والتي ، مع ذلك ، أقلعت أيضا 1.5 سنة. وهذا يعني أن التقنيات الواعدة تتطلب الكثير من الوقت للانتقال من الفكرة إلى التطبيقات التي يمكن للجميع استخدامها.
إذا نظرت إلى الصور التي أنشأتها GAN في
المقالة الأصلية وما الذي يمكن بناؤه باستخدام
StyleGAN ، يصبح من الواضح تمامًا سبب وجود هذا الصمت. في عام 2014 ، لم يتمكن سوى المتخصصين من تقييم مدى روعته - جعل شبكة أخرى ، في جوهرها ، بمثابة وظيفة فقد وتدريبهم معًا. وفي عام 2019 ، يمكن لكل تلميذ أن يقدر مدى روعة هذا (دون أن يفهم تمامًا كيف يتم ذلك):

هناك
العديد من المشكلات المختلفة التي تم حلها بنجاح من قبل الشبكات العصبية اليوم ، يمكنك أن تأخذ أفضل الشبكات وبناء الرسوم البيانية الشعبية لكل اتجاه ، والتعامل مع الضوضاء والقمم من استعلامات البحث ، إلخ. حتى لا
تنشر أفكاري على الشجرة ،
سننهي هذا الاختيار بموضوع خوارزميات التقسيم ، حيث الأفكار من
الالتواء / اتسعت و
ASPP على مدى السنة والنصف الماضية قد أطلقت نفسها تماما
في معيار الخوارزمية :
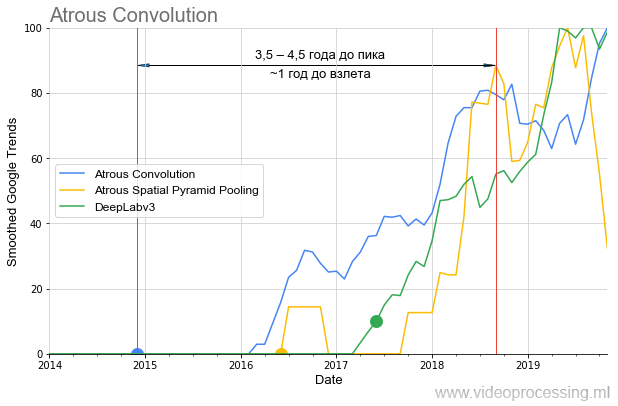
تجدر الإشارة أيضًا إلى أنه في حالة "انتظار"
DeepLabv1 لأكثر من عام "لارتفاع الشعبية" ، فإن
DeepLabv2 أقلعت في غضون عام ، و
DeepLabv3 على الفور تقريبًا. أي بشكل عام ، يمكننا التحدث عن تسريع نمو الاهتمام مع مرور الوقت (جيدًا ، أو تسريع نمو الاهتمام بتكنولوجيات المؤلفين ذوي السمعة الطيبة).
كل هذا أدى إلى خلق المشكلة العالمية التالية - زيادة هائلة في عدد المنشورات حول هذا الموضوع:
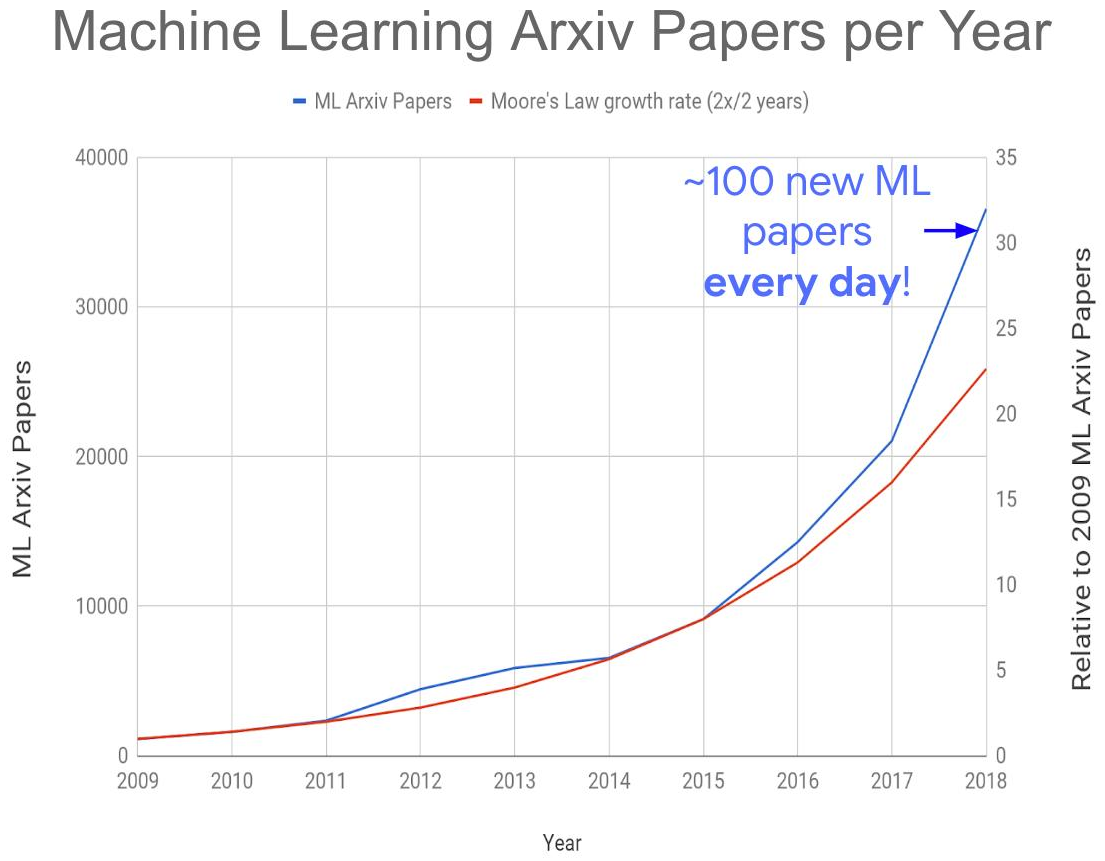 المصدر: الكثير من أوراق تعلم الآلة؟
المصدر: الكثير من أوراق تعلم الآلة؟هذا العام نحصل على حوالي 150 - 200 مقال يوميًا ، نظرًا لعدم نشر جميعها على موقع arXiv-e. من المستحيل تمامًا قراءة المقالات حتى في منطقتها الفرعية اليوم. ونتيجة لذلك ، سيتم بالتأكيد دفن العديد من الأفكار المثيرة للاهتمام تحت أنقاض المنشورات الجديدة ، مما سيؤثر على توقيت "الإقلاع". ومع ذلك ، فإن الزيادة الهائلة في عدد الأخصائيين الأكفاء العاملين في المنطقة
لا تعطي
سوى أمل
ضئيل في التعامل مع المشكلة.
المجموع:
- بالإضافة إلى ImageNet والقصة من وراء الكواليس لنجاحات الألعاب DeepMind ، أدت شبكات GAN إلى موجة جديدة من تعميم الشبكات العصبية. معهم ، كان من الممكن حقًا "إطلاق النار" على الممثلين دون استخدام الكاميرا . وما إذا كان سيكون هناك أكثر! في ظل هذه الضجة المعلوماتية ، سيتم تمويل تقنيات المعالجة والاعتراف الأقل دقة.
- نظرًا لوجود العديد من المنشورات ، نتطلع إلى ظهور أساليب جديدة للشبكات العصبية لتحليل سريع للمقالات ، لأنها فقط ستوفر علينا (مزحة تحتوي على جزء بسيط من نكتة!).
روبوتات العمل ، رجل سعيد
منذ عامين ، أصبح AutoML يكتسب شعبية
من صفحات الصحف . بدأ كل شيء بشكل تقليدي مع ImageNet ، حيث بدأ في الدقة الأولى ، في اتخاذ المراكز الأولى بحزم:
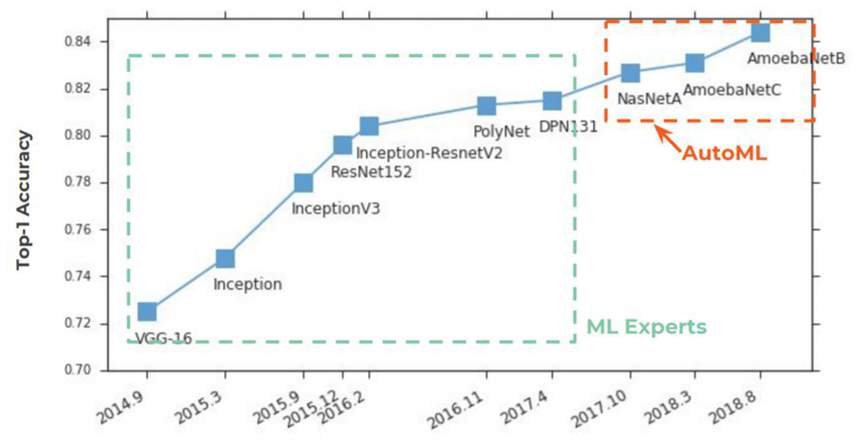
إن جوهر AutoML بسيط للغاية ، لقد تحقق حلم من علماء البيانات منذ قرن من الزمن في حقيقة الأمر - بالنسبة لشبكة عصبية لتحديد المعلمات المفرطة. تم استقبال الفكرة بفارق كبير:
في ما يلي على الرسم البياني ، نرى موقفًا نادرًا إلى حد ما عندما ، بعد نشر المقالات الأولية على
NASNet و
AmoebaNet ، يبدأون في اكتساب شعبية وفقًا لمعايير الأفكار السابقة على الفور تقريبًا (يتأثر الاهتمام الكبير بالموضوع):
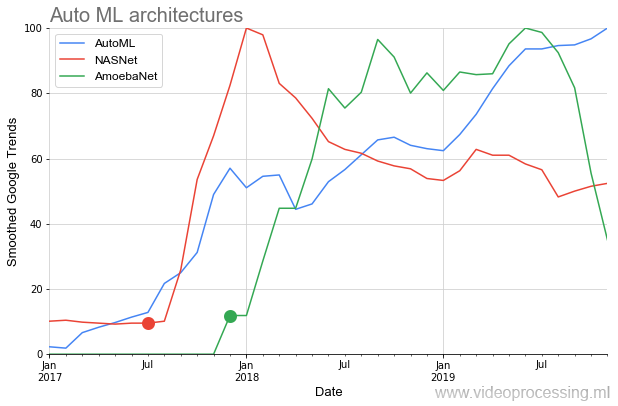
تفسد الصورة المثالية بنقطتين. أولاً ، تبدأ أي محادثة حول AutoML بالعبارة: "إذا كان لديك GPU dofigalion ...". وهذه هي المشكلة. بطبيعة الحال ، تدعي Google أنه باستخدام
Cloud AutoML ، يمكن حل هذا الأمر بسهولة ،
والشيء الرئيسي هو أن لديك ما يكفي من المال ، ولكن لا يتفق الجميع مع هذا النهج. ثانيا ، إنه يعمل بشكل
غير كامل حتى الآن. من ناحية أخرى ، واستدعاء GANs ، خمس سنوات لم تنته بعد ، والفكرة نفسها تبدو واعدة للغاية.
في أي حال ، سيبدأ الإقلاع الرئيسي لـ AutoML بالجيل التالي من مسرعات الأجهزة للشبكات العصبية ، وفي الواقع ، باستخدام خوارزميات محسّنة.
 المصدر: الصورة ديمتري كونوفالتشوك ، مواد المؤلفالمجموع: في الواقع ، لن يحصل علماء البيانات على عطلة أبدية ، بالطبع ، لأنه سيظل هناك صداع كبير مع البيانات لفترة طويلة جدًا. ولكن قبل حلول العام الجديد وبداية العشرينات ، لماذا لا نحلم؟
المصدر: الصورة ديمتري كونوفالتشوك ، مواد المؤلفالمجموع: في الواقع ، لن يحصل علماء البيانات على عطلة أبدية ، بالطبع ، لأنه سيظل هناك صداع كبير مع البيانات لفترة طويلة جدًا. ولكن قبل حلول العام الجديد وبداية العشرينات ، لماذا لا نحلم؟بضع كلمات عن الأدوات
فعالية البحث تعتمد اعتمادا كبيرا على الأدوات. إذا كنت بحاجة إلى برمجة غير تافهة لبرنامج AlexNet ، فيمكنك اليوم جمع مثل هذه الشبكة في عدة أسطر في أطر جديدة.
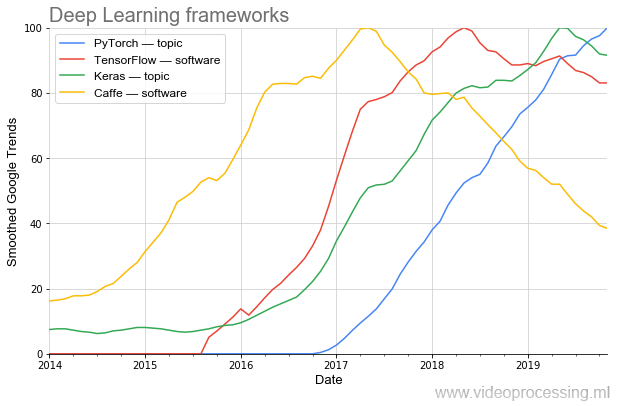
يُرى بوضوح كيف تتغير شعبية الأمواج. اليوم ، الأكثر شعبية (بما في ذلك
وفقا ل PapersWithCode ) هو
PyTorch . وبمجرد أن
مقهى شعبي جميل يترك بسلاسة جدا. (ملاحظة: الموضوع والبرنامج يعني أنه تم استخدام تصفية موضوعات Google عند التخطيط.)
حسنًا ، نظرًا لأننا تطرقنا إلى أدوات التطوير ، تجدر الإشارة إلى المكتبات لتسريع تنفيذ الشبكات:
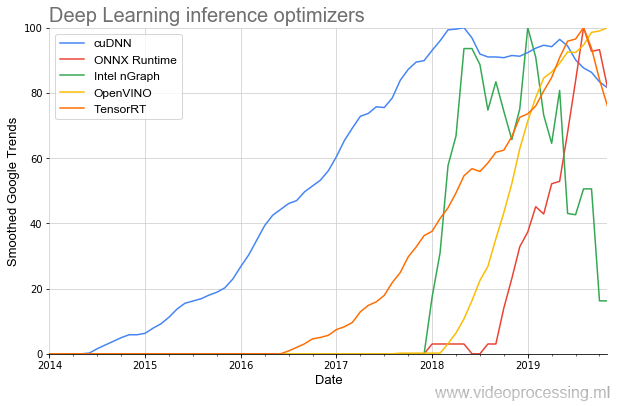
أقدم موضوع هو (respect NVIDIA)
cuDNN ، ولحسن الحظ للمطورين ، زاد عدد المكتبات على مدار العامين الماضيين عدة مرات ، وأصبحت بداية شعبيتها أكثر حدة. ويبدو أن كل هذا هو مجرد بداية.
المجموع: حتى على مدى السنوات الثلاث الماضية ، تغيرت الأدوات بشكل خطير نحو الأفضل. وقبل 3 سنوات ، وفقًا لمعايير اليوم ، لم يكونوا على الإطلاق. التقدم جيد جدا!آفاق الشبكة العصبية الموعودة
لكن المرح يبدأ لاحقا. هذا الصيف ، في
مقالة كبيرة منفصلة ، وصفت بالتفصيل لماذا وحدة المعالجة المركزية وحتى وحدة معالجة الرسومات ليست فعالة بما يكفي للعمل مع الشبكات العصبية ، ولماذا تتدفق مليارات الدولارات على تطوير رقائق جديدة ، وما هي الآفاق. لن أكرر نفسي. يوجد أدناه تعميم وإضافة النص السابق.
بادئ ذي بدء ، تحتاج إلى فهم الاختلافات بين حسابات الشبكة العصبية والحسابات في بنية فون نيومان المألوفة (والتي يمكن ، بالطبع ، حسابها ، ولكن بطريقة أقل كفاءة):
 المصدر: الصورة ديمتري كونوفالتشوك ، مواد المؤلف
المصدر: الصورة ديمتري كونوفالتشوك ، مواد المؤلففي المرة السابقة ، دار النقاش الرئيسي حول FPGA / ASIC ، ولم تتم ملاحظة الحسابات غير الدقيقة تقريبًا ، لذلك دعونا نتناولها بمزيد من التفاصيل. إن الاحتمالات الضخمة لتقليص شرائح الأجيال القادمة هي بالتحديد القدرة على القراءة غير الدقيقة (وتخزين بيانات المعامل محليًا). في الواقع ، يتم استخدام التحجيم في الحساب الدقيق ، عند تحويل أوزان الشبكة إلى أعداد صحيحة وقياسها كمياً ، ولكن بمستوى جديد. على سبيل المثال ، ضع في اعتبارك إعلانًا وحيد بت (المثال مجردة تمامًا):
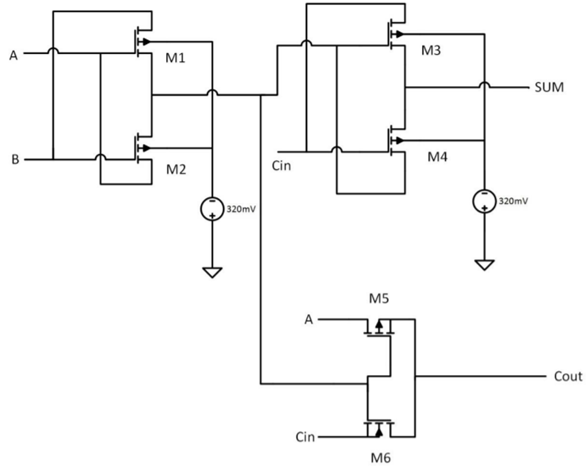 المصدر: تصميم مضاعف عالي السرعة ومنخفض الطاقة 8 بت × 8 بت باستخدام بوابات XOR من Novel Two Transistor (2T)
المصدر: تصميم مضاعف عالي السرعة ومنخفض الطاقة 8 بت × 8 بت باستخدام بوابات XOR من Novel Two Transistor (2T)يحتاج إلى 6 الترانزستورات (هناك طرق مختلفة ، يمكن أن يكون عدد الترانزستورات المطلوبة أكثر فأقل ، ولكن بشكل عام ، شيء من هذا القبيل). لمدة 8 بت ، يلزم حوالي
48 الترانزستورات . في هذه الحالة ، يتطلب الأناظر التناظرية 2 (اثنين فقط) من الترانزستورات ، أي أقل 24 مرة:
 المصدر: المضاعفات التناظرية (تحليل وتصميم الدوائر المتكاملة التناظرية)
المصدر: المضاعفات التناظرية (تحليل وتصميم الدوائر المتكاملة التناظرية)إذا كانت الدقة أعلى (على سبيل المثال ، ما يعادل 10 أو 16 بت رقمي) ، فسيكون الفرق أكبر. أكثر إثارة للاهتمام هو الوضع مع الضرب! إذا كان المضاعف الرقمي 8 بت يتطلب حوالي
400 الترانزستورات ، فإن التناظرية 6 ، أي 67 مرة (!) أقل. بالطبع ، تختلف الترانزستورات "التمثيلية" و "الرقمية" اختلافًا كبيرًا عن وجهة نظر الدوائر ، لكن الفكرة واضحة - إذا تمكنا من زيادة دقة الحسابات التناظرية ، فنحن نصل إلى الموقف بسهولة عندما نحتاج إلى طلبيين بحجم أقل ترنزستورات. وليس الهدف هو تقليل الحجم (وهو أمر مهم فيما يتعلق بـ "تباطؤ قانون مور") ، ولكن في تقليل استهلاك الكهرباء ، وهو أمر بالغ الأهمية لمنصات المحمول. وبالنسبة لمراكز البيانات ، فلن يكون ذلك ضروريًا.
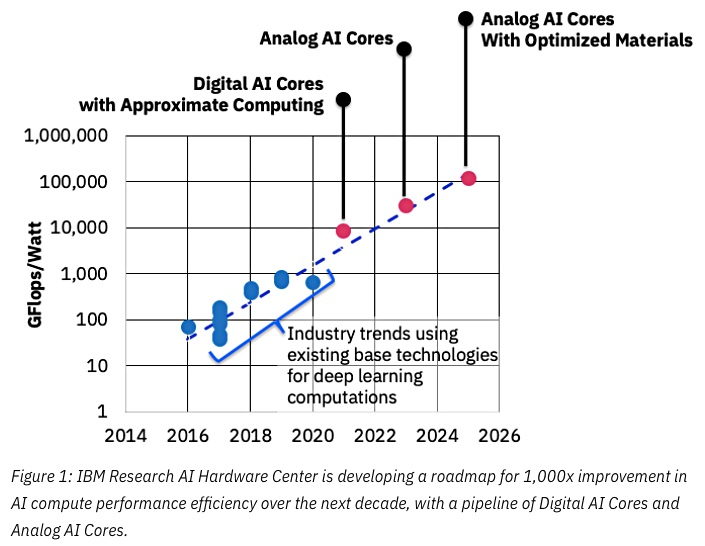 المصدر: آي بي إم تفكر في رقائق التناظرية لتسريع تعلم الآلة
المصدر: آي بي إم تفكر في رقائق التناظرية لتسريع تعلم الآلةسيكون مفتاح النجاح هنا هو تقليل الدقة ، ومرة أخرى هنا تحتل شركة IBM مكان الصدارة:
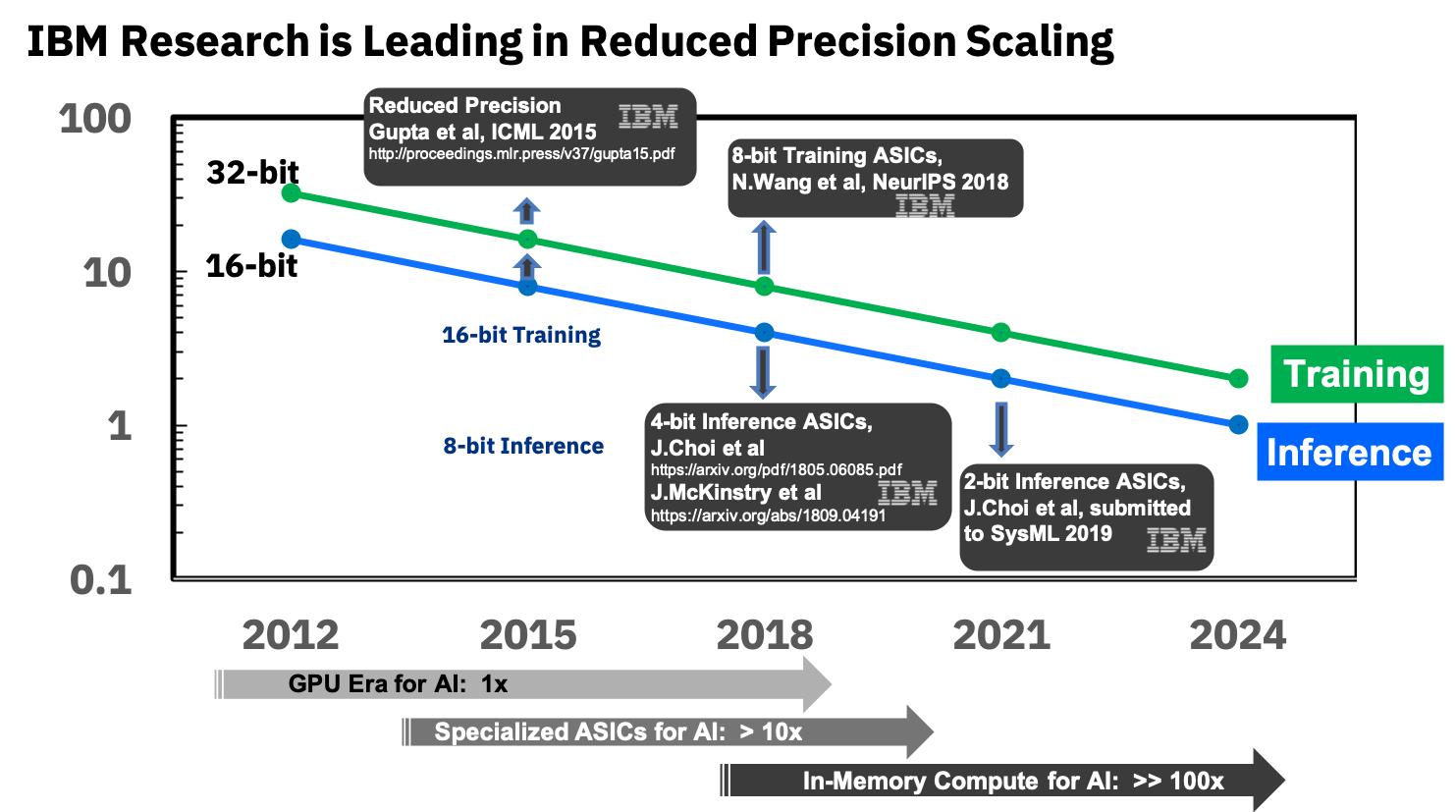 المصدر: IBM Research Blog: الدقة 8 بت للتدريب على أنظمة التعليم العميق
المصدر: IBM Research Blog: الدقة 8 بت للتدريب على أنظمة التعليم العميقإنهم يشاركون بالفعل في أسيكيات متخصصة للشبكات العصبية ، والتي تظهر أكثر من 10 أضعاف التفوق على GPU ، وتخطط لتحقيق تفوق 100 أضعاف في السنوات المقبلة. يبدو الأمر مشجعًا للغاية ، فنحن نتطلع إليه حقًا ، لأنني أكرر أن هذا سيكون بمثابة تقدم للأجهزة المحمولة.
في غضون ذلك ، فإن الوضع ليس سحريًا ، على الرغم من وجود نجاحات جدية. فيما يلي اختبار مثير للاهتمام لمسرعات الأجهزة المحمولة الحالية للشبكات العصبية (الصورة قابلة للنقر ، وهذا يسخن مرة أخرى روح المؤلف ، وكذلك في الصور في الثانية):
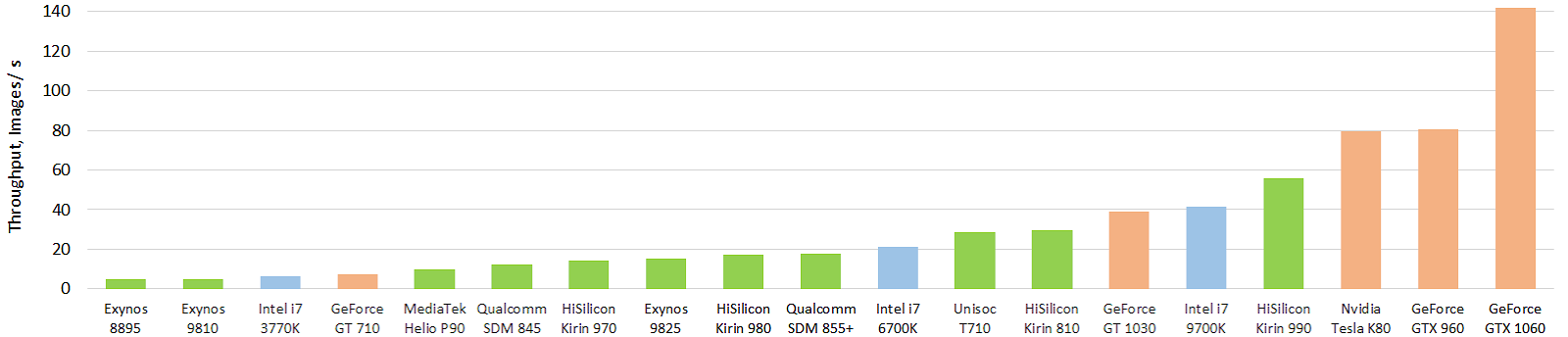 المصدر: تطور أداء مسرعات AI المتنقلة: إنتاجية الصورة لنموذج Inception-V3 العائم (نموذج FP16 باستخدام TensorFlow Lite و NNAPI)
المصدر: تطور أداء مسرعات AI المتنقلة: إنتاجية الصورة لنموذج Inception-V3 العائم (نموذج FP16 باستخدام TensorFlow Lite و NNAPI)الأخضر يشير إلى رقائق المحمول ، الأزرق يشير إلى وحدة المعالجة المركزية ، البرتقالي يشير إلى GPU. من الواضح أن شرائح المحمول الحالية ، وقبل كل شيء ، الشريحة الراقية من Huawei ، تجاوزت بالفعل وحدات المعالجة المركزية (CPU) بعشرات المرات في الحجم (واستهلاك الطاقة). وهو قوي! مع GPU ، كل شيء حتى الآن ليس سحريًا ، لكن سيكون هناك شيء آخر. يمكنك الاطلاع على النتائج بمزيد من التفاصيل على موقع ويب منفصل
http://ai-benchmark.com/ ، مع الانتباه إلى قسم الاختبارات هناك ، اختاروا مجموعة جيدة من الخوارزميات للمقارنة.
المجموع: تقدم مسرعات التناظرية اليوم من الصعب جدا تقييم. هناك سباق. لكن المنتجات لم تصدر بعد ، لذلك هناك عدد قليل نسبيا من المنشورات. يمكنك مراقبة براءات الاختراع التي تظهر مع تأخير (على سبيل المثال ، التدفق الكثيف من IBM ) أو الأسماك لبراءات الاختراع النادرة من الشركات المصنعة الأخرى. يبدو أن هذه ستكون ثورة خطيرة للغاية ، في المقام الأول في الهواتف الذكية والخوادم TPUs.بدلا من الاستنتاج
يُطلق على ML / DL اليوم تقنية برمجة جديدة ، عندما لا نكتب برنامجًا ، ولكننا ندرج كتلة ونقوم بتدريبه. أي كما كان في البداية كان هناك مجمع ، ثم C ، ثم C ++ ، والآن ، بعد مرور 30 عامًا من الانتظار ، فإن الخطوة التالية هي ML / DL:
هذا منطقي. في الآونة الأخيرة ، في الشركات المتقدمة ، يتم استبدال أماكن صنع القرار في البرامج بشبكات عصبية. أي
إذا كانت هناك بالأمس قرارات "بشأن المعايير الدولية" أو حول الاستدلال التي كانت لطيفة مع مبرمج القلب أو حتى معادلات لاغرانج (واو!) واستخدمت إنجازات أكثر تعقيدًا من عقود من تطور نظرية التحكم ، فقد وضعوا اليوم شبكة عصبية بسيطة مع 3-5 طبقات مع العديد من المدخلات وعشرات من الاحتمالات. تتعلم على الفور وتعمل بشكل أكثر فاعلية ويصبح تطوير الشفرة أسرع. إذا كان من الضروري في وقت سابق الجلوس ، والشامان ، وتشغيل الدماغ ، والآن أنا علقت به ، وأطعمته البيانات ، وعملت ، وكنت مشغولا بأشياء من المستوى الأعلى. مجرد نوع من عطلة!وبطبيعة الحال ، تصحيح الأخطاء الآن مختلف. إذا كان الأمر من قبل ، عندما لم ينجح شيء ما ، فكان هناك طلب: "أرسل مثالًا لا يعمل عليه!" ثم لحية خطيرة وذات خبرة- يلتقط الهاتف الذكي صورًا للنص ويتعرف عليه - فهذه شبكات عصبية ،
- يترجم الهاتف الذكي جيدًا أثناء التنقل من لغة إلى أخرى ويتحدث ترجمة - الشبكات العصبية والشبكات العصبية مرة أخرى ،
- يتعرف المستكشف والسماعة الذكية على الكلام تمامًا - مرة أخرى الشبكات العصبية ،
- يعرض التلفزيون صورة تباين ساطعة تبلغ 8K من فيديو 2K الإدخال - أيضًا شبكة عصبية ،
- أصبحت الروبوتات في الإنتاج أكثر دقة ، وبدأوا في رؤية الحالات الشاذة والتعرف عليها بشكل أفضل - مرة أخرى الشبكات العصبية ،
- 10 ,
- — ,
- — - — ,
- — ! )

لقد مرت 4 سنوات فقط منذ أن تعلم الناس تدريب الشبكات العصبية العميقة حقًا في كثير من النواحي بفضل BatchNorm (2015) وتخطي الاتصالات (2015) ، ومرت 3 سنوات منذ أن "أقلعت" ، ونحن نقرأ بالفعل نتائج عملهم لم ير. والآن سوف يصلون إلى المنتجات. يخبرنا شيء أنه في السنوات القادمة تنتظرنا الكثير من الأشياء المثيرة للاهتمام. خاصة عندما تكون مسرعات "الإقلاع" ...

ذات مرة ، إذا تذكر أحد ، سرق بروميثيوس النار من أوليمبوس وسلمها للناس. ابتكر غاضب زيوس مع آلهة أخرى الجمال الأول لامرأة تدعى باندورا ، وهبها الكثير من الصفات الأنثوية الرائعة
(أدركت فجأة أن إعادة سرد بعض أساطير اليونان القديمة بشكل صحيح سياسياً أمر صعب للغاية) . تم إرسال باندورا إلى الناس ، لكن بروميثيوس ، الذي اشتبه في وجود خطأ ما ، قاوم تعويذتها ، ولم يفعل أخوه إبيميثيوس. كهدية لحفل الزفاف ، أرسل زيوس النعش الجميل مع ميركوري وميركوري ، وهي نفس الرقيقة ، استوفى الأمر - لقد أعطى النعش إلى إبيميثيوس ، لكنه حذره من فتحه في أي حال. سرقت الغريب باندورا النعش من زوجها ، وفتحه ، ولكن لم يكن هناك سوى الخطايا والأمراض والحروب وغيرها من مشاكل الجنس البشري. حاولت إغلاق النعش ، ولكن بعد فوات الأوان:
 المصدر: كنيسة الفنان فريدريك ستيوارت ، صندوق باندورا المفتوح
المصدر: كنيسة الفنان فريدريك ستيوارت ، صندوق باندورا المفتوحمنذ ذلك الوقت ، ذهب تعبير "فتح صندوق باندورا" ، أي القيام بعمل لا رجعة فيه
بدافع الفضول ، وقد لا تكون عواقبه جميلة مثل زخارف النعش في الخارج.
كما تعلمون ، كلما تغوصت أكثر في الشبكات العصبية ، كان الشعور هو أن صندوق باندورا آخر أكثر وضوحًا. ومع ذلك ، فإن البشرية لديها أغنى تجربة في فتح هذه الصناديق! من الأخيرة الأخيرة - وهذا هو الطاقة النووية والإنترنت. لذلك ، أعتقد أنه يمكننا التعامل معًا. لا عجب أن حفنة من الرجال
الملتحين القاسية بين الفتاحات. حسنا ، النعش جميل ، توافق! وليس صحيحًا أن هناك مشاكل فقط ، لقد حصلوا بالفعل على مجموعة من الأشياء الجيدة. لذلك ، جاءوا معا و ... نفتح أكثر!
المجموع:
- لم تتضمن المقالة العديد من الموضوعات المثيرة للاهتمام ، على سبيل المثال ، خوارزميات ML الكلاسيكية ، تعلم النقل ، تعلم التعزيز ، شعبية مجموعات البيانات ، إلخ. (السادة ، يمكنك متابعة الموضوع!)
- إلى سؤال حول النعش: أعتقد شخصياً أن مبرمجي Google الذين سمحوا لـ Google بالتخلي عن عقد البنتاغون الذي تبلغ قيمته 10 مليارات دولار رائعون وسيئون. يحترمون ويحترمون. ومع ذلك ، لاحظ أن شخص ما فاز في هذه المناقصة الرئيسية.
اقرأ أيضا:
كل عدد كبير من الاكتشافات الجديدة المثيرة للاهتمام في عام 2020 بشكل عام وفي رأس السنة الجديدة ، على وجه الخصوص!
شكر
أود أن أشكر بحرارة:
- مختبر رسومات الحاسوب والوسائط المتعددة جامعة موسكو الحكومية MV لومونوسوف لمساهمته في تطوير التعلم العميق في روسيا وليس فقط
- شخصيا كونستانتين كوزميياكوف وديمتري كونوفالتشوك ، الذين فعلوا الكثير لجعل هذا المقال أفضل وأكثر بصرية ،
- وأخيرًا ، شكرًا جزيلًا لكيرل ماليشيف ويغور سكلياروف ونيكولاي أولباكو وأندري موسكالينكو وإيفان مولوديتسكي وإيفغيني ليابوستن ورومان كازانتسيف وألكساندر ياكوفينكو وديمتري كليبيكوف على الكثير من التعليقات والتصحيحات المفيدة التي جعلت هذا النص أفضل بكثير!