
أمامك مرة أخرى ، مهمة الكشف عن الأشياء. الأولوية - السرعة مع دقة مقبولة. كنت تأخذ هندسة YOLOv3 وتدريبها. الدقة (mAp75) أكبر من 0.95. لكن سرعة التشغيل لا تزال منخفضة. لعنة.
اليوم سنتجاوز الكمي. وتحت القصاص ، خذ بعين الاعتبار نموذج تشذيب - تقليم أجزاء الشبكة الزائدة لتسريع الاستدلال دون فقدان الدقة. بصريا - أين ، وكم وكيف لخفض. دعونا نتعرف على كيفية القيام بذلك يدويًا وأين يمكنك التنفيذ التلقائي. في النهاية هو مستودع على keras.
مقدمة
في آخر مكان من العمل ، Perm Macroscop ، حصلت على عادة واحدة - دائمًا لمراقبة وقت تنفيذ الخوارزميات. ويجب دائمًا التحقق من وقت تشغيل الشبكة من خلال مرشح كفاية. عادةً ما لا يتم تمرير هذا المرشح ، وهو أحدث ما توصلت إليه التكنولوجيا في هذا المنتج ، مما أدى بي إلى التقليم.
التقليم هو موضوع قديم تم الحديث عنه في محاضرات ستانفورد 2017. الفكرة الرئيسية هي تقليل حجم الشبكة المدربة دون فقد الدقة عن طريق إزالة العقد المختلفة. تبدو رائعة ، ولكن نادراً ما أسمع عن استخدامه. ربما ، لا توجد تطبيقات كافية ، ولا توجد مقالات باللغة الروسية ، أو الجميع يفكر في تقليم المعرفة والصمت.
ولكن الذهاب تفكيكها
نظرة على علم الأحياء
أحب عندما تكون أفكار التعلم العميق من علم الأحياء. يمكن الوثوق بها ، مثل التطور ، (هل تعلم أن ReLU يشبه إلى حد كبير وظيفة تنشيط الخلايا العصبية في الدماغ ؟)
عملية تشذيب النموذج هي أيضا قريبة من علم الأحياء. يمكن مقارنة استجابة الشبكة هنا مع مرونة المخ. يوجد مثالان مثيران للاهتمام في كتاب نورمان دودج :
- دماغ المرأة التي لديها نصف واحد فقط من الولادة أعادت برمجة نفسها لأداء وظائف النصف المفقود
- أطلق الرجل نفسه على جزء المخ المسؤول عن الرؤية. مع مرور الوقت ، أخذت أجزاء أخرى من الدماغ هذه الوظائف. (لا تحاول مرة أخرى)
لذلك من النموذج الخاص بك يمكنك قطع بعض الحزم الضعيفة. في الحالات القصوى ، ستساعد الحزم المتبقية في استبدال الحزم المقطوعة.
هل تحب نقل التعلم أو التعلم من نقطة الصفر؟
الخيار رقم واحد. كنت تستخدم نقل التعلم على Yolov3. شبكية العين ، Mask-RCNN أو U-Net. ولكن في أكثر الأحيان ، لا نحتاج إلى التعرف على 80 فئة من الكائنات ، كما هو الحال في COCO. في ممارستي ، كل شيء يقتصر على 1-2 فصول. يمكن افتراض أن الهندسة المعمارية لـ 80 درسًا لا لزوم لها هنا. يطرح فكرة أن العمارة تحتاج إلى تخفيض. علاوة على ذلك ، أود القيام بذلك دون فقدان الأوزان الحالية المدربة مسبقًا.
الخيار رقم اثنين. ربما لديك الكثير من البيانات وموارد الحوسبة ، أو تحتاج فقط إلى بنية فائقة مخصصة. لا يهم لكنك تعلم الشبكة من الصفر. الترتيب المعتاد هو إلقاء نظرة على بنية البيانات ، وتحديد بنية تم تقليلها من حيث القوة ودفع المتسربين من إعادة التدريب. رأيت المتسربين 0.6 ، كارل.
في كلتا الحالتين ، يمكن تخفيض الشبكة. Promotivirovali. الآن دعنا نذهب لمعرفة أي نوع من ختان تشذيب
الخوارزمية العامة
قررنا أن نتمكن من إزالة الإلتواء. يبدو بسيطا جدا:
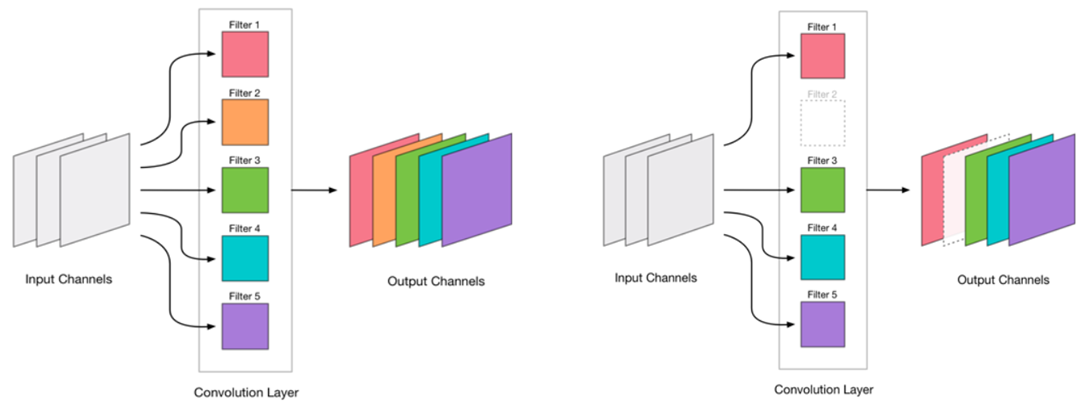
إزالة أي الإلتواء هو إجهاد للشبكة ، مما يؤدي عادة إلى بعض الزيادة في الخطأ. من ناحية ، يمثل نمو الخطأ هذا مؤشرًا على مدى صحة إزالة الالتواء (على سبيل المثال ، يشير النمو الكبير إلى أننا نقوم بشيء خاطئ). لكن النمو الصغير مقبول تمامًا وغالبًا ما يتم القضاء عليه عن طريق التدريب اللاحق السهل الإضافي باستخدام LR صغير. نضيف خطوة لإعادة التدريب:
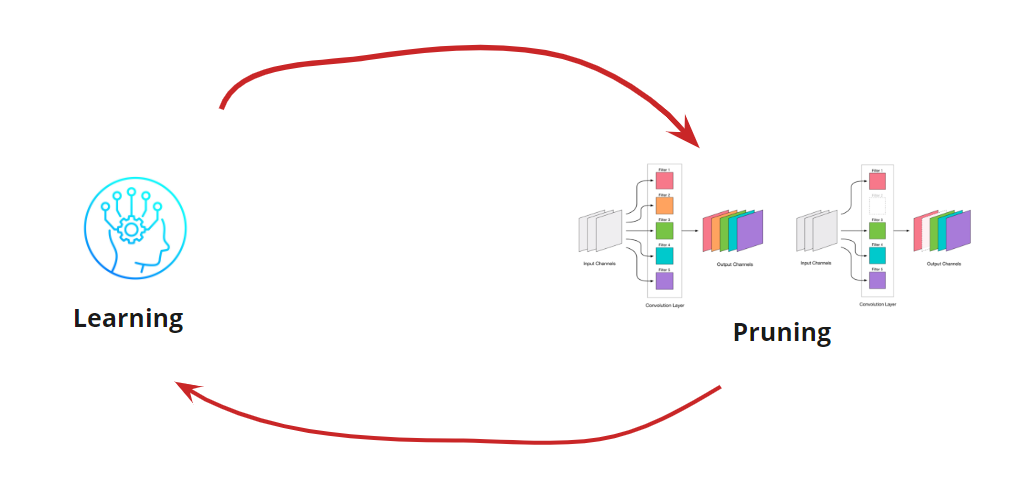
نحن الآن بحاجة إلى أن نفهم عندما نريد إيقاف دورة التعلم الخاصة بنا. قد تكون هناك خيارات غريبة عندما نحتاج إلى تقليل الشبكة إلى حجم معين وسرعة التشغيل (على سبيل المثال ، للأجهزة المحمولة). ومع ذلك ، فإن الخيار الأكثر شيوعًا هو متابعة الدورة حتى يصبح الخطأ أعلى من المسموح به. إضافة شرط:
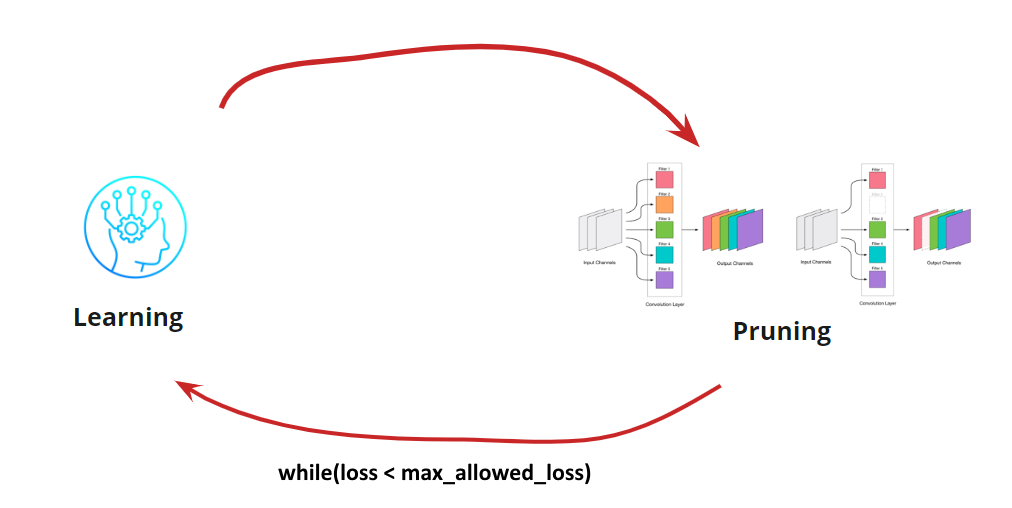
لذلك ، تصبح الخوارزمية واضحة. يبقى لمعرفة كيفية تحديد أي تلوينات لحذفها.
البحث عن الإلتواء ليتم حذفه
نحن بحاجة إلى إزالة بعض التلفيفات. التمرير إلى الأمام و "إطلاق النار" أي فكرة سيئة ، على الرغم من أنها ستنجح. ولكن إذا كان لديك رأس ، فيمكنك التفكير ومحاولة تحديد تلافيف "ضعيف" للإزالة. هناك العديد من الخيارات:
- أصغر مقياس L1 أو low_magnitude_pruning . فكرة أن تلافيف مع الأوزان الصغيرة تقدم مساهمة صغيرة في القرار النهائي
- أصغر مقياس L1 مع مراعاة الانحراف المتوسط والمعياري. نحن نكمل تقييم طبيعة التوزيع.
- إخفاء التلفيات والتقليل من التأثير على الدقة الناتجة . تعريف أكثر دقة للالتفافات الضئيلة ، ولكنه يستهلك الكثير من الوقت ويستهلك الكثير من الموارد.
- آخر
كل خيار من الخيارات له الحق في الحياة وميزات التنفيذ الخاصة به. هنا نعتبر البديل مع أصغر مقياس L1
عملية يدوية ل YOLOv3
الهيكل الأصلي يحتوي على كتل المتبقية. ولكن بغض النظر عن مدى روعة الشبكات العميقة ، فإنها ستعيقنا إلى حد ما. تكمن الصعوبة في أنه لا يمكنك حذف التسويات مع مؤشرات مختلفة في هذه الطبقات:

لذلك ، نختار الطبقات التي يمكننا من خلالها إزالة التسويات بحرية:
الآن دعونا نبني دورة عمل:
- تفريغ التنشيط
- نحن نتساءل كم لخفض
- قطع
- تعلم 10 عصور مع LR = 1e-4
- تجريب
يُعد تفريغ التصفيف مفيدًا لتقييم الجزء الذي يمكننا إزالته في خطوة معينة. أمثلة التفريغ:

نرى أنه في كل مكان تقريبًا ، تحتوي 5٪ من التلفيفات على L1 منخفض جدًا ويمكننا إزالتها. في كل خطوة ، تكررت عملية التفريغ هذه وأجري تقييم للطبقات والمقدار الذي يمكن قطعه.
اكتملت العملية برمتها في 4 خطوات (هنا وفي كل مكان أرقام RTX 2060 Super):
للخطوة 2 ، تمت إضافة تأثير إيجابي واحد - وصل حجم التصحيح 4 إلى الذاكرة ، الأمر الذي أدى إلى تسريع عملية إعادة التدريب بشكل كبير.
في الخطوة 4 ، تم إيقاف العملية ، لأن حتى التعليم المطول لم يرفع mAp75 إلى القيم القديمة.
ونتيجة لذلك ، تمكنا من تسريع الاستدلال بنسبة 15 ٪ ، وتقليل الحجم بنسبة 35 ٪ وعدم فقدان الدقة.
أتمتة أبنية أبسط
بالنسبة لأبنية الشبكات الأكثر بساطة (بدون إضافة شرطية وكتل متسلسلة ومتبقية) ، من الممكن تمامًا التركيز على معالجة جميع الطبقات التلافيفية وأتمتة عملية قطع التلفيف.
لقد نفذت هذا الخيار هنا .
إنه أمر بسيط: لديك فقط وظيفة فقد ومولد محسن ودُفعة:
import pruning from keras.optimizers import Adam from keras.utils import Sequence train_batch_generator = BatchGenerator... score_batch_generator = BatchGenerator... opt = Adam(lr=1e-4) pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt) pruner.prune(train_batch, valid_batch)
إذا لزم الأمر ، يمكنك تغيير معلمات التكوين:
{ "input_model_path": "model.h5", "output_model_path": "model_pruned.h5", "finetuning_epochs": 10, # the number of epochs for train between pruning steps "stop_loss": 0.1, # loss for stopping process "pruning_percent_step": 0.05, # part of convs for delete on every pruning step "pruning_standart_deviation_part": 0.2 # shift for limit pruning part }
بالإضافة إلى ذلك ، يتم تطبيق قيود تستند إلى الانحراف المعياري. الهدف من ذلك هو تحديد جزء من المحذوفات ، باستثناء التلفافات مع تدابير L1 "الكافية" بالفعل:
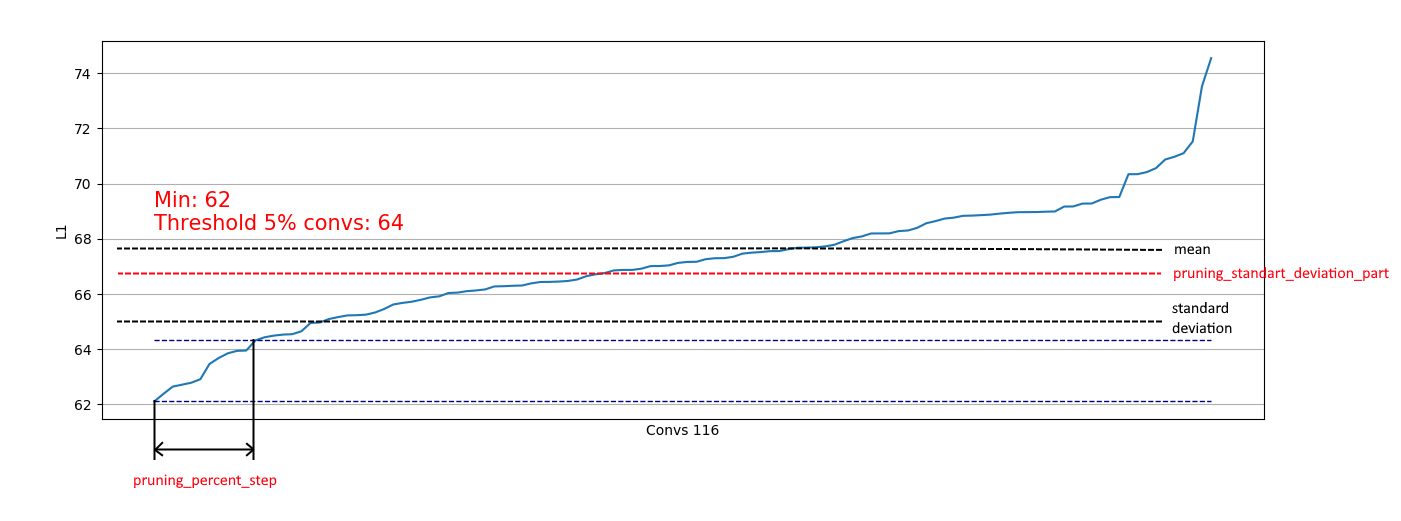
وبالتالي ، يمكننا إزالة التلفيفات الضعيفة فقط من التوزيعات المماثلة لليمين وعدم التأثير على الإزالة من التوزيعات مثل اليسار:

عندما يقترب التوزيع من الوضع الطبيعي ، يمكن تحديد معامل التقليم_standart_deviation_part من:

أوصي افتراض 2 سيغما. أو لا يمكنك التركيز على هذه الميزة ، وترك القيمة <1.0.
الإخراج هو رسم بياني لحجم الشبكة والخسارة ووقت تشغيل الشبكة للاختبار بأكمله ، تطبيع إلى 1.0. على سبيل المثال ، تم تقليل حجم الشبكة هنا مرتين تقريبًا دون فقد الجودة (شبكة تحويل صغيرة لوزن 100 كيلو):
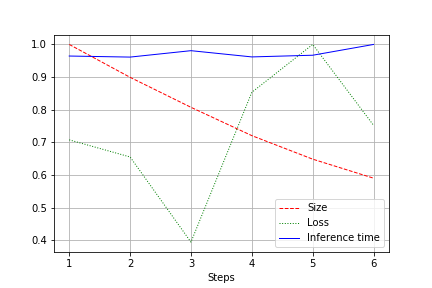
تخضع سرعة التشغيل لتقلبات عادية ولم تتغير كثيرًا. يوجد تفسير لهذا:
- يتغير عدد التلفيفات من مريحة (32 ، 64 ، 128) إلى غير الملائم لبطاقات الفيديو - 27 ، 51 ، إلخ. هنا يمكن أن أكون مخطئا ، ولكن على الأرجح يؤثر ذلك.
- الهندسة المعمارية ليست واسعة ، ولكن متسقة. تقليل العرض ، نحن لا نلمس العمق. وبالتالي ، نحن نخفف الحمل ، لكن لا نغير السرعة.
لذلك ، تم التعبير عن التحسن في انخفاض حمل CUDA أثناء التشغيل بنسبة 20-30 ٪ ، ولكن ليس في انخفاض في وقت التشغيل
النتائج
Porefleksiruem. فكرنا في خيارين للتقليص - بالنسبة إلى YOLOv3 (عندما تضطر إلى العمل بيديك) وللشبكات التي تتميز بنيات أسهل. يمكن ملاحظة أنه في كلتا الحالتين ، يمكن تحقيق انخفاض في حجم الشبكة والتسارع دون فقدان الدقة. النتائج:
- تقليص حجم
- تشغيل التسارع
- تخفيض الحمل CUDA
- نتيجة لذلك ، الود البيئي (نحن نحسن الاستخدام المستقبلي لموارد الحوسبة. في مكان ما تبتهج Greta Tunberg بمفردها)
ملحق
- بعد خطوة التقليم ، يمكنك أيضًا تحريف الكمي (على سبيل المثال ، مع TensorRT)
- يوفر Tensorflow ميزات low_magnitude_pruning . إنه يعمل.
- أريد تطوير المخزون وسأكون سعيدًا للمساعدة