نمت الشبكات العصبية من حالة من الفضول الأكاديمي إلى صناعة ضخمة

على مدى العقد الماضي ، حسنت أجهزة الكمبيوتر قدرتها بشكل كبير على فهم العالم من حولهم. يتعرف برنامج معدات التصوير تلقائيًا على وجوه الأشخاص. الهواتف الذكية تحويل الكلام إلى نص. Robomobiles تتعرف على الأشياء على الطريق وتجنب الاصطدام بها.
في قلب كل هذه الاختراقات ، توجد تقنية الذكاء الاصطناعي (AI) والتي تسمى التعلم العميق (GO). تعتمد GO على الشبكات العصبية (NS) ، وهي هياكل البيانات المستوحاة من الشبكات المكونة من الخلايا العصبية البيولوجية. يتم تنظيم NS في طبقات ، وترتبط مدخلات طبقة واحدة بمخرجات الطبقة المجاورة.
يقوم علماء الكمبيوتر بتجربة NS منذ الخمسينيات. ومع ذلك ، فقد تم إرساء أساس صناعة GO الشاسعة اليوم من خلال إنجازين رئيسيين - حدث في عام 1986 ، والثاني في عام 2012. ارتبط انطلاقة 2012 - ثورة GO - باكتشاف أن استخدام NS مع عدد كبير من الطبقات سوف يسمح لنا بتحسين كفاءتها بشكل ملحوظ. تم تسهيل هذا الاكتشاف من خلال الحجم المتزايد لكل من البيانات وقوة الحوسبة.
في هذه المقالة سوف نقدم لك عالم الجمعية الوطنية. سنشرح ماهية NS وكيف تعمل ومن أين أتوا. وسوف ندرس لماذا - على الرغم من عقود عديدة من الأبحاث السابقة - أصبحت NSs شيئًا مفيدًا حقًا فقط في عام 2012.
ظهرت الشبكات العصبية مرة أخرى في 1950s
 فرانك روزنبلات يعمل على إدراكه - نموذج NS المبكر
فرانك روزنبلات يعمل على إدراكه - نموذج NS المبكرفكرة الجمعية الوطنية قديمة جدًا - على الأقل وفقًا لمعايير علوم الكمبيوتر. مرة أخرى في عام 1957 ، نشر
فرانك روزنبلات من جامعة كورنيل
تقريراً يصف مفهوم NS المبكر المسمى perceptron. في عام 1958 ، وبدعم من البحرية الأمريكية ، ابتكر نظامًا بدائيًا قادرًا على تحليل 20 × 20 بكسل والتعرف على الأشكال الهندسية البسيطة.
لم يكن الهدف الرئيسي لـ Rosenblatt هو إنشاء نظام عملي لتصنيف الصور. حاول أن يفهم كيف يعمل الدماغ البشري ، وأنشأ أنظمة كمبيوتر منظمة على صورته. ومع ذلك ، فقد ولد هذا المفهوم حماسة مفرطة من أطراف ثالثة.
وكتبت صحيفة "نيويورك تايمز": "اليوم ، كشفت البحرية الأمريكية للعالم عن جرثومة جهاز كمبيوتر إلكتروني ، يُتوقع أن يكون قادرًا على المشي والتحدث والرؤية والكتابة وتكاثر نفسها وإدراك وجودها".
في الواقع ، كل خلية عصبية في NS هي مجرد وظيفة رياضية. تحسب كل خلية عصبية المبلغ الموزون لبيانات المدخلات - وكلما زاد وزن المدخلات ، زادت قوة بيانات المدخلات هذه بقوة في مخرجات الخلية العصبية. بعد ذلك ، يتم تغذية المبلغ الموزون بوظيفة "التنشيط" غير الخطية - في هذه الخطوة ، يمكن لـ NSs محاكاة الظواهر المعقدة غير الخطية.
إن قدرات الإدراك الحسي المبكر التي جربها روزنبلات - و NS بشكل عام - تنبع من قدرتهم على "التعلم" بأمثلة. يتم تدريب NS من خلال ضبط أوزان إدخال الخلايا العصبية بناءً على نتائج الشبكة مع اختيار بيانات الإدخال على سبيل المثال. إذا قامت الشبكة بتصنيف الصورة بشكل صحيح ، فإن الأوزان التي تساهم في الإجابة الصحيحة تزيد ، بينما تنخفض الأخرى. إذا كانت الشبكة خاطئة ، يتم ضبط الأوزان في الاتجاه الآخر.
مثل هذا الإجراء سمح للأجهزة الوطنية المبكرة "بالتعلم" بطريقة تذكر بسلوك الجهاز العصبي البشري. الضجة المحيطة بهذا النهج لم تتوقف في الستينيات. ومع ذلك ، فإن
كتاب 1969
المؤثر الذي كتبه مؤلفا علماء الكمبيوتر مارفن مينسكى وسيمور بابيرت أظهر أن لهما NA المبكر قيودًا كبيرة.
كان في أوائل Rosenblatt NSs طبقة أو طبقتان مدربيتان فقط. أظهر مينسكي وبابرت أن مثل هذه NS غير قادرة رياضيا على نمذجة الظواهر المعقدة في العالم الحقيقي.
من حيث المبدأ ، كانت NSs أعمق أكثر قدرة. ومع ذلك ، فإن مثل هذه NS قد أرهقت موارد الحوسبة البائسة التي كانت بها أجهزة الكمبيوتر في ذلك الوقت. لم أبسط خوارزميات
البحث التصاعدي المستخدمة في NSs الأولى لمقاييس NS أعمق.
ونتيجة لذلك ، فقدت الجمعية الوطنية كل الدعم في السبعينيات وأوائل الثمانينيات - كانت جزءًا من عصر "شتاء الذكاء الاصطناعي".
خوارزمية الاختراق
 تعتقد شبكتي العصبية الخاصة القائمة على "المعدات اللينة" أن احتمال وجود كلب ساخن في هذه الصورة هو 1. سنكون أثرياء!
تعتقد شبكتي العصبية الخاصة القائمة على "المعدات اللينة" أن احتمال وجود كلب ساخن في هذه الصورة هو 1. سنكون أثرياء!تحول الحظ مرة أخرى إلى NS بفضل
العمل الشهير
لعام 1986 ، والذي قدم مفهوم انتشار الظهر - طريقة عملية لتعليم NS.
لنفترض أنك تعمل كمبرمج في شركة برمجيات وهمية ، وتم توجيهك لإنشاء تطبيق يحدد ما إذا كان هناك كلب ساخن في الصورة. يمكنك البدء في العمل مع NS تم إعداده بشكل عشوائي ، والذي يأخذ صورة إدخال ويخرج قيمة من 0 إلى 1 - حيث 1 تعني "hot dog" و 0 تعني "not dog hot".
لتدريب الشبكة ، تقوم بجمع الآلاف من الصور ، وتوجد تحت كل منها تسمية تشير إلى وجود كلب ساخن على هذه الصورة. أنت تطعمها الصورة الأولى - وهناك كلب ساخن عليها - في الشبكة العصبية. يعطي قيمة إخراج 0.07 ، مما يعني "لا يوجد كلب ساخن". هذا هو الجواب الخاطئ. يجب أن ترجع الشبكة استجابة قريبة من 1.
الغرض من خوارزمية backpropagation هو ضبط أوزان الإدخال بحيث تنتج الشبكة قيمة أعلى إذا تم إعطاؤها هذه الصورة مرة أخرى ، ويفضل أن تكون الصور الأخرى التي توجد بها كلاب ساخنة. لهذا ، تبدأ خوارزمية backpropagation بفحص الخلايا العصبية المدخلة لطبقة المخرجات. كل قيمة لها متغير الوزن. تقوم خوارزمية backpropagation بضبط كل وزن في اتجاه بحيث يعطي NS قيمة أعلى. كلما زادت قيمة المدخلات ، زاد وزنها.
حتى الآن ، أصف أبسط الصعود إلى القمة المألوفة لدى الباحثين في الستينيات. كانت انطلاقة backpropagation هي الخطوة التالية: تستخدم الخوارزمية مشتقات جزئية لتوزيع "الخطأ" للإخراج غير الصحيح بين مدخلات الخلايا العصبية. تحسب الخوارزمية كيف سيؤثر التغيير الطفيف في كل قيمة إدخال على المخرجات النهائية للخلية العصبية ، وما إذا كان هذا التغيير سيؤدي إلى تقريب النتيجة أقرب إلى الإجابة الصحيحة أم العكس.
والنتيجة هي مجموعة من قيم الخطأ لكل خلية عصبية في الطبقة السابقة - في الواقع ، إشارة تقيّم ما إذا كانت قيمة كل خلية عصبية كبيرة جدًا أم صغيرة جدًا. ثم تكرر الخوارزمية عملية الضبط للخلايا العصبية الجديدة من الطبقة الثانية [من النهاية]. يغير قليلاً من أوزان المدخلات لكل الخلايا العصبية لدفع الشبكة أقرب إلى الإجابة الصحيحة.
ثم تستخدم الخوارزمية مرة أخرى مشتقات جزئية لحساب كيفية تأثير قيمة كل إدخال من الطبقة السابقة على أخطاء الإخراج لهذه الطبقة - ونشر هذه الأخطاء مرة أخرى إلى الطبقة السابقة ، حيث تتكرر العملية مرة أخرى.
هذا هو مجرد نموذج backpropagation مبسطة. إذا كنت بحاجة إلى تفاصيل رياضية مفصلة ، أوصي بكتاب Michael Nielsen حول هذا الموضوع [
ولدينا ترجمتها / تقريبًا. العابرة.]. لأغراضنا ، يكفي أن التوزيع العكسي قد غير جذريًا نطاق NS المدربين. لم يعد الناس يقتصرون على الشبكات البسيطة ذات الطبقة أو الطبقتين. يمكن أن ينشئوا شبكات ذات خمسة أو عشرة أو خمسين طبقة ، ويمكن أن يكون لهذه الشبكات بنية داخلية معقدة بشكل تعسفي.
أطلق اختراع backpropagation الطفرة الثانية للجمعية الوطنية ، والتي بدأت في تحقيق نتائج عملية. في عام 1998 ، أظهرت مجموعة من الباحثين من AT&T كيف يمكن استخدام الشبكات العصبية للتعرف على الأرقام المكتوبة بخط اليد ، مما جعل من الممكن أتمتة معالجة الشيكات.
"الرسالة الرئيسية لهذا العمل هي أنه يمكننا إنشاء أنظمة محسنة للتعرف على الأنماط ، والاعتماد أكثر على التعلم التلقائي وبدرجة أقل على الأساليب البحثية المطورة يدويًا" ، كتب المؤلفون.
ومع ذلك ، في هذه المرحلة ، كانت NSs مجرد واحدة من العديد من التقنيات الموجودة تحت تصرف الباحثين في مجال التعلم الآلي. عندما درست في دورة AI في المعهد في عام 2008 ، كانت الشبكات العصبية مجرد واحدة من تسع خوارزميات MO ، والتي يمكننا من خلالها اختيار الخيار المناسب للمهمة. ومع ذلك ، كانت GO تستعد بالفعل لتلقي بظلالها على بقية التكنولوجيا.
البيانات الكبيرة توضح قوة التعلم العميق
 تم اكتشاف الاسترخاء. فرصة الشاطئ 1.0. نبدأ إجراء استخدام ماي تاي.
تم اكتشاف الاسترخاء. فرصة الشاطئ 1.0. نبدأ إجراء استخدام ماي تاي.سهّلت عملية Backpropagation عملية حساب NS ، لكن الشبكات الأعمق ما زالت بحاجة إلى موارد حوسبية أكثر من تلك الصغيرة. وكثيرا ما أظهرت نتائج الدراسات التي أجريت في التسعينات والألفينيات أنه كان من الممكن الحصول على فائدة أقل وأقل من المضاعفات الإضافية لل NS.
ثم تم تغيير تفكير الناس من خلال العمل الشهير لعام 2012 ، الذي وصف NS تحت اسم AlexNet ، الذي سمي على اسم الباحث الرائد Alex Krizhevsky. مثل الشبكات العميقة يمكن أن توفر كفاءة اختراق ، ولكن فقط في تركيبة مع وفرة من طاقة الكمبيوتر وكمية هائلة من البيانات.
طورت AlexNet ثلاثة من علماء الكمبيوتر من جامعة تورنتو للمشاركة في مسابقة العلوم ImageNet. جمع منظمو المسابقة مليون صورة على الإنترنت ، تم تصنيف كل منها وتخصيصها لأحد آلاف فئات الكائنات ، على سبيل المثال ، "الكرز" أو "سفينة الحاويات" أو "النمر". طُلب من باحثي الذكاء الاصطناعى تدريب برامج MO الخاصة بهم على أجزاء من هذه الصور ، ثم حاول وضع الملصقات الصحيحة للصور الأخرى التي لم يصادفها البرنامج من قبل. كان على البرنامج اختيار خمس علامات ممكنة لكل صورة ، واعتبرت المحاولة ناجحة إذا تزامنت إحداها مع العلامة الحقيقية.
كانت هذه مهمة صعبة ، وحتى عام 2012 ، لم تكن النتائج جيدة للغاية. للفائز عام 2011 ، كان معدل الخطأ 25 ٪.
في عام 2012 ، تفوقت فريق AlexNet على جميع المنافسين من خلال إعطاء إجابات بنسبة 15٪ من الأخطاء. لأقرب منافس ، كان هذا الرقم 26 ٪.
جمع باحثون من تورونتو العديد من التقنيات لتحقيق نتائج مذهلة. وكان واحد منهم استخدام
العصبية التلافيفية (SNS). في الواقع ، يقوم نظام الحسابات القومية ، كما كان ، بتدريب الشبكات العصبية الصغيرة - التي تكون بيانات الإدخال فيها مربعات من 7 إلى 11 بكسل - ثم "تقوم بتثبيتها" على صورة أكبر.
"لقد بدا الأمر كما لو كنت قد أخذت قالبًا صغيرًا أو استنسلًا وحاولت مقارنته بكل نقطة في الصورة" ، أخبرنا باحث منظمة العفو الدولية جي تان العام الماضي. - لديك استنسل كلب ، وتعلقه على الصورة ، ومعرفة ما إذا كان هناك كلب هناك؟ إذا لم يكن كذلك ، حرك الاستنسل. وهكذا للصورة كاملة. وبغض النظر عن مكان ظهور الكلب في الصورة. سوف الاستنسل يتزامن معها. يجب ألا يصبح كل قسم فرعي للشبكة مصنّفًا منفصلاً للكلاب. "
يتمثل عامل النجاح الرئيسي لـ AlexNet في استخدام بطاقات الرسومات لتسريع عملية التعلم. تتمتع بطاقات الرسومات بقوة معالجة متوازية ، ومناسبة تمامًا للحوسبة المتكررة اللازمة لتدريب الشبكة العصبية. نقل عبء الحوسبة إلى زوج من وحدات معالجة الرسومات - Nvidia GTX 580 ، مع 3 غيغابايت من الذاكرة لكل منهما - تمكن الباحثون من تطوير وتدريب شبكة كبيرة ومعقدة للغاية. كان لدى AlexNet ثماني طبقات قابلة للتدريب ، و 650.000 خلية عصبية ، و 60 مليون معلمة.
أخيرًا ، تم ضمان نجاح AlexNet أيضًا من خلال الحجم الكبير لقاعدة بيانات الصور التدريبية من ImageNet: مليون قطعة. هناك حاجة إلى الكثير من الصور لضبط 60 مليون معلمة. لتحقيق نصر حاسم ، تم مساعدة AlexNet من خلال مجموعة من الشبكات المعقدة ومجموعة كبيرة من البيانات.
أتساءل لماذا لم يحدث هذا الاختراق في وقت سابق:
- كان زوج GPU من فئة المستهلك الذي استخدمه باحثو AlexNet بعيدًا عن أقوى جهاز حوسبة لعام 2012. قبل خمس سنوات وحتى عشر سنوات ، كان هناك أجهزة كمبيوتر أكثر قوة. بالإضافة إلى ذلك ، أصبحت تقنية تسريع تعلم NS باستخدام بطاقات الرسوميات معروفة منذ عام 2004 على الأقل.
- كانت قاعدة مليون صورة كبيرة بشكل غير عادي لتدريس خوارزميات MO في عام 2012 ، ومع ذلك ، فإن جمع مثل هذه البيانات لم يكن تقنية جديدة لتلك السنة. يمكن لفريق بحث جيد التمويل أن يجمع بسهولة قاعدة بيانات بهذا الحجم قبل خمس أو عشر سنوات.
- الخوارزميات الرئيسية المستخدمة في AlexNet لم تكن جديدة. كانت خوارزمية backpropagation بحلول عام 2012 موجودة بالفعل منذ حوالي ربع قرن. تم تطوير الأفكار الرئيسية المتعلقة بالشبكات العصبية التلافيفية في الثمانينيات والتسعينيات.
لذلك كان كل عنصر من عناصر نجاح AlexNet موجودًا بشكل منفصل قبل فترة طويلة من حدوث الاختراق. من الواضح أنه لم يحدث قط لأي شخص أن يجمعهم - في الغالب لأن أحدا لم يكن يعرف مدى قوة هذا المزيج.
زيادة عمق NS من الناحية العملية لم تحسن كفاءة عملهم إذا لم يستخدموا مجموعات كبيرة من بيانات التدريب الكافية. وتوسيع مجموعة البيانات لم يحسن أداء الشبكات الصغيرة. لرؤية الزيادة في الكفاءة ، كنا بحاجة إلى كل من الشبكات الأعمق ومجموعات البيانات الأكبر - بالإضافة إلى قوة حوسبة كبيرة سمحت لنا بإجراء عملية التدريب في فترة زمنية معقولة. كان فريق AlexNet أول من جمع العناصر الثلاثة في برنامج واحد.
طفرة التعلم العميق

لقد لاحظ العديد من الأشخاص - كل من العلماء والباحثين وممثلي الصناعة - عرضًا توضيحيًا لكل قوة NS العميق ، التي توفرها كمية كافية من بيانات التدريب.
أول مسابقة ImageNet للتغيير. حتى عام 2012 ، كان معظم المتسابقين يستخدمون تقنيات غير التعلم العميق. في مسابقة 2013 ، كما كتب الرعاة ، استخدمت "غالبية" المتسابقين GO.
انخفضت نسبة الأخطاء بين الفائزين تدريجياً - من 16٪ في AlexNet عام 2012 إلى 2.3٪ في عام 2017:
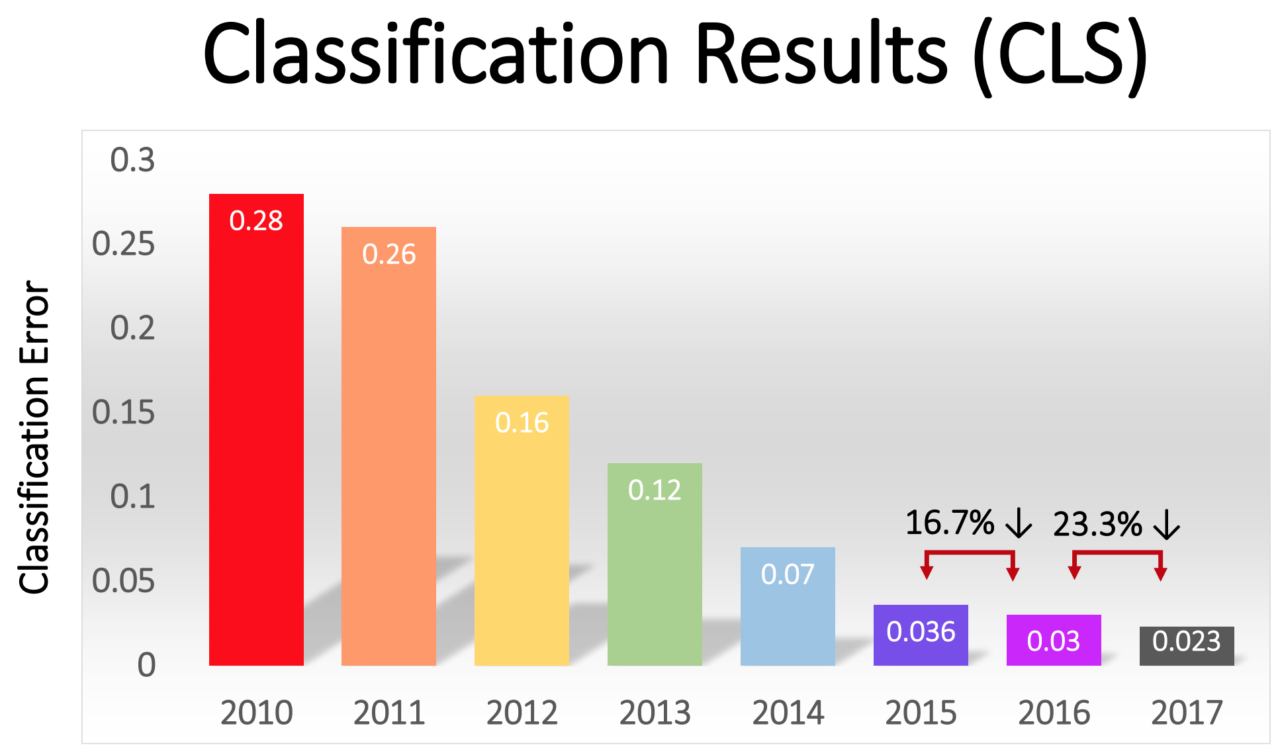
ثورة GO انتشرت بسرعة في جميع أنحاء الصناعة. في عام 2013 ، حصلت Google على شركة ناشئة تم تشكيلها من مؤلفي AlexNet ، واستخدمت تقنيتها كقاعدة لوظيفة البحث عن الصور في صور Google. بحلول عام 2014 ، كان Facebook يروج لبرنامجه الخاص الذي يتعرف على الصور باستخدام GO. تستخدم Apple GO للتعرف على الوجوه في نظام التشغيل iOS منذ عام 2016 على الأقل.
GO أيضا الأساس للتحسن الأخير في تكنولوجيا التعرف على الصوت. يستخدم Siri من Apple ، و Alexa من Amazon ، و Cortana من Microsoft ومساعد Google ، GO - إما لفهم كلمات الشخص ، أو لتوليد صوت أكثر طبيعية ، أو كليهما.
في السنوات الأخيرة ، ظهر اتجاه قائم على الاكتفاء الذاتي في الصناعة ، حيث تدعم كل من الزيادة في طاقة الحوسبة وحجم البيانات وعمق الشبكة بعضها البعض. استخدم فريق AlexNet وحدة معالجة الرسومات (GPU) لأنها عرضت حوسبة متوازية بسعر معقول. ولكن على مدار الأعوام القليلة الماضية ، بدأت المزيد والمزيد من الشركات في تطوير رقائقها الخاصة ، والمصممة خصيصًا للاستخدام في مجال MO.
أعلنت Google عن إصدار رقاقة وحدة معالجة Tensor المصممة خصيصًا لنظام NS في عام 2016. وفي نفس العام ، أعلنت Nvidia عن إطلاق وحدة معالجة رسومات جديدة تسمى Tesla P100 ، وهي الأمثل لنظام NS. قامت إنتل بالرد على المكالمة بشريحة AI الخاصة بها في عام 2017. في عام 2018 ، أعلنت أمازون عن إطلاق شريحة AI الخاصة بها ، والتي يمكن استخدامها كجزء من الخدمات السحابية للشركة. ويقال إن مايكروسوفت تعمل على رقاقة الذكاء الاصطناعي.
يعمل مصنعو الهواتف الذكية أيضًا على الرقاقات التي ستسمح للأجهزة المحمولة بإجراء المزيد من الحوسبة باستخدام NS محليًا ، دون الحاجة إلى تحميل البيانات إلى الخوادم. مثل هذا الحوسبة على الأجهزة يقلل من الكمون ويعزز الخصوصية.
دخلت حتى تسلا هذه اللعبة مع رقائق خاصة. هذا العام ، أظهرت تسلا جهاز كمبيوتر جديد قوي ، الأمثل لحساب NS. أطلقت تسلا اسمها على جهاز كمبيوتر كامل القيادة الذاتية ، واعتبرته لحظة مهمة في استراتيجية الشركة لتحويل أسطول تسلا إلى مركبات آلية.
أدى توافر قدرات الكمبيوتر المُحسّنة لـ AI إلى إنشاء طلب للبيانات اللازمة لتدريب NS على نحو متزايد التعقيد. هذه الديناميكية أكثر وضوحًا في قطاع السيارات الآلية ، حيث تقوم الشركات بجمع البيانات عن ملايين الكيلومترات من الطرق الحقيقية. يمكن لـ Tesla جمع هذه البيانات تلقائيًا من سيارات المستخدمين ، ويدفع منافسوها Waymo و Cruise السائقين الذين قادوا سياراتهم على الطرق العامة.

يمنح طلب البيانات ميزة للشركات الكبيرة عبر الإنترنت التي لديها بالفعل إمكانية الوصول إلى كميات كبيرة من بيانات المستخدم.
غزا التعلم العميق العديد من المجالات المختلفة بسبب مرونته الشديدة. لقد أتاحت عقود من التجربة والخطأ للباحثين تطوير لبنات البناء الأساسية للمهام الأكثر شيوعًا في مجال MO - مثل شبكات الالتفاف للتعرف على الصور بكفاءة. ومع ذلك ، إذا كان لديك شبكة عالية المستوى مناسبة للمخطط وبيانات كافية ، فستكون عملية التدريب بسيطة. NS NS العميق قادر على التعرف على مجموعة واسعة بشكل استثنائي من الأنماط المعقدة دون توجيه خاص من المطورين البشريين.
هناك قيود ، بالطبع. على سبيل المثال ، انغمس بعض الأشخاص في فكرة تدريب أجهزة robomobile بمساعدة GO فقط ، أي تغذية الصور التي تم تلقيها من الكاميرا ، والشبكة العصبية ، وتلقي الإرشادات منها لتحويل عجلة القيادة ودواسة القيادة. أنا متشكك في هذا النهج. , , . , « », . .
. .