مرحباً هبر! تنمو مجموعات البيانات الضخمة والتعلم الآلي بشكل كبير وتحتاج إلى معالجة. نشرنا على تقنية مبتكرة أخرى في الحوسبة عالية الأداء (HPC) ، ظهرت في كشك Kingston في
Supercomputing 2019 . هذا هو تطبيق أنظمة التخزين Hi-End (SHD) في الخوادم التي تحتوي على معالجات رسومية (GPU) وتقنية ناقل GPUDirect Storage. بفضل تبادل البيانات المباشر بين وحدة التخزين ووحدات معالجة الرسومات ، وتجاوز وحدة المعالجة المركزية ، يتم تسريع عملية تحميل البيانات في معجلات وحدة معالجة الرسومات بمعدل ضخم ، لذلك تعمل تطبيقات البيانات الكبيرة بأقصى أداء توفره وحدة معالجة الرسومات. بدوره ، يهتم مطورو أنظمة HPC بالتقدم في التخزين بأعلى سرعة إدخال / إخراج - مثل إصدارات Kingston.

أداء GPU قبل تحميل البيانات
منذ إنشاء CUDA ، بنية الحوسبة المتوازية للأجهزة والبرامج القائمة على GPU لتطوير تطبيقات للأغراض العامة ، في عام 2007 ، نمت قدرات الأجهزة في وحدات معالجة الرسومات نفسها بشكل لا يصدق. اليوم ، يتم استخدام وحدات معالجة الرسومات بشكل متزايد في مجال تطبيقات HPC مثل البيانات الكبيرة والتعلم الآلي والتعلم العميق.
لاحظ أنه على الرغم من تشابه المصطلحات ، فإن الأخيرتين مهمتان مختلفتان حسابيًا. ML يعلم الكمبيوتر على أساس البيانات المنظمة ، DL يعلم الكمبيوتر على أساس استجابة من الشبكة العصبية. مثال يساعد على فهم الاختلافات بسيط للغاية. لنفترض أن الكمبيوتر يجب أن يميز صور القطط والكلاب التي تم تحميلها من التخزين. بالنسبة إلى ML ، يجب عليك تقديم مجموعة من الصور تحتوي على العديد من العلامات ، كل منها يعرّف ميزة واحدة خاصة بالحيوان. بالنسبة إلى DL ، يكفي تحميل عدد أكبر بكثير من الصور ، ولكن باستخدام علامة واحدة فقط "هذه قطة" أو "هذا كلب". يشبه DL إلى حد كبير كيفية تعليم الأطفال الصغار - يتم عرضهم ببساطة على صور للكلاب والقطط في الكتب وفي الحياة (في معظم الأحيان ، دون حتى شرح الفرق التفصيلي) ، ويبدأ دماغ الطفل نفسه في تحديد نوع الحيوان بعد عدد حرج من الصور للمقارنة. وفقا للتقديرات ، نحن نتحدث عن مائة أو اثنين من الانطباعات طوال فترة الطفولة المبكرة). لم تعد خوارزميات DL مثالية بعد: من أجل العمل بنجاح على تعريف صور الشبكة العصبية ، من الضروري إرسال ملايين الصور ومعالجتها في وحدة معالجة الرسومات.
نتيجة المقدمة: على أساس GPU ، يمكنك إنشاء تطبيقات HPC في مجال البيانات الكبيرة ، ML و DL ، ولكن هناك مشكلة - مجموعات البيانات كبيرة للغاية بحيث أن الوقت الذي يستغرقه تنزيل البيانات من نظام التخزين إلى GPU يبدأ في تقليل الأداء العام للتطبيق. بمعنى آخر ، لا تزال وحدات معالجة الرسومات السريعة تعاني من نقص التحميل بسبب بطء إدخال / إخراج البيانات من الأنظمة الفرعية الأخرى. يمكن أن يكون الفرق في سرعة الإدخال / الإخراج في وحدة معالجة الرسومات والحافلة إلى وحدة المعالجة المركزية / SHD أمرًا ذا حجم.
كيف تعمل تقنية GPUDirect Storage؟
يتم التحكم في عملية الإدخال / الإخراج بواسطة وحدة المعالجة المركزية ، وكذلك عملية تحميل البيانات من التخزين إلى وحدات معالجة الرسومات للمعالجة اللاحقة. أدى هذا إلى طلب تقنية توفر وصولاً مباشراً بين محركات GPU و NVMe للتفاعل السريع مع بعضها البعض. تم اقتراح أول تقنية من هذا القبيل بواسطة NVIDIA وسميتها GPUDirect Storage. في الواقع ، هذا هو الاختلاف في تقنية GPUDirect RDMA (عنوان الذاكرة عن بُعد المباشر) التي طورتها سابقًا.
 ينسن هوانغ ، الرئيس التنفيذي لشركة NVIDIA ، يقدم GPUDirect Storage كتنوع من GPUDirect RDMA في SC-19. المصدر: نفيديا
ينسن هوانغ ، الرئيس التنفيذي لشركة NVIDIA ، يقدم GPUDirect Storage كتنوع من GPUDirect RDMA في SC-19. المصدر: نفيدياالفرق بين GPUDirect RDMA و GPUDirect Storage هو في الأجهزة التي يتم تنفيذ العنونة بينها. تم إعادة تعيين تقنية GPUDirect RDMA لنقل البيانات مباشرة بين بطاقة إدخال واجهة الشبكة (NIC) وذاكرة GPU ، وتوفر GPUDirect Storage مسارًا مباشرًا لنقل البيانات بين التخزين المحلي أو البعيد ، مثل NVMe أو NVMe via Fabric (NVMe-oF) وذاكرة GPU.
يتجنب كلا الخيارين ، GPUDirect RDMA و GPUDirect Storage ، نقل البيانات غير الضرورية من خلال مخزن مؤقت في ذاكرة وحدة المعالجة المركزية والسماح لآلية الوصول المباشر للذاكرة (DMA) بنقل البيانات من بطاقة الشبكة أو التخزين مباشرة إلى أو من ذاكرة GPU - كل ذلك دون تحميل على الجهاز المركزي المعالج. بالنسبة إلى GPUDirect Storage ، لا يهم موقع التخزين: يمكن أن يكون قرص NVME داخل وحدة GPU ، أو داخل رف ، أو متصلاً عبر شبكة مثل NVMe-oF.
 GPUDirect نظام التشغيل التخزين. المصدر: نفيديا
GPUDirect نظام التشغيل التخزين. المصدر: نفيدياNVMe Hi-End Storage مطلوب في سوق تطبيقات HPC
مع إدراك أنه مع ظهور GPUDirect Storage ، سيتم تحويل اهتمام العملاء الكبار إلى تقديم أنظمة تخزين مع سرعة إدخال / إخراج تتوافق مع عرض نطاق GPU ، أظهر Kingston نظامًا تجريبيًا يتكون من أنظمة التخزين القائمة على أقراص NVMe ووحدة مع GPU في SC-19 التي حللت الآلاف من صور الأقمار الصناعية في الثانية الواحدة. لقد كتبنا بالفعل عن هذا التخزين على أساس 10 محركات DC1000M U.2 NVMe
في تقرير من معرض الحواسيب الفائقة .
 التخزين على أساس 10 محركات DC1000M U.2 NVMe يكمل الخادم بشكل كاف مع مسرعات الرسومات. المصدر: كينغستون
التخزين على أساس 10 محركات DC1000M U.2 NVMe يكمل الخادم بشكل كاف مع مسرعات الرسومات. المصدر: كينغستونيتم إجراء هذا التخزين على شكل وحدة حامل 1U أو أكثر ويمكن تحجيمه وفقًا لعدد من الأقراص DC1000M U.2 NVMe ، حيث تبلغ سعة كل منها 3.84-7.68 تيرابايت. إن DC1000M هو أول طراز NVMe SSD في عامل الشكل U.2 في خط محرك Kingston لمراكز البيانات. لديه تصنيف القدرة على التحمل (DWPD ، يكتب Drive في اليوم الواحد) ، والذي يسمح لك بالكتابة فوق البيانات بكامل طاقتها مرة واحدة يوميًا لضمان عمر محرك مضمون.
في اختبار fio v3.13 على نظام التشغيل Ubuntu 18.04.3 LTS ، Linux kernel 5.0.0-31-generic ، أظهر طراز تخزين المعرض سرعة قراءة ثابتة تبلغ 5.8 مليون IOPS مع نطاق ترددي ثابت يبلغ 23.8 جيجابت / ثانية.
وصف أرييل بيريز ، مدير أعمال SSD في Kingston ، أنظمة التخزين الجديدة على النحو التالي: "نحن على استعداد لتزويد الجيل التالي من الخوادم بأجهزة SSD U.2 NVMe لمعالجة العديد من اختناقات نقل البيانات المرتبطة تقليديًا بالتخزين. تجعل مجموعة محركات الأقراص الثابتة NVMe و Server Premier DRAM المتميزة من كينغستون واحدة من أكثر موفري معالج البيانات الشاملين شمولاً في هذا المجال. "
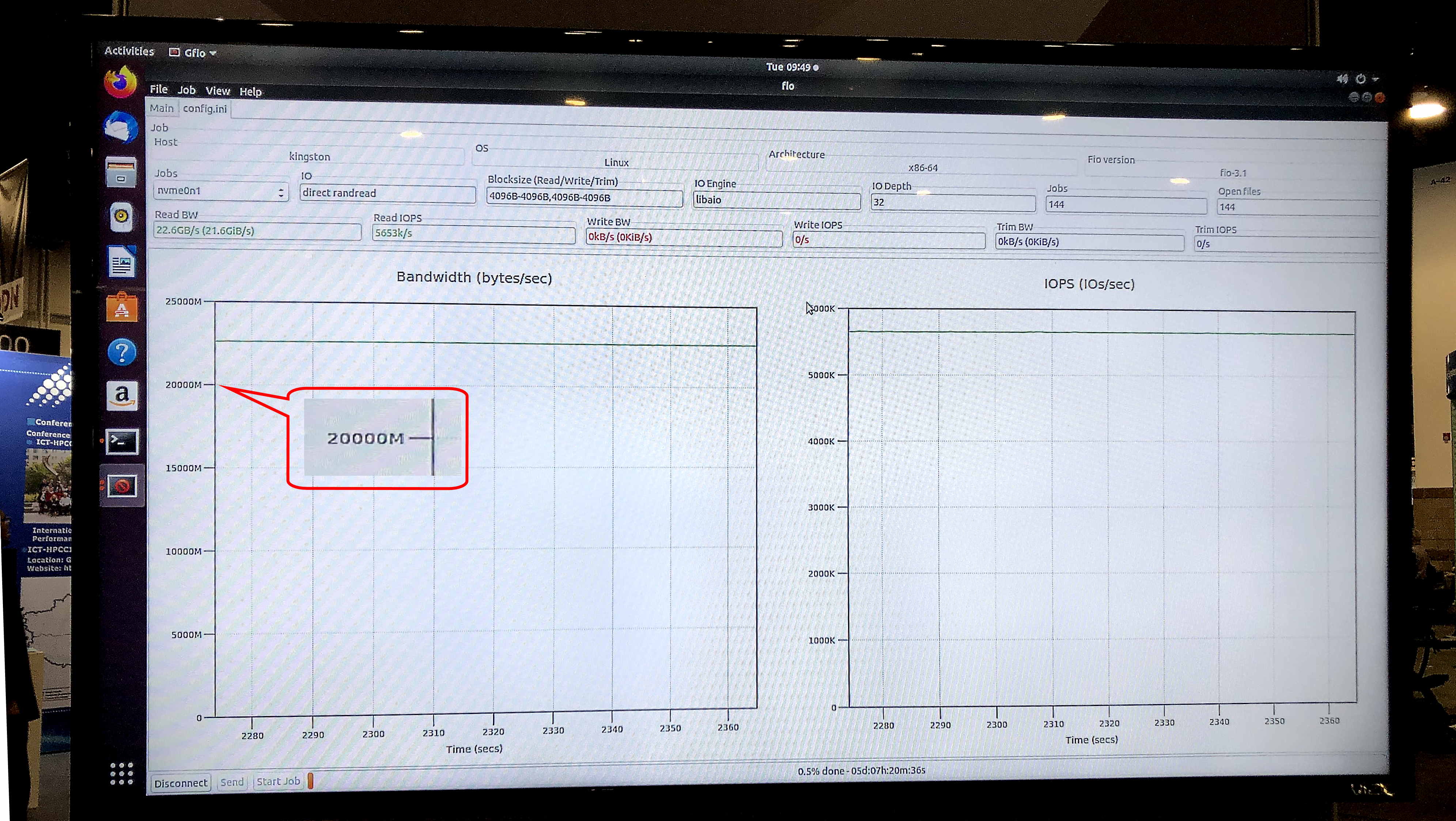 أظهر اختبار gfio v3.13 عرض نطاق ترددي قدره 23.8 جيجابت / ثانية للتخزين التجريبي على محركات DC1000M U.2 NVMe. المصدر: كينغستون
أظهر اختبار gfio v3.13 عرض نطاق ترددي قدره 23.8 جيجابت / ثانية للتخزين التجريبي على محركات DC1000M U.2 NVMe. المصدر: كينغستونكيف سيبدو النظام النموذجي لتطبيقات HPC التي تستخدم تقنية GPUDirect Storage أو ما شابهها؟ هذه بنية مع الفصل المادي للكتل الوظيفية داخل الحامل: وحدة واحدة أو وحدتين لذاكرة الوصول العشوائي ، وعدد قليل آخر للعقد الحوسبية GPU و CPU ووحدة أو أكثر للتخزين.
مع الإعلان عن GPUDirect Storage واحتمال ظهور تقنيات مماثلة في بائعي GPU الآخرين ، تقوم Kingston بتوسيع طلبها على أنظمة التخزين المصممة للاستخدام في الحوسبة عالية الأداء. ستكون العلامة هي سرعة قراءة البيانات من نظام التخزين ، ويمكن مقارنتها مع عرض النطاق الترددي لبطاقات الشبكة 40 أو 100 جيجابت عند مدخل وحدة الحوسبة مع وحدة معالجة الرسومات. وبالتالي ، فإن أنظمة التخزين فائقة السرعة ، بما في ذلك NVMe الخارجية من خلال Fabric ، من غريبة ستصبح السائدة لتطبيقات HPC. بالإضافة إلى الحسابات العلمية والمالية ، سيجدون التطبيق في العديد من المجالات العملية الأخرى ، مثل أنظمة السلامة على مستوى المدن الآمنة الكبرى في المدن الكبرى أو مراكز المراقبة على المركبات التي تتطلب التعرف على ملايين الصور عالية الدقة والتعرف عليها في الثانية "، مكانة السوق في القمة SAN
يمكن العثور على معلومات إضافية حول منتجات Kingston على
الموقع الرسمي للشركة.