مقدمة.
سمع كل شخص على دراية بـ C ++ الحديثة أنه ابتداءً من الإصدار C ++ 11 ، تم تقديم مُحدِّد constexpr في المعيار ، حيث من الممكن إجراء عمليات حسابية محدودة زمن التحويل البرمجي.
إذا تمت إضافة
constexpr و
constexpr lambdas إلى المعايير التالية ، مما يؤدي إلى حد ما إلى إزالة القيود والمساعدة في كتابة التعليمات البرمجية مع حسابات وقت الترجمة. اليوم سنتحدث عن إنشاء شفرة عشوائية في وقت الترجمة.
نختار الأساس لاستلام قيم وقت الترجمة "العشوائية"
من أجل اختيار مسار محدد للرمز في وقت التحويل البرمجي ، فأنت بحاجة إلى PRNG constexpr مع إخراج جيد ، ولهذا اخترت مولد
xorshift ، بالمناسبة ، يمر
xorshift باختبارات
BigCrush التجريبية
(TestU01) .
xorshift256 ++#include <stdint.h> /* This is xoshiro256++ 1.0, one of our all-purpose, rock-solid generators. It has excellent (sub-ns) speed, a state (256 bits) that is large enough for any parallel application, and it passes all tests we are aware of. For generating just floating-point numbers, xoshiro256+ is even faster. The state must be seeded so that it is not everywhere zero. If you have a 64-bit seed, we suggest to seed a splitmix64 generator and use its output to fill s. */ static inline uint64_t rotl(const uint64_t x, int k) { return (x << k) | (x >> (64 - k)); } static uint64_t s[4]; uint64_t next(void) { const uint64_t result = rotl(s[0] + s[3], 23) + s[0]; const uint64_t t = s[1] << 17; s[2] ^= s[0]; s[3] ^= s[1]; s[1] ^= s[2]; s[0] ^= s[3]; s[2] ^= t; s[3] = rotl(s[3], 45); return result; } /* This is the jump function for the generator. It is equivalent to 2^128 calls to next(); it can be used to generate 2^128 non-overlapping subsequences for parallel computations. */ void jump(void) { static const uint64_t JUMP[] = { 0x180ec6d33cfd0aba, 0xd5a61266f0c9392c, 0xa9582618e03fc9aa, 0x39abdc4529b1661c }; uint64_t s0 = 0; uint64_t s1 = 0; uint64_t s2 = 0; uint64_t s3 = 0; for(int i = 0; i < sizeof JUMP / sizeof *JUMP; i++) for(int b = 0; b < 64; b++) { if (JUMP[i] & UINT64_C(1) << b) { s0 ^= s[0]; s1 ^= s[1]; s2 ^= s[2]; s3 ^= s[3]; } next(); } s[0] = s0; s[1] = s1; s[2] = s2; s[3] = s3; } /* This is the long-jump function for the generator. It is equivalent to 2^192 calls to next(); it can be used to generate 2^64 starting points, from each of which jump() will generate 2^64 non-overlapping subsequences for parallel distributed computations. */ void long_jump(void) { static const uint64_t LONG_JUMP[] = { 0x76e15d3efefdcbbf, 0xc5004e441c522fb3, 0x77710069854ee241, 0x39109bb02acbe635 }; uint64_t s0 = 0; uint64_t s1 = 0; uint64_t s2 = 0; uint64_t s3 = 0; for(int i = 0; i < sizeof LONG_JUMP / sizeof *LONG_JUMP; i++) for(int b = 0; b < 64; b++) { if (LONG_JUMP[i] & UINT64_C(1) << b) { s0 ^= s[0]; s1 ^= s[1]; s2 ^= s[2]; s3 ^= s[3]; } next(); } s[0] = s0; s[1] = s1; s[2] = s2; s[3] = s3; }
من هذا ، نحتاج فقط إلى وظائف rotl و next ، حتى لا نجعل الحسابات طويلة جدًا. أبعث بتحياتي الخالصة إلى مطوري برنامج التحويل البرمجي لـ MSVC ، نظرًا لوجود أخطاء برنامج التحويل البرمجي التي تم اكتشافها أثناء عملية الكتابة ، سيتم مناقشته أدناه.
كما ترى من الكود أعلاه ، نحتاج إلى أربعة متغيرات ثابتة 64 بت لتخزين الحالة ، لكي يعمل هذا الكود في وقت الترجمة ، نحتاج إلى التخلص منها بتمرير حالة عشوائية كمعلمات. يمكنك تنظيم ذلك باستخدام constexpr hash fnv1 والماكرو __COUNTER__ ، أعد كتابة الكود وفقًا لهذا والحصول على ما يلي:
تجميع الوقت "عشوائي" #include <cstdint> #define STRING(s) #s // an enumeration can also be used here template <typename T, T value> constexpr T ensure_constexpr() { return value; } #define CONSTEXPR(x) ensure_constexpr<decltype(x), x>() constexpr uint64_t fnv1impl(uint64_t h, const char* s) { return (*s == 0) ? h : fnv1impl((h * 1099511628211ull) ^ static_cast<uint64_t>(*s), s + 1); } constexpr uint64_t fnv1(const char* s) { return fnv1impl(14695981039346656037ull, s); } template <uint64_t n> constexpr uint64_t get_seed(const uint64_t x, const uint64_t y = CONSTEXPR(fnv1(STRING(n)))) { return x ^ y * n; } #define SEED CONSTEXPR(get_seed<__COUNTER__ + 1>(fnv1(__TIME__))) //! Rotate left by constexpr uint64_t rotl(uint64_t x, int k) { return (x << k) | (x >> (64 - k)); } //! XorShift 256 compile time random implementation template <uint64_t a, uint64_t b, uint64_t c, uint64_t d> constexpr uint64_t xorshift256_next() { uint64_t s[4] = {a, b, c, d}; const uint64_t t = s[1] << 17; s[2] ^= s[0]; s[3] ^= s[1]; s[1] ^= s[2]; s[0] ^= s[3]; s[2] ^= t; s[3] = rotl(s[3], 45); return rotl(s[0] + s[3], 23) + s[0]; } #define RND \ xorshift256_next< \ CONSTEXPR(SEED + __COUNTER__), CONSTEXPR(SEED + __COUNTER__), \ CONSTEXPR(SEED + __COUNTER__), CONSTEXPR(SEED + __COUNTER__)>()
تحت غطاء محرك السيارة
الآن نحن بحاجة إلى التأكد من أن المجمعين "ينهارون" الكود في وقت الترجمة.
نحن نجمع الشفرة أدناه باستخدام GCC 9.2.1 في debug g ++ _.cpp -S -masm = intel
#include "compile_random.h" #include <iostream> int main() { std::cout << RND << std::endl; std::cout << RND << std::endl; }
أريد أن أرى قصص الرعب.file "_.cpp"
.intel_syntax noprefix
.text
.section .text._Z4rotlmi,"axG",@progbits,_Z4rotlmi,comdat
.weak _Z4rotlmi
.type _Z4rotlmi, @function
_Z4rotlmi:
.LFB4:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
mov QWORD PTR [rbp-8], rdi
mov DWORD PTR [rbp-12], esi
mov eax, DWORD PTR [rbp-12]
mov rdx, QWORD PTR [rbp-8]
mov ecx, eax
rol rdx, cl
mov rax, rdx
pop rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE4:
.size _Z4rotlmi, .-_Z4rotlmi
.section .rodata
.type _ZStL19piecewise_construct, @object
.size _ZStL19piecewise_construct, 1
_ZStL19piecewise_construct:
.zero 1
.local _ZStL8__ioinit
.comm _ZStL8__ioinit,1,1
.text
.globl main
.type main, @function
main:
.LFB1528:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
call _Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv
mov rsi, rax
mov edi, OFFSET FLAT:_ZSt4cout
call _ZNSolsEm
mov esi, OFFSET FLAT:_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
mov rdi, rax
call _ZNSolsEPFRSoS_E
call _Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv
mov rsi, rax
mov edi, OFFSET FLAT:_ZSt4cout
call _ZNSolsEm
mov esi, OFFSET FLAT:_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
mov rdi, rax
call _ZNSolsEPFRSoS_E
mov eax, 0
pop rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1528:
.size main, .-main
.section .text._Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv,"axG",@progbits,_Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv,comdat
.weak _Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv
.type _Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv, @function
_Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv:
.LFB1790:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
sub rsp, 48
movabs rax, 5485350875583313748
mov QWORD PTR [rbp-48], rax
movabs rax, -1344488152466593804
mov QWORD PTR [rbp-40], rax
movabs rax, -8102276183547423076
mov QWORD PTR [rbp-32], rax
movabs rax, 2938160962983216444
mov QWORD PTR [rbp-24], rax
mov rax, QWORD PTR [rbp-40]
sal rax, 17
mov QWORD PTR [rbp-8], rax
mov rdx, QWORD PTR [rbp-32]
mov rax, QWORD PTR [rbp-48]
xor rax, rdx
mov QWORD PTR [rbp-32], rax
mov rdx, QWORD PTR [rbp-24]
mov rax, QWORD PTR [rbp-40]
xor rax, rdx
mov QWORD PTR [rbp-24], rax
mov rdx, QWORD PTR [rbp-40]
mov rax, QWORD PTR [rbp-32]
xor rax, rdx
mov QWORD PTR [rbp-40], rax
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-24]
xor rax, rdx
mov QWORD PTR [rbp-48], rax
mov rax, QWORD PTR [rbp-32]
xor rax, QWORD PTR [rbp-8]
mov QWORD PTR [rbp-32], rax
mov rax, QWORD PTR [rbp-24]
mov esi, 45
mov rdi, rax
call _Z4rotlmi
mov QWORD PTR [rbp-24], rax
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov esi, 23
mov rdi, rax
call _Z4rotlmi
mov rdx, QWORD PTR [rbp-48]
add rax, rdx
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1790:
.size _Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv, .-_Z16xorshift256_nextILm5485350875583313748ELm17102255921242957812ELm10344467890162128540ELm2938160962983216444EEmv
.section .text._Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv,"axG",@progbits,_Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv,comdat
.weak _Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv
.type _Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv, @function
_Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv:
.LFB1794:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
sub rsp, 48
movabs rax, -3891678030706526748
mov QWORD PTR [rbp-48], rax
movabs rax, 7653162274090525828
mov QWORD PTR [rbp-40], rax
movabs rax, 823244081203417900
mov QWORD PTR [rbp-32], rax
movabs rax, -6510995906087812148
mov QWORD PTR [rbp-24], rax
mov rax, QWORD PTR [rbp-40]
sal rax, 17
mov QWORD PTR [rbp-8], rax
mov rdx, QWORD PTR [rbp-32]
mov rax, QWORD PTR [rbp-48]
xor rax, rdx
mov QWORD PTR [rbp-32], rax
mov rdx, QWORD PTR [rbp-24]
mov rax, QWORD PTR [rbp-40]
xor rax, rdx
mov QWORD PTR [rbp-24], rax
mov rdx, QWORD PTR [rbp-40]
mov rax, QWORD PTR [rbp-32]
xor rax, rdx
mov QWORD PTR [rbp-40], rax
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-24]
xor rax, rdx
mov QWORD PTR [rbp-48], rax
mov rax, QWORD PTR [rbp-32]
xor rax, QWORD PTR [rbp-8]
mov QWORD PTR [rbp-32], rax
mov rax, QWORD PTR [rbp-24]
mov esi, 45
mov rdi, rax
call _Z4rotlmi
mov QWORD PTR [rbp-24], rax
mov rdx, QWORD PTR [rbp-48]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov esi, 23
mov rdi, rax
call _Z4rotlmi
mov rdx, QWORD PTR [rbp-48]
add rax, rdx
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1794:
.size _Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv, .-_Z16xorshift256_nextILm14555066043003024868ELm7653162274090525828ELm823244081203417900ELm11935748167621739468EEmv
.text
.type _Z41__static_initialization_and_destruction_0ii, @function
_Z41__static_initialization_and_destruction_0ii:
.LFB2042:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
sub rsp, 16
mov DWORD PTR [rbp-4], edi
mov DWORD PTR [rbp-8], esi
cmp DWORD PTR [rbp-4], 1
jne .L11
cmp DWORD PTR [rbp-8], 65535
jne .L11
mov edi, OFFSET FLAT:_ZStL8__ioinit
call _ZNSt8ios_base4InitC1Ev
mov edx, OFFSET FLAT:__dso_handle
mov esi, OFFSET FLAT:_ZStL8__ioinit
mov edi, OFFSET FLAT:_ZNSt8ios_base4InitD1Ev
call __cxa_atexit
.L11:
nop
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE2042:
.size _Z41__static_initialization_and_destruction_0ii, .-_Z41__static_initialization_and_destruction_0ii
.type _GLOBAL__sub_I_main, @function
_GLOBAL__sub_I_main:
.LFB2043:
.cfi_startproc
push rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
mov rbp, rsp
.cfi_def_cfa_register 6
mov esi, 65535
mov edi, 1
call _Z41__static_initialization_and_destruction_0ii
pop rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE2043:
.size _GLOBAL__sub_I_main, .-_GLOBAL__sub_I_main
.section .init_array,"aw"
.align 8
.quad _GLOBAL__sub_I_main
.hidden __dso_handle
.ident "GCC: (GNU) 9.2.1 20190827 (Red Hat 9.2.1-1)"
.section .note.GNU-stack,"",@progbits
كما ترى من رمز المجمّع أعلاه ، فإن الدالتين rotl و xorshift256_next موجودة في التعليمات البرمجية ، ولكن في الواقع هذا هو السلوك المتوقع ، حيث تم تعطيل التحسينات.
تحقق مع تمكين التحسينات g ++ _.cpp -S -masm = intel -O2
لم أعد أشعر بالخوف ، لقد رأيت كل شيء.file "_.cpp"
.intel_syntax noprefix
.text
.section .text.startup,"ax",@progbits
.p2align 4
.globl main
.type main, @function
main:
.LFB1550:
.cfi_startproc
sub rsp, 8
.cfi_def_cfa_offset 16
mov edi, OFFSET FLAT:_ZSt4cout
movabs rsi, 6340608927850167019
call _ZNSo9_M_insertImEERSoT_
mov rdi, rax
call _ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
mov edi, OFFSET FLAT:_ZSt4cout
movabs rsi, -1433878323375531419
call _ZNSo9_M_insertImEERSoT_
mov rdi, rax
call _ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
xor eax, eax
add rsp, 8
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE1550:
.size main, .-main
.p2align 4
.type _GLOBAL__sub_I_main, @function
_GLOBAL__sub_I_main:
.LFB2064:
.cfi_startproc
sub rsp, 8
.cfi_def_cfa_offset 16
mov edi, OFFSET FLAT:_ZStL8__ioinit
call _ZNSt8ios_base4InitC1Ev
mov edx, OFFSET FLAT:__dso_handle
mov esi, OFFSET FLAT:_ZStL8__ioinit
mov edi, OFFSET FLAT:_ZNSt8ios_base4InitD1Ev
add rsp, 8
.cfi_def_cfa_offset 8
jmp __cxa_atexit
.cfi_endproc
.LFE2064:
.size _GLOBAL__sub_I_main, .-_GLOBAL__sub_I_main
.section .init_array,"aw"
.align 8
.quad _GLOBAL__sub_I_main
.local _ZStL8__ioinit
.comm _ZStL8__ioinit,1,1
.hidden __dso_handle
.ident "GCC: (GNU) 9.2.1 20190827 (Red Hat 9.2.1-1)"
.section .note.GNU-stack,"",@progbits
الصيحة! حصلنا على ما توقعنا ، قام المترجم بنشر 2 مكالمات من الماكرو RND لتعليمات 2 mov. سلوك clang و MSVC compilers في RELEASE MODE مشابه. يمكنك المتابعة لتجميع توليد رمز الوقت.
لمزيد من الفهم ، تحتاج إلى تعريف نفسك بالعناصر المنطقية العالمية.
NOR (رصيف الميناء)
NAND (شريط شيفر) الذي يمكنك من خلاله بناء المنطق بالكامل. لن أرفق كل الكود لتطبيق & | ^ ++ - ، سنقوم بتحليل مثال واحد فقط على أساس أخذ عينات عشوائية من وظيفة قالب NAND ، في التعليمات الأخرى التي تمت مضاهاتها مبدأ الاختيار هو نفسه.
دعنا نتخيل أن لدينا 5 تطبيقات NAND قالب نرغب في إضفاء الطابع العشوائي عليها.
للقيام بذلك ، نحتاج فقط إلى القيام بما يلي:
template <typename T, const uint64_t n> FORCEINLINE volatile T NandR(volatile T a, volatile T b) { switch (n % 5) { case 0: return Nand_1<T>(a, b); case 1: return Nand_2<T>(a, b); case 2: return Nand_3<T>(a, b); case 3: return Nand_4<T>(a, b); case 4: return Nand_5<T>(a, b); default: return Nand_1<T>(a, b); } }
يمكن أن يطلق عليه في رمز مثل هذا:
NandR<uint64_t, RND>(a,b)
سيترك المحول البرمجي استدعاء دالة واحدة فقط ، والتي سيتم تحديدها وفقًا للنتيجة من الماكرو RND ، حيث أن الرقم معروف في وقت التحويل البرمجي. RND هو ماكرو يستخدم xorshift + fnv1 + __COUNTER__ والذي تمت مناقشته أعلاه. أيضًا للراحة ، تمت كتابة فئة القالب البدائي CNNInt <> والتي تحتوي على حمولات زائدة من المشغلين الضروريين من أجل تحسين قابلية قراءة الكود.
خذ بعين الاعتبار رمز المجمّع الذي تم إنشاؤه و DIFF من مجموعتين مختلفتين للوظيفة التالية:
uint64_t diff_me(uint64_t x) { using u64 = uint64_t; CNNInt<u64> r(std::chrono::system_clock::now().time_since_epoch().count()); CNNInt<u64> test(x); test++; test--; test|=r; test^=r; test&=r; test^=r; test = ~test; return test.value(); }
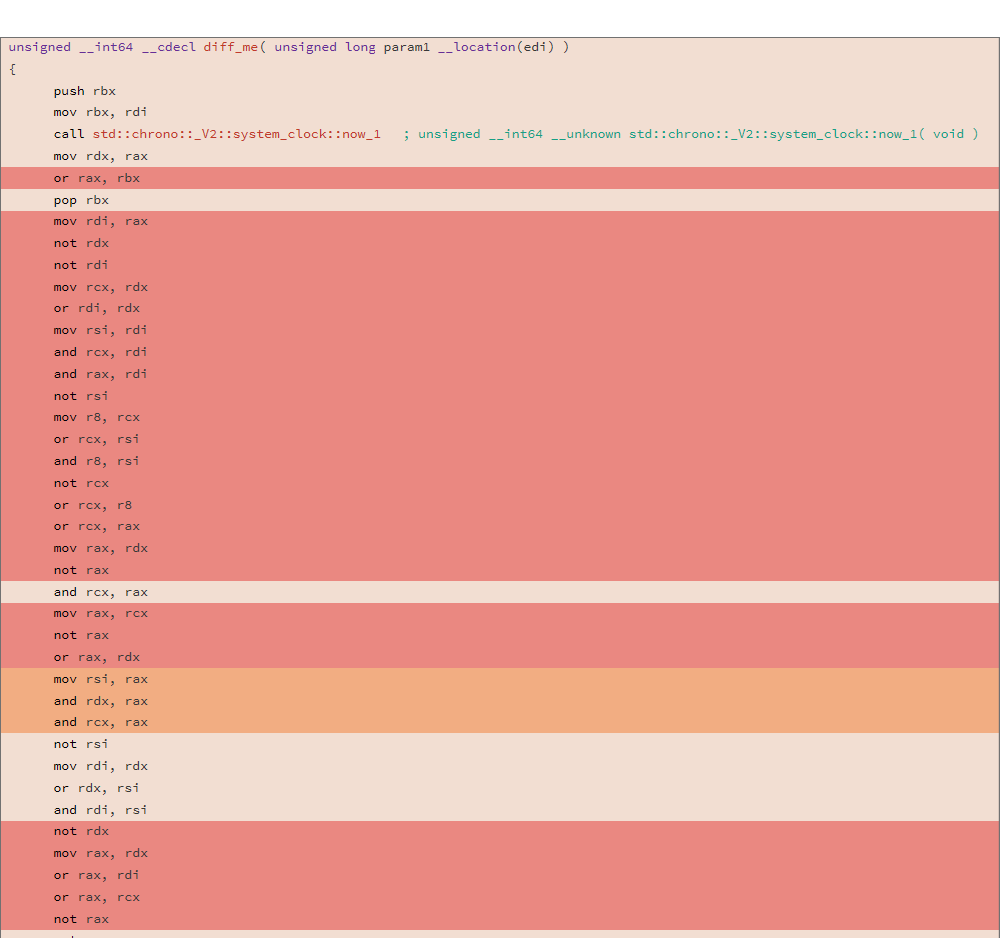
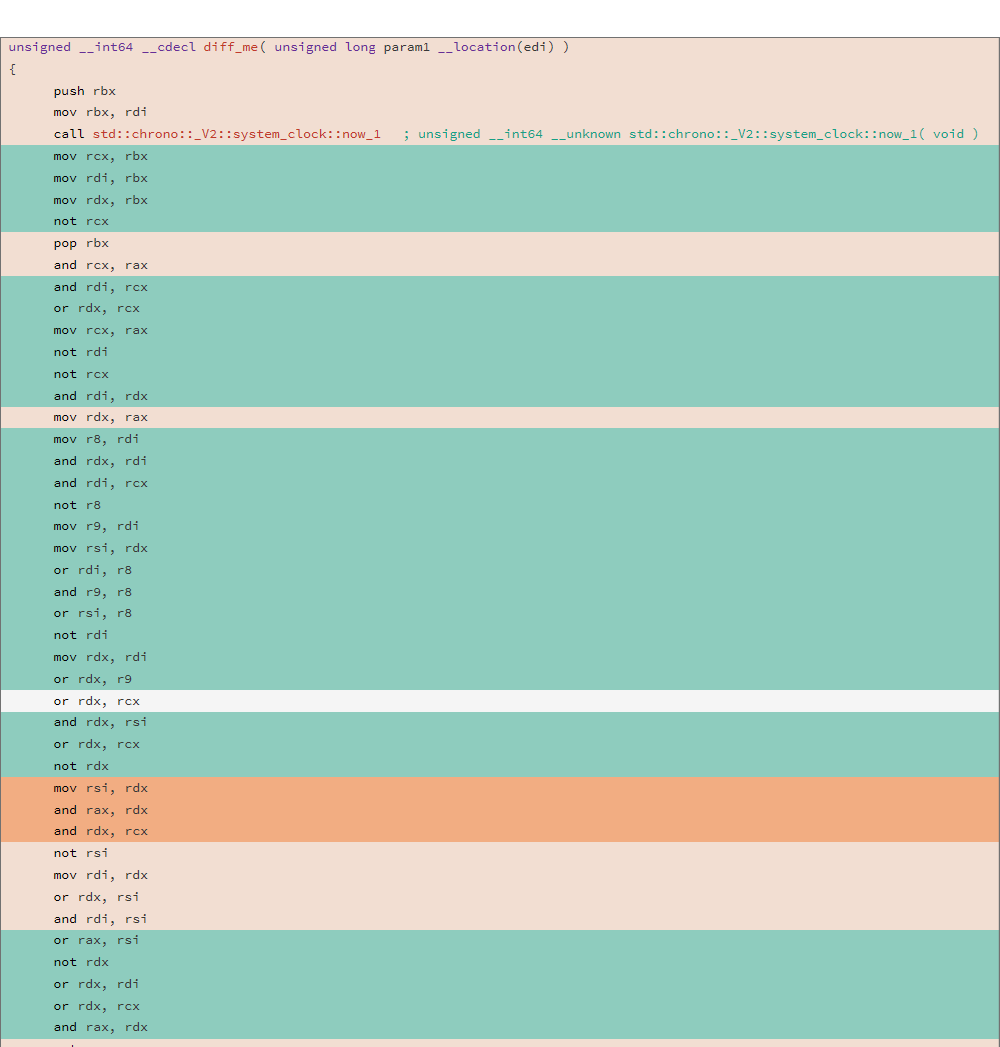
تم إجراء التحليل باستخدام الأداة المساعدة للتحليل ، وأظهر مهرجان دبي السينمائي الدولي للثنائيات النتيجة التالية:
81.13% diff_me - diff_me
دعونا نلقي نظرة على وظيفة diff_me تحت decompilers:
1.
غيدرا ulong diff_me(ulong param_1) { ulong uVar1; ulong uVar2; ulong uVar3; ulong uVar4; uVar1 = now(); uVar2 = ~uVar1; uVar3 = ~(param_1 & ~param_1 & uVar1) & (param_1 | ~param_1 & uVar1); uVar4 = ~uVar3; uVar3 = (~(uVar3 & uVar2 | uVar4) | uVar3 & uVar2 & uVar4 | uVar2) & (uVar1 & uVar3 | uVar4) | uVar2; uVar4 = ~uVar3 & uVar2; return (uVar1 & ~uVar3 | uVar3) & (~(uVar4 | uVar3) | uVar4 & uVar3 | uVar2); }
هناك وظيفة execute_code أخرى في المشروع كمثال ، تعذر على Ghidra إلغاء ترجمته.
2.
النطاط int _Z7diff_mem(long arg0) { rax = std::chrono::_V2::system_clock::now(); rax = (rax & !((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax) | !!((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax)) & (!(!((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax) & !rax | !!((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax)) | !((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax) & !rax & !!((!(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) & !rax & !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax)) | !rax) & (rax & !(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax) | !(!(arg0 & !arg0 & rax) & (arg0 | !arg0 & rax))) | !rax) | !rax); return rax; }
3.
RetDec
المكافآت
1.
مستودع المشروع .
2. دعنا نعود إلى برنامج التحويل البرمجي لـ MSVC (إصدار سلسلة الأدوات 16.4.2) ، حيث يقوم تجميع المثال من المشروع باستهلاك قدر كبير من الذاكرة ويستغرق الكثير من الوقت ، لقد
أبلغت فريق برنامج التحويل البرمجي لـ MSVC عن الخطأ ، وسأكون سعيدًا إذا قمت بالتصويت لإصلاح هذا الخطأ.
استهلاك الذاكرة عند ترجمة مشروع اختبار:

تجدر الإشارة إلى أن تجميع مشروع الاختبار باستخدام Clang 9.0 و GCC 9.1.1 يحدث على الفور تقريبًا ولا يأكل مثل هذا القدر من الذاكرة :)