اليوم ، هناك حلول جاهزة (خاصة) لمراقبة تدفقات IP (TS) ، مثل VB و iQ ، لديهم مجموعة غنية إلى حد ما من الوظائف وعادة ما تتوفر حلول مماثلة للمشغلين الكبار الذين يتعاملون مع خدمات التلفزيون. توضح هذه المقالة حلاً يستند إلى المشروع المفتوح المصدر TSDuck ، المصمم لتقليل التحكم في تدفقات IP (TS) بواسطة عداد CC (عداد الاستمرارية) ومعدل البت. تطبيق ممكن هو التحكم في فقدان الحزم أو الدفق بأكمله من خلال قناة L2 مستأجرة (والتي لا يمكن مراقبتها بشكل طبيعي ، على سبيل المثال ، من خلال قراءة عدادات الخسارة في قوائم الانتظار).
موجز جدا حول TSDuck
TSDuck عبارة عن برنامج مفتوح المصدر (ترخيص 2-Clause BSD) (مجموعة من الأدوات المساعدة لوحدة التحكم ومكتبة لتطوير الأدوات المساعدة أو المكونات الإضافية) لمعالجة تدفقات TS. كمدخل يمكن أن تعمل مع IP (الإرسال المتعدد / أحادي الإرسال) ، http ، hls ، dvb tuners ، dektec dvb-asi demodulator ، هناك مولد تيار TS داخلي وقراءة من الملفات. الإخراج يمكن أن يكون ملف ، IP (الإرسال المتعدد / أحادي الإرسال) ، hls ، dektec dvb-asi و HiDes modulators ، اللاعبين (mplayer ، vlc ، xine) وإسقاط. بين المدخلات والمخرجات ، يمكنك تمكين معالجات حركة المرور المختلفة ، على سبيل المثال ، إعادة تعيين PID ، والتخليط / إزالة التخليط ، وتحليل عدادات CC ، وحساب معدل البت وغيرها من العمليات النموذجية لتدفقات TS.
في هذه المقالة ، سيتم استخدام تدفقات IP (البث المتعدد) كمدخلات ، وتستخدم معالجات bitrate_monitor (من الاسم يكون واضحًا ما هو عليه) والاستمرارية (تحليل عدادات CC). دون أي مشاكل ، يمكنك استبدال البث المتعدد IP بنوع إدخال آخر يدعمه TSDuck.
هناك تصميمات / حزم TSDuck الرسمية لمعظم أنظمة التشغيل الحالية. بالنسبة إلى دبيان ، فهم ليسوا كذلك ، ولكن كان من الممكن التجميع دون مشاكل في إطار دبيان 8 و دبيان 10.
بعد ذلك ، يتم استخدام إصدار TSDuck 3.19-1520 ، ويستخدم نظام Linux باعتباره نظام التشغيل (تم استخدام debian 10 لإعداد الحل ، وتم استخدام CentOS 7 للاستخدام الحقيقي)
إعداد TSDuck ونظام التشغيل
قبل مراقبة التدفقات الحقيقية ، تحتاج إلى التأكد من أن TSDuck يعمل بشكل صحيح وأنه لا توجد قطرات على مستوى بطاقة الشبكة أو نظام التشغيل (المقبس). هذا مطلوب حتى لا يخمن فيما بعد مكان حدوث القطرات - على الشبكة أو "داخل الخادم". يمكنك التحقق من حالات السقوط على مستوى بطاقة الشبكة باستخدام الأمر ethtool -S ethX ، ويتم الضبط باستخدام نفس ethtool (عادة ، تحتاج إلى زيادة المخزن المؤقت RX (-G) وتعطيل بعض عمليات إلغاء التحميل (أحيانًا)). كتوصية عامة ، يمكنك أن توصي باستخدام منفذ منفصل لتلقي حركة المرور التي تم تحليلها ، إن كان ذلك ممكنًا ، فهذا يقلل من الإيجابيات الخاطئة المرتبطة بحقيقة أن الهبوط قد حدث بشكل متماسك على منفذ محلل بسبب وجود حركة مرور أخرى. إذا لم يكن ذلك ممكنًا (يتم استخدام جهاز كمبيوتر صغير / NUC مع منفذ واحد) ، فمن المستحسن للغاية إعطاء أولوية لحركة المرور التي تم تحليلها بالنسبة إلى بقية الجهاز الذي يتصل به المحلل. فيما يتعلق بالبيئات الافتراضية ، عليك هنا أن تكون حذراً وأن تكون قادرًا على العثور على قطرات الحزمة بدءًا من المنفذ الفعلي وتنتهي بالتطبيق داخل الجهاز الظاهري.
إنشاء واستقبال دفق داخل المضيف
كخطوة أولى في إعداد TSDuck ، سنقوم بإنشاء واستقبال حركة المرور داخل نفس المضيف باستخدام netns.
بيئة الطبخ:
ip netns add P
البيئة جاهزة. نبدأ محلل حركة المرور:
ip netns exec P tsp --realtime -t \ -I ip 239.0.0.1:1234 \ -P continuity \ -P bitrate_monitor -p 1 -t 1 \ -O drop
حيث "-p 1 -t 1" تعني أنك تحتاج إلى حساب معدل البت كل ثانية وعرض معلومات حول معدل البت كل ثانية
نبدأ مولد الحركة بسرعة 10 ميغابت في الثانية:
tsp -I craft \ -P regulate -b 10000000 \ -O ip -p 7 -e --local-port 6000 239.0.0.1:1234
حيث يعني "-p 7 -e" أنك تحتاج إلى حزم 7 حزم TS في حزمة IP واحدة والقيام بذلك بجد (-e) ، أي انتظر دائمًا 7 حزم TS من آخر معالج قبل إرسال حزمة IP.
يبدأ المحلل في عرض الرسائل المتوقعة:
* 2020/01/03 14:55:44 - bitrate_monitor: 2020/01/03 14:55:44, TS bitrate: 9,970,016 bits/s * 2020/01/03 14:55:45 - bitrate_monitor: 2020/01/03 14:55:45, TS bitrate: 10,022,656 bits/s * 2020/01/03 14:55:46 - bitrate_monitor: 2020/01/03 14:55:46, TS bitrate: 9,980,544 bits/s
أضف الآن بعض القطرات:
ip netns exec P iptables -I INPUT -d 239.0.0.1 -m statistic --mode random --probability 0.001 -j DROP
ورسائل مثل هذه تظهر:
* 2020/01/03 14:57:11 - continuity: packet index: 80,745, PID: 0x0000, missing 7 packets * 2020/01/03 14:57:11 - continuity: packet index: 83,342, PID: 0x0000, missing 7 packets
ما هو متوقع قم بتعطيل فقد الحزمة (ip netns exec P iptables -F) وحاول زيادة معدل البت للمولد إلى 100 ميجابت في الثانية. يبلغ المحلل عن مجموعة من أخطاء CC وحوالي 75 ميجابت / ثانية بدلاً من 100. نحاول معرفة من يقع اللوم - المولد ليس لديه وقت أو المشكلة ليست في ذلك ، لذلك نبدأ في توليد عدد ثابت من الحزم (700000 حزمة TS = 100000 حزمة IP):
# ifconfig veth0 | grep TX TX packets 151825460 bytes 205725459268 (191.5 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 # tsp -I craft -c 700000 -P regulate -b 100000000 -P count -O ip -p 7 -e --local-port 6000 239.0.0.1:1234 * count: PID 0 (0x0000): 700,000 packets # ifconfig veth0 | grep TX TX packets 151925460 bytes 205861259268 (191.7 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
كما ترون ، تم إنشاء 100000 حزمة IP بالضبط (151925460-151825460). لذلك نحن نفهم ما يحدث مع المحلل ، لذلك نتحقق من عداد RX على veth1 ، فهو يساوي تمامًا عداد TX في veth0 ، ثم ننظر إلى ما يحدث على مستوى المقبس:
# ip netns exec P cat /proc/net/udp sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops 133: 010000EF:04D2 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 72338 2 00000000e0a441df 24355
هنا يمكنك أن ترى عدد قطرات = 24355. في حزم TS هو 170485 أو 24.36 ٪ من 700000 ، لذلك نرى أن 25 ٪ جدا من معدل البت المفقودة هي قطرات في المقبس udp. تحدث حالات السقوط في مقبس UDP عادة بسبب نقص المخزن المؤقت ، انظر إلى حجم المخزن المؤقت للمأخذ الافتراضي والحد الأقصى لحجم المخزن المؤقت للمقبس:
# sysctl net.core.rmem_default net.core.rmem_default = 212992 # sysctl net.core.rmem_max net.core.rmem_max = 212992
وبالتالي ، إذا لم تطلب التطبيقات بشكل صريح حجم المخزن المؤقت ، يتم إنشاء مآخذ مع وجود مخزن مؤقت يبلغ 208 كيلو بايت ، ولكن إذا طلبوا المزيد ، فلن يتلقوا ما هو مطلوب. نظرًا لأنه في tsp ، يمكنك تعيين حجم المخزن المؤقت (- حجم المخزن المؤقت) لإدخال IP ، لن نلمس حجم المقبس افتراضيًا ، لقد قمنا فقط بتعيين الحد الأقصى لحجم المخزن المؤقت للمقبس وتحديد حجم المخزن المؤقت بشكل صريح عبر وسائط tsp:
sysctl net.core.rmem_max=8388608 ip netns exec P tsp --realtime -t -I ip 239.0.0.1:1234 -b 8388608 -P continuity -P bitrate_monitor -p 1 -t 1 -O drop
مع هذا توليف المخزن المؤقت للمقبس ، يبلغ معدل البت المبلَّغ عنه الآن حوالي 100 ميجابت / ثانية ، ولا توجد أخطاء CC.
حسب استهلاك وحدة المعالجة المركزية من خلال تطبيق ملعقة شاي نفسها. بالنسبة إلى مركز واحد من وحدة المعالجة المركزية i5-4260U @ 1.40 جيجاهرتز ، يتطلب تحليل تيار 10 ميجابت / ثانية 3 إلى 4٪ من وحدة المعالجة المركزية ، و 100 ميجابت / ثانية - 25٪ ، و 200 ميجابت / ثانية - 46٪. عند ضبط٪ packet ، لا يزداد الحمل على وحدة المعالجة المركزية عمليًا (ولكن يمكن أن ينقص).
على الأجهزة الأكثر إنتاجية ، كان من الممكن توليد وتحليل تدفقات أكثر من 1 جيجابت / ثانية دون مشاكل.
اختبار على بطاقات الشبكة الحقيقية
بعد الاختبار على زوج veth ، تحتاج إلى أخذ مضيفين أو منفذي مضيف واحد ، وتوصيل المنافذ ببعضها البعض ، وتشغيل المولد على واحد ، والمحلل في الثانية. لم تكن هناك مفاجآت ، ولكن في الواقع ، كل هذا يتوقف على الحديد ، وكلما كان الأمر أضعف.
استخدام البيانات المستلمة بواسطة نظام المراقبة (Zabbix)
لا يحتوي Tsp على أي واجهة برمجة تطبيقات قابلة للقراءة على الآلة مثل SNMP أو ما شابه. يجب تجميع رسائل CC بمقدار ثانية واحدة على الأقل (مع وجود نسبة عالية من فقد الحزمة ، قد يكون هناك مئات / آلاف / عشرات الآلاف في الثانية ، اعتمادًا على معدل البت).
وبالتالي ، من أجل حفظ المعلومات ورسم الرسوم البيانية لأخطاء CC ومعدل البت وجعل نوع من الحوادث ، قد تكون الخيارات التالية أكثر:
- تحليل وتجميع (حسب CC) إخراج ملعقة شاي ، أي تحويلها إلى الشكل المطلوب.
- أضف ملعقة شاي و / أو إضافات المعالج bitrate_monitor والاستمرارية نفسها حتى يتم عرض النتيجة في شكل مقروء آليا ومناسب لنظام المراقبة.
- اكتب طلبك أعلى مكتبة tsduck.
من الواضح ، من وجهة نظر تكاليف العمالة ، الخيار 1 هو أبسط ، وخاصة بالنظر إلى أن tsduck نفسه مكتوب بلغة منخفضة المستوى (وفق المعايير الحديثة) (C ++)
أظهر نموذج أولي بسيط للمحلل + aggregator على bash أنه على تيار 10Mbit / s وفقدان الحزمة بنسبة 50٪ (أسوأ الحالات) ، استهلكت عملية bash وحدة المعالجة المركزية 3-4 مرات أكثر من عملية tsp نفسها. هذا السيناريو غير مقبول. في الواقع قطعة من هذا النموذج الأولي أدناه
إلى جانب حقيقة أنه يعمل ببطء غير مقبول ، لا توجد مؤشرات ترابط عادية في bash ، وظائف bash هي عمليات مستقلة ، واضطررت إلى تسجيل قيمة Packets المفقودة على الآثار الجانبية مرة واحدة في الثانية (عندما أتلقى رسائل معدل البت التي تأتي كل ثانية). نتيجة لذلك ، تم ترك bash بمفرده وتقرر كتابة غلاف (محلل + مجمع) في golang. استهلاك وحدة المعالجة المركزية لرمز جولانج مماثل هو 4-5 مرات أقل من عملية ملعقة شاي نفسها. تبين أن تسريع المجمع عن طريق استبدال bash بـ golang كان حوالي 16 مرة وكانت النتيجة مقبولة بشكل عام (النفقات العامة على وحدة المعالجة المركزية بنسبة 25 ٪ في أسوأ الحالات). الملف المصدر على golang هنا .
التفاف المجمع
لتشغيل المجمع ، تم إنشاء أبسط قالب خدمة لـ systemd ( هنا ). من المفترض أن يتم تجميع المجمّع نفسه في ملف ثنائي (go build tsduck-stat.go) ، الموجود في / opt / tsduck-stat /. من المفترض أن يتم استخدام golang مع دعم لساعة رتابة (> = 1.9).
لإنشاء مثيل للخدمة ، تحتاج إلى تشغيل الأمر systemctl - تمكين tsduck-stat@239.0.0.1: 1234 ، ثم البدء في استخدام systemctl start tsduck-stat@239.0.0.1: 1234.
اكتشاف زابيكس
من أجل أن تتمكن zabbix من اكتشاف الخدمات قيد التشغيل ، تم إنشاء مولد قائمة مجموعة (discovery.sh) ، بالتنسيق الضروري لاكتشاف Zabbix ، من المفترض أنه موجود هناك - في / opt / tsduck-stat. لبدء الاكتشاف عبر وكيل zabbix ، تحتاج إلى إضافة ملف .conf إلى الدليل مع تكوينات وكيل zabbix لإضافة معلمة المستخدم.
قالب Zabbix
يحتوي القالب الذي تم إنشاؤه (tsduck_stat_template.xml) على قاعدة الاكتشاف التلقائي والنماذج الأولية لعناصر البيانات والرسومات والمشغلات.
قائمة مراجعة قصيرة (حسناً ، ماذا لو قرر شخص ما استخدامه)
- تأكد من أن ملعقة شاي لا تسقط الحزم في الظروف "المثالية" (المولد والمحلل متصلان مباشرة) ، إذا كانت هناك قطرات ، راجع القسم 2 أو نص المقال حول هذا الموضوع.
- قم بضبط المخزن المؤقت أقصى مأخذ التوصيل (net.core.rmem_max = 8388608).
- ترجمة tsduck-stat.go (go build tsduck-stat.go).
- ضع قالب الخدمة في / lib / systemd / system.
- ابدأ تشغيل الخدمات باستخدام systemctl ، وتحقق من أن العدادات بدأت تظهر (grep "" / dev / shm / tsduck-stat / *). عدد الخدمات حسب عدد تدفقات الإرسال المتعدد. قد تحتاج هنا إلى إنشاء مسار إلى مجموعة البث المتعدد ، أو ربما إيقاف تشغيل rp_filter أو إنشاء مسار إلى مصدر ip.
- تشغيل discovery.sh ، تأكد من أنه يولد json.
- إرفاق تكوين وكيل zabbix ، أعد تشغيل وكيل zabbix.
- قم بتنزيل القالب على zabbix ، وقم بتطبيقه على المضيف الذي تتم مراقبته وتثبيته على zabbix-agent ، انتظر حوالي 5 دقائق ، وشاهد ظهور عناصر بيانات جديدة ورسوم بيانية ومشغلات.
يؤدي
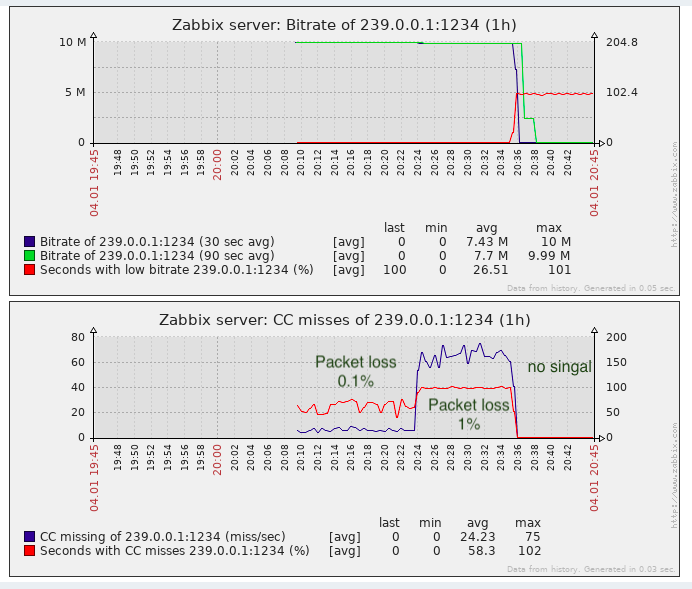
تكفي مهمة اكتشاف فقد الحزمة ، على الأقل فهي أفضل من عدم وجود مراقبة.
في الواقع ، يمكن أن تحدث "خسائر" CC- عند لصق مقاطع الفيديو (على حد علمي ، تتم عمليات الإدراج في مراكز الاتصالات المحلية في الاتحاد الروسي ، أي دون حساب عداد CC) ، يجب تذكر ذلك. في الحلول المسجلة الملكية ، يتم تجاوز هذه المشكلة جزئيًا عن طريق الكشف عن علامات SCTE-35 (إذا تمت إضافتها بواسطة مولد الدفق).
UPD: إضافة دعم للعلامات SCTE-35 إلى القالب والجمع zabbix
من وجهة نظر مراقبة جودة النقل ، ليس هناك ما يكفي من غضب المراقبة (IAT) ، لأن تحتوي تجهيزات التلفزيون (سواء كانت أدوات التعديل أو الأجهزة الطرفية) على متطلبات لهذه المعلمة وليس من الممكن دائمًا تضخيم jitbuffer إلى ما لا نهاية. ويمكن أن تطفو الاهتزازات عند استخدام المعدات ذات المخازن المؤقتة الكبيرة في عملية النقل ولم يتم تكوين جودة الخدمة أو لم تتم تهيئتها جيدًا لنقل مثل هذه الحركة الفعلية.