يرجع تعقيد تفسير البيانات الزلزالية إلى حقيقة أنه لكل مهمة من الضروري البحث عن نهج فردي ، لأن كل مجموعة من هذه البيانات فريدة من نوعها. تتطلب المعالجة اليدوية تكاليف عمالة كبيرة ، وغالبًا ما تحتوي النتيجة على أخطاء متعلقة بالعامل البشري. يمكن أن يؤدي استخدام الشبكات العصبية للتفسير إلى تقليل العمل اليدوي بشكل كبير ، ولكن تفرد البيانات يفرض قيودًا على أتمتة هذا العمل.
توضح هذه المقالة تجربة لتحليل إمكانية تطبيق الشبكات العصبية لأتمتة تخصيص الطبقات الجيولوجية في الصور ثنائية الأبعاد باستخدام بيانات ذات علامات كاملة من بحر الشمال كمثال.
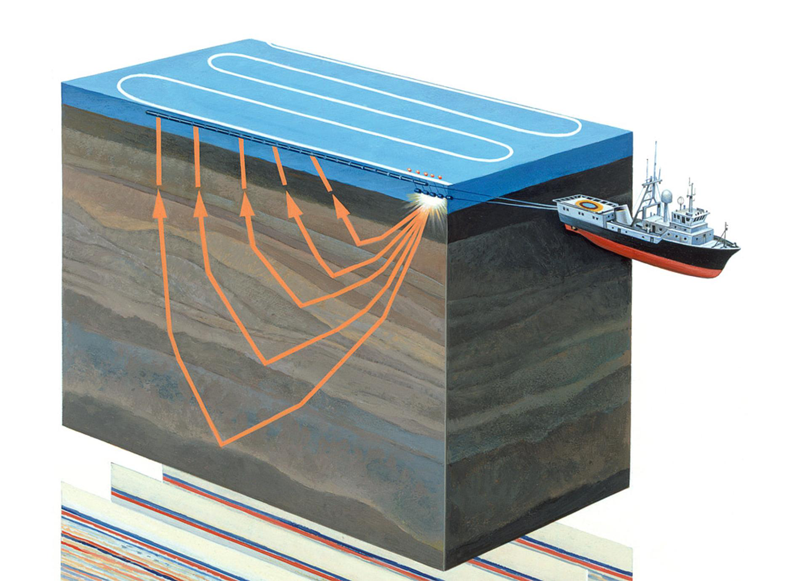
الشكل 1. المسوحات الزلزالية المائية (
المصدر )
قليلا عن الموضوع
الاستكشاف الزلزالي هو طريقة جيوفيزيائية لدراسة الكائنات الجيولوجية باستخدام الاهتزازات المرنة - الموجات الزلزالية. تعتمد هذه الطريقة على حقيقة أن سرعة انتشار الموجات الزلزالية تعتمد على خصائص البيئة الجيولوجية التي تنتشر فيها (تكوين الصخور ، المسامية ، الكسر ، تشبع الرطوبة ، وما إلى ذلك). المرور عبر طبقات جيولوجية بخصائص مختلفة ، تنعكس الموجات الزلزالية من كائنات مختلفة وعاد إلى المتلقي (انظر الشكل 1). يتم تسجيل طبيعتها وبعد أن تسمح لك المعالجة بتكوين صورة ثنائية الأبعاد - قسم زلزالي أو صفيف بيانات ثلاثي الأبعاد - مكعب زلزالي.
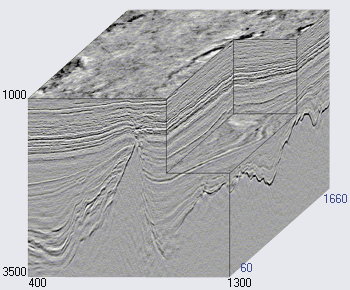
الشكل 2. مثال على المكعب الزلزالي (
المصدر )
يوجد المحور الأفقي للمكعب الزلزالي على طول سطح الأرض ، ويمثل العمودي العمق أو الوقت (انظر الشكل 2). في بعض الحالات ، يتم تقسيم المكعب إلى أقسام رأسية على طول محور الجيوفون (ما يسمى الخطوط المضمنة أو الخطوط الداخلية) أو عبر (الخطوط المتقاطعة ، الخطوط المتقاطعة ، xlines). كل مكعب عمودي (وشريحة) هو أثر زلزالي منفصل.
وبالتالي ، تتكون الخطوط والخطوط المتقاطعة من نفس مسارات الزلازل ، فقط بترتيب مختلف. تتشابه مسارات الزلازل المجاورة مع بعضها البعض. يحدث تغيير أكثر دراماتيكية في نقاط الخلل ، ولكن لا يزال هناك تشابه. هذا يعني أن الشرائح المجاورة تشبه بعضها بعضًا.
كل هذه المعرفة ستكون مفيدة لنا عند التخطيط للتجارب.
مهمة التفسير ودور الشبكات العصبية في حلها
تتم معالجة البيانات التي تم الحصول عليها يدويا من قبل المترجمين الشفويين الذين يحددون مباشرة على المكعب أو في كل شريحة طبقاتها الجيولوجية الفردية من الصخور وحدودها (آفاق ، آفاق) ، رواسب الملح ، والأخطاء وغيرها من الميزات للبنية الجيولوجية لمنطقة الدراسة. يبدأ المترجم الشفهي ، الذي يعمل بمكعب أو شريحة ، عمله مع التحديد اليدوي المضني للطبقات الجيولوجية والآفاق. يجب أن يكون كل أفق مكتوبًا يدويًا (من مجموعة "الالتقاط" باللغة الإنجليزية) عن طريق توجيه المؤشر والنقر فوق الماوس.
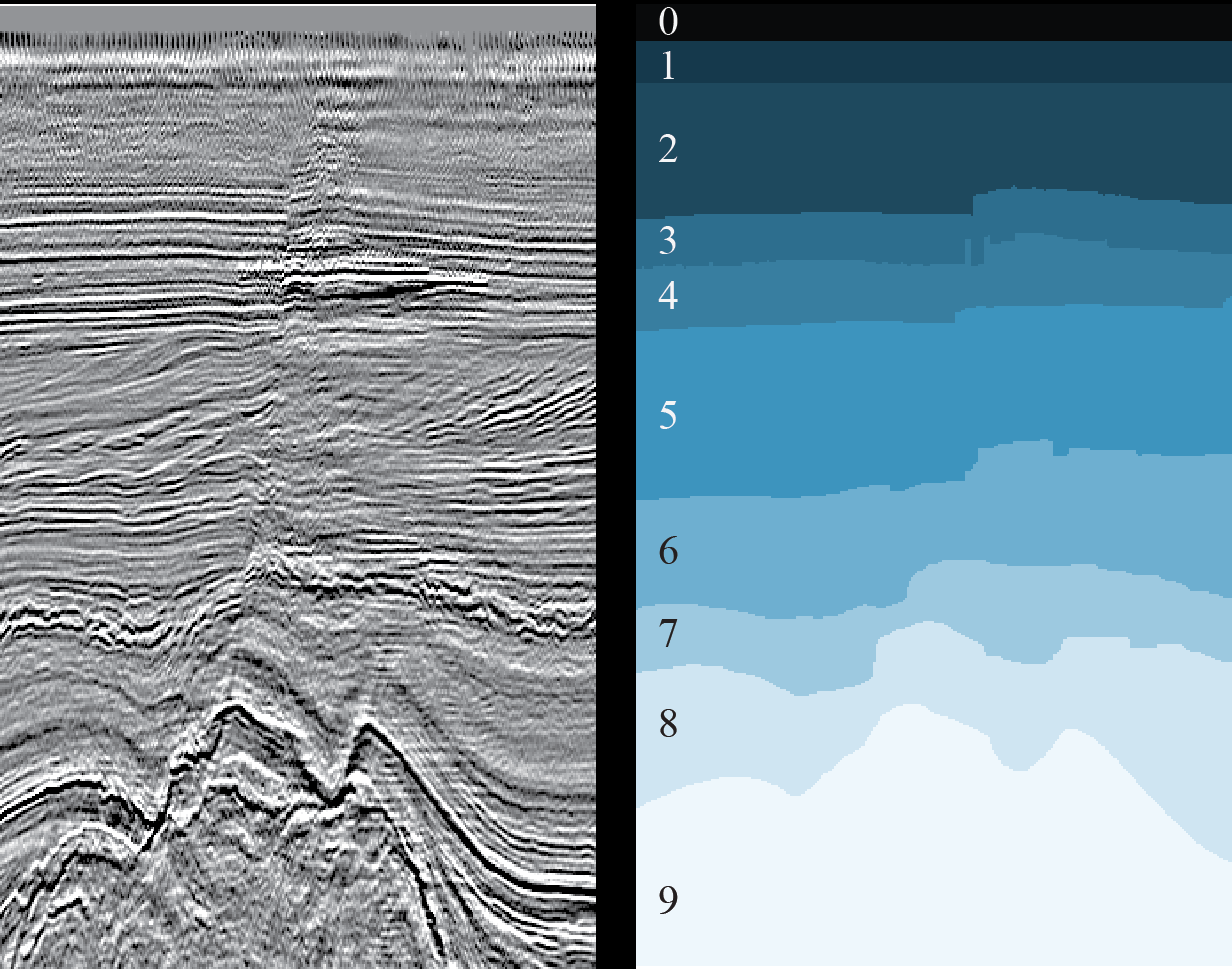
الشكل 3. مثال على شريحة ثنائية الأبعاد (يسار) ونتيجة لوضع علامات على الطبقات الجيولوجية المقابلة (يمين) (
مصدر )
ترتبط المشكلة الرئيسية بالزيادة في حجم البيانات السيزمية التي يتم الحصول عليها كل عام في ظل ظروف جيولوجية متزايدة التعقيد (على سبيل المثال ، الأجزاء تحت الماء ذات أعماق كبيرة من البحر) ، والغموض في تفسير هذه البيانات. بالإضافة إلى ذلك ، في ظل ظروف المواعيد النهائية الضيقة و / أو الكميات الكبيرة ، فإن المترجم الشفهي يخطئ حتماً في أخطاء ، على سبيل المثال ، يخطئ العديد من الميزات في القسم الجيولوجي.
يمكن حل هذه المشكلة جزئيًا بمساعدة الشبكات العصبية ، مما يقلل بشكل كبير من العمل اليدوي ، وبالتالي تسريع عملية التفسير وتقليل عدد الأخطاء. لتشغيل الشبكة العصبية ، هناك حاجة إلى عدد معين من الأقسام الجاهزة والمُسمى عليها (أقسام المكعب) ، ونتيجة لذلك سيتم الحصول على وضع علامة كاملة لجميع الأقسام (أو المكعب بأكمله) ، الأمر الذي سيتطلب بشكل مثالي تحسينًا بسيطًا فقط من قبل شخص لضبط أقسام معينة من الآفاق أو إعادة تحديد المساحات الصغيرة التي تعذر على الشبكة التعرف بشكل صحيح.
هناك العديد من الحلول لمشاكل التفسير باستخدام الشبكات العصبية ، فيما يلي بعض الأمثلة فقط:
واحد ،
اثنان ،
ثلاثة . تكمن الصعوبة في حقيقة أن كل مجموعة من البيانات فريدة من نوعها - بسبب خصوصيات الصخور الجيولوجية للمنطقة المدروسة ، بسبب الوسائل التقنية المختلفة وأساليب الاستكشاف الزلزالي ، بسبب الأساليب المختلفة المستخدمة لتحويل البيانات الخام إلى أخرى جاهزة. حتى بسبب الضوضاء الخارجية (على سبيل المثال ، نباح الكلاب والأصوات العالية الأخرى) ، التي لا يمكن إزالتها دائمًا بشكل كامل. لذلك ، يجب حل كل مهمة على حدة.
لكن على الرغم من ذلك ، فإن العديد من الأعمال تجعل من الممكن التلمس للحصول على مناهج عامة منفصلة لحل مختلف مشاكل التفسير.
نحن في
MaritimeAI (مشروع تم تطويره من مجتمع التعلم الآلي للسلع الاجتماعية
ODS ،
مقال عنا ) لكل منطقة من مجالات اهتماماتنا (البحث البحري) ندرس الأعمال المنشورة وإجراء تجاربنا الخاصة ، مما يتيح لنا توضيح حدود وميزات تطبيق بعض الحلول ، وأحيانا تجد النهج الخاصة بك.
نتائج تجربة واحدة وصفناها في هذه المقالة.
أهداف البحوث التجارية
يكفي أن يقوم أخصائي علوم البيانات بإلقاء نظرة على الشكل 3 لتنفس الصعداء - وهي مهمة شائعة لتجزئة الصور الدلالية ، والتي تم اختراع العديد من هياكل الشبكات العصبية وأساليب التدريس الخاصة بها. تحتاج فقط إلى اختيار المناسب وتدريب الشبكة.
لكن ليس بهذه البساطة.
للحصول على نتيجة جيدة بمساعدة شبكة عصبية ، فأنت بحاجة إلى أكبر قدر ممكن من البيانات المحددة بالفعل والتي ستتعلم عليها. لكن مهمتنا هي بالتحديد تقليل كمية العمل اليدوي. ونادراً ما يكون من الممكن استخدام البيانات الموسومة من مناطق أخرى بسبب اختلافاتها القوية في التركيب الجيولوجي.
نحن نترجم أعلاه إلى لغة العمل.
لكي يكون استخدام الشبكات العصبية مبررًا اقتصاديًا ، من الضروري تقليل مقدار التفسير اليدوي الأساسي وتحسين النتائج التي تم الحصول عليها. لكن تقليل البيانات الخاصة بتدريب الشبكة سيؤثر سلبًا على جودة نتائجها. فهل يمكن لشبكة عصبية تسريع وتيسير عمل المترجمين الفوريين وتحسين جودة الصور المصنفة؟ أو مجرد تعقيد العملية المعتادة؟
الهدف من هذه الدراسة هو محاولة لتحديد الحجم الأدنى الكافي لبيانات المكعب الزلزالي المرمزة لشبكة عصبية وتقييم النتائج التي تم الحصول عليها. حاولنا العثور على إجابات للأسئلة التالية ، والتي من شأنها أن تساعد "مالكي" نتائج المسح الزلزالي في اتخاذ قرار بشأن التفسير اليدوي أو الآلي جزئيًا:
- ما مقدار البيانات التي يحتاج الخبراء إلى ترميزها لتدريب شبكة عصبية؟ وما هي البيانات التي ينبغي اختيارها لهذا؟
- ماذا يحدث في مثل هذا الناتج؟ هل ستحتاج التنقيح اليدوي لتوقعات الشبكة العصبية؟ إذا كان الأمر كذلك ، كيف معقدة وضخمة؟
وصف عام للتجربة والبيانات المستخدمة
للتجربة ، اخترنا واحدة من مشاكل التفسير ، وهي مهمة عزل الطبقات الجيولوجية على أقسام ثنائية الأبعاد من مكعب زلزالي (انظر الشكل 3). لقد حاولنا بالفعل حل هذه المشكلة (انظر
هنا ) ، ووفقًا للمؤلفين ، حصلنا على نتيجة جيدة لـ 1٪ من الشرائح التي تم اختيارها عشوائيًا. بالنظر إلى حجم المكعب ، فهذه 16 صورة. ومع ذلك ، لا تقدم المقالة مقاييس للمقارنة ولا يوجد وصف لمنهجية التدريب (دالة الفقد ، محسن ، مخطط لتغيير سرعة التعلم ، إلخ) ، مما يجعل التجربة غير قابلة للإنتاج.
بالإضافة إلى ذلك ، النتائج المقدمة هناك ، في رأينا ، غير كافية للحصول على إجابات كاملة عن الأسئلة المطروحة. هل هذه القيمة هي الأمثل عند 1٪؟ أو ربما لعينة أخرى من شرائح سيكون مختلفا؟ هل يمكنني اختيار بيانات أقل؟ هل يستحق أخذ المزيد؟ كيف ستتغير النتيجة؟ إلخ
للتجربة ، أخذنا نفس مجموعة البيانات التي تحمل علامات كاملة من القطاع الهولندي في بحر الشمال. تتوفر البيانات السيزمية المصدر على موقع الويب Open Seosic Repository:
Project Netherlands Offshore F3 Block . يمكن العثور على وصف موجز في
Silva et al. "مجموعة بيانات هولندا: مجموعة بيانات عامة جديدة للتعلم الآلي في التفسير الزلزالي .
"نظرًا لأننا في حالتنا نتحدث عن شرائح ثنائية الأبعاد ، فإننا لم نستخدم المكعب ثلاثي الأبعاد الأصلي ، ولكننا استخدمنا بالفعل "التقطيع" المتوفر بالفعل ، وهو:
Netherlands F3 Interpretation Dataset .
أثناء التجربة ، حللنا المهام التالية:
- نظرنا إلى البيانات المصدر وحددنا الشرائح التي هي الأقرب من حيث الجودة إلى وضع علامات يدوية.
- سجلنا بنية الشبكة العصبية ، ومنهجية ومعلمات التدريب ، ومبدأ اختيار الشرائح للتدريب والتحقق من صحتها.
- قمنا بتدريب 20 شبكة عصبية متطابقة على وحدات تخزين بيانات مختلفة من نفس النوع من الشرائح لمقارنة النتائج.
- قمنا بتدريب 20 شبكة عصبية أخرى على كمية مختلفة من البيانات من أنواع مختلفة من الشرائح لمقارنة النتائج.
- يقدر مقدار التنقيح اليدوي اللازم لنتائج التنبؤ.
نتائج التجربة في شكل مقاييس مقدرة والمتوقعة من قبل شبكة شرائح القناع معروضة أدناه.
المهمة 1. اختيار البيانات
لذلك ، كبيانات أولية ، استخدمنا الخطوط المتداخلة والخطوط العريضة للمكعب الزلزالي من القطاع الهولندي في بحر الشمال. أظهر تحليل مفصل أن كل شيء لا يسير بسلاسة - فهناك العديد من الصور والأقنعة مع المصنوعات اليدوية وحتى تلك المشوهة بشدة (انظر الشكلين 4 و 5).

الشكل 4. مثال قناع مع التحف
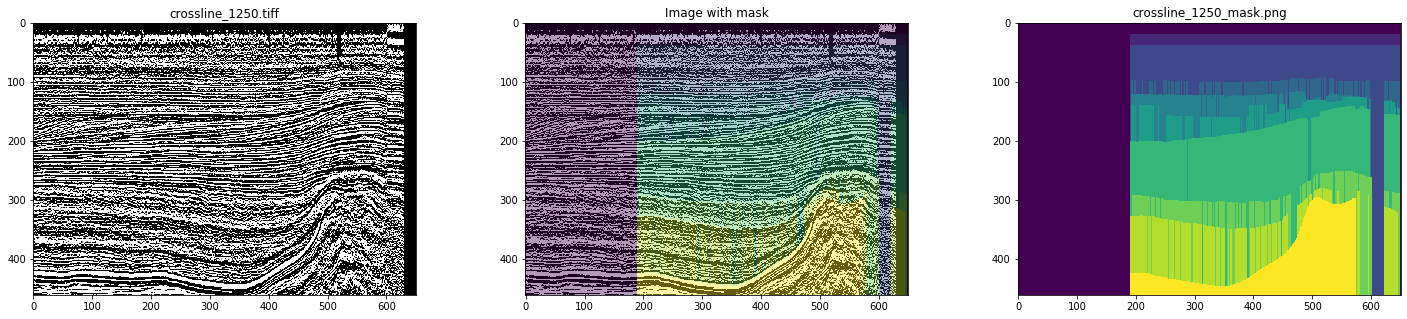
الشكل 5. مثال على قناع مشوه
مع وضع علامات يدوية ، سيتم ملاحظة أي شيء من هذا القبيل. لذلك ، لمحاكاة عمل المترجم الفوري ، لتدريب الشبكة ، اخترنا فقط الأقنعة النظيفة ، بعد أن نظرنا إلى جميع الشرائح. نتيجة لذلك ، تم اختيار 700 خط عرض و 400 خط داخلي.
المهمة 2. إصلاح معالم التجربة
هذا القسم مهم ، أولاً وقبل كل شيء ، للمتخصصين في علوم البيانات ، وبالتالي ، سيتم استخدام المصطلحات المناسبة.
نظرًا لأن الخطوط الداخلية والخطوط المتقاطعة تتكون من نفس الآثار الزلزالية ، فيمكن فرض فرضيتين متبادلتين:
- لا يمكن إجراء التدريب إلا على نوع واحد من الشرائح (على سبيل المثال ، مضمن) ، باستخدام صور من نوع آخر كاختيار مؤجل. هذا سيعطي تقييم أكثر ملاءمة للنتيجة ، لأن ستظل الشرائح المتبقية من نفس النوع التي تم استخدامها في التدريب مماثلة لتلك الموجودة في التدريب.
- من أجل التدريب ، من الأفضل استخدام مزيج من الشرائح من أنواع مختلفة ، لأن هذه زيادة جاهزة.
التحقق من ذلك.
بالإضافة إلى ذلك ، أدى تشابه الشرائح المجاورة من نفس النوع والرغبة في الحصول على نتيجة قابلة للتكرار إلى استراتيجية لاختيار شرائح للتدريب والتحقق من صحتها ، ليس من خلال مبدأ تعسفي ، ولكن بشكل موحد في جميع أنحاء المكعب ، أي بحيث تكون الشرائح متباعدة قدر الإمكان ، وبالتالي تغطي أقصى مجموعة متنوعة من البيانات.
للتحقق من الصحة ، تم استخدام 2 شرائح ، وزعت أيضا بالتساوي بين الصور المجاورة لعينة التدريب. على سبيل المثال ، بالنسبة لعينة تدريب مكونة من 3 خطوط مضمّنة ، تكونت عينة التحقق من الصحة من 4 خطوط مضمّنة ، و 3 خطوط مضمّنة و 3 خطوط عرضية ، مكونة من 8 شرائح ، على التوالي.
نتيجة لذلك ، أجرينا سلسلة من التدريبات:
- تدريب على عينات من الخطوط الداخلية من 3 إلى 20 شريحة موزعة بالتساوي على المكعب مع التحقق من نتيجة تنبؤات الشبكة على الخطوط المضمنة المتبقية وعلى جميع الخطوط المتقاطعة. بالإضافة إلى ذلك ، تم إجراء التدريب على 80 و 160 أقسام.
- تدريب على عينات مجمعة من خطوط مضمّنة وخطوط عرضية من 3 إلى 10 أقسام من كل نوع موزعة بشكل موحد على مكعب مع التحقق من نتائج تنبؤات الشبكة في الصور المتبقية. بالإضافة إلى ذلك ، تم إجراء التدريب على 40 + 40 و 80 + 80 أقسام.
مع هذا النهج ، من الضروري مراعاة أن أحجام عينات التدريب والتحقق من الصحة تختلف اختلافًا كبيرًا ، مما يجعل المقارنة صعبة ، لكن حجم الصور المتبقية لا يتم تقليله كثيرًا بحيث يمكن استخدامه لإجراء تقييم مناسب للتغيرات في النتيجة.
للحد من إعادة التدريب لعينة التدريب ، تم استخدام زيادة حجم المحصول التعسفي 448 × 64 وصورة معكوسة على طول المحور الرأسي مع احتمال 0.5.
نظرًا لأننا مهتمون بالاعتماد على جودة النتيجة فقط على عدد الشرائح في عينة التدريب ، يمكن إهمال المعالجة المسبقة للصور. استخدمنا طبقة واحدة من صور PNG دون أي تغييرات.
للسبب نفسه ، في إطار هذه التجربة ، ليست هناك حاجة للبحث عن أفضل بنية شبكة - الشيء الرئيسي هو أن تكون هي نفسها في كل خطوة. اخترنا UNet بسيطة ولكن راسخة لهذه المهام:

الشكل 6. هندسة الشبكة
تتألف وظيفة الخسارة من مزيج من معامل جاكار والإنتروبيا الثنائية:
def jaccard_loss(y_true, y_pred): smoothing = 1. intersection = tf.reduce_sum(y_true * y_pred, axis = (1, 2)) union = tf.reduce_sum(y_true + y_pred, axis = (1, 2)) jaccard = (intersection + smoothing) / (union - intersection + smoothing) return 1. - tf.reduce_mean(jaccard) def loss(y_true, y_pred): return 0.75 * jaccard_loss(y_true, y_pred) + 0.25 * keras.losses.binary_crossentropy(y_true, y_pred)
خيارات التعلم الأخرى:
keras.optimizers.SGD(lr = 0.01, momentum = 0.9, nesterov = True) keras.callbacks.EarlyStopping(monitor = 'val_loss', patience = 10), keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', patience = 5)
لتقليل تأثير العشوائية في اختيار الأوزان الأولية على النتائج ، تم تدريب الشبكة على 3 خطوط مضمنة لعصر واحد. بدأ كل التدريب الآخر بهذه الأوزان المستلمة.
تم تدريب كل شبكة على GeForce GTX 1060 6GB لمدة 30-60 فترة. استغرق التدريب من كل عصر 10-30 ثانية اعتمادا على حجم العينة.
المهمة 3. التدريب على نوع واحد من الشرائح (مضمنة)
تتألف السلسلة الأولى من 18 دورة تدريبية مستقلة على الشبكة في 3-20 مدمجة. وعلى الرغم من أننا مهتمون فقط بتقدير معامل Jacquard على الشرائح غير المستخدمة في التدريب والتحقق من الصحة ، فمن المثير للاهتمام مراعاة جميع الرسوم البيانية.
تذكر أن نتائج التفسير لكل شريحة عبارة عن 10 فصول (الطبقات الجيولوجية) ، والتي يتم تمييزها في الأشكال بأرقام من 0 إلى 9.

الشكل 7. معامل جاكار لمجموعة التدريب

الشكل 8. معامل جاكار لعينة التحقق من الصحة
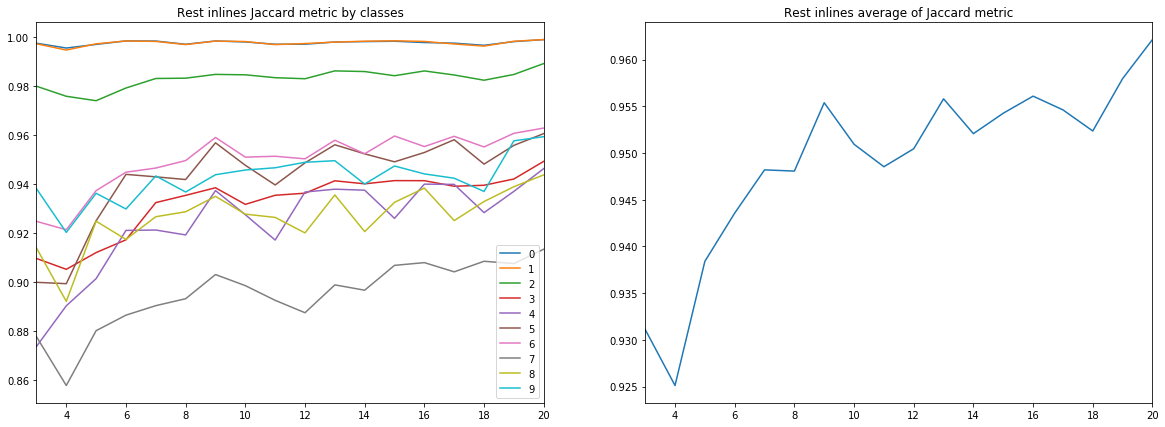
الشكل 9. معامل جاكار للالمضمنة المتبقية
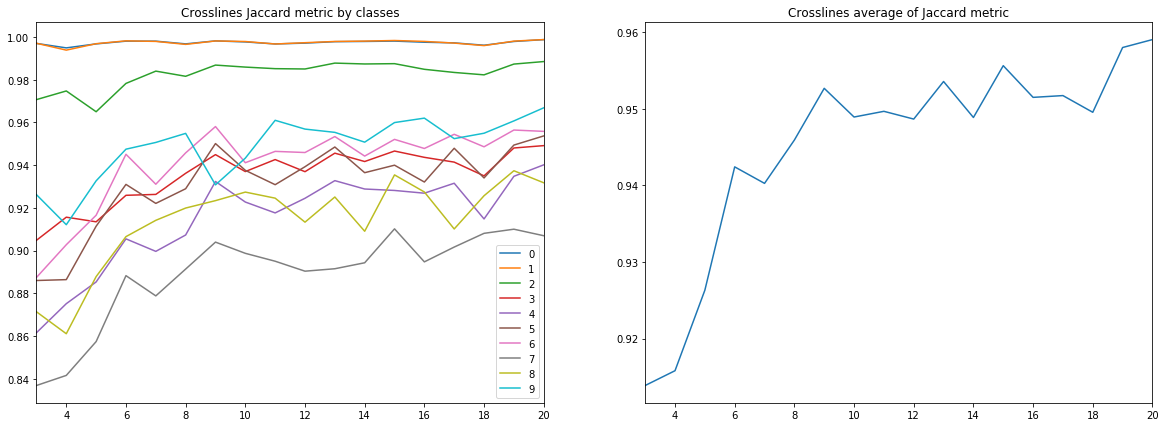
الشكل 10. معامل جاكار للخطوط المتقاطعة
يمكن استخلاص عدد من الاستنتاجات من المخططات أعلاه.
أولاً ، تصل الجودة المتوقعة ، المقاسة بمعامل Jacquard ، بالفعل عند 9 خطوط مضمنة ، إلى قيمة عالية للغاية ، وبعد ذلك تستمر في النمو ، ولكن ليس بشكل مكثف. أي تأكيد فرضية كفاية عدد صغير من الصور المصنفة لتدريب شبكة عصبية.
ثانياً ، تم الحصول على نتيجة عالية جدًا للخطوط المتقاطعة ، على الرغم من حقيقة أنه تم استخدام الخطوط المضمنة فقط للتدريب والتحقق من الصحة - تم تأكيد فرضية كفاية نوع واحد فقط من الشرائح. ومع ذلك ، للنتيجة النهائية ، تحتاج إلى مقارنة النتائج مع التدريب على مزيج من الخطوط المتقاطعة والخطوط المتقاطعة.
ثالثًا ، مقاييس الطبقات المختلفة ، أي نوعية الاعتراف بهم مختلفة جدا. يؤدي ذلك إلى فكرة اختيار استراتيجية تعليمية مختلفة ، على سبيل المثال ، استخدام الأوزان أو الشبكات الإضافية للصفوف الضعيفة ، أو مخطط "واحد مقابل الكل" الكامل.
وأخيرًا ، تجدر الإشارة إلى أن معامل Jacquard لا يمكنه إعطاء وصف كامل لجودة النتيجة. من أجل تقييم تنبؤات الشبكة في هذه الحالة ، من الأفضل النظر إلى الأقنعة نفسها لتقييم مدى ملاءمتها للمراجعة بواسطة المترجم الفوري.
توضح الأشكال التالية العلامات بواسطة شبكة تم تدريبها على 10 خطوط مضمنة. يمثل العمود الثاني ، الذي يحمل علامة "قناع GT" (قناع الحقيقة الأرضية) ، التفسير المستهدف ، والثالث هو التنبؤ بالشبكة العصبية.


الشكل 11. أمثلة لتوقعات الشبكة للخطوط المضمنة
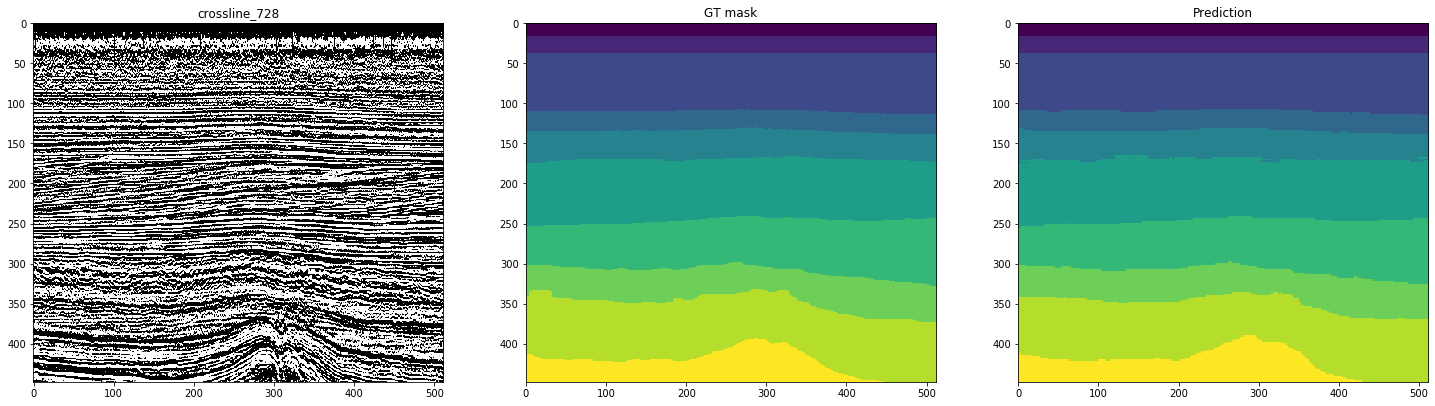

الشكل 12. أمثلة لتوقعات الشبكة للخطوط المتقاطعة
يمكن ملاحظة ذلك من خلال الأشكال التي ، إلى جانب الأقنعة النظيفة إلى حد ما ، يصعب على الشبكة التعرف على الحالات المعقدة حتى على الخطوط الداخلية نفسها. وبالتالي ، على الرغم من القياس العالي الكافي لـ 10 شرائح ، فإن جزءًا من النتائج سيتطلب تحسينًا كبيرًا.
تتقلب أحجام العينات التي نظرنا فيها حوالي 1٪ من إجمالي حجم البيانات - وهذا يجعل من الممكن بالفعل تمييز جزء من الشرائح المتبقية جيدًا. هل يجب علي زيادة عدد الأقسام المميزة في البداية؟ هل سيعطي ذلك زيادة مماثلة في الجودة؟
دعنا نتأمل ديناميكيات التغييرات في النتائج المتوقعة من خلال الشبكات المدربة على 5 و 10 و 15 و 20 و 80 (5٪ من إجمالي حجم المكعب) و 160 (10٪) في السطور باستخدام نفس الأقسام كمثال.
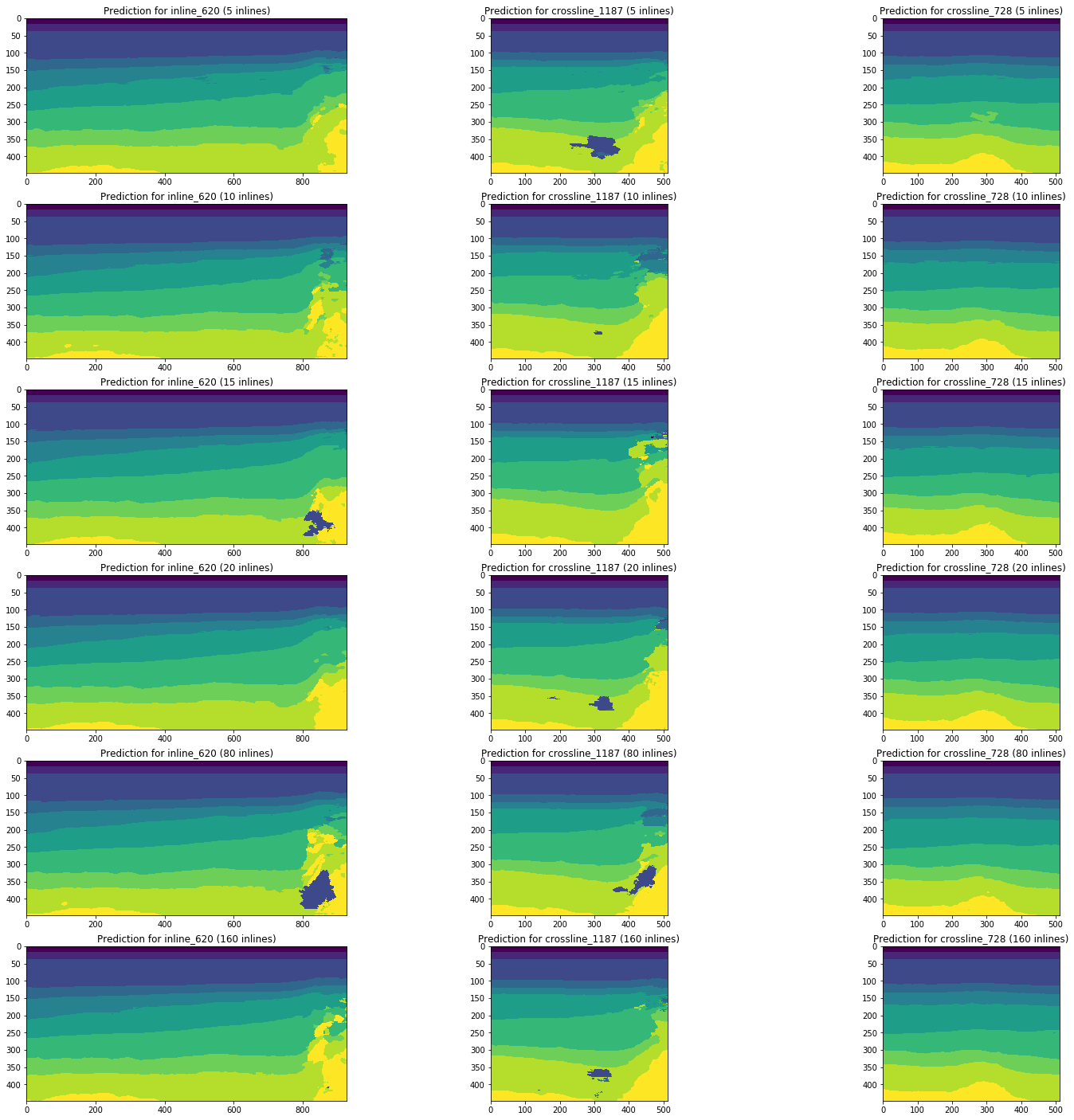
الشكل 13. أمثلة لتوقعات الشبكات المدربة على مجلدات مختلفة من عينة التدريب
يوضح الشكل 13 أن زيادة حجم عينة التدريب بمقدار 5 أو حتى 10 مرات لا يؤدي إلى تحسن كبير. الشرائح المعترف بها جيدًا في 10 صور تدريب لا تزداد سوءًا.
وبالتالي ، حتى شبكة بسيطة بدون ضبط ومعالجة مسبقة للصور تكون قادرة على ترجمة جزء من الشرائح بجودة عالية بما فيه الكفاية مع عدد صغير من الصور المميزة يدويًا. سننظر في مسألة حصة هذه التفسيرات وتعقيد وضع اللمسات الأخيرة على شرائح سيئة الاعتراف.
الاختيار الدقيق للهندسة المعمارية ، معلمات الشبكة والتدريب ، يمكن للصور قبل المعالجة تحسين هذه النتائج على نفس الحجم من البيانات الموسومة. ولكن هذا بالفعل خارج نطاق التجربة الحالية.
المهمة 4. التدريب على أنواع مختلفة من الشرائح (مضمنة وخطوط عرضية)
الآن دعونا نقارن نتائج هذه السلسلة مع التوقعات التي تم الحصول عليها عن طريق التدريب على مزيج من الخطوط المتقاطعة والخطوط المتقاطعة.
توضح المخططات أدناه تقديرات لمعامل جاكار للعينات المختلفة ، بما في ذلك مقارنة بنتائج السلسلة السابقة. للمقارنة (انظر المخططات الصحيحة في الأشكال) ، لم يتم أخذ سوى عينات من نفس الحجم ، أي 10 خطوط مضمّنة مقابل 5 خطوط مضمّنة + 5 خطوط متداخلة ، إلخ

الشكل 14. معامل جاكار لمجموعة التدريب

الشكل 15. معامل جاكار لعينة التحقق من الصحة

الشكل 16. معامل جاكار للالمضمنة المتبقية

الشكل 17. معامل جاكار للخطوط المتقاطعة المتبقية
توضح الرسوم البيانية بوضوح أن إضافة شرائح من نوع مختلف لا يؤدي إلى تحسين النتائج. حتى في سياق الفئات (انظر الشكل 18) ، لا يتم ملاحظة تأثير الخطوط المتقاطعة لأي من أحجام العينات التي تم أخذها في الاعتبار.

الشكل 18. معامل جاكار لفئات مختلفة (على طول المحور X) وأحجام مختلفة وتكوين عينة التدريب
لإكمال الصورة ، نقوم بمقارنة نتائج توقعات الشبكة على الشرائح نفسها:
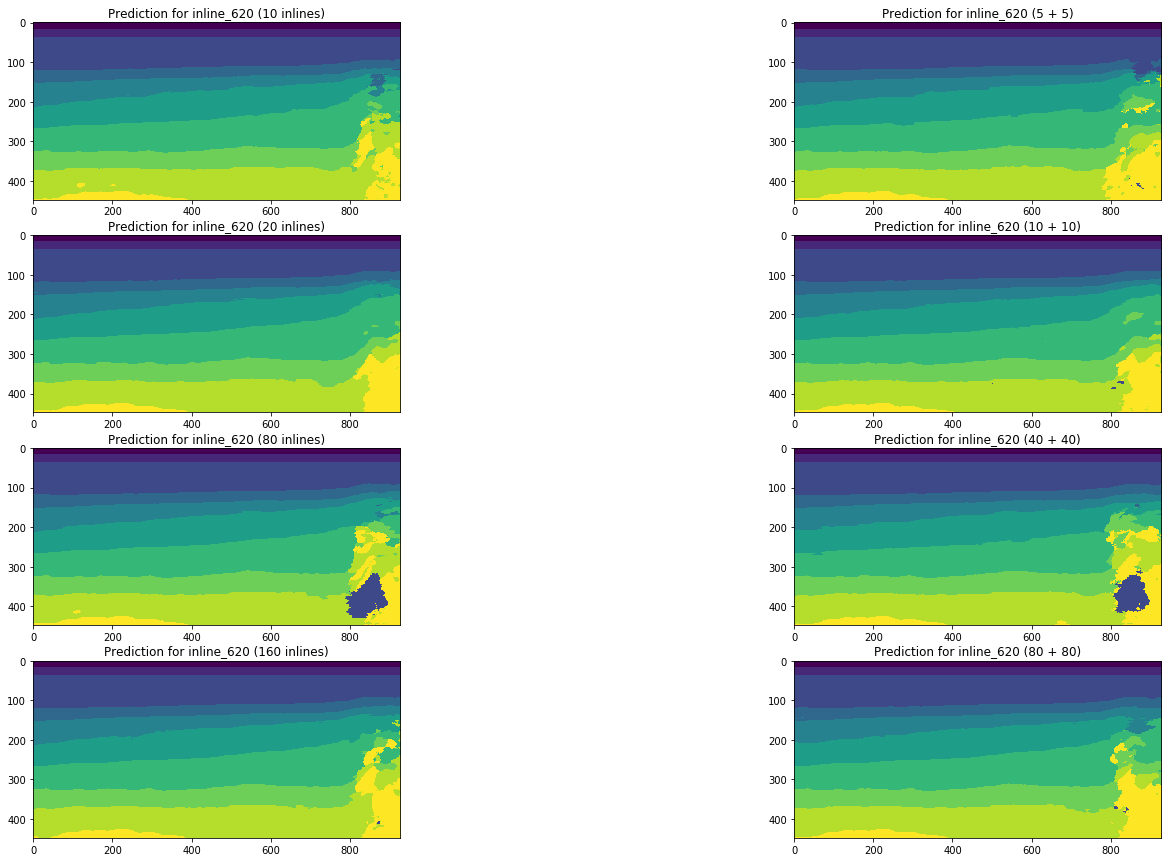
الشكل 19. مقارنة توقعات الشبكة للمضمنة
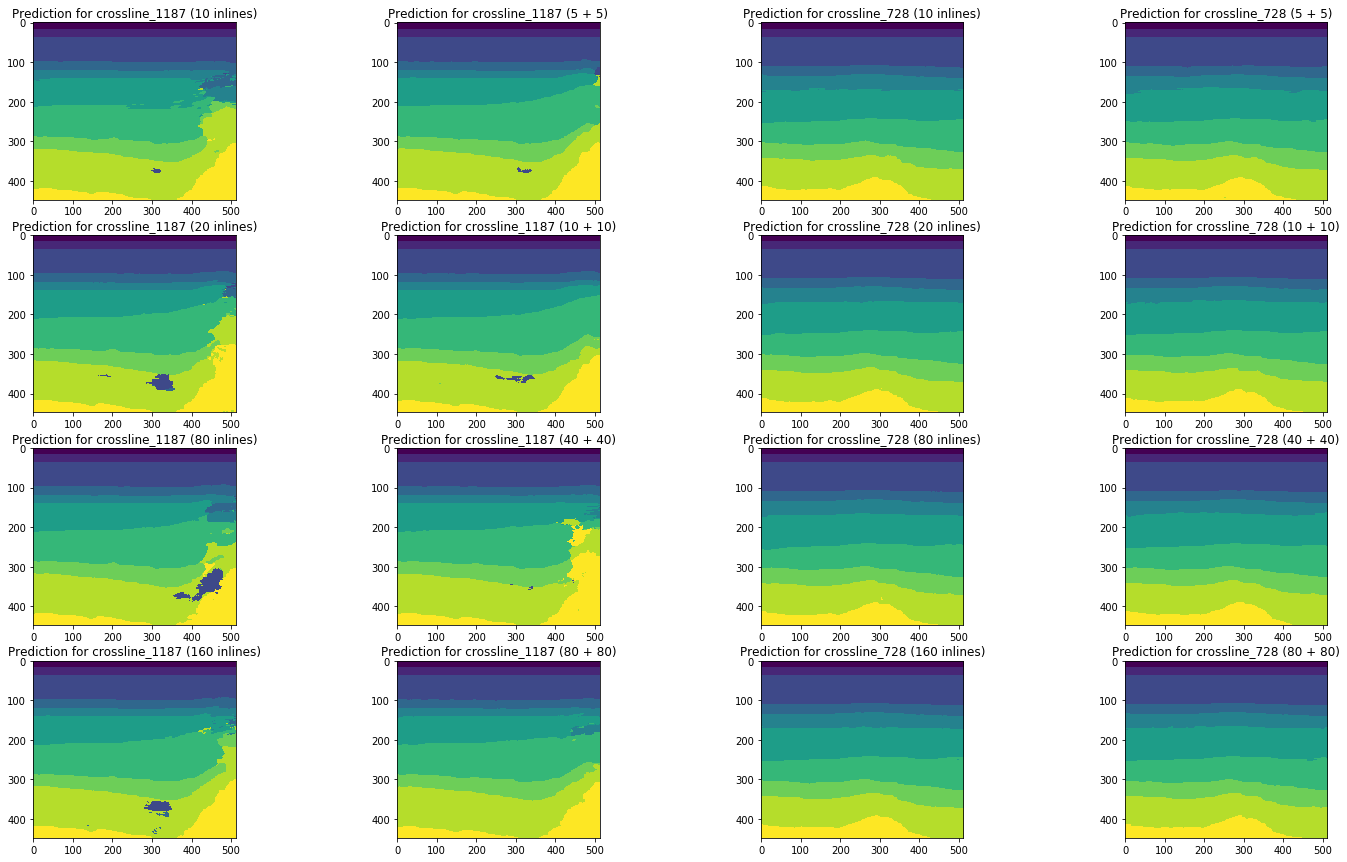
الشكل 20. مقارنة توقعات الشبكة للخطوط المتقاطعة
تؤكد المقارنة المرئية افتراض أن إضافة أنواع مختلفة من الشرائح إلى التدريب لا يغير الموقف بشكل أساسي. يمكن ملاحظة بعض التحسينات فقط على الخط الأيسر ، ولكن هل هي عالمية؟ سنحاول الإجابة على هذا السؤال أكثر.
المهمة 5. تقييم حجم الصقل اليدوي
للحصول على استنتاج نهائي حول النتائج ، من الضروري تقدير مقدار التنقيح اليدوي لتوقعات الشبكة التي تم الحصول عليها. للقيام بذلك ، حددنا عدد المكونات المتصلة (أي النقاط الصلبة من نفس اللون) على كل التنبؤات التي تم الحصول عليها. إذا كانت هذه القيمة هي 10 ، فسيتم اختيار الطبقات بشكل صحيح ونتحدث عن تصحيح أفق بسيط. إذا لم يكن هناك الكثير ، فيجب عليك فقط "تنظيف" المساحات الصغيرة من الصورة. إذا كان هناك الكثير منها ، فسيكون كل شيء سيئًا وربما يحتاج إلى إعادة تخطيط كاملة.
للاختبار ، اخترنا 110 خطوط مضمّنة و 360 خطًا لم تستخدم في تدريب أي من الشبكات التي تم النظر فيها.
جدول 1. متوسط الإحصائيات على كلا النوعين من الشرائح
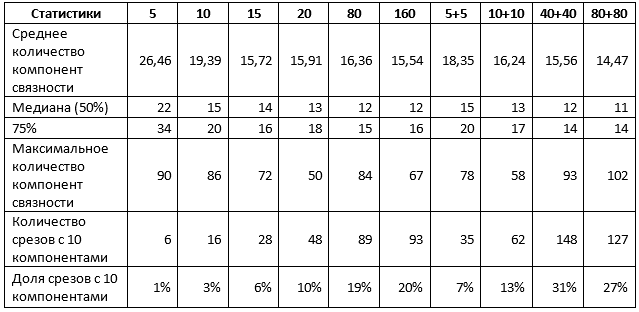
الجدول 1 يؤكد بعض النتائج السابقة. على وجه الخصوص ، عند استخدام شرائح 1٪ للتدريب ، لا يوجد فرق ، استخدم نوعًا واحدًا من الشرائح أو كليهما ، ويمكن وصف النتيجة على النحو التالي:
- حوالي 10٪ من التوقعات قريبة من النموذج المثالي ، أي لا تتطلب أكثر من التعديلات على الأقسام الفردية للآفاق ؛
- 50٪ من التوقعات لا تحتوي على أكثر من 15 موقعًا ، أي لا يزيد عن 5
- 75 ٪ من التوقعات لا تحتوي على أكثر من 20 نقطة ، أي لا يزيد عن 10
- تتطلب نسبة 25٪ المتبقية من التنبؤات مزيدًا من التحسين ، بما في ذلك ، ربما ، إعادة تصميم كاملة للشرائح الفردية.
زيادة في حجم العينة تصل إلى 5 ٪ يغير الوضع. على وجه الخصوص ، تُظهر الشبكات المدربة على مزيج من الأقسام مؤشرات أعلى بكثير ، على الرغم من أن الحد الأقصى لقيمة المكونات يزداد أيضًا ، مما يشير إلى ظهور تفسيرات منفصلة ذات جودة رديئة للغاية. ومع ذلك ، إذا قمت بزيادة العينة بنسبة 5 مرات واستخدمت خليطًا من الشرائح:
- حوالي 30٪ من التوقعات قريبة من النموذج المثالي ، أي لا تتطلب أكثر من التعديلات على الأقسام الفردية للآفاق ؛
- 50٪ من التوقعات لا تحتوي على أكثر من 12 موقعًا ، أي لا يزيد عن 2
- 75 ٪ من التوقعات لا تحتوي على أكثر من 14 نقطة ، أي لا يزيد عن 4
- تتطلب نسبة 25٪ المتبقية من التنبؤات مزيدًا من التحسين ، بما في ذلك ، ربما ، إعادة تصميم كاملة للشرائح الفردية.
زيادة أخرى في حجم العينة لا يؤدي إلى نتائج محسنة.
بشكل عام ، بالنسبة لمكعب البيانات الذي درسناه ، يمكننا استخلاص استنتاجات حول مدى كفاية 1-5 ٪ من إجمالي حجم البيانات للحصول على نتيجة جيدة من شبكة عصبية.
وفقًا لهذه البيانات ، بالاقتران مع المقاييس والرسوم التوضيحية المذكورة أعلاه ، من الممكن بالفعل استخلاص استنتاجات حول استصواب استخدام الشبكات العصبية لمساعدة المترجمين الفوريين والنتائج التي سيتعامل معها المتخصصون.
النتائج
لذلك ، يمكننا الآن الإجابة على الأسئلة التي طرحت في بداية المقال ، وذلك باستخدام النتائج التي تم الحصول عليها على سبيل المثال المكعب الزلزالي لبحر الشمال:
ما مقدار البيانات التي يحتاج الخبراء إلى ترميزها لتدريب شبكة عصبية؟ وما هي البيانات التي يجب علي اختيارها؟للحصول على تنبؤ جيد بالشبكة ، يكفي بالفعل تحديد 1-5٪ من إجمالي عدد الشرائح. لا تؤدي الزيادة الأخرى في الحجم إلى تحسن في النتيجة ، مقارنةً بالزيادة في عدد البيانات التي تم وضع علامة عليها مسبقًا. للحصول على ترميز أفضل على هذا الحجم الصغير باستخدام شبكة عصبية ، من الضروري تجربة أساليب أخرى ، على سبيل المثال ، صقل استراتيجيات الهندسة والتعلم ، ومعالجة الصور مسبقًا ، إلخ.
بالنسبة للعلامة الأولية ، يجدر اختيار شرائح من كلا النوعين - الخطوط الداخلية والخطوط المتقاطعة.
ماذا يحدث في مثل هذا الناتج؟ هل ستحتاج التنقيح اليدوي لتوقعات الشبكة العصبية؟ إذا كان الأمر كذلك ، كيف معقدة وضخمة؟
نتيجة لذلك ، فإن جزءًا كبيرًا من الصور التي تحملها هذه الشبكة العصبية لن يتطلب التحسين الأكثر أهمية ، والذي يتكون من تصحيح مناطق فردية سيئة التعرّف. من بينها سيكون هناك مثل هذه التفسيرات التي لن تتطلب أي تصحيحات. وفقط للصور الفردية ، قد تحتاج إلى تصميم يدوي جديد.
بالطبع ، عند تحسين خوارزمية التعلم ومعلمات الشبكة ، يمكن تحسين قدراتها التنبؤية. في تجربتنا ، لم يتم تضمين حل هذه المشاكل.
بالإضافة إلى ذلك ، لا ينبغي تعميم نتائج دراسة واحدة على مكعب زلزالي واحد بدون تفكير - على وجه التحديد بسبب تفرد كل مجموعة بيانات. لكن هذه النتائج هي تأكيد لتجربة أجراها مؤلفون آخرون ، وأساس للمقارنة مع دراساتنا اللاحقة ، والتي سنكتب عنها أيضًا قريبًا.
شكر
وفي النهاية ، أود أن أشكر زملائي من
MaritimeAI (خاصة Andrey Kokhan) و
ODS على التعليقات القيمة والمساعدة.
قائمة المصادر المستخدمة:
- بس بيترز ، الداد هابر ، جوستين جرانيك. الشبكات العصبية للجيوفيزيائيين وتطبيقها على تفسير البيانات الزلزالية
- هاو وو ، بو تشانغ. شبكة عصبية ترميز-فك تشفير عميقة في مساعدة تتبع الأفق الزلزالي
- تيلو ورونا وإندرانيل بان وروبرت غاوثورب وهاكون فوسن. تحليل الزلازل السطحية باستخدام التعلم الآلي
- رينالدو موزارت سيلفا ، لايس باروني ، رودريغو إس فيريرا ، دانييل تشيفيتاريزي ، دانييلا سزوركمان ، إميليو فيتال البرازيل. مجموعة بيانات هولندا: مجموعة بيانات عامة جديدة للتعلم الآلي في التفسير الزلزالي