في هذه المقالة ، أقدم إليكم أفكاري حول تاريخ وآفاق تطوير الإنترنت ، والشبكات المركزية واللامركزية ، ونتيجة لذلك ، الهيكل المحتمل للجيل القادم من الشبكة اللامركزية.
هناك خطأ ما في الإنترنت
تعرفت أولاً على الإنترنت في عام 2000. بالطبع ، هذا أبعد ما يكون عن البداية - الشبكة موجودة بالفعل قبل ذلك ، ولكن يمكن تسمية ذلك الوقت بالفترة الأولى للإنترنت. الشبكة العنكبوتية العالمية هي اختراع رائع لـ Tim Berners-Lee ، web1.0 في شكله الأساسي الكلاسيكي. العديد من المواقع والصفحات التي ترتبط مع بعضها البعض مع الارتباطات التشعبية. للوهلة الأولى - بسيطة ، مثل كل الهندسة المعمارية الرائعة:
اللامركزية والحرة . أريد - أسافر عبر مواقع أشخاص آخرين ، اتبع الارتباطات التشعبية ؛ أريد - أقوم بإنشاء موقع الويب الخاص بي الذي أنشر عليه ما هو مثير للاهتمام بالنسبة لي - على سبيل المثال ، مقالاتي ، صور ، برامج ، ارتباطات تشعبية إلى مواقع تهمني. وآخرون نشر روابط لي.
يبدو - صورة مثالية؟ لكنك تعرف بالفعل كيف انتهى كل شيء.
كان هناك الكثير من الصفحات ، وأصبح البحث عن المعلومات أمرًا غير تافه للغاية. الارتباطات التشعبية المسجلة من قبل المؤلفين ببساطة لا يمكن بناء هذه الكمية الضخمة من المعلومات. أولاً ، تم ملء الدلائل يدويًا ، ثم محركات البحث العملاقة التي بدأت في استخدام خوارزميات الترتيب الاستدلالي البارعة. تم إنشاء المواقع والتخلي عنها ، وتكرار المعلومات وتشويهها. كان الإنترنت يتاجر بسرعة ويتحرك بعيدًا عن الشبكة الأكاديمية المثالية. تحولت لغة الترميز إلى لغة تنسيق. كان هناك الإعلان ، لافتات مزعجة الخسيس وتكنولوجيا الترويج والخداع لمحركات البحث - جنوب شرقي أوروبا. سرعان ما أصبحت الشبكة مسدودة بالقمامة المعلوماتية. توقف الارتباطات التشعبية لتكون أداة اتصال منطقية وتحولت إلى أداة ترويجية. أصبحت المواقع محصورة ، مغلقة على نفسها ، وتحولت من "صفحات" مفتوحة إلى "تطبيقات محكم" ، وأصبحت فقط وسيلة لتوليد الدخل.
حتى ذلك الحين ، كان لدي بعض الفكر بأن "هناك خطأ ما هنا". مجموعة من المواقع المختلفة ، بدءًا من الصفحات الرئيسية البدائية ذات المظهر vyrviglazny ، وتنتهي بـ "megaportals" ، محملة بلافتات مزهرة. حتى إذا كانت المواقع على نفس الموضوع ، فهي غير مرتبطة تمامًا ، ولكل منها تصميمها الخاص وهيكلها الخاص ولافتات مزعجة وسوء البحث ، ومشاكل في التنزيل (نعم ، أردت الحصول على معلومات في وضع عدم الاتصال). ومع ذلك ، بدأت الإنترنت تتحول إلى نوع من التلفزيون ، حيث تم تثبيت جميع أنواع بهرج لمحتوى مفيد مع المسامير.
أصبحت اللامركزية كابوسا.
ماذا تريد؟
من المفارقات ، كمستخدم ، لم أكن بحاجة إلى اللامركزية! تذكر أفكاري واضحة من تلك الأوقات ، توصلت إلى استنتاج أنني بحاجة ...
قاعدة بيانات واحدة ! مثل هذا الاستعلام الذي من شأنه أن يعطي جميع النتائج ، ولكن ليس الأنسب لخوارزمية الترتيب. إحداها تم تصميم كل هذه النتائج وتصميمها بشكل موحد من خلال تصميمي الفردي ، بدلاً من تصميمات vyrviglaznymi ذاتية الصنع من قبل العديد من Vasya Pupkin. واحدة يمكن أن تبقى في وضع عدم الاتصال ولا تخشى أن يختفي الموقع غدًا وأن المعلومات ستختفي إلى الأبد. واحدة يمكنني فيها إدخال معلوماتي - على سبيل المثال ، التعليقات والعلامات. واحدة يمكنني من خلالها البحث والفرز والتصفية باستخدام خوارزمياتي الشخصية.
الويب 2.0 والشبكات الاجتماعية
في هذه الأثناء ، دخل مفهوم الويب 2.0 إلى الحلبة. صاغه تيم أورايلي في عام 2005 على أنه "منهجية لتصميم النظم التي ، مع مراعاة تفاعلات الشبكات ، تصبح أفضل كلما زاد عدد الأشخاص الذين يستخدمونها" - مما يعني المشاركة النشطة للمستخدمين في الإنشاء الجماعي لمحتوى الويب وتحريره. من دون مبالغة ، أصبحت الشبكات الاجتماعية قمة وانتصار هذا المفهوم. منصات عملاقة تجمع بين مليارات المستخدمين وتخزين مئات بايتات البيانات.
ماذا حصلنا في الشبكات الاجتماعية؟
- توحيد واجهة. اتضح أن جميع إمكانيات إنشاء تصميم المستخدمين vyviglazny متنوعة لا تحتاج ؛ جميع صفحات جميع المستخدمين لديها نفس التصميم وتناسب الجميع وحتى مريحة ؛ فقط المحتوى مختلف.
- توحيد وظيفي كل مجموعة متنوعة من البرامج النصية كانت غير ضرورية أيضًا. Lenta ، الأصدقاء ، الألبومات ... أثناء وجود الشبكات الاجتماعية ، استقرت وظائفها إلى حد ما ومن غير المرجح أن تتغير: بعد كل شيء ، يتم تحديد الوظيفة حسب أنواع نشاط الأشخاص ، والناس لا يتغيرون عملياً.
- قاعدة بيانات واحدة ؛ اتضح أن العمل مع قاعدة البيانات هذه أكثر ملاءمة من كثير من المواقع المختلفة ؛ أصبح البحث أسهل بكثير. بدلاً من المسح المتواصل لمجموعة متنوعة من الصفحات المزدوجة ، يتم تخزين كل ذلك في ذاكرة التخزين المؤقت ، مرتبة حسب خوارزميات إرشادية معقدة - استعلام موحد بسيط نسبياً لقاعدة بيانات واحدة ذات بنية معروفة.
- ردود الفعل واجهة - يحب و reposts. على الويب العادي ، لم يتمكن Google نفسه من الحصول على تعليقات من المستخدمين بعد النقر على الرابط في نتائج البحث. في الشبكات الاجتماعية ، كان هذا الاتصال بسيطًا وطبيعيًا.
ماذا فقدنا؟
لقد فقدنا اللامركزية ، وهو ما يعني الحرية . ويعتقد الآن أن بياناتنا لا تخصنا. إذا قبل أن نتمكن من استضافة صفحة رئيسية حتى على جهاز الكمبيوتر الخاص بنا ، نحن الآن نقدم جميع بياناتنا لعمالقة الإنترنت.
بالإضافة إلى ذلك ، مع تطور الإنترنت ، أصبحت الحكومات والشركات مهتمة به ، وكانت هناك مشكلات الرقابة السياسية وقيود حقوق النشر. يمكن حظر صفحاتنا على الشبكات الاجتماعية وحذفها إذا كان المحتوى لا يتوافق مع أي قواعد للشبكة الاجتماعية ؛ لمنصب مهمل - جلب إلى المسؤولية الإدارية وحتى الجنائية.
وهنا نفكر مرة أخرى: هل من الممكن إعادة اللامركزية إلينا؟ ولكن في شكل مختلف ، خالية من أوجه القصور في المحاولة الأولى؟
شبكات نظير إلى نظير
ظهرت شبكات p2p الأولى قبل وقت طويل من الويب 2.0 وتم تطويرها بالتوازي مع تطوير الويب. التطبيق الكلاسيكي الرئيسي ل p2p هو تبادل الملفات. تم تصميم الشبكات الأولى لمشاركة الموسيقى. كانت الشبكات الأولى (مثل Napster) مركزية بشكل أساسي ، وبالتالي قام أصحاب حقوق الطبع والنشر بتغطيتها بسرعة. أخذ أتباع طريق اللامركزية. في عام 2000 ، ظهرت بروتوكولات ED2K (أول عميل eDokney) وبروتوكولات Gnutella ؛ في عام 2001 ، ظهر بروتوكول FastTrack (عميل KaZaA). تدريجيا ، زادت درجة اللامركزية ، تحسنت التقنيات. تم استبدال الأنظمة التي تحتوي على "قائمة انتظار التنزيل" بواسطة السيول ، وظهر مفهوم جداول تجزئة DHT الموزعة. كما تم تشديد المكسرات من قبل الدول ، أصبحت هوية المشاركين أكثر طلبًا. منذ عام 2000 ، كانت شبكة Freenet قيد التطوير ، منذ عام 2003 I2P ، وفي عام 2006 تم إطلاق مشروع RetroShare. يمكنك ذكر شبكات p2p العديدة التي كانت موجودة سابقًا والتي اختفت بالفعل - وهي الآن تعمل: WASTE و MUTE و TurtleF2F و RShare و PerfectDark و ARES و Gnutella2 و GNUNet و IPFS و ZeroNet و Tribbler وغيرها الكثير. هناك الكثير منهم. إنها مختلفة. مختلف تمامًا - سواء من حيث الغرض أو في التصميم ... ربما لا يعرف الكثير منكم جميع هذه الأسماء. وهذا أبعد ما يكون عن الكل.
ومع ذلك ، فإن شبكات P2P لديها الكثير من العيوب. بالإضافة إلى العيوب الفنية الكامنة في كل تطبيق محدد للبروتوكول والعميل ، على سبيل المثال ، فإن العيب العام إلى حد ما هو تعقيد البحث (على سبيل المثال ، كل شيء واجهه Web 1.0 ، ولكن في إصدار أكثر تعقيدًا). جوجل ليست هنا مع البحث في كل مكان والفوري. وإذا كان لا يزال بإمكانك استخدام البحث حسب اسم الملف أو معلومات التعريف ، بالنسبة لشبكات مشاركة الملفات ، فمن الصعب جدًا العثور على شيء ، على سبيل المثال ، في شبكات البصل أو شبكات i2p ، إذا كان ذلك ممكنًا.
بشكل عام ، إذا قمنا برسم أوجه التشابه مع الإنترنت الكلاسيكي ، فإن معظم الشبكات اللامركزية عالقة في مكان ما على مستوى FTP. تخيل الإنترنت ، حيث لا يوجد سوى بروتوكول نقل الملفات: لا المواقع الحديثة ، ولا web2.0 ، ولا يوتيوب ... هذا في هذه الحالة ، وهناك شبكات لامركزية. وعلى الرغم من المحاولات الفردية لتغيير شيء ما ، هناك تغييرات قليلة.
محتوى
دعنا ننتقل إلى جزء مهم آخر من هذا اللغز - المحتوى. المحتوى هو المشكلة الرئيسية لأي مورد إنترنت ، ولا سيما اللامركزية. من أين تحصل عليه؟ بالطبع ، يمكنك الاعتماد على مجموعة من المتحمسين (كما هو الحال مع شبكات p2p الموجودة) ، ولكن بعد ذلك سيكون تطوير الشبكة طويلاً للغاية ، وسيكون هناك القليل من المحتوى.
العمل مع الإنترنت العادي هو البحث ودراسة المحتوى. في بعض الأحيان ، يتم الحفاظ عليه (إذا كان المحتوى ممتعًا ومفيدًا ، فالكثيرون ، خاصة أولئك الذين أتوا إلى الشبكة أثناء وقت الاتصال الهاتفي - بمن فيهم أنا) يبقونه حاليًا في وضع عدم الاتصال حتى لا تضيع ؛ لأن الإنترنت شيء لا يمكن التحكم فيه بالنسبة لنا ، اليوم لا يوجد موقع ويب غدًا ، يوجد اليوم فيديو على YouTube - غدًا تم حذفه ، إلخ.
وبالنسبة إلى السيول (التي نعتبرها مجرد وسيلة إيصال أكثر من كونها شبكة p2p) ، فإن الحفظ ضمنيًا بشكل عام. وهذه ، بالمناسبة ، هي إحدى مشكلات السيول: من الصعب نقل الملف الذي تم تنزيله مرة واحدة إلى المكان الذي يكون فيه أكثر ملاءمة لاستخدامه (كقاعدة عامة ، تحتاج إلى تجديد التوزيع يدويًا) ومن المستحيل تمامًا إعادة تسميته (يمكنك إنشاء رابط ثابت ، ولكن لا يعرف سوى القليل من الناس عنه).
بشكل عام ، تخزين العديد من المحتوى بطريقة أو بأخرى. ما هو مصيره في المستقبل؟ عادةً ما تظهر الملفات المحفوظة في مكان ما على القرص ، في مجلد مثل التنزيلات ، في كومة شائعة ، وتوجد هناك مع عدة آلاف من الملفات الأخرى. هذا سيء - وسيء للمستخدم نفسه. إذا كان لدى الإنترنت محركات بحث ، فلن يكون للكمبيوتر المحلي للمستخدم أي شيء من هذا القبيل. من الجيد أن يكون المستخدم أنيقًا ويستخدم لفرز الملفات التي تم تنزيلها "الواردة". لكن ليس كلهم ...
في الواقع ، يوجد الآن الكثير من أولئك الذين لا يقومون بحفظ أي شيء ، لكنهم يعتمدون بالكامل على الإنترنت. ولكن في شبكات p2p ، من المفترض أن يتم تخزين المحتوى محليًا على جهاز المستخدم وتوزيعه على المشاركين الآخرين. هل من الممكن إيجاد حل يتيح إشراك كلتا الفئتين من المستخدمين في شبكة لا مركزية دون تغيير عاداتهم ، علاوة على ذلك ، مما يجعل حياتهم أسهل؟
الفكرة بسيطة للغاية: ماذا لو جعلنا وسيلة مريحة وشفافة للمستخدم لحفظ المحتوى من الإنترنت العادي ، والحفظ بذكاء بمعلومات التعريف الدلالية ، وليس في كومة عامة ، ولكن في بنية محددة مع إمكانية مزيد من الهيكلة ، وتوزيع المحتوى المحفوظ في نفس الوقت الشبكة؟
لنبدأ بالحفظ
لن نفكر في استخدام الإنترنت النفعي لعرض توقعات الطقس أو جداول الطائرات. نحن مهتمون أكثر بالأشياء القائمة بذاتها أو غير القابلة للتغيير - مقالات (تبدأ من التغريدات / المشاركات من الشبكات الاجتماعية وتنتهي بمقالات كبيرة ، مثل هنا على Habré) ، والكتب والصور والبرامج والتسجيلات الصوتية والفيديو. من أين تأتي المعلومات؟ عادة ما يكون
- الشبكات الاجتماعية (أخبار متنوعة ، ملاحظات صغيرة - "التغريدات" ، الصور ، الصوت والفيديو)
- مقالات عن الموارد المواضيعية (مثل هبر) ؛ لا يوجد الكثير من الموارد الجيدة ، وعادة ما يتم بناء هذه الموارد أيضا على مبدأ الشبكات الاجتماعية
- مواقع الأخبار
كقاعدة عامة ، هناك وظائف قياسية هناك: مثل ، إعادة النشر ، المشاركة على الشبكات الاجتماعية ، إلخ.
تخيل مكونًا إضافيًا
للمتصفح سيوفر بطريقة خاصة كل ما نود إعادته أو إعادة نشره أو حفظه في "المفضلة" (أو النقر فوق زر مكون إضافي خاص يتم عرضه في قائمة المتصفح في حالة عدم وجود وظيفة مماثلة للموقع) / repost / المرجعية). الفكرة الأساسية هي أنك تعجبك تمامًا - كما فعلت مليون مرة من قبل ، وأن النظام يحفظ المقالة أو الصورة أو الفيديو في مساحة تخزين خاصة دون اتصال بالإنترنت ، وتصبح هذه المقالة أو الصورة متاحة - وللمشاهدة في وضع عدم الاتصال من خلال واجهة العميل اللامركزية وفي الشبكة الأكثر لامركزية! بالنسبة لي ، إنها مريحة للغاية. لا توجد إجراءات غير ضرورية ، ونقوم على الفور بحل العديد من المشكلات:
- حفظ محتوى قيم قد يتم فقده أو حذفه
- شبكة اللامركزية ملء سريع
- تجميع المحتوى من مصادر مختلفة (يمكنك التسجيل في العشرات من موارد الإنترنت ، وستتوافد جميع الإعجابات / إعادة النشر إلى قاعدة بيانات محلية واحدة)
- هيكلة المحتوى الخاص بك وفقا لقواعدك
من الواضح ، يجب تكوين المكون الإضافي للمتصفح على هيكل كل موقع (هذا واقعي تمامًا - هناك بالفعل مكونات إضافية لحفظ المحتوى من Youtube و Twitter و VK ، إلخ). لا يوجد الكثير من المواقع التي تجعل من الإضافات الشخصية لها معنى. وكقاعدة عامة ، فهذه شبكات اجتماعية واسعة النطاق (لا يكاد يوجد أكثر من عشرة منها) وعدد معين من المواقع المواضيعية عالية الجودة مثل هبر (هناك أيضًا القليل منها). مع شفرة المصدر المفتوح والمواصفات ، فإن تطوير مكون إضافي جديد يعتمد على قالب فارغ يجب ألا يستغرق الكثير من الوقت. بالنسبة للمواقع الأخرى ، يمكنك استخدام زر الحفظ العام ، والذي من شأنه أن يحفظ الصفحة بالكامل في ملف mhtml - ربما بعد مسح الصفحة من الإعلانات.
الآن عن الهيكلة
عن طريق الحفظ "الذكي" ، أقصد على الأقل الحفظ باستخدام معلومات التعريف: مصدر المحتوى (URL) ، ومجموعة من الإعجابات التي تم تعيينها مسبقًا ، والعلامات ، والتعليقات ، ومعرفاتها ، إلخ. في الواقع ، أثناء التخزين العادي ، تُفقد هذه المعلومات ... يمكن أن يعني المصدر ليس فقط عنوان URL مباشرًا ، ولكن أيضًا مكون دلالي: على سبيل المثال ، مجموعة على الشبكات الاجتماعية أو مستخدم أعاد نشره. يمكن أن يكون المكون الإضافي ذكيًا بدرجة كافية لاستخدام هذه المعلومات من أجل التنظيم التلقائي ووضع العلامات. أيضًا ، يجب أن يكون من المفهوم أن المستخدم نفسه يمكنه دائمًا إضافة بعض المعلومات الوصفية إلى المحتوى المخزن ، والتي يجب أن توفر لها أدوات واجهة ملائمة بشكل مخفي (لدي الكثير من الأفكار حول كيفية القيام بذلك).
وبالتالي ، تم حل مشكلة هيكلة وتنظيم ملفات المستخدم المحلي. هذه فائدة جاهزة يمكن استخدامها حتى بدون أي p2p. إنها مجرد قاعدة بيانات غير متصلة بالإنترنت تعرف ماذا وأين وفي أي سياق قمنا بحفظه وتسمح لك بإجراء دراسات صغيرة. على سبيل المثال ، ابحث عن مستخدمي شبكة اجتماعية خارجية يعجبهم الأهم من ذلك كله ضمن نفس المشاركات التي تحبونها. كم عدد الشبكات الاجتماعية تسمح بذلك صراحة؟
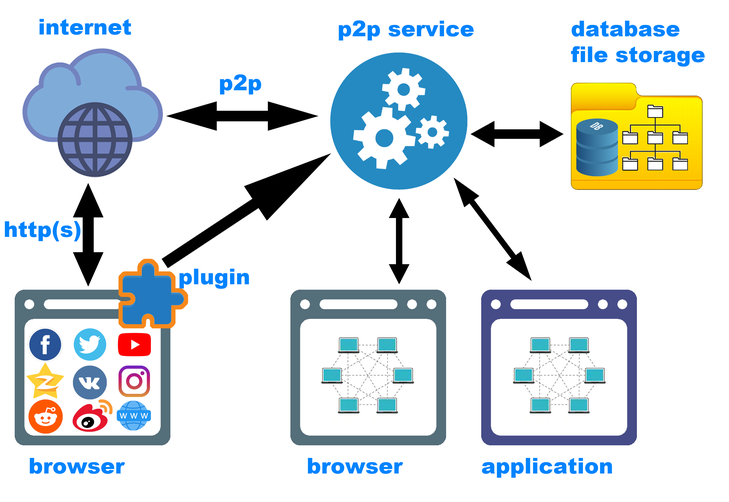
تجدر الإشارة هنا إلى أن المكون الإضافي للمتصفح لا يكفي بالتأكيد. المكون الثاني الأكثر أهمية في النظام هو خدمة الشبكة اللامركزية التي تعمل في الخلفية وتخدم كل من شبكة p2p نفسها (طلبات من الشبكة وطلبات من العميل) ، بالإضافة إلى حفظ محتوى جديد باستخدام المكون الإضافي. ستضع الخدمة ، بالتعاون مع المكون الإضافي ، المحتوى في المكان المناسب ، وتحسب التجزئة (وربما تحدد أن هذا المحتوى قد تم حفظه بالفعل) ، وإضافة المعلومات الوصفية اللازمة إلى قاعدة البيانات المحلية.
ما هو مثير للاهتمام - سيكون النظام مفيد بالفعل في هذا النموذج ، دون أي P2P. يستخدم العديد من الأشخاص كليبرز الويب الذين يضيفون محتوى مثيرًا للاهتمام من الويب ، على سبيل المثال ، إلى Evernote. الهيكل المقترح هو نسخة موسعة من هذا المقص.
وأخيرا ، تبادل P2P
أفضل جزء هو أنه يمكن تبادل المعلومات والمعلومات الوصفية (سواء تم التقاطها من الويب والمعلومات الخاصة بك). إن مفهوم الشبكة الاجتماعية مرتبط جيدًا بالعمارة p2p. يمكننا القول أن الشبكة الاجتماعية و p2p يبدو أنهما صنعا لبعضهما البعض. يجب بناء أي شبكة لامركزية بشكل مثالي كشبكة اجتماعية ، وعندها فقط ستعمل بكفاءة. "الأصدقاء" ، "المجموعات" - هذه هي الأعياد ذاتها التي يجب أن توجد بها علاقات مستقرة ، وتؤخذ تلك من مصدر طبيعي - المصالح المشتركة للمستخدمين.
تتوافق مبادئ تخزين وتوزيع المحتوى في شبكة لا مركزية تمامًا مع مبادئ تخزين (التقاط) المحتوى من الإنترنت العادي. إذا كنت تستخدم بعض المحتوى من الشبكة (مما يعني أنك قمت بحفظه) ، فيمكن لأي شخص استخدام مواردك (القرص والقناة) اللازمة لتلقي هذا المحتوى على وجه التحديد.
الإعجابات هي أسهل أداة للحفظ والمشاركة. إذا أعجبتني - لا يهم ، على الإنترنت الخارجي أو داخل شبكة لا مركزية - فأنا أحب المحتوى ، وإذا كان الأمر كذلك ، فأنا على استعداد للاحتفاظ به محليًا وتوزيعه على أعضاء آخرين في الشبكة اللامركزية.
- المحتوى ليس "ضائع" ؛ تم تخزينه الآن محليًا معي ، يمكنني العودة إليه لاحقًا ، في أي وقت ، دون القلق بشأن قيام شخص ما بحذفه أو حظره
- يمكنني (على الفور أو في وقت لاحق) تصنيفها ، ووضع علامة عليها ، والتعليق عليها ، والربط بها مع محتوى آخر ، بشكل عام القيام بشيء ذي معنى - دعنا نسميها "تكوين معلومات التعريف"
- يمكنني مشاركة معلومات التعريف هذه مع أعضاء الشبكة الآخرين.
- يمكنني مزامنة معلومات التعريف الخاصة بي مع معلومات التعريف الخاصة بالمشاركين الآخرين
من المحتمل أن الرفض من الأشياء التي لا تعجبك أيضًا يبدو منطقيًا: إذا كنت لا أحب المحتوى ، فمن المنطقي تمامًا ألا أريد تضييع مساحة القرص للتخزين وقناة الإنترنت الخاصة بي لتوزيع هذا المحتوى. لذلك ، فإن الأشياء التي لا تحبها عضويا لا تنسجم مع اللامركزية (رغم أنها في بعض الأحيان لا تزال
مفيدة ).
في بعض الأحيان تحتاج أيضًا إلى حفظ ما لا تحبه. هناك مثل هذه الكلمة "ضروري" :)
"
الإشارات المرجعية " (أو "المفضلة") - لا أعبر عن موقفي من المحتوى ، لكنني أحفظه في قاعدة بيانات الإشارات المرجعية المحلية الخاصة بي. «» (favorites) ( ), «» (bookmarks) — . «» — «» (.. «» ), «» - . ?
"
". , , , . () .
"
" — , , - , — , . , «», , — , / , .
, . — . — . , , , .
, , . , , , . , -, , ; , , .
, . , . , , , .. , . — , (, «» — , … , ).
, — ( i2p Retroshare), TOR VPN.
( ). , — , . — p2p , («backend»). , . — frontend. - ( ), GUI- (Windows, Linux, MacOS, Andriod, iOS ..). frontend'. backend'.
, . (.. , , , , — , , , ..), ( , Libgen), ( Freenet), ( ), ( — , , , , ..) .
1. — . (, ...) (, ...) —
2. , — /; p2p,
3.
4. /