 هذا مؤلم فقط لأول مرة!
هذا مؤلم فقط لأول مرة!مرحبا بالجميع! أصدقائي الأعزاء ، أريد في هذه المقالة أن أشارك تجربتي باستخدام TensorRT ، RetinaNet استنادًا إلى مستودع github.com/aidonchuk/retinanet-examples (هذا شوكة المفتاح الرسمي الرسمي من
nvidia ، والذي سيتيح لنا البدء في استخدام النماذج المحسّنة في الإنتاج في أقرب وقت ممكن).
أثناء التمرير عبر قنوات مجتمع
ods.ai ، صادفت بعض الأسئلة حول استخدام TensorRT ، وغالبًا ما يتم تكرار الأسئلة ، لذلك قررت أن أكتب دليلًا
شاملاً قدر الإمكان لاستخدام الاستدلال السريع استنادًا إلى TensorRT و RetinaNet و Unet و docker.
وصف المهمةأقترح تعيين المهمة بهذه الطريقة: نحتاج إلى ترميز مجموعة البيانات ، وتدريب شبكة RetinaNet / Unet على Pytorch1.3 + ، وتحويل الأوزان المستلمة إلى ONNX ، ثم تحويلها إلى محرك TensorRT وتشغيل هذا الأمر برمته في عامل الإرساء ، ويفضل أن يكون ذلك على Ubuntu 18 يفضل أن يكون ذلك على بنية ARM (Jetson) * ، وبالتالي تقليل النشر اليدوي للبيئة. كنتيجة لذلك ، سوف نحصل على حاوية جاهزة ليس فقط لتصدير وتدريب RetinaNet / Unet ، ولكن أيضًا من أجل التطوير والتدريب الكاملين للتصنيف ، والتجزئة مع جميع الروابط اللازمة.
المرحلة 1. إعداد البيئةمن المهم الإشارة هنا إلى أنني تخلت مؤخرًا عن استخدام ونشر بعض المكتبات على الأقل على جهاز سطح المكتب ، وكذلك على devbox. الشيء الوحيد الذي يجب عليك إنشاؤه وتثبيته هو بيئة python الافتراضية و cuda 10.2 (يمكنك قصر نفسك على برنامج تشغيل nvidia فردي) من deb.
لنفترض أن لديك Ubuntu 18. تم تثبيته حديثًا. قم بتثبيت cuda 10.2 (deb) ، ولن أتناول بالتفصيل عملية التثبيت ، فالوثائق الرسمية كافية تمامًا.
الآن سنقوم بتثبيت عامل ميناء ، يمكن العثور بسهولة على دليل تثبيت عامل ميناء ، هنا مثال على ذلك
www.digitalocean.com/community/tutorials/docker-ubuntu-18-04-1-ar ، الإصدار 19+ متاح بالفعل - ضعه. حسنًا ، لا تنسَ أن تجعل من الممكن استخدام عامل الإرساء دون sudo ، سيكون أكثر ملاءمة. بعد أن تحول كل شيء ، نحب هذا:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.imtqy.com/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.imtqy.com/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo systemctl restart docker
ولا يتعين عليك حتى النظر في المستودع الرسمي
github.com/NVIDIA/nvidia-docker .
الآن تفعل git clone
github.com/aidonchuk/retinanet- أمثلة .
يبقى قليلاً ، من أجل البدء في استخدام عامل ميناء مع nvidia-image ، نحتاج إلى التسجيل في NGC Cloud وتسجيل الدخول. نذهب إلى هنا
ngc.nvidia.com ،
وقم بالتسجيل وبعد دخولنا إلى NGC Cloud ، اضغط SETUP في الزاوية العلوية اليسرى من الشاشة أو اتبع هذا الرابط
ngc.nvidia.com/setup/api-key . انقر فوق "إنشاء مفتاح". أوصي بحفظه ، وإلا في المرة التالية التي تقوم فيها بزيارتها ، سيتعين عليك تجديدها ، وبالتالي نشرها على عربة جديدة ، كرر هذه العملية.
الانتهاء:
docker login nvcr.io Username: $oauthtoken Password: <Your Key> -
اسم المستخدم فقط نسخة. حسنا ، لننظر ، يتم نشر البيئة!
المرحلة 2. تجميع حاوية عامل الميناءفي المرحلة الثانية من عملنا ، سنقوم بتجميع عامل الالتحام والتعريف بدواياه الداخلية.
دعنا نذهب إلى المجلد الجذر بالنسبة لمشروع أمثلة شبكية العين وتشغيلها
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
نقوم بتجميع عامل النقل عن طريق طرح المستخدم الحالي فيه - وهذا مفيد للغاية إذا كتبت شيئًا على VOLUME محمّلًا مع حقوق المستخدم الحالي ، وإلا فسيكون هناك جذر وألم.
أثناء سير عامل الميناء ، دعنا نستكشف Dockerfile:
FROM nvcr.io/nvidia/pytorch:19.10-py3 ARG USER=alex ARG UID=1000 ARG GID=1000 ARG PW=alex RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master COPY . retinanet/ RUN pip install --no-cache-dir -e retinanet/ RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl RUN pip install tensorboardx RUN pip install albumentations RUN pip install setproctitle RUN pip install paramiko RUN pip install flask RUN pip install mem_top RUN pip install arrow RUN pip install pycuda RUN pip install torchvision RUN pip install pretrainedmodels RUN pip install efficientnet-pytorch RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch RUN pip install pytorch_toolbelt RUN chown -R ${USER}:${USER} retinanet/ RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping RUN mkdir /var/run/sshd RUN echo 'root:pass' | chpasswd RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd ENV NOTVISIBLE "in users profile" RUN echo "export VISIBLE=now" >> /etc/profile CMD ["/usr/sbin/sshd", "-D"]
كما ترون من النص ، فإننا نأخذ جميع المفضلة لدينا ، وتجميع retinanet ، وتوزيع الأدوات الأساسية لراحة العمل مع Ubuntu ، وتكوين خادم opensh. السطر الأول هو مجرد وراثة صورة nvidia ، التي قمنا بتسجيل الدخول إليها في NGC Cloud والتي تحتوي على Pytorch1.3 و TensorRT6.xxx ومجموعة من libs التي تتيح لنا تجميع شفرة مصدر cpp المصدر للكشف عننا.
المرحلة 3. بدء وتصحيح حاوية عامل الميناءدعنا ننتقل إلى الحالة الرئيسية لاستخدام الحاوية وبيئة التطوير ، لبدء ، تشغيل نفيديا عامل ميناء. الانتهاء:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latest
تتوفر الحاوية الآن في ssh <curr_user_name>localhost. بعد الإطلاق الناجح ، افتح المشروع في PyCharm. بعد ذلك ، افتح
Settings->Project Interpreter->Add->Ssh Interpreter
الخطوة 1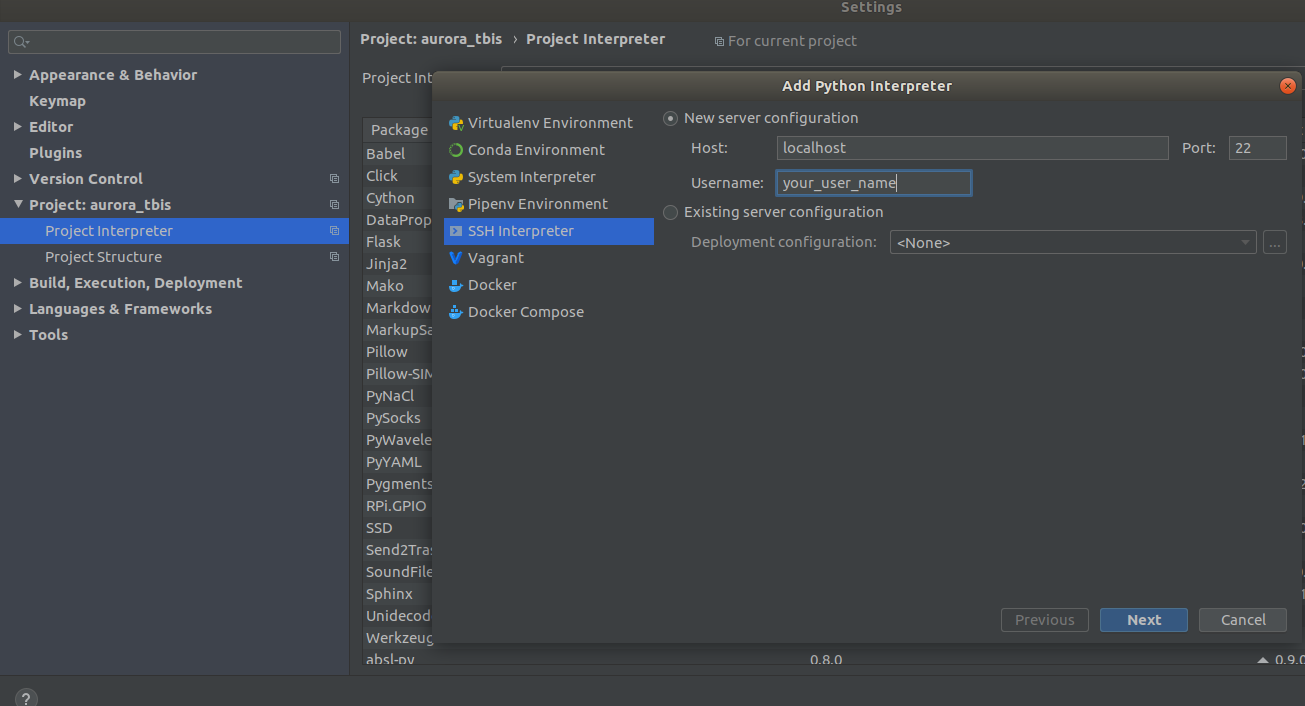 الخطوة 2
الخطوة 2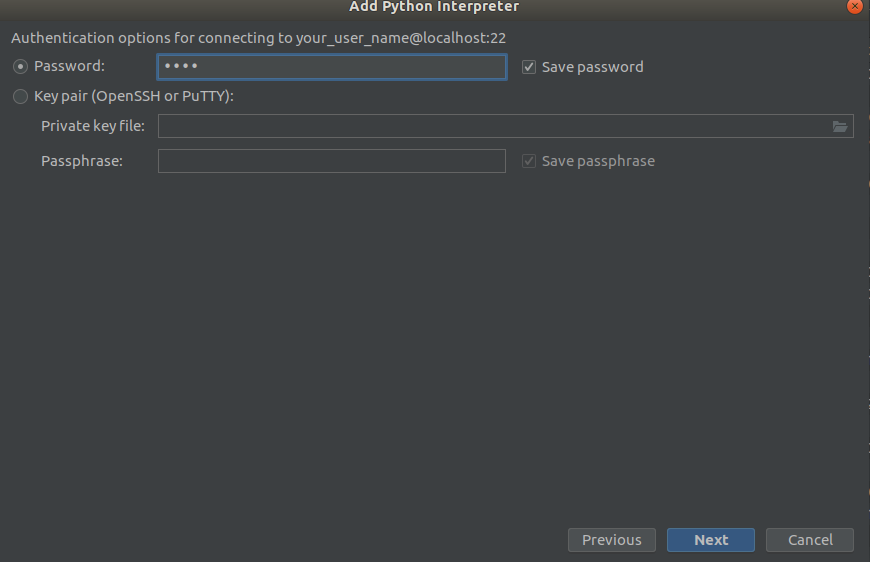 الخطوة 3
الخطوة 3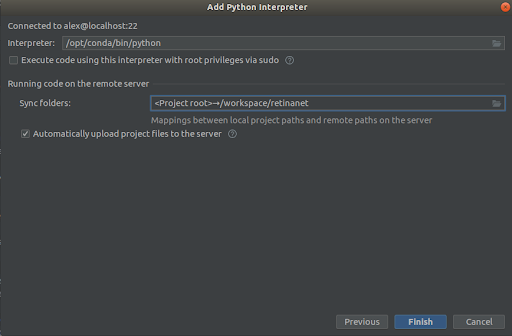
نختار كل شيء كما هو الحال في لقطات ،
Interpreter -> /opt/conda/bin/python
- هذا سيكون في بيثون 3.6 و
Sync folder -> /workspace/retinanet
نضغط على خط النهاية ، ونتوقع الفهرسة ، وهذا كل شيء ، البيئة جاهزة للاستخدام!
هام !!! مباشرة بعد الفهرسة ، استخراج الملفات المترجمة لـ Retinanet من عامل ميناء. في قائمة السياق في جذر المشروع ، حدد
Deployment->Download
سيظهر ملف واحد ومجلدان بناء ، retinanet.egg-info و _so
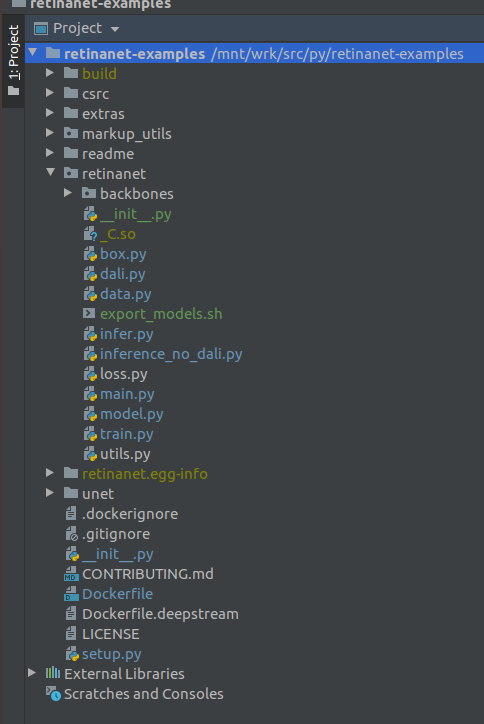
إذا كان مشروعك يبدو كهذا ، فإن البيئة ترى جميع الملفات الضرورية ونحن مستعدون لتعلم RetinaNet.
المرحلة 4. تمييز البيانات وتدريب الكاشفبالنسبة للترميز ، أستخدم
supervise.ly بشكل أساسي - أداة لطيفة ومريحة ، في المرة الأخيرة تم إصلاح مجموعة من عضادات وأصبحت تتصرف بشكل أفضل كثيرًا.
لنفترض أنك قمت بترميز مجموعة بيانات وقمت بتنزيلها ، لكنها لن تعمل على الفور لوضعها في شبكتنا ، لأنها في نسقها الخاص ، ولهذا نحن بحاجة إلى تحويلها إلى COCO. أداة التحويل في:
markup_utils/supervisly_to_coco.py
يرجى ملاحظة أن الفئة في البرنامج النصي هي مثال وتحتاج إلى إدراج الخاصة بك (لا تحتاج إلى إضافة فئة الخلفية)
categories = [{'id': 1, 'name': '1'}, {'id': 2, 'name': '2'}, {'id': 3, 'name': '3'}, {'id': 4, 'name': '4'}]
لسبب ما ، قرر مؤلفو المستودع الأصلي أنك لن تدرب أي شيء باستثناء COCO / VOC للكشف ، لذلك اضطررت إلى تعديل الملف المصدر قليلاً
retinanet/dataset.py
من خلال إضافة tutda ، يمكنك إضافة ألبومات التعيينات المفضلة لديك.
readthedocs.io/en/latest وقطع الفئات الثابتة من COCO. من الممكن أيضًا رش مناطق كبيرة من الاكتشاف إذا كنت تبحث عن كائنات صغيرة في صور كبيرة ، لديك مجموعة بيانات صغيرة =) ، ولا شيء يعمل ، لكن المزيد في هذا الوقت الآخر.
بشكل عام ، حلقة القطار ضعيفة أيضًا ، في البداية لم تقم بحفظ نقاط التفتيش ، واستخدمت بعض المجدول الفظيعة ، إلخ. ولكن الآن كل ما عليك فعله هو تحديد العمود الفقري وتنفيذه
/opt/conda/bin/python retinanet/main.py
مع المعلمات:
train retinanet_rn34fpn.pth --backbone ResNet34FPN --classes 12 --val-iters 10 --images /workspace/mounted_vol/dataset/train/images --annotations /workspace/mounted_vol/dataset/train_12_class.json --val-images /workspace/mounted_vol/dataset/test/images_small --val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json --jitter 256 512 --max-size 512 --batch 32
في وحدة التحكم سترى:
Initializing model... model: RetinaNet backbone: ResNet18FPN classes: 2, anchors: 9 Selected optimization level O0: Pure FP32 training. Defaults for this optimization level are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 1.0 Processing user overrides (additional kwargs that are not None)... After processing overrides, optimization options are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 128.0 Preparing dataset... loader: pytorch resize: [1024, 1280], max: 1280 device: 4 gpus batch: 4, precision: mixed Training model for 20000 iterations... [ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001 [ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001 [ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001 [ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001 [ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001 [ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001 [ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001 [ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001 [ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001 [ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001 [ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001 [ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001 [ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001 [ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001 Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Saving model: 148
لدراسة مجموعة كاملة من المعلمات نظرة
retinanet/main.py
بشكل عام ، فهي قياسية للكشف ، ولهم وصف. قم بتشغيل التدريب وانتظر النتائج. يمكن العثور على مثال للاستدلال في:
retinanet/infer_example.py
أو تنفيذ الأمر:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth --images /workspace/mounted_vol/dataset/test/images --annotations /workspace/mounted_vol/dataset/val.json --output result.json --resize 256 --max-size 512 --batch 32
الخسارة البؤرية والعديد من العمود الفقري بنيت بالفعل في مستودع ، ولهم
retinanet/backbones/*.py
يعطي المؤلفون بعض الخصائص في اللوحة:
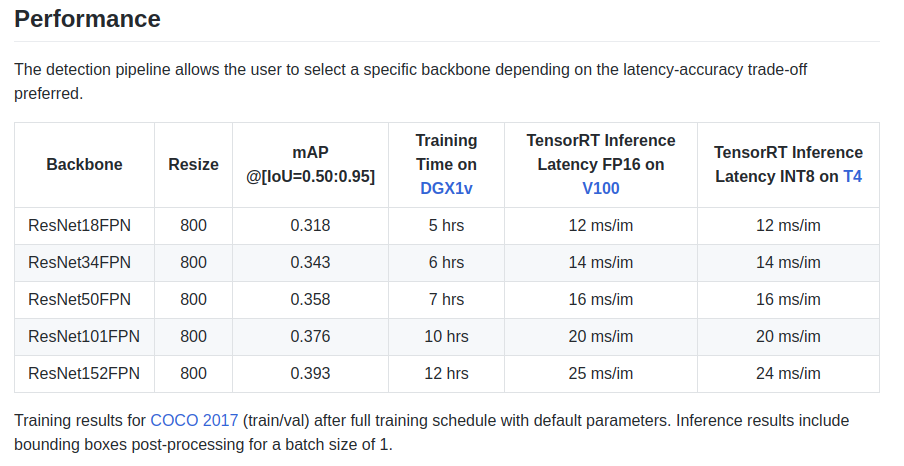
يوجد أيضًا عمود أساسي ResNeXt50_32x4dFPN و ResNeXt101_32x8dFPN ، مأخوذ من torchvision.
آمل أننا اكتشفنا عملية الكشف قليلاً ، لكن يجب عليك بالتأكيد قراءة الوثائق الرسمية
لفهم أوضاع التصدير والتسجيل .
المرحلة 5. تصدير واستدلال نماذج Unet مع تشفير Resnetكما لاحظت على الأرجح ، تم تثبيت مكتبات التجزئة في Dockerfile ، وخاصة المكتبة الرائعة
github.com/qubvel/segmentation_models.pytorch . في حزمة Yunet ، يمكنك العثور على أمثلة لاستدلال وتصدير نقاط تفتيش pytorch في محرك TensorRT.
المشكلة الرئيسية عند تصدير نماذج Unet-like من ONNX إلى TensoRT هي الحاجة إلى تعيين حجم Upsample ثابت أو استخدام ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic def upsample_nearest2d(g, input, output_size):
باستخدام هذا التحويل ، يمكنك القيام بذلك تلقائيًا عند التصدير إلى ONNX ، ولكن بالفعل في الإصدار 7 من TensorRT تم حل هذه المشكلة ، وكان علينا الانتظار قليلاً جدًا.
استنتاجعندما بدأت باستخدام عامل ميناء ، كان لدي شكوك حول أدائه لمهامي. في إحدى الوحدات الخاصة بي ، يوجد الآن كثير من حركة مرور الشبكة التي أنشأتها عدة كاميرات.
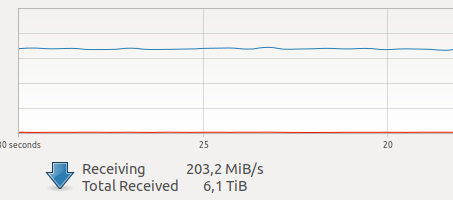
كشفت اختبارات مختلفة على الإنترنت عن حمل كبير نسبيًا لتفاعل الشبكة والتسجيل على VOLUME ، بالإضافة إلى GIL غير معروف ورهيب ، ومنذ إطلاق النار على الإطار ، فإن تشغيل السائق ونقل إطار عبر شبكة هي عمليات ذرية في وضع
الوقت الحقيقي الصعب ، والتأخير الانترنت حاسمة للغاية بالنسبة لي.
لكن لم يحدث شيء =)
PS يبقى لإضافة حلقة القطار المفضلة لديك للتجزئة والإنتاج!
Blagodranostiبفضل مجتمع
ods.ai ، من المستحيل تطويره بدونه! شكرا جزيلا ل
n01z3 ، DL ، الذي تمنى لي أن
أتناول DL ، على نصيحته التي لا تقدر بثمن والاحتراف غير عادية!
استخدام النماذج الأمثل في الإنتاج!
أوروراي