Clickhouse هو محرك قاعدة بيانات (OLAP) لنظام قاعدة بيانات الاستعلام المفتوح المصدر المفتوح المصدر الذي أنشأته ياندكس. يتم استخدامه من قبل Yandex و CloudFlare و VK.com و Badoo وغيرها من الخدمات في جميع أنحاء العالم لتخزين كميات كبيرة جدًا من البيانات (أدخل الآلاف من الأسطر في الثانية أو بايت من البيانات المخزنة على القرص).
في قواعد البيانات "السلسلة" المعتادة ، ومن الأمثلة على ذلك MySQL و Postgres و MS SQL Server ، يتم تخزين البيانات بهذا الترتيب:
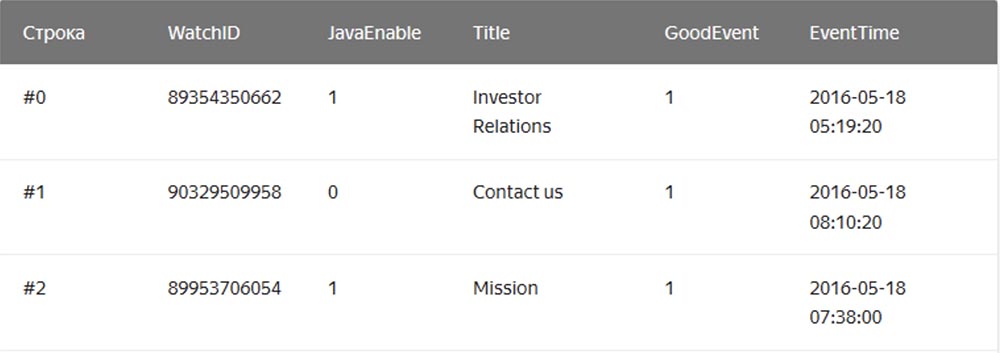
في هذه الحالة ، يتم تخزين القيم المتعلقة صف واحد فعليًا جنبًا إلى جنب. في عمود DBMS ، يتم تخزين القيم من أعمدة مختلفة بشكل منفصل ، ويتم تخزين بيانات عمود واحد معًا:
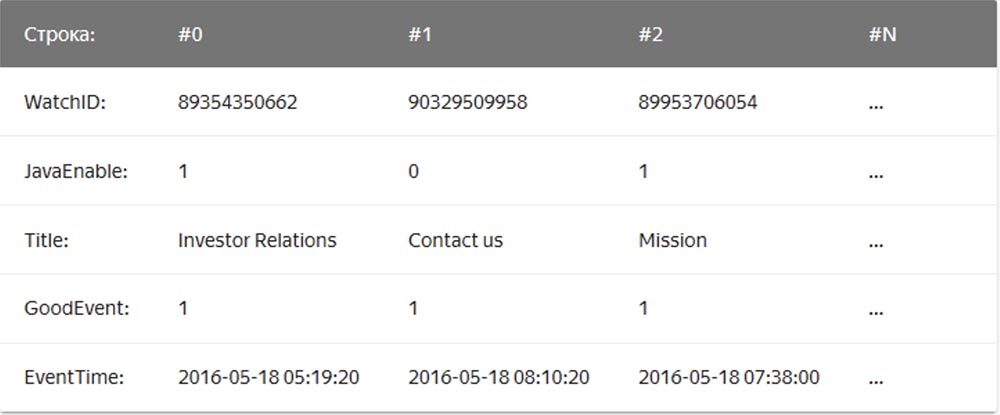
ومن أمثلة قواعد بيانات قواعد البيانات العمودي ، Vertica ، Paraccel (Actian Matrix ، Amazon Redshift) ، Sybase IQ ، Exasol ، Infobright ، InfiniDB ، MonetDB (VectorWise ، Actian Vector) ، LucidDB ، SAP HANA ، Google Dremel ، Google PowerDrill ، Druid ، kdb +.
بدأت شركة
Qwintry لإعادة توجيه البريد باستخدام Clickhouse في عام 2018 لإعداد التقارير ، وقد تأثرت بشدة ببساطتها وقابليتها للتوسع ودعم SQL وسرعتها. يحدها سرعة هذا DBMS بواسطة السحر.
سهولة
يتم تثبيت Clickhouse على أوبونتو باستخدام أمر واحد. إذا كنت تعرف SQL ، فيمكنك البدء على الفور في استخدام Clickhouse لاحتياجاتك. ومع ذلك ، هذا لا يعني أنه يمكنك تشغيل "إظهار جدول إنشاء" في MySQL ونسخ لصق SQL في Clickhouse.
مقارنةً بـ MySQL ، يوجد في DBMS اختلافات مهمة في أنواع البيانات في تعريفات مخططات الجدول ، لذلك بالنسبة للعمل المريح ، فإنك لا تزال بحاجة إلى بعض الوقت لتغيير تعريفات مخطط الجدول ودراسة محركات الجدول.
يعمل Clickhouse بشكل رائع دون أي برامج إضافية ، ولكن إذا كنت تريد استخدام النسخ المتماثل ، فستحتاج إلى تثبيت ZooKeeper. يُظهر تحليل أداء الاستعلام نتائج ممتازة - تحتوي جداول النظام على جميع المعلومات ، ويمكن الحصول على جميع البيانات باستخدام SQL القديم والممل.
إنتاجية
- معيار مقارنة Clickhouse مع Vertica و MySQL على خادم تهيئة: مقبسان Intel® Xeon® CPU E5-2650 v2 @ 2.60GHz ؛ 128 غيغابايت من ذاكرة الوصول العشوائي ؛ MD RAID-5 على 8 6 تيرابايت SATA HDD ، ext4.
- معيار مقارنة Clickhouse مع تخزين بيانات السحابة من Amazon RedShift.
- مقتطفات من مدونة أداء Cloudflare Clickhouse :

تحتوي قاعدة بيانات ClickHouse على تصميم بسيط للغاية - كل العقد في الكتلة لها نفس الوظيفة ولا تستخدم سوى ZooKeeper للتنسيق. لقد بنينا مجموعة صغيرة من عدة عقد وأجرينا اختبارات ، وجدنا خلالها أن النظام يتمتع بأداء مثير للإعجاب ، وهو ما يتوافق مع المزايا المعلنة في معايير قواعد بيانات إدارة قواعد البيانات التحليلية. قررنا إلقاء نظرة فاحصة على المفهوم الكامن وراء ClickHouse. كانت أول عقبة أمام البحث هي الافتقار إلى الأدوات وصغر حجم مجتمع ClickHouse ، لذلك بحثنا في تصميم نظام إدارة قاعدة البيانات هذا لفهم كيفية عمله.
لا يدعم ClickHouse تلقي البيانات مباشرة من كافكا (في الوقت الحالي يعرف بالفعل كيف) ، لأنها مجرد قاعدة بيانات ، لذلك كتبنا خدمة المحول الخاصة بنا في Go. قرأ رسائل Cap'n Proto المشفرة من Kafka ، وحولها إلى TSV ، وأدخلها في ClickHouse على دفعات عبر واجهة HTTP. فيما بعد ، أعدنا كتابة هذه الخدمة لاستخدام مكتبة Go جنبًا إلى جنب مع واجهة ClickHouse الخاصة بنا لتحسين الأداء. عند تقييم أداء تلقي الحزم ، اكتشفنا شيئًا مهمًا - اتضح أنه في ClickHouse يعتمد هذا الأداء بشدة على حجم الحزمة ، أي عدد الصفوف المدرجة في وقت واحد. لفهم سبب حدوث ذلك ، درسنا كيف تقوم ClickHouse بتخزين البيانات.
المحرك الرئيسي ، أو بالأحرى ، مجموعة محركات الجداول التي يستخدمها ClickHouse لتخزين البيانات ، هي MergeTree. يشبه هذا المحرك نظريًا خوارزمية LSM المستخدمة من قِبل Google BigTable أو Apache Cassandra ، لكنه يتجنب إنشاء جدول ذاكرة وسيط وكتابة البيانات مباشرةً إلى القرص. هذا يعطيها سرعة كتابة ممتازة ، حيث يتم فرز كل حزمة مدرجة فقط بواسطة المفتاح الأساسي "المفتاح الأساسي" ، ويتم ضغطها وكتابتها على القرص لتشكيل قطعة.
عدم وجود جدول ذاكرة أو أي مفهوم "لنضارة" البيانات يعني أيضًا أنه يمكن إضافتها فقط ؛ فالنظام لا يدعم تغييرها أو حذفها. واليوم ، فإن الطريقة الوحيدة لحذف البيانات هي حذفها حسب أشهر التقويم ، نظرًا لأن القطاعات لا تتجاوز حدود الشهر مطلقًا. يعمل فريق ClickHouse بنشاط لجعل هذه الميزة قابلة للتخصيص. من ناحية أخرى ، فإن هذا يجعل تسجيل مقاطع الفيديو ودمجها سلسًا ، وبالتالي فإن نطاق عرض النطاق الترددي يتم قياسه خطيًا مع عدد الإضافات المتوازية حتى يتم إدخال I / O أو النوى.
ومع ذلك ، فإن هذه الحقيقة تعني أيضًا أن النظام غير مناسب للحزم الصغيرة ، وبالتالي يتم استخدام خدمات Kafka وإدراجها للتخزين المؤقت. علاوة على ذلك ، تستمر ClickHouse في الخلفية في تنفيذ دمج الأجزاء باستمرار ، بحيث يتم دمج العديد من المعلومات الصغيرة وتسجيلها مرات أكثر ، مما يزيد من كثافة التسجيل. في هذه الحالة ، سيتسبب الكثير من الأجزاء غير ذات الصلة في الاختناق العدواني للمدخلات طالما استمر الاندماج. لقد وجدنا أن أفضل حل وسط بين استقبال البيانات في الوقت الفعلي وأداء الاستقبال هو تلقي عدد محدود من الإدخالات في الثانية في الجدول.
مفتاح أداء قراءة الجدول هو فهرسة وتحديد المواقع على القرص. بغض النظر عن مدى سرعة المعالجة ، عندما يحتاج المحرك إلى مسح تيرابايت من البيانات من القرص واستخدام جزء منها فقط ، فإن الأمر سيستغرق بعض الوقت. ClickHouse هو مخزن أعمدة ، لذلك يحتوي كل مقطع على ملف لكل عمود (عمود) مع قيم مرتبة لكل صف. وبالتالي ، يمكن تخطي الأعمدة بأكملها غير الموجودة في الاستعلام أولاً ، ثم يمكن معالجة عدة خلايا بالتوازي مع التنفيذ المتجه. لتجنب الفحص الكامل ، يحتوي كل مقطع على ملف فهرس صغير.
نظرًا لتصنيف جميع الأعمدة حسب "المفتاح الأساسي" ، فإن ملف الفهرس لا يحتوي إلا على الملصقات (الصفوف التي تم التقاطها) لكل صف Nth لتتمكن من تخزينها في الذاكرة حتى بالنسبة للجداول الكبيرة جدًا. على سبيل المثال ، يمكنك ضبط الإعدادات الافتراضية "وضع علامة على كل صف 8192" ، ثم فهرسة الجدول "الضئيلة" في الجدول بـ 1 تريليون. الخطوط ، التي تناسبها بسهولة في الذاكرة ، سوف تشغل 122،070 حرفًا فقط.
تطوير النظام
يمكن تتبع تطوير وتحسين Clickhouse إلى
Github repo والتأكد من أن عملية "النمو" تسير بوتيرة مثيرة للإعجاب.
شعبية
يبدو Clickhouse أن ينمو بشكل كبير ، وخاصة في مجتمع الناطقين بالروسية. أظهر مؤتمر السنة الماضية High load 2018 (موسكو ، 8 - 9 نوفمبر 2018) أن الوحوش مثل vk.com و Badoo تستخدم Clickhouse ، حيث يقومون بلصق البيانات (على سبيل المثال ، السجلات) من عشرات الآلاف من الخوادم في نفس الوقت. في شريط فيديو مدته 40 دقيقة ،
يتحدث يوري ناسريتدينوف من فريق فكونتاكتي عن كيفية القيام بذلك . قريبا سننشر النص على هبر لراحة العمل مع المواد.
مجالات التطبيق
بعد أن قضيت بعض الوقت في البحث ، أعتقد أن هناك مجالات يمكن أن يكون ClickHouse فيها مفيدة أو قادرة على استبدال حلول أخرى أكثر تقليدية وشعبية بالكامل ، مثل MySQL و PostgreSQL و ELK و Google Big Query و Amazon RedShift ، TimescaleDB ، Hadoop ، MapReduce ، Pinot ، و Druid. فيما يلي تفاصيل حول استخدام ClickHouse للترقية أو استبدال قواعد البيانات المذكورة أعلاه بالكامل.
توسيع الخلية و PostgreSQL
في الآونة الأخيرة ، استبدلنا MySQL جزئيًا بـ ClickHouse لنظام منصة
الرسائل الإخبارية Mautic . كانت المشكلة أن MySQL ، بسبب تصميمها الخاطئ ، سجلت كل رسالة مرسلة وكل رابط في هذه الرسالة بعلامة base64 ، مما أدى إلى إنشاء جدول MySQL ضخم (email_stats). بعد إرسال 10 ملايين رسالة فقط لمشتركي الخدمات ، شغل هذا الجدول مساحة قدرها 150 جيجابايت ، وبدأ MySQL في "الاستغناء" في الاستعلامات البسيطة. لإصلاح مشكلة مساحة الملف ، استخدمنا بنجاح ضغط جدول InnoDB ، مما أدى إلى تقليله بمقدار 4 مرات. ومع ذلك ، لا يزال من غير المنطقي تخزين أكثر من 20 إلى 30 مليون بريد إلكتروني في MySQL فقط من أجل قراءة القصة ، لأن أي طلب بسيط يحتاج لسبب ما إلى إجراء مسح كامل يؤدي إلى مبادلة وتحميل كبير على I / O ، من أجل التي تلقينا بانتظام تحذيرات Zabbix.

يستخدم Clickhouse خوارزمي ضغط يخفضان كمية البيانات بحوالي
3-4 مرات ، ولكن في هذه الحالة بالذات كانت البيانات "قابلة للانضغاط" بشكل خاص.

استبدال ELK
بناءً على تجربتنا الخاصة ، تتطلب رصة ELK (ElasticSearch و Logstash و Kibana ، في هذه الحالة بالذات ، ElasticSearch) موارد أكثر بكثير لتشغيلها مما هو ضروري لتخزين السجلات. يعد تطبيق البحث المرن محركًا رائعًا إذا كنت بحاجة إلى بحث جيد في سجل النص الكامل (ولا أعتقد أنك في حاجة إليه حقًا) ، لكنني أتساءل لماذا ، في الواقع ، أصبح محرك التسجيل القياسي. خلقت أداء الاستقبال في تركيبة مع Logstash مشاكل بالنسبة لنا حتى مع حمولات صغيرة نوعا ما وتطلب إضافة كمية متزايدة من ذاكرة الوصول العشوائي ومساحة القرص. كقاعدة بيانات ، يعتبر Clickhouse أفضل من تطبيق البحث المرن للأسباب التالية:
- دعم لهجة SQL.
- أفضل نسبة ضغط البيانات المخزنة ؛
- دعم عمليات البحث العادية للتعبير regex بدلاً من عمليات البحث عن النص الكامل ؛
- تحسين تخطيط الاستعلام والأداء الكلي العالي.
في الوقت الحالي ، تتمثل المشكلة الأكبر التي تنشأ عند مقارنة ClickHouse مع ELK في عدم وجود حلول لسجلات الشحن ، فضلاً عن نقص الوثائق وأدوات التدريب على هذا الموضوع. في الوقت نفسه ، يمكن لكل مستخدم تكوين ELK باستخدام Digital Ocean Guide ، وهو أمر مهم للغاية للتنفيذ السريع لهذه التقنيات. يوجد محرك قاعدة بيانات هنا ، لكن لا يوجد Filebeat لـ ClickHouse حتى الآن. نعم ، هناك نظام
قوي للعمل مع سجلات
السجل ، وهناك أداة
clicktail لإدخال البيانات من ملفات السجل إلى ClickHouse ، لكن كل هذا يستغرق وقتًا أطول. ومع ذلك ، لا يزال ClickHouse يؤدي إلى بساطته ، لذلك حتى المبتدئين تثبيته بشكل أساسي والبدء في استخدامه بالكامل في 10 دقائق فقط.
بتفضيل حلول الحد الأدنى ، حاولت استخدام FluentBit ، وهي أداة لسجلات الشحن مع مقدار صغير جدًا من الذاكرة ، إلى جانب ClickHouse ، بينما أحاول تجنب استخدام Kafka. ومع ذلك ، يجب إصلاح عدم التوافق البسيط ، مثل
مشكلات تنسيق التاريخ ، قبل أن يتم ذلك دون وجود طبقة وكيل تحول البيانات من FluentBit إلى ClickHouse.
كبديل لـ Kibana ، يمكنك استخدام
Grafana كخلفية ClickHouse. كما أفهمها ، قد يتسبب ذلك في مشاكل في الأداء عند تقديم عدد كبير من نقاط البيانات ، خاصة مع الإصدارات القديمة من Grafana. في Qwintry ، لم نقم بتجربة ذلك بعد ، لكن الشكاوى المتعلقة بذلك من وقت لآخر تظهر على قناة دعم ClickHouse في Telegram.
استبدال Google Big Query و Amazon RedShift (حل للشركات الكبيرة)
حالة الاستخدام المثالية لـ BigQuery هي تنزيل 1 تيرابايت من بيانات JSON وإجراء استفسارات تحليلية عليها. Big Query هو منتج رائع يصعب المبالغة في تقديره. يعد هذا البرنامج أكثر تعقيدًا من ClickHouse ، الذي يعمل على نظام مجموعة داخلي ، ولكن من وجهة نظر العميل ، يوجد الكثير من القواسم المشتركة مع ClickHouse. يمكن أن يرتفع سعر BigQuery بسرعة بمجرد الدفع لكل SELECT ، لذلك هذا هو حل SaaS حقيقي بكل إيجابيات وسلبيات.
ClickHouse هو الخيار الأفضل عندما تقوم بالكثير من الاستعلامات باهظة الثمن من الناحية الحسابية. كلما زادت استعلامات SELECT التي تنفذها يوميًا ، كلما كان من المنطقي استبدال Big Query بـ ClickHouse ، لأن هذا الاستبدال سيوفر لك آلاف الدولارات عندما يتعلق الأمر بالعديد من تيرابايت من البيانات المعالجة. لا ينطبق هذا على البيانات المخزنة ، والتي تعتبر رخيصة جدًا للمعالجة في Big Query.
تتحدث مقالة مؤسس Altinity المؤسس ألكسندر زايتسيف ،
"التبديل إلى ClickHouse" ، عن فوائد عملية الترحيل DBMS هذه.
استبدال TimescaleDB
TimescaleDB هو امتداد PostgreSQL يعمل على تحسين العمل مع الجداول الزمنية للسلاسل الزمنية في قاعدة بيانات عادية (
https://docs.timescale.com/v1.0/introduction ،
https://habr.com/ar/company/zabbix/blog/458530 / ).
على الرغم من أن ClickHouse ليس منافسًا جادًا في مكانة السلاسل الزمنية ، ولكن بنية العمود وتنفيذ الاستعلامات الموجهة ، في معظم حالات معالجة الاستعلامات التحليلية ، يكون أسرع بكثير من TimescaleDB. في الوقت نفسه ، يكون أداء تلقي بيانات حزم ClickHouse أعلى بنحو 3 مرات ، بالإضافة إلى أنه يستخدم مساحة قرص أقل 20 مرة ، وهو أمر مهم حقًا لمعالجة كميات كبيرة من البيانات التاريخية:
https://www.altinity.com/blog/ClickHouse-for وقت السلسلة .
بخلاف ClickHouse ، فإن الطريقة الوحيدة لتوفير بعض مساحة القرص في TimescaleDB هي استخدام ZFS أو أنظمة الملفات المشابهة.
من المحتمل أن تقدم تحديثات ClickHouse القادمة ضغط دلتا ، مما يجعله أكثر ملاءمة لمعالجة وتخزين بيانات السلاسل الزمنية. قد يكون TimescaleDB اختيارًا أفضل من ClickHouse عارية في الحالات التالية:
- المنشآت الصغيرة مع كمية صغيرة جدا من ذاكرة الوصول العشوائي (أقل من 3 جيجابايت) ؛
- عدد كبير من INSERTs الصغيرة التي لا تريد المخزن المؤقت إلى أجزاء كبيرة؛
- أفضل الاتساق والتوحيد ومتطلبات حمض ؛
- دعم PostGIS
- الدمج مع جداول PostgreSQL الحالية ، لأن Timescale DB هو PostgreSQL بشكل أساسي.
المنافسة مع Hadoop و MapReduce Systems
تستطيع Hadoop وغيرها من منتجات MapReduce إجراء العديد من العمليات الحسابية المعقدة ، لكنها عادة ما تعمل بتأخير كبير ، حيث يعمل ClickHouse على حل هذه المشكلة عن طريق معالجة تيرابايت من البيانات وتقديم النتائج على الفور تقريبًا. وبالتالي ، فإن ClickHouse أكثر كفاءة لإجراء أبحاث تحليلية سريعة وتفاعلية ، والتي ينبغي أن تكون ممتعة لمتخصصي معالجة البيانات.
المنافسة مع Pinot و Druid
أقرب منافسي ClickHouse هم Pinot و Druid ، وهو منتج مفتوح المصدر قابل للخطي عموديًا. تم نشر عمل ممتاز لمقارنة هذه الأنظمة في مقال بقلم
رومان ليفنتوف بتاريخ 1 فبراير 2018.
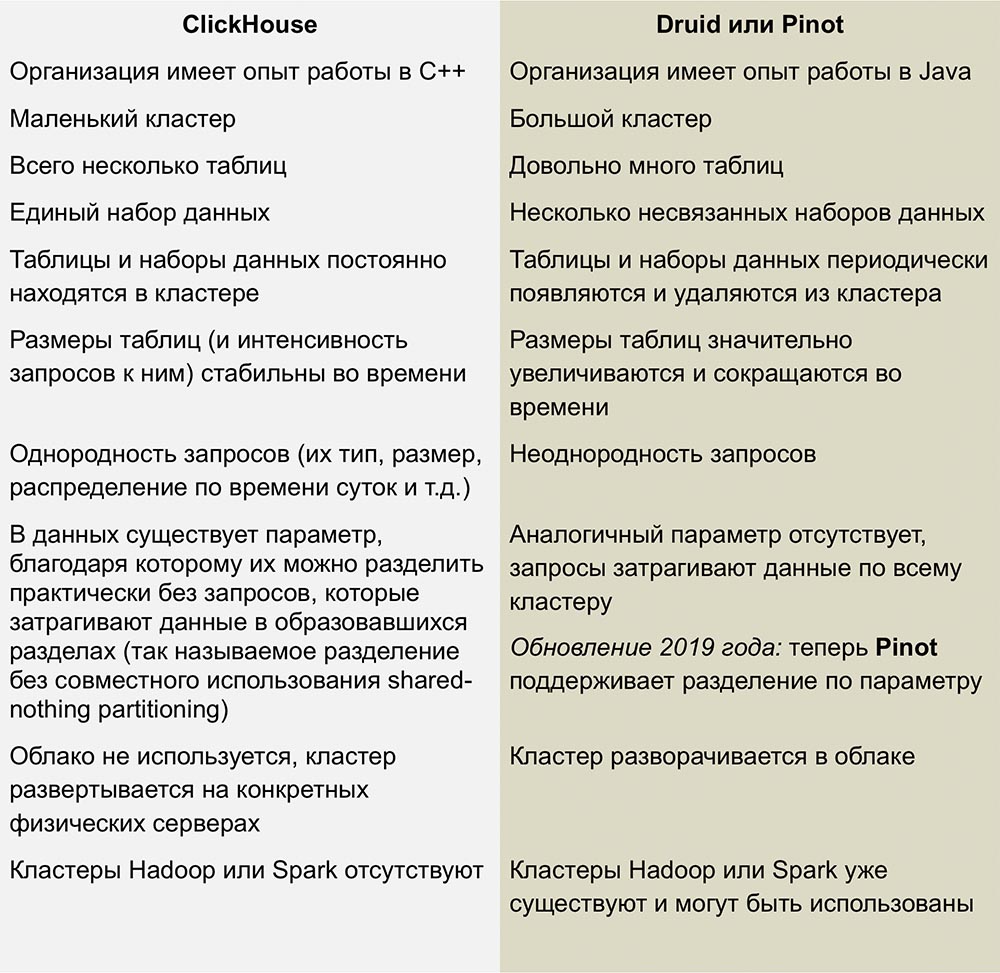
تتطلب هذه المقالة تحديثًا - تنص على أن ClickHouse لا يدعم عمليات التحديث والحذف ، وهذا غير صحيح تمامًا بالنسبة للإصدارات الأحدث.
ليست لدينا خبرة كافية مع قواعد بيانات إدارة قواعد البيانات هذه ، لكنني لا أحب تعقيد البنية التحتية المستخدمة لتشغيل Druid و Pinot - فهذه مجموعة كاملة من "الأجزاء المتحركة" التي تحيط بها Java من جميع الجهات.
Druid و Pinot هما مشروعا حاضنات Apache ، حيث يتم تغطية تقدم التطوير بالتفصيل بواسطة Apache على صفحات مشاريع GitHub. ظهر بينوت في الحاضنة في أكتوبر 2018 ، وولد درويد قبل 8 أشهر - في فبراير.
يعطيني نقص المعلومات حول كيفية عمل AFS بعض الأسئلة وربما الأسئلة السخيفة. أتساءل ما إذا كان مؤلفو Pinot قد لاحظوا أن مؤسسة Apache أكثر ميلًا إلى Druid ، وهل أدى هذا الموقف تجاه المنافس إلى الحسد؟ هل سيتباطأ تطور Druid وسيتسارع Pinot إذا أصبح الرعاة الذين يدعمون السابق مهتمين بالأخير؟
عيوب ClickHouse
عدم النضج: من الواضح أن هذه ليست تقنية مملة ، ولكن على أي حال ، لا يوجد شيء مماثل يلاحظ في أنظمة قواعد البيانات العمودي الأخرى.
لا تعمل المقحمات الصغيرة جيدًا بسرعة عالية: يجب تقسيم المقاطع إلى أجزاء كبيرة ، لأن أداء المقحمات الصغيرة يتناقص بنسبة عدد الأعمدة في كل صف. هذه هي الطريقة التي يقوم بها ClickHouse بتخزين البيانات على القرص - يعني كل عمود ملفًا واحدًا أو أكثر ، لذا لإدراج صف واحد يحتوي على 100 عمود ، يجب عليك فتح وكتابة 100 ملف على الأقل. هذا هو السبب في أن وسيطًا مطلوبًا للتخزين المؤقت (ما لم يوفر العميل نفسه التخزين المؤقت) - عادة ما يكون هذا هو Kafka أو نوع من نظام إدارة قائمة الانتظار. يمكنك أيضًا استخدام مشغل جدول Buffer لنسخ مجموعات كبيرة من البيانات لاحقًا في جداول MergeTree.
الصلات الجدول محدودة من قبل RAM الخادم ، ولكن على الأقل هناك! على سبيل المثال ، ليس لدى Druid و Pinot مثل هذه الاتصالات على الإطلاق ، حيث يصعب تنفيذها مباشرة في الأنظمة الموزعة التي لا تدعم نقل أجزاء كبيرة من البيانات بين العقد.
النتائج
في السنوات المقبلة ، نخطط للاستفادة بشكل كبير من ClickHouse في Qwintry ، حيث يوفر نظام إدارة قواعد البيانات هذا توازنًا ممتازًا للأداء ، وانخفاض الحمل ، وقابلية التوسع ، والبساطة. أنا متأكد من أنه سيبدأ الانتشار بسرعة بمجرد أن يأتي مجتمع ClickHouse بمزيد من الطرق لاستخدامه في المنشآت الصغيرة والمتوسطة.
قليلا من الإعلان :)
شكرا لك على البقاء معنا. هل تحب مقالاتنا؟ تريد أن ترى المزيد من المواد المثيرة للاهتمام؟ ادعمنا عن طريق تقديم طلب أو التوصية لأصدقائك
VPS المستندة إلى مجموعة النظراء للمطورين من 4.99 دولار ، وهو
تمثيلي فريد من الخوادم على مستوى الدخول التي اخترعناها لك: الحقيقة الكاملة حول VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps من 19 $ أو كيفية تقسيم الخادم؟ (تتوفر خيارات مع RAID1 و RAID10 ، ما يصل إلى 24 مركزًا وما يصل إلى 40 جيجابايت من ذاكرة DDR4).
Dell R730xd أرخص مرتين في مركز بيانات Equinix Tier IV في أمستردام؟ فقط لدينا
2 من Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6 جيجا هرتز 14 جيجا بايت 64 جيجا بايت DDR4 4 × 960 جيجا بايت SSD 1 جيجابت في الثانية 100 TV من 199 دولار في هولندا! Dell R420 - 2x E5-2430 سعة 2 جيجا هرتز 6 جيجا بايت 128 جيجا بايت ذاكرة DDR3 2x960GB SSD بسرعة 1 جيجابت في الثانية 100 تيرابايت - من 99 دولارًا! اقرأ عن
كيفية بناء البنية التحتية فئة باستخدام خوادم V4 R730xd E5-2650d تكلف 9000 يورو عن بنس واحد؟