
مقدمة
تعجبني البرمجة حقًا ، فأنا من هواة وأول مرة وآخر كسبت فيها أموالًا على البرمجة في عام 1996. لكن في بعض الأحيان أكتب شيئًا لأتمتة المهام اليومية. منذ حوالي عام ، تم اكتشاف golang. كأداة لإنشاء الأدوات المساعدة ، تبين أن golang مريحة للغاية. هكذا.
كانت هناك حاجة لمعالجة عدد كبير (أكثر من ألف ، وأرى ابتسامات مؤيد) من ملفات الأرشيف مع معلومات الجيوفيزيائية الخاصة. تنسيق الملف نص بسيط. إذا كنت مهتمًا فجأة فهذا تنسيق LAS .
يحتوي ملف LAS على رأس وبيانات.
البيانات عبارة عن ملف CSV عمليًا ، فقط محدد علامات تبويب أو مسافات.
ويحتوي العنوان على وصف للبيانات وهنا عادة ما يحتوي على نص روسي. قد يكون هذا هو اسم الحقل ، واسم الدراسات المسجلة في ملف ، إلخ.
تم إنشاء هذه الملفات في أوقات مختلفة وفي برامج مختلفة ، الأمر الذي يشير إلى أنه في جزء ملف واحد تم ترميزه في CP1251 ، وجزء في CP866. أحتاج إلى معالجة هذه الملفات ، مما يعني أن أفهم. لذلك كان مطلوبًا تحديد ترميز الملف تلقائيًا.
ونتيجة لذلك ، اخترع دراجة هوائية على golang ، وبالتالي ، وُلدت مكتبة صغيرة لديها القدرة على اكتشاف صفحة الرموز.
حول الترميزات. منذ وقت ليس ببعيد على habr كان هناك مقال جيد حول الترميزات كيف تعمل ترميزات النص. من أين تأتي التماسيح؟ مبادئ الترميز. التعميم والتحليل المفصل: إذا كنت تريد أن تفهم ما هي "العظام" أو "العظام" ، فإن الأمر يستحق القراءة.
في البداية رميت قراري. ثم حاولت أن أجد حلًا عمليًا جاهزًا على golang ، لكنني فشلت. كان هناك حلان ، ولكن كلاهما لا يعملان.
- أول "خارج الصندوق" - وظيفة golang.org/x/net/html/charset DetermineEncoding ()
- المكتبة الثانية - القديسين / chardet على جيثب
كلاهما مخطئ بالتأكيد في بعض الترميزات. لا يمكن للمعيار بشكل عام تحديد أي شيء تقريبًا من الملفات النصية ، وهو أمر مفهوم ، وقد تم إجراؤه لصفحات HTML.
عند البحث ، غالبًا ما صادفت أدوات مساعدة جاهزة من عالم linux - enca . العثور على إصدار المترجمة لـ WIN32 ، الإصدار 1.12. أنا أيضا سوف تنظر في ذلك ، هناك أشياء ممتعة هناك. أعتذر على الفور عن جهلي الكامل لنظام التشغيل linux ، مما يعني أنه من المحتمل أن يكون هناك المزيد من الحلول التي يمكنك أيضًا محاولة حلها وفقًا لرمز golang ، لم أعد أبحث.
مقارنة بين الحلول الموجودة لترميز الاكتشاف التلقائي
أعد كتالوج بيانات اختبار softlandia \ cpd مع ملفات بترميزات مختلفة. محتويات الملفات قصيرة جدا ونفس الشيء. سطر واحد "الروسية في الترميز CodePageName". أضفت الملفات مع مزيج من الترميزات وبعض الحالات المعقدة وحاولت تحديد.
أعتقد أنه تبين مضحك.
الملاحظة 1
لم يحدد enca ترميز ملف UTF-16LE بدون BOM - هذا غريب ، حسنًا. حاولت إضافة المزيد من النص ، لكن لم أحصل على النتيجة.
الملاحظة 2. مشاكل الترميز CP1251 و KOI8-R
السطور 15 و 16. الأمر enca لديه مشاكل.
سأشرح هنا ، الحقيقة هي أن تشفير CP1251 (المعروف أيضًا باسم Windows 1251) و KOI8-R قريبان جدًا إذا أخذنا في الاعتبار الأحرف الأبجدية فقط.
الجدول CP 1251
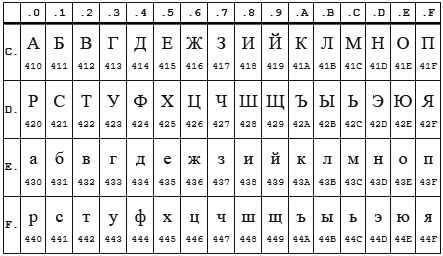
طاولة KOI8-r

في كلا الترميزين ، تقع الأبجدية من 0xC0 إلى 0xFF ، ولكن عندما يكون لأحد الترميز حروف كبيرة ، يكون الآخر صغيرًا. ويبدو أن enca يعمل بأحرف صغيرة. هكذا اتضح ، إذا أرسلت السلسلة "STP" المشفرة في CP1251 إلى برنامج enca ، فسوف تقرر أنها السلسلة "شديدة" المشفرة في KOI8-r ، والتي سيتم الإبلاغ عنها. عكس يعمل أيضا.
الملاحظة 3
لا يمكن الوثوق بالمكتبة القياسية لـ html / charset إلا من خلال تعريف UTF-8 ، ولكن كن حذرًا! يجب استخدامه charset.DetermineEncoding () بالضبط ، لأن طريقة utf8.Valid (b [] byte) على الملفات المشفرة utf-16be تُرجع إلى true .
الدراجة الخاصة

لا يمكن الكشف التلقائي عن الترميز إلا عن طريق الأساليب التجريبية ، غير الدقيقة. إذا لم نكن نعرف أي لغة وبأي نوع من ترميز الملف النصي المكتوب ، فمن الممكن تحديد الترميز بدقة عالية ، لكن سيكون الأمر صعبًا ... وستحتاج إلى الكثير من النص.
بالنسبة لي ، لم يتم تحديد هذا الهدف. يكفي بالنسبة لي لتحديد الترميزات على افتراض أن هناك الروسية. وثانيا ، تحتاج إلى تحديد عدد صغير من الأحرف - يجب أن يكون لدى 10 أحرف تعريف واثق إلى حد ما ، ويفضل أن يكون 5-6 أحرف بشكل عام.
خوارزمية
عندما اكتشفت مصادفة الترميزين KOI8-r و CP1251 حسب موقع الأبجدية ، كنت حزينًا لبضعة أيام ... أصبح من الواضح أنه كان علي التفكير قليلاً. اتضح مثل هذا.
القرارات الرئيسية:
- سنعمل مع شريحة من البايتات ، من أجل التوافق مع charset.DetermineEncoding ()
- يتم فحص حالات ترميز UTF-8 و BOM بشكل منفصل
- يتم تمرير بيانات الإدخال بدوره إلى كل ترميز. كل نفسه يحسب اثنين من معايير عدد صحيح. الذي جمع اثنين من المعايير هو أكبر ، وفاز.
معايير الامتثال
المعيار الأول
المعيار الأول هو عدد الأحرف الأكثر شيوعًا في الأبجدية الروسية.
الأحرف الأكثر شيوعًا هي: o ، e ، a ، و ، n ، t ، s ، p ، b ، l ، k ، m ، d ، p ، y . هذه الرسائل تعطي تغطية 82 ٪. بالنسبة لجميع الترميزات باستثناء KOI8-r و CP1251 ، استخدمت الأحرف التسعة الأولى فقط: o ، e ، a ، و ، n ، t ، s ، p ، c. هذا يكفي لتحديد موثوق.
ولكن ل KOI8-r و CP1251 اضطررت إلى تعديل الملف. تتزامن أكواد بعض هذه الحروف ، على سبيل المثال ، يحتوي الحرف o على الرمز 0xEE في CP1251 ، بينما في KOI8-r يحتوي هذا الرمز على الحرف n . اتخذت الحروف الشعبية التالية لهذه الترميزات. بالنسبة إلى CP1251 ، استخدمت a ، و ، n ، c ، p ، b ، l ، k ، i. بالنسبة إلى KOI8-r - o ، a ، u ، t ، s ، b ، l ، k ، m.
المعيار الثاني
لسوء الحظ ، بالنسبة للحالات القصيرة جدًا (يبلغ الطول الإجمالي للنص الروسي 5-6 أحرف) ، فإن حدوث الأحرف الشائعة يكون في مستوى 1-3 أجهزة كمبيوتر وهناك تداخل بين ترميزات KOI8-r و CP1251. اضطررت لتقديم معيار ثان. بالتوافق + حرف علة العد .
من المتوقع أن تحدث هذه المجموعات في الغالب باللغة الروسية ، وبالتالي ، في هذا الترميز الذي يكون فيه عدد هذه الأزواج أكبر ، فإن الترميز لديه معيار أكبر.
يتم احتساب كلا المعيارين وإضافته والمبلغ المستلم هو المعيار النهائي.
تظهر النتيجة في الجدول أعلاه.
ميزات واجهت
لمسة صغيرة على السحر والمشاكل المرتبطة golang. قد يكون القسم ممتعًا للمبتدئين فقط للكتابة بلغة غولانغ.
المشاكل
تجول شخصياً حول بعض الحصى الموجودة تحت 50 ظلال من Go: الفخاخ والمزالق والأخطاء الشائعة للمبتدئين .
كان القلق المفرط ومحاولة النفخ في الماء ، والاستماع من الآخرين حول الحروق الرهيبة من الحليب ، أبعد من التحقق من معلمة الإدخال من نوع io.Reader. راجعت متغير مثل io.Reader مع التفكير.
ولكن كما اتضح في حالتي ، يكفي التحقق من عدم وجود شيء. الآن كل شيء أسهل
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
استدعاء bufio.NewReader (r) .Peek (ReadBufSize) يمر بهدوء الاختبار التالي:
var data *os.File res, err := CodePageDetect(data)
في هذه الحالة ، ترجع Peek () خطأ.
صعدت مرة واحدة على أشعل النار مع نقل المصفوفات من حيث القيمة. غبي قليلاً عند محاولة تغيير العناصر المخزنة في الخريطة ، من خلال تشغيلها في النطاق ...
مفاتن
من الصعب أن نقول بالضبط ما إذا كانت ثابتة المصافحة من linter والمترجم أو الاستخدام الفعال للنطاق ، أو كل ذلك معا ، ولكن لا توجد توغلات عمليا لإخراج الفهرس من الحدود.
بالطبع ، من الجيد جدًا العيش مع جامع القمامة. أفترض أنه لا يزال يتعين علي إتقان أشعل النار في تخصيص / إطلاق الذاكرة ، لكن الابتسامة الشريرة حتى الآن لا تترك وجهي.
الكتابة القوية هي أيضًا جزء من السعادة.
المتغيرات التي لها نوع من الوظيفة هي ، بالتالي ، تطبيق سهل للسلوكيات المختلفة للكائنات من نفس النوع.
كان قليلا غريب للجلوس في المصحح ، وإعادة قراءة رمز عادة ما يعطي النتيجة.
جرو فرحة من وجود الكثير من الأدوات من خارج منطقة الجزاء ، إنه شعور رائع عندما يعمل المترجم واللغة والمكتبة والرمز البصري IDE Visual Studio معك بشكل متناغم.
شكرا فالكوندي على نصائح بناءة ومفيدة.
شكرا له
- الاختبارات المترجمة على شهادة وأصبحت حقا أكثر قابلية للقراءة
- اختبارات ثابتة لمسارات ملفات البيانات للتوافق مع Linux
- مشى من قبل linter - ومع ذلك وجد خطأ حقيقيًا واحدًا (نسخة اللعنة / الماضي)
ما زلت لإضافة اختبارات ، تم الكشف عن حالة عدم تحديد UTF16. المحدثة. الآن يتم الكشف عن UTF16 و LE و BE حتى في حالة عدم وجود الحروف الروسية