في هذه المقالة ، أود أن أشارك تجربتي في استخدام هذه المكتبة مفتوحة المصدر على سبيل المثال لتنفيذ مهمة واحدة من خلال تحليل
ملفات PDF / DOC / DOCX التي تحتوي على سير ذاتية للمتخصصين.
سوف أصف هنا أيضًا مراحل تنفيذ الأداة لإعداد مجموعة البيانات. بعد ذلك ، سيكون من الممكن تدريب نموذج
BERT على مجموعة البيانات المستلمة كجزء من مهمة التعرف على الكيانات من النصوص (
Named Entity Recognition - من الآن فصاعدا
NER ).
لذلك ، من أين تبدأ. بطبيعة الحال ، تحتاج أولاً إلى تثبيت البيئة وتكوينها لتشغيل الأداة الخاصة بنا. سأقوم بتثبيت على
نظام التشغيل Windows 10 .
يوجد في Habré بالفعل العديد من المقالات من مطوري هذه المكتبة ، حيث يوجد فقط دليل تثبيت مفصل. وفي هذه المقالة ، أود أن أجمع كل شيء ، من الإطلاق إلى التدريب النموذجي. سأشير أيضًا إلى حلول لبعض المشكلات التي واجهتها أثناء العمل مع هذه المكتبة.
هام: عند التثبيت ، من المهم الامتثال لإصدارات جميع المنتجات والمكونات ، لأنه غالبًا ما توجد مشكلات في الإصدارات غير المتوافقة. هذا ينطبق بشكل خاص على مكتبة TensorFlow . حتى أنه يحدث بالنسبة لبعض المهام ، وحتى الالتزام الضروري على GitHub ، تحتاج إلى استخدامه. في حالة DeepPavlov ، يكفي الامتثال للنسخة المدعومة فقط.
سأشير إلى إصدارات منتجات تكوين العمل ومواصفات جهاز الكمبيوتر المحمول الذي بدأت عليه عملية تدريب الشبكة العصبية. سأقدم بعض الروابط التي تصف أيضًا تثبيت وتكوين مكتبة
DeepPavlov مفتوحة المصدر.
روابط مفيدة من مطوري DeepPavlov
إصدارات المكونات للتثبيت
- بيثون 3.6.6 - 3.7
- Visual Studio Community 2017 (اختياري)
- أدوات إنشاء Visual C ++ 14.0.25420.1
- nVIDIA CUDA 10.0.130_411.31_win10
- cuDNN-10.0 windows10-إلى x64 v7.6.5.32
إعداد البيئة لدعم GPU
- قم بتثبيت Python أو Visual Studio Community 2017 المضمنة مع Python . في التثبيت الخاص بي ، استخدمت الطريقة الثانية ، وهي تثبيت Visual Studio Community مع دعم Python .
بالطبع ، عليك إضافة المسار إلى المجلد يدويًاC:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64
إلى متغير نظام PATH ، حيث يتم تثبيت Python من Visual Studio ، لكن هذه ليست مشكلة بالنسبة لي ، من المهم بالنسبة لي أن أعرف أنني قمت بتثبيت إصدار واحد لـ Python .
ولكن هذه هي حالتي ، يمكنك تثبيت كل شيء على حدة. - الخطوة التالية هي تثبيت أدوات إنشاء Visual C ++ .
- بعد ذلك ، قم بتثبيت nVIDIA CUDA .
هام: إذا كانت مكتبة nVIDIA CUDA مثبتة مسبقًا ، فيجب عليك إزالة جميع المكونات المثبتة مسبقًا من nVIDIA ، وحتى برنامج تشغيل الفيديو. وفقط عند التثبيت النظيف لبرنامج تشغيل الفيديو ، قم بإجراء تثبيت nVIDIA CUDA .
- الآن تثبيت cuDNN ل nVIDIA CUDA .
للقيام بذلك ، تحتاج إلى التسجيل للحصول على عضوية برنامج مطور NVIDIA (مجاني).

- قم بتنزيل إصدار cuDNN لـ CUDA 10.0

- فك الأرشيف في مجلد
C:\Users\<_>\Downloads\cuDNN
- انسخ محتويات المجلد بالكامل .. \ cuDNN إلى المجلد حيث قمنا بتثبيت CUDA
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
- أعد تشغيل الكمبيوتر. اختياري ، لكنني أوصي.
تثبيت DeepPavlov
- إنشاء وتفعيل بيئة بيثون الافتراضية.
هام: لقد فعلت ذلك من خلال Visual Studio.
- للقيام بذلك ، قمتُ بإنشاء مشروع جديد لكود From Python code .

- نضغط أكثر على النافذة الأخيرة ، لكن في النهاية ، لا نضغط حتى الآن. يجب إلغاء تحديد " الكشف عن البيئات الافتراضية "

- انقر فوق " إنهاء" .
- تحتاج الآن إلى إنشاء بيئة افتراضية.

- نترك كل شيء افتراضيا.

- افتح مجلد المشروع في سطر الأوامر. وتنفيذ الأمر:
.\env\Scripts\activate.bat

- الآن كل شيء جاهز لتثبيت DeepPavlov . نحن ننفذ الأمر:
pip install deeppavlov
- بعد ذلك ، تحتاج إلى تثبيت TensorFlow 1.14.0 بدعم GPU . للقيام بذلك ، قم بتشغيل الأمر:
pip install tensorflow-gpu==1.14.0
- تقريبا كل شيء جاهز. ما عليك سوى التأكد من أن TensorFlow سيستخدم بطاقة الرسومات لإجراء العمليات الحسابية. للقيام بذلك ، نكتب برنامج نصي بسيط devices.py ، المحتويات التالية:
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
أو tensorflow_test.py :
import tensorflow as tf tf.test.is_built_with_cuda() tf.test.is_gpu_available(cuda_only=False, min_cuda_compute_capability=None)
- بعد تشغيل devices.py ، يجب أن نرى شيئًا مما يلي:
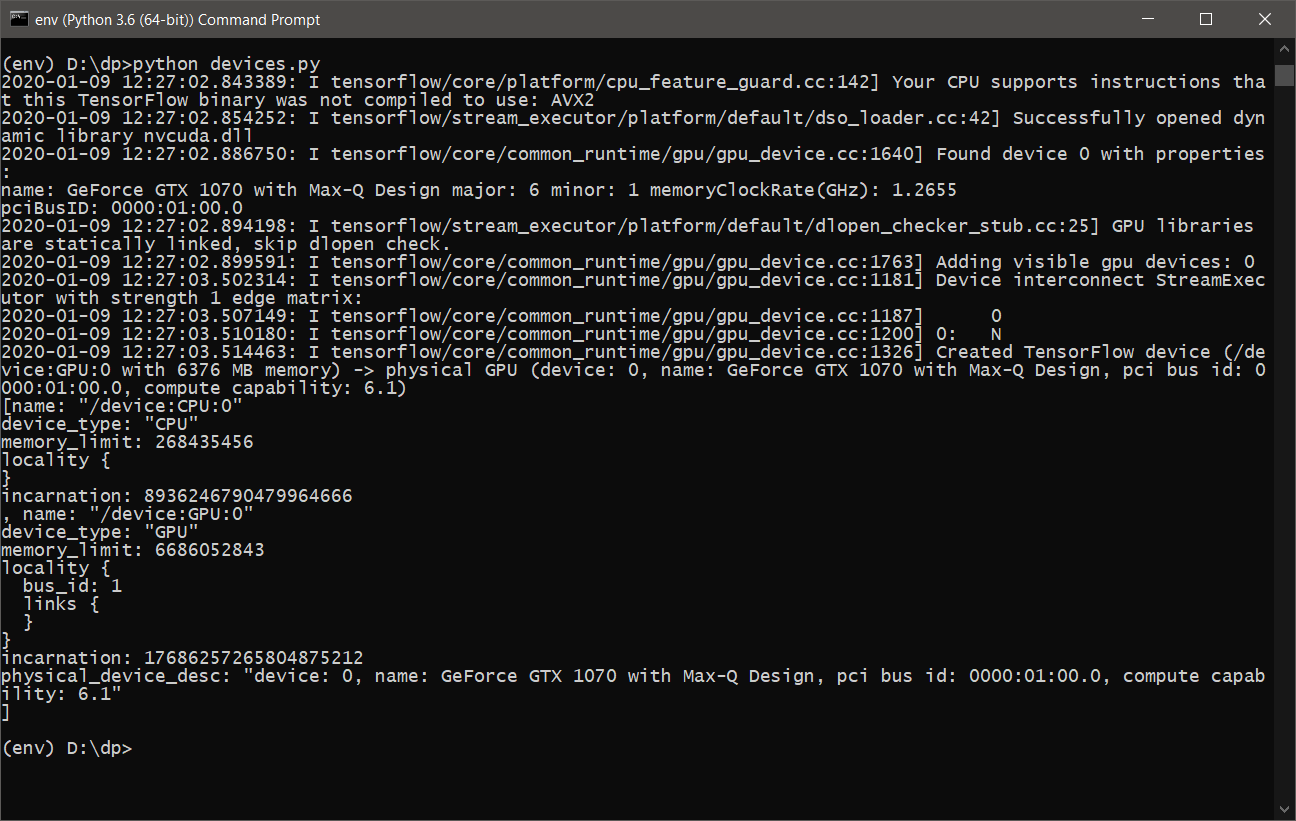
- أنت الآن جاهز للتعلم واستخدام DeepPavlov مع دعم GPU .
DeepPavlov على REST API
لبدء وتثبيت الخدمة لـ REST API ، تحتاج إلى تشغيل الأوامر التالية:
- تثبيت في بيئة افتراضية نشطة
python -m deeppavlov install ner_ontonotes_bert_mult
- قم بتنزيل نموذج ner_ontonotes_bert_mult من خوادم DeepPavlov
python -m deeppavlov download ner_ontonotes_bert_mult
- تشغيل REST API
python -m deeppavlov riseapi ner_ontonotes_bert_mult -p 5005
سيكون هذا النموذج متاحًا على
الموقع http: // localhost: 5005 . يمكنك تحديد المنفذ الخاص بك.
سيتم تنزيل جميع الطرز بشكل افتراضي على طول الطريق.
C:\Users\<_>\.deeppavlov
إعداد DeepPavlov للتدريب
قبل البدء في عملية التعلم ، نحتاج إلى تكوين
DeepPavlov بحيث لا
تتعطل عملية التعلم بسبب خطأ امتلاء الذاكرة الموجودة على بطاقة الفيديو الخاصة بنا. لهذا ، لدينا ملفات التكوين لكل نموذج.
كما في المثال من المطورين ،
سأستخدم أيضًا نموذج
ner_ontonotes_bert_mult . توجد جميع التكوينات الافتراضية لـ
DeepPavlov على طول المسار:
<_>\env\Lib\site-packages\deeppavlov\configs\ner
في حالتي ، سيتم تسمية الملف مثل نموذج
ner_ontonotes_bert_mult.json .
لتهيئة الكمبيوتر المحمول ، اضطررت لتغيير قيمة
batch_size في كتلة
القطار إلى 4.

خلاف ذلك ، تم اختناق بطاقة الفيديو الخاصة بي بعد بضع دقائق ، وسقطت عملية التعلم بسبب خطأ.
التكوين نوبوك
- الموديل: MSI GS-65
- المعالج: كور i7 8750H 2200 ميغاهيرتز
- مقدار الذاكرة المثبتة: 32 جيجابايت DDR-4
- القرص الصلب: 512 جيجابايت SSD
- بطاقة الفيديو: GeForce GTX 1070 8192 Mb
أداة إعداد مجموعة البيانات
من أجل تدريب النموذج ، تحتاج إلى إعداد مجموعة بيانات. تتكون مجموعة البيانات من ثلاثة ملفات
train.txt و
valid.txt و
test.txt . مع تفصيل البيانات في النسبة المئوية التالية من القطار - 80 ٪ ، صالحة واختبار 10 ٪.
مجموعة البيانات لنموذج BERT هي كما يلي:
Ivan B-PERSON Ivanov I-PERSON Senior B-WORK_OF_ART Java I-WORK_OF_ART Developer I-WORK_OF_ART IT B-ORG - I-ORG Company I-ORG Key O duties O : 0 Java B-WORK_OF_ART Python B-WORK_OF_ART CSS B-WORK_OF_ART JavaScript B-WORK_OF_ART Russian B-LOC Federation I-LOC . O Petr B-PERSON Petrov I-PERSON Junior B-WORK_OF_ART Web I-WORK_OF_ART Developer I-WORK_OF_ART Boogle B-ORG IO ' O ve O developed O Web B-WORK_OF_ART - O Application O . Skills O : O ReactJS B-WORK_OF_ART Vue B-WORK_OF_ART - I-WORK_OF_ART JS I-WORK_OF_ART HTML B-WORK_OF_ART CSS B-WORK_OF_ART Russian B-LOC Federation I-LOC . O ...
تنسيق مجموعة البيانات كما يلي:
<_><><_>
هام: بعد نهاية الجملة ، يجب أن يكون هناك فاصل أسطر. إذا كان العرض يحتوي على أكثر من 75 رمزًا ، فمن الضروري أيضًا وضع استراحة ، وإلا عند معرفة النموذج ستفشل العملية.
لإعداد مجموعة البيانات ، كتبت واجهة ويب حيث يمكن تحميل ملفات
DOC / PDF / DOCX إلى خادم ، وتحليلها في نص عادي ، ثم تمرير هذا النص من خلال نموذج نشط مع وصول REST API مع حفظ النتيجة في قاعدة بيانات وسيطة. لهذا أنا استخدم
MongoDB .
بعد الانتهاء من الإجراءات المذكورة أعلاه ، يمكنك المتابعة إلى تشكيل مجموعة البيانات لتلبية احتياجاتنا.
للقيام بذلك ، قمت بإنشاء لوحة منفصلة في واجهة الويب المكتوبة الخاصة بي ، حيث يمكن البحث عن طريق الرموز المميزة لمجموعة البيانات ثم تغيير نوع الرمز المميز والنص المميز نفسه.
تعرف الأداة أيضًا كيفية تحديث نوع الرمز المميز الذي يحدده المستخدم عند الطلب تلقائيًا ، بناءً على قائمة الكلمات.
بشكل عام ، تساعد الأداة في أتمتة جزء من العمل ، ولكن لا يزال يتعين عليك القيام بالكثير من العمل اليدوي.
يتم أيضًا تطبيق واجهة لفحص النتيجة وتقسيم مجموعة البيانات إلى ثلاثة ملفات.
تدريب DeepPavlov
لذلك وصلنا إلى الجزء الأكثر إثارة للاهتمام. لعملية التعلم ، تحتاج أولاً إلى تنزيل نموذج
ner_ontonotes_bert_mult ، إذا لم تكن قد قمت بذلك بالفعل ، فستحتاج إلى إكمال الخطوتين الأولين من قسم
DeepPavlov إلى واجهة برمجة تطبيقات REST أعلاه.
قبل البدء في عملية التعلم ، يجب عليك إكمال خطوتين:
- احذف المجلد بالكامل باستخدام النموذج المدربين:
C:\Users\<_>\.deeppavlov\models\ner_ontonotes_bert_mult
منذ تم تدريب هذا النموذج على مجموعة بيانات مختلفة. - انسخ ملفات مجموعة البيانات المعدة ، train.txt و valid.txt و test.txt إلى المجلد
C:\Users\<_>\.deeppavlov\downloads\ontonotes
الآن يمكنك البدء في عملية التعلم.
لبدء التدريب ، يمكنك كتابة برنامج نصي
train.py بسيط من النموذج التالي:
from deeppavlov import configs, train_model ner_model = train_model(configs.ner.ner_ontonotes_bert_mult, download=False)
أو استخدم سطر الأوامر:
python -m deeppavlov train <_>\env\Lib\site-packages\deeppavlov\configs\ner\ner_ontonotes_bert_mult.json
النتائج
قمت بتدريب نموذج على مجموعة بيانات بحجم 115.540 رمزًا. تم إنشاء مجموعة البيانات هذه من 100 ملف من ملفات استئناف الموظفين. استغرقت عملية التعلم 5 ساعات و 18 دقيقة.
كان للنموذج المعاني التالية:
- الدقة: 76.32 ٪ ؛
- أذكر: 72.32 ٪ ؛
- FB1: 74.27 ؛
- الخسارة: 5.4907482981681826 ؛
بعد تحرير العديد من المشكلات في الإنشاء التلقائي لمجموعة البيانات ، تلقيت
خسارة أدناه. لكن بشكل عام ، كنت سعيدًا بالنتيجة. بالطبع ، لا يزال لدي العديد من الأسئلة حول استخدام هذه المكتبة ، وما وصفته هنا هو مجرد قطرة في المجموعة.
أحببت المكتبة حقًا لبساطتها وسهولة استخدامها. على الأقل لمهمة
NER . سأكون سعيدًا جدًا لمناقشة الميزات الأخرى لهذه المكتبة ، وآمل أن يجد شخص ما مادة هذه المادة مفيدة.