مرحبا بالجميع!
ربما تعرف بالفعل مبادرة مبادرة التعلم من أجل الخير الاجتماعي (# ml4sg) لمجتمع علوم البيانات المفتوحة. في إطاره ، يستخدم المتحمسون أساليب التعلم الآلي لحل المشكلات ذات الأهمية الاجتماعية على أساس حر. نحن ، فريق مشروع Lacmus (#proj_rescuer_la) ، نشارك في تنفيذ حلول التعليم العميق الحديثة للعثور على الأشخاص الذين فقدوا خارج المنطقة المأهولة بالسكان: في الغابة ، الحقل ، إلخ.

وفقا لتقديرات تقريبية ، في روسيا أكثر من مائة ألف شخص يختفون كل عام. الجزء الملموس منهم هم الأشخاص الذين فقدوا طريقهم بعيدًا عن السكن البشري. لحسن الحظ ، يتم اختيار بعض من فقدوا بأنفسهم ؛ يتم تعبئة فرق البحث والإنقاذ المتطوعين لمساعدة الآخرين. أشهر هذه الانفصال هي ليزا أليرت ، لكنني أريد أن أشير إلى أنه ليس الوحيد.
تتمثل طرق البحث الرئيسية في الوقت الحالي ، في القرن الحادي والعشرين ، في تمشيط المناطق المحيطة سيراً على الأقدام باستخدام الوسائل التقنية ، والتي غالباً ما لا تكون أكثر تعقيدًا من صفارات الإنذار أو المنارة الصاخبة. الموضوع ، بالطبع ، ذو صلة وساخن ، يثير العديد من الأفكار لاستخدام التقدم العلمي والتكنولوجي في البحث عن الإنجازات ؛ تم تجسيد بعضها في شكل نماذج أولية واختبارها في مسابقات منظمة خصيصًا. لكن الغابة هي الغابة ، والظروف الحقيقية للبحث ، إلى جانب الموارد المادية المحدودة ، تجعل هذه المشكلة صعبة ولا تزال بعيدة عن الحل الكامل.
في الآونة الأخيرة ، يستخدم رجال الإنقاذ على نحو متزايد المركبات الجوية غير المأهولة (UAVs) لمسح مناطق واسعة من الإقليم ، وتصوير التضاريس من ارتفاع 40-50 متر. من خلال عملية بحث وإنقاذ واحدة ، يتم الحصول على عدة آلاف من الصور الفوتوغرافية ، والتي حتى الآن ، يبحث المتطوعون يدويًا. من الواضح أن هذه المعالجة طويلة وغير فعالة. بعد ساعتين من هذا العمل ، أصبح المتطوعون متعبين ولا يمكنهم مواصلة البحث ، وبعد كل شيء ، فإن صحة الأشخاص وحياتهم تعتمد على سرعته.
بالتعاون مع فرق البحث والإنقاذ ، نقوم بتطوير برنامج للبحث عن الأشخاص المفقودين في الصور الملتقطة باستخدام الطائرات بدون طيار. كمتخصصين في التعلم الآلي ، نحن نسعى جاهدين لجعل البحث تلقائيًا وسريعًا.

الاختلافات من حلول مماثلة
سيكون من الظلم القول أن Lacmus هو المشروع الوحيد الذي يتم تطويره في هذا الاتجاه. ومع ذلك ، يبدو أن قلة قليلة من الناس تتطور بالتعاون الوثيق مع فرق الإنقاذ ، مع التركيز على احتياجاتهم وقدراتهم العاجلة. منذ بعض الوقت ، عقدت مسابقة Odyssey ، حيث تنافست فرق مختلفة في تشكيل أفضل حل للبحث عن الأشخاص وإنقاذهم ، بما في ذلك استخدام الطائرات بدون طيار. في المرحلة الأولى من التطوير ، حضرنا هذه المسابقة ليس كمشاركين ، ولكن كمراقبين. بمقارنة نتائج المسابقة ، ومعلومات حول مشاريع مماثلة وتجربتنا في التواصل مع فرق مثل ليزا أليرت ، أوول ، إكستريم ، أريد أن أشير إلى المشاكل الكامنة في العديد من نظائرها:
- تكلفة التنفيذ. تقوم بعض الفرق من مسابقة Odyssey بتطوير طائرات بدون طيار وطائرات بدون طيار مبتكرة. لكن عليك أن تفهم أن PSO في روسيا تعمل عادة على أساس غير ربحي ، وأن تزويد مشغلي الطائرات بدون طيار بأجهزة تبلغ قيمتها أكثر من 1،000،000 روبل باهظ الثمن. بالإضافة إلى ذلك ، لا يكفي إنتاج طائرة فقط ، بل من الضروري إنشاء صيانتها. من الصعب على الشركات الصغيرة تقديم حلول لنفس المال مثل حلول الشركات الصينية المنافسة.
- التركيز التجاري للعديد من الحلول. لا حرج في مشاريع الأعمال ، ولكن العثور على أشخاص فقدوا في الغابة مهمة محددة إلى حد ما ؛ لا يمكن دمج كل تطوير تجاري فيها. يمكنك إنشاء طائرة بدون طيار رائعة والعصا على خلية عصبية تتعرف على المحاصيل هناك ، ولكن من غير المرجح أن يكون هذا المشروع مفيدًا للعثور على أشخاص في الغابة باستخدام فرق البحث التطوعية: هنا تحتاج إلى حل أرخص ولكنه فعال. كاميرات متعددة القنوات باهظة الثمن ليست مناسبة هنا. فقط RGB ، المتشددين فقط. وللأسباب نفسها ، تختفي أجهزة التصوير الحرارية أيضًا ، حيث تتميز النماذج الرخيصة منها بدقة منخفضة للغاية. (وبصفة عامة ، فإن التصوير الحراري غير فعال هنا ، لأن الشخص المتجمد في الغابة ينبعث منه حرارة قليلة جدًا).
- تتمتع بنيات الشبكات العصبية الشائعة المستخدمة في الحلول المعروفة - YOLO و SSD و VGG - بمقاييس ذات جودة جيدة في مجموعات البيانات العامة مثل ImageNet ، ولكنها لا تعمل بشكل جيد على الصور في مجالنا المحدد نوعًا ما. (حول اختيار بنية الشبكة العصبية والخيارات والميزات التي تم تجربتها واختبارها المستخدمة في النهاية - أدناه).
- تقريبا لا أحد يستخدم الفرص لتحسين النماذج للاستدلال. في مناطق البحث ، غالبًا ما لا يوجد اتصال بالإنترنت ، لذلك تحتاج إلى معالجة الصور المستلمة محليًا. يستخدم معظم رجال الإنقاذ أجهزة الكمبيوتر المحمولة مع وحدات معالجة الرسومات منخفضة الطاقة ، أو بدونها على الإطلاق ، التي تدير شبكات عصبية على وحدات المعالجة المركزية التقليدية. من السهل حساب أنه إذا تم إنفاق 10 ثوان في المتوسط على معالجة صورة واحدة ، فستتم معالجة 1000 صورة في حوالي 3 ساعات. هنا ، يمكننا أن نقول أن كل ثانية مهمة.
- إغلاق التطورات الحالية. جميع الحلول التي نعرفها مغلقة ومملوكة. لكن المشكلة معقدة للغاية ولا يمكن حلها بواسطة قوى حفنة صغيرة من الناس ، وليس كلهم على استعداد للمساعدة. لذلك ، نحن نعمل على تطوير حل مفتوح المصدر بالكامل: من الغريب الاعتقاد بأن موضوعًا يجذب الكثير من المتطوعين الذين يعملون "في الحقول" لن يكون بنفس القدر من الاهتمام لمتخصصي تكنولوجيا المعلومات.
- عدم وجود حرية التوزيع. غالبًا ما تكون مراكز دعم البرامج التطوعية غير مركزية ، حيث يتم نقل أساليب العمل والتطبيقات من يد إلى آخر ، ولن يعمل البرنامج الذي يحتوي على نسخ مرخصة هنا. هذا هو السبب في أننا ، من بين أمور أخرى ، اخترنا استراتيجية مفتوحة المصدر والتوزيع المفتوح بحيث يمكن لأي شخص تنزيل حلنا واستخدامه. نحن للعلوم المفتوحة والمفتوحة المصدر!
إعداد البيانات
يبدو أنه إذا كانت كل عملية بحث تستخدم الطائرات بدون طيار تجلب الآلاف من الصور ، فإن مجموعة البيانات المتراكمة يجب أن تكون ضخمة - التقط وتدرب. لم يتبين أن كل شيء بسيط للغاية ، لأنه:
- لا يوجد تخزين مركزي للبيانات الموسومة. لا يتم استخدام الصور التي تم التقاطها أثناء عمليات البحث أو معالجتها في المستقبل.
- البيانات التي تم الحصول عليها غير متوازنة للغاية. في طلقة واحدة مع الشخص الذي عثر عليه ، هناك عدة آلاف من الصور "الفارغة". نظرًا لأن المعلومات حول الصور الممسوحة ضوئيًا لا يتم تسجيلها في أي مكان ، من أجل العثور على الصور الضرورية بينها ، يجب القيام بعدد كبير من العمل للمرة الثانية - بجهود فريق صغير ليس لديه "عيون مدربة".
- كل صورة في حد ذاتها "غير متوازنة": يشغل الشخص المرغوب جزءًا صغيرًا من مساحة الصورة بأكملها. من الواضح أنه لا ينبغي أن تكون الشبكة العصبية الجيدة قادرة فقط على القول ، في رأيها ، أن الشخص موجود في الصورة - بل يجب أن يحيط بمكان معين (على سبيل المثال ، أداء مهمة الكشف عن الأشياء ، وليس تصنيف الصور). وإلا ، فإن المشغل سوف يقضي وقتًا إضافيًا وطاقة إضافية في النظر إليه ، وقد يرفض أيضًا عن طريق الخطأ الصورة المطلوبة. ولكن لهذا ، يجب أن تتعلم الشبكة العصبية من البيانات المحددة ، في الصور الفوتوغرافية ، حيث يتم تمييز الكائن المطلوب باستخدام برنامج خاص. لن يقوم أحد بذلك أثناء عملية البحث - وليس قبل ذلك.
- لا تؤخذ في الحسبان الإحصاءات المتعلقة بالمواقع التي تم العثور على الأشخاص فيها ، ووقت العام ، ونوع التضاريس ، وغيرها من ميزات الصور. ستكون مثل هذه البيانات مفيدة للغاية لإنشاء صور تدريب "تركيبية" باستخدام التصوير المرحلي أو محرري الصور أو النماذج التوليفية - ولكن لاستخدام كل هذا تحتاج إلى فهم كيف تبدو الصورة مع شخص ضائع حقًا. الآن ، عند إعادة بناء مثل هذه الصور ، يتعين على المرء أن يعتمد على الخبرة الذاتية لخبراء الإنقاذ.
- بالإضافة إلى الصعوبات التقنية ، هناك عقبات قانونية يمكن أن تفرض قيودًا على ملكية الصور التي تم الحصول عليها. في كثير من الأحيان ، تظل طلباتنا للمساعدة في جمع البيانات دون إجابة كاملة. بسبب عدم وجود مثل هذه البيانات أو المشكلات القانونية أو الكسل الشائع - فمن غير الواضح.
وبالتالي ، لا يتم استخدام المعلومات القيمة بأي شكل من الأشكال لتدريب الشبكات العصبية ، حيث يتم فقدها أو موتها في مكان ما على الأقراص والمستودعات السحابية ، بدلاً من تحسين حجم ونوعية عينة التدريب. نكتب خدمة تتيح ، من بين أشياء أخرى ، تحميل الصور القيمة لنا (حولها أيضًا أدناه) ، ولكن ، كما هو الحال دائمًا ، هناك مهام أكثر من الأشخاص.
علاوة على ذلك ، حتى الآن ، تحتوي الشبكة على عدد قليل جدًا من مجموعات البيانات الجيدة (المفتوحة) مع صور من الطائرات بدون طيار. أنسب واحدة وجدناها
ستانفورد الطائرة بدون طيار مجموعة البيانات (SDD) . إنها صورة من ارتفاع فوق الحرم الجامعي ، مع أشياء ملحوظة من فئة "المشاة" (المشاة) ، جنبًا إلى جنب مع راكبي الدراجات والحافلات والسيارات. على الرغم من زاوية التصوير المماثلة ، إلا أن المشاة الذين تم تصويرهم والبيئة لا يتقاسمون سوى القليل مما يحدث في صورنا. أظهرت التجارب التي أجريت على مجموعة البيانات هذه أن مقاييس جودة أجهزة الكشف المدربة عليها على بياناتنا تظهر نتيجة منخفضة. نتيجةً لذلك ، نستخدم الآن SDD لتدريب ما يسمى العمود الفقري ، الذي يستخلص سمات المستوى الأعلى ، ويجب إكمال الطبقات القصوى على صور منطقة النطاق لدينا.
هذا هو السبب في أننا تواصلنا أولاً مع مختلف محركات البحث والإنقاذ لفترة طويلة ، في محاولة لفهم كيف يبدو الشخص الذي فقد في الغابة في صورة من أعلى. نتيجةً لذلك ، قمنا بجمع إحصائيات فريدة من نوعها على 24 موضعًا ، والتي غالبًا ما يتم العثور على الأشخاص المفقودين. قمنا بتصوير وتمييز مجموعة البيانات الخاصة بنا - Lacmus Drone Dataset (LaDD) ، والتي تضمنت في الإصدار الأول أكثر من 400 صورة. تم تنفيذ التصوير بشكل أساسي بمساعدة DJI Mavic Pro و Phantom من ارتفاع 50 - 100 متر ، كانت دقة الصور 3000 × 4000 ، وكان متوسط حجم الشخص 50 × 100 بكسل. في الوقت الحالي ، لدينا بالفعل الإصدار الرابع من مجموعة البيانات مع 2000 صورة ، حقيقية و "محاكاة". نحن نواصل العمل على تجديد مجموعة البيانات والإصدار الخامس قاب قوسين أو أدنى.
أثناء تجديد مجموعة البيانات الخاصة بنا ، توصلنا إلى ضرورة فصل الصور حسب الموسم. الحقيقة هي أن نموذجًا تم تدريبه على صور الشتاء يُظهر نتائج أفضل من نموذج تم تدريبه على مجموعة البيانات بأكملها ، إما في الصيف أو الربيع بشكل منفصل. ربما يتم استخراج العلامات على خلفية ثلجية أفضل من العشب صاخبة.

في الوقت نفسه ، عند التدريب على الصور الشتوية فقط ، يزيد عدد الإيجابيات الخاطئة (الإيجابية الخاطئة). على ما يبدو ، فإن صور المواسم المختلفة هي مناظر طبيعية مختلفة (المجالات) والشبكة العصبية غير قادرة على تعميمها. يبقى أن نرى هذا ، وحتى الآن نرى طريقتين:
- اصنع الكثير من الشبكات "الصغيرة" وتعرف عليها في نطاقات مختلفة بشكل منفصل (واحد لفصل الشتاء ، وآخر لفصل الصيف ... بالإضافة إلى الفصول ، يمكنك أيضًا تقسيم حسب المنطقة: على سبيل المثال ، نموذج للشريط الأوسط والسهول ، وآخر للجنوب ، وهكذا) .
- قم بزيادة بياناتنا بشكل متكرر ومحاولة تدريب النموذج مرة واحدة على جميع المجالات. استنادًا إلى حل مشكلة مماثلة في مقال من Yandex ، نميل إلى تجربة هذا الخيار المحدد. من الصعب جمع عدد كبير من الصور الحقيقية مع الأشخاص الضائعين للأسباب الموصوفة بالفعل ، لذلك ، ربما سنحاول إعادة إنشاء أمثلة تعليمية واقعية تستند إلى صور "فارغة" (يوجد الكثير منها). لذلك قد يكون لدينا قريبا شبكات GAN.
عملية التعلم
تختلف طبيعة صورنا بشكل كبير عن صور مجموعات البيانات الشائعة مثل ImageNet ، COCO ، إلخ. نظرًا لأن الشبكات العصبية المطورة لمثل هذه المجموعات قد تكون غير مناسبة لمهمتنا ، فقد كان من الضروري إجراء دراسة حول قابلية تطبيق مختلف البنى. للقيام بذلك ، أخذنا نماذج تم تدريبها مسبقًا على ImageNet ، وأعدنا تدريبهم على قاعدة بيانات Stanford Drone Dataset ، وبعد ذلك قمنا بتجميد العمود الفقري ، وتم تدريب الأجزاء المتبقية من أجهزة الكشف مباشرة على صورنا. يتم عرض أفضل المقاييس في الجدول:
بالإضافة إلى الأرقام الموجودة في الجدول أعلاه ، يجب الانتباه إلى هذه الميزة من صور Lacmus Drone Dataset باعتبارها اختلالًا كبيرًا في الفئة: نسبة مساحة الخلفية إلى مساحة المستطيل (المرساة) بالكائن المرغوب هو عدة آلاف. عند تدريب الكاشف ، يستلزم ذلك مشكلتين:
- معظم المناطق ذات الخلفية لا تحمل أي معلومات مفيدة.
- المناطق التي تحتوي على كائنات بسبب أعدادها الصغيرة أيضًا لا تقدم مساهمة كبيرة في تدريب الأوزان.
من أجل التغلب على هذه المشكلات بطريقة ما ، تم استخدام مخططات تدريب مختلفة وإعدادات الشبكة وعينات التدريب. تهدف واحدة من بنية الشبكة العصبية التي اختبرناها ، RetinaNet ، بالتحديد إلى تقليل الآثار السلبية لخلل كبير في الصف. صممه منشئو RetinaNet لزيادة دقة أجهزة الكشف أحادية الطور (التي تغطي الصورة بشبكة كثيفة من المراسي المستطيلات المحددة مسبقًا ثم صقل تلك التي تغطي الكائن بشكل أفضل) مقارنة بجودة أفضل ، لكن أبطأ للكشف عن مرحلتين (الذين يدرسون للعثور على المناطق المرشحة أولاً ، ثم تحديد موقفهم). من وجهة نظر مؤلفي المقالة حول RetinaNet ، تفقد أجهزة الكشف أحادية المرحلة بالتحديد بسبب الخلل الناجم عن عدد كبير من المراسي الفارغة. على خلفية هذه الميزة ، تم اختيارنا لصالح RetinaNet مع العمود الفقري ResNet50.
تم تقديم بنية هذه الشبكة في عام 2017. الميزة الرئيسية لشبكة RetinaNet ، التي تسمح لك بالتعامل مع الآثار السلبية للاختلالات الصفية في التدريب ، هي الوظيفة الأصلية لفقدان
الخسارة البؤري :
FL(pt)=−(1−pt) gammalog(pt)pt= startcasesp، mboxify=1،1 - ص م ب س س و إ ل ا ه ن د ج على الصورة ه ق
حيث
p هو الاحتمال المقدر للمحتوى في المنطقة الخاصة بالكائن المرغوب المقدّر من قبل النموذج (بعبارة بسيطة ، خرج الشبكة العصبية ، إذا تم اختزاله إلى الفاصل الزمني [0 ، 1]).
في نطاقات المجالات الأخرى ، ينبغي أن تكون وظيفة الخسارة ، كقاعدة عامة ، مقاومة للحالات غير التقليدية (أمثلة قاسية) ، والتي من المرجح أن تكون متطرفة ؛ يجب تقليل تأثيرها على تدريب الأثقال. في Focal Loss ، على العكس من ذلك ، يتم تقليل تأثير الخلفية التي تحدث بشكل متكرر (inliers ، أمثلة سهلة) ، ونادراً ما يكون للعناصر التي يتم رؤيتها التأثير الأكبر عند تدريب أوزان RetinaNet. يتم ذلك بسبب هذا الجزء من الصيغة:
( 1 - p t ) g a m m a
عامل
g a m m a في الأس تحدد "وزن" الأمثلة الصعبة في دالة الخسارة الكلية.
أثناء عملية تدريب RetinaNet ، تُحسب وظيفة الخسارة لجميع التوجهات المدروسة لمناطق المرشحين (نقاط الارتساء) ، من جميع مستويات تحجيم الصور. في المجموع ، هناك حوالي 100 كيلو بايت من المساحات لصورة واحدة ، والتي تختلف تمامًا عن طرق أخذ العينات التجريبية (RPN) أو البحث عن الحالات النادرة (OHEM ، SSD) مع عدد صغير من المساحات (حوالي 256) لكل ناقل صغير. يتم حساب قيمة الخسارة البؤرية على أنها مجموع قيم الوظائف لجميع نقاط الارتساء ، ويتم تطبيعها بعدد المراس التي تحتوي على الكائنات المطلوبة. يتم إجراء التطبيع عليها فقط ، وليس على العدد الإجمالي ، نظرًا لأن الغالبية العظمى من المراسي هي خلفية يمكن تحديدها بسهولة ، مع مساهمة ضئيلة في وظيفة الخسارة الكلية.
من الناحية الهيكلية ، تتكون RetinaNet من تعريفات الشبكة الفرعية وتعريفين للشبكة الفرعية للتصنيف الفرعي والانحدار الفرعي.
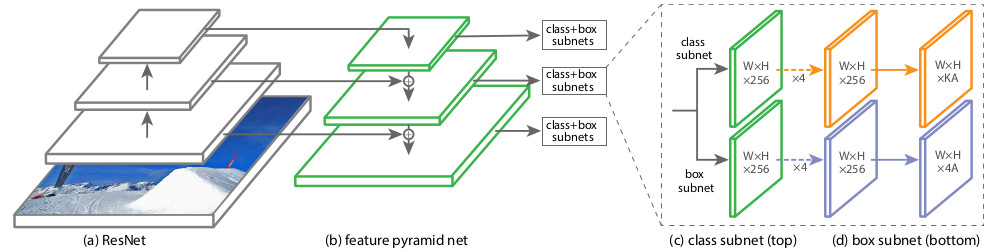
باعتبارها العمود الفقري ، يتم استخدام ما يسمى
شبكة الهرم الهرم ، FPN ، التي تعمل على واحدة من الشبكات العصبية التلافيفية الشائعة الاستخدام (على سبيل المثال ، ResNet50). لدى FPN مخرجات جانبية إضافية من طبقات مخفية من شبكة الالتواء ، وتشكيل مستويات هرمية بمقاييس مختلفة. يُستكمل كل مستوى بـ "مسار من أعلى إلى أسفل" ، أي معلومات من مستويات أعلى أصغر ، ولكنها تحتوي على معلومات حول مناطق من منطقة أكبر. يبدو وكأنه زيادة مصطنعة (على سبيل المثال ، ببساطة تكرار العناصر) لخريطة الميزة "المصغّرة" بحجم الخريطة الحالية ، مع إضافتها عنصرًا تلو الآخر ونقلها إلى مستويات أدنى من الهرم وإدخال شبكات فرعية أخرى (أي في الشبكة الفرعية للتصنيف و مربع الانحدار الشبكة الفرعية). يتيح لك هذا اختيار هرم علامات من الصورة الأصلية بمقاييس مختلفة ، والتي يمكن من خلالها اكتشاف الكائنات الكبيرة والصغيرة. يستخدم FPN في العديد من البنى ، مما يساعد على تحسين اكتشاف الكائنات ذات الأحجام المختلفة: RPN ، DeepMask ، Fast R-CNN ، Mask R-CNN ، إلخ.
يمكنك قراءة المزيد حول FPN في
المقالة الأصلية.
في شبكتنا ، كما هو الحال في الأصل ، FPN مع 5 مستويات مرقمة
P 3 د و ل ا في
P 7 د و ل ا . مستوى
ف ل لديه إذن ل
2 لتر مرات أصغر من صورة الإدخال (لن ندخل في التفاصيل التي منها نقاط ResNet التي يأتون منها - هذا سيؤدي إلى كسر الساق). جميع مستويات الهرم لها نفس عدد القنوات C = 256 وعدد المراسى A حوالي 1000 (حسب حجم الصور).
المراسي لها مساحات من [16 × 16] إلى [256 × 256] لكل مستوى من الهرم من
P 3 د و ل ا إلى
P 7 د و ل ا وفقًا لذلك ، مع خطوة الإزاحة (خطوات) [8 - 128] بكسل. يتيح لك هذا الحجم تحليل الأشياء الصغيرة وبعض المناطق المحيطة بها. على سبيل المثال ، فإن الفرع ، إذا كنت لا تأخذ بعين الاعتبار الواقع المحيط به ، يشبه إلى حد بعيد الشخص الكذب.
يستخدم FPN الأصلي ثلاث نسب أبعاد للمراسي (1: 2 ، 1: 1 ، 2: 1) ؛ أضاف مؤلفو RetinaNet ثلاثة موازين لكل من هذه النسبة الباعية لتغطية أكثر كثافة [2 0 ، 2 1 / 3 ، 2 2 / 3 ]. يتيح لك استخدام 9 أنواع من نقاط الارتساء في كل مستوى العثور على كائنات ذات طول / عرض يتراوح بين 16 و 400 بكسل في الصورة الأصلية. الشبكة الفرعية للتصنيفتتنبأ باحتمالية التواجد لكل فئة من فصول K في نقطة ربط معينة. في الواقع ، إنها شبكة بسيطة متصلة بالكامل (Fully ConvNet ، FCN) متصلة بكل طبقة من طبقات FPN. معالمه هي نفسها في مستويات مختلفة من الهرم ، والهندسة المعمارية بسيطة للغاية:- بطاقة الميزة هي الإدخال (العرض × الارتفاع × الارتفاع)
- 3x3 الإلتواء مع مع المرشحات
- تنشيط ReLU
- الإلتفاف 3x3 مع مرشحات (K x A) ،
- تفعيل السيني من الطبقة الأخيرة
في المجموع ، يتم تشكيل متجه طوله K x A عند إخراج هذه الشبكة ، حيث K هو عدد الفئات المختلفة. في حالتنا ، يتم استخدام فئة واحدة فقط - وهذا هو المشاة. تسمح لكالشبكة الفرعية للانحدار في المربع بتحسين ناقل إحداثيات المكوّن المكون من 4 مكونات إلى الحجم الفعلي للكائن. هذه شبكة صغيرة متصلة بالكامل متصلة بكل طبقة من طبقات FPN ، والتي تعمل بشكل مستقل عن الشبكة الفرعية للتصنيف. تصميماتها متشابهة تقريبًا ، باستثناء أنه أثناء التدريب يتم تقليل متجه الحجم (4 × A) - لكل مرساة:( Δ س م ط ن ، Δ ذ م ط ن ، Δ س م إلى س ، Δ ذ م إلى س )
تعتبر المرساة تحتوي على كائن إذا كان IoU (تقاطع فوق الاتحاد) مع منطقة حقيقية تحتوي على الكائن> 0.5. في هذه الحالةذ ط يتم تعيين 1، وإلا 0. هذا النهج يقلل من تكاليف الحسابية في الكشف عن التدريب.يتمثل التداخل(الكشف عن الكائنات في الصورة) في حساب الوظيفة الأمامية للشبكة الأساسية والشبكتين الفرعيتين. لزيادة السرعة ، يتم التصنيف فقط في أفضل المناطق التي يبلغ طولها 1 كيلو مع احتمال متوقع أعلى من 0.05. في المرحلة الأخيرة من الكشف ، تبقى فقط تلك المناطق من جميع مستويات الهرم ، واحتمال التصنيف الذي يتجاوز العتبة = 0.5.يمكن أيضًا قراءة تحليل مفصل لبنية RetinaNet علىاتجاه نحو المعرفة.بطبيعة الحال ، قلة من الناس ينفذون مثل هذه الهياكل المعقدة من الصفر. أخذنا أساسًا مكتبة المصادر المفتوحة التي توفرها fizyr: keras-retinanet على جيثب ، والتي قمنا بمراجعتها لاحقًا عدة مرات.تحسين الشبكة العصبية
تعد سرعة الشبكة مهمة جدًا بالنسبة لنا ، لذلك فقد بحثنا منذ فترة طويلة عن حلول من أجل الحصول على أقصى استفادة من جهاز كمبيوتر محمول متوسط مقابل 20 إلى 30 ألف روبل. فيما يلي بعض الأساليب والأطر التلقائية التي جربناها:- Intel OpenVINO - للتحسين على وحدة المعالجة المركزية (نتيجة لذلك ، قمنا بتجميع شبكتنا ، ولكن لسبب ما لم ينجح هذا).
- TensorRT - للتحسين على وحدة معالجة الرسومات (لم يتم تحويل شبكتنا).
- PlaidML - أطلقت شبكتنا على Intel HD Graphics (!) (عملت الشبكة ولكن زيادة السرعة مقارنة بوحدة المعالجة المركزية كانت صغيرة جدًا).
- nGraph - لا مكاسب في الأداء.
و ايضا ...
- نفيديا جيتسون
- كورال حافة TPU
نتيجة لذلك ، قمنا بتجميع إصدار tensoflow 1.14 الخاص بنا مع تحسينات لوحدات المعالجة المركزية مع دعم AVX باستخدام مختلف الحيل والمكتبات من Intel مثل nndl. لم نمر من قبل المعالجات القديمة دون تعليمات AVX (تم إصدارها بشكل رئيسي حتى عام 2012) والآن يمكننا أن نقول أن حلنا يعمل حتى على Core 2 Duo! نحن أيضا إصلاح زيادة البيانات غير فعالة في البداية عن طريق القياس مع رمز مكتبة Albumentations .الإحصاءات الجافة:إنتاج
docker
بناءً على رغبات وطلبات رجال الإنقاذ ، قمنا بتطوير تطبيق سطح المكتب وأردنا تبسيط العمل معه إلى أقصى حد ممكن ، مما يسهل عملية تثبيت المكتبات اللازمة. لا يعد تثبيت Nvidia Cuda و CuDNN أو بناء مخصص TensorFlow مهمة سهلة للمستخدم العادي. أردت أيضًا ألا يقلق طيارو الطائرات بدون طيار حول تثبيت Python على جهاز كمبيوتر محمول وإعداد التبعيات. هناك حاجة إلى شيء مضغوط من شأنه أن يخفي عن المستخدم تعقيد إعداد المكتبات وتثبيتها. ووجدنا مثل هذا الحل - وهذا هو عامل الميناء. في الحاوية ، ننشر خادم ويب صغيرًا محليًا به خلية عصبية على متن المركبة ونقوم بتثبيت التبعيات. إذا أردنا فجأة تحديث النموذج ، فسنحتاج فقط إلى تنزيل الإصدار الجديد من صورة عامل الميناء. بالإضافة إلى ذلك ، نحن نفصل بين واجهة المستخدم الرسومية والنموذج بهذه الطريقة.وبالتالي ، لا يمكن لواجهة المستخدم الرسومية الوصول إلى الخادم المحلي ، ولكن يمكن الوصول إلى الخادم البعيد ، على سبيل المثال ، إذا كان لدى المستخدم قناة اتصال جيدة. بالإضافة إلى ذلك ، يوفر Docker واجهة برمجة تطبيقات ملائمة يمكن التحكم فيها تلقائيًا مباشرة من واجهة المستخدم الرسومية ، بحيث يظل كل شيء شفافًا للمستخدم. بالإضافة إلى ذلك ، يوفر Docker مستودعًا خاصًا به حيث يمكنك تخزين إصدارات مختلفة من الصور ولا تقلق بشأن الخادم مع الطرز.واجهة المستخدم أو C # يعمل المعجزات
الآن عن الواجهة. في عملية تطوير التطبيق ، كانت 3 معايير مهمة بالنسبة لنا:- سرعة التنمية
- عبر منصة
- انخفاض استهلاك الموارد
بعد البحث على الإنترنت ، صادفنا هذا التقرير من مؤتمر dotnext . "هم! هذا شيء جديد! نوع من الإطار الشباب جدا؟ من المثير للاهتمام أن نلمسها "فكرنا ولم نخسر! نتيجةً لذلك ، تتم كتابة واجهة المستخدم الرسومية الخاصة بتطبيقنا في إطار AvaloniaUI C # ، والذي يسمح لك بتشغيله على أنظمة تشغيل 64 بت Win10 و Linux و Mac.AvaloniaUI هو إطار الشباب ، ولكن قوية جدا وسريعة. في مفهومه ، إنه مشابه جدًا لـ WPF ، والذي يسمح لك بنقل التطبيقات إليه دون تغيير الكود حقًا. إنه سريع وفعال ، فهو يرسم رسومات ثنائية الأبعاد بشكل أسرع ويستهلك موارد أقل من WPF. هناك أيضًا بعض الأشياء الجيدة التي تعزز WPF الأصلي.بالنسبة للجهاز الداخلي ، يتم استخدام مكتبة SkiaSharp هنا لتقديم الرسومات و GTK (لأنظمة Unix). تطوير طراز X11 مستمر أيضًا. كل هذا يسمح لك برسم الواجهة في أي مكان وفي أي مكان ، حتى في المخزن المؤقت لوحدة التحكم (!). إذا كان من الممكن إطلاق .Net Core في Bios ، فسوف ترسم AvaloniaUI واجهة ألعاب عصرية مثل اللوحات الأم الرائعة.يكتسب AvaloniaUI شعبية وهو إطار مفتوح ، على الرغم من أنه لا يزال في مرحلة تجريبية ، وهناك أخطاء في هذا الإطار. ولكن المطورين يقومون بتحسينه واستكماله باستمرار ، وبحلول نهاية عام 2019 ، يمكننا القول أنه من الممكن بالفعل كتابة حلول تجارية صغيرة عليه. إذا كنت معتادًا على WPF و C # ، فعليك بالتأكيد تجربة ذلك. يمكن أيضًا أن تعزى المزايا إلى انخفاض استهلاك الموارد عن طريق الواجهة (والتي لا يمكن قولها عن الإلكترون) ، مما يعني أننا نربح عدة ميغابايت من ذاكرة الوصول العشوائي لشبكتنا. هذا ما يمكنه ... وأريدأيضًا أن أقول إن المشروع يتمتع بدعم استجابة سريعًا ، وسرعان ما يستجيب المطورون لهذه المشكلة. يمكن لأولئك المهتمين قراءة مقالتنا ، وكذلك هذه المقالة. و هذا.لفهم كامل لهذا المفهوم ، يجدر النظر في العرض التقديمي الذي قدمته نيكيتا تسوكانوفkekekeks . هو مطور هذا الإطار ، وهو على دراية جيدة به وفي .NET بشكل عام.
هذا ما يمكنه ... وأريدأيضًا أن أقول إن المشروع يتمتع بدعم استجابة سريعًا ، وسرعان ما يستجيب المطورون لهذه المشكلة. يمكن لأولئك المهتمين قراءة مقالتنا ، وكذلك هذه المقالة. و هذا.لفهم كامل لهذا المفهوم ، يجدر النظر في العرض التقديمي الذي قدمته نيكيتا تسوكانوفkekekeks . هو مطور هذا الإطار ، وهو على دراية جيدة به وفي .NET بشكل عام.الخلفية
بالإضافة إلى تطبيق سطح المكتب ، نقوم بتطوير بنية أساسية لـ mlOps لإجراء التجارب وإيجاد أفضل بنية الشبكة العصبية في السحابة. باستخدام جانب الخادم ، نريد:- تجميع البيانات وتخزينها مركزيا ؛
- أتمتة عملية التعلم للشبكة العصبية ، وخلق بيئة للبحث وتوفير الوصول إليها للآخرين ؛
- توفير الوصول إلى السحابة لفرق البحث والإنقاذ حتى يتمكنوا من استخدام البيانات المتراكمة إذا لزم الأمر ؛
تبدو بنية النظام الكلية شيئًا مثل هذا:
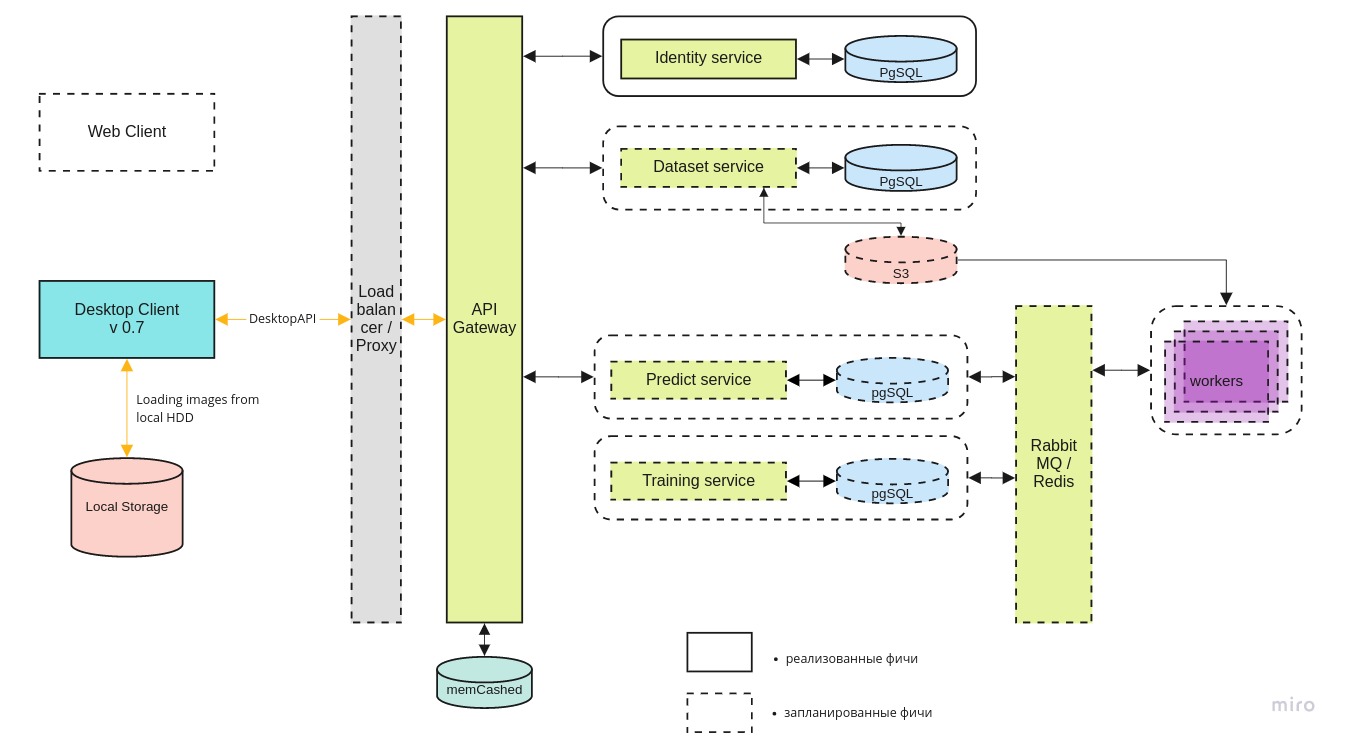 يمكن لسطح المكتب العميل
يمكن لسطح المكتب العميل العمل مع كل من الإصدار المحلي من حاوية الإرساء والإصدار الأخير على الخادم المركزي ، من خلال واجهة برمجة تطبيقات REST.
يوفر microservice
الهوية الوصول إلى الخادم فقط للمستخدمين المصرح لهم.
يتم استخدام خدمة
Dataset لتخزين الصور نفسها وترميزها.
تتيح لك خدمة
التنبؤ إمكانية معالجة عدد كبير من الصور بسرعة في وجود قناة واسعة للطيارين.
هناك حاجة إلى خدمة
التدريب لاختبار نماذج جديدة وإعادة تدريب النماذج الحالية عند وصول بيانات جديدة.
تتم إدارة قائمة انتظار المهام باستخدام RabbitMQ / Redis.
GPU قدرات البحث
على الرغم من حقيقة أن استنتاج الشبكة العصبية يمكن أن يعمل حتى على جهاز كمبيوتر محمول بسيط ، هناك حاجة إلى GPU لتدريب النموذج. من الناحية الفنية ، يمكنك تدريبه على وحدة المعالجة المركزية ، ولكن في الممارسة العملية يستغرق الكثير من الوقت. ليس كل الأشخاص الذين يأتون إلى الفريق لديهم جهاز كمبيوتر مناسب للتعلم العميق ، لذلك نحن نبحث عن قدرات GPU مركزية.
في الوقت الحالي نتفاوض مع
DTL ونأمل أن يتطور التعاون. تفرد خوادم DTL GPU هو استخدام تبريد الغمر: غمر الرفوف في سائل عازل خاص. يبدو مثل هذا:

 (ملاحظة المصور: الأزرق ليس توهج شيرينكوف. إنه تسليط الضوء عليه).
(ملاحظة المصور: الأزرق ليس توهج شيرينكوف. إنه تسليط الضوء عليه).انحدار غنائي. "هل تعرف الشبكة العصبية من الخط المباشر؟"
بصراحة ، لا أريد فعلاً أن أتطرق إلى هذا الموضوع (الزلق) ، لكنه لا يزال يمسنا ، لذلك من المستحيل التظاهر بأننا في الخزان. نعم ، نحن نعرف عن الشبكة العصبية من الخط المباشر. وفقًا لتعليقات الطيارين الذين يتعاونون معنا ، فهو يعمل بشكل أسوأ من نسختنا وفقط على المنصات المتطورة. وفقا للمطورين من الخط المباشر - المشروع متجمد ولا يتطور الآن. من وجهة نظر الفطرة السليمة ، كانت الأخبار في روح الخط المباشر هي الأولى في روسيا لتطوير مثل هذه الشبكة العصبية. قلة من الناس يطبقون حتى بنيات مصممة بواسطة مختبرات مثل Facebook Research أو Google Brain ، وأقل من ذلك بكثير يقومون بإنشاء بنياتهم الخاصة. غالبًا ما يتعلق الأمر بتكييف مكتبة مفتوحة المصدر عامة مع احتياجات مجال الموضوع الخاص بك. كم مرة تستخدم المكتبات المفتوحة في البرامج التجارية الروسية ، يعرف كل من يطور هذا البرنامج. بالنسبة للجزء الأكبر ، لا يوجد أي انتهاك للترخيص ؛ لكن التخلي عن إنجازات برنامج OpenSource الدولي ككل في تطوره والقيام بعلاقات عامة عالية بصوت عالٍ أمر قبيح على الأقل. يبدو أن إنجازاتنا كانت تستخدم أيضًا: على وجه الخصوص ، في الصور الخاصة بنا ، كانت
صورنا مضاءة. قارن مع صورة "فصل الشتاء" من القسم الخاص بمجموعة بيانات Lacmus:

هناك أسباب أخرى للاعتقاد بأن الأمر لم يقتصر على البيانات هنا.
ما هو سيء بالنسبة لنا في المقام الأول هو أن الشبكة العصبية الخط المباشر أصبحت الآن غير مستحيلة. عندما يتم ذكرها ، يستحيل فهم ما إذا كان الأمر يتعلق بها حقًا ، أو حول طلبنا ، أو بشكل عام حول خيار شخص آخر. في ظروف اللامركزية وضعف القدرة على التحكم في JI وعدد قليل من قنوات التغذية المرتدة ، فإن أي معلومات حول مدى انتشار وجودة عمل Lacmus ستكون مفيدة ، وكذلك حول التطورات المماثلة - لكن الضجة حول Beeline طغت على كل شيء.
نحن نخطط لمواصلة مراقبة الموقف في الوقت الحالي ، لكن طلبنا إلى المجتمع هو أولاً أن نقول "شبكة عصبية مباشرة" فقط عندما يكونون متأكدين 100 ٪ من أن هذا هو ، وثانياً ، قراءة تراخيص المصادر المفتوحة والإشارة بصراحة إلى التأليف.
النتائج
على مدار عام 2019 ، أعضاء مؤسسة Lacmus:
- قمنا بتصوير وتمييز مجموعة بيانات فريدة تضم أحدث نسخة منها أكثر من 2000 صورة ؛
- حاول عدد من أبنية الشبكات العصبية المختلفة واختار الأنسب ؛
- لقد اخترنا أفضل المقاييس الفوقية للشبكة العصبية وقمنا بتدريبها على البيانات الفريدة الخاصة بنا من أجل التعرف الأكثر دقة ؛
- تطوير تطبيق عبر الأنظمة الأساسية لمشغلي الطائرات بدون طيار مع القدرة على استخدامها عند العمل دون اتصال بالإنترنت ؛
- تحسين عمل شبكتنا العصبية للعمل على أجهزة الكمبيوتر المحمولة ذات الميزانية المنخفضة والطاقة ؛
في الوقت الحالي ، فإن أفضل مؤشرات قياس LAPMUS للشبكة العصبية هي 94٪. برنامجنا جاهز للاستخدام في عمليات البحث والإنقاذ الحقيقية وقد تم اختباره على فترات تشغيل عامة. في المناطق المفتوحة من النوع "الحقل" و "مصدات الرياح" تم العثور على جميع الاختبارات "المفقودة". بالفعل الآن تستخدم Lakmus من قبل فرق الإنقاذ وتساعد في العثور على أشخاص.
كما حصلنا على جائزة مشروع العام من علوم البيانات المفتوحة:

نخطط هذا العام:
- العثور على شريك لبنية استضافة موثوقة ؛
- تنفيذ واجهة الويب و mlOps ؛
- تشكيل مجموعة بيانات تركيبية كبيرة على محرك UE4 أو بمساعدة GANs ؛
- إطلاق مسابقة InClass في Kaggle لكل من يريد ترقية مهارات DL / CV والبحث عن أفضل حلول SOTA ؛
- إضافة إلى شبكتنا أكثر تطبيقات العمود الفقري والاختلافات في هذه البنية ؛
نحن نفتقر إلى العمال لتنفيذ هذه الخطط ، لذلك سنكون سعداء للجميع بغض النظر عن مستوى واتجاه التدريب.
إذا تمكنا معاً من إنقاذ شخص آخر على الأقل ، فلن تذهب كل الجهود سدى.
كيفية مساعدة المشروع
نحن مشروع مفتوح المصدر ، وسنقبل بكل سرور الجميع! فيما يلي الروابط إلى مستودعات جيثب لدينا:
إذا كنت مطورًا وترغب في الانضمام إلى المشروع ، فيمكنك الكتابة إلى Perevozchikov Georgy Pavlovich ،
gosha20777 في جميع الشبكات الاجتماعية ،
gosha20777@live.ru أو الانضمام إلى المشروع من خلال القناة
# ml4sg في ODS slack (إذا كنت هناك).
نحتاج:
- مطوري ML
- C # / go / python للمطورين ؛
- عمال الخط الأمامي ؛
- Bekendschiki.
- فقط نشط الناس من أي اتجاه! سنكون دائما سعداء لرؤيتك!
إذا لم تكن مشتركًا في التطوير ، يمكنك أيضًا مساعدة المشروع:
- يمكنك مساعدتنا في كتابة المقالات.
- يمكنك مساعدتنا في كتابة وثائق المستخدم ويكي (وتصحيح الأخطاء النحوية هناك)))
- يمكنك البقاء في دور مدير المنتج وإكمال المهام في trello ؛
- يمكنك أن تقدم لنا فكرة ؛
- يمكنك توزيع هذا المنشور ؛
عن الفريق
مدير المشروع: جورجي بافلوفيتش
بيريفوزيكوف ،
gosha20777 .
قائمة غير كاملة من المتورطين (في الواقع ، أكبر بكثير ، إذا كنت قد نسيت بشكل غير عادل ، أخبرني وسوف نضيف):
- أكثر المشاركين نشاطًا في نظام ODS في القناة #proj_rescuer_la : Kseniia ، balezz ، ei-grad ، Palladdiumm ، sharov_am ، dartov
- المشاركون في المشروع خارج نظام الوثائق الرسمية: Martynova Viktoriya Viktorovna (تنظيم المشروع ، وجمع البيانات ووضع العلامات عليها) ، و Denis Petrovich Shurankov (منظمة جمع البيانات) ، و Daria Pavlovna Perevozchikova (تم تمييزها بحوالي 30 ٪ من جميع الصور).
- مشغلي الطائرات بدون طيار من فرقة Liza Alert ، الذين ساعدوا في الصور وتكوين مجموعة البيانات: Partyzan ، Vanteyich ، Sevych ، كاليفورنيا ، Tarekon ، Evgen ، GB.
شكر خاص:
- للمبرمجين من AvaloniaUI - أفضل إطار عمل .NET: worldbeater و kekekeks و Larymar
- مدراء نظام الوثائق الرسمية لتنظيم أروع مجتمع: natekin ، ساشا ، mististopheies.
شارك في كتابة هذا المقال مع
balezz و
gosha20777 habrozhitelami .
الجميع ليكون الحيلة ولا تضيع!
 فيديو مظاهرة من العمل للحلوى. قبل وقت مبكر ألفا الإصدار. بالنسبة لأولئك الذين يقرؤون حتى النهاية. فبراير 2019.
فيديو مظاهرة من العمل للحلوى. قبل وقت مبكر ألفا الإصدار. بالنسبة لأولئك الذين يقرؤون حتى النهاية. فبراير 2019.