الفصول السابقة
30. تفسير منحنى التعلم: انحياز كبير
لنفترض أن منحنى الخطأ في نموذج التحقق من الصحة يبدو كما يلي:
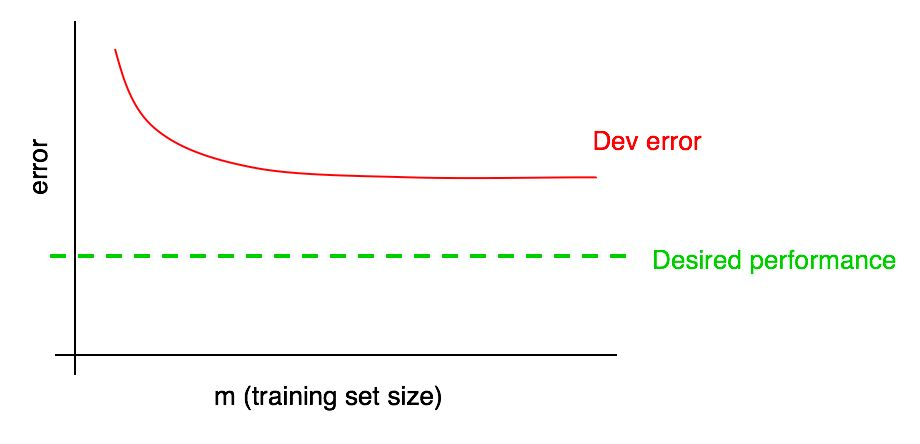
لقد سبق أن قلنا إنه إذا وصل خطأ في الخوارزمية في عينة التحقق من الصحة إلى هضبة ، فمن غير المحتمل أن تحقق المستوى المطلوب من الجودة بمجرد إضافة البيانات.
ولكن من الصعب تخيل كيف سيظهر استقراء منحنى الاعتماد على جودة الخوارزمية على عينة التحقق من الصحة (خطأ ديف) عند إضافة البيانات. وإذا كانت عينة التحقق من الصحة صغيرة ، فإن الإجابة على هذا السؤال تكون أكثر صعوبة بسبب حقيقة أن المنحنى يمكن أن يكون صاخبًا (يكون له عدد كبير من النقاط).
لنفترض أننا أضفنا إلى الرسم البياني لدينا منحنى اعتماد حجم الخطأ على مقدار البيانات من عينة الاختبار وحصلنا على الصورة التالية:
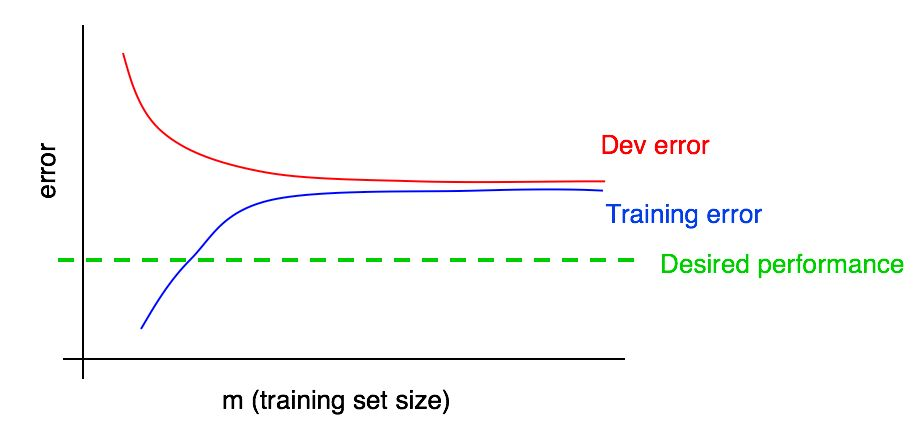
من خلال النظر إلى هذين المنحنيين ، يمكنك التأكد تمامًا من أن إضافة بيانات جديدة بمفردها لن يعطي التأثير المطلوب (لن يسمح بزيادة جودة الخوارزمية). أين يمكن استخلاص هذا الاستنتاج؟
دعنا نتذكر النقطتين التاليتين:
- إذا أضفنا المزيد من البيانات إلى مجموعة التدريب ، فإن خطأ الخوارزمية في مجموعة التدريب يمكن أن يزيد فقط. وبالتالي ، فإن الخط الأزرق من مخططنا إما لن يتغير ، أو سيتسلل لأعلى وسيبتعد عن مستوى الجودة المطلوب للخوارزمية (الخط الأخضر).
- عادة ما يكون خط الخطأ الأحمر في نموذج التحقق من الصحة أعلى من خط الخطأ الأزرق للخوارزمية في نموذج التدريب. وبالتالي ، تحت أي ظرف من الظروف المعقولة ، لن تؤدي إضافة البيانات إلى المزيد من الانخفاض في الخط الأحمر ، ولن تقربه من مستوى الخطأ المرغوب فيه. هذا مستحيل تقريبًا ، نظرًا لأن الخطأ في عينة التدريب أعلى من المستوى المطلوب.
يتيح لك النظر في كلا منحني اعتماد خطأ الخوارزمية على مقدار البيانات الموجودة في عينات التحقق من الصحة والتدريب على نفس الرسم البياني أن تستقر بمزيد من الثقة في منحنى خطأ خوارزمية التعلم من كمية البيانات في عينة التحقق من الصحة.
افترض أن لدينا تقديرًا للجودة المطلوبة للخوارزمية في شكل مستوى مثالي من الأخطاء في نظامنا. في هذه الحالة ، تمثل الرسوم البيانية أعلاه توضيحًا لحالة "كتاب مدرسي" قياسي لكيفية ظهور منحنى التعلم بمستوى عالٍ من التحيز القابل للإزالة. في أكبر حجم لعينة التدريب ، من المفترض أنه يتوافق مع جميع البيانات الموجودة لدينا ، توجد فجوة كبيرة بين خطأ الخوارزمية في عينة التدريب والجودة المطلوبة للخوارزمية ، مما يشير إلى تجنب مستوى عالٍ من التحيز. بالإضافة إلى ذلك ، الفجوة بين الخطأ في عينة التدريب والخطأ في عينة التحقق من الصحة صغيرة ، مما يدل على انتشار صغير.
في وقت سابق ، ناقشنا أخطاء الخوارزميات المدربة على عينات التدريب والتحقق من الصحة فقط في أقصى نقطة أعلى الرسم البياني الذي يتوافق مع استخدام جميع بيانات التدريب المتاحة. إن منحنى تبعية الخطأ على كمية البيانات من عينة التدريب ، التي تم إنشاؤها لأحجام مختلفة من العينة المستخدمة للتدريب ، يعطينا صورة أكثر اكتمالا لجودة الخوارزمية المدربة على أحجام مختلفة من عينة التدريب.
31. تفسير منحنى التعلم: حالات أخرى
النظر في منحنى التعلم:
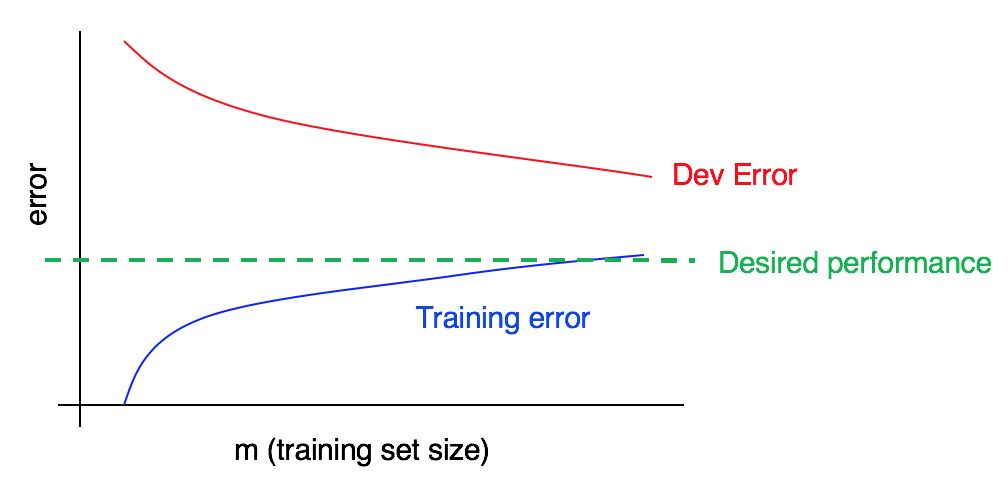
هل هناك تحيز كبير ، تحليل عالي ، أو كلاهما في آن واحد؟
منحنى الخطأ الأزرق في بيانات التدريب منخفض نسبيًا ، ومنحنى الخطأ الأحمر في بيانات التحقق من الصحة أعلى بكثير من الخطأ الأزرق في بيانات التدريب. وبالتالي ، في هذه الحالة ، يكون التحيز صغيرًا ، لكن الانتشار كبير. قد تساعد إضافة المزيد من بيانات التدريب في سد الفجوة بين الخطأ في نموذج التحقق من الصحة والخطأ في نموذج التدريب.
الآن النظر في هذا المخطط:
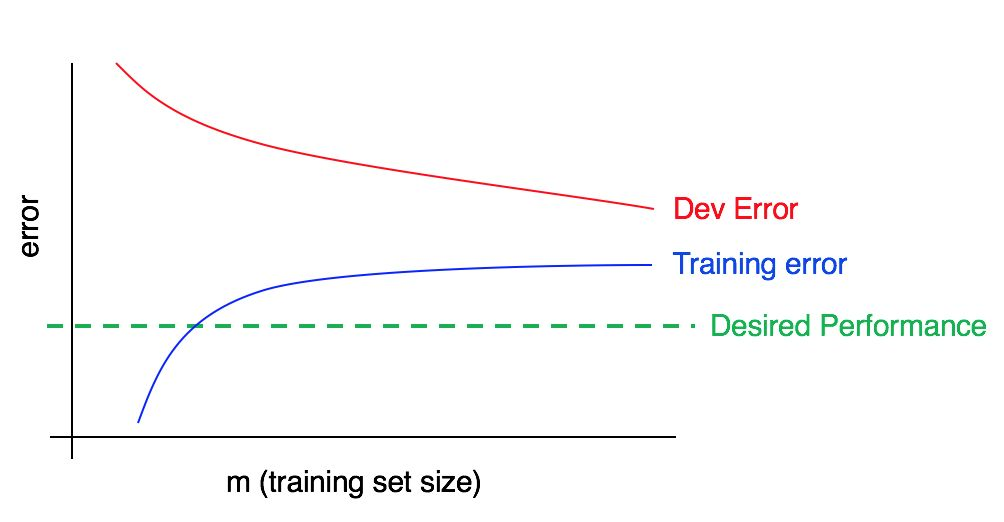
في هذه الحالة ، يكون الخطأ في نموذج التدريب كبيرًا ؛ وهو أعلى بكثير من الخوارزمية المقابلة لمستوى الجودة المطلوب. الخطأ في عينة التحقق من الصحة أعلى أيضًا من الخطأ في نموذج التدريب. وبالتالي ، نحن نتعامل مع تحيز كبير ومبعثر في وقت واحد. يجب أن تبحث عن طرق لتقليل وتعطيل الخوارزمية الخاصة بك.
32. بناء منحنيات التعلم
افترض أن لديك عينة تدريب صغيرة جدًا ، تتكون من 100 مثال فقط. تقوم بتدريب الخوارزمية باستخدام مجموعة فرعية تم اختيارها عشوائيًا من 10 أمثلة ، ثم من 20 مثالًا ، ثم من 30 وما إلى ذلك إلى 100 ، مما يزيد من عدد الأمثلة بفاصل من عشرة أمثلة. ثم باستخدام هذه النقاط العشر ، يمكنك بناء منحنى التعلم الخاص بك. قد تجد أن المنحنى يبدو صاخباً (قيم أعلى أو أقل من المتوقع) لعينات التدريب الأصغر.
عندما تقوم بتدريب الخوارزمية مع 10 أمثلة فقط تم اختيارها بشكل عشوائي ، فقد لا تكون محظوظًا ، وقد يتحول هذا إلى نموذج فرعي تدريب "سيء" بشكل خاص مع مشاركة أكبر من الأمثلة الغامضة / التي تم وضع علامة عليها بشكل غير صحيح. أو ، على العكس ، قد تصادف نموذجًا فرعيًا للتدريب "الجيد" بشكل خاص. وجود عينة تدريب صغيرة يعني أن قيمة الأخطاء في التحقق من صحة وعينات التدريب قد تكون عرضة لتقلبات عشوائية.
إذا كانت البيانات المستخدمة للتطبيق الخاص بك باستخدام التعلم الآلي منحازة بقوة نحو فئة واحدة (كما هو الحال مع مشكلة تصنيف القط ، حيث تكون نسبة الأمثلة السلبية أكبر بكثير من نسبة الإيجابية) ، أو إذا كنا نتعامل مع عدد كبير من الطبقات (مثل التعرف على 100 نوع مختلف من الحيوانات) ، ثم تزداد أيضًا فرصة الحصول على عينة تدريب "غير ممثلة" أو سيئة. على سبيل المثال ، إذا كان 80٪ من الأمثلة الخاصة بك أمثلة سلبية (ص = 0) ، و 20٪ فقط أمثلة إيجابية (ص = 1) ، فهناك فرصة جيدة أن تحتوي مجموعة التدريب الفرعية المكونة من 10 أمثلة على أمثلة سلبية فقط ، وفي هذه الحالة جدًا من الصعب الحصول على شيء معقول من الخوارزمية المدربة.
إذا كان من الصعب إجراء تقييم للاتجاهات ، بسبب ضجيج منحنى التعلم في عينة التدريب ، فيمكنه اقتراح الحلين التاليين:
بدلاً من تدريب نموذج واحد فقط لـ 10 أمثلة تدريب ، قم بالاختيار مع استبدال عدة (على سبيل المثال 3-10) نماذج فرعية تدريب عشوائي مختلفة من العينة الأولية التي تتكون من 100 مثال. تدريب النموذج على كل منها وحساب لكل من هذه النماذج الخطأ في التحقق من الصحة وعينة التدريب. عد ورسم متوسط الخطأ على عينات التدريب والتحقق.
ملاحظة المؤلف: تعني العينة التي تحتوي على بديل ما يلي: حدد بشكل عشوائي أول 10 أمثلة مختلفة من 100 لتكوين أول نموذج فرعي للتدريب. بعد ذلك ، لتكوين النموذج الفرعي للتدريب الثاني ، خذ مرة أخرى 10 أمثلة ، لكن مع استبعاد الأمثلة المحددة في النموذج الفرعي الأول (مرة أخرى من بين مائة مثال). وبالتالي ، قد يظهر مثال واحد محدد في كلا النموذجين الفرعيين. هذا يميز عينة مع بديل من عينة دون بديل ؛ في حالة وجود عينة دون بديل ، سيتم اختيار العينة الفرعية الثانية للتدريب من بين 90 مثال فقط لم تندرج في العينة الفرعية الأولى. في الممارسة العملية ، لا ينبغي أن تكون طريقة اختيار الأمثلة باستبدال أو بدونه ذات أهمية كبيرة ، لكن اختيار الأمثلة باستبدالها ممارسة شائعة.
إذا كانت عينة التدريب الخاصة بك منحازة تجاه أحد الفصول ، أو إذا كانت تتضمن العديد من الفصول ، فاختر نموذج فرعي "متوازن" يتكون من 10 أمثلة تدريب ، تم اختيارها عشوائيًا من 100 عينة. على سبيل المثال ، يمكنك التأكد من أن 2/10 أمثلة إيجابية و 8/10 سلبية. للتلخيص ، يمكنك التأكد من أن نسبة أمثلة كل فصل في مجموعة البيانات الملاحظة قريبة قدر الإمكان من مشاركتها في نموذج التدريب الأولي.
لن أزعج أيًا من هذه الطرق حتى يؤدي الرسم البياني لمنحنيات الأخطاء إلى استنتاج مفاده أن هذه المنحنيات صاخبة للغاية ، مما لا يسمح لنا برؤية اتجاهات مفهومة. إذا كان لديك عينة تدريب كبيرة - دعنا نقول حوالي 10000 نموذج وتوزيع الفصول الدراسية غير منحاز للغاية ، فقد لا تحتاج إلى هذه الطرق.
أخيرًا ، قد يكون بناء منحنى التعلم مكلفًا من وجهة نظر حسابية: على سبيل المثال ، تحتاج إلى تدريب عشرة نماذج ، في أول 1000 مثال ، في 2000 الثانية ، وهكذا حتى آخر واحد يحتوي على 10000 مثال. التدريب النموذجي على كميات صغيرة من البيانات أسرع بكثير من التدريب النموذجي على عينات كبيرة. وبالتالي ، بدلاً من توزيع أحجام العينات الفرعية التدريبية بالتساوي على مقياس خطي ، كما هو موضح أعلاه (1000 ، 2000 ، 3000 ، ... ، 10000) ، يمكنك تدريب النماذج مع زيادة غير خطية في عدد الأمثلة ، على سبيل المثال ، 1000 ، 2000 ، 4000 ، 6000 و 10000 أمثلة. ومع ذلك ، ينبغي أن يوفر لك فهمًا واضحًا لاتجاه الاعتماد على جودة النموذج على عدد أمثلة التدريب في منحنيات التعلم. بالطبع ، هذه التقنية ذات صلة فقط إذا كانت التكلفة الحسابية لتدريب النماذج الإضافية عالية.
تمديد