هذه ليست مجرد نكتة ، ويبدو أن هذه الصورة بعينها تعكس بدقة أكثر جوهر قواعد البيانات هذه ، وفي النهاية سيكون من الواضح لماذا:

وفقًا لتصنيف DB-Engines ، فإن قاعدتي أعمدة NoSQL الأكثر شيوعًا هما Cassandra (المشار إليها فيما يلي باسم CS) و HBase (HB).
بناءً على إرادة المصير ، يعمل فريق إدارة تحميل البيانات التابع لنا في سبيربنك عن كثب مع HB لفترة
طويلة . خلال هذا الوقت ، درسنا نقاط القوة والضعف بشكل جيد وتعلمنا كيف نطبخها. ومع ذلك ، فإن وجود بديل في شكل CS طوال الوقت جعلني أعذب نفسي بشكوك: هل اتخذنا الخيار الصحيح؟ علاوة على ذلك ، قالت نتائج
المقارنة التي أجراها DataStax أن CS قد هزم بسهولة HB بدرجة تقريبية ساحقة. من ناحية أخرى ، DataStax هو شخص مهتم ، ويجب ألا تأخذ كلمة هنا. أيضا ، كانت كمية صغيرة من المعلومات حول شروط الاختبار محرجة ، لذلك قررنا أن نعرف بشكل مستقل من هو ملك BigData NoSql ، وكانت النتائج مثيرة للاهتمام للغاية.
ومع ذلك ، قبل الانتقال إلى نتائج الاختبارات المنجزة ، من الضروري وصف الجوانب الأساسية لتكوينات البيئة. الحقيقة هي أن CS يمكن استخدامها في وضع التسامح فقدان البيانات. أي هذا عندما يكون خادم واحد (عقدة) مسؤولاً عن البيانات الخاصة بمفتاح معين ، وإذا تم إيقاف تشغيله لسبب ما ، فسيتم فقد قيمة هذا المفتاح. بالنسبة للعديد من المهام ، هذا ليس بالأمر الحاسم ، لكن بالنسبة للقطاع المصرفي ، فهذا هو الاستثناء وليس القاعدة. في حالتنا ، من المهم أن يكون لديك عدة نسخ من البيانات للتخزين الموثوق به.
لذلك ، تم النظر فقط في وضع CS للنسخ المتماثل الثلاثي ، أي تم إنشاء الحالة باستخدام المعلمات التالية:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3};
علاوة على ذلك ، هناك طريقتان لضمان المستوى المطلوب من الاتساق. القاعدة العامة:
NW + NR> RF
هذا يعني أن عدد التأكيدات من العقد عند الكتابة (NW) بالإضافة إلى عدد التأكيدات من العقد عند القراءة (NR) يجب أن يكون أكبر من عامل النسخ المتماثل. في حالتنا ، RF = 3 وبالتالي فإن الخيارات التالية مناسبة:
2 + 2> 3
3 + 1> 3
نظرًا لأنه من الأهمية بمكان بالنسبة لنا أن نحافظ على موثوقية البيانات قدر الإمكان ، فقد تم اختيار مخطط 3 + 1. بالإضافة إلى ذلك ، يعمل HB على أساس مشابه ، أي مثل هذه المقارنة ستكون أكثر صدقا.
تجدر الإشارة إلى أن DataStax قام بالعكس في أبحاثهم ، فقد قاموا بتعيين RF = 1 لكل من CS و HB (بالنسبة إلى الأخير من خلال تغيير إعدادات HDFS). هذا جانب مهم حقًا ، لأن التأثير على أداء CS في هذه الحالة كبير. على سبيل المثال ، توضح الصورة أدناه الزيادة في الوقت اللازم لتحميل البيانات في CS:
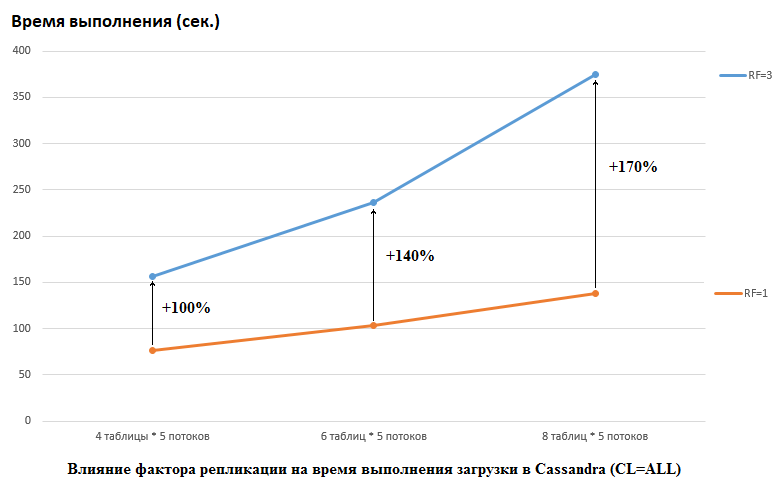
هنا نرى ما يلي ، المواضيع الأكثر تنافسا تكتب البيانات ، كلما طالت المدة. هذا أمر طبيعي ، ولكن من المهم أن يكون تدهور أداء RF = 3 أعلى بكثير. بمعنى آخر ، إذا كتبنا في 4 جداول في كل من 5 تدفقات (المجموع 20) ، فإن RF = 3 تفقد حوالي مرتين (150 ثانية RF = 3 مقابل 75 لل RF = 1). ولكن إذا قمنا بزيادة الحمل عن طريق تحميل البيانات في 8 جداول في كل من 5 تدفقات (إجمالي 40) ، فإن فقدان RF = 3 يكون بالفعل 2.7 مرة (375 ثانية مقابل 138).
ربما هذا جزئيًا سر اختبار DataStax الناجح لاختبار تحميل CS ، لأن تغيير عامل النسخ المتماثل من 2 إلى 3 لم يكن له تأثير بالنسبة لـ HB في موقفنا. أي أقراص ليست عنق الزجاجة ل HB التكوين لدينا. ومع ذلك ، هناك العديد من المزالق الأخرى ، لأنه تجدر الإشارة إلى أن إصدار HB الخاص بنا تم تصحيحه وتعتيمه قليلاً ، البيئات مختلفة تمامًا ، إلخ. تجدر الإشارة أيضًا إلى أنني ربما لا أعرف كيفية إعداد CS بشكل صحيح وهناك بعض الطرق الأكثر فاعلية للتعامل معها وآمل في التعليقات التي سنكتشفها. لكن أول الأشياء أولا.
تم إجراء جميع الاختبارات على مجموعة حديدية تتكون من 4 خوادم ، كل في تكوين:
وحدة المعالجة المركزية: زيون E5-2680 v4 @ 2.40GHZ 64 المواضيع.
الأقراص: 12 قطعة من SATA HDD
نسخة جافا: 1.8.0_111
إصدار CS: 3.11.5
معلمات cassandra.ymlعدد الأرقام: 256
hinted_handoff_enabled: صحيح
hinted_handoff_throttle_in_kb: 1024
max_hints_delivery_threads: 2
تلميحات: / data10 / cassandra / تلميحات
hints_flush_period_in_ms: 10000
max_hints_file_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
الموثق: AllowAllAuthenticator
المخول: AllowAllAuthorizer
Role_manager: CassandraRoleManager
role_validity_in_ms: 2000
أذونات_المادة_العام: 2000
credentials_validity_in_ms: 2000
أداة التقسيم: org.apache.cassandra.dht.Murmur3Partitioner
data_file_directories:
- / data1 / cassandra / data # كل دليل dataN هو محرك منفصل
- / data2 / كاساندرا / البيانات
- / data3 / كاساندرا / البيانات
- / data4 / كاساندرا / البيانات
- / data5 / كاساندرا / البيانات
- / data6 / كاساندرا / البيانات
- / data7 / كاساندرا / البيانات
- / data8 / كاساندرا / البيانات
conflog_directory: / data9 / cassandra / conflog
cdc_enabled: خطأ
disk_failure_policy: توقف
conf_failure_policy: توقف
prepared_statements_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
key_cache_save_period: 14400
row_cache_size_in_mb: 0
row_cache_save_period: 0
counter_cache_size_in_mb:
counter_cache_save_period: 7200
save_caches_directory: / data10 / cassandra / save_caches
conflog_sync: دورية
conflog_sync_period_in_ms: 10000
conflog_segment_size_in_mb: 32
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
المعلمات:
- البذور: "* ، *"
concurrent_reads: 256 # حاول 64 - لا فرق لاحظت
concurrent_writes: 256 # حاول 64 - لا فرق لاحظت
concurrent_counter_writes: 256 # جرب 64 - لم يلاحظ فرق
concurrent_materialized_view_writes: 32
memtable_heap_space_in_mb: 2048 # جرب 16 جيجابايت - كان أبطأ
memtable_allocation_type: heap_buffers
index_summary_capacity_in_mb:
index_summary_resize_interval_in_minutes: 60
trickle_fsync: خطأ
trickle_fsync_interval_in_kb: 10240
storage_port: 7000
ssl_storage_port: 7001
listen_address: *
عنوان البث: *
listen_on_broadcast_address: صحيح
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: صحيح
native_transport_port: 9042
start_rpc: صحيح
rpc_address: *
rpc_port: 9160
rpc_keepalive: صحيح
rpc_server_type: sync
thrift_framed_transport_size_in_mb: 15
incremental_backups: false
snapshot_before_compaction: خطأ
auto_snapshot: صحيح
column_index_size_in_kb: 64
column_index_cache_size_in_kb: 2
مضادات المتزامنة: 4
compaction_throughput_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
read_request_timeout_in_ms: 100000
range_request_timeout_in_ms: 200000
write_request_timeout_in_ms: 40000
counter_write_request_timeout_in_ms: 100000
cas_contention_timeout_in_ms: 20000
truncate_request_timeout_in_ms: 60000
request_timeout_in_ms: 200000
slow_query_log_timeout_in_ms: 500
cross_node_timeout: خطأ
endpoint_snitch: GossipingPropertyFileSnitch
dynamic_snitch_update_interval_in_ms: 100
dynamic_snitch_reset_interval_in_ms: 600000
dynamic_snitch_badness_threshold: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
server_encryption_options:
internode_encryption: لا شيء
client_encryption_options:
تمكين: خطأ
internode_compression: dc
inter_dc_tcp_nodelay: false
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: false
enable_scripted_user_defined_functions: false
windows_timer_interval: 1
transparent_data_encryption_options:
تمكين: خطأ
علامة مميزة: الحد الأدنى: 1000
tombstone_failure_threshold: 100000
batch_size_warn_threshold_in_kb: 200
batch_size_fail_threshold_in_kb: 250
unlogged_batch_across_partitions_warn_threshold: 10
compaction_large_partition_warning_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
back_pressure_enabled: خطأ
enable_materialized_views: true
enable_sasi_indexes: صحيح
إعدادات GC:
### إعدادات CMS-XX: + UseParNewGC
-XX: + UseConcMarkSweepGC
-XX: + CMSParallelRemarkEnabled
-XX: SurvivorRatio = 8
-XX: MaxTenuringThreshold = 1
-XX: CMSInitiatingOccupancyFraction = 75
-XX: + UseCMSInitiatingOccupancyOnly
-XX: CMSWaitDuration = 10000
-XX: + CMSParallelInitialMarkEnabled
-XX: + CMSEdenChunksRecordAlways
-XX: + CMSClassUnloadingEnabled
تم تخصيص ذاكرة jvm.options بسرعة 16 جيجا بايت (لا تزال تحاول 32 جيجا بايت ، ولم يلاحظ أي اختلاف).
تم إنشاء الجداول بواسطة الأمر:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};
إصدار HB: 1.2.0-cdh5.14.2 (في الصف org.apache.hadoop.hbase.regionserver.HRegion استبعدنا MetricsRegion مما أدى إلى GC مع أكثر من 1000 منطقة على RegionServer)
خيارات HBase غير الافتراضيةzookeeper.session.timeout: 120000
hbase.rpc.timeout: دقيقتان
hbase.client.scanner.timeout.period: دقيقتان
hbase.master.handler.count: 10
hbase.regionserver.lease.period ، hbase.client.scanner.timeout.period: 2 دقيقة (دقائق)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.period: 4 ساعات
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 GiB
hbase.hregion.memstore.block.multiplier: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.m Majorcompaction: يوم واحد
HBase Service Advanced Configuration Snippet (صمام الأمان) لـ hbase-site.xml:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
خيارات تكوين Java لـ HBase RegionServer:
-XX: + UseParNewGC -XX: + UseConcMarkSweepGC -XX: CMSInitiatingOccupancyFraction = 70 -XX: + CMSParallelRemarkEnabled -XX: ReservedCodeCacheSize = 256m
hbase.snapshot.master.timeoutMillis: دقيقتان
hbase.snapshot.region.timeout: دقيقتان
hbase.snapshot.master.timeout.millis: دقيقتان
HBase REST Server Max حجم السجل: 100 MiB
HBase خادم أقصى خادم سجل النسخ الاحتياطي: 5
HBase Thrift Server Max حجم السجل: 100 MiB
HBase الادخار خادم الحد الأقصى سجل ملف النسخ الاحتياطي: 5
ماجستير ماكس حجم السجل: 100 ميجابايت
ماجستير النسخ الاحتياطي ملف السجل الأقصى: 5
سجل منطقة النطاق الأقصى: 100 ميجابايت
النسخ الاحتياطي الأقصى لملف سجل RegionServer: 5
نافذة اكتشاف Master HBase النشطة: 4 دقائق
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: 10 مللي ثانية
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
واصفات ملف العملية القصوى: 180،000
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.size: 20
المواضيع منطقة المحرك: 6
عميل Java Heap Size بالبايت: 1 GiB
HBase REST Server المجموعة الافتراضية: 3 GiB
HBase Thrift Server المجموعة الافتراضية: 3 GiB
Java Heap Size of HBase Master in Bytes: 16 GiB
حجم كومة Java من HBase RegionServer بالبايت: 32 جيجا بايت
+ ZooKeeper
maxClientCnxns: 601
maxSessionTimeout: 120000
إنشاء الجداول:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns: t1 UniformSplit -c 64 -f cf
تغيير 'ns: t1' ، {NAME => 'cf' ، DATA_BLOCK_ENCODING => 'FAST_DIFF' ، COMPRESSION => 'GZ'}هناك نقطة مهمة واحدة - لا يوضح وصف DataStax عدد المناطق التي تم استخدامها لإنشاء جداول HB ، على الرغم من أن هذا أمر مهم بالنسبة للكميات الكبيرة. لذلك ، للاختبارات ، تم اختيار الرقم = 64 ، والذي يسمح بتخزين ما يصل إلى 640 جيجابايت ، أي طاولة متوسطة الحجم.
في وقت الاختبار ، كان لدى HBase 22 ألف طاولة و 67 ألف منطقة (سيكون ذلك قاتلاً بالنسبة للإصدار 1.2.0 ، إن لم يكن للتصحيح المذكور أعلاه).
الآن للرمز. نظرًا لأنه لم يكن من الواضح التكوينات الأكثر فائدة لقاعدة بيانات معينة ، فقد تم إجراء الاختبارات في مجموعات مختلفة. أي في بعض الاختبارات ، ذهب الحمل في وقت واحد إلى 4 جداول (تم استخدام جميع العقد الأربعة للاتصال). في اختبارات أخرى ، عملوا مع 8 طاولات مختلفة. في بعض الحالات ، كان حجم الدُفعات 100 ، وفي حالات أخرى 200 (معلمة الدُفعات - انظر الكود أدناه). حجم البيانات للقيمة 10 بايت أو 100 بايت (حجم البيانات). في المجموع ، تم كتابة 5 ملايين السجلات وطرحها في كل مرة في كل جدول. في الوقت نفسه ، تمت كتابة / قراءة 5 تدفقات في كل جدول (رقم الدفق هو thNum) ، استخدم كل منها نطاقه الرئيسي (عدد = 1 مليون):
if (opType.equals("insert")) { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { StringBuilder sb = new StringBuilder("BEGIN BATCH "); for (int i = 0; i < batch; i++) { String value = RandomStringUtils.random(dataSize, true, true); sb.append("INSERT INTO ") .append(tableName) .append("(id, title) ") .append("VALUES (") .append(key) .append(", '") .append(value) .append("');"); key++; } sb.append("APPLY BATCH;"); final String query = sb.toString(); session.execute(query); } } else { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN ("); for (int i = 0; i < batch; i++) { sb = sb.append(key); if (i+1 < batch) sb.append(","); key++; } sb = sb.append(");"); final String query = sb.toString(); ResultSet rs = session.execute(query); } }
وفقًا لذلك ، تم توفير وظيفة مماثلة لـ HB:
Configuration conf = getConf(); HTable table = new HTable(conf, keyspace + ":" + tableName); table.setAutoFlush(false, false); List<Get> lGet = new ArrayList<>(); List<Put> lPut = new ArrayList<>(); byte[] cf = Bytes.toBytes("cf"); byte[] qf = Bytes.toBytes("value"); if (opType.equals("insert")) { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { lPut.clear(); for (int i = 0; i < batch; i++) { Put p = new Put(makeHbaseRowKey(key)); String value = RandomStringUtils.random(dataSize, true, true); p.addColumn(cf, qf, value.getBytes()); lPut.add(p); key++; } table.put(lPut); table.flushCommits(); } } else { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { lGet.clear(); for (int i = 0; i < batch; i++) { Get g = new Get(makeHbaseRowKey(key)); lGet.add(g); key++; } Result[] rs = table.get(lGet); } }
نظرًا لأن العميل يجب أن يهتم بالتوزيع الموحد للبيانات في HB ، فإن وظيفة التمليح الرئيسية تبدو كما يلي:
public static byte[] makeHbaseRowKey(long key) { byte[] nonSaltedRowKey = Bytes.toBytes(key); CRC32 crc32 = new CRC32(); crc32.update(nonSaltedRowKey); long crc32Value = crc32.getValue(); byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7); return ArrayUtils.addAll(salt, nonSaltedRowKey); }
الآن الأكثر إثارة للاهتمام هي النتائج:

نفس الرسم البياني:
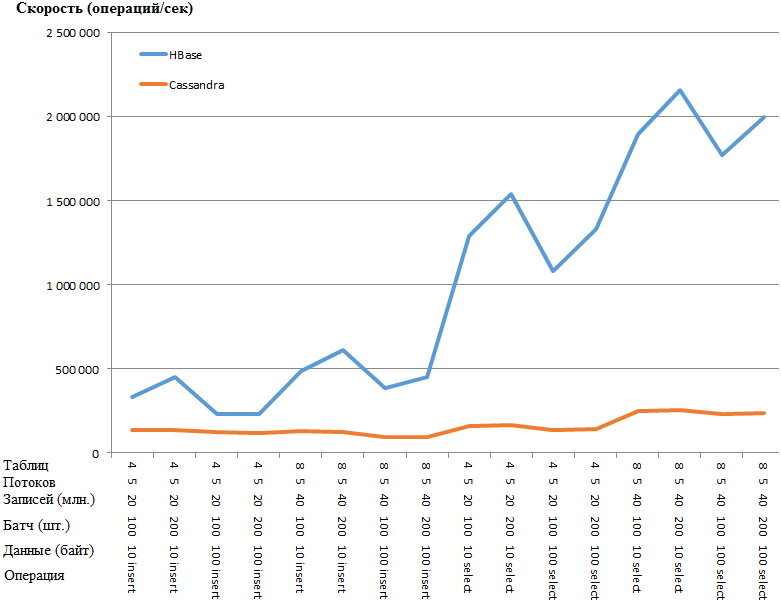
تتميز ميزة HB بأنها مدهشة لدرجة أنه يوجد شك في وجود نوع من عنق الزجاجة في إعدادات CS. ومع ذلك ، فإن googling والتواء المعلمات الأكثر وضوحًا (مثل concurrent_writes أو memtable_heap_space_in_mb) لم يعطيا تسارعًا. في الوقت نفسه ، سجلات نظيفة ، لا أقسم على أي شيء.
تكمن البيانات بالتساوي عبر العقد ، والإحصاءات من جميع العقد هي نفسها تقريبا.
فيما يلي الإحصاءات الموجودة على الجدول مع إحدى العقدKeyspace: كانساس
عدد مرات القراءة: 9383707
قراءة الكمون: 0.04287025042448576 مللي
عدد الكتابة: 15462012
الكتابة الكمون: 0.1350068438699957 مللي
الهبات المعلقة: 0
الجدول: t1
SSTable العد: 16
المساحة المستخدمة (حي): 148.59 ميجابايت
المساحة المستخدمة (المجموع): 148.59 ميجابايت
المساحة المستخدمة من قبل لقطات (الإجمالي): 0 بايت
إيقاف كومة الذاكرة المستخدمة (الإجمالي): 5.17 ميجابايت
نسبة ضغط SSTable: 0.5720989576459437
عدد الأقسام (تقدير): 3970323
عدد الخلايا Memtable: 0
حجم البيانات Memtable: 0 بايت
Memtable إيقاف الذاكرة كومة الذاكرة المؤقتة المستخدمة: 0 بايت
Memtable التبديل العد: 5
إحصاء القراءة المحلي: 2346045
قراءة زمن الوصول المحلي: NaN ms
عدد الكتابة المحلية: 3865503
زمن انتقال الكتابة المحلية: NaN ms
الهبات المعلقة: 0
إصلاح النسبة المئوية: 0.0
بلوم مرشح ايجابيات كاذبة: 25
بلوم مرشح نسبة كاذبة: 0.00000
مساحة مرشح بلوم المستخدمة: 4.57 ميجابايت
تصفية بلوم قبالة ذاكرة كومة المستخدمة: 4.57 ميغابايت
ملخص الفهرس إيقاف الذاكرة كومة الذاكرة المؤقتة المستخدمة: 590.02 KiB
بيانات التعريف ضغط خارج الذاكرة كومة الذاكرة المؤقتة المستخدمة: 19.45 كيلوبايت
الحد الأدنى من وحدات البايت المضغوطة: 36
الحد الأقصى لقسم البايت المضغوطة: 42
يعني القسم المضغوط بايت: 42
متوسط الخلايا الحية لكل شريحة (آخر خمس دقائق): NaN
الحد الأقصى للخلايا الحية لكل شريحة (آخر خمس دقائق): 0
شواهد القبور المتوسطة لكل شريحة (آخر خمس دقائق): NaN
الحد الأقصى لشواهد القبور لكل شريحة (آخر خمس دقائق): 0
الطفرات المسقطة: 0 بايت
لم يكن لمحاولة تقليل حجم الدُفعة (حتى إرسال واحدة تلو الأخرى) تأثير ، بل ازدادت سوءًا. من الممكن أن يكون هذا في الواقع هو أقصى أداء لـ CS ، حيث إن النتائج التي تم الحصول عليها على CS تشبه تلك التي تم الحصول عليها لـ DataStax - حوالي مئات الآلاف من العمليات في الثانية. بالإضافة إلى ذلك ، إذا نظرت إلى استخدام الموارد ، فسترى أن CS يستخدم الكثير من وحدة المعالجة المركزية والأقراص:
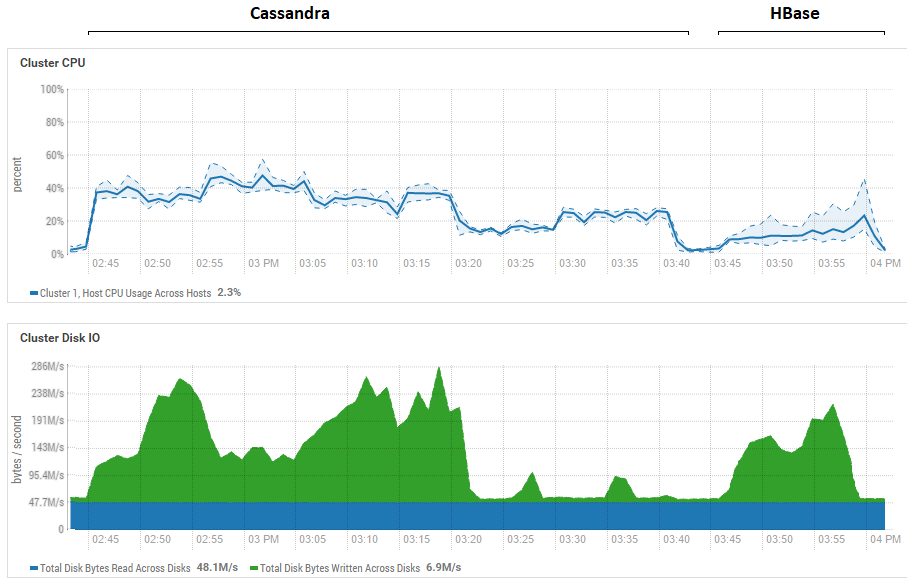 يوضح الشكل استخدام جميع الاختبارات على التوالي لكل من قواعد البيانات.
يوضح الشكل استخدام جميع الاختبارات على التوالي لكل من قواعد البيانات.فيما يتعلق بفوائد القراءة القوية لـ HB. يمكن ملاحظة أن استخدام القرص أثناء القراءة منخفض للغاية بالنسبة لكل من قواعد البيانات (اختبارات القراءة هي الجزء الأخير من دورة الاختبار لكل قاعدة بيانات ، على سبيل المثال ، لـ CS من 15:20 إلى 15:40). في حالة HB ، السبب واضح - فمعظم البيانات معلقة في الذاكرة ، في الذاكرة ، وبعضها تم تخزينه في ذاكرة التخزين المؤقت. بالنسبة إلى CS ، ليس من الواضح تمامًا كيف يعمل ، ومع ذلك ، فإن استخدام القرص غير مرئي أيضًا ، ولكن فقط في حالة حدوث محاولة لتشغيل ذاكرة التخزين المؤقت row_cache_size_in_mb = 2048 وتعيين التخزين المؤقت = {'keys': 'ALL'، 'rows_per_partition': ' 2،000،000 '} ، ولكن هذا جعل الأمر أسوأ قليلا.
يجدر أيضًا أن نقول مرة أخرى نقطة مهمة حول عدد المناطق في HB. في حالتنا ، تمت الإشارة إلى القيمة 64. إذا قمت بتقليلها وجعلتها تساوي على سبيل المثال 4 ، ثم عند انخفاض السرعة تنخفض مرتين. والسبب هو أن memstore سوف تسد بشكل أسرع وأن الملفات سوف تتسرب أكثر من مرة ، وعند قراءتها ستحتاج إلى معالجة المزيد من الملفات ، وهي عملية معقدة إلى حد ما بالنسبة لـ HB. في الظروف الحقيقية ، يمكن معالجة ذلك من خلال التفكير في استراتيجية الإعداد المسبق والتعاقد ، على وجه الخصوص ، نستخدم أداة مساعدة ذاتية تجمع القمامة وتضغط HFiles باستمرار في الخلفية. من الممكن أنه بالنسبة لاختبارات DataStax ، تم تخصيص منطقة واحدة عمومًا لكل جدول (وهذا غير صحيح) وهذا سيوضح إلى حد ما سبب فقدان HB كثيرًا في اختبارات القراءة الخاصة بهم.
الاستنتاجات الأولية من هذا هي على النحو التالي. على افتراض عدم وجود أخطاء فادحة أثناء الاختبار ، فإن كاساندرا يشبه العملاق ذو أقدام من الطين. بتعبير أدق ، بينما تتوازن على ساق واحدة ، كما في الصورة في بداية المقال ، فإنها تظهر نتائج جيدة نسبيًا ، لكن عندما تقاتل في ظل نفس الظروف ، فإنها تخسر تمامًا. في الوقت نفسه ، مع الأخذ في الاعتبار الاستخدام المنخفض لوحدة المعالجة المركزية على أجهزتنا ، تعلمنا أن نزرع HBs من RegionServer لكل مضيف وبالتالي ضاعفت الإنتاجية. أي مع الأخذ في الاعتبار استخدام الموارد ، فإن وضع CS أكثر استياءًا.
بالطبع ، هذه الاختبارات اصطناعية تمامًا وكمية البيانات المستخدمة هنا متواضعة نسبيًا. من المحتمل أنه عند التبديل إلى تيرابايت ، سيكون الموقف مختلفًا ، ولكن إذا كان بوسع HB تحميل تيرابايت ، فقد كان هذا بالنسبة إلى CS يمثل مشكلة. غالبًا ما يتم طرحه على OperationTimedOutException حتى مع هذه الكميات ، على الرغم من أن معلمات توقع الاستجابة قد تمت زيادتها بالفعل عدة مرات مقارنة بالعناصر الافتراضية.
آمل أنه من خلال الجهود المشتركة ، سنجد اختناقات في خدمة العملاء وإذا نجحنا في تسريعها ، فعندئذ سأضيف بالتأكيد معلومات حول النتائج النهائية في نهاية المنشور.
محدث: تم تطبيق الإرشادات التالية على إعداد CS:
disk_optimization_strategy: الغزل
MAX_HEAP_SIZE = "32G"
HEAP_NEWSIZE = "3200M"
-Xms32G
-Xmx32G
-XX: + UseG1GC
-XX: G1RSetUpdatingPauseTimePercent = 5
-XX: MaxGCPauseMillis = 500
-XX: initatingHeapOccupancyPercent = 70
-XX: ParallelGCThreads = 32
-XX: ConcGCThreads = 8بالنسبة إلى إعدادات نظام التشغيل ، يعد هذا الإجراء طويلًا ومعقدًا (الحصول على الجذر ، إعادة تشغيل الخوادم ، وما إلى ذلك) ، لذلك لم يتم تطبيق هذه التوصيات. من ناحية أخرى ، كلا قواعد البيانات في ظروف متساوية ، لذلك كل شيء عادل.
في جزء الكود ، يوجد موصل واحد لجميع مؤشرات الترابط التي تكتب إلى الجدول:
connector = new CassandraConnector(); connector.connect(node, null, CL); session = connector.getSession(); session.getCluster().getConfiguration().getSocketOptions().setConnectTimeoutMillis(120000); KeyspaceRepository sr = new KeyspaceRepository(session); sr.useKeyspace(keyspace); prepared = session.prepare("insert into " + tableName + " (id, title) values (?, ?)");
تم إرسال البيانات عبر الربط:
for (Long key = count * thNum; key < count * (thNum + 1); key++) { String value = RandomStringUtils.random(dataSize, true, true); session.execute(prepared.bind(key, value)); }
لم يكن لهذا تأثير كبير على أداء التسجيل. من أجل الموثوقية ، أطلقت الحمل باستخدام أداة YCSB ، وهي نفس النتيجة تمامًا. يوجد أدناه إحصائيات لمؤشر واحد (من أصل 4):
2020-01-18 14: 41: 53: 180 315 ثانية: 10،000،000 عملية ؛ 21589.1 العمليات الحالية / ثانية ؛ [CLEANUP: Count = 100 ، Max = 2236415 ، Min = 1 ، Avg = 22356.39 ، 90 = 4 ، 99 = 24 ، 99.9 = 2236415 ، 99.99 = 2236415] [INSERT: Count = 119551، Max = 174463، Min = 273، المتوسط = 2582.71 ، 90 = 3491 ، 99 = 16767 ، 99.9 = 99711 ، 99.99 = 171263]
[بشكل عام] ، RunTime (مللي ثانية) ، 315539
[بشكل عام] ، الإنتاجية (العمليات / ثانية) ، 31691.803548848162
[TOTAL_GCS_PS_Scavenge] ، العدد ، 161
[TOTAL_GC_TIME_PS_Scavenge] ، الوقت (مللي ثانية) ، 2433
[TOTAL_GC_TIME _٪ _ PS_Scavenge] ، الوقت (٪) ، 0.7710615803434757
[TOTAL_GCS_PS_MarkSweep] ، عدد ، 0
[TOTAL_GC_TIME_PS_MarkSweep] ، الوقت (مللي ثانية) ، 0
[TOTAL_GC_TIME _٪ _ PS_MarkSweep] ، الوقت (٪) ، 0.0
[TOTAL_GCs] ، الكونت ، 161
[TOTAL_GC_TIME] ، الوقت (مللي ثانية) ، 2433
[TOTAL_GC_TIME_٪] ، الوقت (٪) ، 0.7710615803434757
[إدراج] ، العمليات ، 1000000
[INSERT] ، AverageLatency (us) ، 3114.2427012
[إدراج] ، MinLatency (لنا) ، 269
[INSERT] ، MaxLatency (us) ، 609279
[INSERT] ، 95thPercentileLatency (us) ، 5007
[INSERT] ، 99 thPercentileLatency (us) ، 33439
[INSERT] ، Return = OK ، 10000000
هنا يمكنك أن ترى أن سرعة دفق واحد هي حوالي 32 ألف سجل في الثانية الواحدة ، تعمل 4 تدفقات ، وتبين 128 ألفًا ، ويبدو أنه لا يوجد شيء آخر للضغط على الإعدادات الحالية للنظام الفرعي للقرص.
حول قراءة أكثر إثارة للاهتمام. بفضل نصيحة الرفاق ، تمكن من تسريع جذري. أجريت القراءة ليس في 5 تيارات ، ولكن في 100. زيادة إلى 200 لم ينتج عنها تأثير. تمت الإضافة أيضًا إلى المنشئ:
.withLoadBalancingPolicy (TokenAwarePolicy الجديد (DCAwareRoundRobinPolicy.builder (). build ()))
نتيجة لذلك ، إذا أظهر الاختبار في وقت مبكر 159 644 مكتب خدمات المشاريع (5 تدفقات ، 4 جداول ، 100 دفعة) ، الآن:
100 مؤشر ترابط ، 4 جداول ، مجموعة = 1 (بشكل فردي): 301 969 ops
100 مؤشر ترابط ، 4 جداول ، دُفعة = 10: 447 608 ops
100 مؤشر ترابط ، 4 جداول ، دُفعة = 100: 625 655 ops
نظرًا لأن النتائج أفضل مع الدُفعات ، فقد أجريت اختبارات * مماثلة مع HB:
 * منذ العمل في 400 مؤشر ترابط ، فإن وظيفة RandomStringUtils ، التي تم استخدامها سابقًا ، قد تم تحميل وحدة المعالجة المركزية بنسبة 100٪ ، وتم استبدالها بمولد أسرع.
* منذ العمل في 400 مؤشر ترابط ، فإن وظيفة RandomStringUtils ، التي تم استخدامها سابقًا ، قد تم تحميل وحدة المعالجة المركزية بنسبة 100٪ ، وتم استبدالها بمولد أسرع.وبالتالي ، فإن زيادة عدد مؤشرات الترابط عند تحميل البيانات يعطي زيادة بسيطة في أداء HB.
أما بالنسبة للقراءة ، فإليك نتائج العديد من الخيارات. بناءً على طلب
0x62ash ، تم تنفيذ أمر التدفق قبل القراءة ، كما تتوفر عدة خيارات أخرى للمقارنة:
Memstore - القراءة من الذاكرة ، أي قبل التنظيف على القرص.
HFile + zip - القراءة من الملفات المضغوطة بواسطة خوارزمية GZ.
HFile + upzip - قراءة من الملفات دون ضغط.
هناك ميزة مهمة جديرة بالملاحظة ، حيث تتم معالجة الملفات الصغيرة (راجع حقل "البيانات" ، حيث تتم كتابة 10 بايت) ببطء أكثر ، خاصةً إذا تم ضغطها. من الواضح أن هذا ممكن فقط حتى حجم معين ، ومن الواضح أن ملف 5 جيجابايت لن تتم معالجته بشكل أسرع من 10 ميغابايت ، لكنه يشير بوضوح إلى أنه في جميع هذه الاختبارات لا يوجد أي حقل محروث للبحث في التكوينات المختلفة.
من أجل الاهتمام ، قمت بتصحيح رمز YCSB للعمل مع دفعات HB من 100 قطعة لقياس الكمون وأكثر من ذلك. فيما يلي نتيجة عمل 4 نسخ مكتوبة على طاولاتها ، ولكل منها 100 موضوع. اتضح ما يلي:
عملية واحدة = 100 السجلات[بشكل عام] ، RunTime (ms) ، 1165415
[بشكل عام] ، الإنتاجية (العمليات / ثانية) ، 858.06343662987
[TOTAL_GCS_PS_Scavenge] ، الكونت ، 798
[TOTAL_GC_TIME_PS_Scavenge] ، الوقت (مللي ثانية) ، 7346
[TOTAL_GC_TIME _٪ _ PS_Scavenge] ، الوقت (٪) ، 0.6303334005483026
[TOTAL_GCS_PS_MarkSweep] ، عدد ، 1
[TOTAL_GC_TIME_PS_MarkSweep] ، الوقت (مللي ثانية) ، 74
[TOTAL_GC_TIME _٪ _ PS_MarkSweep] ، الوقت (٪) ، 0.006349669431061038
[TOTAL_GCs] ، الكونت ، 799
[TOTAL_GC_TIME] ، الوقت (مللي ثانية) ، 7420
[TOTAL_GC_TIME_٪] ، الوقت (٪) ، 0.6366830699793635
[INSERT] ، العمليات ، 1،000،000
[INSERT] ، AverageLatency (us) ، 115893.891644
[أدرج] ، MinLatency (لنا) ، 14528
[INSERT] ، MaxLatency (us) ، 1470463
[INSERT] ، 95thPercentileLatency (us) ، 248319
[INSERT] ، 99 thPercentileLatency (us) ، 445951
[INSERT] ، Return = OK ، 1،000،000
20/01/19 13:19:16 عميل INFO.ConnectionManager $ HConnectionImplementation: إغلاق برنامج zookeeper sessionid = 0x36f98ad0a4ad8cc
20/01/19 13:19:16 INFO zookeeper.ZooKeeper: الجلسة: 0x36f98ad0a4ad8cc مغلقة
20/01/19 13:19:16 INFO zookeeper.ClientCnxn: EventThread اغلاق
[بشكل عام] ، RunTime (ms) ، 1165806
[بشكل عام] ، الإنتاجية (العمليات / ثانية) ، 857.7756504941646
[TOTAL_GCS_PS_Scavenge] ، الكونت ، 776
[TOTAL_GC_TIME_PS_Scavenge] ، الوقت (مللي ثانية) ، 7517
[TOTAL_GC_TIME _٪ _ PS_Scavenge] ، الوقت (٪) ، 0.6447899564764635
[TOTAL_GCS_PS_MarkSweep] ، عدد ، 1
[TOTAL_GC_TIME_PS_MarkSweep] ، الوقت (مللي ثانية) ، 63
[TOTAL_GC_TIME _٪ _ PS_MarkSweep] ، الوقت (٪) ، 0.005403986598113236
[TOTAL_GCs] ، الكونت ، 777
[TOTAL_GC_TIME] ، الوقت (مللي ثانية) ، 7580
[TOTAL_GC_TIME_٪] ، الوقت (٪) ، 0.6501939430745767
[INSERT] ، العمليات ، 1،000،000
[INSERT] ، AverageLatency (us) ، 116042.207936
[INSERT] ، MinLatency (us) ، 14056
[INSERT] ، MaxLatency (us) ، 1462271
[INSERT] ، 95thPercentileLatency (us) ، 250239
[INSERT] ، 99 thPercentileLatency (us) ، 446719
[INSERT] ، Return = OK ، 1،000،000
20/01/19 13:19:16 عميل INFO.ConnectionManager $ HConnectionImplementation: إغلاق برنامج zookeeper sessionid = 0x26f98ad07b6d67e
20/01/19 13:19:16 INFO zookeeper.ZooKeeper: الجلسة: 0x26f98ad07b6d67e مغلقة
20/01/19 13:19:16 INFO zookeeper.ClientCnxn: EventThread اغلاق
[بشكل عام] ، RunTime (ms) ، 1165999
[بشكل عام] ، الإنتاجية (العمليات / ثانية) ، 857.63366863951
[TOTAL_GCS_PS_Scavenge] ، العدد ، 818
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7557
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6481137633908777
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 79
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.006775305982252128
[TOTAL_GCs], Count, 819
[TOTAL_GC_TIME], Time(ms), 7636
[TOTAL_GC_TIME_%], Time(%), 0.6548890693731299
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116172.212864
[INSERT], MinLatency(us), 7952
[INSERT], MaxLatency(us), 1458175
[INSERT], 95thPercentileLatency(us), 250879
[INSERT], 99thPercentileLatency(us), 446463
[INSERT], Return=OK, 1000000
20/01/19 13:19:17 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x36f98ad0a4ad8cd
20/01/19 13:19:17 INFO zookeeper.ZooKeeper: Session: 0x36f98ad0a4ad8cd closed
20/01/19 13:19:17 INFO zookeeper.ClientCnxn: EventThread shut down
[OVERALL], RunTime(ms), 1166860
[OVERALL], Throughput(ops/sec), 857.000839860823
[TOTAL_GCS_PS_Scavenge], Count, 707
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7239
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6203829079752499
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 67
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0057419056270675145
[TOTAL_GCs], Count, 708
[TOTAL_GC_TIME], Time(ms), 7306
[TOTAL_GC_TIME_%], Time(%), 0.6261248136023173
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116230.849308
[INSERT], MinLatency(us), 7352
[INSERT], MaxLatency(us), 1443839
[INSERT], 95thPercentileLatency(us), 250623
[INSERT], 99thPercentileLatency(us), 447487
[INSERT], Return=OK, 1000000
, CS AverageLatency(us) 3114, HB AverageLatency(us) = 1162 (, 1 = 100 ).
— HBase. , SSD . , , , 4 , 400 , . : — . . ScyllaDB , …