لفترة طويلة كنت أكتب مقالاً عن نومبا وعن مقارنة سرعته مع سي. هاسكل المادة " أسرع من C ++ ؛ أبطأ من PHP "دفعت إلى العمل. في التعليقات على هذه المقالة ، ذكروا مكتبة numba وأنه يمكن تقريبًا سحريًا سرعة تنفيذ التعليمات البرمجية في الثعبان إلى السرعة في s. في هذه المقالة ، بعد مراجعة قصيرة على numba (الجزء 1) ، تحليل أكثر تفصيلاً قليلاً لهذا الموقف ( الجزء 2 ).

العيب الرئيسي للثعبان يعتبر سرعته. بدأ رفع تردد التشغيل بيثون مع نجاح متفاوتة تقريبا من الأيام الأولى من وجودها: shedskin ، psyco ، الضحلة unladen ، ببغاء ، theano ، nuitka ، pythran ، cython ، pypy ، numba .
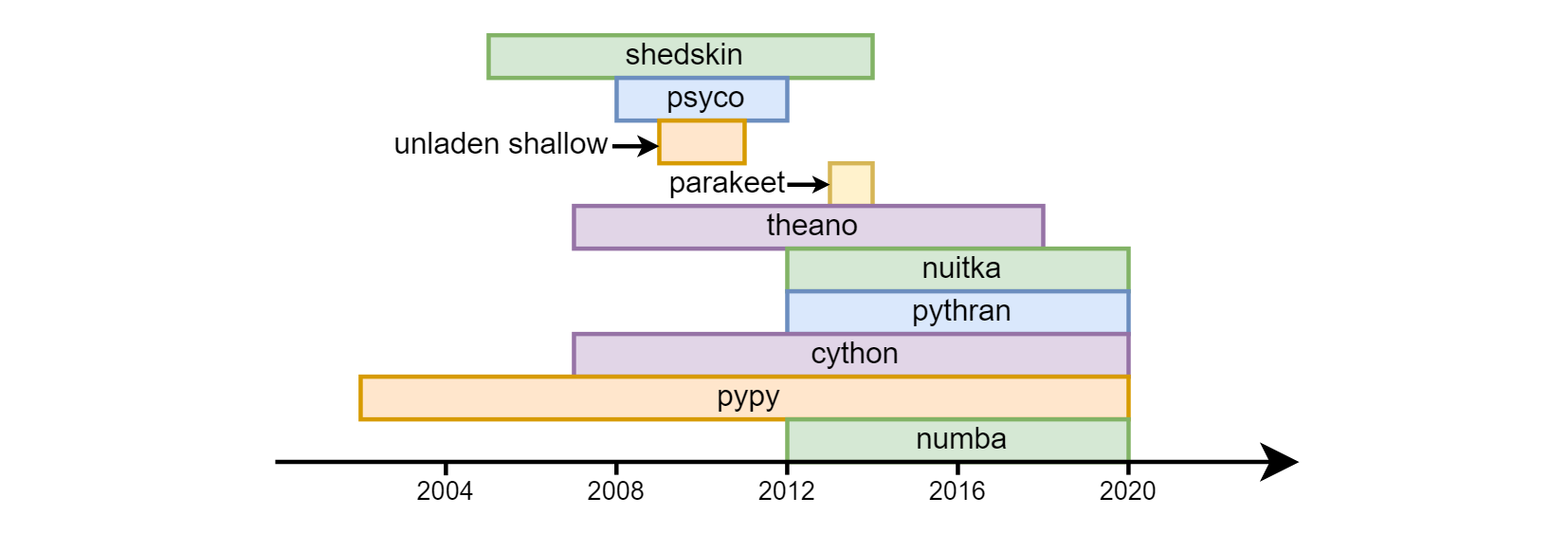
حتى الآن ، الثلاثة الأخيرة هي الأكثر طلبا. Cython (يجب عدم الخلط بينه وبين cpython) - يختلف تمامًا عن دلالات الثعبان العادي. في الواقع ، هذه لغة منفصلة - مزيج من C و python. أما بالنسبة لـ pypy (تطبيق بديل لمترجم python باستخدام تجميع jit) و numba (مكتبة لتجميع التعليمات البرمجية في llvm) ، فقد ذهبوا بطرق مختلفة. أعلن pypy البداية دعمه لجميع بنيات الثعبان. في numba ، انطلقوا من حقيقة أنه في معظم الأحيان يتطلب حسابات رياضية مرتبطة بوحدة المعالجة المركزية ، على التوالي ، حددوا جزء اللغة المرتبطة بالحسابات وبدأوا في رفع تردد التشغيل ، مما زاد تدريجياً من "التغطية" (على سبيل المثال ، حتى وقت قريب لم يكن هناك دعم خطي) ، الآن لقد ظهرت). وفقًا لذلك ، لا يتم رفع تردد التشغيل عن البرنامج بالكامل في numba ، ولكن وظائف منفصلة ، يتيح لك هذا الجمع بين السرعة العالية والتوافق مع الإصدارات السابقة مع المكتبات التي لا numba (حتى الآن). Numpy معتمد (مع قيود طفيفة) في كل من numba و numba .
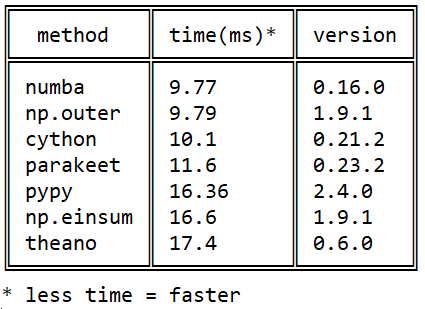 بدأت معرفتي بـ Numba في عام 2015 مع هذا السؤال حول stackoverflow حول سرعة تكاثر المصفوفة في الثعبان: منتج خارجي فعال في الثعبان
بدأت معرفتي بـ Numba في عام 2015 مع هذا السؤال حول stackoverflow حول سرعة تكاثر المصفوفة في الثعبان: منتج خارجي فعال في الثعبان
منذ ذلك الحين ، وقعت العديد من الأحداث في كل من المكتبات ، لكن الصورة المتعلقة بـ numba / numba / cython لم تتغير من حيث numba : numba تتفوق على cython خلال استخدام إرشادات المعالج الأصلي ( cython لا يمكن jit) ، و pypy بسبب التنفيذ الأكثر فعالية لل llvm bytecode .
Numba مفيد لي في العمل (معالجة الصور الفائقة الطيفية) وفي التدريس (التكامل العددي ، حل المعادلات التفاضلية).
كيفية تعيين
قبل عامين ، كانت هناك مشاكل في التثبيت ، والآن تم حل كل شيء: يتم تثبيته جيدًا على حد سواء من خلال pip install numba ومن خلال conda install numba . يتم تشديد llvm وتثبيته تلقائيا.
كيفية تسريع
لتسريع إحدى الوظائف ، يجب عليك إدخال الديكور njit قبل تحديده:
from numba import njit @njit def f(n): s = 0. for i in range(n): s += sqrt(i) return s
تسارع 40 مرة.
هناك حاجة إلى الجذر ، لأنه خلاف ذلك سوف يتعرف numba على مجموع التقدم الحسابي (!) وحسابه في وقت ثابت.
جيت مقابل njit
في السابق ، @jit وضع @jit فقط (وليس @njit ) ذا صلة. النقطة المهمة هي أنه في هذا الوضع ، يمكنك استخدام العمليات غير المدعومة من قبل numba: يصل numba بسرعة عالية إلى أول عملية من هذا القبيل ، ثم يتباطأ ، وحتى نهاية تنفيذ الوظيفة بالسرعة المعتادة Python ، حتى لو لم تتم مصادفة أي شيء آخر "ممنوع" في الوظيفة ( وضع كائن ما يسمى) ، وهو أمر غير منطقي واضح. الآن يتخلون عن @jit ، يوصى دائمًا باستخدام @ njit (أو في شكله الكامل @jit(nopython=True) ): في هذا الوضع ، يقسم numba باستثناءات في مثل هذه الأماكن - من الأفضل إعادة كتابتها حتى لا تفقد سرعتها.
ما يمكن تسريع
في وظائف overclocked ، يمكن استخدام جزء فقط من وظائف python و numba. تنقسم جميع العوامل والوظائف والفئات إلى جزأين فيما يتعلق بالرقم: الأرقام التي "يفهمها" الرقم "والذين يفهمون".
توجد قائمتان من هذا القبيل في وثائق numba (مع أمثلة):
- مجموعة فرعية من وظائف الثعبان مألوفة لخدر و
- مجموعة فرعية من وظيفي numpy مألوفة لخدر .
من الجدير بالذكر في هذه القوائم:
- numba "يفهم" قوائم Python مع الإضافات السريعة (المطفأة O (1)) إلى النهاية التي "numpy" لا تفهم "(على الرغم من تلك المتجانسة فقط من عناصر من نفس النوع) ،
- صفائف numpy التي ليست في الثعبان الأساسي. يفهم أيضا
- tuples: يمكنهم ، مثل الثعبان العادي ، تحتوي على عناصر من أنواع مختلفة.
- القواميس: numba له تطبيقه الخاص لقاموس مكتوب. يجب أن تكون جميع المفاتيح من نفس النوع ، تمامًا مثل القيم. لا يمكن تمرير dict python إلى numba ، ولكن يمكن إنشاء numba
numba.typed.Dict في python ونقله إلى / من numba (بينما يعمل في python أبطأ قليلاً من python). - str ومؤخرا بايت ، ومع ذلك ، فقط كما لا يمكن إنشاء معلمات الإدخال (حتى الآن؟).
إنها لا تفهم أي مكتبات أخرى (على وجه الخصوص ، سكيدي والباندا) على الإطلاق.
لكن حتى هذه المجموعة الفرعية من اللغة التي تفهمها تكفي لرفع تردد معظم التعليمات البرمجية للتطبيقات العلمية التي تركز عليها numba بشكل أساسي.
! المهم
من وظائف فيركلوكيد ، وظائف فقط فيركلوكيد ، ليست فيركلوكيد ، يمكن أن يسمى.
(على الرغم من أنه يمكن استدعاء وظائف overclocked من فيركلوكيد وليس فيركلوكيد).
غلوبالس
في الدالات فيركلوكيد ، تصبح المتغيرات العامة ثوابت: يتم إصلاح قيمتها في وقت تجميع الوظيفة ( مثال ). => لا تستخدم المتغيرات العامة في وظائف فيركلوكيد (باستثناء الثوابت).
التوقيعات
في عدد كل وظيفة ، يتم تعيين وسيطة أو عدة أنواع من وسائط المدخلات والمخرجات ، أي التوقيعات. عند استدعاء الوظيفة لأول مرة ، يتم إنشاء التوقيع ويتم تجميع رمز الوظيفة الثنائية المقابل تلقائيًا. عند بدء التشغيل باستخدام أنواع أخرى من الوسائط ، سيتم إنشاء تواقيع جديدة وثنائيات جديدة (يتم الاحتفاظ القديمة). وبالتالي ، يحدث "الخروج إلى الوضع" من حيث سرعة التنفيذ لكل توقيع ، بدءًا من التشغيل الثاني بهذه الأنواع من الوسائط. لذلك سواء
- "قم بتسخين ذاكرة التخزين المؤقت" عن طريق التشغيل بأحجام صغيرة من صفائف الإدخال ، أو
- حدد الوسيطة
@jit(cache=True) لحفظ التعليمة البرمجية المترجمة إلى القرص مع التحميل التلقائي لها أثناء إطلاقات البرنامج اللاحقة (على الرغم من أن هذا الإطلاق الأول لا يزال في الممارسة العملية أبطأ قليلاً من الإصدارات اللاحقة ، ولكنه أسرع من دون cache=True ) .
هناك طريق ثالث. يمكن ضبط التواقيع يدويًا:
from numba import int16, int32 @njit(int32(int16, int16)) def f(x, y): return x + y >>> f.signatures [(int16, int16)]
عندما تقوم بتشغيل دالة بالتوقيع المحدد في الديكور ، فإن التشغيل الأول سيكون سريعًا: سيحدث التجميع في الوقت الذي يرى فيه الثعبان تعريف الوظيفة ، وليس في البداية. يمكن أن يكون هناك العديد من التواقيع ، ترتيب تسلسلها يهم.
تحذير: هذه الطريقة الأخيرة ليست آمنة في المستقبل. يحذر مؤلفو numba من أن بناء جملة تحديد الأنواع قد يتغير في المستقبل ، @jit / @njit بدون توقيعات يعد خيارًا أكثر أمانًا في هذا الصدد.
تبدأ التوقيعات في إظهار التوقيعات فقط عندما يكتشف الثعبان عنها ، أي بعد استدعاء الوظيفة الأولى ، أو إذا تم ضبطها يدويًا.
بالإضافة إلى f.signatures يمكن عرض التواقيع من خلال f.inspect_types() - بالإضافة إلى أنواع معلمات الإدخال ، ستُظهر هذه الوظيفة أنواع معلمات الإخراج وكذلك أنواع جميع المتغيرات المحلية.
بالإضافة إلى أنواع معلمات الإدخال والإخراج ، من الممكن تحديد أنواع المتغيرات المحلية يدويًا:
from numba import int16, int32 @njit(int32(int16, int16), locals={'z': int32}) def f(x, y): z = y + 10 return x + z
الباحث
في numba ، لا تحتوي الأعداد الصحيحة على حساب طويل كما هو الحال في الثعبان "البسيط" ، ولكن هناك أنواع قياسية من العروض المختلفة من int8 إلى int64 ( جدول النوع في الوثائق). هناك أيضًا أنواع int_ (وكذلك float_ ) ، والتي تستخدمها تعطي numba الفرصة لاختيار عرض الحقل الأمثل (من وجهة نظرها).
فصول
يوجد عمومًا دعم للفصول الدراسية (jitclass) ، ولكنه حتى الآن تجريبي ، لذا من الأفضل تجنب استخدامها في الوقت الحالي (في تجربتي ، يكون أبطأ بكثير معهم من دونهم).
dtypes مخصص
يدعم Numba بديلاً معينًا للفئات من الصفائف المهيكلة ، أو بمعنى آخر أنواع dtype المخصصة. إنها تعمل بنفس سرعة المصفوفات المعتمة ، فهي أكثر ملاءمة للفهرسة (على سبيل المثال ، a['y2'] أكثر قابلية للقراءة من a[3] ). ومن المثير للاهتمام ، في numba ، على عكس numpy ، يُسمح باستخدام a.y2 أكثر إيجازًا مع بناء الجملة المعتاد a['y2'] . ولكن بشكل عام ، فإن دعمهم في numba يترك الكثير مما هو مرغوب فيه ، وبعض العمليات ، حتى واضحة في numpy ، معهم في numba يتم تسجيلها بشكل تافه.
GPU
إنه قادر على تنفيذ التعليمات البرمجية فيركلوكيد على GPU ، وعلى عكس نفس واحدة ، على سبيل المثال ، pycuda أو pytorch ، ليس فقط على نفيديا ، ولكن أيضا على بطاقات amd'shnyh. مع هذا ، حتى الآن تم التعامل مع القليل. هنا مقال عن مقارنة Habre 2016 لأداء حسابات GPU في Python و C. هناك ، تم الحصول على سرعة مماثلة ل C.
تجميع في وقت مبكر
هناك وضع طبيعي (أي ، وليس جيت) تجميع ( الوثائق ) في نومبا ، ولكن هذا الوضع ليس هو الوضع الرئيسي ، لم أفهمها.
التوازي التلقائي
تتم موازاة بعض المهام (على سبيل المثال ، ضرب مصفوفة برقم) بشكل طبيعي. ولكن هناك مهام لا يمكن موازاة تنفيذها. باستخدام @njit(parallel=True) decorator @njit(parallel=True) numba بتحليل رمز الوظيفة overclocked ، ويجد مثل هذه الأقسام ، التي لا يمكن أن يكون كل منها متوازيًا بمفرده ، ويقوم بتشغيلها في نفس الوقت على نوى CPU مختلفة ( وثائق ). في السابق ، كان يمكنك فقط موازاة الوظائف يدويًا باستخدام @vectorize ( التوثيق ) ، والتي تتطلب تغييرات في الكود.
في الممارسة العملية ، يبدو الأمر كما يلي: add parallel=True ، وقياس السرعة ، إذا كنا محظوظين وانتهى الأمر بشكل أسرع - نتركه أبطأ - نزيله. (** التحديث كما هو موضح في التعليق على الجزء الثاني من المقال ، تحتوي هذه العلامة على العديد من الأخطاء المفتوحة)
جيل الإفراج
يمكن تنفيذ الوظائف المُزيَّنة بـ @jit(nogil=True) والتشغيل في مؤشرات @jit(nogil=True) مختلفة بشكل متوازٍ. لتجنب ظروف السباق ، يجب عليك استخدام مزامنة مؤشر الترابط.
الوثائق
Numbe لا يزال يفتقر إلى وثائق معقولة. هي ، ولكن ليس كل شيء فيها.
الأمثل
هناك بعض عدم القدرة على التنبؤ عند تحسين الكود يدويًا: غالبًا ما يتم تشغيل الكود غير الموروث بشكل أسرع من pythonic.
للراغبين في الموضوع ، يمكنني أن أوصي بمقطع فيديو لفئة رئيسية من numba من مؤتمر scipy 2017 (توجد أكواد مصدر في github). إنه طويل بالفعل ومتقادم جزئيًا (على سبيل المثال ، الخطوط مدعومة بالفعل) ، لكنه يساعد في الحصول على فكرة عامة: بشكل خاص ، حول pythonic / nonythonic ، jit (parallel = True) ، إلخ.
في الجزء الثاني ، سننظر في استخدام numba باستخدام الكود من المقالة المذكورة في بداية المقال.