هذا هو الجزء الثاني من المقالة حول نومبا. الأول كان مقدمة تاريخية ودليل إرشادي مختصر. هنا أقدم رمز مهمة معدلة قليلاً من مقالة Haskell " أسرع من C ++ ؛ أبطأ من PHP "(يقارن أداء تطبيقات خوارزمية واحدة بلغات مختلفة / مترجمين) بمقاييس ورسومات توضيحية وشرح أكثر تفصيلاً. سأقول على الفور أنني رأيت المقالة أوه ، هذا C / C ++ البطيء ، وعلى الأرجح ، إذا أجريت هذه التغييرات على الكود C ، فستتغير الصورة قليلاً ، ولكن حتى في هذه الحالة ، يمكن أن يتجاوز الثعبان سرعة C حتى في هذا الإصدار هي نفسها رائعة.

استبدل قائمة Python بمصفوفة numpy (وبالتالي ، v0[:] بـ v0.copy() ، لأنه في numpy إرجاع a[:] view بدلاً من النسخ).
لفهم طبيعة سلوك الأداء ، قمت بإجراء "فحص" حسب عدد العناصر في الصفيف.
في رمز Python ، استبدلت time.monotonic بـ time.perf_counter ، لأنه أكثر دقة (1 مقابل 1ms للرتابة).
نظرًا لأن numba يستخدم التحويل البرمجي jit ، يجب أن يحدث هذا التجميع في يوم ما. بشكل افتراضي ، تحدث هذه المرة الأولى التي يتم فيها استدعاء الوظيفة وتؤثر حتماً على نتائج المعايير (على الرغم من أنك إذا كنت تأخذ الوقت من ثلاث عمليات إطلاق ، فقد لا تلاحظ ذلك) ، كما أنها تشعر أيضًا بالاستخدام العملي. هناك عدة طرق للتعامل مع هذه الظاهرة:
1) نتائج تجميع ذاكرة التخزين المؤقت على القرص:
@njit(cache=True) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
ثم سوف يحدث التحويل البرمجي عند أول مكالمة للبرنامج ، وسيتم سحب المكالمات اللاحقة من القرص.
2) تشير إلى التوقيع
سيحدث التجميع في الوقت الذي يقوم فيه بيثون بتوزيع تعريف الوظيفة ، وستكون البداية الأولى سريعة بالفعل.
يتم إرسال السلسلة الأصلية (بشكل أكثر دقة ، البايتات) ، ولكن تم إضافة دعم السلاسل في الآونة الأخيرة ، لذلك التوقيع وحشي جدًا (انظر أدناه). عادة ما تكون التواقيع مكتوبة بشكل أبسط:
@njit(nb.int64(nb.uint8[:], nb.uint8[:])) def lev_dist(s1, s2):
ولكن بعد ذلك يجب عليك تحويل البايتات إلى صفيف numpy مقدمًا:
s1_py = [int(x) for x in b"a" * 15000] s1 = np.array(s1_py, dtype=np.uint8)
أو
s1 = np.full(15000, ord('a'), dtype=np.uint8)
ويمكنك ترك بايت كما هو وتحديد التوقيع في هذا النموذج:
@njit(nb.int64(nb.bytes(nb.uint8, nb.1d, nb.C), nb.bytes(nb.uint8, nb.1d, nb.C))) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
سرعة التنفيذ للبايت وصفيف numpy من uint8 (في هذه الحالة) هي نفسها.
3) سخن مخبأ
s1 = b"a" * 15
ثم سيحدث التجميع في المكالمة الأولى ، والثاني سيكون سريعًا بالفعل.
كود C (clang -O3 - مارس = مواطن) #include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> static long lev_dist (const char *s1, unsigned long m, const char *s2, unsigned long n) { // unsigned long m, n; unsigned long i, j; long *v0, *v1; long ret, *temp; /* Edge cases. */ if (m == 0) { return n; } else if (n == 0) { return m; } v0 = malloc (sizeof (long) * (n + 1)); v1 = malloc (sizeof (long) * (n + 1)); if (v0 == NULL || v1 == NULL) { fprintf (stderr, "failed to allocate memory\n"); exit (-1); } for (i = 0; i <= n; ++i) { v0[i] = i; } memcpy (v1, v0, sizeof(long) * (n + 1)); for (i = 0; i < m; ++i) { v1[0] = i + 1; for (j = 0; j < n; ++j) { const long subst_cost = (s1[i] == s2[j]) ? v0[j] : (v0[j] + 1); const long del_cost = v0[j + 1] + 1; const long ins_cost = v1[j] + 1; #if !defined(__GNUC__) || defined(__llvm__) if (subst_cost < del_cost) { v1[j + 1] = subst_cost; } else { v1[j + 1] = del_cost; } #else v1[j + 1] = (subst_cost < del_cost) ? subst_cost : del_cost; #endif if (ins_cost < v1[j + 1]) { v1[j + 1] = ins_cost; } } temp = v0; v0 = v1; v1 = temp; } ret = v0[n]; free (v0); free (v1); return ret; } int main () { char s1[25001], s2[25001], s3[25001]; int lengths[] = {1000, 2000, 5000, 10000, 15000, 20000, 25000}; FILE *fout; fopen_s(&fout, "c.txt", "w"); for(int j = 0; j < sizeof(lengths)/sizeof(lengths[0]); j++){ int len = lengths[j]; int i; clock_t start_time, exec_time; for (i = 0; i < len; ++i) { s1[i] = 'a'; s2[i] = 'a'; s3[i] = 'b'; } s1[len] = s2[len] = s3[len] = '\0'; start_time = clock (); printf ("%ld\n", lev_dist (s1, len, s2, len)); printf ("%ld\n", lev_dist (s1, len, s3, len)); exec_time = clock () - start_time; fprintf(fout, "%d %.6f\n", len, ((double) exec_time) / CLOCKS_PER_SEC); fprintf (stderr, "Finished in %.3fs\n", ((double) exec_time) / CLOCKS_PER_SEC); } return 0; }
تم إجراء المقارنة تحت windows (windows 10 x64 ، python 3.7.3 ، numba 0.45.1 ، clang 9.0.0 ، intel m5-6y54 skylake): وتحت linux (debian 4.9.30 ، python 3.7.4 ، numba 0.45.1 ، رنة 9.0.0).
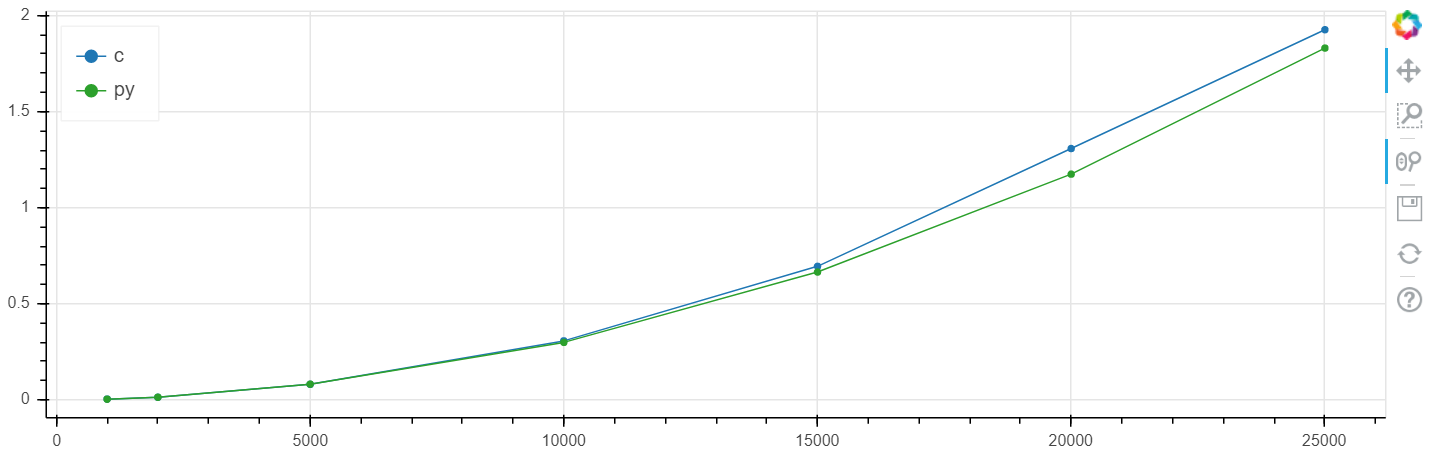
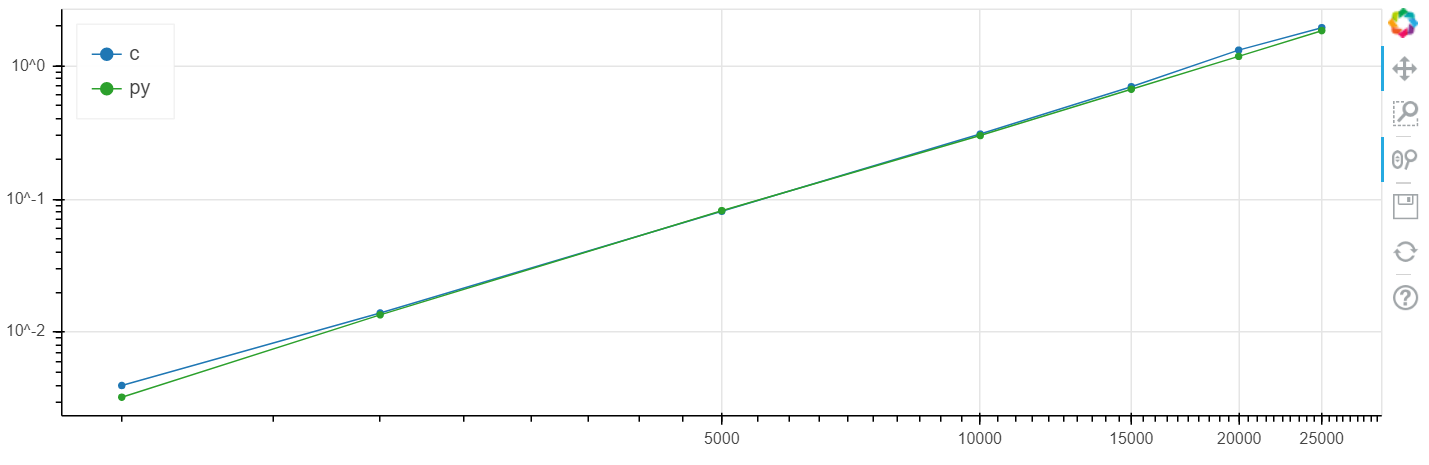
X هو حجم المصفوفة ، y هو الوقت بالثواني.
مقياس الخطي ويندوز:
مقياس لوغاريتمي Windows:
مقياس لينوكس الخطي:

نطاق لوغاريتمي لينكس
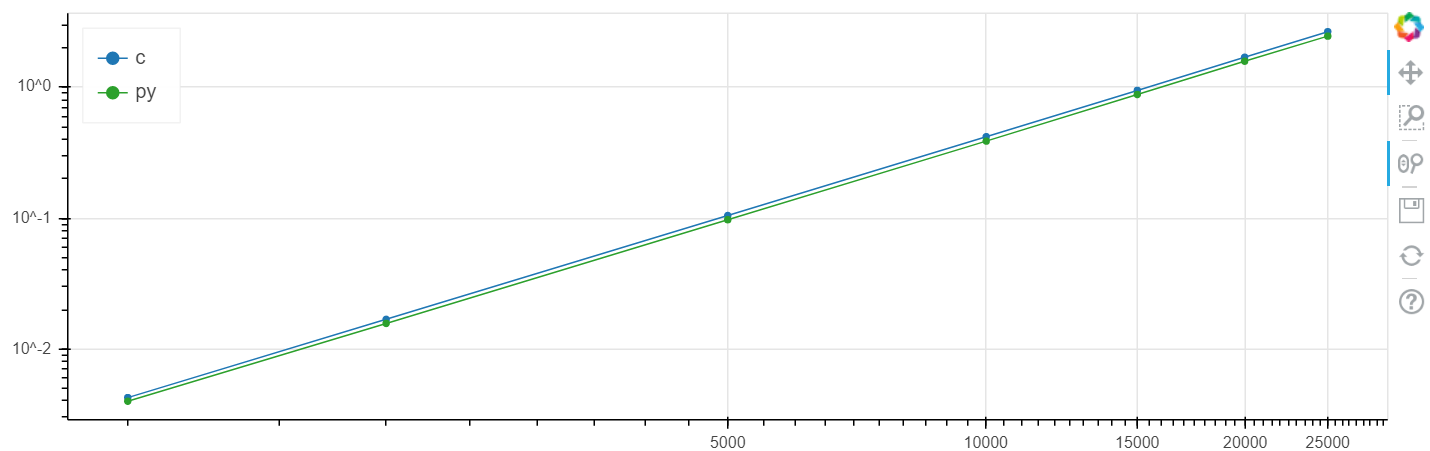
في هذه المشكلة ، تم الحصول على زيادة في السرعة مقارنةً بـ clang عند مستوى عدة بالمائة ، وهو أعلى بشكل عام من الخطأ الإحصائي.
لقد أجريت هذه المقارنة مرارًا وتكرارًا على مهام مختلفة ، وكقاعدة عامة ، إذا كان بإمكان numba تسريع شيء ما ، فإنه يسرع إلى سرعة ضمن هامش الخطأ الذي يتزامن مع السرعة C (دون استخدام إدراج المجمّع).
أكرر أنه إذا أجريت تغييرات على الكود الموجود في C من Oh ، فقد يتغير هذا الوضع C / C ++ البطيء .
سأكون سعيدًا لسماع الأسئلة والاقتراحات في التعليقات.
ملاحظة: عند تحديد توقيع المصفوفات ، من الأفضل تعيين طريقة تناوب الصفوف / الأعمدة بشكل صريح:
بحيث لا يفكر numba في 'C' (si) هذا أو 'A' (si / fortran التعرف التلقائي) - وهذا لسبب ما يؤثر على الأداء حتى بالنسبة للصفائف أحادية البعد ، لهذا يوجد بناء جملة أصلي: uint8[:,:] هذا '' A ((الكشف التلقائي) ، nb.uint8[:, ::1] هو 'C' (si) ، np.uint8[::1, :] هو 'F' (فورتران).
@njit(nb.int64(nb.uint8[::1], nb.uint8[::1])) def lev_dist(s1, s2):