يعرف مستخدمو ClickHouse بالفعل أن أكبر ميزة هي معالجة الاستعلامات التحليلية عالية السرعة. ولكن مثل هذه المطالبات تحتاج إلى تأكيد مع اختبار أداء موثوق. هذا ما نريد أن نتحدث عنه اليوم.
بدأنا في إجراء الاختبارات في عام 2013 ، قبل وقت طويل من توفر المنتج كمصدر مفتوح. في ذلك الوقت ، تمامًا كما هو الحال الآن ، كان شاغلنا الرئيسي هو سرعة معالجة البيانات في Yandex.Metrica. لقد قمنا بتخزين هذه البيانات في ClickHouse منذ يناير من عام 2009. تمت كتابة جزء من البيانات إلى قاعدة بيانات تبدأ في عام 2012 ، وتم تحويل جزء من
OLAPServer و Metrage (هياكل البيانات المستخدمة سابقًا بواسطة Yandex.Metrica). للاختبار ، أخذنا المجموعة الفرعية الأولى بشكل عشوائي من البيانات الخاصة بمليارات مشاهدة للصفحات. لم يكن لدى Yandex.Metrica أي استفسارات في تلك المرحلة ، لذلك توصلنا إلى استفسارات تهمنا ، باستخدام كل الطرق الممكنة لتصفية البيانات وتجميعها وفرزها.
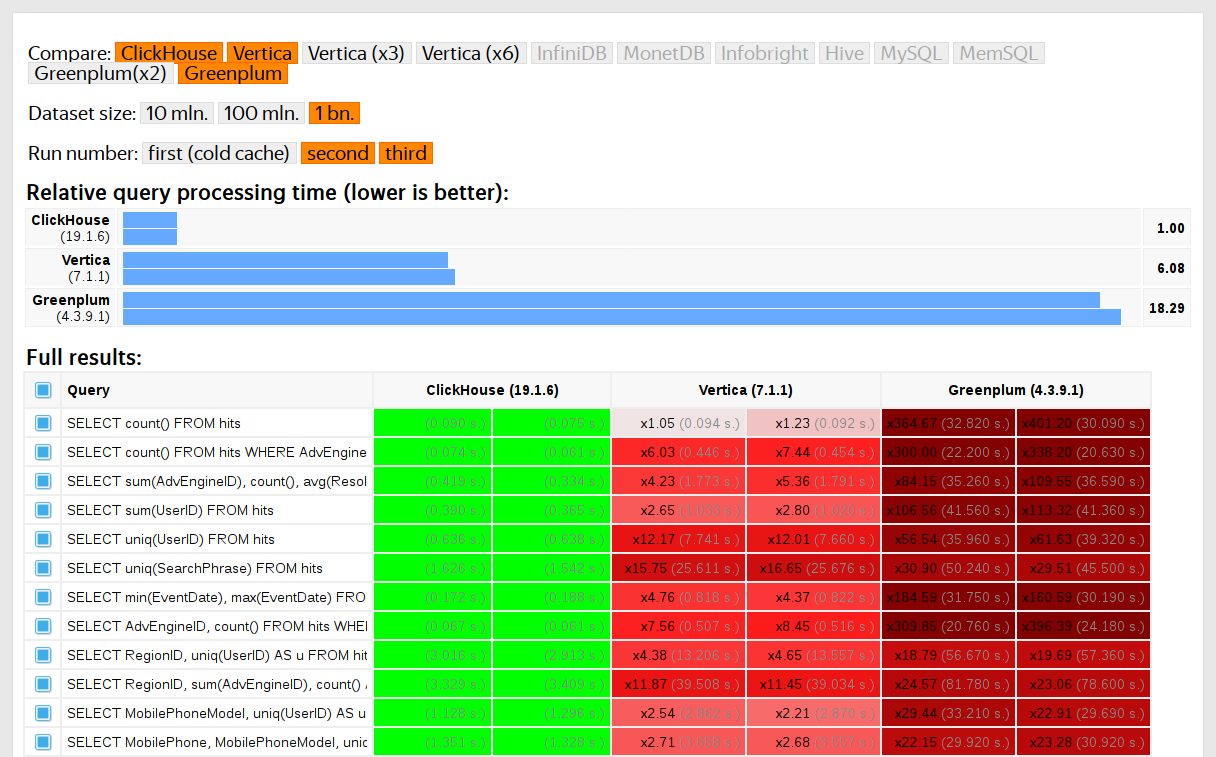
تمت مقارنة أداء ClickHouse مع أنظمة مماثلة مثل Vertica و MonetDB. لتجنب التحيز ، تم إجراء الاختبار بواسطة موظف لم يشارك في تطوير ClickHouse ، ولم يتم تحسين الحالات الخاصة في الكود حتى يتم الحصول على جميع النتائج. استخدمنا نفس الطريقة للحصول على مجموعة بيانات للاختبار الوظيفي.
بعد إصدار ClickHouse كمصدر مفتوح في عام 2016 ، بدأ الأشخاص بالتشكيك في هذه الاختبارات.
أوجه القصور في الاختبارات على البيانات الخاصة
اختبارات أدائنا:
- لا يمكن إعادة إنتاجها بشكل مستقل لأنهم يستخدمون بيانات خاصة لا يمكن نشرها. بعض الاختبارات الوظيفية غير متاحة للمستخدمين الخارجيين لنفس السبب.
- بحاجة الى مزيد من التطوير. يجب توسيع مجموعة الاختبارات بشكل كبير من أجل عزل تغييرات الأداء في الأجزاء الفردية من النظام.
- لا تعمل على أساس الالتزام أو لطلبات السحب الفردية. لا يمكن للمطورين الخارجيين التحقق من الكود الخاص بهم لمعرفة انحدارات الأداء.
يمكننا حل هذه المشكلات من خلال التخلص من الاختبارات القديمة وكتابة اختبارات جديدة تستند إلى بيانات مفتوحة ، مثل
بيانات الرحلات الجوية للولايات المتحدة وركوب سيارات الأجرة في نيويورك . أو يمكننا استخدام معايير مثل TPC-H و TPC-DS و
Star Schema Benchmark . العيب هو أن هذه البيانات تختلف اختلافًا كبيرًا عن بيانات Yandex.Metrica ، ونفضل الاحتفاظ باستفسارات الاختبار.
لماذا من المهم استخدام البيانات الحقيقية
يجب اختبار الأداء فقط على بيانات حقيقية من بيئة الإنتاج. لنلقي نظرة على بعض الأمثلة.
مثال 1لنفترض أنك تملأ قاعدة بيانات بأرقام عشوائية مزيفة موزعة بالتساوي. لن يعمل ضغط البيانات في هذه الحالة ، على الرغم من أن ضغط البيانات ضروري لقواعد البيانات التحليلية. لا يوجد حل رصاصي للتحدي المتمثل في اختيار خوارزمية الضغط الصحيحة والطريقة الصحيحة لدمجها في النظام ، لأن ضغط البيانات يتطلب حلاً وسطًا بين سرعة الضغط وإلغاء الضغط وكفاءة الضغط المحتملة. لكن الأنظمة التي لا تستطيع ضغط البيانات مضمونة الخاسرين. إذا كانت اختباراتك تستخدم أرقام عشوائية مزيفة موزعة بالتساوي ، فسيتم تجاهل هذا العامل ، وسيتم تشويه النتائج.
خلاصة القول: يجب أن تحتوي بيانات الاختبار على نسبة ضغط واقعية.
لقد غطيت تحسين خوارزميات ضغط بيانات ClickHouse في منشور
سابق .
مثال 2لنفترض أننا مهتمون بسرعة تنفيذ استعلام SQL هذا:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10
هذا استعلام نموذجي لـ Yandex.Metrica. ما يؤثر على سرعة المعالجة؟
- كيف يتم تنفيذ GROUP BY.
- ما هي بنية البيانات المستخدمة لحساب الدالة التجميعية uniq.
- كم من معرف المناطق المختلفة الموجودة ومقدار ذاكرة الوصول العشوائي التي تتطلبها كل حالة من وظائف uniq.
ولكن هناك عامل مهم آخر وهو أن كمية البيانات موزعة بشكل غير متساو بين المناطق. (من المحتمل أن يتبع قانون السلطة. لقد وضعت التوزيع على رسم بياني لسجل الدخول ، لكن لا يمكنني أن أؤكد ذلك بالتأكيد.) إذا كان الأمر كذلك ، فمن المهم أن تستخدم حالات الدالة التجميعية الفريدة ذات القيم الأقل القليل جدا من الذاكرة. عندما يكون هناك الكثير من مفاتيح التجميع المختلفة ، يتم حساب كل بايت واحد. كيف يمكننا الحصول على بيانات تم إنشاؤها تحتوي على كل هذه الخصائص؟ الحل الواضح هو استخدام البيانات الحقيقية.
تقوم العديد من نظم إدارة قواعد البيانات بتطبيق بنية بيانات HyperLogLog لتقريب COUNT (DISTINCT) ، لكن أيا منها لا يعمل بشكل جيد للغاية لأن بنية البيانات هذه تستخدم مقدارًا ثابتًا من الذاكرة. لدى ClickHouse وظيفة تستخدم
مجموعة من ثلاثة هياكل بيانات مختلفة ، اعتمادًا على حجم مجموعة البيانات.
خلاصة القول: يجب أن تمثل بيانات الاختبار خصائص توزيع البيانات الحقيقية بشكل جيد بما فيه الكفاية ، مما يعني العلاقة الأساسية (عدد القيم المتميزة لكل عمود) والأرقام الرئيسية للعمود المتقاطع (عدد القيم المختلفة التي تم حسابها عبر عدة أعمدة مختلفة).
مثال 3بدلاً من اختبار أداء ClickHouse DBMS ، دعنا نأخذ شيئًا أكثر بساطة ، مثل جداول التجزئة. لجداول التجزئة ، من الضروري اختيار وظيفة التجزئة الصحيحة. هذا ليس مهمًا بالنسبة إلى std :: unordered_map ، لأنه جدول تجزئة يستند إلى تسلسل ويتم استخدام رقم أولي كحجم الصفيف. يستخدم تطبيق المكتبة القياسي في GCC و Clang دالة تجزئة تافهة كدالة تجزئة افتراضية لأنواع رقمية. ومع ذلك ، فإن std :: unordered_map ليس الخيار الأفضل عندما نبحث عن السرعة القصوى. مع جدول تجزئة مفتوح العنونة ، لا يمكننا استخدام دالة تجزئة قياسية فقط. اختيار وظيفة التجزئة الصحيحة يصبح العامل الحاسم.
من السهل العثور على اختبارات أداء جدول التجزئة باستخدام بيانات عشوائية لا تأخذ وظائف التجزئة المستخدمة في الاعتبار. هناك أيضًا الكثير من اختبارات دالة التجزئة التي تركز على سرعة الحساب ومعايير جودة معينة ، على الرغم من أنها تتجاهل هياكل البيانات المستخدمة. ولكن الحقيقة هي أن جداول التجزئة و HyperLogLog تتطلب معايير جودة دالة التجزئة المختلفة.
يمكنك معرفة المزيد حول هذا الموضوع في
"كيفية عمل جداول التجزئة في ClickHouse" (عرض تقديمي باللغة الروسية). المعلومات قديمة بعض الشيء ، لأنها لا تغطي
الجداول السويسرية .
تحد
هدفنا هو الحصول على بيانات لاختبار الأداء الذي له نفس بنية بيانات Yandex.Metrica مع جميع الخصائص المهمة للمعايير ، ولكن بطريقة لا توجد بها آثار لمستخدمي موقع الويب الحقيقي في هذه البيانات. بمعنى آخر ، يجب أن تكون البيانات مجهولة المصدر وأن تظل محفوظة:
- نسبة الضغط.
- أصل (عدد القيم المتميزة).
- العلاقة المتبادلة بين عدة أعمدة مختلفة.
- خصائص توزيعات الاحتمالية التي يمكن استخدامها لنمذجة البيانات (على سبيل المثال ، إذا كنا نعتقد أن المناطق موزعة وفقًا لقانون الطاقة ، فيجب أن يكون الأس - معلمة التوزيع - هو نفسه تقريبًا للبيانات الاصطناعية والبيانات الحقيقية).
كيف يمكننا الحصول على نسبة ضغط مماثلة للبيانات؟ إذا تم استخدام LZ4 ، فيجب أن تتكرر السلاسل الفرعية في البيانات الثنائية في نفس المسافة تقريبًا ويجب أن تكون التكرار بنفس الطول تقريبًا. بالنسبة إلى ZSTD ، يجب أن تتطابق إنتروبيا لكل بايت.
الهدف النهائي هو إنشاء أداة متاحة للجمهور يمكن لأي شخص استخدامها لإخفاء هوية مجموعات البيانات للنشر. سيتيح لنا ذلك تصحيح الأداء واختباره على بيانات الأشخاص الآخرين المشابهة لبيانات الإنتاج الخاصة بنا. نود أيضًا أن تكون البيانات التي تم إنشاؤها مثيرة للاهتمام.
ومع ذلك ، فهذه متطلبات محددة بشكل كبير جدًا ولا نخطط لكتابة بيان مشكلة رسمي أو مواصفات لهذه المهمة.
الحلول الممكنة
لا أريد أن أجعل الأمر يبدو كما لو أن هذه المشكلة مهمة للغاية. لم يتم تضمينه بالفعل في التخطيط ولم يكن لدى أحد نوايا للعمل عليه. ظللت آمل أن تظهر فكرة في يوم ما ، وفجأة سأكون في مزاج جيد وأكون قادرًا على تأجيل كل شيء آخر إلى وقت لاحق.
نماذج احتمالية صريحة
تتمثل الفكرة الأولى في أخذ كل عمود في الجدول والعثور على مجموعة من توزيعات الاحتمالات التي تقوم بنمذجه ، ثم ضبط المعلمات بناءً على إحصاءات البيانات (تركيب النموذج) واستخدام التوزيع الناتج لإنشاء بيانات جديدة. يمكن استخدام مولد الأرقام العشوائية المزيفة مع بذرة محددة مسبقًا للحصول على نتيجة قابلة للتكرار.
يمكن استخدام سلاسل Markov لحقول النص. هذا نموذج مألوف يمكن تنفيذه بفعالية.
ومع ذلك ، فإنه يتطلب بعض الحيل:
- نريد الحفاظ على استمرارية السلسلة الزمنية. هذا يعني أنه بالنسبة لبعض أنواع البيانات ، نحتاج إلى نمذجة الفرق بين القيم المجاورة ، بدلاً من القيمة نفسها.
- لنمذجة "العلاقة المشتركة" للأعمدة ، سيتعين علينا أيضًا أن نعكس بوضوح التبعيات بين الأعمدة. على سبيل المثال ، عادةً ما يكون هناك عدد قليل جدًا من عناوين IP لكل معرف مستخدم ، لذلك لإنشاء عنوان IP ، نستخدم قيمة تجزئة لمعرف المستخدم كبذرة وإضافة كمية صغيرة من البيانات العشوائية المزيفة أيضًا.
- لسنا متأكدين من كيفية التعبير عن التبعية التي يزورها المستخدم نفسه بشكل متكرر لعناوين URL ذات النطاقات المتطابقة في نفس الوقت تقريبًا.
كل هذا يمكن كتابته في "نص" C ++ مع التوزيعات والتبعيات ترميز الثابت. ومع ذلك ، يتم الحصول على نماذج Markov من مجموعة من الإحصاءات مع تجانس وإضافة ضوضاء. بدأت في كتابة نص مثل هذا ، لكن بعد كتابة نماذج صريحة لعشرة أعمدة ، أصبحت مملة بشكل لا يطاق - وكان جدول "الزيارات" في Yandex.Metrica قد عاد إلى أكثر من 100 عمود في عام 2012.
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); };
كان هذا النهج فشل. إذا كنت قد حاولت أكثر صعوبة ، فربما يكون البرنامج النصي جاهزًا الآن.
المزايا:
العيوب:
- كمية كبيرة من العمل المطلوب.
- ينطبق الحل فقط على نوع واحد من البيانات.
وأفضّل حلاً أكثر عمومية يمكن استخدامه لبيانات Yandex.Metrica بالإضافة إلى تعتيم أي بيانات أخرى.
في أي حال ، يمكن تحسين هذا الحل. بدلاً من تحديد النماذج يدويًا ، يمكننا تطبيق كتالوج من النماذج واختيار الأفضل بينها (أفضل ملاءمة بالإضافة إلى شكل من أشكال التنظيم). أو ربما يمكننا استخدام نماذج Markov لجميع أنواع الحقول ، وليس فقط للنص. يمكن أيضًا استخراج التبعيات بين البيانات تلقائيًا. هذا يتطلب حساب
الانتروبيا النسبية (الكمية النسبية للمعلومات) بين الأعمدة. البديل الأبسط هو حساب القيم النسبية لكل زوج من الأعمدة (شيء مثل "عدد القيم المختلفة لـ A الموجودة في المتوسط بقيمة ثابتة B"). على سبيل المثال ، سيوضح ذلك أن URLDomain يعتمد بالكامل على عنوان URL ، وليس العكس.
لكنني رفضت هذه الفكرة أيضًا ، لأن هناك العديد من العوامل التي يجب أخذها في الاعتبار وستستغرق الكتابة وقتًا طويلاً.
الشبكات العصبية
كما ذكرت سابقًا ، لم تكن هذه المهمة على رأس قائمة الأولويات - لم يكن أحد يفكر في محاولة حلها. ولكن كما يحظى الحظ ، فإن زميلنا إيفان بوزيرفسكي كان يدرس في المدرسة العليا للاقتصاد. سألني إذا كان لدي أي مشاكل مثيرة للاهتمام من شأنها أن تعمل كموضوعات أطروحة مناسبة لطلابه. عندما عرضت عليه هذا ، أكد لي أن لديها إمكانات. لذا سلمت هذا التحدي إلى رجل لطيف "خارج الشارع" شريف (كان عليه أن يوقع على NDA للوصول إلى البيانات ، على الرغم من).
شاركت كل أفكاري معه ، لكنني أكدت أنه لا توجد قيود على كيفية حل المشكلة ، وسيكون الخيار الجيد هو تجربة الأساليب التي لا أعرف عنها شيئًا ، مثل استخدام LSTM لإنشاء تفريغ نص للبيانات. بدا هذا واعدًا بعد نشر مقال بعنوان
"الفعالية غير المعقولة للشبكات العصبية المتكررة" .
التحدي الأول هو أننا نحتاج إلى إنشاء بيانات منظمة ، وليس فقط النص. لكن لم يكن واضحًا ما إذا كانت الشبكة العصبية المتكررة يمكنها توليد بيانات بالبنية المطلوبة. هناك طريقتان لحل هذا. الحل الأول هو استخدام نماذج منفصلة لإنشاء الهيكل و "الحشو" واستخدام الشبكة العصبية فقط لتوليد القيم. ولكن تم تأجيل هذا النهج ثم لم يكتمل. الحل الثاني هو ببساطة إنشاء تفريغ TSV كنص. أظهرت التجربة أن بعض الصفوف في النص لن تتطابق مع البنية ، ولكن يمكن التخلص من هذه الصفوف عند تحميل البيانات.
التحدي الثاني هو أن الشبكة العصبية المتكررة تولد سلسلة من البيانات ، وبالتالي يجب أن تتبع التبعيات في البيانات حسب ترتيب التسلسل. ولكن في بياناتنا ، يمكن أن يكون ترتيب الأعمدة في عكس التبعيات بينهما.
لم نفعل أي شيء لحل هذه المشكلة.
مع اقتراب الصيف ، كان لدينا أول نص بيثون يعمل على توليد البيانات. بدا أن جودة البيانات لائقة للوهلة الأولى:

ومع ذلك ، واجهنا بعض الصعوبات:
- حجم النموذج هو حوالي غيغابايت. لقد حاولنا إنشاء نموذج للبيانات بحجم عدة غيغابايت (للبدء). حقيقة أن النموذج الناتج كبير جدًا يثير المخاوف. هل سيكون من الممكن استخراج البيانات الحقيقية التي تم تدريبها عليها؟ غير مرجح. لكنني لا أعرف الكثير عن التعلم الآلي والشبكات العصبية ، وأنا لم أقرأ رمز بيثون لهذا المطور ، فكيف يمكنني التأكد من ذلك؟ كان هناك العديد من المقالات المنشورة في ذلك الوقت حول كيفية ضغط الشبكات العصبية دون فقدان الجودة ، لكنها لم تنفذ. من ناحية ، لا يبدو أن هذا يمثل مشكلة خطيرة ، حيث يمكننا إلغاء الاشتراك في نشر النموذج ونشر البيانات التي تم إنشاؤها فقط. من ناحية أخرى ، إذا حدث overfitting ، قد تحتوي البيانات التي تم إنشاؤها على جزء من البيانات المصدر.
- على جهاز مزود بوحدة معالجة مركزية واحدة ، تبلغ سرعة إنشاء البيانات حوالي 100 صف في الثانية. كان هدفنا هو توليد ما لا يقل عن مليار صف. أظهرت الحسابات أنه لن يتم الانتهاء من هذا قبل تاريخ أطروحة الدفاع. لم يكن من المنطقي استخدام أجهزة إضافية ، لأن الهدف كان إنشاء أداة لتوليد البيانات يمكن لأي شخص استخدامها.
حاول شريف تحليل جودة البيانات من خلال مقارنة الإحصاءات. من بين أشياء أخرى ، قام بحساب تواتر الأحرف المختلفة التي تحدث في البيانات المصدر والبيانات التي تم إنشاؤها. كانت النتيجة مذهلة: أكثر الشخصيات تكرارا كانت Ð و Ñ.
لا تقلق بشأن شريف. لقد دافع بنجاح عن أطروحته ثم نسينا بسعادة عن كل شيء.
طفرة البيانات المضغوطة
دعنا نفترض أن بيان المشكلة قد تم تخفيضه إلى نقطة واحدة: نحن بحاجة إلى إنشاء بيانات لها نفس نسبة الضغط مثل البيانات المصدر ، ويجب إلغاء ضغط البيانات بنفس السرعة. كيف يمكننا تحقيق هذا؟ نحن بحاجة إلى تعديل بايت البيانات المضغوطة مباشرة! يتيح لنا ذلك تغيير البيانات دون تغيير حجم البيانات المضغوطة ، بالإضافة إلى أن كل شيء سيعمل بسرعة. أردت تجربة هذه الفكرة على الفور ، على الرغم من أن المشكلة التي تحلها ليست هي نفسها التي بدأناها. ولكن هذا هو الحال دائما.
إذا كيف يمكننا تعديل ملف مضغوط؟ دعنا نقول أننا مهتمون فقط بـ LZ4. تتكون البيانات المضغوطة LZ4 من سلاسل ، والتي بدورها عبارة عن سلاسل من البايتات غير المضغوطة (بالأحرف الحرفية) ، متبوعة بنسخة مطابقة:
- حرفية (نسخ البايتات N التالية كما هي).
- يطابق الحد الأدنى لطول التكرار 4 (كرر N بايت التي كانت في الملف على مسافة M).
مصدر البيانات:
Hello world Hello .
البيانات المضغوطة (مثال تعسفي):
literals 12 "Hello world " match 5 12 .
في الملف المضغوط ، نترك "التطابق" كما هو ، ونغير قيم البايت في "القيم الحرفية". نتيجةً لذلك ، بعد إلغاء الضغط ، نحصل على ملف تتكرر فيه أيضًا جميع التسلسلات المتكررة التي يبلغ طولها 4 بايت على الأقل ، ولكنها تتألف من مجموعة مختلفة من وحدات البايت (في الأساس ، لا يحتوي الملف المعدل على ملف مفرد البايت التي اتخذت من الملف المصدر).
ولكن كيف يمكننا تغيير البايتات؟ الجواب غير واضح ، لأنه بالإضافة إلى أنواع الأعمدة ، تحتوي البيانات أيضًا على هيكلها الداخلي الضمني الذي نود الحفاظ عليه. على سبيل المثال ، يتم تخزين النص غالبًا بترميز UTF-8 ، ونريد أن تكون البيانات التي تم إنشاؤها صالحة أيضًا لـ UTF-8. لقد طورت منهجية إرشادية بسيطة تنطوي على تلبية عدة معايير:
- يتم الاحتفاظ بايت بايت وأحرف التحكم ASCII كما هو.
- تبقى بعض علامات الترقيم كما هي.
- يتم تحويل ASCII إلى ASCII ولكل شيء آخر ، يتم الاحتفاظ بالبت الأكثر أهمية (أو كتابة مجموعة واضحة من عبارات "if" بأطوال UTF-8 مختلفة). في فئة بايت واحد يتم اختيار قيمة جديدة بشكل عشوائي.
- يتم حفظ أجزاء مثل
https:// ، وإلا فإنها تبدو سخيفة بعض الشيء.
التحذير الوحيد لهذا النهج هو أن نموذج البيانات هو مصدر البيانات نفسه ، مما يعني أنه لا يمكن نشره. يصلح النموذج فقط لتوليد كميات من البيانات لا يزيد حجمها عن المصدر. على العكس من ذلك ، توفر الأساليب السابقة نماذج تتيح إنشاء بيانات ذات حجم تعسفي.
مثال لعنوان URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
كانت النتائج إيجابية وكانت البيانات مثيرة للاهتمام ، لكن شيئًا ما لم يكن صحيحًا تمامًا. احتفظت عناوين URL بنفس البنية ، لكن كان من السهل جدًا في بعضها التعرف على "yandex" أو "avito" (سوق شائع في روسيا) ، لذلك قمت بإنشاء دليل ارشادي يقوم بتبادل بعض البايتات الموجودة حوله.
كانت هناك مخاوف أخرى كذلك. على سبيل المثال ، يمكن أن توجد المعلومات الحساسة في عمود FixedString في التمثيل الثنائي ، وربما تتكون من أحرف تحكم ASCII وعلامات الترقيم ، التي قررت الاحتفاظ بها. ومع ذلك ، لم آخذ أنواع البيانات في الاعتبار.
مشكلة أخرى هي أنه إذا قام عمود بتخزين البيانات بتنسيق "الطول والقيمة" (هكذا يتم تخزين أعمدة السلسلة) ، كيف أتأكد من بقاء الطول صحيحًا بعد حدوث طفرة؟ عندما حاولت إصلاح هذا ، فقدت الاهتمام على الفور.
التباديل العشوائي
لسوء الحظ ، لم يتم حل المشكلة. أجرينا بعض التجارب ، وتفاقم الأمر. الشيء الوحيد المتبقي هو الجلوس وعدم القيام بأي شيء وتصفح الويب بشكل عشوائي ، حيث تم اختفاء السحر. لحسن الحظ ، صادفت صفحة
توضح الخوارزمية لتجسيد وفاة الشخصية الرئيسية في لعبة Wolfenstein 3D.

تم تحريك الرسوم المتحركة بشكل جيد - تملأ الشاشة بالدم. تشرح المقالة أن هذا هو في الواقع تقليب عشوائي مزيف. التقليب العشوائي لمجموعة من العناصر هو تحويل bijective (واحد لواحد) انتقائي عشوائيًا للمجموعة ، أو تعيين حيث يتوافق كل عنصر مشتق مع عنصر أصلي واحد بالضبط (والعكس بالعكس). بمعنى آخر ، إنها طريقة للتكرار العشوائي من خلال جميع عناصر مجموعة البيانات. وهذه هي بالضبط العملية الموضحة في الصورة: يتم تعبئة كل بكسل بترتيب عشوائي ، دون أي تكرار. إذا كان علينا فقط اختيار بكسل عشوائي في كل خطوة ، فسوف يستغرق الأمر وقتًا طويلاً للوصول إلى آخرها.
تستخدم اللعبة خوارزمية بسيطة جدًا للتحول العشوائي الكاذب تسمى سجل تغيير الملاحظات الخطي (
LFSR ). على غرار مولدات الأرقام العشوائية المزيفة ، يمكن أن يكون التباديل العشوائي ، أو بالأحرى أسرهم ، قويًا بشكل مشفر عند تحديده بواسطة مفتاح. هذا هو بالضبط ما نحتاجه لتحويل البيانات. ومع ذلك ، قد تكون التفاصيل أكثر صعوبة. على سبيل المثال ، يبدو تشفير التشفير القوي للبايتات N إلى البايتات N بمفتاح محدد مسبقًا ومتجه التهيئة وكأنه سينجح من أجل التقليب العشوائي المزيف لمجموعة من السلاسل N بايت. في الواقع ، هذا تحول واحد لواحد ويبدو أنه عشوائي. ولكن إذا استخدمنا نفس التحويل لجميع بياناتنا ، فقد تكون النتيجة عرضة لتحليل التشفير لأن نفس متجه التهيئة والقيمة الرئيسية يتم استخدامهما عدة مرات. هذا مشابه لوضع "
دفتر الشفرة
الإلكتروني" للتشغيل من أجل تشفير الكتل.
ما هي الطرق الممكنة للحصول على التقليب العشوائي المزيف؟ يمكننا أن نأخذ تحولات بسيطة من شخص لآخر وأن نبني وظيفة معقدة تبدو عشوائية. فيما يلي بعض التحولات المفضلة لدي:
- الضرب برقم فردي (مثل عدد أولي كبير) في حساب مكمل للاثنين.
- Xorshift:
x ^= x >> N - CRC-N ، حيث N هو عدد البتات في الوسيطة.
على سبيل المثال ، يتم استخدام ثلاث عمليات الضرب و عمليتي xorshift من أجل
أداة إنهاء
murmurhash . هذه العملية هي التقليب العشوائي المزيف. ومع ذلك ، يجب أن أشير إلى أن وظائف التجزئة لا يجب أن تكون واحدة لواحد (حتى التجزئة من N بت إلى N بت).
أو إليك
مثال آخر مثير للاهتمام
من نظرية الأعداد الأولية من موقع Jeff Preshing.
كيف يمكننا استخدام التباديل العشوائي الكاذب لحل مشكلتنا؟ يمكننا استخدامها لتحويل جميع الحقول الرقمية حتى نتمكن من الحفاظ على الكاردينالات والأصوات المتبادلة لجميع مجموعات الحقول. بمعنى آخر ، سيعود COUNT (DISTINCT) بنفس القيمة كما كان قبل التحويل ، وأيضًا مع أي GROUP BY.
تجدر الإشارة إلى أن الحفاظ على جميع العناصر الأساسية يتناقض إلى حد ما مع هدفنا المتمثل في إخفاء البيانات. لنفترض أن شخصًا يعرف أن البيانات المصدر لجلسات الموقع تحتوي على مستخدم زار مواقع من 10 دول مختلفة ، ويريدون العثور على هذا المستخدم في البيانات المحولة. تُظهر البيانات المحولة أيضًا أن المستخدم زار مواقع من 10 دول مختلفة ، مما يجعل من السهل تضييق نطاق البحث. حتى إذا اكتشفوا ما تم تحويل المستخدم إليه ، فلن يكون ذلك مفيدًا للغاية ، لأن جميع البيانات الأخرى قد تم تحويلها أيضًا ، لذلك لن يتمكنوا من معرفة المواقع التي زارها المستخدم أو أي شيء آخر. ولكن هذه القواعد يمكن تطبيقها في سلسلة. على سبيل المثال ، إذا كان شخص ما يعرف أن أكثر مواقع الويب التي يتم تكرارها في بياناتنا هو Yandex ، مع وجود Google في المرتبة الثانية ، فيمكنهم فقط استخدام الترتيب لتحديد معرفات المواقع المحولة تعني بالفعل Yandex و Google. لا يوجد شيء يثير الدهشة حول هذا ، لأننا نعمل مع بيان مشكلة غير رسمي ونحاول فقط إيجاد توازن بين إخفاء الهوية للبيانات (إخفاء المعلومات) والحفاظ على خصائص البيانات (الكشف عن المعلومات). للحصول على معلومات حول كيفية التعامل مع مشكلة إخفاء البيانات بشكل أكثر موثوقية ، اقرأ هذه
المقالة .
بالإضافة إلى الحفاظ على القيم الأصلية الأصلية للقيم ، أريد أيضًا الحفاظ على حجم القيم. ما أعنيه هو أنه إذا كانت البيانات المصدر تحتوي على أرقام أقل من 10 ، فأنا أريد أن تكون الأرقام المحولة صغيرة أيضًا. كيف يمكننا تحقيق هذا؟
على سبيل المثال ، يمكننا تقسيم مجموعة من القيم الممكنة إلى فئات الحجم وتنفيذ عمليات التباديل داخل كل فصل على حدة (الحفاظ على فئات الحجم). أسهل طريقة للقيام بذلك هي أن تأخذ أقرب قوة من اثنين أو موقف الشيء الأكثر أهمية في العدد مثل فئة الحجم (هذه هي نفس الشيء). الأرقام 0 و 1 ستبقى دائما كما هي. سيبقى الرقمان 2 و 3 في بعض الأحيان كما هو (مع احتمال 1/2) وسيتم تبديلهما أحيانًا (مع احتمال 1/2). مجموعة الأرقام 1024. سيتم تعيين 2047 إلى واحد من 1024! المتغيرات (مضربي) ، وهلم جرا. بالنسبة للأرقام الموقعة ، سنحتفظ بالعلامة.
من المشكوك فيه أيضًا ما إذا كنا بحاجة إلى وظيفة فردية. ربما يمكننا فقط استخدام دالة تجزئة قوية مشفرة. لن يكون التحويل واحدًا لواحد ، لكن العلاقة الأساسية ستكون قريبة من نفسه.
ومع ذلك ، فنحن نحتاج إلى تشفير عشوائي قوي مشفر ، لذلك عندما نعرّف المفتاح ونشتق التقليب باستخدام هذا المفتاح ، سيكون من الصعب استعادة البيانات الأصلية من البيانات التي تمت إعادة ترتيبها دون معرفة المفتاح.
هناك مشكلة واحدة: بالإضافة إلى عدم معرفة أي شيء عن الشبكات العصبية والتعلم الآلي ، فأنا جاهل جدًا عندما يتعلق الأمر بالتشفير. هذا يترك فقط شجاعتي. كنت لا أزال أقرأ صفحات الويب العشوائية ، ووجدت رابطًا على موقع
Hackers News لمناقشة حول صفحة Fabien Sanglard. كان له رابط إلى منشور
مدونة من قبل مطور Redis Salvatore Sanfilippo تحدث عن استخدام طريقة عامة رائعة للحصول على التباديل العشوائي ، المعروف باسم
شبكة Feistel .
شبكة Feistel تكرارية ، وتتألف من جولات. كل جولة عبارة عن تحول ملحوظ يتيح لك الحصول على وظيفة فردية من أي وظيفة. دعونا ننظر في كيفية عملها.
- تنقسم أجزاء الوسيطة إلى نصفين:
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - النصف الأيمن يستبدل اليسار. في مكانها ، نضع نتيجة XOR على القيمة الأولية للنصف الأيسر ونتائج الوظيفة المطبقة على القيمة الأولية للنصف الأيمن ، مثل هذا:
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
هناك أيضًا مطالبة بأنه إذا استخدمنا دالة شبه عشوائية قوية مشفرة لـ F وقمنا بتطبيق جولة Feistel على الأقل 4 مرات ، فسنحصل على التقليب العشوائي القوي المشفر.
هذا يشبه المعجزة: نحن نأخذ وظيفة تنتج بيانات عشوائية عشوائية استنادًا إلى البيانات ، ونضيفها إلى شبكة Feistel ، ولدينا الآن وظيفة تنتج بيانات غير مقبولة استنادًا إلى البيانات ، ولكن بعد ذلك لا يمكن عكسها!
تقع شبكة Feistel في قلب العديد من خوارزميات تشفير البيانات. ما سنفعله هو شيء مثل التشفير ، إنه أمر سيء حقًا. هناك سببان لهذا:
- نحن نقوم بتشفير القيم الفردية بشكل مستقل وبنفس الطريقة ، على غرار طريقة تشغيل دفتر الشفرة الإلكتروني.
- نقوم بتخزين معلومات حول ترتيب الحجم (أقرب قوة من اثنين) وعلامة القيمة ، مما يعني أن بعض القيم لا تتغير على الإطلاق.
بهذه الطريقة يمكننا تشويش الحقول الرقمية مع الحفاظ على الخصائص التي نحتاجها. على سبيل المثال ، بعد استخدام LZ4 ، يجب أن تظل نسبة الضغط كما هي تقريبًا ، لأن القيم المكررة في البيانات المصدر ستتكرر في البيانات المحولة ، وعلى نفس المسافات من بعضها البعض.
نماذج ماركوف
تُستخدم نماذج النص لضغط البيانات ، والمدخلات التنبؤية ، والتعرف على الكلام ، وإنشاء سلسلة عشوائية. نموذج النص هو توزيع احتمالي لجميع السلاسل الممكنة. دعنا نقول أن لدينا توزيع احتمالي وهمي لنصوص جميع الكتب التي يمكن للبشرية أن تكتبها. لإنشاء سلسلة ، نأخذ قيمة عشوائية مع هذا التوزيع ونعيد السلسلة الناتجة (كتاب عشوائي يمكن أن تكتبه البشرية). ولكن كيف يمكننا معرفة توزيع الاحتمالات لجميع السلاسل الممكنة؟
أولاً ، هذا يتطلب الكثير من المعلومات. هناك 256 ^ 10 سلاسل محتملة يبلغ طولها 10 بايت ، وسوف يستغرق الأمر الكثير من الذاكرة لكتابة جدول بوضوح مع احتمال كل سلسلة. ثانياً ، ليس لدينا إحصائيات كافية لتقييم التوزيع بدقة.
هذا هو السبب في أننا نستخدم توزيع الاحتمالات الذي تم الحصول عليه من إحصائيات تقريبية كنموذج نصي. على سبيل المثال ، يمكننا حساب احتمال كل حرف في النص ، ومن ثم إنشاء سلاسل عن طريق اختيار كل حرف التالي مع نفس الاحتمال. هذا النموذج البدائي يعمل ، ولكن الأوتار لا تزال غير طبيعية للغاية.
لتحسين النموذج بشكل طفيف ، يمكننا أيضًا الاستفادة من الاحتمال المشروط لحدوث الرسالة إذا سبقتها حروف محددة. N هو ثابت محدد مسبقا. دعنا نقول N = 5 ونحن نحسب احتمال الحرف "e" التي تحدث بعد الحروف "تتكون". يُسمى نموذج النص هذا نموذج Order-N Markov.
P(cat a | cat) = 0.8
P(cat b | cat) = 0.05
P(cat c | cat) = 0.1
...لنلقِ نظرة على كيفية عمل نماذج ماركوف على موقع
Hay Kranen . بخلاف الشبكات العصبية لـ LSTM ، لا تملك النماذج سوى ذاكرة كافية لسياق صغير من N ثابت الطول ، وبالتالي فإنها تنشئ نصوصًا مضحكة لا معنى لها. تُستخدم نماذج Markov أيضًا في الطرق البدائية لتوليد البريد العشوائي ، ويمكن تمييز النصوص التي تم إنشاؤها بسهولة عن النصوص الحقيقية عن طريق حساب الإحصائيات التي لا تناسب النموذج. هناك ميزة واحدة: نماذج ماركوف تعمل بشكل أسرع بكثير من الشبكات العصبية ، وهو بالضبط ما نحتاجه.
مثال على العنوان (أمثلةنا باللغة التركية بسبب البيانات المستخدمة):
Hyunday Butter'dan anket shluha - رئيس Politika manşetleri | STALKER BOXER Çiftede book - Yanudistkarışmanlı Mı Kanal | الفنادق القريبة من Centry'ler Neden babah.com League el Digitalika Haberler - هابرلريسي
يمكننا حساب الإحصاءات من البيانات المصدر ، وإنشاء نموذج ماركوف ، وإنشاء بيانات جديدة معها. لاحظ أن النموذج يحتاج إلى تجانس لتجنب الكشف عن معلومات حول مجموعات نادرة في البيانات المصدر ، ولكن هذه ليست مشكلة. يمكنني استخدام مجموعة من الطرز من 0 إلى N. إذا كانت الإحصائيات غير كافية لطراز الترتيب N ، يتم استخدام طراز N - 1 بدلاً من ذلك.
لكننا ما زلنا نريد الحفاظ على أصل البيانات. بمعنى آخر ، إذا كانت البيانات المصدر تحتوي على 123456 قيم عناوين URL فريدة ، فيجب أن تحتوي النتيجة على نفس عدد القيم الفريدة تقريبًا. يمكننا استخدام مولد الأرقام العشوائية المحدد بشكل قاطع لتحقيق ذلك. أسهل طريقة للقيام بذلك هي استخدام دالة تجزئة وتطبيقها على القيمة الأصلية. بمعنى آخر ، نحصل على نتيجة عشوائية مزيفة يتم تحديدها بوضوح من خلال القيمة الأصلية.
مطلب آخر هو أن البيانات المصدر قد تحتوي على العديد من عناوين URL المختلفة التي تبدأ بنفس البادئة ولكنها غير متطابقة. على سبيل المثال:
https://www.yandex.ru/images/cats/?id=xxxxxx . نريد أن يكون للنتيجة أيضًا عناوين URL التي تبدأ جميعها بنفس البادئة ، ولكن مختلفة. على سبيل المثال:
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx . كمولد أرقام عشوائي لإنشاء الحرف التالي باستخدام نموذج Markov ، سنأخذ دالة التجزئة من نافذة متحركة من 8 بايت في الموضع المحدد (بدلاً من أخذها من السلسلة بأكملها).
https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ...اتضح أن ما نحتاجه بالضبط. فيما يلي مثال لعناوين الصفحات:
PhotoFunia - Haber7 - Hava mükemment.net Oynamak içinde şaşıracak haber، Oyunu Oynanılmaz • apród.hu kínálatában - RT العربية
PhotoFunia - Kinobar.Net - apród: Ingyenes | Posti
PhotoFunia - ربط الوتد - Castika ، Sıradışı Deniz Lokoning المدونة الخاصة بك ، أب Eminema.tv/
PhotoFunia - TUT.BY - Your Ayakkanın ve Son Dakika Spor ،
PhotoFunia - izle film big، Del Meireles offilim، Samsung DealeXtreme Değerler NEWSru.com.tv، Smotri.com Mobile yapmak Okey
فوتو فونيا 5 | Galaxy، gt، după ce anal bilgi yarak Ceza RE050A V-Stranç
PhotoFunia :: Miami olacaksını yerel Haberler Oyun Young video
PhotoFunia Monstelli'nin En İyi kisa.com.tr - Star Thunder Ekranı
PhotoFunia Seks - Politika ، Ekonomi ، Spor GTA SANAYİ VE
PhotoFunia Taker-Star Star TV Resmi Söylenen Yatağa każdy dzież wierzchnie
PhotoFunia TourIndex.Marketime oyunu Oyna Geldolları Mynet Spor، Magazin، Haberler yerel Haberleri ve Solvia، korkusuz Ev SahneTv
PhotoFunia ما يجب القيام به في دون رسم بياني Parti'nin yapıyı بو
PhotoFunian Dünyasın takımız halles en kulları - TEZ
النتائج
بعد تجربة أربع طرق ، تعبت من هذه المشكلة لدرجة أن الوقت قد حان لاختيار شيء ما ، وجعله أداة قابلة للاستخدام ، والإعلان عن الحل. اخترت الحل الذي يستخدم التباديل العشوائي ونماذج ماركوف المحددة بواسطة مفتاح. يتم تنفيذه كبرنامج
clickhouse-obfuscator ، وهو سهل الاستخدام للغاية. الإدخال عبارة عن تفريغ جدول
بأي تنسيق مدعوم (مثل CSV أو JSONEachRow) ، وتحدد معلمات سطر الأوامر بنية الجدول (أسماء الأعمدة وأنواعها) والمفتاح السري (أي سلسلة ، والتي يمكنك نسيانها فور استخدامها). الإخراج هو نفس عدد صفوف البيانات المبهمة.
تم تثبيت البرنامج مع clickhouse-client ، وليس له أي تبعيات ، ويعمل على أي نكهة تقريبا لنظام Linux. يمكنك تطبيقه على أي تفريغ قاعدة بيانات ، وليس فقط ClickHouse. على سبيل المثال ، يمكنك إنشاء بيانات اختبار من قواعد بيانات MySQL أو PostgreSQL أو إنشاء قواعد بيانات تطوير مشابهة لقواعد بيانات الإنتاج.
clickhouse-obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse-obfuscator --help
بالطبع ، لا يتم قص كل شيء وتجفيفه ، لأن البيانات التي يتم تحويلها بواسطة هذا البرنامج يمكن عكسها تمامًا تقريبًا. والسؤال هو ما إذا كان من الممكن إجراء التحول العكسي دون معرفة المفتاح. إذا استخدم التحويل خوارزمية تشفير ، فستكون هذه العملية صعبة مثل عملية البحث باستخدام القوة الغاشمة. على الرغم من أن التحول يستخدم بعض الأولويات المشفرة ، إلا أنه لا يتم استخدامها بالطريقة الصحيحة ، وتكون البيانات عرضة لبعض طرق التحليل. لتجنب المشكلات ، تتم تغطية هذه المشكلات في وثائق البرنامج (الوصول إليه باستخدام
--help ).
في النهاية ، قمنا بتحويل مجموعة البيانات التي نحتاجها
للاختبار الوظيفي واختبار الأداء ونشرة ياندكس VP لنشر أمان البيانات المعتمد.
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xzclickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xzيستخدم مطورو البرامج غير التابعة لـ Yandex هذه البيانات لاختبار الأداء الحقيقي عند تحسين الخوارزميات داخل ClickHouse. يمكن لمستخدمي الطرف الثالث تزويدنا ببياناتهم المبهمة حتى نتمكن من جعل ClickHouse أسرع بالنسبة لهم. أصدرنا أيضًا معيارًا مفتوحًا مستقلًا لموفري الأجهزة والسحابة أعلى هذه البيانات:
clickhouse.yandex/benchmark_hardware.html