هذه المقالة هي ترجمة لمقالتي حول "
البدء - مع Data Lake" ، والتي تحولت إلى شعبية كبيرة ، ربما بسبب بساطتها. لذلك ، قررت أن أكتبها باللغة الروسية وأكملها قليلاً حتى يتمكن الشخص البسيط الذي ليس متخصصًا في البيانات من فهم ماهية مستودع البيانات (DW) وما هي بحيرة البيانات وكيف تتوافق مع ذلك .
لماذا أريد أن أكتب عن بحيرة بيانات؟ لقد كنت أعمل مع البيانات والتحليلات منذ أكثر من 10 سنوات ، والآن أنا بالتأكيد أعمل مع البيانات الكبيرة في Amazon Alexa AI في كامبريدج ، الموجودة في بوسطن ، على الرغم من أنني أعيش في فيكتوريا في جزيرة فانكوفر وغالبًا ما أقوم بزيارة بوسطن وسياتل و فانكوفر ، وأحيانا حتى في موسكو ، أتحدث في المؤتمرات. أيضًا ، من وقت لآخر ، أكتب ، لكنني أكتب بشكل رئيسي باللغة الإنجليزية ، وقد كتبت بالفعل
العديد من الكتب ، كما أنني بحاجة إلى مشاركة اتجاهات التحليل من أمريكا الشمالية ، وأحيانًا أكتب في
البرقيات .
عملت دائمًا مع مستودعات البيانات ، ومنذ عام 2015 بدأت العمل عن كثب مع Amazon Web Services ، وتحولت عمومًا إلى التحليلات السحابية (AWS ، Azure ، GCP). لقد لاحظت تطور حلول التحليلات منذ عام 2007 ، وحتى عملت في بائع Teradat لمستودع البيانات وقمت بتنفيذه في Sberbank ، ثم ظهرت Big Data with Hadoop. بدأ الجميع في القول إن عصر المخازن قد انتهى والآن أصبح كل شيء في Hadoop ، ثم بدأوا يتحدثون عن بحيرة البيانات ، مرة أخرى ، بعد أن انتهى مستودع البيانات بالتأكيد. لكن لحسن الحظ (ربما لشخص ما وللأسف ، الذي كسب الكثير من المال على إنشاء Hadoop) ، لم يذهب مستودع البيانات.
في هذه المقالة ، سننظر في ماهية بحيرة البيانات. هذه المقالة مخصصة للأشخاص الذين لديهم خبرة قليلة أو معدومة في تخزين البيانات.

في الصورة ، تعد بحيرة بليد واحدة من بحيراتي المفضلة ، رغم أنني كنت هناك مرة واحدة فقط ، لكنني أتذكرها مدى الحياة. لكننا سنتحدث عن نوع آخر من البحيرة - بحيرة البيانات. ربما سمع الكثير منكم بالفعل عن هذا المصطلح أكثر من مرة ، لكن التعريف الآخر لن يضر أحداً.
بادئ ذي بدء ، فيما يلي التعريفات الأكثر شيوعًا لبحيرة البيانات:
"تخزين الملفات لجميع أنواع البيانات الخام المتاحة للتحليل من قبل أي شخص في المنظمة" - مارتن فاولر.
"إذا كنت تعتقد أن عرض البيانات عبارة عن زجاجة مياه - معبأة ومعبأة ومعبأة للاستخدام المريح ، فإن بحيرة البيانات عبارة عن خزان ضخم للمياه في شكله الطبيعي. المستخدمين ، يمكنني أن أسحب الماء لنفسي ، وأغوص في الأعماق ، واستكشف "- James Dixon.
الآن نحن نعرف على وجه اليقين أن بحيرة البيانات تدور حول التحليلات ، فهي تسمح لنا بتخزين كميات كبيرة من البيانات في شكلها الأصلي ولدينا وصول ضروري ومناسب إلى البيانات.
غالبًا ما أرغب في تبسيط الأشياء ، إذا كان بإمكاني تحديد مصطلح معقد بكلمات بسيطة ، ففهمت بنفسي كيف يعمل ولماذا. بطريقة ما ، كنت أقوم باختيار جهاز iPhone الخاص بي في معرض الصور ، وقد بزغ فجرًا بالنسبة لي ، لذا فهذه بحيرة حقيقية من البيانات ، حتى أنني صنعت شريحة للمؤتمرات:

كل شيء بسيط جدا. نلتقط صورة على الهاتف ، يتم حفظ الصورة على الهاتف ويمكن حفظها في iCloud (تخزين الملفات في السحابة). يجمع الهاتف أيضًا بيانات التعريف للصورة: ما هو معروض ، علامة جغرافية ، وقت. نتيجةً لذلك ، يمكننا استخدام واجهة iPhone المناسبة للعثور على صورتنا وفي الوقت نفسه نرى مؤشرات ، على سبيل المثال ، عندما أبحث عن صور بكلمة fire ، أجد 3 صور بها صورة نار. بالنسبة لي ، إنه يشبه تمامًا أداة ذكاء الأعمال التي تعمل بسرعة كبيرة ووضوح.
وبالطبع ، لا ينبغي لنا أن ننسى الأمن (الترخيص والمصادقة) ، وإلا فإن بياناتنا يمكن أن تدخل بسهولة في الوصول المفتوح. هناك الكثير من الأخبار حول الشركات الكبيرة والشركات الناشئة ، والتي دخلت فيها البيانات إلى المجال العام بسبب إهمال المطورين وعدم مراعاة القواعد البسيطة.
حتى هذه الصورة البسيطة تساعدنا على تخيل شكل بحيرة البيانات ، اختلافاتها من مستودع البيانات التقليدي وعناصرها الرئيسية:
- يعد تحميل البيانات (الابتلاع) مكونًا رئيسيًا لبحيرة البيانات. يمكن أن تدخل البيانات إلى مستودع البيانات بطريقتين - الدفعة (التنزيل على فترات) والبث (دفق البيانات).
- تخزين الملفات هو المكون الرئيسي لبحيرة البيانات. نحتاج إلى أن تكون وحدة التخزين قابلة للتوسعة بسهولة وموثوقية ومنخفضة التكلفة. على سبيل المثال ، في AWS ، هذا هو S3.
- الكاتالوج والبحث - لتجنب تعرّض البيانات (هذا عندما نلقي جميع البيانات في كومة واحدة ، ومن ثم يستحيل العمل معها) ، نحتاج إلى إنشاء طبقة بيانات التعريف لتصنيف البيانات بحيث يمكن للمستخدمين بسهولة العثور على البيانات التي يحتاجونها للتحليل. بالإضافة إلى ذلك ، يمكنك استخدام حلول بحث إضافية ، مثل ElasticSearch. يساعد البحث المستخدم في البحث عن البيانات المطلوبة من خلال واجهة مريحة.
- المعالجة (العملية) - هذه الخطوة مسؤولة عن معالجة البيانات وتحويلها. يمكننا تحويل البيانات ، وتغيير بنيتها ، واضحة وأكثر من ذلك بكثير.
- الأمان - من المهم قضاء بعض الوقت في تصميم حل أمني. على سبيل المثال ، تشفير البيانات أثناء التخزين والمعالجة والتحميل. من المهم استخدام أساليب المصادقة والترخيص. في الختام ، هناك حاجة إلى أداة التدقيق.
من وجهة نظر عملية ، يمكننا وصف بحيرة البيانات بثلاث سمات:
- جمع وتخزين أي شيء تريده - تحتوي بحيرة البيانات على جميع البيانات ، سواء البيانات الخام الخام لأي فترة من الوقت ، والبيانات المعالجة / التي تم محوها.
- تحليل عميق - تتيح بحيرة البيانات للمستخدمين استكشاف وتحليل البيانات.
- الوصول المرن - توفر بحيرة البيانات وصولاً مرنًا لمختلف البيانات والسيناريوهات المختلفة.
الآن يمكننا التحدث عن الفرق بين مستودع البيانات وبحيرة البيانات. يسأل الناس عادة:
- ولكن ماذا عن مستودع البيانات؟
- هل نقوم باستبدال مستودع البيانات ببحيرة بيانات أم أننا بصدد توسيعها؟
- هل من الممكن الاستغناء عن بحيرة بيانات؟
باختصار ، لا توجد إجابة واضحة. كل هذا يتوقف على الوضع المحدد ، ومهارات الفريق والميزانية. على سبيل المثال ، ترحيل مستودع بيانات إلى Oracle في AWS وإنشاء بحيرة بيانات بواسطة شركة Amazon التابعة - Woot -
قصة بحيرة البيانات الخاصة بنا: كيف بنى Woot.com بحيرة بيانات بدون خادم على AWS .
من ناحية أخرى ، يوضح بائع Snowflake أنك لم تعد بحاجة إلى التفكير في بحيرة بيانات ، لأن منصة البيانات الخاصة بها (حتى عام 2020 كانت مستودع بيانات) تتيح لك الجمع بين بحيرة البيانات ومستودع البيانات. لم أعمل كثيرًا مع Snowflake ، وهو منتج فريد حقًا يمكنه القيام بذلك. سعر السؤال هو سؤال آخر.
في الختام ، رأيي الشخصي هو أننا ما زلنا بحاجة إلى مستودع بيانات كمصدر رئيسي للبيانات الخاصة بتقاريرنا ، ونخزن كل شيء لا يلائم بحيرة البيانات. الدور الكامل للتحليلات هو توفير وصول سهل إلى الأعمال التجارية لاتخاذ القرارات. على أي حال ، يعمل مستخدمو الأعمال بشكل أكثر كفاءة مع مستودع بيانات من بحيرة البيانات ، على سبيل المثال ، في Amazon - هناك Redshift (مستودع البيانات التحليلية) و Redshift Spectrum / Athena (واجهة SQL لبحيرة البيانات في S3 بناءً على Hive / Presto). الأمر نفسه ينطبق على مستودعات البيانات التحليلية الحديثة الأخرى.
لنلقِ نظرة على بنية مستودع البيانات النموذجية:
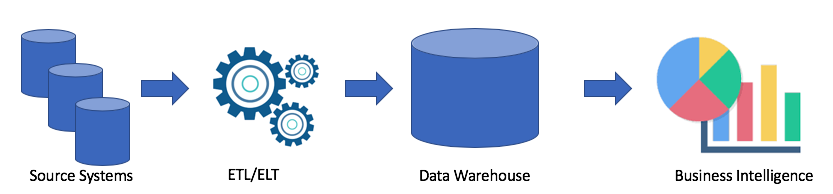
هذا هو الحل الكلاسيكي. لدينا أنظمة مصدر ، باستخدام ETL / ELT نقوم بنسخ البيانات إلى مستودع البيانات التحليلية وربط الحل بـ Business Intelligence (تابلو المفضل لدي ، ولديك؟).
هذا الحل له العيوب التالية:
- تستغرق عمليات ETL / ELT الوقت والموارد.
- وكقاعدة عامة ، فإن ذاكرة تخزين البيانات في مستودع بيانات تحليلية ليست رخيصة (على سبيل المثال ، Redshift ، BigQuery ، Teradata) ، حيث نحتاج إلى شراء مجموعة كاملة.
- يمكن لمستخدمي الأعمال الوصول إلى البيانات التي تم تنظيفها وتجميعها في كثير من الأحيان وليس لديهم القدرة على الحصول على البيانات الخام.
بالطبع ، كل هذا يتوقف على قضيتك. إذا لم يكن لديك أي مشكلة في مستودع البيانات ، فأنت لا تحتاج مطلقًا إلى بحيرة بيانات. ولكن عندما تنشأ مشاكل مع نقص المساحة أو القدرة أو سعر المشكلة يكون لها دور رئيسي ، فيمكنك عندئذٍ التفكير في خيار بحيرة البيانات. هذا هو السبب ، بحيرة البيانات تحظى بشعبية كبيرة. فيما يلي مثال على بنية بحيرة البيانات:

باستخدام نهج بحيرة البيانات ، نقوم بتحميل البيانات الخام في بحيرة البيانات الخاصة بنا (الدفعي أو الدفق) ، ثم نقوم بمعالجة البيانات حسب الضرورة. تسمح مجموعة البيانات لمستخدمي الأعمال بإنشاء تحويلات البيانات الخاصة بهم (ETL / ELT) أو تحليل البيانات في حلول ذكاء الأعمال (إذا كان لديك برنامج التشغيل الصحيح).
الهدف من أي حل تحليلي هو خدمة مستخدمي الأعمال. لذلك ، يجب أن نعمل دائمًا على متطلبات العمل. (في أمازون ، هذا هو أحد المبادئ - العمل للخلف).
من خلال العمل مع كل من مستودع البيانات وبحيرة البيانات ، يمكننا مقارنة كلا الحلين:
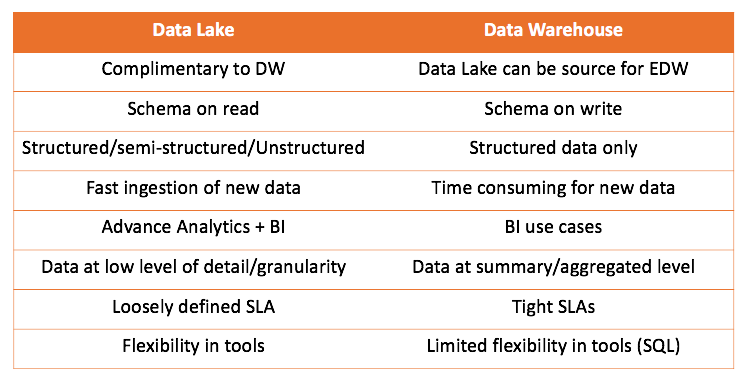
الاستنتاج الرئيسي الذي يمكن استخلاصه هو أن مستودع البيانات لا ينافس بحيرة البيانات ، لكنه يكملها أكثر. ولكن الأمر متروك لك ما هو الصحيح لقضيتك. من المثير للاهتمام دائمًا أن تجرب ذلك بنفسك وتستخلص النتائج الصحيحة.
أود أيضًا أن أتحدث عن إحدى الحالات عندما بدأت في استخدام نهج بحيرة البيانات. كل شيء شائع إلى حد ما ، لقد حاولت استخدام أداة ELT (كان لدينا Matillion ETL) و Amazon Redshift ، وقد نجح الحل الخاص بي ، لكنه لم يتناسب مع المتطلبات.
كنت بحاجة لأخذ سجلات الويب وتحويلها وتجميعها لتوفير بيانات لحالتين:
- أراد فريق التسويق تحليل نشاط الروبوتات لكبار المسئولين الاقتصاديين
- أراد تكنولوجيا المعلومات لمشاهدة مقاييس الموقع
سجلات بسيطة جدا وبسيطة جدا. هنا مثال:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188 192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57 "GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2 arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012" 1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"
ملف واحد يزن 1-4 ميغابايت.
ولكن كان هناك صعوبة واحدة. كان لدينا 7 مجالات في جميع أنحاء العالم ، وفي يوم واحد تم إنشاء 7000 ألف ملف. هذا ليس حجمًا كبيرًا جدًا ، فقط 50 غيغابايت. لكن حجم كتلة Redshift الخاصة بنا كان صغيرًا أيضًا (4 عقد). استغرق تنزيل ملف واحد بالطريقة التقليدية حوالي دقيقة. وهذا هو ، لم يتم حل المهمة في الجبهة. وكان هذا هو الحال عندما قررت استخدام نهج بحيرة البيانات. بدا الحل شيء من هذا القبيل:
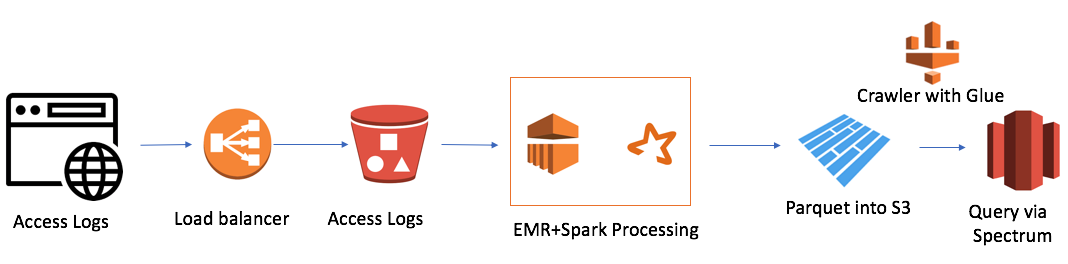
الأمر بسيط للغاية (أريد أن أشير إلى أن ميزة العمل في السحابة هي البساطة). اعتدت:
- AWS خريطة مرنة تقليل (Hadoop) كقوة الحوسبة
- AWS S3 كتخزين ملفات مع القدرة على تشفير البيانات وتقييد الوصول
- شرارة كقوة الحوسبة InMemory و PySpark لتحويل المنطق والبيانات
- الباركيه نتيجة سبارك
- AWS الغراء الزاحف كمجمع للبيانات الوصفية حول البيانات الجديدة والأقسام
- Redshift Spectrum كواجهة SQL إلى بحيرة البيانات لمستخدمي Redshift الحاليين
معالجة أصغر مجموعة EMR + Spark مجموعة كاملة من الملفات في 30 دقيقة. هناك حالات أخرى لـ AWS ، خاصةً العديد منها تتعلق بـ Alexa ، حيث يوجد الكثير من البيانات.
في الآونة الأخيرة ، اكتشفت أن أحد عيوب بحيرة البيانات هو إجمالي الناتج المحلي. المشكلة هي عندما يطلب منه العميل حذفه ، وتكون البيانات في أحد الملفات ، لا يمكننا استخدام لغة معالجة البيانات وعملية DELETE كما هو الحال في قاعدة البيانات.
نأمل أن توضح المقالة الفرق بين مستودع البيانات وبحيرة البيانات. إذا كان الأمر ممتعًا ، فلا يزال بإمكاني ترجمة مقالاتي أو مقالة المهنيين الذين قرأتهم. وتحدث أيضًا عن الحلول التي أعمل بها وهندستها المعمارية.