
للسنة الثالثة الآن ، عقدنا منتدى RAIF (منتدى الذكاء الاصطناعي الروسي) حيث يتحدث متحدثون من عالم الأعمال والعلوم عن عملهم. قررنا مشاركة التقارير الأكثر إثارة للاهتمام. في هذا المنشور ، يخبر Andrey Filchenkov ، رئيس ITMO Machine Learning Lab ، الحقيقة الكاملة حول AutoML.
في إطار منتدى RAIF 2019 الذي عقد في سكولكوفو ، نظمته Jet Infosystems ، قدمت عرضًا تقديمي تحدثت فيه عن AutoML وآفاق استخدامه. منذ أن كنت عالمة ، ليس من الضروري أن أتحدث في مثل هذه الأحداث في كثير من الأحيان: عادة ما أشارك في المؤتمرات العلمية.
أحد المجالات الرئيسية التي نتعامل معها هي AutoML. بالإضافة إلى ذلك ، أنا CTO اثنين من الشركات الناشئة الصغيرة. واحد منهم - تقنيات Statanly - يخلق خدمات AutoML ويشارك في تحليل البيانات. في الواقع ، أنا الشخص الذي يخترع الخوارزميات وينفذها ويستخدمها. أعتقد أنني الشخص الوحيد الذي يمكنه التحدث عن AutoML من المواضع الثلاثة المحتملة.
ما هو AutoML؟
في العام الماضي ، كان هذا الاتجاه ذا أهمية كبيرة ، والآن يمكن مقارنته بتركيز الاهتمام على التعلم العميق الشائع في وقته. يمكن أن يعود تاريخ ظهور التعلم الآلي التلقائي إلى عام 1976. كان هناك مجتمع ML صغير ، وفي عام 2017 بدأ يكتسب شعبية ، بعد سنة تتجاوز حدود التعلم الآلي نفسه. الآن يتحدثون عنه في الأعمال التجارية والصناعة وفي مختلف المجالات الأخرى. صحيح ، في روسيا ، لسوء الحظ ، لا يتخيل كل الناس حتى من مجتمع ML ماهية تعلم الآلة التلقائي. لماذا حدث هذا؟
الجواب بسيط - ينمو الطلب على علماء البيانات بشكل أسرع بكثير مما ينجحون في التخرج من الجامعات واستكمال الدورات. في الوقت نفسه ، يقضون معظم الوقت (ما يصل إلى 80 ٪) في اختيار نموذج ، وإعداده والانتظار حتى يتم حساب كل شيء. هذا بسبب عدم وجود خوارزمية مثالية - لسوء الحظ ، يكون لأي منها نطاق محدود ، ويتعين على المتخصصين في تحليل البيانات تحديد الخوارزمية المثلى لكل مهمة محددة ، ثم تكوينها. هنا ، يعتمد الكثير بالفعل على مؤهلات المحلل: فكلما زاد معرفته في مجال الموضوع وفهم الخوارزميات ، زاد الحل الأمثل لفترة زمنية معينة. هذا هو المكان الذي يساعدك AutoML. في الواقع ، يسمح لك AutoML بأتمتة وتسريع عملية اختيار حلول ومهام التعلم الآلي.
لنقرر على الفور: هناك اتجاهان مرتبطان ، لكنهما مختلفان عن بعضنا البعض.
أولاً: يتم تقديم البيانات في الجدول ، وهناك تسميات ، وعندما نحتاج إلى تصنيفها ، نختار كائنًا من قائمة كبيرة ونقوم بتكوين معلماته المفرطة ، وفي نفس الوقت يمكننا معالجة البيانات.
السيناريو الثاني أكثر تعقيدًا. على سبيل المثال ، الصور والتسلسلات والمناطق التي أصبح التعليم العميق فيها الآن هو المعيار - هنا تصبح المهمة أكثر إثارة للاهتمام قليلاً ، لأنه يمكنك الخروج بنيات جديدة: ليس من السهل فرزها. لذلك ، "البحث عن البنى العصبية" ، تعمل في حقيقة أنها تختار الشبكة المثلى وتضع معلمات مفرطة تسمح بحل مشكلة أو أخرى. ومع ذلك ، لا يأخذ AutoML في الاعتبار دلالات البيانات. هناك أيضًا طرق تتيح لك "إخراج" أوصاف البيانات واستخدامها للتنبؤ ، ولكن هذا يساعد فقط على زيادة قابلية تطبيق AutoML العالمي. لا يهم حقًا من أين جاءت البيانات: سواء كنت رجل غاز أو بائع آيس كريم أو أي شخص آخر - فالطرق عالمية. في الوقت نفسه ، يسمح لك AutoML ببناء الحلول الأكثر فعالية من ناحية ، واختيار الحلول المعقدة وليس الأكثر وضوحًا حتى بالنسبة للمتخصص في تحليل البيانات الهيكلية ، ومن ناحية أخرى ، البحث عن هذه الحلول وتحسينها بشكل أسرع. وهناك شيء آخر غير واضح - AutoML يجعل من الممكن تسريع كتابة التعليمات البرمجية. هنا ، على سبيل المثال:

على اليمين ، يتم كتابة الرمز في Keras للتعرف على MNIST ، وعلى اليسار هو رمز Auto-Keras في مكتبة الأتمتة المكتوبة تحت Keras. الفرق واضح ، بينما يتم حفظ وقت الكتابة.
وفرة من الحلول القائمة (2019)
في الوقت الحالي ، يوجد عدد كبير من المكتبات والأنظمة الأساسية المختلفة لتحليل البيانات تلقائيًا ، وقد استشهدت ببعضها فقط (في الواقع ، يوجد الكثير منها).
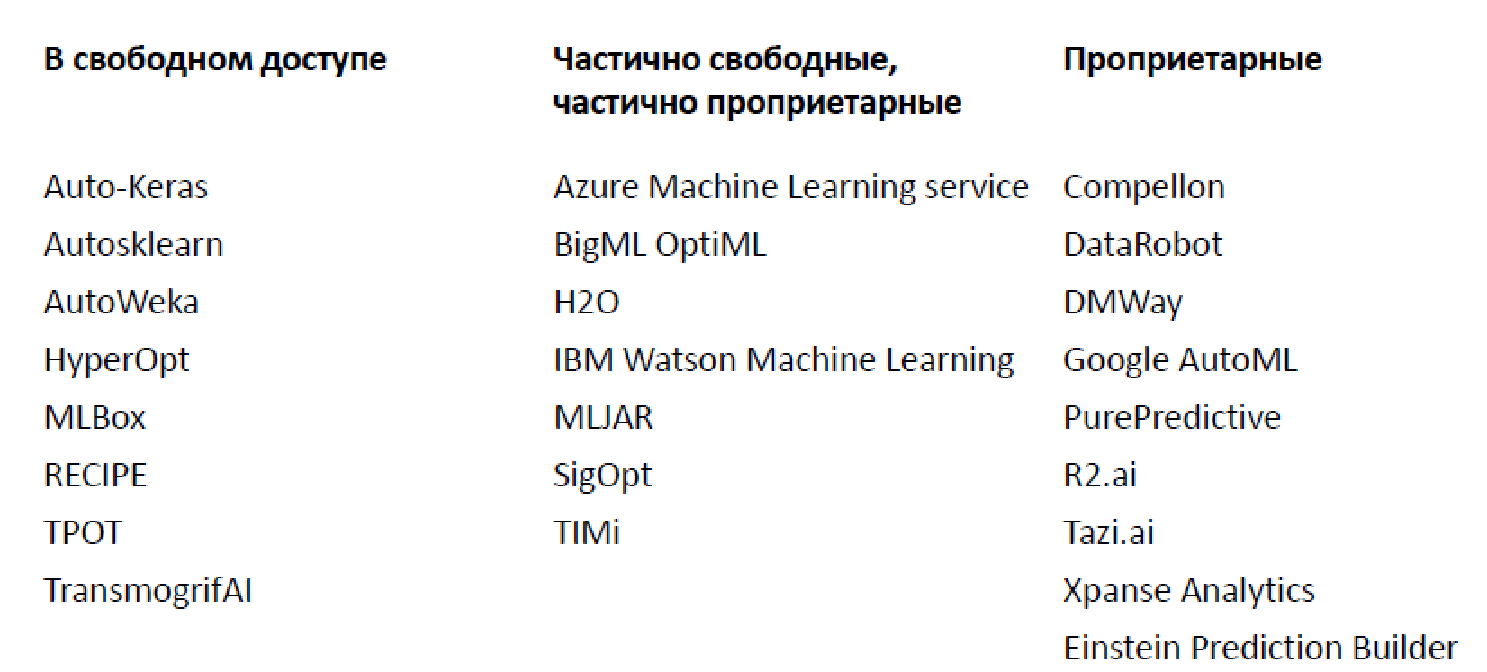
هناك كلاهما مفتوحان ، يعملان على تطبيق وظائف محدودة وخيارات الملكية. الأكثر شهرة ، على الأرجح ، Google AutoML ، الذي لا يمنحك نموذجًا ، ولكنه يدربه على بياناتك ، مما يتيح لك استخدامه مقابل 20 دولارًا في الساعة. بالإضافة إلى ذلك ، هناك عدد كبير من السيناريوهات اللائقة عندما يتم توفير الوظيفة الأساسية مجانًا ، ولكن عليك أن تدفع مقابل المكونات الأكثر تقدماً.
توقعات مشرق
يشيد المجتمع نفسه باحتمالات AutoML. على سبيل المثال ، قال جيف دين ، عالم الذكاء الاصطناعي وباحث كبير في Google ، مرة أخرى في مارس 2018 أنه يمكن الاستعاضة عن الخبرة الحالية في تعلم الماكينات بزيادة مائة في قوة الحوسبة (كل ما يفعله عالم البيانات تقريبًا) -يمكنك الآلي). هناك توقعات أكثر تقييدًا قليلاً ، ولكن لا تزال مخيفة ، من Gartner تقول أنه بحلول عام 2020 ، يمكن استبدال 40 ٪ من علماء البيانات بـ AutoML.
قليلا من القطران
هذا ما تبدو عليه منهجية CRISP DM القياسية:
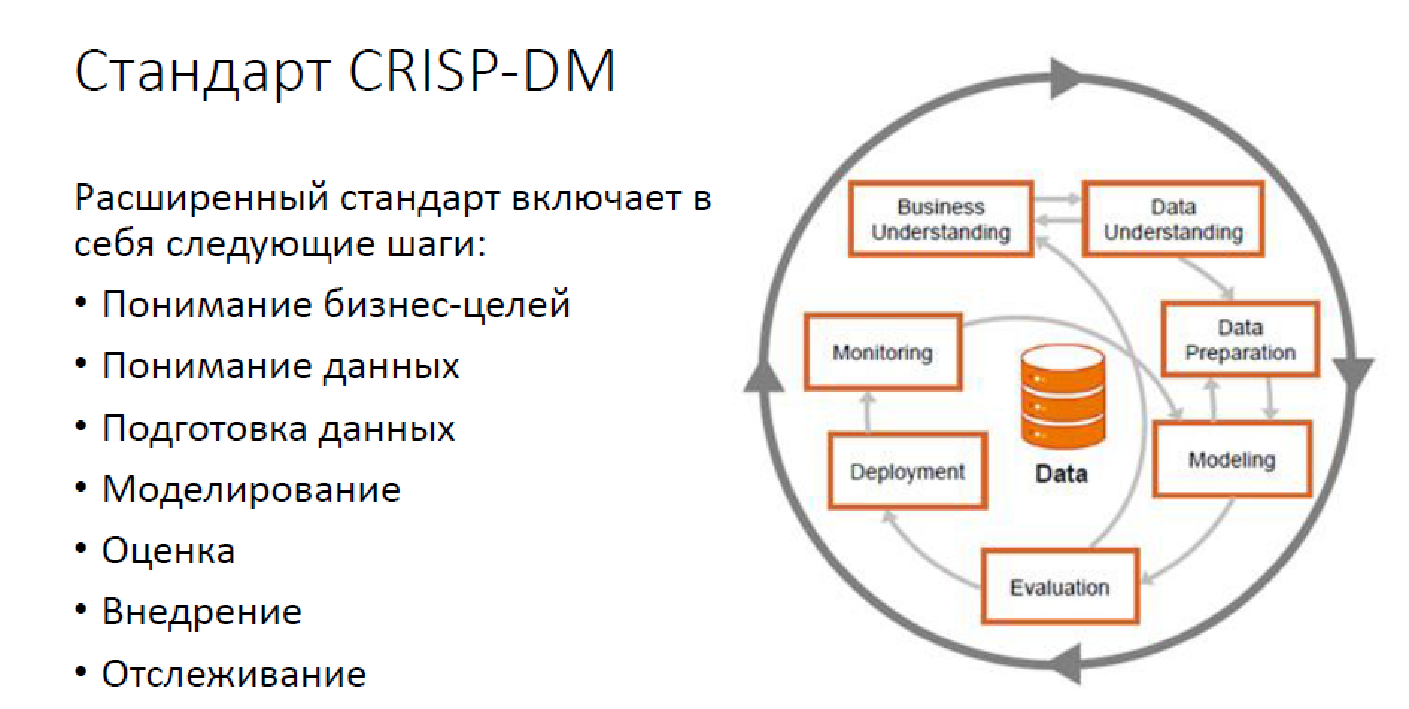
هذا هو خيار متقدم ، مع المراقبة ، ولكن مع ذلك. اليوم ، حل مشاكل تحليل البيانات لا يتلخص في بناء النماذج فقط. لدينا عدد كبير من المهام التي تحتاج إلى حل ، ومن الضروري حلها بدقة من قبل الناس.
في الوقت الحالي ، في معظم الحالات ، يقف AutoML على 2.5 عمودًا فقط: اختيار نموذج وإعداده وأحيانًا عندما يظهر ، اختيار ميزات التجميع والبيانات فقط.
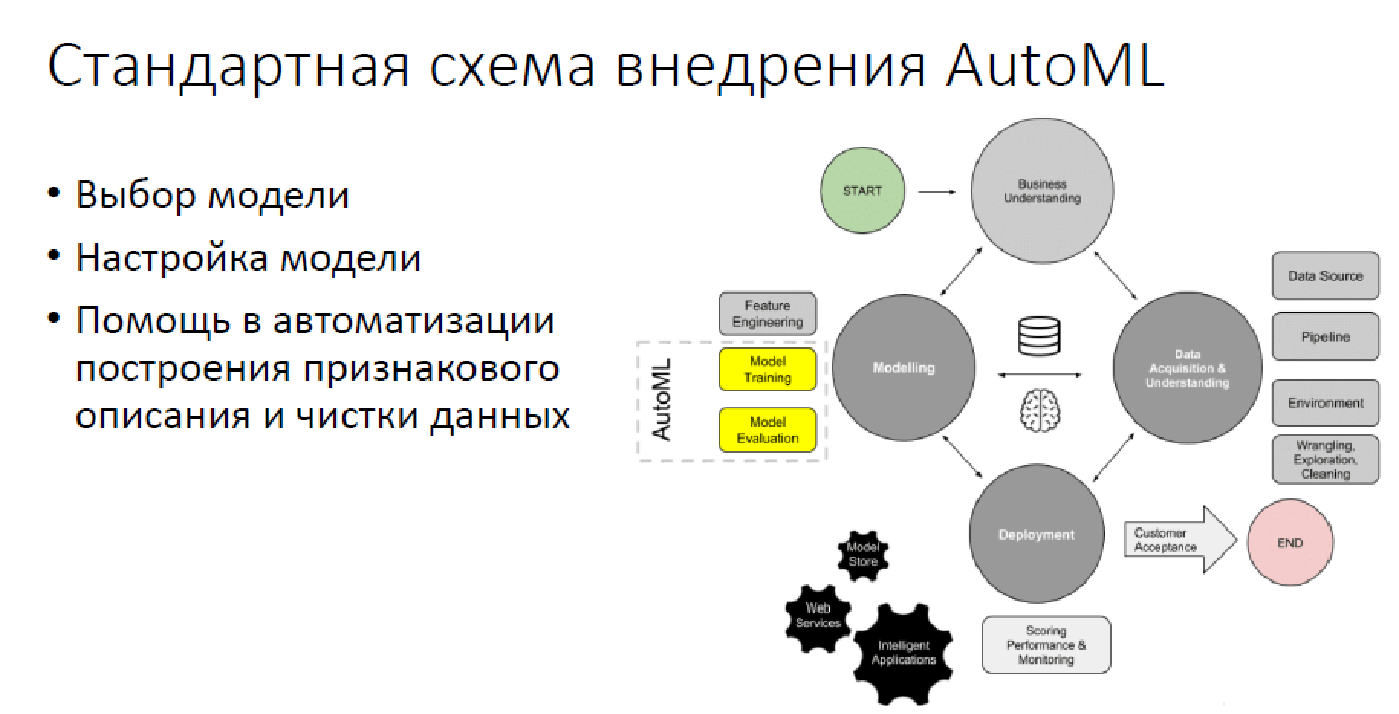
ما بعد AutoML
لسوء الحظ ، يتم ترك عدد كبير إلى حد ما من العمليات في الخارج ، وهو ما لا يسمح به AutoML ولن يتمكن من القيام به في مستقبل معقول. وبطبيعة الحال ، هذا يعني تحويل المهام من العالم الحقيقي إلى عالم تحليل البيانات: "كيف يمكن إسقاط مشكلتك بحيث يمكن حلها عن طريق تحليل البيانات؟" هذه كلها أنواع من تتبع النماذج ، وتقييم الجودة ، والبحث عن لحظات غير سارة مختلفة - كل ذلك حتى لا يتحول الحل ، على سبيل المثال ، إلى عدم التسامح مع أي شخص ، لأن هذا قد حدث بالفعل. بطبيعة الحال ، لا يمكن لـ AutoML دعم الحلول والتواصل مع العملاء. بالإضافة إلى ذلك ، التفسير في الوقت الحالي غير وارد.
وبالتالي ، هذه أداة مريحة للغاية ، لكن لسوء الحظ ، فهي لا تحل بعيدًا عن جميع المشكلات.

ماذا نفعل؟
هذا ما تبدو عليه الدائرة المثالية (كما أراها):
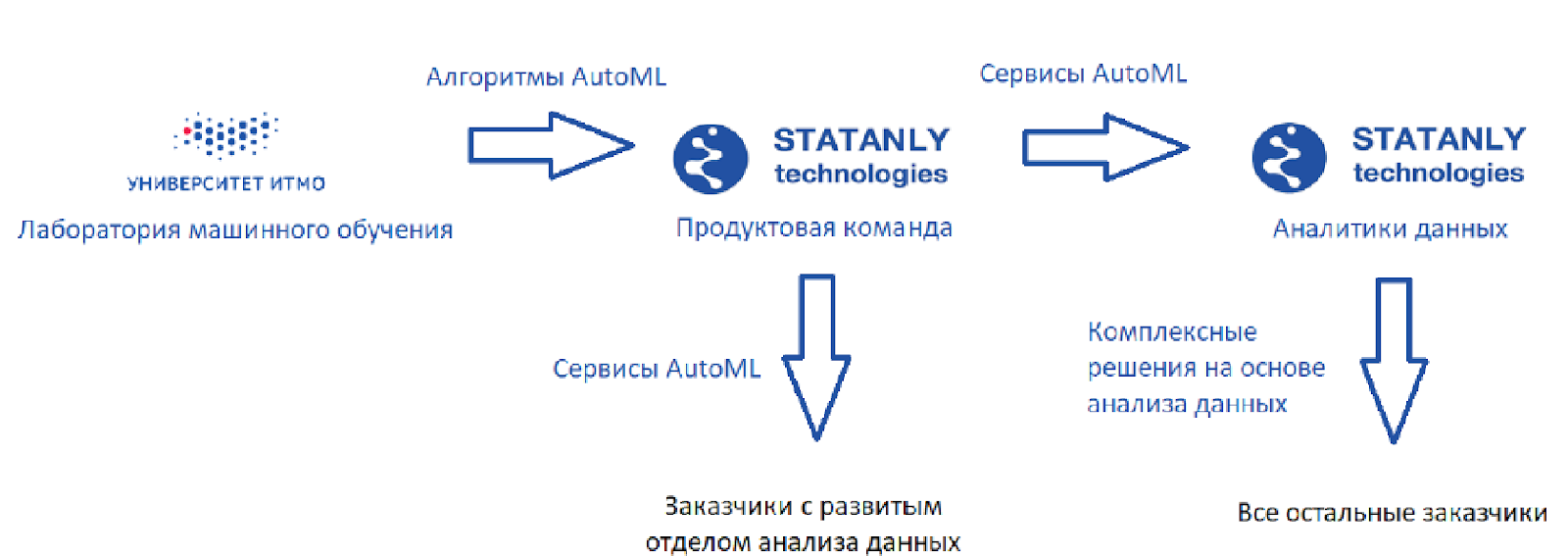
يوجد مختبر للتعلم الآلي يقوم بتطوير الخوارزميات ، بالإضافة إلى
تقنيات Statanly - فريق منتج يقوم بتنفيذ خدمات AutoML استنادًا إلى الخوارزميات الخاصة بنا. إنهم يعملون لصالح الشركات التي لديها قسم كبير لعلوم البيانات. يتم استخدام هذه المنتجات نفسها بواسطة فريق من محللي البيانات في شركة
Statanly Technologies نفسها ، وتحل على وجه التحديد مشاكل الشركات التي لم توسع بعد أو حتى أنشأت قسم تحليل البيانات الخاص بها. يبدو النموذج رائعًا ، ولكن الواقع ، بطبيعة الحال ، أكثر إحساسًا بالراحة.
بدأنا في عام 2017 بحقيقة أنه لم يكن هناك تحليل للبيانات هنا:
لقد أردنا إصدار منتج يستخدمه محللو البيانات ، ولكن في عام 2017 ، للأسف ، لم نتمكن من العثور على اتصال مع المستثمرين - فهم لم يفهموا ماهية AutoML ولماذا كانت هناك حاجة ومن سيستخدمه.
في الوقت الحالي ، نحن لا نبيع أي شيء ، كشركة تقوم بتطوير حلول AutoML ، فإننا نجعل حياتنا أسهل فقط ، كفريق واحد يشارك في تحليل البيانات:

قليلا عن كيف نفعل ذلك. بطبيعة الحال ، قمنا بإعداد معلمات مفرطة (لا توجد شبكة بحثية) ، ولكن بالإضافة إلى إعدادها ، نحاول دائمًا إنشاء بعض الحلول الأساسية المستندة إلى AutoML ، وأحيانًا نساعد أنفسنا في خطوات معالجة البيانات المسبقة.
لدي بعض الأمثلة الملهمة والمتنوعة - كل شيء فعلته AutoML وفعلته ، من البسيط إلى المعقد.
مثال بسيط هو المهمة في Gazpromneft: هناك بئر ، تحتاج إلى التنبؤ بالوقت المحتمل للفشل. لدينا تحت تصرفنا البيانات والميزات الجدولية الكلاسيكية. كنتيجة لذلك ، قمنا ببناء نموذج تنبؤي باستخدام AutoML ، بينما لم يصب أي محلل واحد ، ولكن لم يشارك حتى في هذه العملية. في الواقع ، تبين أن هذا هو الحل الأفضل:

القصة الثانية: سينارا تكنولوجيز. كانت المهمة هنا أكثر تعقيدًا قليلاً ، لأنه في الواقع كان هناك عمودين: الوقت / المعلمة + كيف تغيرت. كان من الضروري التنبؤ بفشل المحرك. استخدمنا هنا AutoML لمساعدتنا بعض الشيء في معالجة البيانات - صممنا خطًا أساسيًا ، تجاوزناه فيما بعد:

المثال الثالث: المهمة التي للوهلة الأولى لا علاقة لها بـ AutoML. هناك موقع على شبكة الإنترنت لقناة TVC - قاعدة بيانات للمقالات التي يمكن البحث فيها ، والبحث غني جدًا. نود أن نجد ليس فقط تعبيرات دقيقة للكلمات ، ولكن أيضًا مناسبة في المعنى. بالإضافة إلى قائمة كبيرة من المتطلبات المختلفة التي تحتاج أيضا إلى النظر فيها.
كيف تعاملنا مع هذه المشكلة؟
قررنا فهرسة جميع المستندات بناءً على مجموعات مرنة من الكلمات المتشابهة ، لأن الفهرسة أكثر ملاءمة. علاوة على ذلك ، هناك أكثر من 100 ألف مستند في قاعدة البيانات ، وإذا لم يتم ذلك ، فسيكون البحث طويلًا بلا حدود. بعد ذلك ، قمنا ببناء تمثيل متجه (آمل أن يكون الجميع قد سمعوا عنه) وتجمعوا حول تمثيلات المتجهات للسماح بفهرستنا.
المشكلة الثانية: كيف يمكننا تجميع البيانات؟ طبقنا AutoML لتحديد مقاييس لتقييم جودة التجميع ، وكذلك لتحديد الخوارزميات والمعلمات المفرطة للتجميع:

علاوة على ذلك ، غالبًا لا نستخدم AutoML. هنا مثالان كاشفا للغاية.
في بدء التشغيل الثاني ، تحليلات الفيديو الخاصة ، يعتبر المنتج نظامًا للتعرف على علامات السيارات لضمان وصولها المركزي إلى منطقة مغلقة. المشكلة الرئيسية هنا هي كمية صغيرة من البيانات. في هذه الحالة ، من الصعب ضبط معلمات النموذج. نحن محدودون للغاية ، لأنه غالبًا ما يتم استخدام AutoML بدون تفكير ومحاولة ضبط النماذج على نفس البيانات التي تم اختبارها عليها. لا يمكن القيام بذلك: وفقًا لكلاسيكيات التعليم الآلي ، يحتاج المرء إلى تحديد مجموعة التحقق من الصحة: كلما زاد البحث ، زاد عدد الأجهزة المتاحة. لذلك ، عندما يكون لدينا بيانات قليلة ، فإننا نشعر بالقلق إزاء العثور على هذه البيانات ووضع العلامات عليها أكثر من بناء نموذج أكثر تعقيدًا.
مثال آخر هو تطويرنا المشترك مع Huawei. لقد قمنا بمشروع لهم من أجل التعرف على النص على الصور. يبدو أنه يمكنك استخدام AutoML هنا ، نظرًا لأن هناك بالفعل ثلاثة مقاييس يمكن تحسينها: جودة التعرف ، وقت التعرف ومعلمة الطراز (حيث كان من المفترض أن يتم تنفيذ كل هذا في الأجهزة المحمولة). ولكن الآن لا أحد لديه ما يكفي من الخبرة لتنفيذ الجوانب الثلاثة على النحو الأمثل.
نتيجة لذلك ، لم تكن هناك طاقة كافية للحوسبة: لقد كنا محدودين في الوقت ولم يكن لدينا عدد كافٍ من الخوادم. إذا بدأنا تشغيله في المنزل (وكان ينبغي أن يكون في LICE) ، فلن يكون لدينا وقت ببساطة. نظرًا لأن معالجة الأمر تستغرق خمس ساعات ، فقد كلفنا ذلك كفاءاتنا فقط.
استنتاج
بشكل عام ، يعد AutoML شيئًا مفيدًا للغاية ، ولكنه ضيق في التطبيق. بطبيعة الحال ، لن يتمكن من التوصل إلى حلول للمعارف التقليدية. AutoML مفيد حاليًا لمحللي البيانات فقط. ربما في يوم من الأيام سيحل محله ، لكن من الواضح أنه لن يحدث في السنوات الخمس المقبلة.
بقلم أندريه فيلتشينكوف ، رئيس مختبر تعلم الآلة ، ITMO