إذا كنت مهتمًا بالتعلم الآلي ، فربما تكون قد سمعت عن BERT والمحولات.
يعد BERT نموذجًا لغويًا من Google ، حيث يعرض أحدث النتائج بهامش واسع في عدد من المهام. أصبح بيرت ، والمحولات عمومًا ، خطوة جديدة تمامًا في تطوير خوارزميات معالجة اللغة الطبيعية (NLP). يمكن الاطلاع على المقالة المتعلقة بهم و "الترتيب" لمختلف المعايير على موقع Papers With Code .
هناك مشكلة واحدة مع بيرت: إنها مشكلة في الاستخدام في النظم الصناعية. بيرت قاعدة تحتوي على 110M المعلمات ، بيرت كبيرة - 340M. نظرًا لهذا العدد الكبير من المعلمات ، يصعب تنزيل هذا الطراز على الأجهزة ذات الموارد المحدودة ، مثل الهواتف المحمولة. بالإضافة إلى ذلك ، فإن الوقت الطويل للاستدلال يجعل هذا النموذج غير مناسب حيث تكون سرعة الاستجابة حاسمة. لذلك ، فإن إيجاد طرق لتسريع BERT هو موضوع ساخن للغاية.
لدينا في Avito في كثير من الأحيان لحل مشاكل تصنيف النص. هذه مهمة نموذجية للتعلم الآلي تم دراستها جيدًا. ولكن هناك دائما إغراء لمحاولة شيء جديد. ولدت هذه المقالة من محاولة تطبيق بيرت في مهام التعلم الآلي اليومية. فيه ، سأوضح كيف يمكنك تحسين جودة النموذج الحالي بشكل كبير باستخدام BERT دون إضافة بيانات جديدة ودون تعقيد النموذج.

تقطير المعرفة كوسيلة لتسريع الشبكات العصبية
هناك عدة طرق لتسريع / تخفيف الشبكات العصبية. يتم نشر المراجعة الأكثر تفصيلاً التي قابلتها على مدونة Intento على المتوسط .
يمكن تقسيم الطرق تقريبًا إلى ثلاث مجموعات:
- تغيير بنية الشبكة.
- ضغط النموذج (الكمي ، التقليم).
- تقطير المعرفة.
إذا كانت أول طريقتين معروفة ومتفهمة نسبيًا ، فإن الطريقة الثالثة تكون أقل شيوعًا. لأول مرة ، اقترح ريتش كاروانا فكرة التقطير في مقال "ضغط النموذج" . جوهرها بسيط: يمكنك تدريب نموذج خفيف الوزن يحاكي سلوك نموذج المعلم أو حتى مجموعة من النماذج. في حالتنا ، سيكون المعلم بيرت ، وسيكون الطالب أي نموذج ضوء.
مهمة
دعنا نحلل التقطير باستخدام التصنيف الثنائي كمثال. خذ مجموعة بيانات SST-2 المفتوحة من مجموعة المهام القياسية التي تختبر نماذج NLP.
مجموعة البيانات هذه عبارة عن مجموعة من مراجعات الأفلام مع IMDb موزعة حسب اللون العاطفي - إيجابية أو سلبية. الدقة في مجموعة البيانات هذه هي الدقة.
تدريب النماذج المعتمدة على BERT أو "المعلمين"
بادئ ذي بدء ، تحتاج إلى تدريب النموذج "الكبير" القائم على BERT ، والذي سيصبح مدرسًا. أسهل طريقة للقيام بذلك هي أخذ الزخارف من BERT وتدريب المصنف عليها ، إضافة طبقة واحدة إلى الشبكة.
بفضل مكتبة المحولات ، من السهل القيام بذلك ، نظرًا لوجود فئة طراز BertForSequenceClassification جاهزة. في رأيي ، تم نشر البرنامج التعليمي الأكثر تفصيلا ومفهومًا لتدريس هذا النموذج من قِبل Towards Data Science .
دعونا نتخيل أننا حصلنا على نموذج BertForSequenceClassification المدربين. في حالتنا ، num_labels = 2 ، نظرًا لأن لدينا تصنيفًا ثنائيًا. سوف نستخدم هذا النموذج "كمعلم".
تعلم "الطالب"
يمكنك أن تأخذ أي هندسة كطالب: شبكة عصبية ، نموذج خطي ، شجرة قرار. دعونا نحاول تعليم BiLSTM لتصور أفضل. للبدء ، سنقوم بتدريس BiLSTM بدون BERT.
لإرسال النص إلى مدخلات الشبكة العصبية ، تحتاج إلى تقديمه كمتجه. إحدى أسهل الطرق هي تعيين كل كلمة إلى فهرسها في القاموس. سيتألف القاموس من أفضل الكلمات شيوعًا في مجموعة بياناتنا بالإضافة إلى كلمتين للخدمة: "pad" - "الكلمة الوهمية" بحيث تكون جميع التسلسلات متماثلة الطول و "unk" - لكلمات خارج القاموس. سنبني القاموس باستخدام المجموعة القياسية من الأدوات من torchtext. من أجل البساطة ، لم أستخدم زخارف الكلمات المدربة مسبقًا.
import torch from torchtext import data def get_vocab(X): X_split = [t.split() for t in X] text_field = data.Field() text_field.build_vocab(X_split, max_size=10000) return text_field def pad(seq, max_len): if len(seq) < max_len: seq = seq + ['<pad>'] * (max_len - len(seq)) return seq[0:max_len] def to_indexes(vocab, words): return [vocab.stoi[w] for w in words] def to_dataset(x, y, y_real): torch_x = torch.tensor(x, dtype=torch.long) torch_y = torch.tensor(y, dtype=torch.float) torch_real_y = torch.tensor(y_real, dtype=torch.long) return TensorDataset(torch_x, torch_y, torch_real_y)
نموذج BiLSTM
سيبدو رمز النموذج كما يلي:
import torch from torch import nn from torch.autograd import Variable class SimpleLSTM(nn.Module): def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout, batch_size, device=None): super(SimpleLSTM, self).__init__() self.batch_size = batch_size self.hidden_dim = hidden_dim self.n_layers = n_layers self.embedding = nn.Embedding(input_dim, embedding_dim) self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout) self.fc = nn.Linear(hidden_dim * 2, output_dim) self.dropout = nn.Dropout(dropout) self.device = self.init_device(device) self.hidden = self.init_hidden() @staticmethod def init_device(device): if device is None: return torch.device('cuda') return device def init_hidden(self): return (Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device)), Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device))) def forward(self, text, text_lengths=None): self.hidden = self.init_hidden() x = self.embedding(text) x, self.hidden = self.rnn(x, self.hidden) hidden, cell = self.hidden hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1)) x = self.fc(hidden) return x
تدريب
بالنسبة إلى هذا النموذج ، سيكون بُعد متجه الإخراج (batch_size ، output_dim). في التدريب ، سوف نستخدم logloss المعتاد. لدى PyTorch فئة BCEWithLogitsLoss التي تجمع بين السيني وعبر إنتروبيا. ما تحتاجه.
def loss(self, output, bert_prob, real_label): criterion = torch.nn.BCEWithLogitsLoss() return criterion(output, real_label.float())
رمز لعصر واحد من التعلم:
def get_optimizer(model): optimizer = torch.optim.Adam(model.parameters()) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 2, gamma=0.9) return optimizer, scheduler def epoch_train_func(model, dataset, loss_func, batch_size): train_loss = 0 train_sampler = RandomSampler(dataset) data_loader = DataLoader(dataset, sampler=train_sampler, batch_size=batch_size, drop_last=True) model.train() optimizer, scheduler = get_optimizer(model) for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Train')): text, bert_prob, real_label = to_device(text, bert_prob, real_label) model.zero_grad() output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) loss.backward() optimizer.step() train_loss += loss.item() scheduler.step() return train_loss / len(data_loader)
رمز التحقق بعد الحقبة:
def epoch_evaluate_func(model, eval_dataset, loss_func, batch_size): eval_sampler = SequentialSampler(eval_dataset) data_loader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=batch_size, drop_last=True) eval_loss = 0.0 model.eval() for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Val')): text, bert_prob, real_label = to_device(text, bert_prob, real_label) output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) eval_loss += loss.item() return eval_loss / len(data_loader)
إذا تم تجميع كل هذا ، فسوف نحصل على الكود التالي لتدريب النموذج:
import os import torch from torch.utils.data import (TensorDataset, random_split, RandomSampler, DataLoader, SequentialSampler) from torchtext import data from tqdm import tqdm def device(): return torch.device("cuda" if torch.cuda.is_available() else "cpu") def to_device(text, bert_prob, real_label): text = text.to(device()) bert_prob = bert_prob.to(device()) real_label = real_label.to(device()) return text, bert_prob, real_label class LSTMBaseline(object): vocab_name = 'text_vocab.pt' weights_name = 'simple_lstm.pt' def __init__(self, settings): self.settings = settings self.criterion = torch.nn.BCEWithLogitsLoss().to(device()) def loss(self, output, bert_prob, real_label): return self.criterion(output, real_label.float()) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=1, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings['train_batch_size']) return model def train(self, X, y, y_real, output_dir): max_len = self.settings['max_seq_length'] text_field = get_vocab(X) X_split = [t.split() for t in X] X_pad = [pad(s, max_len) for s in tqdm(X_split, desc='pad')] X_index = [to_indexes(text_field.vocab, s) for s in tqdm(X_pad, desc='to index')] dataset = to_dataset(X_index, y, y_real) val_len = int(len(dataset) * 0.1) train_dataset, val_dataset = random_split(dataset, (len(dataset) - val_len, val_len)) model = self.model(text_field) model.to(device()) self.full_train(model, train_dataset, val_dataset, output_dir) torch.save(text_field, os.path.join(output_dir, self.vocab_name)) def full_train(self, model, train_dataset, val_dataset, output_dir): train_settings = self.settings num_train_epochs = train_settings['num_train_epochs'] best_eval_loss = 100000 for epoch in range(num_train_epochs): train_loss = epoch_train_func(model, train_dataset, self.loss, self.settings['train_batch_size']) eval_loss = epoch_evaluate_func(model, val_dataset, self.loss, self.settings['eval_batch_size']) if eval_loss < best_eval_loss: best_eval_loss = eval_loss torch.save(model.state_dict(), os.path.join(output_dir, self.weights_name))
التقطير
فكرة طريقة التقطير هذه مأخوذة من مقال لباحثين من جامعة واترلو . كما قلت أعلاه ، يجب أن يتعلم "الطالب" تقليد سلوك "المعلم". ما هو بالضبط السلوك؟ في حالتنا ، هذه هي تنبؤات نموذج المعلم في مجموعة التدريب. والفكرة الأساسية هي استخدام إخراج الشبكة قبل تطبيق وظيفة التنشيط. من المفترض أنه بهذه الطريقة سيكون النموذج قادراً على تعلم التمثيل الداخلي بشكل أفضل من حالة الاحتمالات النهائية.
تقترح المقالة الأصلية إضافة مصطلح إلى وظيفة الخسارة ، والتي ستكون مسؤولة عن الخطأ "التقليد" - MSE بين سجلات النماذج.

لهذه الأغراض ، نجري تغييرين صغيرين: تغيير عدد مخرجات الشبكة من 1 إلى 2 وتصحيح وظيفة الخسارة.
def loss(self, output, bert_prob, real_label): a = 0.5 criterion_mse = torch.nn.MSELoss() criterion_ce = torch.nn.CrossEntropyLoss() return a*criterion_ce(output, real_label) + (1-a)*criterion_mse(output, bert_prob)
يمكنك إعادة استخدام كل الشفرة التي كتبناها عن طريق إعادة تعريف النموذج والخسارة فقط:
class LSTMDistilled(LSTMBaseline): vocab_name = 'distil_text_vocab.pt' weights_name = 'distil_lstm.pt' def __init__(self, settings): super(LSTMDistilled, self).__init__(settings) self.criterion_mse = torch.nn.MSELoss() self.criterion_ce = torch.nn.CrossEntropyLoss() self.a = 0.5 def loss(self, output, bert_prob, real_label): return self.a * self.criterion_ce(output, real_label) + (1 - self.a) * self.criterion_mse(output, bert_prob) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=2, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings['train_batch_size']) return model
هذا كل شيء ، الآن نموذجنا يتعلم "تقليد".
مقارنة النموذج
في المقالة الأصلية ، يتم الحصول على أفضل نتائج لتصنيف SST-2 عند 0 = ، عندما يتعلم النموذج فقط تقليدها ، دون مراعاة العلامات الحقيقية. لا تزال الدقة أقل من BERT ، ولكنها أفضل بكثير من BiLSTM العادية.

حاولت تكرار نتائج المقال ، ولكن في تجاربي ، تم الحصول على أفضل نتيجة عند 0.5 =.
هذه هي الطريقة التي تبدو بها الرسوم البيانية للخسارة والدقة عند تعلم LSTM بالطريقة المعتادة. بالحكم على سلوك الخسارة ، فإن النموذج تعلم بسرعة ، وفي مكان ما بعد الحقبة السادسة ، بدأ إعادة التدريب.
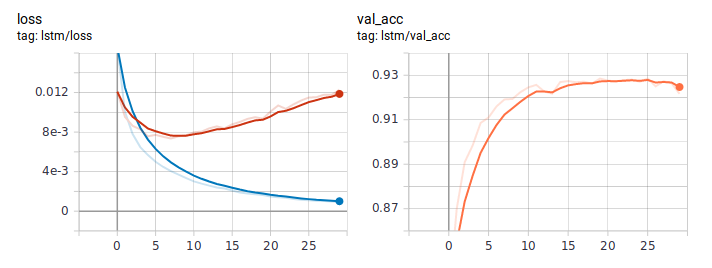
الرسوم البيانية تقطير:
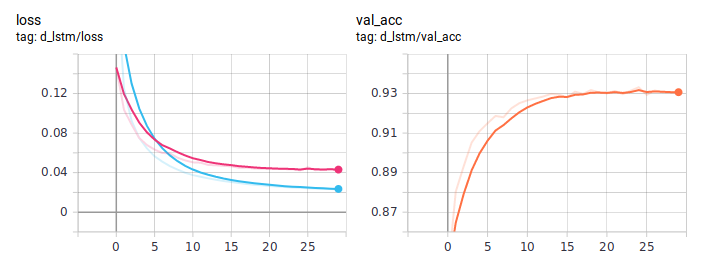
BiLSTM المقطر هو أفضل باستمرار من المعتاد. من المهم أن تكون متطابقة تماما في الهندسة المعمارية ، والفرق الوحيد هو في طريقة التدريس. لقد نشرت رمز التدريب الكامل على جيثب .
استنتاج
في هذا الدليل ، حاولت أن أشرح الفكرة الأساسية لنهج التقطير. تعتمد البنية المحددة للطالب على المهمة التي في متناول اليد. ولكن بشكل عام ، هذا النهج قابل للتطبيق في أي مهمة عملية. بسبب التعقيد في مرحلة التدريب النموذجي ، يمكنك الحصول على زيادة كبيرة في جودته ، مع الحفاظ على البساطة الأصلية للهندسة المعمارية.