سننظر في كيفية عمل Zabbix مع قاعدة بيانات TimescaleDB كواجهة خلفية. نعرض كيفية البدء من نقطة الصفر وكيفية الترحيل باستخدام PostgreSQL. نقدم أيضًا اختبارات أداء مقارنة للتكوينين.

HighLoad ++ سيبيريا 2019. قاعة تومسك. 24 يونيو ، 16:00. الملخصات
والعرض التقديمي . سيعقد مؤتمر HighLoad ++ التالي في 6 و 7 أبريل 2020 في سان بطرسبرغ. التفاصيل والتذاكر
هنا .
Andrey Gushchin (يشار إليه
فيما يلي باسم
AG): - أنا مهندس دعم فني من ZABBIX (يشار إليه فيما يلي باسم Zabbix) ، مدرب. لقد عملت في الدعم الفني لأكثر من 6 سنوات ، وقد واجهت الأداء بشكل مباشر. سأتحدث اليوم عن الأداء الذي يمكن أن يقدمه TimescaleDB عند مقارنته بـ PostgreSQL 10. أيضًا ، بعض الأجزاء التمهيدية - حول كيفية عمله.
تحديات الأداء الرئيسية: من المجموعة إلى تطهير البيانات
بادئ ذي بدء ، هناك بعض تحديات الأداء التي يواجهها كل نظام مراقبة. يتمثل التحدي الأول في الأداء في الجمع السريع للبيانات ومعالجتها.

يجب على نظام مراقبة جيد استلام جميع البيانات على الفور وفي الوقت المناسب ، ومعالجتها وفقًا لتعبيرات المشغل ، أي معالجتها وفقًا لبعض المعايير (هذا يختلف في الأنظمة المختلفة) وحفظه في قاعدة البيانات لاستخدام هذه البيانات في المستقبل.

التحدي الثاني في الأداء هو الحفاظ على التاريخ. تخزينها في قاعدة البيانات في كثير من الأحيان ، والوصول السريع والسهل إلى هذه المقاييس التي تم جمعها على مدى فترة من الزمن. الشيء الأكثر أهمية هو أنه من المناسب الحصول على هذه البيانات ، واستخدامها في التقارير ، والرسوم البيانية ، والمشغلات ، في بعض القيم ، للتنبيهات ، إلخ.

يتمثل التحدي الثالث في الأداء في مسح القصة ، أي عندما يكون يومك لا تحتاج إلى تخزين أي مقاييس مفصلة تم جمعها على مدار 5 سنوات (حتى أشهر أو شهرين). تم حذف بعض عقد الشبكة ، أو لم تعد هناك حاجة لبعض المقاييس ، لأنها عفا عليها الزمن ولم تعد مجمعة. كل هذا يحتاج إلى تنظيف بحيث لا تنمو قاعدة البيانات الخاصة بك إلى حجم كبير. بشكل عام ، يعد مسح السجل غالبًا اختبارًا جادًا للتخزين - وغالبًا ما يؤثر على الأداء.
كيفية حل مشاكل التخزين المؤقت؟
سأتحدث الآن بالتحديد عن Zabbix. في Zabbix ، يتم حل المكالمات الأولى والثانية باستخدام التخزين المؤقت.

جمع ومعالجة البيانات - نستخدم ذاكرة الوصول العشوائي لتخزين كل هذه البيانات. الآن ستتم مناقشة هذه البيانات بمزيد من التفاصيل.
يوجد أيضًا على جانب قاعدة البيانات تخزين مؤقت معين للعينات الرئيسية - للرسوم البيانية وأشياء أخرى.
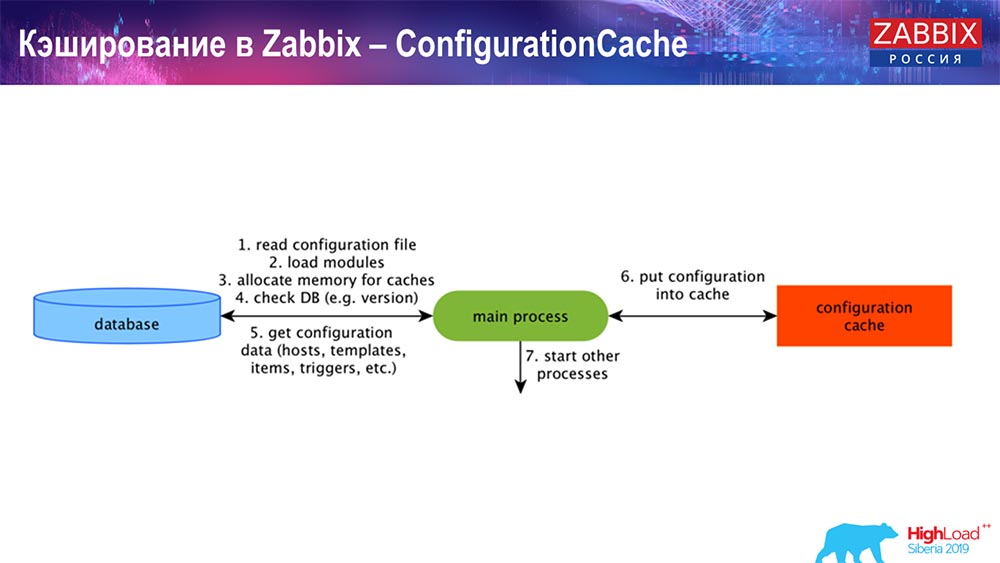
التخزين المؤقت على جانب خادم Zabbix نفسه: لدينا ConfigurationCache و ValueCache و HistoryCache و TrendsCache. ما هذا

ConfigurationCache هو ذاكرة التخزين المؤقت الرئيسية التي نخزن فيها المقاييس والمضيفات وعناصر البيانات والمشغلات. كل ما تحتاجه لمعالجة المعالجة المسبقة ، وجمع البيانات ، والتي يستضيفها التجميع ، مع أي تردد. يتم تخزين كل هذا في ConfigurationCache ، حتى لا تذهب إلى قاعدة البيانات ، وليس لإنشاء طلبات غير ضرورية. بعد بدء تشغيل الخادم ، نقوم بتحديث ذاكرة التخزين المؤقت هذه (إنشاء) وتحديثها بشكل دوري (حسب إعدادات التكوين).
التخزين المؤقت في Zabbix. جمع البيانات
هنا المخطط كبير جدًا:

أهمها في المخطط هؤلاء هواة الجمع:
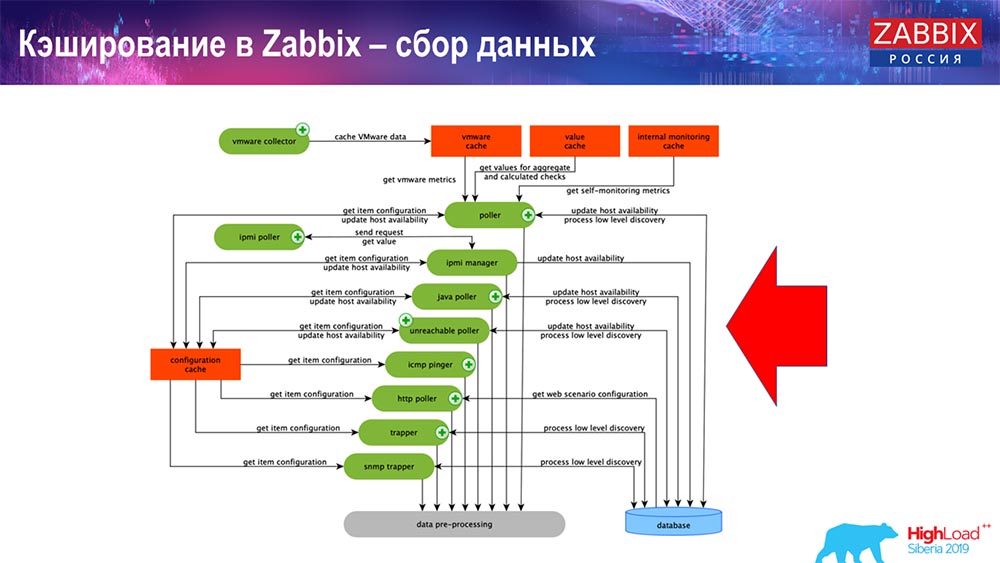
هذه هي عمليات التجميع بأنفسهم ، مختلف "المستطلعين" المسؤولين عن أنواع مختلفة من الجمعيات. يقومون بجمع البيانات عبر icmp و ipmi وفقًا لبروتوكولات مختلفة ونقلها جميعًا إلى المعالجة المسبقة.
قبل تجهيز HistoryCache
أيضًا ، إذا قمنا بحساب عناصر البيانات (من يعرف Zabbix - يعرف) ، أي عناصر البيانات المحسوبة المجمعة ، فنحن نأخذها مباشرةً من ValueCache. حول كيفية شغلها ، سأقول لاحقًا. يستخدم كل هؤلاء المجمعين ConfigurationCache للحصول على وظائفهم ثم نقلها إلى المعالجة المسبقة.
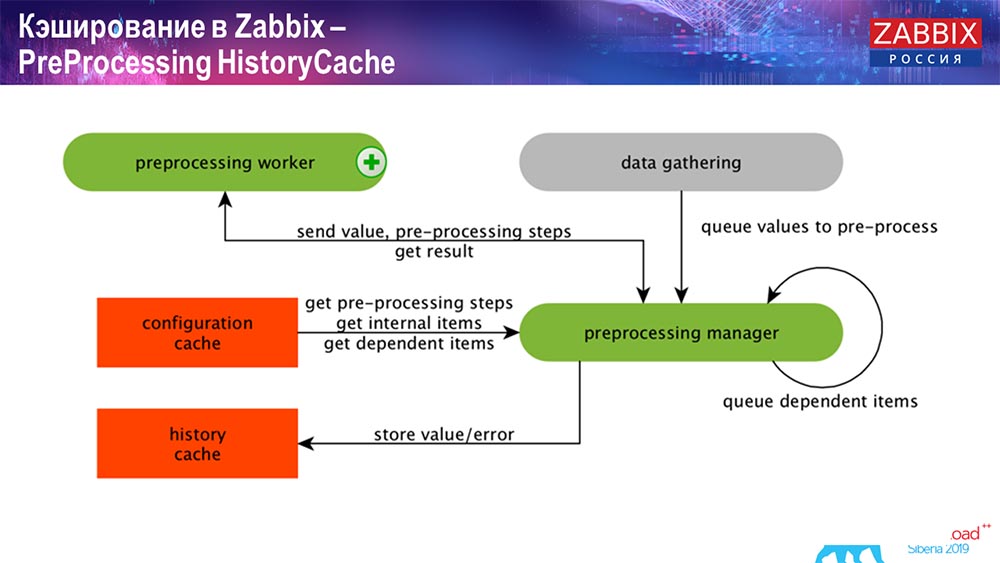
تستخدم المعالجة المسبقة أيضًا ConfigurationCache للحصول على خطوات المعالجة المسبقة ؛ حيث تقوم بمعالجة هذه البيانات بطرق مختلفة. بدءًا من الإصدار 4.2 ، أرسلناه إلى الوكيل. هذا أمر مريح للغاية ، لأن تجهيز نفسه عملية صعبة إلى حد ما. وإذا كان لديك "Zabbix" كبير جدًا ، مع وجود عدد كبير من عناصر البيانات وتيرة عالية من التجميع ، فهذا يسهل العمل إلى حد كبير.
وفقًا لذلك ، بعد أن قمنا بمعالجة هذه البيانات بطريقة ما باستخدام المعالجة المسبقة ، فإننا نقوم بحفظها في HistoryCache من أجل معالجتها بشكل أكبر. هذا ينتهي جمع البيانات. ننتقل إلى العملية الرئيسية.
عملية مزامنة التاريخ
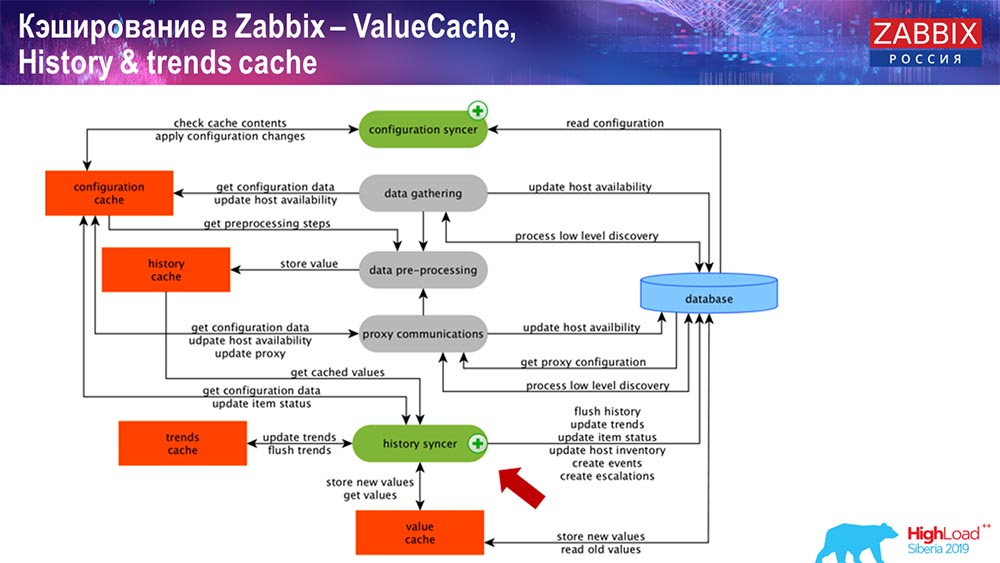
العملية الرئيسية في Zabbix (نظرًا لأنها بنية متجانسة) هي مزامنة التاريخ. هذه هي العملية الرئيسية التي تتناول بالتحديد المعالجة الذرية لكل عنصر من عناصر البيانات ، أي لكل قيمة:
- القيمة تأتي (يأخذها من HistoryCache) ؛
- يتحقق في تزامن التكوين: هل هناك أي مشغلات للحساب؟
إذا كان هناك ، فإنه ينشئ الأحداث ، يخلق تصعيدًا لإنشاء تنبيه ، إذا لزم الأمر من خلال التكوين ؛ - سجلات مشغلات للمعالجة اللاحقة ، التجميع ؛ إذا قمت بالتجميع في الساعة الأخيرة وهكذا ، فإن هذه القيمة تتذكر ValueCache ، حتى لا تذهب إلى جدول المحفوظات ؛ وبالتالي ، يتم تعبئة ValueCache بالبيانات الضرورية اللازمة لحساب المشغلات والعناصر المحتسبة وما إلى ذلك.
- ثم يكتب سجل المزامنة جميع البيانات في قاعدة البيانات ؛
- تكتبهم قاعدة البيانات إلى القرص - حيث تنتهي عملية المعالجة.
قواعد البيانات. التخزين المؤقت
على الجانب DB ، عندما تريد إلقاء نظرة على المخططات أو بعض تقارير الأحداث ، فهناك العديد من ذاكرات التخزين المؤقت. لكن كجزء من هذا التقرير ، لن أتحدث عنهم.
بالنسبة لـ MySQL ، يوجد Innodb_buffer_pool ، مجموعة من ذاكرات التخزين المؤقت المختلفة التي يمكن تهيئتها أيضًا.
ولكن هذه هي أهمها:
- shared_buffers.
- effective_cache_size.
- shared_pool.

لقد ذكرت لجميع قواعد البيانات أن هناك بعض ذاكرات التخزين المؤقت التي تسمح لك أن تحتفظ في الذاكرة بالبيانات المطلوبة غالبًا للاستعلامات. هناك لديهم التقنيات الخاصة بهم لهذا الغرض.
حول أداء قاعدة البيانات
وفقًا لذلك ، هناك بيئة تنافسية ، أي أن خادم Zabbix يجمع البيانات ويسجلها. عند إعادة التشغيل ، يقرأ أيضًا من السجل لملء ValueCache وما إلى ذلك. هنا يمكنك الحصول على البرامج النصية والتقارير التي تستخدم Zabbix-API ، والتي بنيت على أساس واجهة الويب. يتم تضمين "Zabbiks" -API في قاعدة البيانات ويتلقى البيانات اللازمة للحصول على الرسوم البيانية والتقارير أو بعض الأحداث القائمة ، والمشاكل الأخيرة.

أيضا حل التصور الشائع جدا هو Grafana ، والذي يستخدمه مستخدمونا. قادرة على إدخال مباشرة سواء من خلال "Zabbiks" -API ، ومن خلال قاعدة البيانات. كما أنه يخلق منافسة معينة للحصول على البيانات: هناك حاجة إلى ضبط أفضل وأكثر دقة لقاعدة البيانات لتتوافق مع سرعة تسليم النتائج والاختبار.

مسح التاريخ. Zabbix ديه مدبرة منزل
التحدي الثالث الذي تستخدمه Zabbix هو مسح القصة مع مدبرة منزل. يتوافق Hauskiper مع جميع الإعدادات ، أي في عناصر البيانات الخاصة بنا ، يُشار إلى مقدار التخزين (بالأيام) ، وكمية تخزين الاتجاهات ، وديناميات التغييرات.
لم أتحدث عن TrendCache ، التي نقوم بحسابها على الفور: وصول البيانات ، نقوم بتجميعها في ساعة واحدة (أساسًا أن هذه أرقام في الساعة الأخيرة) ، والمبلغ متوسط / الحد الأدنى ، ثم اكتبه مرة واحدة في الساعة في جدول التغييرات في الديناميات (الاتجاهات) . يقوم Hauskiper ببدء وحذف البيانات من قاعدة البيانات باستخدام تحديدات منتظمة ، وهي ليست فعالة دائمًا.
كيف نفهم أنه غير فعال؟ يمكنك رؤية الصورة التالية على الرسوم البيانية لأداء العمليات الداخلية:
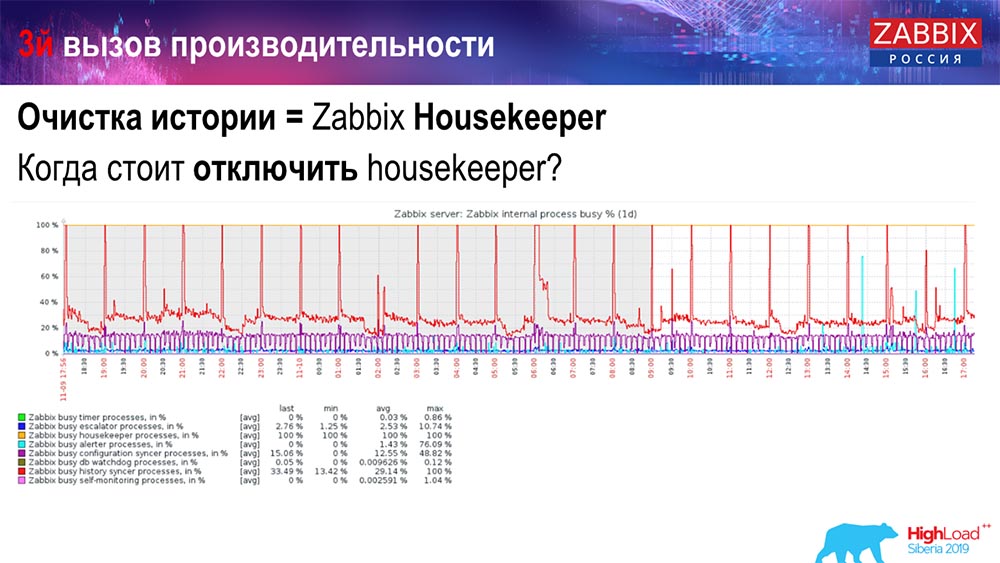
مزامنة السجل مشغول باستمرار (الرسم البياني الأحمر). والرسم البياني "الأحمر" الذي يستمر في المقدمة. هذا هو Hauskiper ، الذي يبدأ وينتظر قاعدة البيانات عندما يحذف جميع الأسطر التي حددتها.
تأخذ بعض معرف العنصر: تحتاج إلى حذف آخر 5 آلاف ؛ بالطبع ، من خلال المؤشرات. ولكن عادةً ما تكون مجموعة البيانات كبيرة بما يكفي - فما زالت قاعدة البيانات تقرأ هذا من القرص وترفعه إلى ذاكرة التخزين المؤقت ، وهذه عملية مكلفة للغاية لقاعدة البيانات. اعتمادًا على حجمها ، يمكن أن يؤدي ذلك إلى بعض مشكلات الأداء.
يمكنك تعطيل Hauskiper بطريقة بسيطة - لدينا واجهة ويب مألوفة للجميع. الإعداد في الإدارة العامة (إعدادات "مدبرة المنزل") نقوم بتعطيل التدبير المنزلي الداخلي للتاريخ والاتجاهات الداخلية. وفقًا لذلك ، لم يعد Hauskiper يتحكم في هذا:

ماذا يمكنني أن أفعل بعد ذلك؟ لقد قطعت اتصالك ، وزادت جداولك ... ما هي المشاكل التي يمكن أن تكون أكثر في هذه الحالة؟ ما يمكن أن تساعد؟
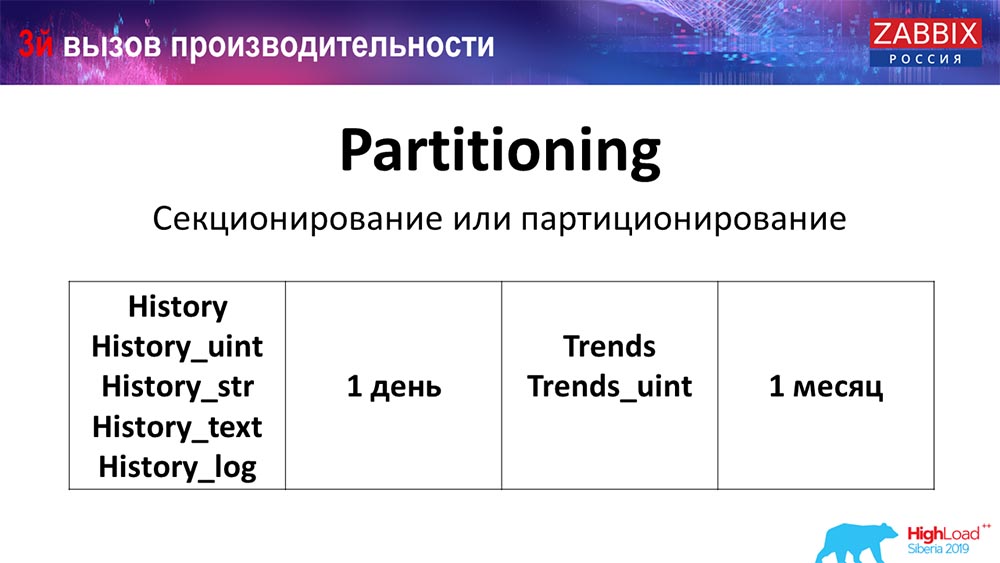
التقسيم (التقسيم)
يتم تكوين هذا عادةً على كل قاعدة بيانات علائقية أدرجتها بطريقة مختلفة. الخلية لديها التكنولوجيا الخاصة بها. لكن بشكل عام ، تكون متشابهة جدًا عندما يتعلق الأمر بـ PostgreSQL 10 و MySQL. بالطبع ، هناك الكثير من الاختلافات الداخلية في كيفية تنفيذها كلها وكيف تؤثر جميعها على الأداء. ولكن بشكل عام ، غالباً ما يؤدي إنشاء قسم جديد إلى بعض المشكلات.

بناءً على الإعداد الخاص بك (مقدار البيانات التي تنشئها في يوم واحد) ، فإنها عادة ما تحدد الحد الأدنى ليوم واحد / قسم ، وبالنسبة لـ "الاتجاهات" ، ديناميات التغييرات - شهر واحد / قسم جديد. قد يتغير هذا إذا كان لديك إعداد كبير جدًا.
دعنا نقول على الفور عن حجم الإعداد: ما يصل إلى 5 آلاف القيم الجديدة في الثانية (ما يسمى nvps) - سوف يعتبر هذا "الإعداد" صغير. المتوسط - من 5 إلى 25 ألف قيمة في الثانية. كل ما سبق هو بالفعل عمليات تثبيت كبيرة وكبيرة جدًا تتطلب تكوينًا دقيقًا جدًا لقاعدة البيانات نفسها.
في المنشآت الكبيرة جدًا ، يوم واحد - قد لا يكون هذا هو الأمثل. رأيت شخصيا على أقسام MySQL من 40 غيغابايت في اليوم (وربما يكون هناك المزيد). هذا هو كمية كبيرة جدا من البيانات ، والتي يمكن أن تؤدي إلى بعض المشاكل. يجب تخفيضه.
لماذا التقسيم؟
ما يقدمه التقسيم ، أعتقد أن الجميع يعلم ، هو تقسيم الجدول. غالبًا ما تكون هذه ملفات منفصلة على القرص وطلبات الامتداد. إنه أكثر اختيارًا لقسم واحد ، إذا كان هذا جزءًا من القسم المعتاد.
بالنسبة إلى Zabbix ، على وجه الخصوص ، يتم استخدامه حسب النطاق ، حسب النطاق ، أي أننا نستخدم طابعًا زمنيًا (الرقم عادي ، والوقت من بداية العصر). يمكنك تحديد بداية اليوم / نهاية اليوم ، وهذا قسم. وفقًا لذلك ، إذا كنت تقدم طلبًا للبيانات قبل يومين ، فسيتم تحديد كل ذلك من قاعدة البيانات بشكل أسرع ، لأنك تحتاج فقط إلى تحميل ملف واحد إلى ذاكرة التخزين المؤقت والمشكلة (بدلاً من جدول كبير).

العديد من قواعد البيانات أيضا تسريع الإدراج (الإدراج في جدول تابع واحد). بينما أتحدث بشكل تجريدي ، إلا أنه ممكن أيضًا. Partitoning غالبا ما يساعد.
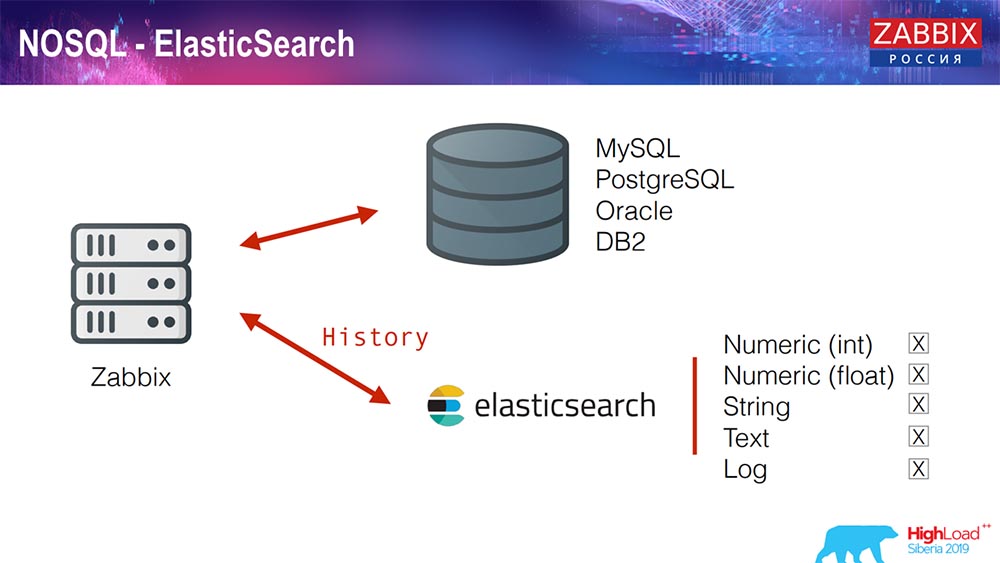
Elasticsearch ل NoSQL
في الآونة الأخيرة ، في 3.4 ، قمنا بتنفيذ حل ل NoSQL. وأضاف القدرة على الكتابة في Elasticsearch. يمكنك كتابة بعض الأنواع المنفصلة: اختر - إما كتابة الأرقام أو بعض العلامات ؛ لدينا نص السلسلة ، يمكنك كتابة سجلات في Elasticsearch ... وفقا لذلك ، فإن واجهة الويب أيضا الوصول إلى Elasticsearch. يعمل هذا بشكل جيد في بعض الحالات ، ولكن في الوقت الحالي يمكن استخدامه.
TimescaleDB. Gipertablitsy
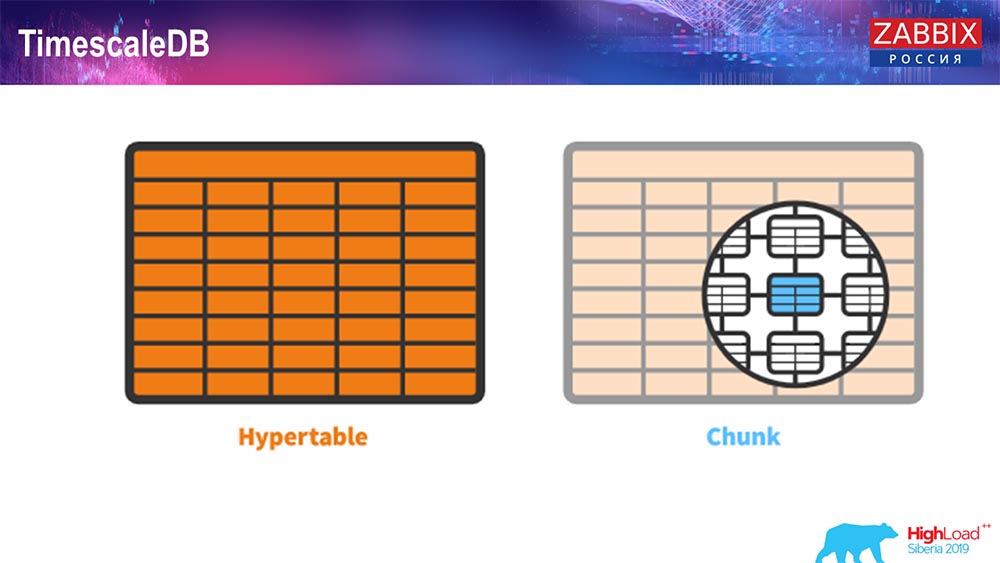
بالنسبة إلى الإصدار 4.4.2 ، لاحظنا شيئًا واحدًا مثل TimescaleDB. ما هذا هذا امتداد لـ Postgres ، أي أنه يحتوي على واجهة PostgreSQL أصلية. بالإضافة إلى ذلك ، يتيح لك هذا الامتداد العمل مع بيانات الجداول الزمنية بكفاءة أكبر وتقسيم تلقائي. كيف تبدو؟

هذا هو hypertable - هناك مثل هذا المفهوم في Timescale. هذا هو hypertable التي تنشئها ، ويحتوي على قطع. المقاطع عبارة عن أقسام ، فهذه جداول فرعية ، إذا لم أكن مخطئًا. انها فعالة حقا.
TimescaleDB و PostgreSQL
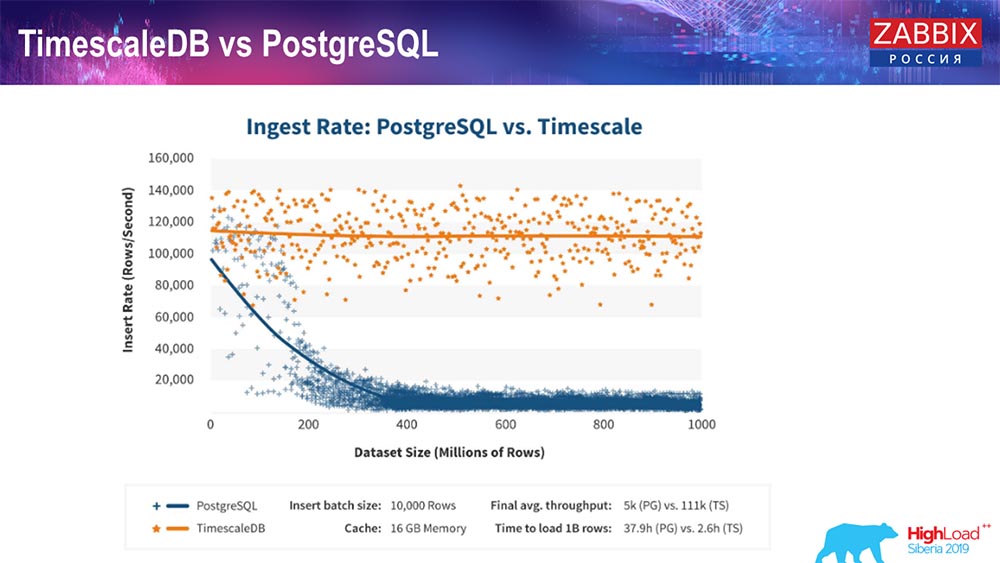
كما يؤكد مصنعو TimescaleDB ، يستخدمون خوارزمية معالجة طلب أكثر دقة ، خاصة insert'ov ، مما يتيح لك الحصول على أداء ثابت تقريبًا مع زيادة حجم إدراج مجموعة البيانات. وهذا يعني أنه بعد 200 مليون سطر من "Postgres" ، يبدأ الخط المعتاد في التراجع ويفقد الأداء حرفيًا إلى الصفر ، في حين أن "Timescale" يسمح لك بإدراج إدراج بأكبر قدر ممكن من الكفاءة مع أي كمية من البيانات.
كيفية تثبيت TimescaleDB؟ كل شيء بسيط!
لديه في الوثائق ، وهو موصوف - يمكن تسليمها من الحزم لأي ... يعتمد على الحزم الرسمية ل Postgres. ويمكن تجميعها يدويا. لقد حدث أن اضطررت إلى ترجمة لقاعدة البيانات.
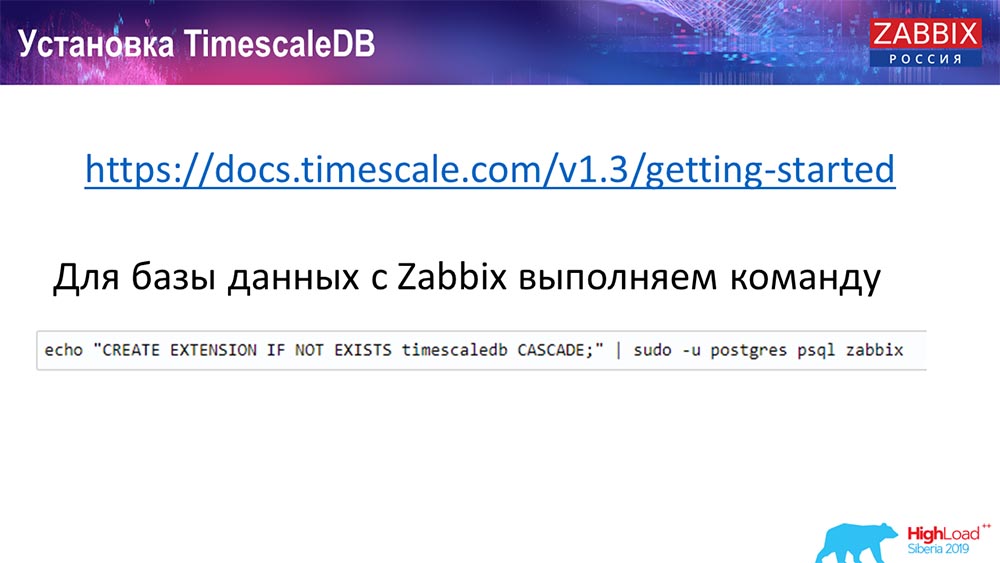
في Zabbix ، نقوم فقط بتنشيط Extention. أعتقد أن أولئك الذين استخدموا Extention في Postgres ... أنت فقط تقوم بتنشيط Extention ، قم بإنشائه لقاعدة بيانات Zabbix التي تستخدمها.
والخطوة الأخيرة ...
TimescaleDB. جداول محفوظات الترحيل
تحتاج إلى إنشاء hypertable. هناك وظيفة خاصة لهذا - إنشاء hypertable. في ذلك ، تشير المعلمة الأولى إلى الجدول المطلوب في قاعدة البيانات هذه (التي تحتاج إلى إنشاء hypertable).

الحقل الذي تريد إنشاءه ، و chunk_time_interval (هذا هو الفاصل الزمني للأجزاء (الأقسام التي سيتم استخدامها). 86،400 هي يوم واحد.
Parameter migrate_data: إذا قمت بإدراج true ، فسيؤدي ذلك إلى نقل جميع البيانات الحالية إلى مجموعات تم إنشاؤها مسبقًا.
أنا نفسي استخدم migrate_data - يستغرق وقتًا لا بأس به ، وهذا يتوقف على حجم قاعدة البيانات الخاصة بك. كان لدي أكثر من تيرابايت - استغرق الخلق أكثر من ساعة. في بعض الحالات ، عند الاختبار ، قمت بحذف البيانات التاريخية للنص (history_text) والسلسلة (history_str) ، حتى لا أقوم بنقلها - لم تكن مثيرة للاهتمام بالنسبة لي.
وننفذ التحديث الأخير في db_extention الخاص بنا: لقد قمنا بتعيين timescaledb بحيث تفهم قاعدة البيانات ، وعلى وجه الخصوص Zabbix لدينا ، ما db_extention. يقوم بتنشيطه ويستخدم بناء الجملة الصحيح واستعلامات قاعدة البيانات ، وذلك باستخدام "الميزات" الضرورية لـ TimescaleDB.
تكوين الخادم
اعتدت خادمين. الخادم الأول عبارة عن جهاز افتراضي صغير بدرجة كافية ، و 20 معالجات ، و 16 غيغابايت من ذاكرة الوصول العشوائي. قم بإعداد Postgres 10.8 عليه:

نظام التشغيل هو دبيان ، نظام الملفات هو xfs. لقد قمت بإعداد الحد الأدنى من الإعدادات لاستخدام قاعدة البيانات هذه ، ناقصًا ما ستستخدمه Zabbix. على نفس الجهاز ، كان خادم Zabbix و PostgreSQL ووكلاء التحميل.

لقد استخدمت 50 وكيلًا نشطًا يستخدمون LoadableModule لإنشاء نتائج متنوعة بسرعة. لقد قاموا بإنشاء خطوط وأرقام وما إلى ذلك. أنا انسداد DB مع الكثير من البيانات. في البداية ، تضمن التكوين 5 آلاف عنصر بيانات لكل مضيف ، واحتوى كل عنصر بيانات تقريبًا على مشغل - بحيث كان إعدادًا حقيقيًا. في بعض الأحيان ، يتطلب الأمر أكثر من مشغل واحد.

قمت بتنظيم الفاصل الزمني للتحديث ، التحميل نفسه حتى لا أستخدم فقط 50 وكيلًا (إضافة المزيد) ، ولكن أيضًا استخدام عناصر البيانات الديناميكية وخفض الفاصل الزمني للتحديث إلى 4 ثوانٍ.
اختبار الأداء. PostgreSQL: 36 ألف NVPs
الإطلاق الأول ، الإعداد الأول الذي أجريته على PostreSQL 10 الخالص على هذا الجهاز (35 ألف قيمة في الثانية). بشكل عام ، كما ترى على الشاشة ، يأخذ إدخال البيانات كسور في الثانية - كل شيء على ما يرام وسريع ، محركات أقراص الحالة الصلبة (200 غيغابايت). الشيء الوحيد هو أن 20 جيجابايت بسرعة ملء.
سيكون هناك العديد من هذه الرسوم البيانية. هذه هي لوحة القيادة القياسية للأداء لخادم Zabbix.
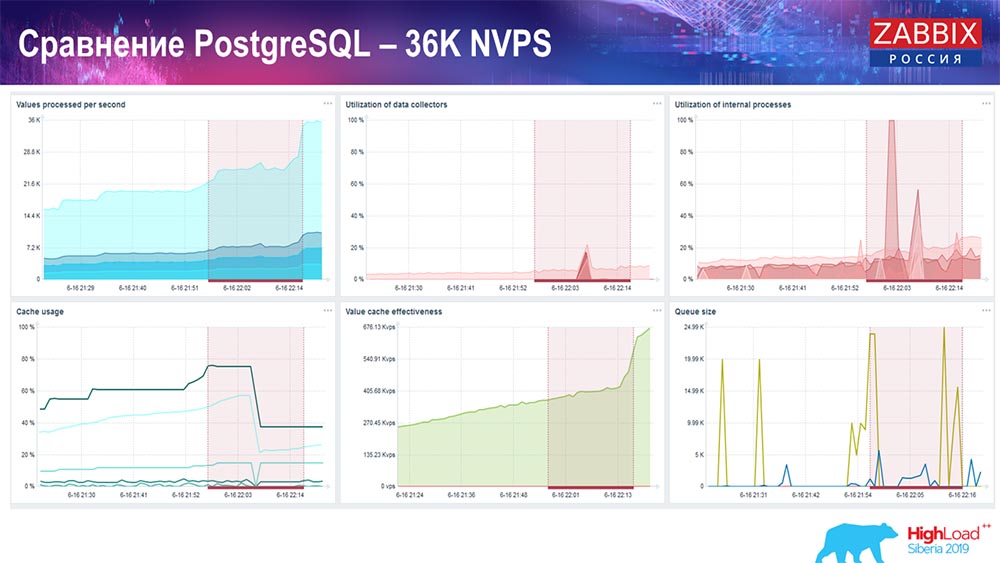
الرسم البياني الأول هو عدد القيم في الثانية (أزرق ، أعلى اليسار) ، 35 ألف قيمة في هذه الحالة. هذا (مركز التحميل) هو عملية التحميل لعمليات التجميع ، وهذا (الجزء العلوي الأيمن) يتم تحميل العمليات الداخلية: مزامنة التاريخ ومدبرة المنزل ، والتي تم تشغيلها هنا لفترة كافية.
يوضح هذا الرسم البياني (الوسط السفلي) استخدام ValueCache - عدد مرات دخول ValueCache للمشغلات (عدة آلاف من القيم في الثانية الواحدة). الرسم البياني المهم الآخر هو الرسم الرابع (أسفل اليسار) ، والذي يوضح استخدام HistoryCache ، التي تحدثت عنها ، وهو مخزن مؤقت قبل الإدراج في قاعدة البيانات.
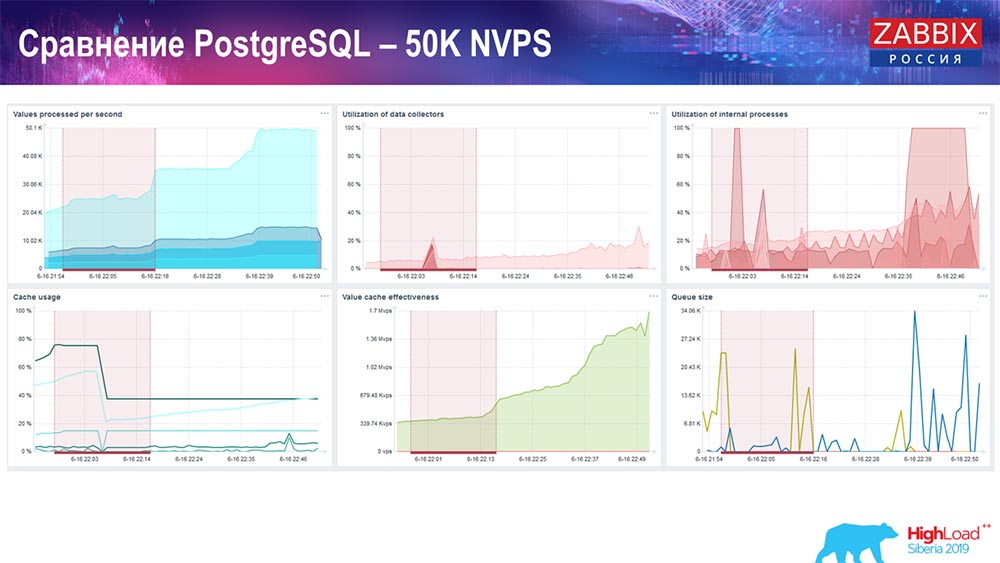
اختبار الأداء. PostgreSQL: 50 ألف NVPs
بعد ذلك ، قمت بزيادة الحمل إلى 50 ألف قيمة في الثانية على نفس الجهاز. عند التحميل باستخدام Hauskiper ، تم تسجيل 10 آلاف قيمة بالفعل في 2-3 ثوانٍ مع الحساب. الذي ، في الواقع ، يظهر في لقطة الشاشة التالية:
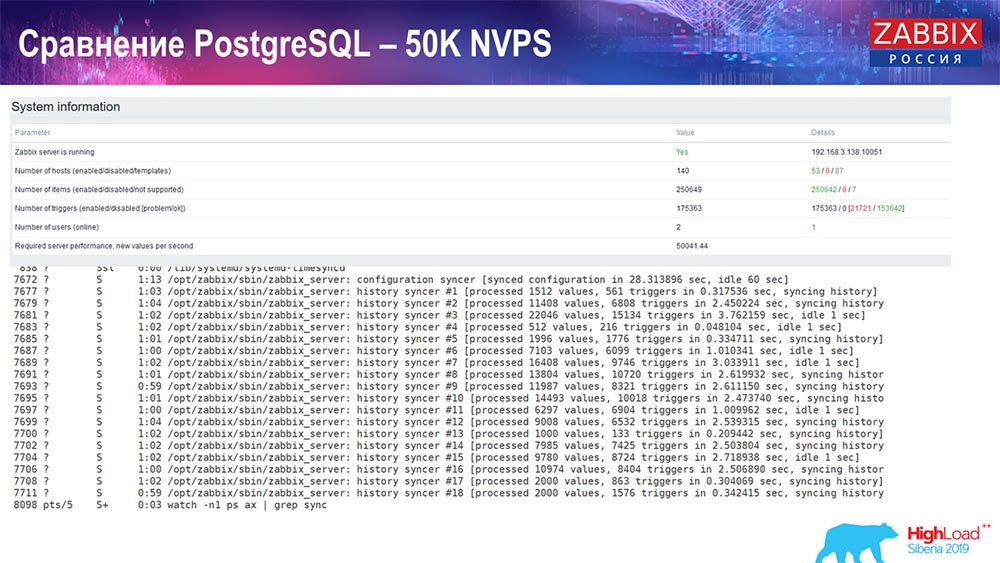
بدأت Hauskiper بالفعل في التدخل في العمل ، ولكن بشكل عام ، لا يزال تحميل الصيادون في غرق التاريخ عند 60٪ (المخطط الثالث ، أعلى اليمين). HistoryCache بالفعل أثناء عمل "Hauskiper" يبدأ في ملء (أسفل اليسار) بنشاط. كان حوالي نصف غيغابايت ، شغل في 20 ٪.
اختبار الأداء. PostgreSQL: 80 ألف NVPs
زاد إلى 80 ألف قيمة في الثانية:
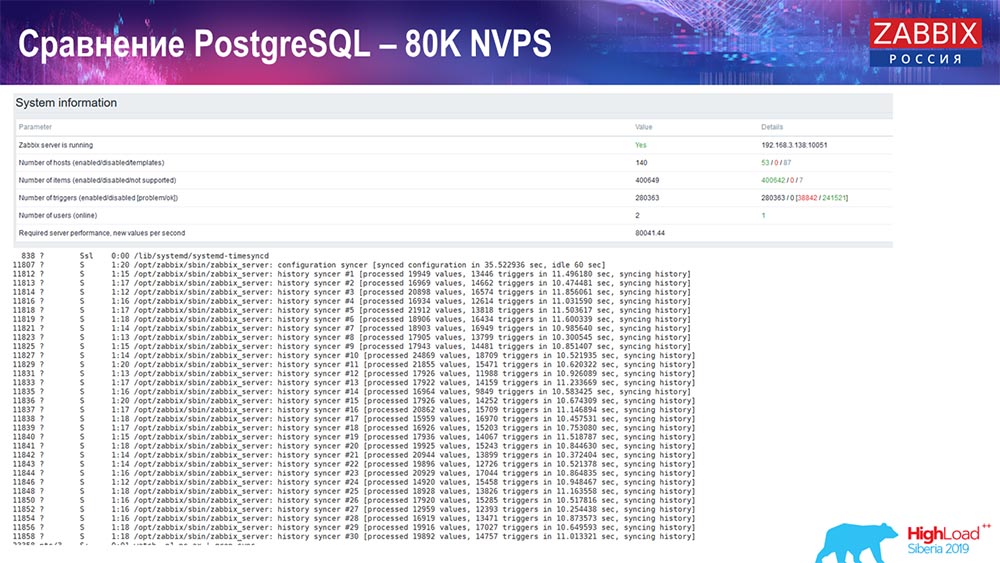
وكان ما يقرب من 400 ألف عنصر البيانات ، 280 ألف مشغلات. كان الملحق ، كما ترون ، لتحميل الغواصات التاريخية (كان هناك 30 منهم) مرتفعًا بالفعل. علاوةً على ذلك ، قمت بزيادة المعلمات المختلفة: غطاسات التاريخ ، وذاكرة التخزين المؤقت ... على هذا الجهاز ، بدأ تحميل غطاسات التاريخ في الزيادة إلى الحد الأقصى ، تقريبًا "إلى الرف" - وفقًا لذلك ، انتقلت HistoryCache إلى حمل كبير جدًا:
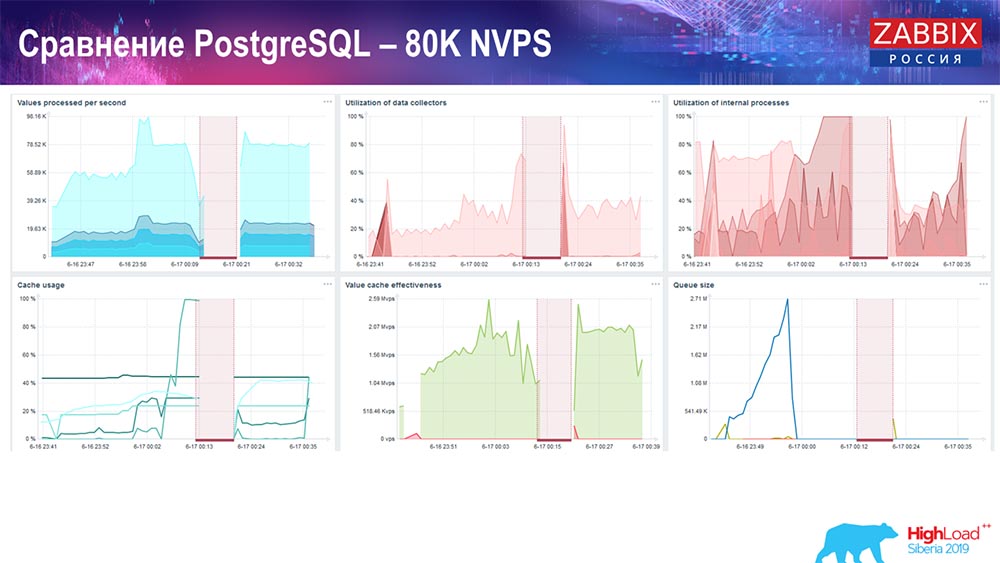
طوال هذا الوقت ، شاهدت جميع معلمات النظام (كيفية استخدام المعالج وذاكرة الوصول العشوائي) ووجدت أن استخدام القرص كان الحد الأقصى - لقد حققت أقصى سعة لهذا القرص على هذا الجهاز ، على هذا الجهاز الظاهري. بدأت "Postgres" بكثافة كبيرة لتفريغ البيانات بنشاط كبير ، ولم يعد القرص لديه وقت للكتابة ، وقراءة ...
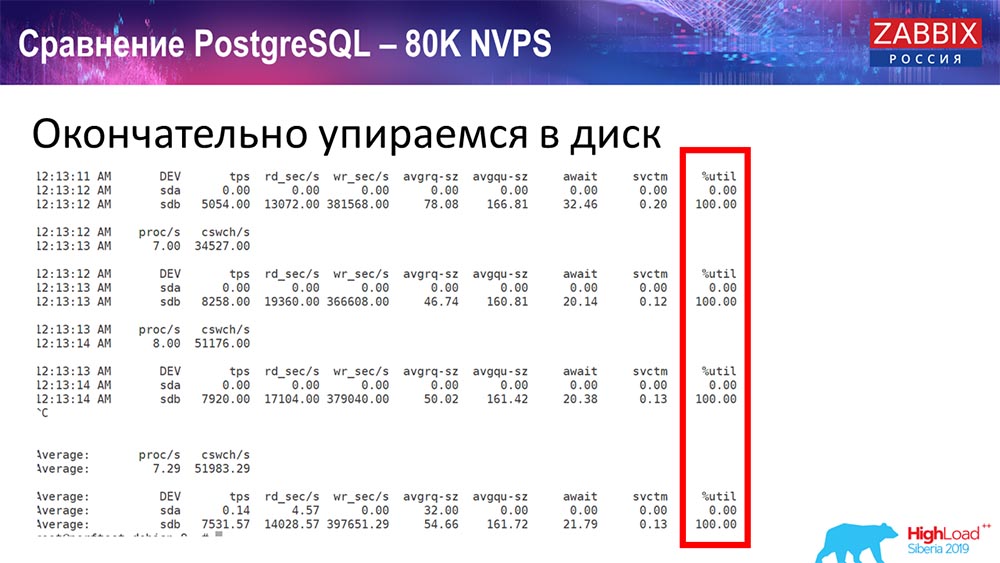
أخذت خادمًا آخر يحتوي بالفعل على 48 معالجًا مع 128 جيجابايت من ذاكرة الوصول العشوائي:
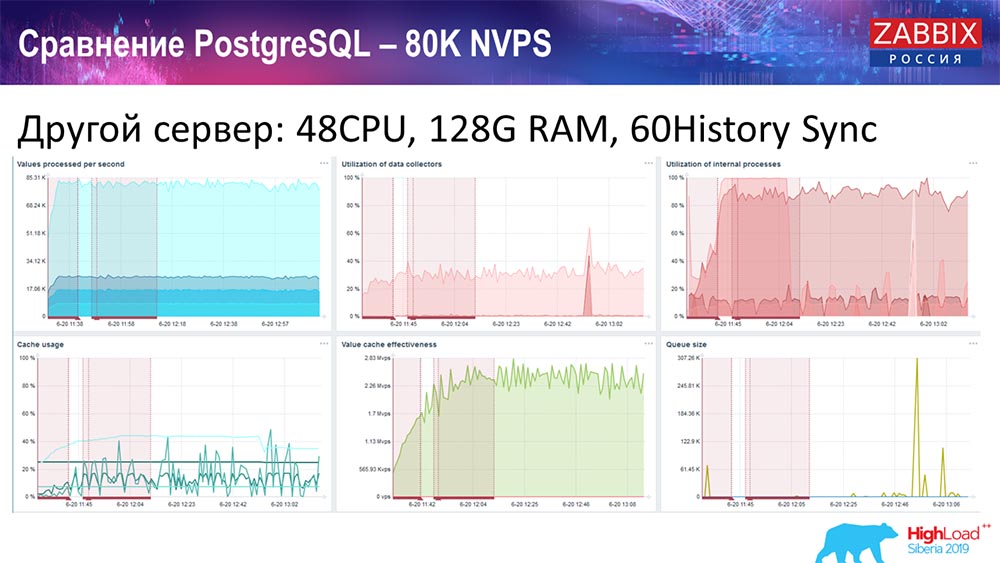
وأيضًا ، "شوهت" - قمت بتثبيت "مزامنة السجل" (60 قطعة) وحققت أداءً مقبولاً. في الواقع ، نحن لسنا "في الرف" ، ولكن ربما يكون هذا هو الحد الأقصى للإنتاجية ، حيث من الضروري بالفعل القيام بشيء حيال ذلك.
اختبار الأداء. TimescaleDB: 80 ألف NVPs
كانت مهمتي الرئيسية لاستخدام TimescaleDB. الفشل مرئي في كل مخطط:
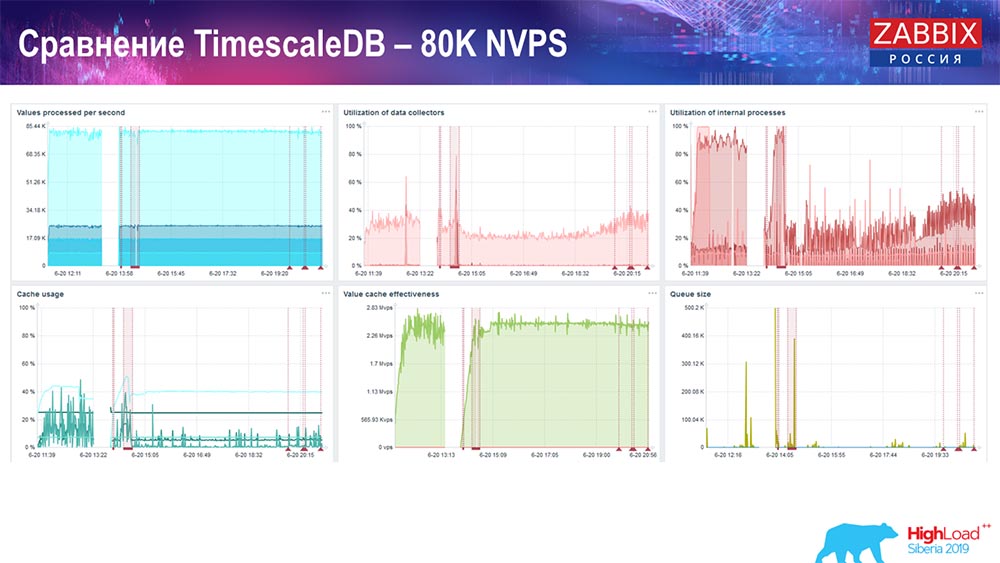
هذه الانخفاضات هي مجرد ترحيل البيانات. بعد ذلك ، في خادم "Zabbix" ، تغير الملف التعريفي لتحميل مستودعات التاريخ ، كما ترى ، كثيرًا.
إنه ما يقرب من 3 مرات أسرع مما يسمح لك بإدخال البيانات واستخدام أقل HistoryCache - وفقا لذلك ، سوف تتلقى البيانات في الوقت المناسب. مرة أخرى ، 80 ألف قيمة في الثانية الواحدة هي معدل مرتفع إلى حد ما (بالطبع ، ليس لياندكس). بشكل عام ، هذا إعداد كبير إلى حد ما ، مع خادم واحد.اختبار أداء PostgreSQL: 120 ألف NVPs
بعد ذلك ، قمت بزيادة قيمة عدد عناصر البيانات إلى نصف مليون وحصلت على القيمة المقدرة بـ 125 ألف في الثانية: وحصلت على هذه الرسوم البيانية: من
وحصلت على هذه الرسوم البيانية: من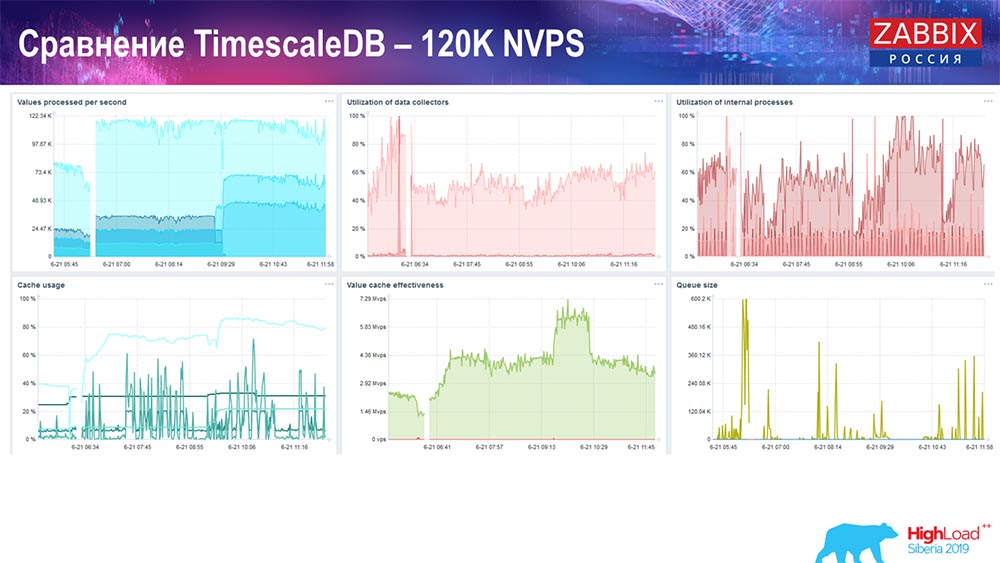 حيث المبدأ ، هذا إعداد عملي ، يمكن أن يعمل لفترة طويلة إلى حد ما. ولكن بما أن لدي 1.5 تيرابايت فقط من القرص ، فقد قضيت ذلك في غضون يومين. الأهم من ذلك ، في الوقت نفسه ، تم إنشاء أقسام TimescaleDB جديدة ، وهذا لم يلاحظه أحد تمامًا للأداء ، والذي لا يمكن قوله عن MySQL.عادة ما يتم إنشاء الأقسام في الليل ، لأنها تمنع الإدراج العام وتشغيل الجداول ، ويمكن أن تؤدي إلى تدهور الخدمة. في هذه الحالة ، هذا ليس كذلك! كانت المهمة الرئيسية لاختبار قدرات TimescaleDB. وكانت النتيجة مثل هذا الرقم: 120 ألف قيمة في الثانية.هناك أيضًا أمثلة في المجتمع:
حيث المبدأ ، هذا إعداد عملي ، يمكن أن يعمل لفترة طويلة إلى حد ما. ولكن بما أن لدي 1.5 تيرابايت فقط من القرص ، فقد قضيت ذلك في غضون يومين. الأهم من ذلك ، في الوقت نفسه ، تم إنشاء أقسام TimescaleDB جديدة ، وهذا لم يلاحظه أحد تمامًا للأداء ، والذي لا يمكن قوله عن MySQL.عادة ما يتم إنشاء الأقسام في الليل ، لأنها تمنع الإدراج العام وتشغيل الجداول ، ويمكن أن تؤدي إلى تدهور الخدمة. في هذه الحالة ، هذا ليس كذلك! كانت المهمة الرئيسية لاختبار قدرات TimescaleDB. وكانت النتيجة مثل هذا الرقم: 120 ألف قيمة في الثانية.هناك أيضًا أمثلة في المجتمع: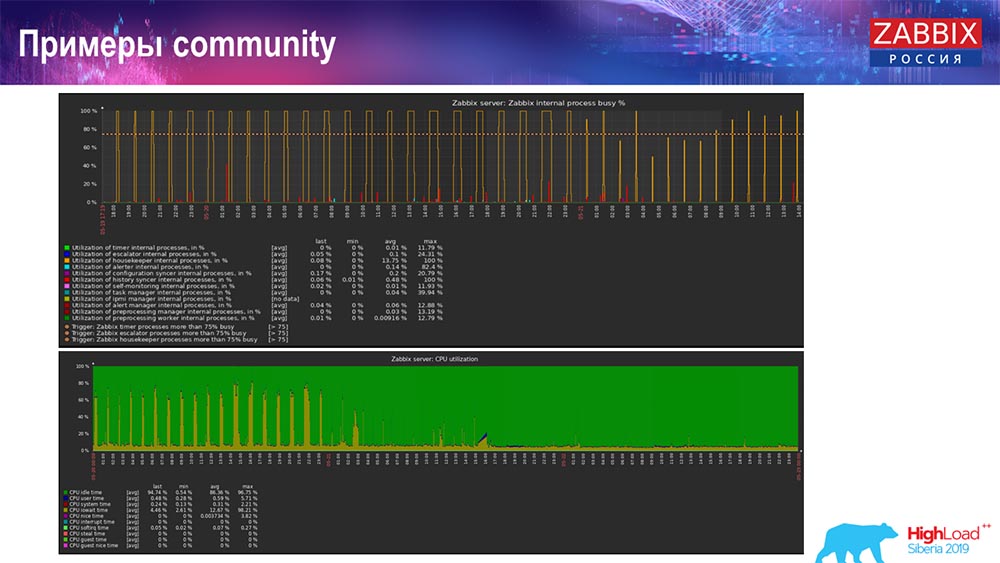 قام الرجل أيضًا بتشغيل TimescaleDB وانخفض العبء على استخدام io.weight على المعالج ؛ كما انخفض استخدام عناصر العملية الداخلية بفضل تضمين TimescaleDB. وهذه هي أقراص فطيرة عادية ، وهذا هو ، آلة افتراضية عادية على الأقراص العادية (وليس SSDs)!بالنسبة إلى بعض الإعدادات الصغيرة التي تعتمد على أداء القرص ، يعتبر TimescaleDB ، في رأيي ، حلاً جيدًا للغاية. سيسمح لك بمواصلة العمل بشكل جيد قبل الترحيل إلى أجهزة أسرع لقاعدة البيانات.أدعوكم جميعًا إلى أحداثنا: مؤتمر - في موسكو ، قمة - في ريغا. استخدم قنواتنا - Telegram ، منتدى ، IRC. إذا كان لديك أي أسئلة - تعال إلى مكتبنا ، يمكننا التحدث عن كل شيء.
قام الرجل أيضًا بتشغيل TimescaleDB وانخفض العبء على استخدام io.weight على المعالج ؛ كما انخفض استخدام عناصر العملية الداخلية بفضل تضمين TimescaleDB. وهذه هي أقراص فطيرة عادية ، وهذا هو ، آلة افتراضية عادية على الأقراص العادية (وليس SSDs)!بالنسبة إلى بعض الإعدادات الصغيرة التي تعتمد على أداء القرص ، يعتبر TimescaleDB ، في رأيي ، حلاً جيدًا للغاية. سيسمح لك بمواصلة العمل بشكل جيد قبل الترحيل إلى أجهزة أسرع لقاعدة البيانات.أدعوكم جميعًا إلى أحداثنا: مؤتمر - في موسكو ، قمة - في ريغا. استخدم قنواتنا - Telegram ، منتدى ، IRC. إذا كان لديك أي أسئلة - تعال إلى مكتبنا ، يمكننا التحدث عن كل شيء.أسئلة الجمهور
سؤال من الجمهور (يشار إليه فيما يلي - أ): - إذا كان إعداد TimescaleDB سهل للغاية ، ويعطي دفعة أداء كهذه ، فربما ينبغي استخدامه كأفضل ممارسة لإعداد Zabbix مع Postgres؟ وهل هناك أي عيوب وسلبيات لهذا القرار ، أم لا يزال ، إذا قررت أن أجعل Zabbix بنفسي ، يمكنني أن آخذ Postgres بأمان ، وأضع Timescale هناك على الفور ، استخدمه ولا أفكر في أي مشاكل ؟ AG:- نعم ، أود أن أقول إن هذه توصية جيدة: استخدم Postgres على الفور مع ملحق TimescaleDB. كما قلت ، الكثير من المراجعات الجيدة ، على الرغم من حقيقة أن هذه "الميزة" تجريبية. ولكن في الواقع ، تظهر الاختبارات أن هذا حل رائع (مع TimescaleDB) ، وأعتقد أنه سيتطور! إننا نراقب كيف يتطور هذا التوسع وسيقوم بتصحيح ما هو مطلوب.حتى أثناء التطوير ، اعتمدنا على واحدة من "ميزاتها" الشهيرة: حيث يمكنك العمل مع قطع مختلفة قليلاً. لكن بعد ذلك نشروها في الإصدار التالي ، ولم يعد علينا الاعتماد على هذا الرمز. أوصي باستخدام هذا الحل على العديد من الأجهزة. إذا كنت تستخدم MySQL ... للإعدادات المتوسطة ، فإن أي حل يعمل بشكل جيد.و:- على أحدث الرسوم البيانية ، التي هي من المجتمع ، كان هناك رسم بياني مع "مدبرة منزل":
AG:- نعم ، أود أن أقول إن هذه توصية جيدة: استخدم Postgres على الفور مع ملحق TimescaleDB. كما قلت ، الكثير من المراجعات الجيدة ، على الرغم من حقيقة أن هذه "الميزة" تجريبية. ولكن في الواقع ، تظهر الاختبارات أن هذا حل رائع (مع TimescaleDB) ، وأعتقد أنه سيتطور! إننا نراقب كيف يتطور هذا التوسع وسيقوم بتصحيح ما هو مطلوب.حتى أثناء التطوير ، اعتمدنا على واحدة من "ميزاتها" الشهيرة: حيث يمكنك العمل مع قطع مختلفة قليلاً. لكن بعد ذلك نشروها في الإصدار التالي ، ولم يعد علينا الاعتماد على هذا الرمز. أوصي باستخدام هذا الحل على العديد من الأجهزة. إذا كنت تستخدم MySQL ... للإعدادات المتوسطة ، فإن أي حل يعمل بشكل جيد.و:- على أحدث الرسوم البيانية ، التي هي من المجتمع ، كان هناك رسم بياني مع "مدبرة منزل": استمر في العمل. ماذا تفعل Hauskiper مع TimescaleDB؟AG: - الآن لا أستطيع أن أقول بالتأكيد - سألقي نظرة على الكود وأقول بمزيد من التفصيل. لا يستخدم استعلامات TimescaleDB لحذف القطع ، ولكنه يجمعها بطريقة أو بأخرى. على الرغم من أنني لست مستعدًا للإجابة على هذا السؤال الفني. سنوضح في الموقف اليوم أو غدا.ج: - لدي سؤال مماثل - حول أداء عملية الحذف في الجدول الزمني.ج (استجابة من الجمهور): - عند حذف البيانات من جدول ، إذا قمت بذلك من خلال الحذف ، فأنت بحاجة إلى المرور عبر الجدول - حذف ، تنظيف ، وضع علامة على كل شيء لفراغ في المستقبل. في Timescale ، نظرًا لأن لديك قطعًا كبيرة ، يمكنك إسقاطها. بمعنى تقريبي ، أنت فقط تقول للملف الموجود في البيانات الكبيرة: "حذف!""Timescale" يفهم ببساطة أنه لم يعد هناك مثل هذه القطعة. ونظرًا لأنه يتم دمجه في مخطط الاستعلام ، فإنه يدرك الشروط الخاصة بك على الخطافات في عمليات محددة أو أخرى ويفهم على الفور أن هذه القطعة لم تعد موجودة - "لن أذهب إلى هناك بعد الآن!" (البيانات غير متوفرة). هذا كل شئ! أي ، يتم استبدال فحص الجدول بإزالة الملف الثنائي ، لذلك فهو سريع.و:- بالفعل لمست في الموضوع ليس SQL. بقدر ما أفهم ، لا يحتاج Zabbix حقًا إلى تعديل البيانات ، ولكن كل هذا يشبه السجل. هل من الممكن استخدام قواعد البيانات المتخصصة التي لا يمكن تغيير بياناتها ، ولكن في الوقت نفسه حفظ ، وتجميع ، التخلي - Clickhouse ، دعنا نقول شيء يشبه الكافكا؟ .. كافكا هو أيضا سجل! هل من الممكن دمجها بطريقة أو بأخرى؟AG:- التفريغ يمكن القيام به. لدينا "ميزة" معينة من الإصدار 3.4: يمكنك كتابة جميع الملفات التاريخية والأحداث وكل شيء آخر للملفات ؛ ثم أرسله بواسطة أي معالج إلى أي قاعدة بيانات أخرى. في الواقع ، العديد من الذين يعيدون والكتابة مباشرة إلى قاعدة البيانات. أثناء التنقل ، تكتب المزامنات السابقة كل هذا إلى الملفات وتدوير هذه الملفات وما إلى ذلك ، ويمكنك رميها في Clickhouse. لا أستطيع أن أقول عن الخطط ، ولكن ، ربما ، سوف يستمر دعم إضافي لحلول NoSQL (مثل "Clickhouse").A: - بشكل عام ، اتضح أنه يمكنك التخلص من postgres تماما؟AG:- بطبيعة الحال ، فإن الجزء الأكثر صعوبة في Zabbix هو الجداول التاريخية ، والتي تخلق معظم المشاكل ، والأحداث. في هذه الحالة ، إذا لم تقم بتخزين الأحداث لفترة طويلة واحتفظت بالتاريخ في اتجاهات في بعض التخزين السريع الآخر ، فلن تكون هناك مشكلة بشكل عام ، على ما أعتقد.ج: - هل يمكنك تقييم مدى سرعة عمل كل شيء إذا ذهبت إلى Clickhouse ، على سبيل المثال؟AG: - أنا لم تختبر. أعتقد أنه يمكن تحقيق نفس الأرقام على الأقل بكل بساطة ، نظرًا لأن "Clickhouse" له واجهة خاصة به ، لكن لا يمكنني القول بالتأكيد. أفضل لاختبار. كل هذا يتوقف على التكوين: كم عدد المضيفين لديك وهلم جرا. الإدراج عبارة عن شيء واحد ، ولكن لا يزال يتعين عليك أخذ هذه البيانات - Grafana أو أي شيء آخر.و:- وهذا هو ، نحن نتحدث عن معركة متساوية ، وليس عن ميزة كبيرة من قواعد البيانات السريعة هذه؟أ.ج .: - عندما ندمج ، سيكون هناك اختبارات أكثر دقة.A: - أين ذهبت RRD القديم الجيد؟ ما الذي جعلك تتحول إلى قواعد بيانات SQL؟ في البداية ، على RRD ، تم جمع جميع المقاييس.AG: - في "RRD Zabbix" ، ربما كان في نسخة قديمة جدا. كانت هناك دائما قواعد بيانات SQL - النهج الكلاسيكي. النهج الكلاسيكي هو MySQL ، PostgreSQL (وهي موجودة بالفعل لفترة طويلة). لدينا واجهة مشتركة لقواعد بيانات SQL و RRD ، لم نستخدمها أبدًا.
استمر في العمل. ماذا تفعل Hauskiper مع TimescaleDB؟AG: - الآن لا أستطيع أن أقول بالتأكيد - سألقي نظرة على الكود وأقول بمزيد من التفصيل. لا يستخدم استعلامات TimescaleDB لحذف القطع ، ولكنه يجمعها بطريقة أو بأخرى. على الرغم من أنني لست مستعدًا للإجابة على هذا السؤال الفني. سنوضح في الموقف اليوم أو غدا.ج: - لدي سؤال مماثل - حول أداء عملية الحذف في الجدول الزمني.ج (استجابة من الجمهور): - عند حذف البيانات من جدول ، إذا قمت بذلك من خلال الحذف ، فأنت بحاجة إلى المرور عبر الجدول - حذف ، تنظيف ، وضع علامة على كل شيء لفراغ في المستقبل. في Timescale ، نظرًا لأن لديك قطعًا كبيرة ، يمكنك إسقاطها. بمعنى تقريبي ، أنت فقط تقول للملف الموجود في البيانات الكبيرة: "حذف!""Timescale" يفهم ببساطة أنه لم يعد هناك مثل هذه القطعة. ونظرًا لأنه يتم دمجه في مخطط الاستعلام ، فإنه يدرك الشروط الخاصة بك على الخطافات في عمليات محددة أو أخرى ويفهم على الفور أن هذه القطعة لم تعد موجودة - "لن أذهب إلى هناك بعد الآن!" (البيانات غير متوفرة). هذا كل شئ! أي ، يتم استبدال فحص الجدول بإزالة الملف الثنائي ، لذلك فهو سريع.و:- بالفعل لمست في الموضوع ليس SQL. بقدر ما أفهم ، لا يحتاج Zabbix حقًا إلى تعديل البيانات ، ولكن كل هذا يشبه السجل. هل من الممكن استخدام قواعد البيانات المتخصصة التي لا يمكن تغيير بياناتها ، ولكن في الوقت نفسه حفظ ، وتجميع ، التخلي - Clickhouse ، دعنا نقول شيء يشبه الكافكا؟ .. كافكا هو أيضا سجل! هل من الممكن دمجها بطريقة أو بأخرى؟AG:- التفريغ يمكن القيام به. لدينا "ميزة" معينة من الإصدار 3.4: يمكنك كتابة جميع الملفات التاريخية والأحداث وكل شيء آخر للملفات ؛ ثم أرسله بواسطة أي معالج إلى أي قاعدة بيانات أخرى. في الواقع ، العديد من الذين يعيدون والكتابة مباشرة إلى قاعدة البيانات. أثناء التنقل ، تكتب المزامنات السابقة كل هذا إلى الملفات وتدوير هذه الملفات وما إلى ذلك ، ويمكنك رميها في Clickhouse. لا أستطيع أن أقول عن الخطط ، ولكن ، ربما ، سوف يستمر دعم إضافي لحلول NoSQL (مثل "Clickhouse").A: - بشكل عام ، اتضح أنه يمكنك التخلص من postgres تماما؟AG:- بطبيعة الحال ، فإن الجزء الأكثر صعوبة في Zabbix هو الجداول التاريخية ، والتي تخلق معظم المشاكل ، والأحداث. في هذه الحالة ، إذا لم تقم بتخزين الأحداث لفترة طويلة واحتفظت بالتاريخ في اتجاهات في بعض التخزين السريع الآخر ، فلن تكون هناك مشكلة بشكل عام ، على ما أعتقد.ج: - هل يمكنك تقييم مدى سرعة عمل كل شيء إذا ذهبت إلى Clickhouse ، على سبيل المثال؟AG: - أنا لم تختبر. أعتقد أنه يمكن تحقيق نفس الأرقام على الأقل بكل بساطة ، نظرًا لأن "Clickhouse" له واجهة خاصة به ، لكن لا يمكنني القول بالتأكيد. أفضل لاختبار. كل هذا يتوقف على التكوين: كم عدد المضيفين لديك وهلم جرا. الإدراج عبارة عن شيء واحد ، ولكن لا يزال يتعين عليك أخذ هذه البيانات - Grafana أو أي شيء آخر.و:- وهذا هو ، نحن نتحدث عن معركة متساوية ، وليس عن ميزة كبيرة من قواعد البيانات السريعة هذه؟أ.ج .: - عندما ندمج ، سيكون هناك اختبارات أكثر دقة.A: - أين ذهبت RRD القديم الجيد؟ ما الذي جعلك تتحول إلى قواعد بيانات SQL؟ في البداية ، على RRD ، تم جمع جميع المقاييس.AG: - في "RRD Zabbix" ، ربما كان في نسخة قديمة جدا. كانت هناك دائما قواعد بيانات SQL - النهج الكلاسيكي. النهج الكلاسيكي هو MySQL ، PostgreSQL (وهي موجودة بالفعل لفترة طويلة). لدينا واجهة مشتركة لقواعد بيانات SQL و RRD ، لم نستخدمها أبدًا.
قليلا من الإعلان :)
شكرا لك على البقاء معنا. هل تحب مقالاتنا؟ تريد أن ترى المزيد من المواد المثيرة للاهتمام؟ ادعمنا عن طريق تقديم طلب أو التوصية لأصدقائك ،
VPS المستندة إلى مجموعة النظراء للمطورين من 4.99 دولار ، وهو
تناظرية فريدة من الخوادم على مستوى الدخول التي اخترعناها لك: الحقيقة الكاملة حول VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps من 19 $ أو كيفية تقسيم الخادم؟ (تتوفر خيارات مع RAID1 و RAID10 ، ما يصل إلى 24 مركزًا وما يصل إلى 40 جيجابايت من ذاكرة DDR4).
Dell R730xd أرخص مرتين في مركز بيانات Equinix Tier IV في أمستردام؟ فقط لدينا
2 من Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6 جيجا هرتز 14 جيجا بايت 64 جيجا بايت DDR4 4 × 960 جيجا بايت SSD 1 جيجابت في الثانية 100 TV من 199 دولار في هولندا! Dell R420 - 2x E5-2430 سعة 2 جيجا هرتز 6 جيجا بايت 128 جيجا بايت DDR3 2x960GB SSD بسرعة 1 جيجابت في الثانية 100 تيرابايت - من 99 دولارًا! اقرأ عن
كيفية بناء البنية التحتية فئة باستخدام خوادم V4 R730xd E5-2650d تكلف 9000 يورو عن بنس واحد؟