R هي أداة قوية للغاية للعمل مع الإحصاءات: من المعالجة المسبقة إلى بناء نماذج لأي تعقيد والرسومات المقابلة.
سيوفر طلب بسيط من Google قدرًا كبيرًا من المؤلفات حول كيفية "استخدام R بسهولة وسرعة". سيكون هناك كتب ضخمة والعديد من الملاحظات على Stack Overflow ، والتي تبدو للوهلة الأولى بمثابة مخزن لا حصر له من الأمثلة ، ولكل منها في حالتين سيجمع الكود الضروري لحل مشكلة معينة. ومع ذلك ، في الواقع هذا ليس صحيحا على الإطلاق. هناك القليل من المواد التي من شأنها أن توضح ، على سبيل المثال ، كيفية بناء جدول بسيط "من نقطة الصفر" مع وصفات جاهزة لحل الصعوبات التي ستنشأ أثناء حل هذه المشكلة.
لحل المشكلات العملية ، هناك حاجة إلى إرشادات محددة خطوة بخطوة ، وليس وصفاً مفصلاً للقوة الكاملة للحزمة. بالإضافة إلى ذلك ، غالباً ما تكون أمثلة التدريب الجاهزة (نفس القزحية ) ذات فائدة قليلة ، لأنها تتخطى على الفور واحدة من أهم مراحل العمل مع الإحصاءات - التجميع الأولي للمعالجة ومعالجتها. ولكن على وجه التحديد لهذا العمل الذي غالبا ما يستغرق جزء كبير من كل وقت! هناك مشكلة منفصلة تتمثل في إنشاء جداول تتوافق مع المعايير الرسمية ، وغالبًا ما تكون غير رسمية ، لبيئة مهنية معينة.
أنا وزملائي بحاجة بانتظام إلى القيام بمزيد من التصورات للإحصائيات والنماذج بناءً عليها لنشر النتائج العلمية. بما أن الدراسات تتعلق بالاقتصاد ، فإن العديد من هذه الأعمال تشبه الصحافة المهنية.
في مرحلة ما ، أصبح من الواضح أنه من أجل العمل الجماعي الفعال ، هناك حاجة إلى نوع من خطوط الأنابيب الكاملة لمعالجة الإحصاءات. وُلدت هذه المقالة كدليل تمهيدي للزملاء وورقة غش لنفسي لتشغيل هذا الناقل. يبدو أن هذه المادة يمكن أن تكون مفيدة لجمهور أوسع.
ص الرسومات خالية من الألم: تجول
الإعداد الأساسي R
للعمل ، تحتاج إلى حزمة قياسية: R + RStudio . وهي متوفرة مجانًا لجميع المنصات المشتركة. يتم تثبيت R أولاً ، ثم RStudio. عادة لا توجد مشاكل.
قبل العمل ، من الأفضل حفظ البرنامج النصي الجديد على الفور في مكان ما في نظام الملفات الخاص بك وتثبيت دليل العمل R على الفور في المجلد حيث يتم تخزين البرنامج النصي (قائمة الجلسة - تعيين دليل العمل - إلى موقع ملف المصدر). الملاحظة الأخيرة مهمة ، لأنه بخلاف ذلك ، لن يتم بدء تشغيل أي برنامج نصي خارجي أو أصلي بعد إعادة التشغيل RStudio. لسبب ما ، لا يقوم RStudio بهذا بشكل افتراضي ، وهو أمر منطقي.
حتى في الحزمة الأساسية R ، توجد أدوات تصورية قياسية (وظيفة الرسم) تتيح لك إنشاء أنواع كثيرة من الرسوم البيانية ، ومع ذلك ، من الواضح أن هذه الميزات ليست كافية للتوضيحات كاملة التخصيص.
مكتبة ggplot2 الأكثر استخدامًا للرسومات في R هي حزمة ، والتي سوف نستخدمها أيضًا.
من المهم أيضًا تثبيت حزم readxl على الفور (لقراءة ملفات .xls وملفات .xlsx) و dplyr (للعمل مع المصفوفات) ، والمقاييس (للعمل مع جداول بيانات مختلفة) ، القاهرة (لرسم الرسومات من ggplot إلى الملفات). كل هذا يمكن أن يتم بأمر واحد:
install.packages("ggplot2", "readxl", "scales", "dplyr", "Cairo")
جمع البيانات وإعدادها
الأمر الأكثر إثارة للدهشة هو أن هذه المرحلة في أي أدب ، سواء كان كتابًا نظريًا خطيرًا عن الإحصاءات النظرية المطبقة أو إرشادات لحزم إحصائية محددة ، مكرسة لوقت ووقت قليلين بشكل كارثي. ومع ذلك ، ووفقًا لتجربة البحث والقيادة المستقلة للطلاب والزملاء المبتدئين ، من المعروف أنه في هذه المرحلة يمكن أن تنخفض حصة الأسد من الوقت والجهد ، لذلك من المهم للغاية توفيرها حتى عند حل المشكلات الفنية البحتة.
هناك سؤالان هنا:
- كيفية اختيار تنسيق الملف الصحيح؟
- ما هي أفضل طريقة لهيكلة البيانات؟
مع التنسيق ، تكون المعضلة بسيطة: ملف CSV مقابل Microsoft Excel (ليس مهمًا جدًا ، .xlsx .xls القديم.). يعتقد الكثير من الناس أن ملف CSV يستفيد من البساطة (في الواقع ، هذا ملف نصي منتظم يتم فيه فصل قيم الأعمدة بفاصلة أو فاصلة منقوطة) والسرعة. لكنني اخترت Excel لسببين: أولاً ، في هذا الملف ، يمكنك تخزين عدة جداول في وقت واحد في علامات تبويب مختلفة ، وثانياً ، الأهم من ذلك ، ليس عليك التفكير في اختيار فاصل العمود الصحيح والمكان العشري. بالنسبة إلى ملف CSV ، يجب كتابة هذا يدويًا في رمز R وتأكد من حفظ ملف البيانات بنفس الإعدادات.
تشكل هيكلة البيانات مشكلة أكثر تعقيدًا ، وتتطلب فهمًا أساسيًا لكيفية ترتيب قواعد البيانات. إذا لم تذهب إلى نظرية قواعد البيانات العلائقية حول الأشكال العادية المختلفة ، إذن يجب أن يكون جدول البيانات متكررًا ، أي أنه يحتوي على أعمدة إضافية. يعد ذلك ضروريًا حتى تتمكن لاحقًا في البرنامج النصي في R من تحديد أجزاء معينة من المعلومات بمرونة لمزيد من المعالجة. على سبيل المثال ، إذا أردنا تصوير سلسلة زمنية بدائية ، فيجب علينا إنشاء أعمدة تتوافق مع جميع خصائص التجميع الممكنة. على سبيل المثال ، إذا كانت هذه هي سلسلة من الملاحظات السنوية لسكان مدينة Severovostochinsk الشرطية ، فسنحتاج إلى الأعمدة التالية: السنة (السنة) ، var (اسم المؤشر) ، القيمة (قيمة المؤشر).
سنقدم أي بيانات إدخال إلى هذا النمط من تقديم المعلومات.
مثال
الهدف: بناء مقارنة بين ديناميات حصاد الأحجام في روسيا ، والمقاطعة الفيدرالية السيبيرية وإقليم كراسنويارسك في الفترة 2009-2018.
الحصول على البيانات لهذه المهمة بسيط للغاية: فقط ابحث عن المؤشر المقابل في نظام المعلومات والإحصاءات الموحد بين الإدارات . دقة تأتي بعد ذلك. يمكنك تنزيل البيانات فورًا بتنسيق .xlsx ومن ثم تنظيمها يدويًا كما هو موضح أعلاه. لحسن الحظ ، تسمح لك بعض مصادر المعلومات (على سبيل المثال ، EMISS) بالقيام بذلك مع إمكانات الخدمة نفسها ، مما يبسط العمل إلى حد كبير ويقلل الوقت اللازم لإكماله.
لذلك ، بالنسبة لـ EMISS ، يكفي الانتقال إلى وضع "الإعدادات" (الزر المقابل في الركن الأيمن العلوي من صفحة البيانات) ونقل جميع العلامات ، باستثناء "الفترة" من عمود "الأعمدة" إلى عمود "الصفوف". اتضح جدولًا جاهزًا تقريبًا لعملنا في المستقبل. علاوة على ذلك ، بالفعل في Excel (أو أي محرر آخر مناسب) ، فمن المنطقي أن يتم نقل بنية الجدول إلى نموذج مشابه للنموذج الموضح أعلاه والتأكد من أن السطر الأول يحتوي فقط على أسماء المتغيرات ، علاوة على ذلك ، البيانات باللغة اللاتينية (من حيث المبدأ ، يمكن أن تعمل R مع عناوين باللغة الروسية ولكن هذا غير مريح عند كتابة التعليمات البرمجية). وكانت النتيجة مثل هذا الجدول (يتم إعطاء جزء في عدة صفوف).
يمكنك الآن استدعاء logging الورقة هذا ، وحفظ الكتاب بالكامل في ملف graphs.xlsx والانتقال إلى RStudio.
نحن ربط المكتبات اللازمة.
library(ggplot2) library(readxl) library(Cairo) library(scales) library(dplyr)
إذا كان يتم إعداد جدول لنشر باللغة الروسية ، يجب عليك بالتأكيد تكوين الإعدادات المحلية المناسبة. الخيار الأكثر حداثة الذي سينجح في معظم الحالات هو ، بالطبع ، تشفير UTF-8:
Sys.setlocale("LC_ALL", "ru_RU.UTF-8")
إذا كان النظام قديمًا (بعض أنظمة تشغيل Windows أو Linux القديمة) ، فستحتاج أولاً إلى فهم الترميز المستخدم افتراضيًا - هذه ليست مهمة بسيطة ، وهي بعيدة عن غرض هذه المقالة.
الآن تحتاج إلى تحميل البيانات إلى R.
df_logging <- read_excel("graphs.xlsx", sheet ="logging")
يحدد خيار sheet هنا اسم الورقة داخل مصنف Excel الذي سيتم تحميل البيانات منه.
نحن نبني أبسط نسخة من الجدول الزمني المطلوب.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location))

من حيث المبدأ ، تبين أن "الخروج من الصندوق" هو جدول يستحق الزيارة ، وهو مناسب تمامًا لإجراء تحليل أولي للعملية قيد الدراسة ، ولكن من وجهة نظر أي منشور محتمل ، لا يزال يتطلب تنقيحًا كبيرًا.
أولاً ، دعنا نجلب أسلوب الرسوم إلى أسلوب أكاديمي أكثر. ggplot2 حزمة ggplot2 على العديد من الموضوعات الأساسية الجاهزة. يمكن التعرف على موضوع theme_classic باعتباره الأنسب theme_classic . كجزء من التكوين الخاص به ، يمكنك على الفور ضبط الحجم الأساسي للخط وسماعه. تفضيلاتي الشخصية تنتمي إلى نظام الخطوط الحديث PT Sans و PT Serif و PT Mono . ولكن ، بالطبع ، يمكنك أن تسأل تايمز الكلاسيكية أو هلفتيكا. وأيضًا ، قد يكون للنشر الذي تم تخطيط المنشور تعليمات خاصة به في هذا الصدد. النقطة الأساسية مصممة تجريبياً على أن تكون 12 نقطة.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location)) + theme_classic(base_family = "PT Sans", base_size = 12)
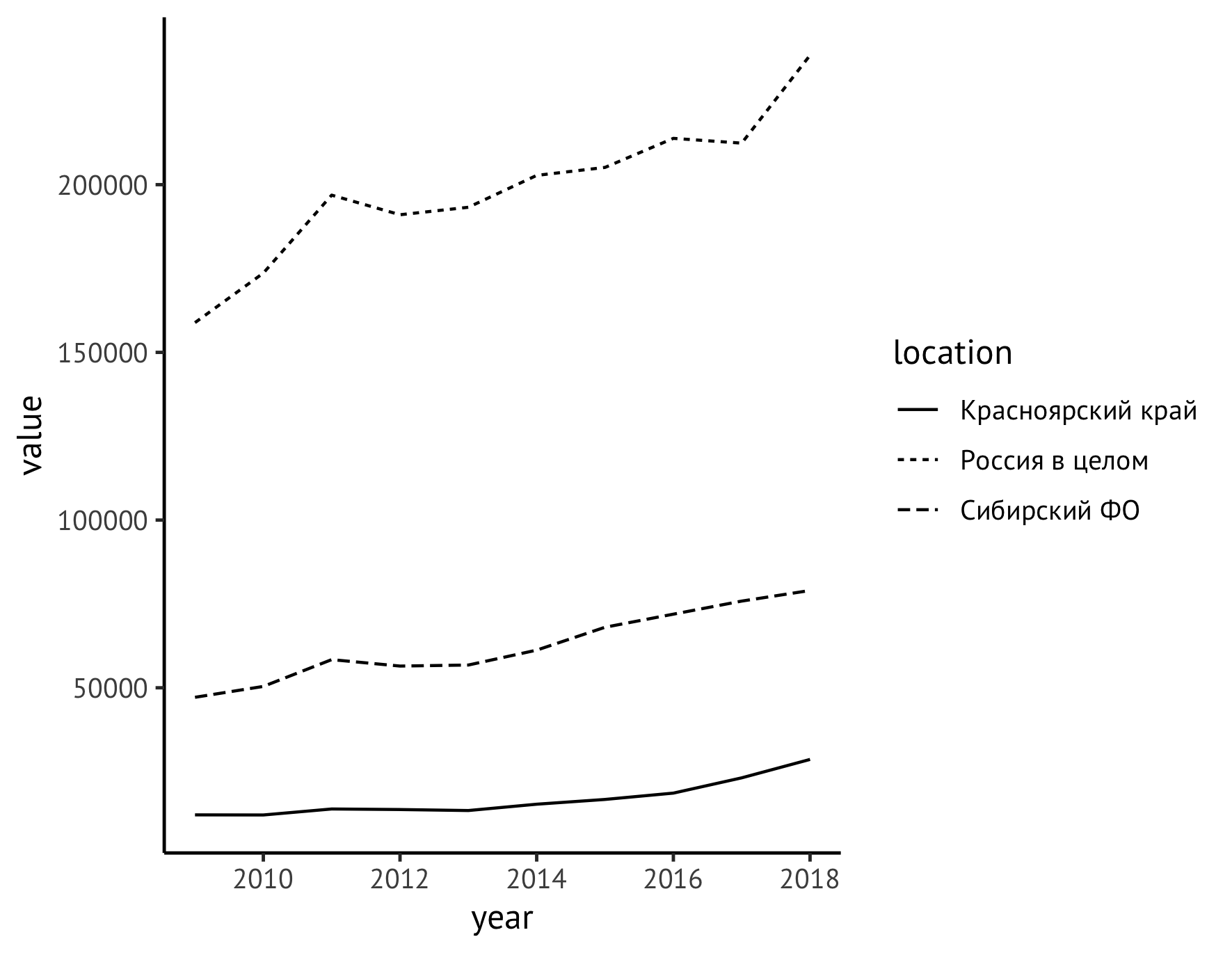
بعد ذلك ، انقل وسيلة الإيضاح من الحقل الأيمن للرسم البياني لأسفل (باستخدام تعليمة theme ) وفي نفس الوقت أعطِ أسماء ذات معنى للمحاور (إرشادات labs ). على طول المحور Y ، نكتب اسم المؤشر بوحدات القياس ("أحجام قطع الأشجار ، مليون متر مكعب") ، ونحذف الملصقات على طول المحور X تمامًا ، لأنه من الواضح أن هناك علامات على سنوات.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location)) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + labs(x = "", y = " , . . ", color="")

لجعل وحدات القياس أكثر ملاءمة للإدراك ، سننتقل من ألف متر مكعب. م إلى الملايين. للقيام بذلك ، قم ببساطة بتقسيم القيم على 1000 ، أي ، اضبط السطر الأول من الكود لدينا على النحو التالي:
ggplot(data=df_logging, aes(x=year, y=value/1000))
في الوقت نفسه ، تحتاج إلى تغيير الوحدات الموجودة في النقش:
labs(x = "", y = " , . ", color="")
وسنقوم على الفور بتحسين نمط الصورة قليلاً عن طريق إضافة نقاط للإشارة إلى كل قيمة تمت ملاحظتها ، والتي سنضيف إليها تعليمة:
geom_point(size=2)
يمكنك أيضًا تعيين نمط الخطوط بشكل صريح. من المنطقي أن نجعل المؤشر بالنسبة لروسيا خطًا متينًا ، وللمقاطعة الفيدرالية السيبيرية وإقليم كراسنويارسك - إصدارات مختلفة من فترات متقطعة:
scale_linetype_manual(values=c("twodash", "solid", "dotted"))
الآن رمز العام والرسم البياني تبدو مثل هذا:
ggplot(data=df_logging, aes(x=year, y=value/1000)) + geom_line(aes(linetype=location)) + geom_point(size=1) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + scale_linetype_manual(values=c("twodash", "solid", "dotted")) + labs(x = "", y = " , . ", color="")

يبقى لحل مهمة أكثر جوهرية - لزيادة محتوى المعلومات من جدولنا الزمني. الآن يمكن أن يتضح من ذلك أنه ، بشكل عام ، نما مؤشر جميع كائنات الملاحظة ، علاوة على ذلك ، منذ حوالي عام 2014 أصبح أقوى من ذي قبل. ولكن سيكون الأمر أكثر وضوحًا إذا ما صورنا مباشرة على الرسم البياني أيضًا القيم في العامين الأول والأخير ، على سبيل المثال ، في ذروة عام 2011. سوف يساعد بيان geom_text الجديد في:
geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8)
للوهلة الأولى ، يبدو الأمر معقدًا إلى حد ما ، ولا بد لي من القول إنه ليس من السهل تجميعه. سأحاول شرح ما يحدث هنا. في حد ذاته ، يضيف geom_text تسميات نصية إلى المخطط. لهذه التعليمات ، هناك حاجة إلى مجموعة البيانات. إذا حددنا df_logging مباشرة فيه ، df_logging على نقوش فوق كل نقطة. يتم ذلك في كثير من الأحيان ، ولكن بالنسبة للسلاسل الزمنية البسيطة إلى حد ما مثلنا ، لن يخلق هذا النهج إلا ضجيجًا بصريًا غير ضروري دون تزويدنا بمعلومات جديدة حول سلوك المؤشر المرصود. لذلك ، سوف نأخذ فقط تلك السنوات الضرورية لفهم ديناميات المؤشر: 2009 (بداية الملاحظات) ، 2011 (الذروة المحلية) ، 2018 (نهاية الملاحظات). وهذا سوف يساعد subset .
للعرض الصحيح للأرقام وفقًا للتقليد الناطق باللغة الروسية ، نحتاج إلى فاصلة كفاصل بين الأعداد الصحيحة والعشرية ( decimal.mark ) decimal.mark عدد المنازل العشرية ، يتم تعليم الأرقام. أدت التجارب المختلفة معها ، بما في ذلك استخدام الوظيفة round ، إلى حقيقة أننا إذا كنا بحاجة إلى منزلة عشرية واحدة ، فإننا نحتاج إلى تمرير القيمة 3 إلى digits .
ليس هناك حاجة مباشرة إلى check_overlap هنا ، ولكن يمكن أن يكون مفيدًا في حالات أخرى: إنه عنصر تحكم تلقائي للتسميات المتداخلة. يتحكم خيار vjust في وضع الملصقات رأسياً. يتم تحديد القيمة بناءً على اعتبارات الذوق.
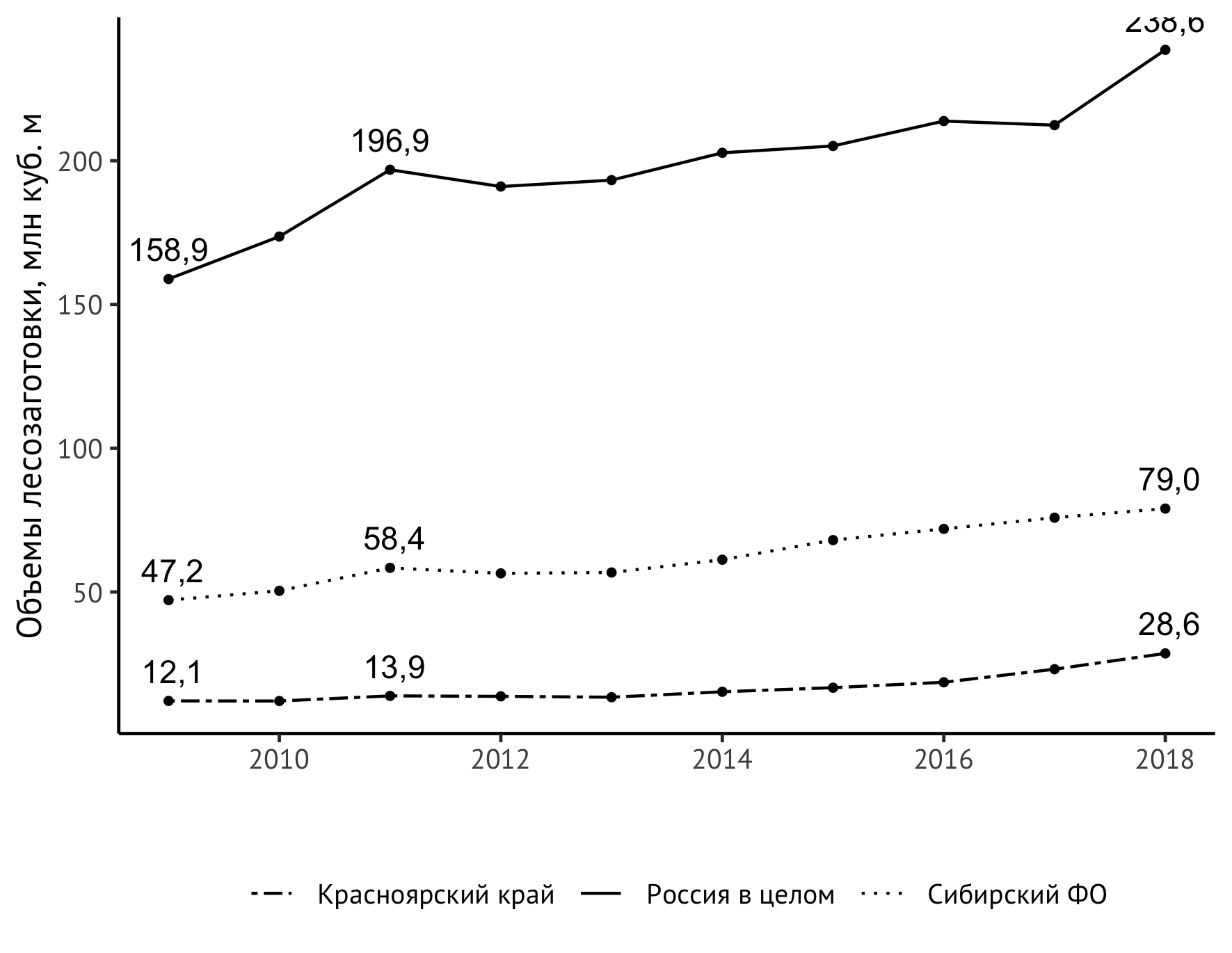
الآن الجدول الزمني المثير للاهتمام حقا للنظر!
ولكن تم اكتشاف مشكلة غير متوقعة - القيمة العليا اليمنى "مقطوعة" حسب الحجم الرأسي للصورة. هناك عدة طرق لحل هذه المشكلة. خرجت بامتداد طفيف من مقياس المحور الرأسي بحد أقصى واضح يبلغ 250 مليون متر مكعب. م:
scale_y_continuous(limits = c(0,250))
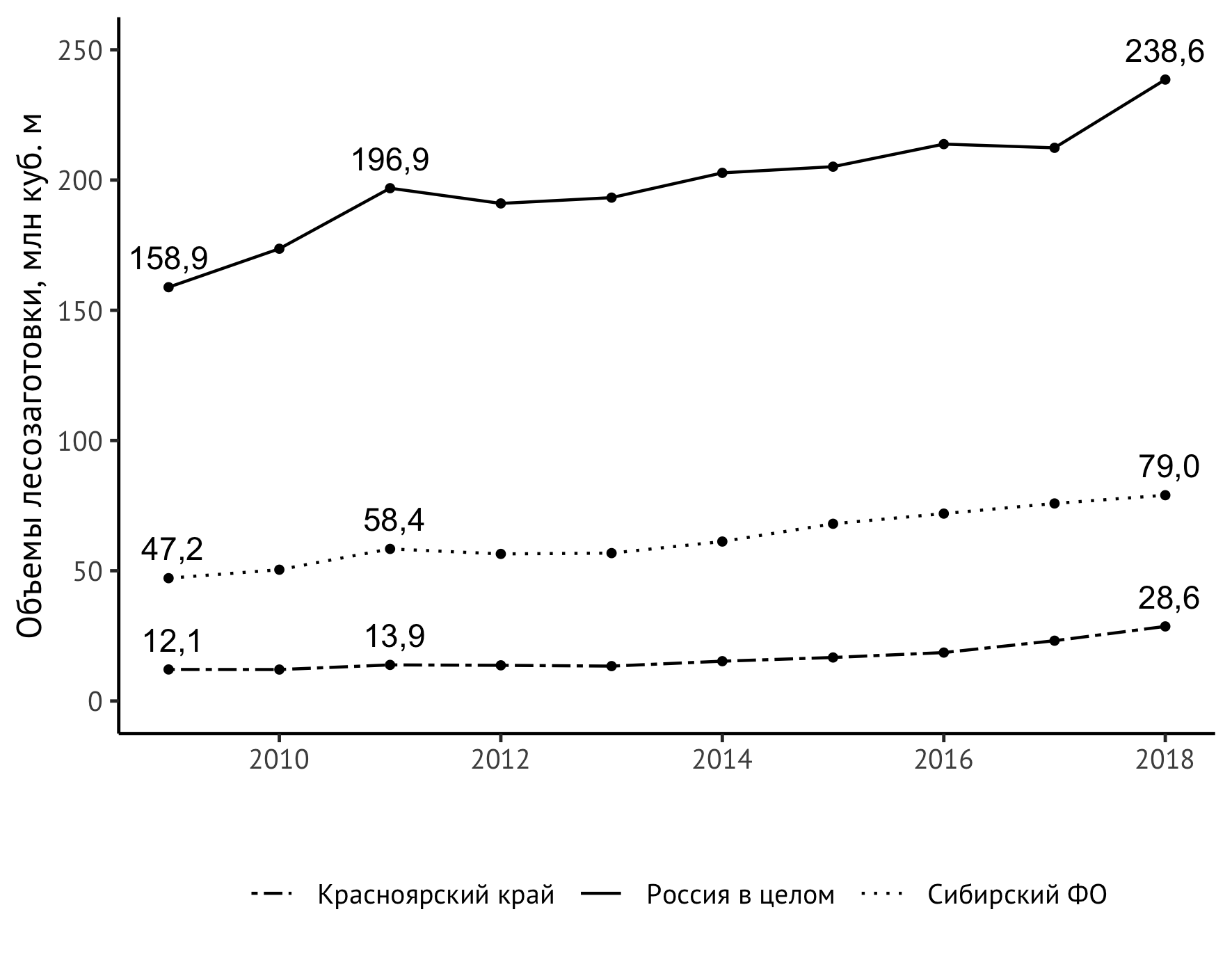
القيام به! لذلك ، يبدو الرمز النهائي كالتالي:
ggplot(data=df_logging, aes(x=year, y=value/1000)) + geom_line(aes(linetype=location)) + geom_point(size=1) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8) + geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8) + scale_linetype_manual(values=c("twodash", "solid", "dotted")) + scale_y_continuous(limits = c(0,250)) + labs(x = "", y = " , . ", color="")
يتم تضمين الصورة الناتجة في الدراسة: التحديث الهيكلي كعامل في زيادة القدرة التنافسية للمنطقة (على سبيل المثال في إقليم كراسنويارسك) / ed. شيشتسكي إن جي - نوفوسيبيرسك: IEOPP SB RAS ، 2020 (تحت الطبع).
صادرات
يتيح لك الرسم البياني الذي يعرض المكون الإضافي المدمج في RStudio تصدير الصور بتنسيقات متعددة دون أوامر إضافية ، ببضع نقرات فقط. المشكلة هي أنه بالنسبة للمهام العملية هذه الخدمة غير مجدية عمليا. عند الحفظ إلى تنسيقات نقطية (.jpg ، .png) ، يكون الإعداد الافتراضي منخفضًا جدًا ، لذلك عند استيراد صورة ، على سبيل المثال ، في Word ، سيتم ضبابية. مع vector .eps أو .pdf ، يكون الموقف أسوأ بصراحة: يحدث الحفظ إما بأخطاء لا تسمح بعد ذلك بفتح الملف ، أو يتم حفظه دون إمكانية استخدام نقوش باللغة الروسية.
الحل هو استخدام وظيفة ggsave من حزمة ggplot .
إذا كان الإخراج يتطلب ملف نقطي منتظم ، على سبيل المثال ، بتنسيق .png ، فكل شيء بسيط للغاية:
ggsave("logging.png", width=709, height=549, units="px")
يمكن حذف الشكل الهندسي ( width الخيارات height ) ووحدات القياس ( units ) ، ولكن بعد ذلك سيتم تصدير الصورة مربعًا ، وهو بالكاد مناسب. لذلك ، من الأفضل التوصل إلى نسبتك الخاصة والحجم المطلوب وتعيين هذه المعلمات يدويًا ، كما هو الحال في سطر التعليمات البرمجية أعلاه.
من أجل الاستخدام اللاحق للصورة في المنشورات الورقية ، من المعقول تصدير الصورة بتنسيقات متجهة ، بحيث في وقت لاحق في التخطيط ، هناك إمكانية لتغيير هندسة الصورة بحرية. تفضل العديد من المجلات تنسيق .eps - كما أنه مناسب لاستخدامه للتصدير إلى Word. سنحتاج إلى برنامج التشغيل المثبت بالفعل والمتصل بالقاهرة:
ggsave(filename = "export.eps", width=15, height=11.6, units="cm", device = cairo_ps)
سيتم حفظ الملفات في الدليل الحالي حيث يوجد البرنامج النصي R.
ماذا تقرأ
الأدب على الرسومات في R هو الكثير جدا. فيما يلي بعض الأمثلة ، أولها عمل مؤلف حزمة ggplot:
من المحتمل أن يكون الكتاب الذي أعده تيموفي سامسونوف هو أفضل وأشمل كتاب عن الرسومات باللغة الروسية . تصور وتحليل البيانات الجغرافية في لغة البحث والتطوير . هذا هو دليل مفصل ممتاز لكثير من المشاكل الشائعة والمحددة التي يمكن حلها مع R.
يمكنك أيضًا أن توصي بكتاب باللغة الروسية عن البحث بشكل عام:
Shitikov V.K. ، Mastitsky S.E. التصنيف ، الانحدار ، خوارزميات تعدين البيانات باستخدام R. 2017 .
مثال مثير للاهتمام ومحفز هو عرض تقديمي قوي حول استخدام ggplot2 في إعداد الرسومات لصحيفة فاينانشال تايمز المؤثرة .