Selbstlernendes Bilderkennungsprogramm von Disney Research
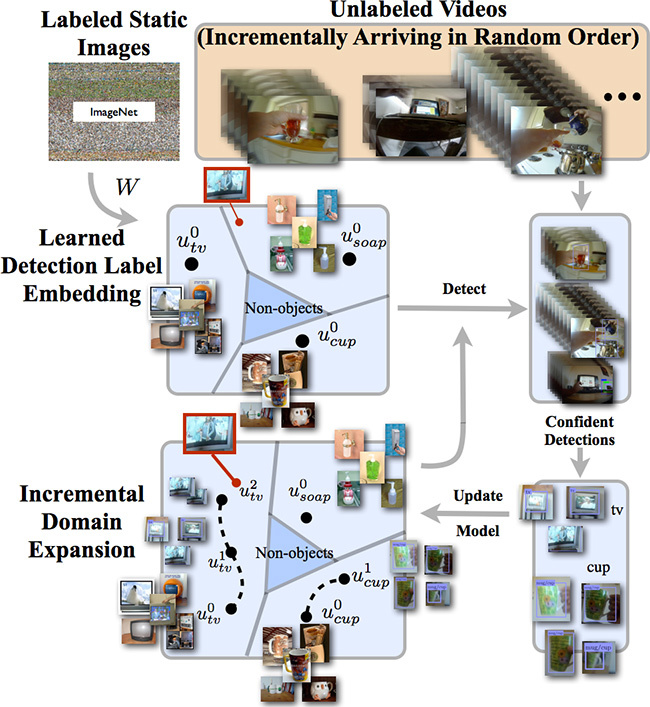 Ein Forscherteam der Pittsburgh-Abteilung von Disney Research hat ein Computer-Vision-System entwickelt, das einige Prinzipien des menschlichen Sehens verwendet ( pdf ). Insbesondere enthält es Algorithmen zum Selbstlernen und kann die Objekterkennung im Laufe der Zeit verbessern.Wie bei den meisten anderen Computer-Vision-Systemen wird bei der Entwicklung von Disney Research ein konzeptionelles Modell für jedes Objekt erstellt, unabhängig davon, ob es sich um ein Flugzeug oder einen Seifenspender handelt. In diesem Fall wird ein trainierter Algorithmus verwendet, der viele Fotos eines bestimmten Objekts analysiert.Eine Besonderheit des Disney Research-Algorithmus besteht darin, dass er dieses Modell anschließend verwendet, um Objekte im Video zu erkennen, während gleichzeitig neue Informationen zu diesen Objekten extrahiert und das ursprünglich festgelegte Modell ergänzt werden. Auf diese Weise können Sie Objekte in einem größeren Bereich erkennen, auch wenn sie anders aussehen als bei zuvor angetroffenen Beispielen.Die Abbildungen (anklickbar) zeigen das Ergebnis der Mustererkennung. In der oberen Reihe befinden sich Testbilder aus der ImageNet-Datenbank, mit denen das ursprüngliche Modell trainiert wurde. In der unteren Zeile finden Sie Beispiele für die korrekte Erkennung von Objekten durch das IDE-LME-Programm. Die Forscher stellen fest, dass sich die auf den Fotos erkannten Objekte im Aussehen erheblich von denen unterscheiden, mit denen das System trainiert wurde. "Der [selbstlernende] Prozess wird möglicherweise auf unbestimmte Zeit während der gesamten Lebensdauer des Erkennungssystems fortgesetzt", sagt Leonid Sigal, leitender Mitarbeiter bei Disney Research Pittsburgh. "Dies ist ein selbstlernendes System, das sich durch unkontrollierten Erfahrungserwerb kontinuierlich weiterentwickelt und ein zunehmend vollständiges und komplexeres Modell der Welt darstellt."
Ein Forscherteam der Pittsburgh-Abteilung von Disney Research hat ein Computer-Vision-System entwickelt, das einige Prinzipien des menschlichen Sehens verwendet ( pdf ). Insbesondere enthält es Algorithmen zum Selbstlernen und kann die Objekterkennung im Laufe der Zeit verbessern.Wie bei den meisten anderen Computer-Vision-Systemen wird bei der Entwicklung von Disney Research ein konzeptionelles Modell für jedes Objekt erstellt, unabhängig davon, ob es sich um ein Flugzeug oder einen Seifenspender handelt. In diesem Fall wird ein trainierter Algorithmus verwendet, der viele Fotos eines bestimmten Objekts analysiert.Eine Besonderheit des Disney Research-Algorithmus besteht darin, dass er dieses Modell anschließend verwendet, um Objekte im Video zu erkennen, während gleichzeitig neue Informationen zu diesen Objekten extrahiert und das ursprünglich festgelegte Modell ergänzt werden. Auf diese Weise können Sie Objekte in einem größeren Bereich erkennen, auch wenn sie anders aussehen als bei zuvor angetroffenen Beispielen.Die Abbildungen (anklickbar) zeigen das Ergebnis der Mustererkennung. In der oberen Reihe befinden sich Testbilder aus der ImageNet-Datenbank, mit denen das ursprüngliche Modell trainiert wurde. In der unteren Zeile finden Sie Beispiele für die korrekte Erkennung von Objekten durch das IDE-LME-Programm. Die Forscher stellen fest, dass sich die auf den Fotos erkannten Objekte im Aussehen erheblich von denen unterscheiden, mit denen das System trainiert wurde. "Der [selbstlernende] Prozess wird möglicherweise auf unbestimmte Zeit während der gesamten Lebensdauer des Erkennungssystems fortgesetzt", sagt Leonid Sigal, leitender Mitarbeiter bei Disney Research Pittsburgh. "Dies ist ein selbstlernendes System, das sich durch unkontrollierten Erfahrungserwerb kontinuierlich weiterentwickelt und ein zunehmend vollständiges und komplexeres Modell der Welt darstellt."
 Das konzeptionelle Modell für jedes Objekt wird schrittweise erweitert und verfeinert, wenn das System auf neue Informationen stößt. Theoretisch kann ein solches Verfahren dazu führen, dass das System ohne Überwachung dem Objekt ungewöhnliche Merkmale zuweist, was zu Erkennungsfehlern führt. Die Autoren des Programms sagen jedoch, dass ein solches Problem noch nicht bemerkt wurde.Zu den Autoren der wissenschaftlichen Arbeit gehören neben Sigal Alina Kuznetsova, Bodo Rosenhahn von der Universität Wilhelm Leibniz (Hannover) und der ehemalige Disney-Mitarbeiter Sen Hwan Yu (Sung Ju Hwang), der derzeit am National Institute of Science arbeitet und Technologie in Ulsan (Südkorea).Die Präsentation der wissenschaftlichen Arbeit fand auf der IEEE-Konferenz über Computer Vision und Mustererkennung in Boston (7.-12. Juni 2015) statt.
Das konzeptionelle Modell für jedes Objekt wird schrittweise erweitert und verfeinert, wenn das System auf neue Informationen stößt. Theoretisch kann ein solches Verfahren dazu führen, dass das System ohne Überwachung dem Objekt ungewöhnliche Merkmale zuweist, was zu Erkennungsfehlern führt. Die Autoren des Programms sagen jedoch, dass ein solches Problem noch nicht bemerkt wurde.Zu den Autoren der wissenschaftlichen Arbeit gehören neben Sigal Alina Kuznetsova, Bodo Rosenhahn von der Universität Wilhelm Leibniz (Hannover) und der ehemalige Disney-Mitarbeiter Sen Hwan Yu (Sung Ju Hwang), der derzeit am National Institute of Science arbeitet und Technologie in Ulsan (Südkorea).Die Präsentation der wissenschaftlichen Arbeit fand auf der IEEE-Konferenz über Computer Vision und Mustererkennung in Boston (7.-12. Juni 2015) statt.Source: https://habr.com/ru/post/de380363/
All Articles