Generische Musikgenerierung mit einem wiederkehrenden neuronalen Netzwerk
Heutzutage machen trainierte neuronale Netze erstaunliche Dinge, aber Experimente in diesem Bereich entdecken immer wieder etwas Neues. Zum Beispiel veröffentlichte der Programmierer Daniel Johnson die Ergebnisse seiner Experimente zur Verwendung neuronaler Netze zur Erzeugung klassischer Musik.Leider können Sie keine Audiodatei in GT einbetten, daher müssen Sie einen direkten Link angeben, um eines der Ergebnisse anzuhören: http://hexahedria.com/files/nnet_music_2.mp3 .Wie hat er es gemacht?Daniel Johnson sagt, dass er sich auf das Eigentum der Invarianz konzentriert hat. Die meisten vorhandenen neuronalen Netze zur Musikgenerierung sind zeitinvariant, aber nicht noteninvariant. Das Transponieren von nur einem Schritt führt daher zu einem völlig anderen Ergebnis. Für die meisten anderen Anwendungen funktioniert dieser Ansatz gut, jedoch nicht für Musik. Hier möchte ich Harmonie der Harmonien erreichen.Daniel fand nur einen Typ populärer neuronaler Netze, bei denen es eine Invarianz in verschiedene Richtungen gibt: Dies sind Faltungs-Neuronale Netze zur Bilderkennung.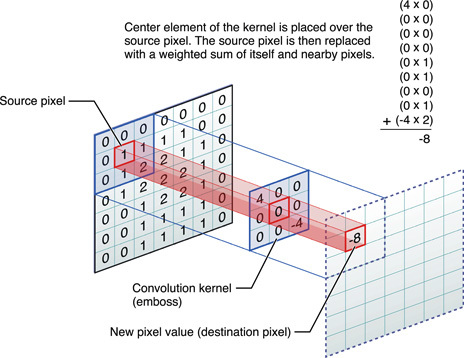 Der Autor passte das Faltungsmodell an, fügte für jedes Pixel ein wiederkehrendes neuronales Netzwerk mit einem eigenen Speicher hinzu und ersetzte die Pixel durch Notizen. So erhielt er ein System, das sowohl zeitlich als auch in Notizen unveränderlich ist.
Der Autor passte das Faltungsmodell an, fügte für jedes Pixel ein wiederkehrendes neuronales Netzwerk mit einem eigenen Speicher hinzu und ersetzte die Pixel durch Notizen. So erhielt er ein System, das sowohl zeitlich als auch in Notizen unveränderlich ist.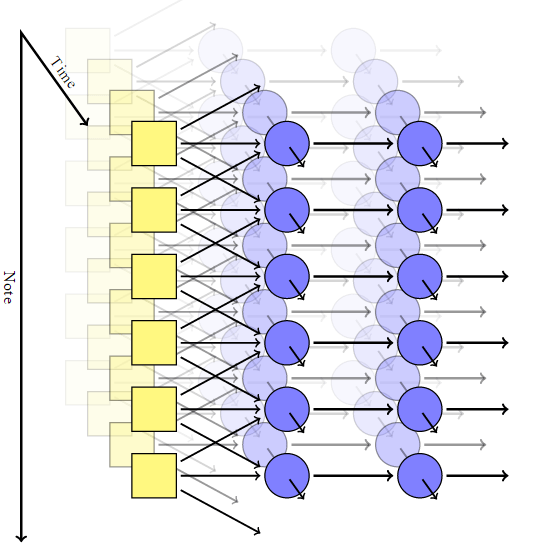 In einem solchen Netzwerk gibt es jedoch keinen Mechanismus, um harmonische Akkorde zu erhalten: Am Ausgang ist jede Note völlig unabhängig von den anderen.Um eine Kombination von Noten zu erzielen, verwendete Johnson ein Modell wie RNN-RBM, bei dem ein Teil des neuronalen Netzwerks für die Zeit und der andere Teil für Konsonantenakkorde verantwortlich ist. Um die Einschränkungen von RBM zu umgehen, entwickelte er zwei Achsen: für Zeit und für Noten (und eine Pseudoachse für die Richtung der Berechnungen).
In einem solchen Netzwerk gibt es jedoch keinen Mechanismus, um harmonische Akkorde zu erhalten: Am Ausgang ist jede Note völlig unabhängig von den anderen.Um eine Kombination von Noten zu erzielen, verwendete Johnson ein Modell wie RNN-RBM, bei dem ein Teil des neuronalen Netzwerks für die Zeit und der andere Teil für Konsonantenakkorde verantwortlich ist. Um die Einschränkungen von RBM zu umgehen, entwickelte er zwei Achsen: für Zeit und für Noten (und eine Pseudoachse für die Richtung der Berechnungen).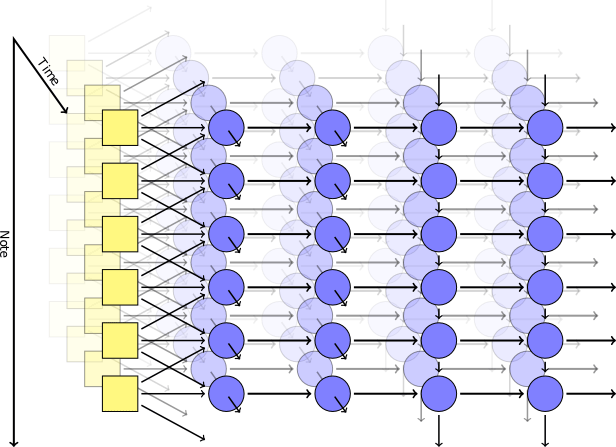 Verwenden der Theano- BibliothekDer Autor erzeugte ein neuronales Netzwerk nach seinem Modell. Die erste Ebene mit der Zeitachse nahm am Eingang die folgenden Parameter an: Position, Tonhöhe, Wert der umgebenden Noten, vorheriger Kontext, Rhythmus. Dann wurden selbsterzeugende Blöcke basierend auf dem Kurzzeitgedächtnis (LSTM) ausgelöst: In einem Fall sind die wiederkehrenden Verbindungen entlang der Zeitachse und in dem anderen entlang der Notenachse gerichtet. Nach dem letzten LSTM-Block gibt es eine einfache, nicht wiederkehrende Schicht zum Ausgeben des Endergebnisses. Sie hat zwei Ausgabewerte: die Wahrscheinlichkeit, für eine bestimmte Note zu spielen, und die Wahrscheinlichkeit der Artikulation (dh die Wahrscheinlichkeit, dass die Note mit einer anderen kombiniert wird).Während des Trainings verwendeten wir einen zufällig ausgewählten Satz kurzer musikalischer Fragmente aus der MIDI-Sammlung Classical Piano Midi Page. Dann haben wir ein wenig mit den Logarithmen gespielt, damit der Kreuzentropieparameter in der Ausgabe zumindest nicht zu niedrig ist. Um die Spezialisierung der Schichten zu gewährleisten, verwendeten wir eine Technik wie Dropout , bei der bei jedem Schritt des Trainings die Hälfte der versteckten Knoten versehentlich ausgeschlossen wurde.Das praktische Modell bestand aus zwei zeitlich verborgenen Schichten mit jeweils 300 Knoten und zwei Schichten entlang der Notenachse für 100 bzw. 50 Knoten. Die Schulung wurde in der virtuellen Maschine g2.2xlarge in der Amazon Web Services-Cloud durchgeführt.
Verwenden der Theano- BibliothekDer Autor erzeugte ein neuronales Netzwerk nach seinem Modell. Die erste Ebene mit der Zeitachse nahm am Eingang die folgenden Parameter an: Position, Tonhöhe, Wert der umgebenden Noten, vorheriger Kontext, Rhythmus. Dann wurden selbsterzeugende Blöcke basierend auf dem Kurzzeitgedächtnis (LSTM) ausgelöst: In einem Fall sind die wiederkehrenden Verbindungen entlang der Zeitachse und in dem anderen entlang der Notenachse gerichtet. Nach dem letzten LSTM-Block gibt es eine einfache, nicht wiederkehrende Schicht zum Ausgeben des Endergebnisses. Sie hat zwei Ausgabewerte: die Wahrscheinlichkeit, für eine bestimmte Note zu spielen, und die Wahrscheinlichkeit der Artikulation (dh die Wahrscheinlichkeit, dass die Note mit einer anderen kombiniert wird).Während des Trainings verwendeten wir einen zufällig ausgewählten Satz kurzer musikalischer Fragmente aus der MIDI-Sammlung Classical Piano Midi Page. Dann haben wir ein wenig mit den Logarithmen gespielt, damit der Kreuzentropieparameter in der Ausgabe zumindest nicht zu niedrig ist. Um die Spezialisierung der Schichten zu gewährleisten, verwendeten wir eine Technik wie Dropout , bei der bei jedem Schritt des Trainings die Hälfte der versteckten Knoten versehentlich ausgeschlossen wurde.Das praktische Modell bestand aus zwei zeitlich verborgenen Schichten mit jeweils 300 Knoten und zwei Schichten entlang der Notenachse für 100 bzw. 50 Knoten. Die Schulung wurde in der virtuellen Maschine g2.2xlarge in der Amazon Web Services-Cloud durchgeführt.Ergebnisse
Der Quellcode für das Programm wird auf Github veröffentlicht . Source: https://habr.com/ru/post/de382711/
All Articles