Google hört besser, die Suche ist einfacher
Google gab bekannt, dass das Sprachsuchsystem fertiggestellt wurde, um die Spracherkennung des Nutzers an lauten Orten besser erkennen zu können. Es war schon immer eines der besten Spracherkennungssysteme und ist besonders praktisch bei der Suche mit Smartphones. Jetzt ist die Sprachsuchfunktion noch weiter entwickelt als je zuvor. Der Google Research Blog beschreibt die Verbesserungen, die am aktualisierten System vorgenommen wurden.Seit 2012 hat sich der Suchriese vor dreißig Jahren von der Gaußschen Mischmethode (MGS) bei der Spracherkennung verabschiedet. Die neuen Systeme begannen, tiefe neuronale Netze ( Deep Neural Networks ) zu verwenden. STS kann besser erkennen, welche Geräusche der Benutzer zu einem bestimmten Zeitpunkt macht, was die Erkennungsgenauigkeit erheblich erhöht.
Es war schon immer eines der besten Spracherkennungssysteme und ist besonders praktisch bei der Suche mit Smartphones. Jetzt ist die Sprachsuchfunktion noch weiter entwickelt als je zuvor. Der Google Research Blog beschreibt die Verbesserungen, die am aktualisierten System vorgenommen wurden.Seit 2012 hat sich der Suchriese vor dreißig Jahren von der Gaußschen Mischmethode (MGS) bei der Spracherkennung verabschiedet. Die neuen Systeme begannen, tiefe neuronale Netze ( Deep Neural Networks ) zu verwenden. STS kann besser erkennen, welche Geräusche der Benutzer zu einem bestimmten Zeitpunkt macht, was die Erkennungsgenauigkeit erheblich erhöht.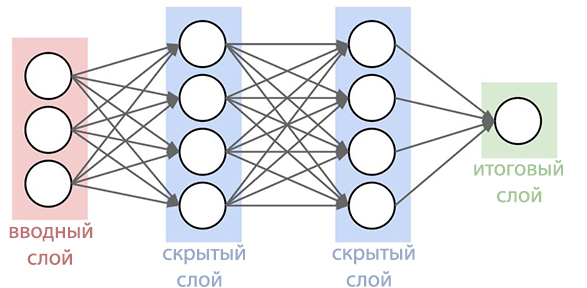 Jetzt haben Google-Experten bekannt gegeben, dass es ihnen gelungen ist, ein fortschrittlicheres neuronales Netzwerk von akustischen Modellen zu erstellen, das verbindungsorientierte zeitliche Klassifizierung und diskriminierende Lernalgorithmen verwendet . Diese Modelle stellen eine spezielle Erweiterung periodischer neuronaler Netze dar, die insbesondere in lauten Umgebungen genauer und unglaublich schnell sind!Bei der herkömmlichen Spracherkennung wurde das vom Benutzer ausgefüllte Sprachformular in aufeinanderfolgende Frames (Segmente) von 10 Millisekunden unterteilt. Jeder Frame wurde einer Frequenzanalyse unterzogen, und der resultierende Vektor mit den Eigenschaften wurde durch akustische Modelle wie GNS geleitet, die Wahrscheinlichkeiten für alle Klangübereinstimmungen angeben. Das Hidden-Markov-Modell (SMM) hilft dabei, unbekannte Details auf der Grundlage bereits erhaltener zu entschlüsseln, wodurch eine Art Strukturierung dieser Folge von Wahrscheinlichkeitsverteilungen eingeführt werden kann. Dieses Modell wird ferner mit anderen Wissensquellen kombiniert, wie dem Aussprachemodell, das die Tonfolgen mit bestimmten Wörtern, der ausgewählten Sprache und dem Sprachmodell verknüpft, das wiederum ausdrückt, wie sehr sich das Wort auf die ausgewählte Sprache bezieht.Der Erkenner stimmt dann alle diese Informationen ab, um den Satz zu bestimmen, den der Benutzer macht. Wenn der Benutzer beispielsweise das Wort „Museum“ sagt (mju: 'zɪəm ist eine phonetische Form), kann es schwierig sein, festzustellen, wann der Ton „j“ endet und der Ton „u“ beginnt. In Wahrheit ist es der Determinante jedoch egal, wann dieser Übergang stattfindet. Das einzige, was ihn stört, sind genau die Geräusche, die ausgesprochen wurden.Das neue verbesserte akustische Modell basiert auf periodischen neuronalen Netzen (PNS). In der Topologie des PNS gibt es Rückkopplungsschleifen, mit denen Sie die Zeitabhängigkeit simulieren können. Wenn der Benutzer im vorherigen Beispiel / U / ausspricht, bewegt sich der Artikulationsapparat der Person zunächst reibungslos vom Ton / J / zum Ton / M /. Versuchen Sie, das Wort "Museum" auszusprechen. Für Menschen, die fließend Englisch sprechen, wird es nicht schwierig sein und das Wort wird leicht in einem Atemzug ausgesprochen. PNS ist in der Lage, diesen Moment einzufangen.
Jetzt haben Google-Experten bekannt gegeben, dass es ihnen gelungen ist, ein fortschrittlicheres neuronales Netzwerk von akustischen Modellen zu erstellen, das verbindungsorientierte zeitliche Klassifizierung und diskriminierende Lernalgorithmen verwendet . Diese Modelle stellen eine spezielle Erweiterung periodischer neuronaler Netze dar, die insbesondere in lauten Umgebungen genauer und unglaublich schnell sind!Bei der herkömmlichen Spracherkennung wurde das vom Benutzer ausgefüllte Sprachformular in aufeinanderfolgende Frames (Segmente) von 10 Millisekunden unterteilt. Jeder Frame wurde einer Frequenzanalyse unterzogen, und der resultierende Vektor mit den Eigenschaften wurde durch akustische Modelle wie GNS geleitet, die Wahrscheinlichkeiten für alle Klangübereinstimmungen angeben. Das Hidden-Markov-Modell (SMM) hilft dabei, unbekannte Details auf der Grundlage bereits erhaltener zu entschlüsseln, wodurch eine Art Strukturierung dieser Folge von Wahrscheinlichkeitsverteilungen eingeführt werden kann. Dieses Modell wird ferner mit anderen Wissensquellen kombiniert, wie dem Aussprachemodell, das die Tonfolgen mit bestimmten Wörtern, der ausgewählten Sprache und dem Sprachmodell verknüpft, das wiederum ausdrückt, wie sehr sich das Wort auf die ausgewählte Sprache bezieht.Der Erkenner stimmt dann alle diese Informationen ab, um den Satz zu bestimmen, den der Benutzer macht. Wenn der Benutzer beispielsweise das Wort „Museum“ sagt (mju: 'zɪəm ist eine phonetische Form), kann es schwierig sein, festzustellen, wann der Ton „j“ endet und der Ton „u“ beginnt. In Wahrheit ist es der Determinante jedoch egal, wann dieser Übergang stattfindet. Das einzige, was ihn stört, sind genau die Geräusche, die ausgesprochen wurden.Das neue verbesserte akustische Modell basiert auf periodischen neuronalen Netzen (PNS). In der Topologie des PNS gibt es Rückkopplungsschleifen, mit denen Sie die Zeitabhängigkeit simulieren können. Wenn der Benutzer im vorherigen Beispiel / U / ausspricht, bewegt sich der Artikulationsapparat der Person zunächst reibungslos vom Ton / J / zum Ton / M /. Versuchen Sie, das Wort "Museum" auszusprechen. Für Menschen, die fließend Englisch sprechen, wird es nicht schwierig sein und das Wort wird leicht in einem Atemzug ausgesprochen. PNS ist in der Lage, diesen Moment einzufangen.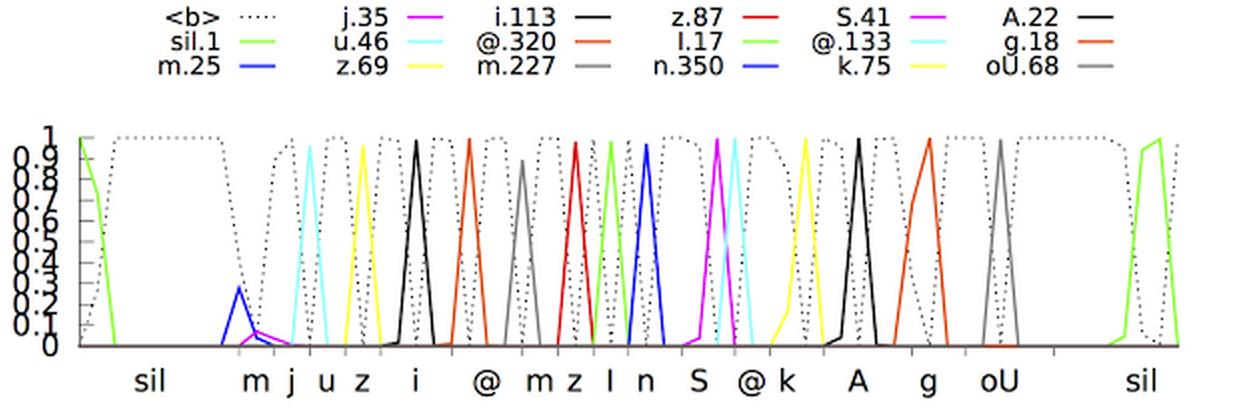 Eine Art von periodischen neuronalen Netzen in diesem System ist ein langes Kurzzeitgedächtnis, das mit Hilfe von Speicherzellen und einem komplexen Gating-Mechanismus Informationen besser speichert als andere PNS. Das Gating ist ein Verfahren zum Zuweisen eines bestimmten Zeitintervalls, um die Wahrscheinlichkeit zu erhöhen, nützliche Signale vor einem Hintergrund von Interferenzen zu erfassen. Die Einführung solcher Modelle hat die Qualität der Spracherkennung bereits erheblich verbessert.Der nächste Schritt bestand darin, dem akustischen Modell beizubringen, Phoneme (Töne) in der gelieferten Sprache zu erkennen, ohne für jeden Frame eine Vorhersage zu treffen. Modelle mit der assoziativen Zeitklassifizierung erstellen ein Diagramm mit einer Folge von "Spitzen", die die Folge von Tönen im empfangenen Signal anzeigen. Sie können dies tun, bis die Folge unterbrochen ist.Tatsächlich kann das Spracherkennungssystem von Google jetzt den Kontext untersuchen, in dem das Wort gesprochen wurde, und sich von Hintergrundgeräuschen entfernen.
Eine Art von periodischen neuronalen Netzen in diesem System ist ein langes Kurzzeitgedächtnis, das mit Hilfe von Speicherzellen und einem komplexen Gating-Mechanismus Informationen besser speichert als andere PNS. Das Gating ist ein Verfahren zum Zuweisen eines bestimmten Zeitintervalls, um die Wahrscheinlichkeit zu erhöhen, nützliche Signale vor einem Hintergrund von Interferenzen zu erfassen. Die Einführung solcher Modelle hat die Qualität der Spracherkennung bereits erheblich verbessert.Der nächste Schritt bestand darin, dem akustischen Modell beizubringen, Phoneme (Töne) in der gelieferten Sprache zu erkennen, ohne für jeden Frame eine Vorhersage zu treffen. Modelle mit der assoziativen Zeitklassifizierung erstellen ein Diagramm mit einer Folge von "Spitzen", die die Folge von Tönen im empfangenen Signal anzeigen. Sie können dies tun, bis die Folge unterbrochen ist.Tatsächlich kann das Spracherkennungssystem von Google jetzt den Kontext untersuchen, in dem das Wort gesprochen wurde, und sich von Hintergrundgeräuschen entfernen. Eine ganz andere Frage: Wie kann man alles in Echtzeit zugänglich und bequem machen? Nach einer großen Anzahl von Iterationen gelang es Google-Programmierern, Single-Stream-Streaming-Modelle zu erstellen, die eingehende Signale mit Blöcken verarbeiten, die größer als die Blöcke in akustischen Standardmodellen sind, gleichzeitig aber weniger tatsächliche Berechnungen durchführen. Das Reduzieren der Anzahl von Rechenoperationen beschleunigt den Erkennungsprozess erheblich. Außerdem wurden dem Systemtrainingsprogramm künstliches Rauschen und Nachhall (künstliche Reduzierung von Geräuschen) hinzugefügt, um das Erkennungssystem widerstandsfähiger gegen Fremdgeräusche zu machen. Im Video unten können Sie sehen, wie das System den Satz lernt.Dennoch blieb noch ein Problem zu lösen: Das System erstellt weniger Prognosen, verzögert diese jedoch um ca. 300 Millisekunden. Durch die Ausgabe des Ergebnisses nach vollständiger Fertigstellung des Vorschlags wurde die Erkennungsstufe erhöht, gleichzeitig wurden jedoch zusätzliche Verzögerungen für Benutzer verursacht, was für Goolge-Spezialisten völlig inakzeptabel ist. Um das Problem zu lösen, wurde das System geschult, das Ergebnis für jede Phrase zu analysieren und zu produzieren, bevor sie abgeschlossen ist. Dies machte den Erkennungsprozess synchroner mit der normalen Aussprachegeschwindigkeit einer Person. Der Benutzer muss nicht länger warten, bis das Programm seine eigene Version der gesprochenen Phrase anzeigt.In der Google- Anwendung werden bereits neue akustische Modelle für die Sprachsuche und Befehle verwendet(auf Android und iOS) und zum Diktieren auf Android-Geräten. Neue Modelle benötigten weniger Ressourcen, wurden widerstandsfähiger gegen Umgebungsgeräusche und konnten viel schneller Ergebnisse erzielen als ihre Vorgänger. Dies macht die Sprachsuche für den Benutzer angenehmer.
Eine ganz andere Frage: Wie kann man alles in Echtzeit zugänglich und bequem machen? Nach einer großen Anzahl von Iterationen gelang es Google-Programmierern, Single-Stream-Streaming-Modelle zu erstellen, die eingehende Signale mit Blöcken verarbeiten, die größer als die Blöcke in akustischen Standardmodellen sind, gleichzeitig aber weniger tatsächliche Berechnungen durchführen. Das Reduzieren der Anzahl von Rechenoperationen beschleunigt den Erkennungsprozess erheblich. Außerdem wurden dem Systemtrainingsprogramm künstliches Rauschen und Nachhall (künstliche Reduzierung von Geräuschen) hinzugefügt, um das Erkennungssystem widerstandsfähiger gegen Fremdgeräusche zu machen. Im Video unten können Sie sehen, wie das System den Satz lernt.Dennoch blieb noch ein Problem zu lösen: Das System erstellt weniger Prognosen, verzögert diese jedoch um ca. 300 Millisekunden. Durch die Ausgabe des Ergebnisses nach vollständiger Fertigstellung des Vorschlags wurde die Erkennungsstufe erhöht, gleichzeitig wurden jedoch zusätzliche Verzögerungen für Benutzer verursacht, was für Goolge-Spezialisten völlig inakzeptabel ist. Um das Problem zu lösen, wurde das System geschult, das Ergebnis für jede Phrase zu analysieren und zu produzieren, bevor sie abgeschlossen ist. Dies machte den Erkennungsprozess synchroner mit der normalen Aussprachegeschwindigkeit einer Person. Der Benutzer muss nicht länger warten, bis das Programm seine eigene Version der gesprochenen Phrase anzeigt.In der Google- Anwendung werden bereits neue akustische Modelle für die Sprachsuche und Befehle verwendet(auf Android und iOS) und zum Diktieren auf Android-Geräten. Neue Modelle benötigten weniger Ressourcen, wurden widerstandsfähiger gegen Umgebungsgeräusche und konnten viel schneller Ergebnisse erzielen als ihre Vorgänger. Dies macht die Sprachsuche für den Benutzer angenehmer. Source: https://habr.com/ru/post/de384747/
All Articles