IoT und Hackathon Azure Machine Learning: Wie wir das Projekt außerhalb des Wettbewerbs durchgeführt haben
 Vor nicht allzu langer Zeit fand ein weiterer Microsoft- Hackathon statt . Dieses Mal widmete er sich dem maschinellen Lernen . Das Thema ist sehr relevant und vielversprechend, für mich jedoch eher vage. Zu Beginn des Hackathons hatte ich nur eine allgemeine Vorstellung davon, was es war, warum es gebraucht wurde, und ich sah die Ergebnisse der trainierten Modelle einige Male. Nachdem ich erfahren hatte, dass die Ankündigung viele Experten versprach, Anfängern zu helfen, entschied ich mich, Geschäft mit Vergnügen zu verbinden und zu versuchen, maschinelles Lernen zu verwenden, wenn ich mit einer Art IoT- Lösung arbeite . Als nächstes werde ich Ihnen sagen, was daraus geworden ist.Ich habe schon lange in Eingriff Perimeter Sicherheitssystemen, basierend auf der Analyse von Schwingungen des Zauns, so dass , sobald die Idee zur Arbeit mit Beschleunigungssensor. Die Idee war einfach: dem System beizubringen, anhand der Daten des Beschleunigungsmessers zwischen den Vibrationen mehrerer Telefone zu unterscheiden. Ähnliche Experimente wurden bereits von meinen Kollegen erfolgreich durchgeführt, so dass ich keinen Zweifel daran hatte, dass dies möglich war.Anfangs wollte ich alles auf dem Raspberry Pi 2 und Windows IoT machen . Ein spezielles Board wurde (auf dem Foto unten) mit digitalen und analogen Beschleunigungsmessern vorbereitet, aber ich habe es nicht geschafft, es in der Praxis zu versuchen, da ich beschlossen hatte, alles auf einem Hackathon zu machen. Für alle Fälle habe ich auch unseren Sensor erfasst , mit dem Sie auch „Rohdaten“ zu Schwankungen lernen können.
Vor nicht allzu langer Zeit fand ein weiterer Microsoft- Hackathon statt . Dieses Mal widmete er sich dem maschinellen Lernen . Das Thema ist sehr relevant und vielversprechend, für mich jedoch eher vage. Zu Beginn des Hackathons hatte ich nur eine allgemeine Vorstellung davon, was es war, warum es gebraucht wurde, und ich sah die Ergebnisse der trainierten Modelle einige Male. Nachdem ich erfahren hatte, dass die Ankündigung viele Experten versprach, Anfängern zu helfen, entschied ich mich, Geschäft mit Vergnügen zu verbinden und zu versuchen, maschinelles Lernen zu verwenden, wenn ich mit einer Art IoT- Lösung arbeite . Als nächstes werde ich Ihnen sagen, was daraus geworden ist.Ich habe schon lange in Eingriff Perimeter Sicherheitssystemen, basierend auf der Analyse von Schwingungen des Zauns, so dass , sobald die Idee zur Arbeit mit Beschleunigungssensor. Die Idee war einfach: dem System beizubringen, anhand der Daten des Beschleunigungsmessers zwischen den Vibrationen mehrerer Telefone zu unterscheiden. Ähnliche Experimente wurden bereits von meinen Kollegen erfolgreich durchgeführt, so dass ich keinen Zweifel daran hatte, dass dies möglich war.Anfangs wollte ich alles auf dem Raspberry Pi 2 und Windows IoT machen . Ein spezielles Board wurde (auf dem Foto unten) mit digitalen und analogen Beschleunigungsmessern vorbereitet, aber ich habe es nicht geschafft, es in der Praxis zu versuchen, da ich beschlossen hatte, alles auf einem Hackathon zu machen. Für alle Fälle habe ich auch unseren Sensor erfasst , mit dem Sie auch „Rohdaten“ zu Schwankungen lernen können. Beim Hackathon wurden alle Teilnehmer gebeten, sich in Teams aufzuteilen und eines von drei Problemen mit vorbereiteten Daten zu lösen. Meine Aufgabe stellte sich als „außer Konkurrenz“ heraus, aber das Team versammelte sich schnell genug:
Beim Hackathon wurden alle Teilnehmer gebeten, sich in Teams aufzuteilen und eines von drei Problemen mit vorbereiteten Daten zu lösen. Meine Aufgabe stellte sich als „außer Konkurrenz“ heraus, aber das Team versammelte sich schnell genug: Keiner von uns hatte Erfahrung mit Azure Machine Learning, also gab es viel zu tun! Vielen Dank an die Kollegen, darunter auch psfinaki , für ihre Bemühungen!Es wurde beschlossen, in drei Richtungen zu unterteilen:
Keiner von uns hatte Erfahrung mit Azure Machine Learning, also gab es viel zu tun! Vielen Dank an die Kollegen, darunter auch psfinaki , für ihre Bemühungen!Es wurde beschlossen, in drei Richtungen zu unterteilen:- Vorbereitung der Daten für die Analyse
- Daten in die Cloud hochladen
- Arbeiten Sie mit Azure Machine Learning
Die Vorbereitung der Daten bestand darin, sie vom Beschleunigungsmesser abzurufen und dann in einer Form darzustellen, die zum Herunterladen in die Cloud verfügbar ist. Das Hochladen in die Cloud wurde über den Event Hub geplant . Nun, dann mussten Sie verstehen, wie diese Daten in Azure Machine Learning verwendet werden.In allen drei Punkten begannen Probleme. Die Konfiguration von Windows IoT auf Raspberry hat lange gedauert. Sie gab kein Bild auf dem Monitor aus. Dies konnte nur durch Eingabe der folgenden Zeilen in config.txt behoben werden:
Die Konfiguration von Windows IoT auf Raspberry hat lange gedauert. Sie gab kein Bild auf dem Monitor aus. Dies konnte nur durch Eingabe der folgenden Zeilen in config.txt behoben werden:hdmi_ignore_edid=0xa5000080hdmi_drive=2hdmi_group=2hdmi_mode=16Dadurch wurde der Grafiktreiber auf das gewünschte Format, die gewünschte Auflösung und Frequenz eingestellt. Die für diese Lektion aufgewendete Zeit hat jedoch deutlich gemacht, dass Sie möglicherweise keine Zeit haben, den Empfang von Daten vom Beschleunigungsmesser zu organisieren. Daher wurde beschlossen, den Sensor zu verwenden, den ich in Reserve genommen hatte.Viele Anwendungen wurden bereits für den Sensor geschrieben. Einer von ihnen zeigte auf dem Bildschirm eine Grafik mit „Rohdaten“ an:
Die für diese Lektion aufgewendete Zeit hat jedoch deutlich gemacht, dass Sie möglicherweise keine Zeit haben, den Empfang von Daten vom Beschleunigungsmesser zu organisieren. Daher wurde beschlossen, den Sensor zu verwenden, den ich in Reserve genommen hatte.Viele Anwendungen wurden bereits für den Sensor geschrieben. Einer von ihnen zeigte auf dem Bildschirm eine Grafik mit „Rohdaten“ an: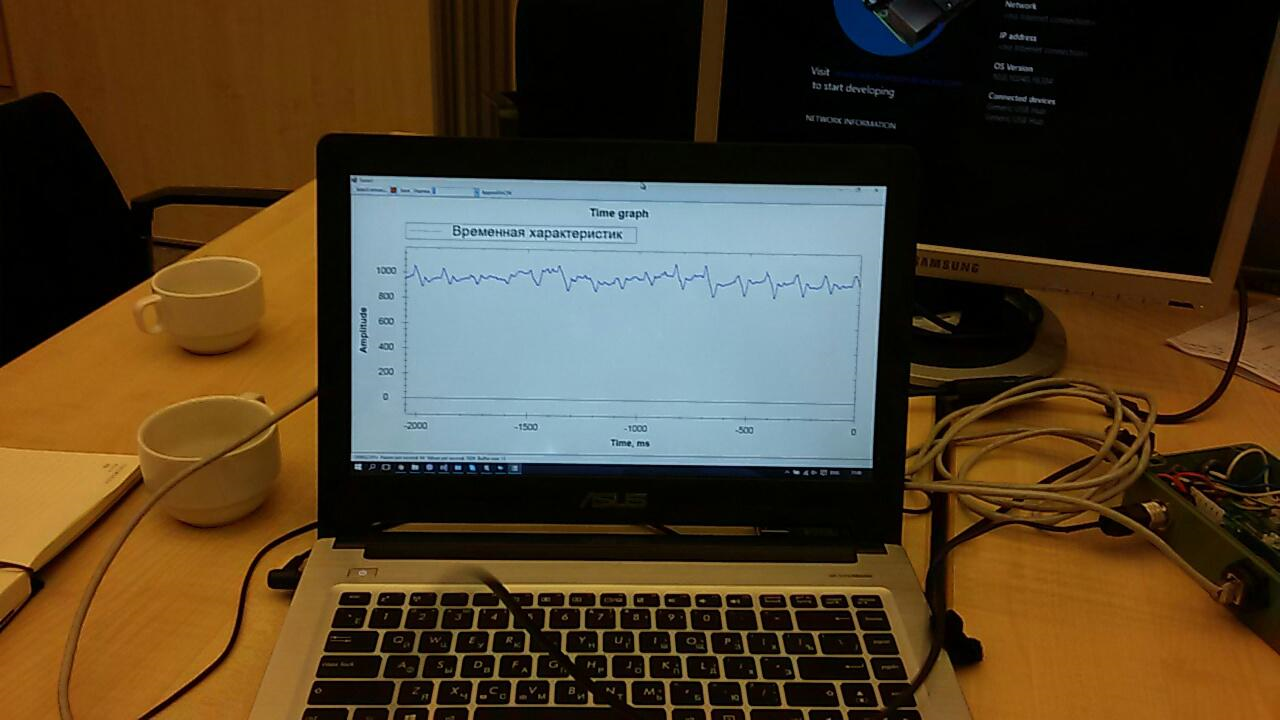 Es war notwendig, diese ein wenig zu vervollständigen, um die Daten für das Senden an die Cloud vorzubereiten.Event Hub funktionierte auch nicht sofort. Zunächst haben wir versucht, nur eine zufällige Sequenz dorthin zu senden. Die Daten wollten jedoch nicht in den Berichten erscheinen. Es gab mehrere Probleme, und wie sich herausstellte, waren sie alle „kindisch“: Sie haben etwas falsch eingerichtet, irgendwo den falschen Schlüssel verwendet und so weiter. Die Arbeit in diese Richtung war schwierig und kostete viel Energie:
Es war notwendig, diese ein wenig zu vervollständigen, um die Daten für das Senden an die Cloud vorzubereiten.Event Hub funktionierte auch nicht sofort. Zunächst haben wir versucht, nur eine zufällige Sequenz dorthin zu senden. Die Daten wollten jedoch nicht in den Berichten erscheinen. Es gab mehrere Probleme, und wie sich herausstellte, waren sie alle „kindisch“: Sie haben etwas falsch eingerichtet, irgendwo den falschen Schlüssel verwendet und so weiter. Die Arbeit in diese Richtung war schwierig und kostete viel Energie: Aber am Abend des ersten Tages konnten wir Daten vom Sensor im laufenden Betrieb senden und empfangen ... Richtig, dies war in der endgültigen Lösung nicht erforderlich. Ich werde etwas später über die Gründe sprechen.Beim maschinellen Lernen war überhaupt nichts klar. Zuerst haben wir zusammen das Schöne studiertArtikel mit einem Beispiel für die Verwendung einer mobilen Anwendung als Client. Dann haben wir das Datenformat und die Arbeitsweise herausgefunden. Dann überlegten sie, wie man Trainingssequenzen erstellt.Azure Mashine Learning verfügt über viele Algorithmen für verschiedene Klassifizierungen. Diese Algorithmen müssen an einem Testdatensatz trainiert werden. Diejenigen, die das beste Ergebnis erzielen, können dann als Webdienst veröffentlicht und über die Anwendung mit ihnen verbunden werden.Das Erlernen eines Algorithmus wird als "Experiment" bezeichnet. Alle Aktionen werden in einem visuellen Editor ausgeführt: Durch
Aber am Abend des ersten Tages konnten wir Daten vom Sensor im laufenden Betrieb senden und empfangen ... Richtig, dies war in der endgültigen Lösung nicht erforderlich. Ich werde etwas später über die Gründe sprechen.Beim maschinellen Lernen war überhaupt nichts klar. Zuerst haben wir zusammen das Schöne studiertArtikel mit einem Beispiel für die Verwendung einer mobilen Anwendung als Client. Dann haben wir das Datenformat und die Arbeitsweise herausgefunden. Dann überlegten sie, wie man Trainingssequenzen erstellt.Azure Mashine Learning verfügt über viele Algorithmen für verschiedene Klassifizierungen. Diese Algorithmen müssen an einem Testdatensatz trainiert werden. Diejenigen, die das beste Ergebnis erzielen, können dann als Webdienst veröffentlicht und über die Anwendung mit ihnen verbunden werden.Das Erlernen eines Algorithmus wird als "Experiment" bezeichnet. Alle Aktionen werden in einem visuellen Editor ausgeführt: Durch Ziehen und Ablegen von Elementen aus der Liste links können Sie Daten empfangen, ändern und transformieren, Modelle trainieren und ihre Arbeit bewerten.So sieht ein typisches Experiment aus:
Ziehen und Ablegen von Elementen aus der Liste links können Sie Daten empfangen, ändern und transformieren, Modelle trainieren und ihre Arbeit bewerten.So sieht ein typisches Experiment aus: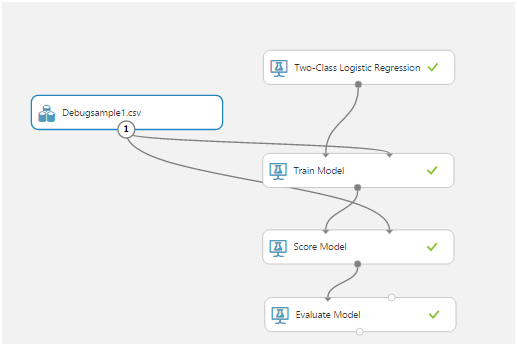 Das Zugmodell, das Punktemodell und das Bewertungsmodell erwiesen sich als das wichtigste.Der erste trainiert anhand der Eingabedaten den Algorithmus, der zweite testet den trainierten Algorithmus am Datensatz, der dritte wertet das Testergebnis aus.Die Quelldaten in unserem Fall sind eine CSV-Datei. Aber was sollte darin enthalten sein?Das empfindliche Element unseres Sensors wird 1024 Mal pro Sekunde abgefragt. Jede Vermessung ist ein Zwei-Byte-Wert, der der Amplitude der Stromschwingung entspricht. Darüber hinaus wird die Amplitude nicht von Null aus gemessen, sondern von der Referenznummer, die einem festen Sensor entspricht.Nach dem Nachdenken entschieden wir uns, temporäre Scheiben zu verwenden. Zum Beispiel gaben uns alle Sensorabfragen für 256 ms eine Zeile in der CSV-Tabelle. Diese Daten in einer zusätzlichen Spalte können auf die eine oder andere Weise markiert werden, je nachdem, was mit dem Sensor geschieht. Zum Beispiel haben wir 0 verwendet, um Rauschen anzuzeigen (Schütteln des Sensors mit den Händen, Tippen usw.) und 1, um das Signal anzuzeigen (am Sensor befindet sich ein vibrierendes Telefon).So haben wir die Testsequenzen aufgezeichnet:
Das Zugmodell, das Punktemodell und das Bewertungsmodell erwiesen sich als das wichtigste.Der erste trainiert anhand der Eingabedaten den Algorithmus, der zweite testet den trainierten Algorithmus am Datensatz, der dritte wertet das Testergebnis aus.Die Quelldaten in unserem Fall sind eine CSV-Datei. Aber was sollte darin enthalten sein?Das empfindliche Element unseres Sensors wird 1024 Mal pro Sekunde abgefragt. Jede Vermessung ist ein Zwei-Byte-Wert, der der Amplitude der Stromschwingung entspricht. Darüber hinaus wird die Amplitude nicht von Null aus gemessen, sondern von der Referenznummer, die einem festen Sensor entspricht.Nach dem Nachdenken entschieden wir uns, temporäre Scheiben zu verwenden. Zum Beispiel gaben uns alle Sensorabfragen für 256 ms eine Zeile in der CSV-Tabelle. Diese Daten in einer zusätzlichen Spalte können auf die eine oder andere Weise markiert werden, je nachdem, was mit dem Sensor geschieht. Zum Beispiel haben wir 0 verwendet, um Rauschen anzuzeigen (Schütteln des Sensors mit den Händen, Tippen usw.) und 1, um das Signal anzuzeigen (am Sensor befindet sich ein vibrierendes Telefon).So haben wir die Testsequenzen aufgezeichnet: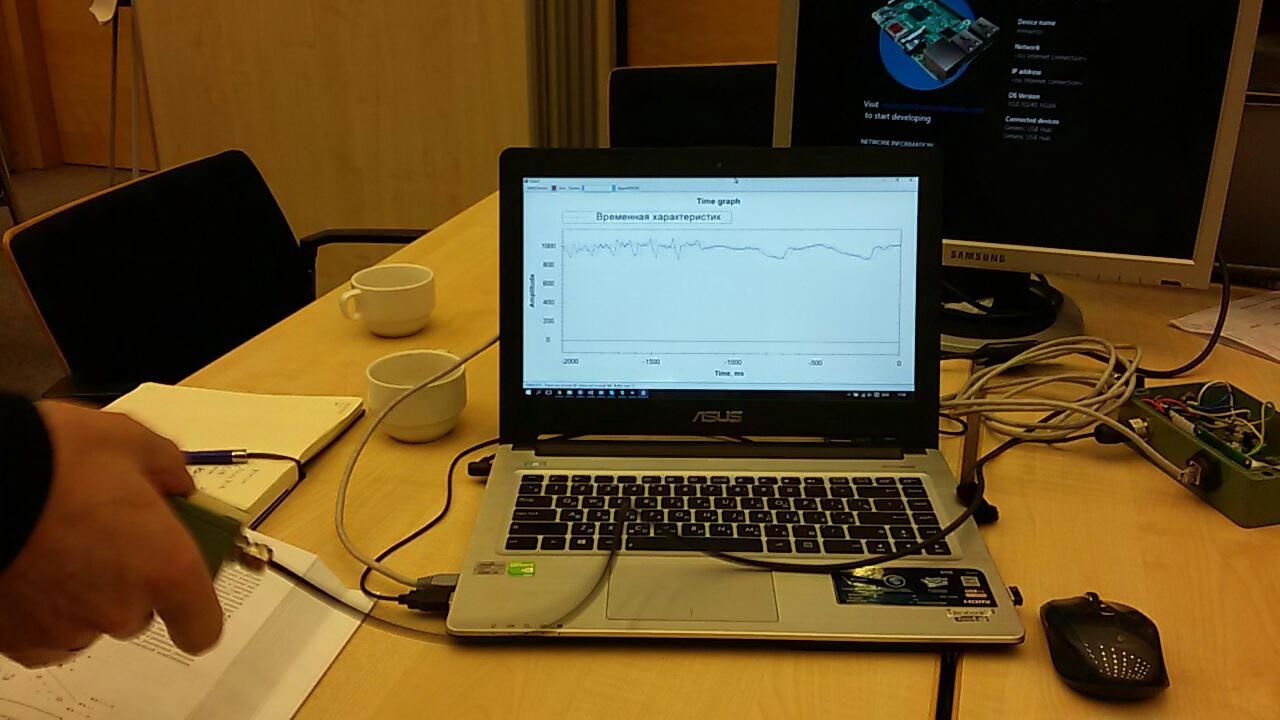 Nachdem wir die Daten erhalten und erkannt hatten, was mit ihnen zu tun ist, lernten wir das erste Modell:
Nachdem wir die Daten erhalten und erkannt hatten, was mit ihnen zu tun ist, lernten wir das erste Modell: Der erste Pfannkuchen erwies sich als klumpig:
Der erste Pfannkuchen erwies sich als klumpig: Zu diesem Zeitpunkt war selbst die Bedeutung dieser Indikatoren nicht klar. Wir wurden von einem Vertreter des Supportteams, Jewgeni Grigorenko, gerettet, der über die ROC-Kurven sprach. Die Hauptsache war, dass wenn das Diagramm an einer Stelle unterhalb der Mittellinie liegt, das Modell noch schlechter funktioniert als wenn es ein zufälliges Ergebnis liefert! Eugene half uns weiterhin so viel er konnte, wofür wir ihm vielmals danken!
Zu diesem Zeitpunkt war selbst die Bedeutung dieser Indikatoren nicht klar. Wir wurden von einem Vertreter des Supportteams, Jewgeni Grigorenko, gerettet, der über die ROC-Kurven sprach. Die Hauptsache war, dass wenn das Diagramm an einer Stelle unterhalb der Mittellinie liegt, das Modell noch schlechter funktioniert als wenn es ein zufälliges Ergebnis liefert! Eugene half uns weiterhin so viel er konnte, wofür wir ihm vielmals danken! Dann haben wir die Trainingssequenz für eine lange Zeit umgeschrieben und uns die Ergebnisse angesehen:
Dann haben wir die Trainingssequenz für eine lange Zeit umgeschrieben und uns die Ergebnisse angesehen: Es stellte sich heraus, dass die Arbeit mit einer 2-Sekunden-Aufzeichnung (2048 Sensorumfragen) weniger optimal war. Dies ermöglichte es uns, Tabellen-CSV-Zeilen aussagekräftiger zu machen. Das Ergebnis war jedoch alles andere als gut.Dies endete am ersten Tag.Ich verbrachte die Nacht damit, das Material zu studieren. Der Artikel hat wirklich geholfenüber binäre Klassifikation. Ich habe auch den Artikel mit Tipps für diesen Hackathon sorgfältig gelesen . Im Allgemeinen war ich zu Beginn der Arbeit voller neuer Ideen.Wir haben die gesamte erste Hälfte des zweiten Tages damit verbracht, verschiedene Modelle zu studieren. Das Ergebnis der Arbeit war ein solches „Blatt“:
Es stellte sich heraus, dass die Arbeit mit einer 2-Sekunden-Aufzeichnung (2048 Sensorumfragen) weniger optimal war. Dies ermöglichte es uns, Tabellen-CSV-Zeilen aussagekräftiger zu machen. Das Ergebnis war jedoch alles andere als gut.Dies endete am ersten Tag.Ich verbrachte die Nacht damit, das Material zu studieren. Der Artikel hat wirklich geholfenüber binäre Klassifikation. Ich habe auch den Artikel mit Tipps für diesen Hackathon sorgfältig gelesen . Im Allgemeinen war ich zu Beginn der Arbeit voller neuer Ideen.Wir haben die gesamte erste Hälfte des zweiten Tages damit verbracht, verschiedene Modelle zu studieren. Das Ergebnis der Arbeit war ein solches „Blatt“: Zu diesem Zeitpunkt war bereits klar, dass wir einfach keine Zeit hatten, zwischen zwei Vibrationsringen zu unterscheiden, da die Qualität der Trainingsdaten zu wünschen übrig ließ und nicht genügend Zeit blieb, um neue aufzunehmen. Daher haben wir uns auf die Trennung von Daten in „Signal“ und „Rauschen“ konzentriert.Für die Arbeit haben wir 3 Datensätze verwendet:
Zu diesem Zeitpunkt war bereits klar, dass wir einfach keine Zeit hatten, zwischen zwei Vibrationsringen zu unterscheiden, da die Qualität der Trainingsdaten zu wünschen übrig ließ und nicht genügend Zeit blieb, um neue aufzunehmen. Daher haben wir uns auf die Trennung von Daten in „Signal“ und „Rauschen“ konzentriert.Für die Arbeit haben wir 3 Datensätze verwendet:- Ein Trainingssatz, in dem ein Signal (Zeilen der mit 1 gekennzeichneten CSV-Datei) und Rauschen (mit 0 gekennzeichnete Zeilen) vorhanden waren.
- Ein Set, das nur Rauschen enthält (Zeilen von 0)
- Ein Satz, der nur das Signal enthält (Zeilen von 1)
Die Modelle wurden zuerst trainiert, dann getestet und an jedem der Datensätze bewertet. Die Ergebnisse waren ermutigend: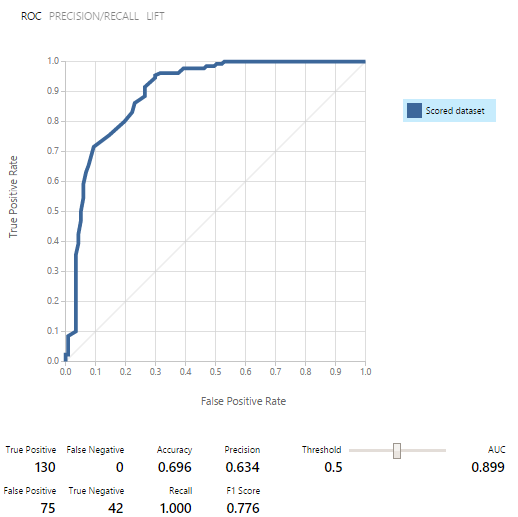 Aus neun Modellen der binären Klassifikation haben wir fünf ausgewählt.Wie sich herausstellte, ist die Verwendung des Modells als Webdienst viel einfacher als das Verschrauben mit dem Event-Hub. Aus diesem Grund haben wir uns entschlossen, alle 5 Modelle zu veröffentlichen und mit ihnen über REQUEST / RESPONSE zu arbeiten, was von einem sehr guten Beispiel begleitet wird.
Aus neun Modellen der binären Klassifikation haben wir fünf ausgewählt.Wie sich herausstellte, ist die Verwendung des Modells als Webdienst viel einfacher als das Verschrauben mit dem Event-Hub. Aus diesem Grund haben wir uns entschlossen, alle 5 Modelle zu veröffentlichen und mit ihnen über REQUEST / RESPONSE zu arbeiten, was von einem sehr guten Beispiel begleitet wird. Die Anforderung ist ein Eingabearray mit 2048 Werten, die vom Sensor übernommen wurden. Die Antwort sieht so aus:
Die Anforderung ist ein Eingabearray mit 2048 Werten, die vom Sensor übernommen wurden. Die Antwort sieht so aus: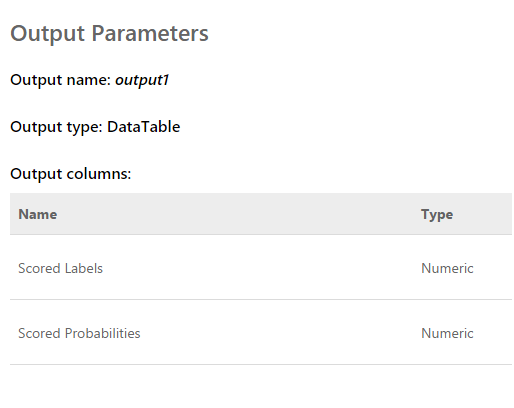 Die bewerteten Bezeichnungen sind entweder 0 oder 1. Das heißt, das Ergebnis der Klassifizierung. Bewertete Wahrscheinlichkeiten - eine Dezimalzahl, die die Richtigkeit der Bewertung widerspiegelt. So wie ich es verstehe, rundet der erste Wert den zweiten. Das heißt, je näher der zweite Wert an 0 liegt, desto wahrscheinlicher ist die Punktzahl 0 und umgekehrt. Je näher der Wert an 1 liegt, desto wahrscheinlicher ist die Punktzahl 1.Nachdem wir das Programm fertiggestellt hatten, das das Diagramm „Rohdaten“ auf dem Bildschirm anzeigt, konnten wir gleichzeitig Daten von allen fünf Webdiensten aus mehreren Streams empfangen. Nachdem wir die Schätzungen ein wenig beobachtet hatten, schlossen wir eine aus, da dies zu einem Ergebnis führte, das sich von den anderen völlig unterschied und das gesamte Bild beeinträchtigte.Das Ergebnis ist folgendes:
Die bewerteten Bezeichnungen sind entweder 0 oder 1. Das heißt, das Ergebnis der Klassifizierung. Bewertete Wahrscheinlichkeiten - eine Dezimalzahl, die die Richtigkeit der Bewertung widerspiegelt. So wie ich es verstehe, rundet der erste Wert den zweiten. Das heißt, je näher der zweite Wert an 0 liegt, desto wahrscheinlicher ist die Punktzahl 0 und umgekehrt. Je näher der Wert an 1 liegt, desto wahrscheinlicher ist die Punktzahl 1.Nachdem wir das Programm fertiggestellt hatten, das das Diagramm „Rohdaten“ auf dem Bildschirm anzeigt, konnten wir gleichzeitig Daten von allen fünf Webdiensten aus mehreren Streams empfangen. Nachdem wir die Schätzungen ein wenig beobachtet hatten, schlossen wir eine aus, da dies zu einem Ergebnis führte, das sich von den anderen völlig unterschied und das gesamte Bild beeinträchtigte.Das Ergebnis ist folgendes: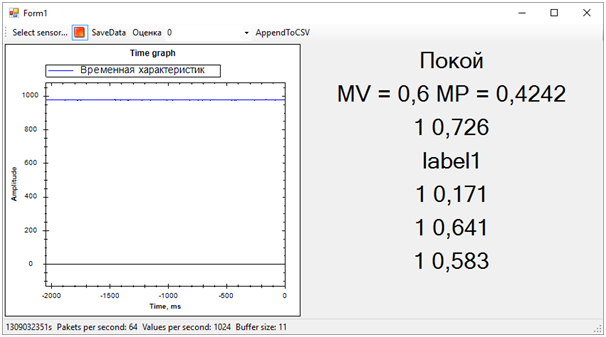
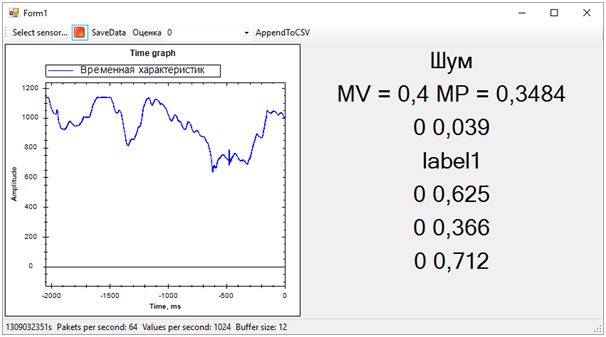
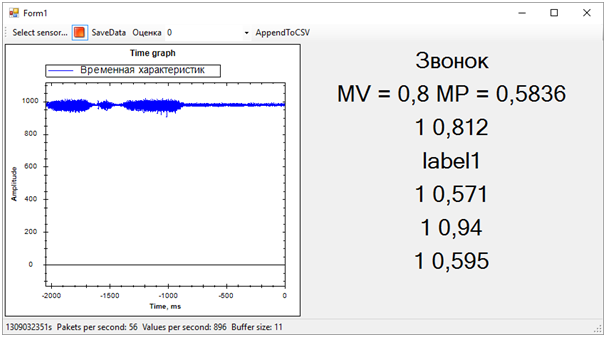 Dann wurden alle Probleme der Trainingssequenz sofort gelöst. Obwohl wir versucht haben, den Vibrationsalarm von allem anderen (Lärm und Ruhe) zu trennen, stellte sich heraus, dass der Ruhezustand dem Anruf sehr nahe kam. Dies wurde jedoch nicht immer festgestellt. Die Differenz zwischen dem Anruf und dem Rest haben wir durch die durchschnittliche Anzahl von Wahrscheinlichkeiten für jedes Modell bestimmt. Ein Wert näher an 1 bedeutet einen Anruf, ein Wert von ungefähr 0,5 mit einer Punktzahl von 1 ist Frieden. Nun, wenn die Punktzahl 0 ist, ist dies definitiv Rauschen.Zu diesem Zeitpunkt ging der Hackathon zu Ende. Wir hatten nicht einmal Zeit, den Experten die Ergebnisse zu zeigen, da sie mit der Auswertung der Einträge beschäftigt waren.All dies war jedoch nicht mehr von besonderer Bedeutung. Vor allem haben wir ein völlig vernünftiges Ergebnis erzielt und gleichzeitig viel gelernt!In zwei Tagen harter Arbeit haben wir die Aufgabe erledigt, wenn auch teilweise. Vielen Dank an die Kollegen aus dem Team und die Experten, die uns geholfen haben!Jetzt können wir die Entwicklungspfade unseres Projekts notieren. Wir haben Zeitmerkmale verwendet, um Ereignisse zu trennen. Wenn wir jedoch in den Frequenzbereich wechseln, sollte die Effizienz der Algorithmen höher sein. Rauschen, Frieden und Glocke haben deutlich unterschiedliche spektrale Eigenschaften.Darüber hinaus schlugen erfahrene Personen vor, die Daten zu normalisieren. Das heißt, die Nummern der Eingabesequenz müssen im Bereich von -1 bis +1 liegen. Algorithmen arbeiten effizienter mit solchen Daten.Gut und dennoch ist es notwendig, an der Bildung von Trainingssequenzen zu arbeiten, um das Signal klarer vom Rauschen zu trennen.Diese Verbesserungen sollten die Genauigkeit der Zustandsbestimmung erheblich erhöhen, die ich in Zukunft überprüfen möchte.
Dann wurden alle Probleme der Trainingssequenz sofort gelöst. Obwohl wir versucht haben, den Vibrationsalarm von allem anderen (Lärm und Ruhe) zu trennen, stellte sich heraus, dass der Ruhezustand dem Anruf sehr nahe kam. Dies wurde jedoch nicht immer festgestellt. Die Differenz zwischen dem Anruf und dem Rest haben wir durch die durchschnittliche Anzahl von Wahrscheinlichkeiten für jedes Modell bestimmt. Ein Wert näher an 1 bedeutet einen Anruf, ein Wert von ungefähr 0,5 mit einer Punktzahl von 1 ist Frieden. Nun, wenn die Punktzahl 0 ist, ist dies definitiv Rauschen.Zu diesem Zeitpunkt ging der Hackathon zu Ende. Wir hatten nicht einmal Zeit, den Experten die Ergebnisse zu zeigen, da sie mit der Auswertung der Einträge beschäftigt waren.All dies war jedoch nicht mehr von besonderer Bedeutung. Vor allem haben wir ein völlig vernünftiges Ergebnis erzielt und gleichzeitig viel gelernt!In zwei Tagen harter Arbeit haben wir die Aufgabe erledigt, wenn auch teilweise. Vielen Dank an die Kollegen aus dem Team und die Experten, die uns geholfen haben!Jetzt können wir die Entwicklungspfade unseres Projekts notieren. Wir haben Zeitmerkmale verwendet, um Ereignisse zu trennen. Wenn wir jedoch in den Frequenzbereich wechseln, sollte die Effizienz der Algorithmen höher sein. Rauschen, Frieden und Glocke haben deutlich unterschiedliche spektrale Eigenschaften.Darüber hinaus schlugen erfahrene Personen vor, die Daten zu normalisieren. Das heißt, die Nummern der Eingabesequenz müssen im Bereich von -1 bis +1 liegen. Algorithmen arbeiten effizienter mit solchen Daten.Gut und dennoch ist es notwendig, an der Bildung von Trainingssequenzen zu arbeiten, um das Signal klarer vom Rauschen zu trennen.Diese Verbesserungen sollten die Genauigkeit der Zustandsbestimmung erheblich erhöhen, die ich in Zukunft überprüfen möchte.Source: https://habr.com/ru/post/de387857/
All Articles