Ein weiterer Schritt im maschinellen Selbstlernen
 Natürlich gibt es in Data Science viele selbstlernende Modelle, aber sind sie es wirklich? Nein, jetzt gibt es beim maschinellen Lernen eine Situation, in der der Faktor Mensch eine entscheidende Rolle beim Aufbau effektiver Modelle spielt.Data Science ist jetzt eine Art Verschmelzung von Wissenschaft und Intuition, da es kein formalisiertes Wissen darüber gibt, wie Prädiktoren korrekt vorhergesagt werden können, welches Modell aus Dutzenden vorhandener Modelle ausgewählt werden kann und wie viele Parameter in diesem Modell konfiguriert werden. All dies ist schwer zu formalisieren, und daher entsteht eine paradoxe Situation - maschinelles Lernen erfordert einen menschlichen Faktor.Es ist die Person, die die Lernkette aufbauen und die Parameter anpassen muss, die das beste Modell leicht in absolut nutzlos verwandeln können. Der Aufbau dieser Kette, die die Anfangsdaten in ein Vorhersagemodell umwandelt, kann je nach Komplexität der Aufgabe mehrere Wochen dauern und erfolgt häufig einfach durch Ausprobieren.Dies ist ein schwerwiegender Fehler, und daher entstand die Idee: Kann maschinelles Lernen - sich auf die gleiche Weise wie eine Person weiterbilden? Ein solches System wurde geschaffen, und es ist überraschend, dass diese Nachricht die Habrasociety noch nicht erreicht hat!
Natürlich gibt es in Data Science viele selbstlernende Modelle, aber sind sie es wirklich? Nein, jetzt gibt es beim maschinellen Lernen eine Situation, in der der Faktor Mensch eine entscheidende Rolle beim Aufbau effektiver Modelle spielt.Data Science ist jetzt eine Art Verschmelzung von Wissenschaft und Intuition, da es kein formalisiertes Wissen darüber gibt, wie Prädiktoren korrekt vorhergesagt werden können, welches Modell aus Dutzenden vorhandener Modelle ausgewählt werden kann und wie viele Parameter in diesem Modell konfiguriert werden. All dies ist schwer zu formalisieren, und daher entsteht eine paradoxe Situation - maschinelles Lernen erfordert einen menschlichen Faktor.Es ist die Person, die die Lernkette aufbauen und die Parameter anpassen muss, die das beste Modell leicht in absolut nutzlos verwandeln können. Der Aufbau dieser Kette, die die Anfangsdaten in ein Vorhersagemodell umwandelt, kann je nach Komplexität der Aufgabe mehrere Wochen dauern und erfolgt häufig einfach durch Ausprobieren.Dies ist ein schwerwiegender Fehler, und daher entstand die Idee: Kann maschinelles Lernen - sich auf die gleiche Weise wie eine Person weiterbilden? Ein solches System wurde geschaffen, und es ist überraschend, dass diese Nachricht die Habrasociety noch nicht erreicht hat!TROT (Tree-based Pipeline Optimization Tool)
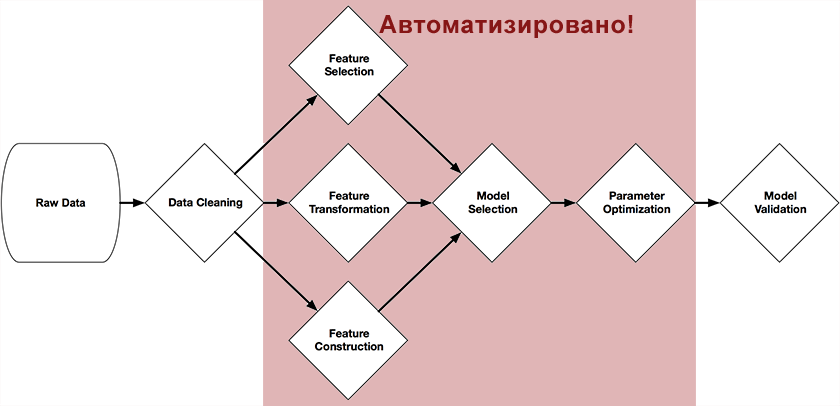
Randy Olson, ein Doktorand am Computational Genetics Lab (Universität von Pennsylvania), entwickelte im Rahmen seines Abschlussprojekts ein baumbasiertes Pipeline-Optimierungstool .Dieses System ist als Data Science-Assistent positioniert. Es automatisiert den mühsamsten Teil des maschinellen Lernens, Studierens und Auswählens unter Tausenden von möglichen Gebäudeketten, genau der, die für die Verarbeitung Ihrer Daten am besten geeignet ist.Das System wurde in Python unter Verwendung der Scikit-Learn-Bibliothek geschrieben und baut durch genetische Algorithmen unabhängig voneinander eine vollständige Kette der Modellvorbereitung und -konstruktion auf. Die Abbildung am Anfang dieses Artikels zeigt die Teile der Kette, die mit ihrer Hilfe automatisiert werden können: Vorverarbeitung und Auswahl von Prädiktoren, Auswahl von Modellen, Optimierung ihrer Parameter.Die Idee ist ganz einfach - ein genetischer Algorithmus .Dies ist ein Algorithmus zum Finden der Kette, die wir durch zufällige Auswahl benötigen, unter Verwendung von Mechanismen, die der natürlichen Auswahl in der Natur ähnlich sind. Sie sind in Wikipedia , im Habr oder im Buch "Selbstlernende Systeme" ausreichend detailliert beschrieben.(Ich empfehle allen, die sich für dieses Thema interessieren, ein Netzwerk in elektronischer Form).In Abhängigkeit von der Auswahl (Fitnessfunktion) wird die Genauigkeit der Vorhersage im Testsatz verwendet, da ein Objekt der Population Scikit-Methoden und deren Parameter sind.Ergebnisse
Der Autor hat ein einfaches Beispiel für die Verwendung von TPOT zur Lösung des Referenzproblems für die Klassifizierung handschriftlicher Ziffern aus dem MNIST-Satzfrom tpot import TPOT
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75)
tpot = TPOT(generations=5, verbosity=2)
tpot.fit(X_train, y_train)
print( tpot.score(X_train, y_train, X_test, y_test) )
tpot.export('tpot_exported_pipeline.py')
Wenn Sie den Code ausführen, kann TPOT nach einigen Minuten die Modellbaukette abrufen, deren Genauigkeit 98% erreicht. Dies geschieht, wenn TPOT feststellt, dass der Random Forest-Klassifikator für MNIST-Daten perfekt funktioniert.Da dieser Prozess jedoch probabilistisch ist, wird empfohlen, den Parameter random_state für wiederholbare Ergebnisse festzulegen. Beispielsweise habe ich für 5 Generationen nur eine Kette mit SVC und KNeighborsClassifier gefunden.Die Überprüfung des Systems auf ein anderes klassisches Problem, die Iris von Fisher , ergab eine Genauigkeit von 97% über 10 Generationen.Die Zukunft
Trot ist ein Open-Source-Projekt, das vor einem Monat entstanden ist (was für solche Systeme im Allgemeinen das Alter eines Kindes ist) und sich jetzt aktiv weiterentwickelt. Auf der Website des Projekts ermutigt der Autor die Data Scientists-Community, sich an der Entwicklung eines Systems zu beteiligen, dessen Code auf github verfügbar ist (https://github.com/rhiever/tpot).Natürlich ist das System jetzt alles andere als ideal, aber die Idee dieses Systems sieht äußerst logisch aus - vollständige Automatisierung der gesamte Prozess des maschinellen Lernens. Und wenn sich die Idee entwickelt, werden vielleicht bald Systeme auftauchen, in denen eine Person nur Daten herunterladen und ein Ergebnis erhalten muss. Und dann stellt sich eine andere Frage: Wird eine Person überhaupt benötigt, um selbstlernende Modelle zu erstellen?